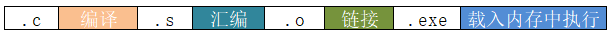本章学习内容参考了清华大学陈渝老师所讲的操作系统(Operating System).
课程概要 1)操作系统基本概念及原理
1.操作系统基本概念及原理 1) 什么是操作系统
1.1 什么是操作系统 没有清晰的定义,它的层次在硬件之上,应用程序之下,主要实现2个功能:
即操作系统是控制软件,管理与杀死应用程序,并且为应用程序提供服务,分配资源与管理外设;
Linux,windows(gui),android的界面都属于Shell(壳),而不是内核(kernel);Kernel是我们研究的重点,在Shell之下.
CPU(CPU调度,进程,线程管理)
内存(物理内存,虚拟内存)
文件 disk(磁盘块)较为底层,抽象为文件系统 (文件系统管理)
中断处理和外设设备驱动
抽象硬件:CPU -> 进程,内存 -> 地址空间,磁盘 -> 文件;
OS kernel 的特征:
并发 concurrent:交替运行,计算机系统中同时存在多个运行的程序,需要OS管理和调度;
并行parallel:同时运行,在一个时间点上有多个程序需要有多个cpu;
共享:分时,互斥共享,同时对一个资源只有一个程序可以访问,但可以通过隔离成两块,达到“同时”访问 ;
虚拟:操作系统面对的是硬件.将CPU虚拟化成进程,磁盘虚拟化成文件,内存->虚拟空间,每个应用程序/用户觉得有一个计算机专门为他服务;
异步:一个CPU的情况下,只能有一个程序在跑,程序的执行不是一贯到底,而是走走停停,但只要运行环境相同,OS保证程序运行的结果相同.
1.2 为什么学习操作系统 操作系统是一门综合类学科,涵括的知识比较多,您需要对程序设计语言,数据结构,算法,计算机体系结构,材料,操作系统改类和原理,源代码,技能,操作系统的设计与实现等.
只要做大型系统软件的开发,就绕不开,操作系统是计算机科学研究的基石之一.
Q:怎么学习操作系统?
并发,异步,使编程很容易出错;管理原始硬件,应对非法行为,时间依赖;
A:到底研究什么?
但是现在课本滞后:并发和调度算法,只是操作系统的一小部分,I/O磁盘调度,已经交给硬件去管理,进程调度,磁盘调度已经是关注度比较小的点了.
1.3 操作系统实例 实例如UNIX BSD,LINUX,WIN:
Unix家族 UNIX BSD(伯克利软件发行版) 写C的那俩 BSD由伯克利在UNIX基础上改编,尤其网络协议方面有独到之处,开源,产业界(惠普,苹果);
linux 家族一个学生linus在大学时期开发出来的,使用linux比如红帽子,deforo ,suse安卓终端是linux内核,移动端(嵌入式)占据最多;
dos-> windows家族,桌面用户龙头,用户友好
1.4 操作系统历史 1)早期只是监控器和加载作用,计算机使用纸带机上输入-计算-输出,串行过程 ;
2)CPU高速了,顺序执行,批处理,并发的特征;
操作系统发展的2个趋势:
一个是集成电路发展越来越快,一个cpu中集成多个cpu核,普遍是多核多处理;
二是网络得到飞速发展,分布式操作系统,很多操作放到数据中心完成,前端->后端,松(通过internet交互,及时有效)、紧耦合(数据中心,紧密的集成系统完成计算)
Q:操作系统之后会怎么样?
操作系统的转变:
AIX/HP-UX (主机型计算)
Windows/Linux/BSD (个人机服务器计算)
IOS/Android (移动网络计算)
Future OS (普通计算:移动计算,云计算,大数据处理,物联网设备计算服务)
1.5 操作系统的结构 早期简单,MS-DOS,没有模块化,汇编语言;UNIX面对的是服务器,有layer的概念,C语言,可移植 .
1)微内核的设计,尽量把内核缩小,文件和网络之类都放到外围,通过消息传递来耦合(松耦合)内外界,可扩展,但性能下降了.
2)学术界还有一种,内核分两块,一块处理硬件,完成复制称为exokernel即外核,另一块为内部OS,和具体应用打交道,因为应用和内部OS是紧耦合,速度会快.
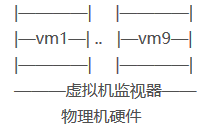
虚拟机 VMS 跑在传统OS之下,在一台物理机器下,每个虚拟机接口是一个原始计算机系统的由副本并完成所有的处理器指令,原因是CPU越来越强,硬件能力过剩;
虚拟机设备情况
2.操作系统启动介绍,中断及系统调用 1)操作系统的启动
2.1 操作系统的启动 机器启动的重要三部分: CPU —总线— I/O | 内存
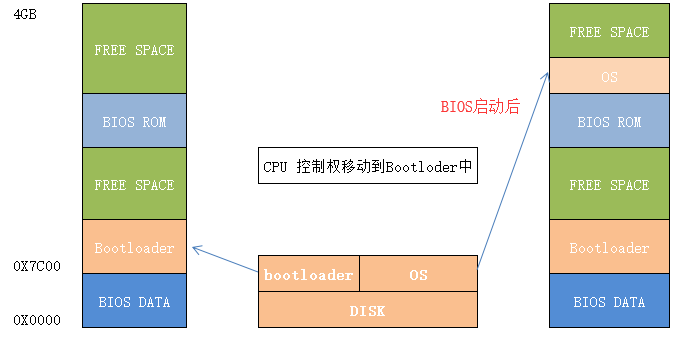
Disk而不是内存存放OS;硬盘上有个小程序Bootloader用于加载OS;
Step1.内存中有一部分是BIOS占满,第一步从特定地址开始执行
内存地址
Step2.BIOS会POST加电自检,寻找显卡(找屏幕),有键盘鼠标等外设,BIOS将其初始化;
Step3.这时Bootloader会将OS的代码和数据从磁盘加载到内存中,把控制权给操作系统(跳转到OS的起始地址).
操作系统的启动示意图如下:
操作系统的启动
2.2 中断、异常和系统调用 操作系统正常工作后,与设备和程序交互, interface包含三个面向外设通过中断和I/O,面向应用程序通过系统调用和异常.
Q:什么是系统外设中断,系统异常和系统调用?
系统调用:应用程序主动向OS发出服务请求system call,一种特殊指令;
异常:不良的应用程序,非法指令或者坏的处理状态;
中断:有外设来发送请求了,来自不同的硬件设备的计时器和网络的中断;
Q:为什么应用程序不能直接访问外设?
三者差异:
本章学习内容参考了清华大学陈渝老师所讲的操作系统(Operating System).
课程概要 1)操作系统基本概念及原理
1.操作系统基本概念及原理 1) 什么是操作系统
1.1 什么是操作系统 没有清晰的定义,它的层次在硬件之上,应用程序之下,主要实现2个功能:
即操作系统是控制软件,管理与杀死应用程序,并且为应用程序提供服务,分配资源与管理外设;
Linux,windows(gui),android的界面都属于Shell(壳),而不是内核(kernel);Kernel是我们研究的重点,在Shell之下.
CPU(CPU调度,进程,线程管理)
内存(物理内存,虚拟内存)
文件 disk(磁盘块)较为底层,抽象为文件系统 (文件系统管理)
中断处理和外设设备驱动
抽象硬件:CPU -> 进程,内存 -> 地址空间,磁盘 -> 文件;
OS kernel 的特征:
并发 concurrent:交替运行,计算机系统中同时存在多个运行的程序,需要OS管理和调度;
并行parallel:同时运行,在一个时间点上有多个程序需要有多个cpu;
共享:分时,互斥共享,同时对一个资源只有一个程序可以访问,但可以通过隔离成两块,达到“同时”访问 ;
虚拟:操作系统面对的是硬件.将CPU虚拟化成进程,磁盘虚拟化成文件,内存->虚拟空间,每个应用程序/用户觉得有一个计算机专门为他服务;
异步:一个CPU的情况下,只能有一个程序在跑,程序的执行不是一贯到底,而是走走停停,但只要运行环境相同,OS保证程序运行的结果相同.
1.2 为什么学习操作系统 操作系统是一门综合类学科,涵括的知识比较多,您需要对程序设计语言,数据结构,算法,计算机体系结构,材料,操作系统改类和原理,源代码,技能,操作系统的设计与实现等.
只要做大型系统软件的开发,就绕不开,操作系统是计算机科学研究的基石之一.
Q:怎么学习操作系统?
并发,异步,使编程很容易出错;管理原始硬件,应对非法行为,时间依赖;
A:到底研究什么?
但是现在课本滞后:并发和调度算法,只是操作系统的一小部分,I/O磁盘调度,已经交给硬件去管理,进程调度,磁盘调度已经是关注度比较小的点了.
1.3 操作系统实例 实例如UNIX BSD,LINUX,WIN:
Unix家族 UNIX BSD(伯克利软件发行版) 写C的那俩 BSD由伯克利在UNIX基础上改编,尤其网络协议方面有独到之处,开源,产业界(惠普,苹果);
linux 家族一个学生linus在大学时期开发出来的,使用linux比如红帽子,deforo ,suse安卓终端是linux内核,移动端(嵌入式)占据最多;
dos-> windows家族,桌面用户龙头,用户友好
1.4 操作系统历史 1)早期只是监控器和加载作用,计算机使用纸带机上输入-计算-输出,串行过程 ;
2)CPU高速了,顺序执行,批处理,并发的特征;
操作系统发展的2个趋势:
一个是集成电路发展越来越快,一个cpu中集成多个cpu核,普遍是多核多处理;
二是网络得到飞速发展,分布式操作系统,很多操作放到数据中心完成,前端->后端,松(通过internet交互,及时有效)、紧耦合(数据中心,紧密的集成系统完成计算)
Q:操作系统之后会怎么样?
操作系统的转变:
AIX/HP-UX (主机型计算)
Windows/Linux/BSD (个人机服务器计算)
IOS/Android (移动网络计算)
Future OS (普通计算:移动计算,云计算,大数据处理,物联网设备计算服务)
1.5 操作系统的结构 早期简单,MS-DOS,没有模块化,汇编语言;UNIX面对的是服务器,有layer的概念,C语言,可移植 .
1)微内核的设计,尽量把内核缩小,文件和网络之类都放到外围,通过消息传递来耦合(松耦合)内外界,可扩展,但性能下降了.
2)学术界还有一种,内核分两块,一块处理硬件,完成复制称为exokernel即外核,另一块为内部OS,和具体应用打交道,因为应用和内部OS是紧耦合,速度会快.
虚拟机 VMS 跑在传统OS之下,在一台物理机器下,每个虚拟机接口是一个原始计算机系统的由副本并完成所有的处理器指令,原因是CPU越来越强,硬件能力过剩;
虚拟机设备情况
2.操作系统启动介绍,中断及系统调用 1)操作系统的启动
2.1 操作系统的启动 机器启动的重要三部分: CPU —总线— I/O | 内存
Disk而不是内存存放OS;硬盘上有个小程序Bootloader用于加载OS;
Step1.内存中有一部分是BIOS占满,第一步从特定地址开始执行
内存地址
Step2.BIOS会POST加电自检,寻找显卡(找屏幕),有键盘鼠标等外设,BIOS将其初始化;
Step3.这时Bootloader会将OS的代码和数据从磁盘加载到内存中,把控制权给操作系统(跳转到OS的起始地址).
操作系统的启动示意图如下:
操作系统的启动
2.2 中断、异常和系统调用 操作系统正常工作后,与设备和程序交互, interface包含三个面向外设通过中断和I/O,面向应用程序通过系统调用和异常.
Q:什么是系统外设中断,系统异常和系统调用?
系统调用:应用程序主动向OS发出服务请求system call,一种特殊指令;
异常:不良的应用程序,非法指令或者坏的处理状态;
中断:有外设来发送请求了,来自不同的硬件设备的计时器和网络的中断;
Q:为什么应用程序不能直接访问外设?
三者差异:1 2 3 4 5 6 7 8 9 10 11 12 13 14 1)源头不一样 网卡声卡显卡等等外设产生事件—中断; APPLICATION意想不到的行为—异常; APPLICATION主动请求OS提供服务—系统调用 2)处理时间不一样 中断-异步(当一个事件发生时,APPLICATION并不知道它什么时候会发生 ); 异常-同步(当一个事件发生时,都是一个特殊指令触发了事件,但它不需要等待事件响应); 系统调用-同步或异步; 3)响应状态 中断:持续,APP对用户是透明的,感觉不到; 异常:杀死或重新执行APP的异常指令(有时由于是系统原因导致异常所以需要重新执行),也透明; 系统调用:等待和持续,不会重复;
Q:操作系统如何设计和实现中断、异常和系统调用?
中断–硬件:设置中断标记(CPU初始化),CPU看到具体的中断事件的ID中断号(程序访问的中断向量地址),根据中断表访问一些为该事件服务的功能,跳到对应地址.
软件:OS要保存当前程序处理状态,中断服务程序处理(根据具体的时间ID对应功能/地址),清除中断标记,恢复之前保存的处理状态(应用程序是不知道的,是透明的)
异常–异常编号,OS会保存现场,异常处理(杀死程序or OS修复程序需要的服务后重新执行异常指令),恢复现场;应用程序不知道在执行到特定指令后会产生异常,也是透明的.
系统调用–应用程序:比如调用printf时会触发系统调用write(),OS再去访问对应的外设,执行后OS返回一个成功或者失败;
系统调用之上有API供应用程序访问调用:
Q:OS是怎么设计和实现系统调用的?
APP直接或间接通过library code库访问系统调用的接口,CPU不同状态分为内核态与用户态,并触发内核态到用户态的转变,控制权从应用程序交到了OS,OS标识ID号后完成具体的服务.
内核态:OS运行中,CPU处的高权限的状态,OS可以执行任何CPU提供的任何指令或调用I/O.
用户态:APP执行中,CPU处的一个较低权限的状态.不能直接访问特殊的机器指令和I/O
系统调用与传统的函数调用区别:
中断、异常、系统调用知识点总结:
3.内存管理 1) 计算机体系结构&内存分层体系
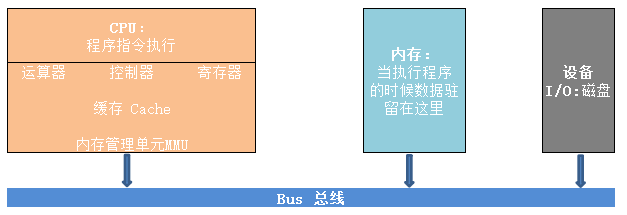
3.1 计算机体系结构与内存分层 计算机体系结构的基本硬件结构:
计算机体系结构
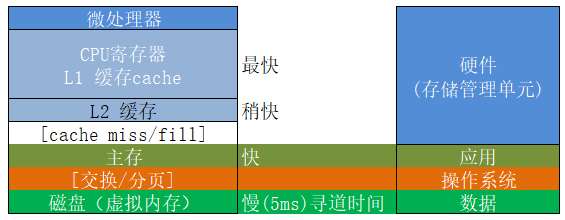
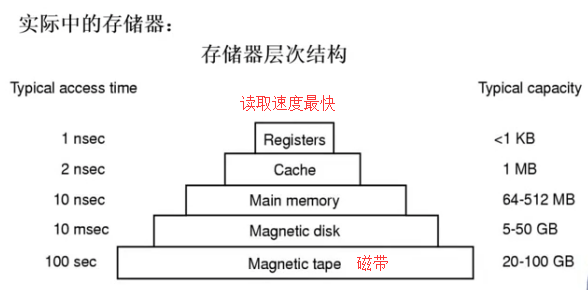
Memery内存的层次结构:
内存的层次结构
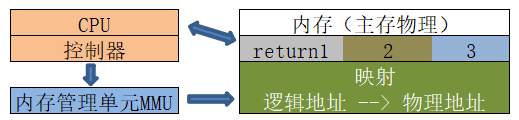
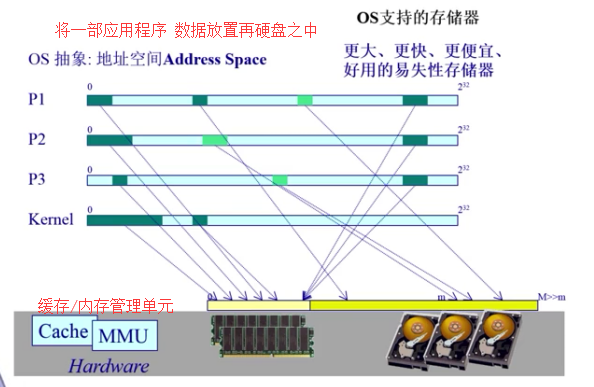
OS本身也是软件,实现高度依赖于硬件,要知道内存架构,MMU(内存管理单元,硬件组件中负责处理CPU的内存访问请求)
Q:操作系统对内存分配做了什么?
操作系统内存分配
Q:操作系统管理内存的不同机制?
3.2 地址空间和地址生成 地址空间的概念:
物理地址空间是硬件支持的地址空间 , E.G:内存条代表的主存,硬盘代表的磁盘 ;
逻辑地址空间是一个运行的程序所具有的内存范围,一维线性 ,E.G: 起始地址空间0,到地址max ;
二者之间的交互,映射关系,落在物理地址空间上.
Step1.LA逻辑地址的生成:
Step2.PA物理地址的生成:
CPU方面:运算器需要在逻辑地址中内存内容,MMU查表根据CPU中的有块区域表示映射关系,如果在MMU没查到会去内存中的MAP找,查表逻辑地址->映射->物理地址.
内存方法:CPU控制器给主存(就是内存)发请求,请求一个物理地址的内容(就是指令的内容),主存会通过总线把物理地址的内容传给CPU,CPU执行指令.
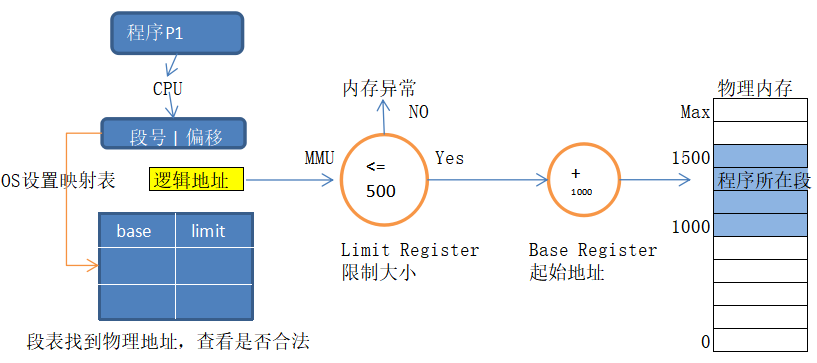
操作系统方面:建立逻辑地址和物理地址之间的映射, 以及地址安全检查 ( 逻辑地址要检查起始地址和长度 )
内存逻辑映射物理地址
OS设置逻辑地址的界限和基址,不对就抛出内存异常;
3.3 内存碎片与分区的动态分配 物理内存分配可以分为连续分配和非连续分配.
连续分配会造成内存碎片问题,空闲内存不能被利用,内存碎片可分为如下:
外部碎片,在分配单元外的未使用内存(- 程序之间);
内部碎片,在分配单元中的未使用内存(- 程序之内);
程序物理地址空间(0.执行栈,1.数据(Data),2.程序代码 “text”)
内存分配策略:首次(第一)适配、最优适配、最差适配;
(1) 首次(第一)适配:从0首地址往后查找和使用第一个可用空闲快(要比需要的空间大),基本实现机制要求把空闲的内存块按地址排序,回收要考虑能否合并内存块.
(2) 最优适配:找比需求大但最接近需求的空闲内存块,产生尽可能小的内存碎片.原理是为了避免分配大空闲块,最小化外部碎片,要求对空闲地址快按尺寸size排序,回收要合并.
(3) 最差匹配: 使用最大的空闲快,大块拆分变小块,可以避免产生太多微小的碎片,也要排序,回收合并.
3.4 压缩式/交换式碎片整理 (1)压缩式(compression)碎片整理
压缩式碎片整理
(2)交换式碎片整理
交换式碎片整理
4.非连续内存分配 (1)非连续内存分配:分段
Q:为什么需要非连续内存分配?
非连续的优点:更好的内存利用和管理;允许共享代码和数据(共享库);支持动态加载和动态链接.
非连续的缺点:分配给一个程序的物理内存是连续的;内存利用率低;有外碎片/内碎片的问题.
Q:采用什么管理方法?
程序的分段地址空间设计寻址方案:
分段地址空间设计寻址方案
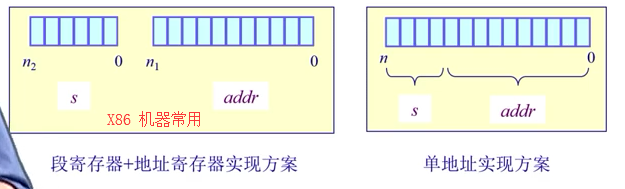
4.1 分段(segment) 段访问机制概念:一个段就是一个内存块,一个逻辑地址空间,内存块大小可变 ;内存地址表示 (segment number, offset)s 段号(segment number)+ addr基址(段内偏移的寻址) ,如下面的两种寻址方案:
寻址方案
硬件实现方案:
硬件实现方案
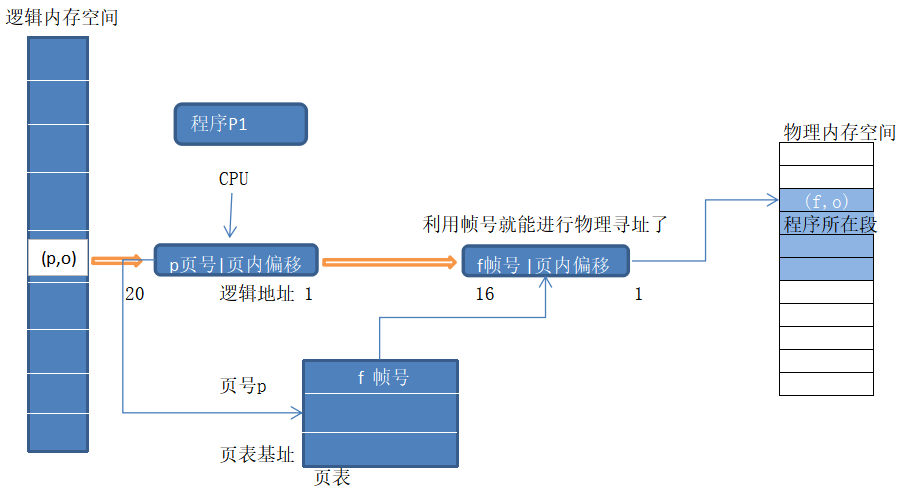
4.2 分段( page) 分页也是实现机制和寻址,也需要页号和偏移类似,区别在于内存块大小固定(帧) ;
物理地址:(frame number, offset)
逻辑地址:(page number, offset)
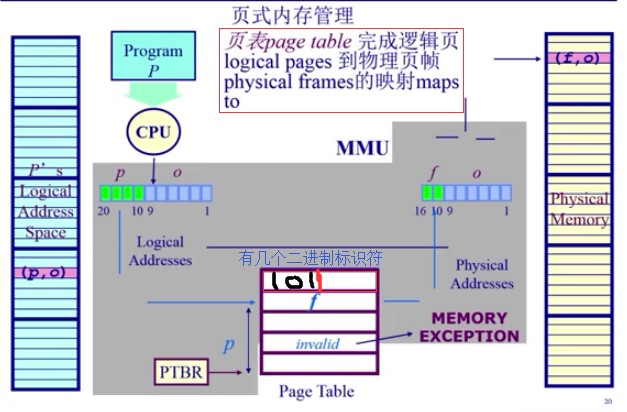
页表:page - frame
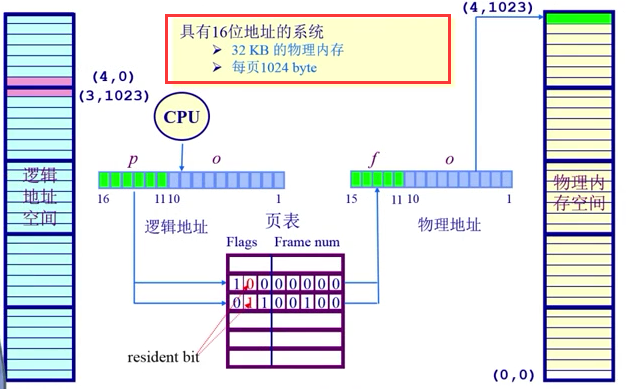
划分物理内存至固定大小的帧frame(物理页)与逻辑地址空间也要到相同大小的页(page,逻辑页),两者大小要相等是为2的幂数,如512,4096,8192;
建立方案转换逻辑地址为物理地址(change pages to frames),需要页表和MMU/TLB(快表,完成对MMU的缓存 )
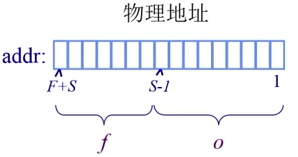
帧Frame的概念:
物理地址
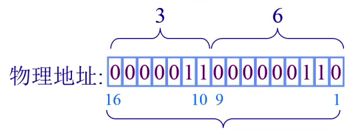
例如: 对16bit的地址空间,9bit大小的页帧,物理地址(3,6) ; 3 + 6 = 512 3 + 6 = 1542}$
帧Frame案例
物理地址比较:
物理地址比较
页Page的概念:
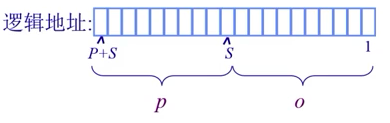
逻辑地址:${2^S * p + o}$ , ${2^n -1 = (2^P-1,2^S-1)}$
逻辑地址
页寻址机制:其中OS建立的页表(page table)保存了逻辑地址<—>物理地址之间的映射关系.
页寻址机制示例图
页内寻址的机制:
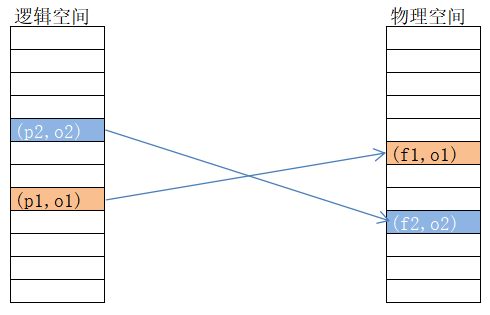
页Page映射到帧Frame
页是连续的虚拟内存
帧是不连续的物理内存
不是所有页都对应的帧
逻辑与物理空间
4.3 页表概述,TLB(快表) Q:如何解决页表过大的情况?
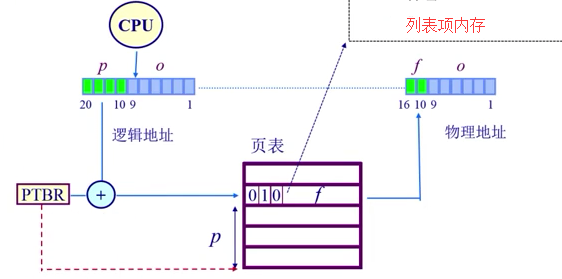
页表结构:每个运行的程序都有一个页表,属于程序运行状态,会动态变化;PTBR(页表基址寄存器).
大数组(索引是page number,内容frame number);
页表
地址转换实例:(011,0000 0100)
地址转换
分页机制的性能问题:
时间开销:页表太大不能放到CPU缓存中只能放内存,每次寻址一个内存单元需要2次内存访问(获取列表项与访问数据);
空间开销:
(1) 页表可能非常大,64位机器,寻址空间是2的64次幂,一个页size如果只有1024 K,要建立一个极大的页表=254,存不下.
(2) n个程序对应n个页表,页表个数非常大.
Q:如何处理分页机制的性能问题?
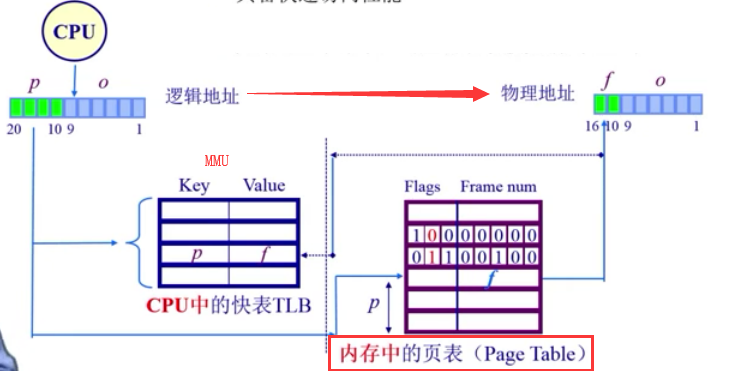
TLB( translation look-aside Buffer): 在cpu的MMU中,存在一个cache叫TLB,缓存近期访问的页帧转换表项;
首先CPU根据逻辑地址查快表TLB(key=p, value=f,由于使用关联内存(associate memory)实现,具备快速访问性能,很少超过64个表项,每个对应一个页面的相关信息)
如果命中,物理页号(FRAME)很快被获取.
如果未命中,则去查页表并更新对应的表项到TLB中
TLB
主要事项:
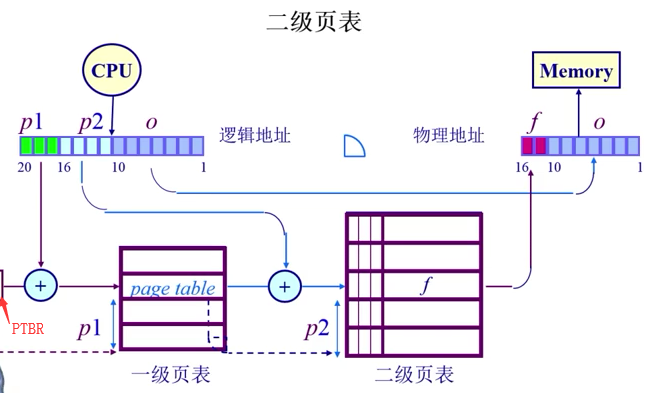
4.4 页表—二级,多级页表 Q:空间上怎么压缩页表?
将大的PAGE(也)的page number分为两部分P1&P2,OFFSET偏移不变;
二级页表
Q:多次访问,存俩表,开销大,怎么节省的呢?
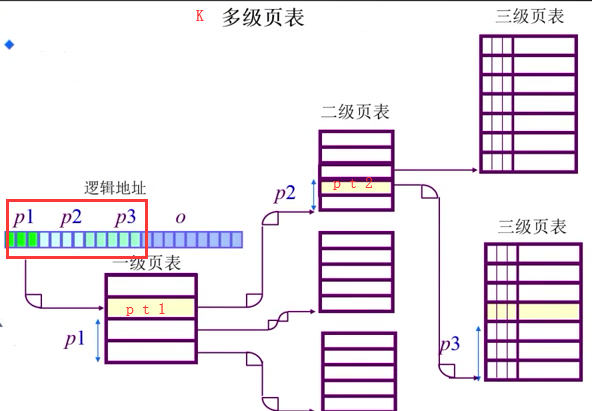
多级页表:
多级页表
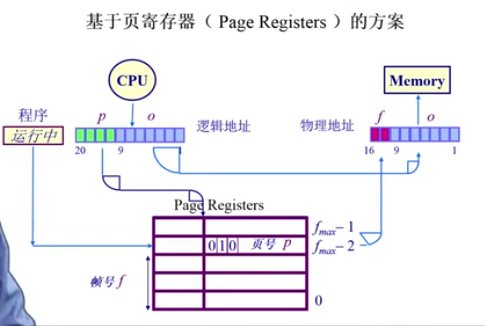
页表—反向页表 inverted page table 反向页表的实现:页寄存器、关联内存、hash table;
Q:大地址空间问题?
因此,前向页表与逻辑空间地址的大小相关 → 反向页表则是与物理地址空间的大小相对应.
pageRegister方案
使用页寄存器(Page Registers)每一帧和一个寄存器关系,寄存器内容包括:1 2 3 4 5 6 7 8 9 10 11 esidence bit:此帧是不是被占用. Occpuier:对应的页号P. Protection bits: 保护位. # 案例:寄存器例子 物理内存大小:4096 * 4096 byte= 4K*4K=16M, 页面大小:4096 byte = 4KB, 页帧数:4096 = 4K, 页寄存器使用的空间(If 8 bytes per page register)8 * 4K=32KB, 页寄存器带来的额外开销:32K/16M=0.2% 虚拟内存大小:任意
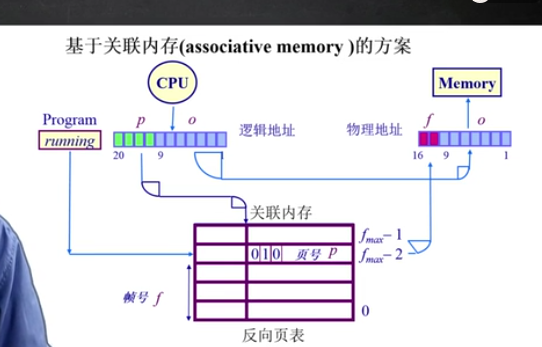
反向页表基于页寄存器,采用关联内存 associate memory方式.
Q:问题在于怎么用页号找帧号?
基于关联内存(associative memory)
但关联存储器缺点是用到的硬件逻辑很复杂,开销很大,本身空间较小,还需要放到CPU否则要二次访问,大的关联存储器也会造成时间开销大.
反向页表整体搜索机制:
如果帧数少,放到关联内存中,在关联内存中查找逻辑页号,成功则提取帧号,失败抛出page fault.
限制因素在于大量的关联内存很昂贵,难以在单个时钟周期内完成且耗电.
折中方案-哈希表:
优点:本身物理存址小省空间,不再是每个应用程序都要page table了,整个系统只用一个.
哈希表问题列表:
5.虚拟内存管理 (1)虚拟内存的起因
5.1 虚拟内存的起因 原因:理想中的存储器是更大,更快,更便宜的非易失存储器,而现实是内存越来越不够用;所以虚拟内存的出现就是缓解内存不足.
内存分构
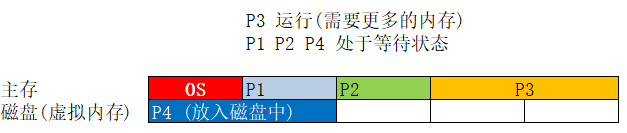
为了有效管理物理内存,采用了分段/分页,也许在这个基础上可以达到更大更快的理想情况,但数据随着掉电会丢失,硬件还达不到;所以仍然希望将不经常访问的数据放在硬盘中对硬件和OS要求很高.
内存逻辑与磁盘
对系统内存不够用采取的措施:
早期微软的DOS,内存仅640K,程序大需要 手动覆盖(overlay) ,把需要的指令和数据保存在内存中;
程序多采用 自动交换技术(swapping) ,暂时不能执行的程序送到外存因为代价大;
以更小的页粒度单位在有限的内存中装入更多更大的程序,采用 自动的虚拟存储技术 ;
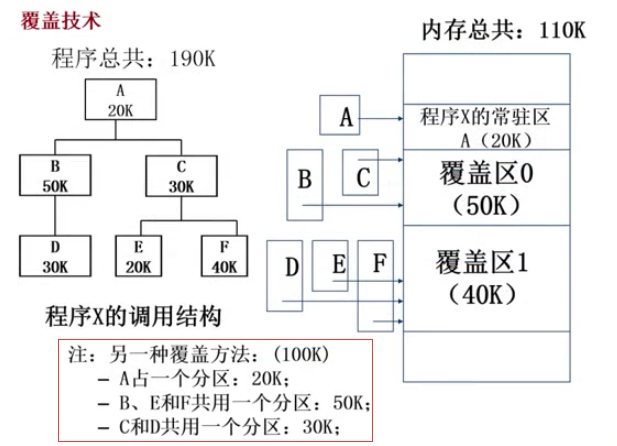
5.2 覆盖技术(overlay) Q:怎么更好地利用内存,其实几种技术都是为了这个目标?
目标:在比较小的内存中运行较大程序,常用于多道程序系统,与分区存储管理配合使用.
原理:按自身逻辑把程序分成几个功能上相对独立的模块,不会同时执行的模块可以共享同一块内存区域,按时间先后运行(分时.
例子:A,B,C,D,E这5个函数占用190K空间及调用关系,占用内存空间110K如下图,如B/C之间不会相互调用因此可以共用一个分区,同理DEF也能在同一个分区之中.
内存覆盖技术
覆盖技术的缺点:
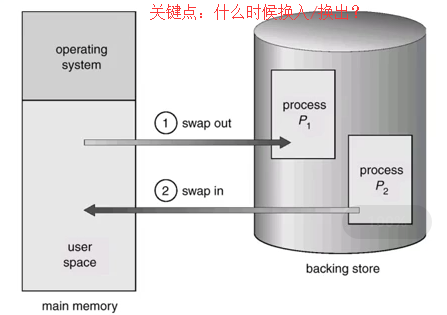
5.3 交换技术(swapping) 背景:UNIX,让OS管理而不是程序员管理,以运行的程序为单位;内存可能不足时进行内存和硬盘间数据交换.
方法:
交换示例图:看是交换比较简单其实内部做的工作比较多.
交换示例图
交换技术的几个问题 :
Q:交换区的大小?
Q:程序换入(swap in)时候重定位:再次换入的内存地址一定要在原来位置上吗?
重点:覆盖、交换的比较:
5.4 虚拟内存技术 Q:为什么要出现虚拟内存管理技术?
目标:
实现虚存技术–程序的局部性原理(principle of locality):
时间局部性:一条指令的一次执行和下次执行,一个数据的一次访问和下次访问都在较短时间内.
空间局部性:当前指令和邻近的几条指令,当前访问的数据和邻近的几个数据都集中在一个较小区域内.
总结:就是小空间,高效;原理表明理论上虚存可以实现,程序只有一小部分在内存上,大部分在硬盘上,os在MMU帮助下完成.
案例:编程对缺页率的影响1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //编程方法1 for (j=0 ;j<1024 ;j++){ for (i=0 ;i<1024 ;i++){ a[i][j]=0 ; //甲 从i开始增加 } } //编程方法2 for (i=0 ;i<1024 ;i++){ for (j=0 ;j<1024 ;j++){ b[i][j]=0 ; //乙 从j开始增加 } } //a0,0 a0,1 ..... a0,1023 1 //a1,0 a1,1 ..... a1,1023 2 //...................... //a1023,0 a1023,1 ..... a1023,1023 1024
基本概念:在分页/分段内存管理的硬件支持基础上实现。
(2) 当执行到指令或数据不在内存上时(缺页、缺段异常),由处理器通知操作系统(若有空余空间的前提下)将相应的页面或段调入内存,继续执行;
(3) OS将内存中暂时不用的页/段调出保存在外存上以腾出空间给将要调入的页面或者段。
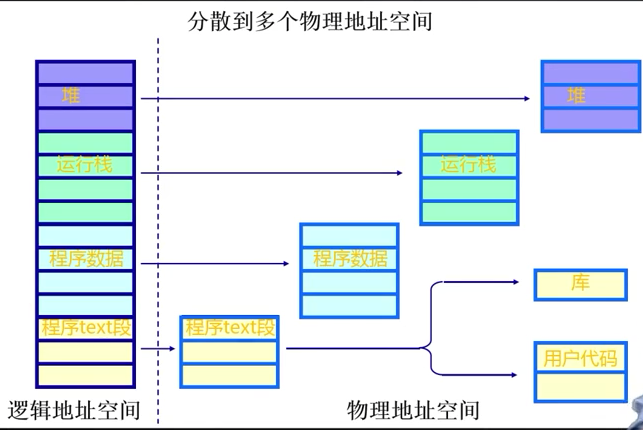
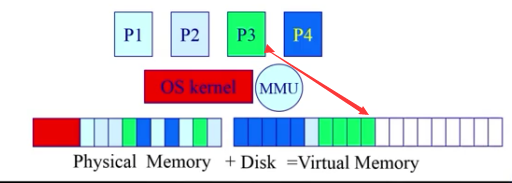
虚拟技术-虚拟页式的内存管理:
大的用户空间:内存可以小,硬盘必须足够。提供给用户的虚拟空间=物理内存+硬盘。
部分交换:swap in /swap out 是对部分虚拟地址空间进行的
不连续性:物理内存分配的不连续,虚拟空间使用的不连续(内外存)
具体实现:多采用虚拟页式内存管理,增加了请求调页和页面置换功能
虚拟页式的内存管理图
寻存储系统都基本采用虚拟页式存储管理技术,在此基础上增加请求调页和页面置换功能。
基本思路:
只装入部分页面即可启动程序,不需要将该程序所有页面都装入内存中
运行的程序和数据不在内存(即页表某表项项无效|invalid),向OS系统发出缺页中断请求,OS根据产生异常的地址找到对应在外存中的页面并调入内存中使得继续运行。
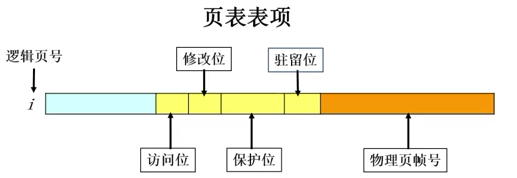
数据结构,通过页表实现:
驻留位(resident bit, 1表示在内存中,0表示在硬盘中[如果现在访问该项则导致缺页中断])
保护位(设置权限,包括只读、读写、可执行等)
修改位(dirty bit, 数据是否被修改过,换出时是否需要写回硬盘外存)
访问位(access/used bit, 是否被访问(1表示访问过),长时间未访问的数据在内存不足时优先被换出,用于页面置换算法)
锁定位(lock bit, 标记需要常驻内存的数据,如OS进程和对时间敏感的进程)
列表表项图
补充:页面置换算法,在页表中查找所需数据的物理地址,如存在则直接读取;如不存在先判断是否有空余内存,如无先换出内存上的数据(未被修改直接free,被修改过则写回硬盘),再从硬盘读取数据.
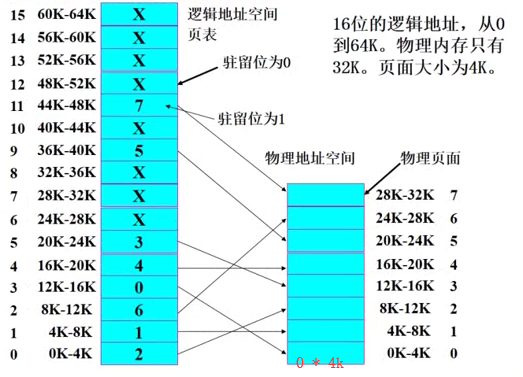
例子:虚拟页式内存管理
MOV REG 0 8192
案例图
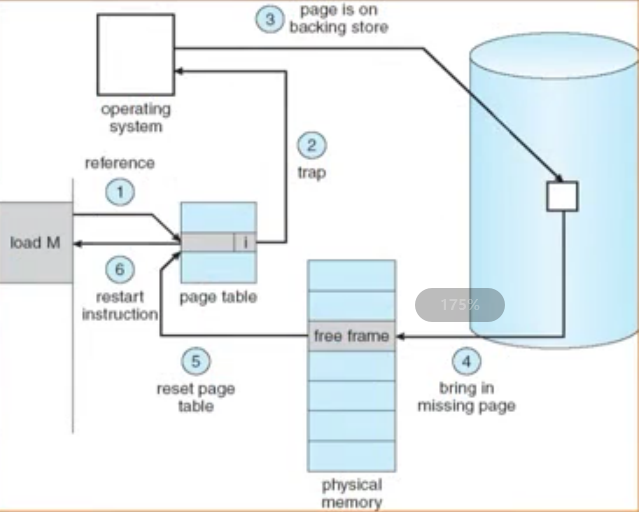
缺页中断处理过程图:
缺页中断
对缺页中断的处理:
后备存储(Backing Store)
硬盘也有多种方式存储:数据/代码/动态库—>后备存储中的前三个,动态产生的数据,是没与文件直接对应的内存内容→硬盘上专门开一个区(来交换文件 swap file)
后备存储概念:
一个虚拟地址空间的页面可以被映射到一个文件(在二级存储中某个位置)
代码段:映射到可执行二进制文件;
动态加载的共享库程序段:映射到动态调用的库文件
其他段:可能被映射到交换文件(swap file)
有效存储访问时间(effective memory access time, EAT):
由于为了便于理解分页开销,使用有效存储器访问时间的概念
EAT = 访存时间 页表命中机率(即1-page fault) + page fault处理时间 page fault 机率
案例:1 2 3 4 #访问时间:10ns #磁盘访问时间:5ms #参数p: page fault 机率 #参数q: dirty page 机率
(1 - p) + 5000000 p(1 + q)}$
总结:
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】【WeiyiGeek】
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】 , 个人首页地址( https://weiyigeek.top )
专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】 ,这将对我的肯定,我将持续整理发布更多优质原创文章!。