1)Python笔试基础知识
问以下类定义中哪些是类属性,哪些是实例属性?
答:num 和 count 是类属性(静态变量),x 和 y 是实例属性;通常你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。

问以下类定义中哪些是类属性,哪些是实例属性?
答:num 和 count 是类属性(静态变量),x 和 y 是实例属性;通常你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。
问以下类定义中哪些是类属性,哪些是实例属性?
答:num 和 count 是类属性(静态变量),x 和 y 是实例属性;通常你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。
1 | class C: |
如何优雅地避免访问对象不存在的属性(不产生异常)?
1 | @something |
在鸭子类型中,关注的不是对象的类型本身,而是它是如何使用的; 鸭子类型通常得益于不测试方法和函数中参数的类型,而是依赖文档、清晰的代码和测试来确保正确使用。
注意事项:
1 | #!/usr/bin/python3 |
总结:
1 | #!/usr/bin/python3 |
总结:
(1) 协程(协同程序)与子例程
调用一个普通的 Python 函数时,结束于 return 语句、异常或者函数结束(可以看作隐式的返回 None),函数中做的所有工作以及保存在局部变量中的数据都将丢失;
函数需要能够“保存自己的工作”,这时便是yield出现的最佳时期;
当生成器函数调用 yield,生成器函数的“状态”会被冻结,所有的变量的值会被保留下来,下一行要执行的代码的位置也会被记录,调用一次next()就指向下一个yield位置(永远不会退回指向)。
while 循环是用来确保生成器函数永远也不会执行到函数末尾的,只要调用 next() 这个生成器就会生成一个值(引出了一个处理无穷序列的常见方法(这类生成器也是很常见的));
当 yield 关键字返回 number 的值,而像 other = yield foo 这样的语句的意思是,“返回 foo 的值,这个值返回给调用者的同时将 other 的值也设置为那个值”1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def get_primes(number):
while True:
if is_prime(number):
number = yield number #如普通函数return一样将值返回给调用则
number += 1
def print_successive_primes(iterations, base=10):
prime_generator = get_primes(base)
prime_generator.send(None) #必须调用设置None才能 通过 send 方法来将一个值“发送”给生成器。
for power in range(iterations):
print(prime_generator.send(base ** power)) #发生send值
# 首先我们打印的是 generator.send 的结果是OK的,因为 send 在发送数据给生成器的同时还返回生成器通过 yield 生成的值(就如同生成器中 yield 语句做的那样)。
# 看一下 prime_generator.send(None) 这一行,当你用 send 来“启动”一个生成器时(就是从生成器函数的第一行代码执行到第一个 yield 语句的位置),你必须发送 None。这
# 不难理解,根据刚才的描述,生成器还没有走到第一个 yield 语句,如果我们发生一个真实的值,这时是没有人去“接收”它的。一旦生成器启动了,我们就可以像上面那样发送数据了。
案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45import random
def get_data():
"""返回0到9之间的3个随机数"""
return random.sample(range(10), 3)
def consume():
"""显示每次传入的整数列表的动态平均值"""
running_sum = 0
data_items_seen = 0
while True:
data = yield #生成器接收点 关键点
data_items_seen += len(data) # 每次调用值将会保留,下次执行的时候将会调用该值
running_sum += sum(data) #
print('The running average is {}'.format(running_sum / float(data_items_seen)))
def produce(consumer):
"""产生序列集合,传递给消费函数(consumer)"""
while True:
data = get_data()
print('Produced {}'.format(data))
consumer.send(data) #关键点 #通过 send 方法来将一个值“发送”给生成器。
yield #设置生成器
if __name__ == '__main__':
consumer = consume()
consumer.send(None) #启动生成器
producer = produce(consumer)
for _ in range(3):
print('Producing...')
next(producer)
########### 执行结果 ################
# 传递进去的值不会随着函数接收而消失,而是暂时进行了保存(以供下次使用);
# Producing...
# Produced [0, 9, 8]
# The running average is 5.666666666666667
# Producing...
# Produced [2, 3, 1]
# The running average is 3.8333333333333335
# Producing...
# Produced [3, 5, 2]
# The running average is 3.666666666666666
注意事项:
1 | def __setattr__(self, name, value): |

weiyigeek.top-错误根源
1 | class Counter: |
1 | # a.py |
难道模块也可以是一个对象?
没错啦在 Python 中无处不对象,到处都是你的对象。使用以下方法可以将你的模块与类 A 的对象挂钩。
1 | # 该模块用于让 Python 支持常量操作 |
案例:1
2
3
4
5
6
7
8
9
10#实现一个功能与 reversed() 相同(内置函数 reversed(seq) 是返回一个迭代器,是序列 seq 的逆序显示)的生成器
>>> for i in myRev("FishC"):
print(i, end='')
ChsiF
def myRev(data):
# 这里用 range 生成 data 的倒序索引
# 注意,range 的结束位置是不包含的
for index in range(len(data)-1, -1, -1):
yield data[index]
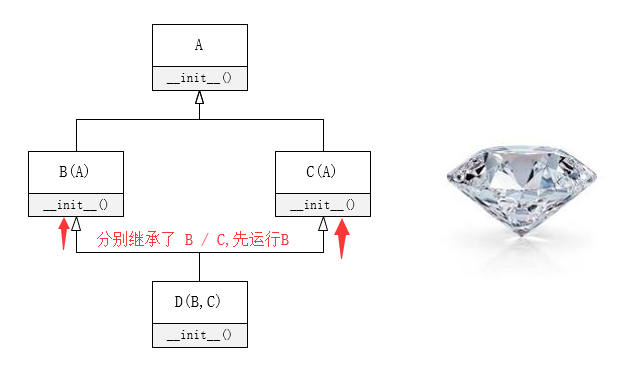
weiyigeek.top-钻石继承
Q:钻石继承(菱形继承)会带来什么问题?
多重继承容易导致钻石继承(菱形继承)问题,上边代码实例化 D 类后我们发现 A 被前后进入了两次。
Q:这有什么危害?
我举个例子,假设 A 的初始化方法里有一个计数器,那这样 D 一实例化,A 的计数器就跑两次(如果遭遇多个钻石结构重叠还要更多),很明显是不符合程序设计的初衷的(程序应该可控,而不能受到继承关系影响)。
Q:如何避免钻石继承(菱形继承)问题?
为解决这个问题,Python 使用了一个叫“方法解析顺序(Method Resolution Order,MRO)”的东西,还用了一个叫 C3 的算法。
解释下 MRO 的顺序基本就是:在避免同一类被调用多次的前提下,使用广度优先和从左到右的原则去寻找需要的属性和方法。
在继承体系中,C3 算法确保同一个类只会被搜寻一次。
例子中如果一个属性或方法在 D 类中没有被找到,Python 就会搜寻 B 类,然后搜索 C类,如果都没有找到,会继续搜索 B 的基类 A,如果还是没有找到,则抛出“AttributeError”异常。
使用 类名.mro 获得 MRO 的顺序(注:object 是所有类的基类,金字塔的顶端):1
2>>> D.__mro__
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
解决方法:你应该召唤 super 函数大显神威1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
super().__init__() #超类
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
super().__init__() #超类
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
super().__init__() #超类
print("离开D…")
############## 执行结果 ###############
# >>> d = D()
# 进入D…
# 进入B…
# 进入C…
# 进入A…
# 离开A…
# 离开C…
# 离开B…
# 离开D…
定义一个点(Point)类和直线(Line)类,使用 getLen 方法可以获得直线的长度。
1 | #设点 A(X1,Y1)、点 B(X2,Y2),则两点构成的直线长度 |AB| = √((x1-x2)^2+(y1-y2)^2) |
Python Mixin 编程机制学习说明?
!important
Mixin 编程是一种开发模式,是一种将多个类中的功能单元的进行组合的利用的方式,这听起来就像是有类的继承机制就可以实现,然而这与传统的类继承有所不同。
通常 Mixin 并不作为任何类的基类,也不关心与什么类一起使用,而是在运行时动态的同其他零散的类一起组合使用。
Mixin 机制特点:
Mixin 机制实现方法:
插件方式:通常我们希望修改对象的行为,而不是修改类的。同样的我们可以利用dict来扩展对象的方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51#!/usr/bin/python3
#功能:采用字典的方式来扩展对象方法 (值得学习)
class PlugIn(object): #注意这里的参数
def __init__(self):
self._exported_methods = []
def plugin(self, owner): #owner 即 我们combine 实例化的对象
for f in self._exported_methods:
print("类方法名 :"+f.__name__," 类方法地址:",f) #实际是AFeature/BFeature 方法名/方法地址地址
owner.__dict__[f.__name__] = f #在实例化对象c的字典之中加入将其他类方法
def plugout(self, owner):
for f in self._exported_methods:
del owner.__dict__[f.__name__]
#注意这里是扩展的Plugin类
class AFeature(PlugIn):
def __init__(self):
super(AFeature, self).__init__() #使用超类进行父类初始化
self._exported_methods.append(self.get_a_value) #初始化的时候讲本类的方法地址传入到父类的列表之中 (重点)
def get_a_value(self):
print("c可以被调用 a feature.")
#注意这里是扩展的Plugin类
class BFeature(PlugIn):
def __init__(self):
super(BFeature, self).__init__()
self._exported_methods.append(self.get_b_value)
def get_b_value(self):
print("c可以被调用 b feature.")
class Combine:
pass
c = Combine()
print("Plugin 中 owner 即是传入的 c 对象地址:",c)
AFeature().plugin(c) #作为插件 将A类中方法通过插件 加入到 c 对象中
BFeature().plugin(c) #同上
c.get_a_value()
c.get_b_value()
#######################执行结果###########################
# >python demo3.6.py
# Plugin 中 owner 即是传入的 c 对象地址: <__main__.Combine object at 0x000001D024DBDC18>
# 类方法名 :get_a_value 类方法地址: <bound method AFeature.get_a_value of <__main__.AFeature object at 0x000001D024DBDCC0>>
# 类方法名 :get_b_value 类方法地址: <bound method BFeature.get_b_value of <__main__.BFeature object at 0x000001D024DBDC88>>
# c可以被调用 a feature.
# c可以被调用 b feature.
1 | #!/usr/bin/python3 |
采用类属性访问方式进行设置描述符,实现华氏度与摄氏度之间的转换
1 | #!/usr/bin/python3 |
魔法方法的利用
1 | #1. 只需要重载 __lshift__ 和 __rshift__ 魔法方法即可 |
根据课堂上的例子,定制一个列表,同样要求记录列表中每个元素被访问的次数。这一次我们希望定制的列表功能更加全面一些,比如支持 append()、pop()、extend() 原生列表所拥有的方法。你应该如何修改呢?
要求1:实现获取、设置和删除一个元素的行为(删除一个元素的时候对应的计数器也会被删除)
要求2:增加 counter(index) 方法,返回 index 参数所指定的元素记录的访问次数
要求3:实现 append()、pop()、remove()、insert()、clear() 和 reverse() 方法(重写这些方法的时候注意考虑计数器的对应改变).1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49class CountList(list):
def __init__(self, *args):
super().__init__(args)
self.count = []
for i in args:
self.count.append(0)
def __len__(self):
return len(self.count)
def __getitem__(self, key):
self.count[key] += 1
return super().__getitem__(key)
def __setitem__(self, key, value):
self.count[key] += 1
super().__setitem__(key, value)
def __delitem__(self, key):
del self.count[key]
super().__delitem__(key)
def counter(self, key):
return self.count[key]
def append(self, value):
self.count.append(0)
super().append(value)
def pop(self, key=-1):
del self.count[key]
return super().pop(key)
def remove(self, value):
key = super().index(value)
del self.count[key]
super().remove(value)
def insert(self, key, value):
self.count.insert(key, 0)
super().insert(key, value)
def clear(self):
self.count.clear()
super().clear()
def reverse(self):
self.count.reverse()
super().reverse()
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/编程世界/Python/基础学习/Python3扩展知识之笔试操作总结(三).md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/3-20-339.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议