[TOC]
目录结构
(1) urllib 简单的爬取指定网站
(2) Scrapy 爬虫框架
(3) BeautifulSoup 爬虫解析
0x00 urllib简单爬取
1.初始爬虫
案例1:采用Python自带的url+lib形成的urllib包

[TOC]
(1) urllib 简单的爬取指定网站
(2) Scrapy 爬虫框架
(3) BeautifulSoup 爬虫解析
1.初始爬虫
案例1:采用Python自带的url+lib形成的urllib包
[TOC]
(1) urllib 简单的爬取指定网站
(2) Scrapy 爬虫框架
(3) BeautifulSoup 爬虫解析
1.初始爬虫
案例1:采用Python自带的url+lib形成的urllib包1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#!/usr/bin/python
#功能:爬虫的第一课
import urllib.request #导入urllib包里面的指定模块
import urllib.parse #解析使用
#案例1:
response = urllib.request.urlopen("http://www.weiyigeek.github.io"+urllib.parse.quote("网络安全")) #Url中文解析
html = response.read() #进行返回一个二进制取字符串
html = html.decode('utf-8') #解码操作
print("正在写入文件之中.....")
f = open('weiyigeek.txt','w+',encoding='utf-8') #打开
f.writelines(html)
f.close() #关闭
print("网站请求的结果:\n",html)
#案例2:
url = "http://placekitten.com/g/600/600"
response = urllib.request.urlopen(url) #可以是url字符串或者Request()对象,返回一个对象
img = response.read()
filename = url[-3:]+'.jpg'
with open(filename,'wb+') as f: #注意这里存储二进制
f.write(img)
2.Py爬虫实现/优化
案例1:Spider调用有道翻译接口进行中英文翻译1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65#!/usr/bin/python
#功能:爬虫的第2课 JSON / 代理
import urllib.request
import urllib.parse
import json
import time
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
while True:
i = input("请输入翻译的英文(输入Q退出):")
if i == 'Q' or i == 'q':
break
data = {}
data['i'] = i
data['from'] = 'AUTO'
data['to'] = 'AUTO'
data['doctype'] = 'json'
data['smartresult'] = 'dict'
data['client'] = 'fanyideskweb'
data['version'] = '2.1'
data['keyfrom'] = 'fanyi.web'
data['salt'] = '15550362545153'
data['sign'] = 'a28b8eb61693e30842ebbb4e0b36d406'
data['action'] = 'FY_BY_CLICKBUTTION'
data['typoResult'] = 'false'
data = urllib.parse.urlencode(data).encode('utf-8')
#修改Header
#url 对象 request 以及 添加 请求头信息
req = urllib.request.Request(url, data) #也能直接传入 header 对象字典
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')
req.add_header('Cookie',' YOUDAO_MOBILE_ACCESS_TYPE=1; OUTFOX_SEARCH_USER_ID=597755369@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb')
req.add_header('Referer','http://fanyi.youdao.com/')
#url 请求返回的对象
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
jtarget = json.loads(html) #json解析
print("翻译后的结果 :",jtarget['translateResult'][0][0]['tgt'])
time.sleep(1) #延迟1s 防止请求频繁
print("请求头信息:",req.headers)
print("请求URL:",res.geturl())
print("状态码:",res.getcode())
print("返回头消息:\n",res.info())
# 请输入翻译的英文(输入Q退出):whoami
# 翻译后的结果 : 显示本用户信息
# 请求头信息: {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0', 'Cookie': ' YOUDAO_MOBILE_ACCESS_TYPE=1; OUTFOX_SEARCH_USER_ID=597755369@10.169.0.84; OUTFOX_SEARCH_USER_ID_NCOO=1911553850.7151666; YOUDAO_FANYI_SELECTOR=ON; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8N5HySla85aD-6kpOw; ___rl__test__cookies=1555036254514; UM_distinctid=16a0f2c1b0b146-0612adf0fe3fd6-4c312c7c-1fa400-16a0f2c1b0c659; SESSION_FROM_COOKIE=fanyiweb', 'Referer': 'http://fanyi.youdao.com/'}
# 请求URL: http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule
# 状态码: 200
# 返回头消息:
# Server: Tengine
# Date: Fri, 12 Apr 2019 03:23:02 GMT
# Content-Type: application/json;charset=utf-8
# Transfer-Encoding: chunked
# Connection: close
# Vary: Accept-Encoding
# Vary: Accept-Encoding
# Content-Language: en-US
3.爬虫参数设置
案例3:使用代理进行请求网站1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41#!/usr/bin/python3
#爬虫第三课:代理 一般urllib使用代理ip的步骤如下
# 设置代理地址
# 创建Proxyhandler
# 创建Opener
# 安装Opener
import urllib.request
import random
url1 = 'http://myip.kkcha.com/'
url2 = 'http://freeapi.ipip.net/'
proxylist = ['116.209.52.49:9999','218.60.8.83:3129']
ualist = ['Mozilla/5.0 (compatible; MSIE 12.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',\
'Mozilla/5.0 (Windows NT 6.7; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.7; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'\
]
proxyip = random.choice(proxylist)
# 代理设置 参数是一个字典 {'类型':'代理IP:端口'}
proxy = urllib.request.ProxyHandler({'http':proxyip})
#创建一个定制一个opener
pro_opener = urllib.request.build_opener(proxy)
pro_opener.addheaders = [('User-Agent',random.choice(ualist))] #随机请求头
#安装opener
urllib.request.install_opener(pro_opener)
##调用opener.open(url)
##利用代理进行请求
url2 = url2+proxyip.split(":")[0]
with urllib.request.urlopen(url1) as u:
print(u.headers)
res = u.read().decode('utf-8')
print(res)
with urllib.request.urlopen(url2) as u:
res = u.read().decode('utf-8')
print(res)
3.爬虫urllib 库的异常处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#!/usr/bin/python3
#功能:urllib 异常处理
from urllib.request import Request,urlopen
from urllib.error import HTTPError,URLError
urlerror = 'http://www.weiyigeek.com'
urlcode = 'http://www.weiyigeek.github.io/demo.html'
def url_open(url):
req = Request(url)
req.add_header('APIKEY','This is a password!')
try:
res = urlopen(req)
except (HTTPError,URLError) as e:
if hasattr(e,'code'): #需要放在reason属性前面
print('HTTP请求错误代码:', e.code)
print(e.read().decode('utf-8')) #[注意]这里是e.read
elif hasattr(e,'reason'):
print('服务器链接失败',e.reason)
else:
print("Suceeccful!")
if __name__ == '__main__':
url_open(urlerror)
url_open(urlcode)
################## 执行结果 #####################
# 服务器链接失败 [Errno 11001] getaddrinfo failed
# HTTP请求错误代码: 404
# <html>
# <head><title>404 Not Found</title></head>
# <body>
# <center><h1>404 Not Found</h1></center>
# <hr><center>nginx/1.15.9</center>
# </body>
# </html>
weiyigeek.top-正则与爬虫利用
4.爬虫之正则匹配
案例4:正则与爬虫利用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47#!/usr/bin/python3
#功能:正则与爬虫
from urllib.request import Request,urlopen,urlretrieve
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req = Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')
try:
res = urlopen(req)
html = res.read()
except HTTPError as e:
print("服务器请求错误:",e.code())
return 0
except URLError as e:
print("链接服务器Fail:",e.reason())
return 0
else:
return html
def save_img(url,dir):
i = 0
os.mkdir(dir)
os.chdir(os.curdir+'/'+dir)
for each in url:
#以后将要废弃不建议使用但是真心方便
urlretrieve(each,str(i)+'.jpg',None)
i += 1
else:
print("下载完成!\a\a")
def get_img(url):
res = url_open(url).decode('utf-8')
if res == 0:
exit("请求错误退出")
p = r'<img src="([^"]+\.jpg)"'
imglist= re.findall(p,res)
save_img(imglist,'test')
print(imglist)
if __name__ == '__main__':
url = 'http://tieba.baidu.com/f?kw=%E9%87%8D%E5%BA%86%E7%AC%AC%E4%BA%8C%E5%B8%88%E8%8C%83%E5%AD%A6%E9%99%A2&ie=utf-8&tab=album'
get_img(url)
5.爬虫正则进阶
案例5:爬虫抓取代理网站的ip:port1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45#!/usr/bin/python3
#urllib爬虫最后一课
import urllib.request
from urllib.error import HTTPError,URLError
import re
import os
def url_open(url):
req = urllib.request.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0')
try:
res = urllib.request.urlopen(req)
except (HTTPError,URLError) as e:
print("出现错误:",e.code,'错误的网页:',e.read())
return 0
else:
return res.read().decode('utf-8')
def main1(url,filename):
html = url_open(url)
if html == 0:
exit("请求错误,程序退出!")
exp = r'<td>((?:(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){0,3}(?:[01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5]))</td>\n(?:\s*?)<td>(?P<port>\d{0,4})</td>' #这里是坑呀
regres = re.findall(exp,html,re.M)
iplist = []
for each in regres:
ipport = each[0] + ':' + each[1]
iplist.append(ipport)
with open(filename,'w+',encoding='utf-8') as f:
for i in range(len(iplist)):
f.write(iplist[i]+'\n')
if __name__ == '__main__':
url = 'https://www.xicidaili.com/nn/'
main1(url,'proxyip.txt')
######### 抓取代理结果 ################
# 119.102.186.99:9999
# 111.177.175.234:9999
# 222.182.121.10:8118
# 110.52.235.219:9999
# 112.85.131.64:9999
1.1 Anaconda安装流程
这种方法是一种比较简单的安装Scrapy的方法(尤其是对Windows来说),你可以使用该方法安装,也可以选用下文中专用平台的安装方法。
Anaconda是包含了常用的数据科学库的Python发行版本,如果没有安装,可以到https://www.continuum.io/downloads下载对应平台的包安装。
如果已经安装,那么可以轻松地通过conda命令安装Scrapy。
安装命令如下:
conda install Scrapy
1.2 Windows安装流程
WINDOS下最好的安装方式是通过wheel文件来安装;我这里是WIN10的环境所有还是采用pip3安装1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#当前环境:win10+py3.7
pip3 install wheel
pip3 install lxml #注意找到对应的版本 - 安装lxml
pip3 install zope.interface #安装zope.interface
pip3 install Twisted
pip3 install pywin32
pip3 install Scrapy #最后安装Scrapy即可
#安装pyOpenSSL
#官方网站下载wheel文件,https://pypi.python.org/pypi/pyOpenSSL#downloads
pip3 install pyOpenSSL-16.2.0-py2.py3-none-any.whl
#Py3.7一键升级所有库
from subprocess import call
from pip._internal.utils.misc import get_installed_distributions
for dist in get_installed_distributions():
call("pip install --upgrade " + dist.project_name, shell=True)
1.3 CentOS、RedHat、Fedora
确保一些必须的类库已经安装,运行如下命令:
sudo yum groupinstall development tools
sudo yum install python34-devel epel-release libxslt-devel libxml2-devel openssl-devel
pip3 install Scrapy
1.4Ubuntu、Debian、Deepin
依赖库安装首先确保一些必须的类库已经安装,运行如下命令:
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
pip3 install Scrapy
1.5Mac OS
依赖库安装在Mac上构建Scrapy的依赖库需要C编译器以及开发头文件,它一般由Xcode提供,运行如下命令安装即可:
xcode-select –install
pip3 install Scrapy
验证安装之后,在命令行下输入,如果出现类似下方的结果,就证明Scrapy安装成功。 weiyigeek.top-scrapy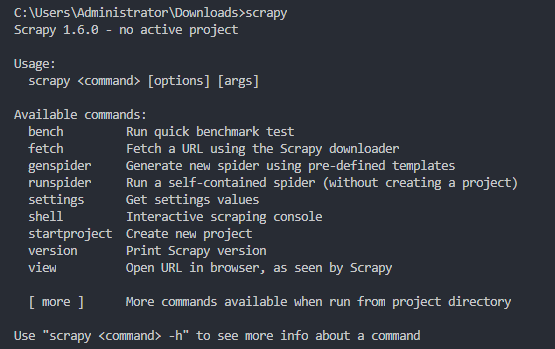
Scrapy是基于Python的爬虫框架,它为了爬取网站数据,提取结构性数据而编写的应用框架,可以应用在数据挖掘,信息处理或存储历史数据等需求之中;
使用Scrapy抓取一个网站分四个步骤:
框架示例图: weiyigeek.top-Scrapy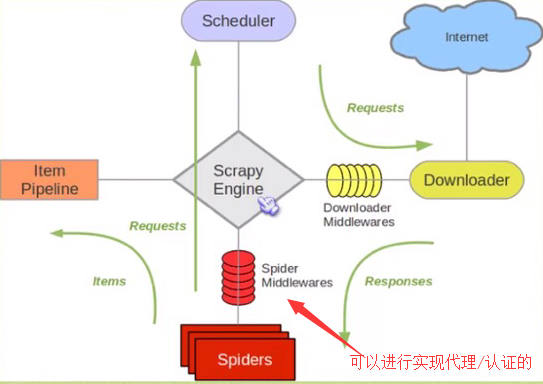
2.1 scrapy 常用命令1
2
3
4
5
6
7
8
9scrapy startproject douban #并初始化一个项目douban
scrapy genspider douban_spider movie.douban.com #建立通用爬虫文件后面是爬取的地址
scrapy crawl douban_spider #开启scrapy项目进行爬取,douban_spider 项目入口名称
scrapy shell <url> #交互测试爬虫项目中执行 测试提取数据的代码
scrapy shell "http://scrapy.org" --nolog #打印日志 注意是双引号
scrapy crawl douban_spider -o movielist.json #将爬取数据存储到特定格式
scrapy crawl douban_spider -o movielist.cvs
2.2 scrapy 项目解析1
2
3
4
5
6
7
8
9
10weiyigeek
│ items.py # 数据模型文件,容器创建对象(序号,名称,描述,评价)
│ middlewares.py # 中间件设置 (爬虫ip地址伪装)
│ pipelines.py # 将数据通过管道写入数据/磁盘中
│ settings.py # 项目设置(USER-AGENT,抓取时间)
│ __init__.py
├─spiders
│ │ douban_spider.py #爬虫项目入口
│ │ __init__.py
scrapy.cfg #配置文件信息
2.3 scrapy 选择器介绍
在Scrapy中是使用一种基于XPath和CSS的表达式机制的选择器(selectors),它有四个基本方法:
1 | #xml的解析方法xpath语法: |
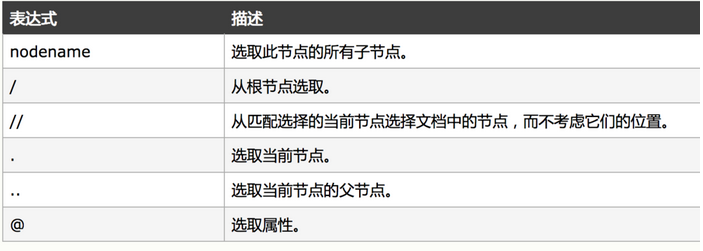
weiyigeek.top-xpath语法属性
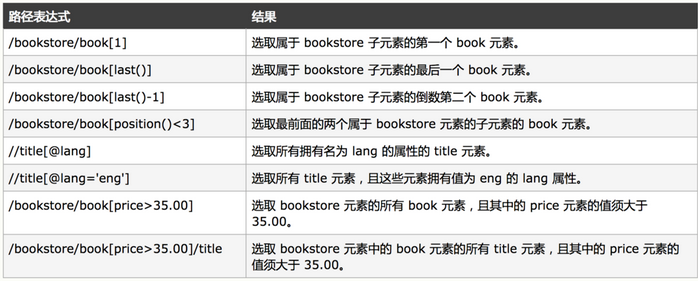
weiyigeek.top-示例
1 | response.css('.类名 标签::方法').extract() #截取字符串 |
extract():序列化该节点为unicode字符串并返回list
re():根据传入的正则表达式对数据进行提取,返回unicode字符串list列表
2.4 scrapy 交互调试
描述: Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码;
案例: weiyigeek.top-scrapyshell1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52> scrapy shell "http://movie.douban.com/chart"
>>> help(命令)
>>> request
<GET http://www.weiyigeek.github.io>
> response.url
'https://movie.douban.com/chart'
>>> response
<200 https://movie.douban.com/chart>
>>> response.headers #请求头
>>> response.body #网页源代码
>>> response.text
>>> response.xpath('//title') #返回一个xpath选择器
>>> response.xpath('//title').extract() #xpath表达式抽取内容
['<title>\n豆瓣电影排行榜\n</title>']
response.xpath('//title/text()').extract() #抽取文本信息
['\n豆瓣电影排行榜\n']
>>> response.xpath("//div[@class='pl2']//a").extract_first().strip() # extract_first 提取第一次匹配的数据
'<a href="https://movie.douban.com/subject/25986662/" class="">\n疯狂的外星人\n / <span style="font-size:13px;">Crazy Alien</span>\n </a>'
#CSS进行提取
>>> sel.css('.pl2 a::text').extract_first().strip()
'疯狂的外星人\n /'
#有网站提取需要上request的header信息如何解决:
from scrapy import Request #导入模块
>>> data = Request("https://www.taobao.com",headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
})
>>> fetch(data) #取得请求网站
2017-11-30 22:24:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.taobao.com> (referer: None)
>>> sel.xpath('/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]')
[<Selector xpath='/html/body/div[4]/div[1]/div[1]/div[1]/div/ul/li[1]/a[1]' data='<a href="https://www.taobao.com/markets/'>]
>>> data.headers #查看设置的header
{b'User-Agent': [b'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'], b'Accept-Encoding': [b'gzip,deflate']}
#匹配多个字符串进行迭代循环
>>> fetch('http://weiyigeek.github.io')
>>> title = response.css('.article-header a::text').extract()
>>> for each in title:
... print(each)
...
安全设备策略绕过技术总结.md
Win平台安全配置.md
Python3 正则表达式特殊符号及用法.md
Python3爬虫学习.md
磁盘高可用解决方案(DBA).md
Nodejs入门学习1.md
Node.js简介与安装.md
域控安全基础.md
Win内网渗透信息搜寻.md
高可用服务解决方案(DBA).md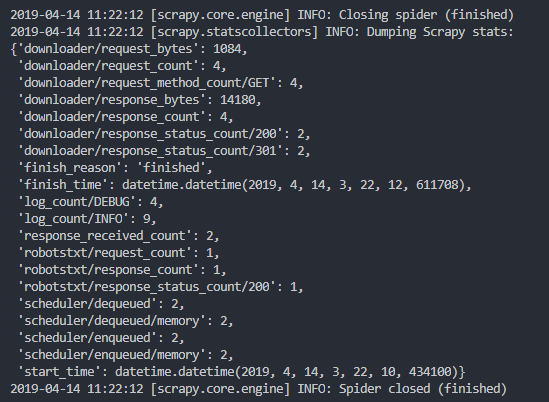
weiyigeek.top-执行结果
2.4 scrapy 简单实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41scrapy startproject weiyigeek
scrapy genspider blog_spider www.weiyigeek.github.io
'''
items.py 抓取的对象编辑数据模型文件
'''
import scrapy
class WeiyigeekItem(scrapy.Item):
#items.py 设置需要抓取的对象编辑数据模型文件 ,创建对象(序号,名称,描述,评价)
title = scrapy.Field() #标题
href = scrapy.Field() #标题地址
time = scrapy.Field() #创建时间
'''
blog_spider.py 爬虫处理主文件
'''
# -*- coding: utf-8 -*-
import scrapy
from weiyigeek.items import WeiyigeekItem #导入数据容器中的类中的属性(其实就导入该项目中items.py)
class BlogSpiderSpider(scrapy.Spider):
name = 'blog_spider' #爬虫名称
allowed_domains = ['www.weiyigeek.github.io'] #爬虫允许抓取的域名
start_urls = ['http://www.weiyigeek.github.io/','http://weiyigeek.github.io/page/2/'] #爬虫抓取数据地址,给调度器
#解析请求返回的网页对象
def parse(self, response):
sel = scrapy.selector.Selector(response) #scrapy选择器
sites = sel.css('.article-header') #利用css选择器进行赛选
items = []
for each in sites:
item = WeiyigeekItem() #数据容器类
item['title'] = each.xpath('a/text()').extract()
item['href'] = each.xpath('a/@href').extract()
item['time'] = each.xpath('div[@class="article-meta"]/time/text()').extract() #注意这里使用的
items.append(item)
#输出到屏幕之中
print(">>>",item['title'],item['href'],item['time'])
return items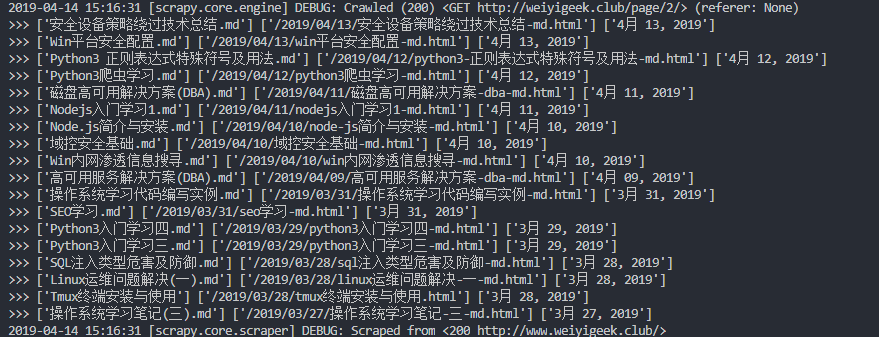
描述:爬取爱奇艺的TOPS250项目;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
#Step1.创建spider项目和初始化爬虫名称
scrapy startproject douban
scrapy genspider douban_spider movie.douban.com
'''
Step2.修改items模板文件
'''
class DoubanItem(scrapy.Item):
serial_number = scrapy.Field() #序号
movie_name = scrapy.Field() #电影名称
introduce = scrapy.Field() # 介绍
star = scrapy.Field() # 星级
evaluate = scrapy.Field() # 评价
describle = scrapy.Field() # 描述
'''
Step3.修改爬虫文件
'''
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem #导入容器 douban\items.py
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider' # 爬虫的名称
allowed_domains = ['movie.douban.com'] # 爬虫允许抓取的域名
start_urls = ['https://movie.douban.com/top250'] # 爬虫抓取数据地址,给调度器
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
douban_item = DoubanItem() #模型初始化
#以text()结束表示获取其信息, extract_first() 筛选结果的第一个值
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first() #排名
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first() #名称
descs = i_item.xpath(".//div[@class='info']//div[@class='bd']/p[1]/text()").extract_first() #
#处理空格问题
desc_str = ''
for i_desc in descs:
i_desc_str = "".join(i_desc.split())
desc_str += i_desc_str
douban_item['introduce'] = desc_str #介绍
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first() #星星
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() #评价数量
douban_item['describle'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first() #描述
yield douban_item #是将返回结果压入 item Pipline 进行处理(重点)
#处理下一页功能
next_link = response.xpath("//div[@class='article']//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse) #(重点)
# 解释:
# 1 每次for循环结束后,需要获取next页面链接:next_link
# 2 如果到最后一页时没有下一页,需要判断一下
# 3 下一页地址拼接: 点击第二页时页面地址是https://movie.douban.com/top250?start=25&filter=
# 4 callback=self.parse : 请求回调
'''
Step4.修改配置文件
'''
$ grep -E -v "^#" settings.py
BOT_NAME = 'douban' #项目名称
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
USER_AGENT = ' Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
#通道设置
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
#下载中间件设置调用
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.my_proxy': 543,
'douban.middlewares.my_useragent': 544,
}
#设置mongo_db数据库信息
mongo_host = '172.16.0.0'
mongo_port = 27017
mongo_db_name = 'douban'
mongo_db_collection = 'douban_movie'
'''
Step5. 修改pipelines.py
'''
# -*- coding: utf-8 -*-
import pymongo
from douban.settings import mongo_host ,mongo_port,mongo_db_name,mongo_db_collection
class DoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
'''
Step6. 中间价文件:middlewares.py
'''
# ip代理中间价编写(爬虫ip地址伪装) / 头信息User-Agent伪装随机
import base64
import random
#文件结尾添加方法:
class my_proxy(object): # 代理
def process_request(self,request,spider):
request.meta['proxy'] = 'http-cla.abuyun.com:9030'
proxy_name_pass = b'H622272STYB666BW:F78990HJSS7'
enconde_pass_name = base64.b64encode(proxy_name_pass)
request.headers['Proxy-Authorization'] = 'Basic ' + enconde_pass_name.decode()
# 解释:根据阿布云注册购买http隧道列表信息
# request.meta['proxy'] : '服务器地址:端口号'
# proxy_name_pass: b'证书号:密钥' ,b开头是字符串base64处理
# base64.b64encode() : 变量做base64处理
# 'Basic ' : basic后一定要有空格
class my_useragent(object): # userAgent
def process_request(self, request, spider):
UserAgentList = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
]
agent = random.choice(UserAgentList)
request.headers['User_Agent'] = agent
## 运行 scrapy crawl 将会看到 上面设置的中间键方法
也可以将数据保存到 json文件 或者 csv文件
Q:安装twisted出现依赖问题? weiyigeek.top-问题1
解决方法:官网下载twisted的whl包安装
Twisted‑19.2.0‑cp37‑cp37m‑win_amd64.whl
功能:实现利用学校找出省份 weiyigeek.top-执行后效果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#功能: 学校地区解析
import urllib.request
import urllib.parse
from lxml import etree
number = []
name = []
file1 = open('2.txt','r',encoding='utf-8')
for i in file1:
keyvalue = i.split(" ")
number.append(str(keyvalue[0]))
name.append(str(keyvalue[1]))
file1.close()
def test1(html,parm=""):
dom_tree = etree.HTML(html)
links = dom_tree.xpath("//div[@class='basic-info cmn-clearfix']/dl/dd/text()")
for i in links:
for v in range(0,len(number)):
if (i.find(name[v][:2]) != -1):
return number[v] + name[v] +parm+"\n"
return "未找到(或者是海外)"
file = open('1.txt','r+',encoding='utf-8')
file.seek(0,0)
for eachline in file:
url = "https://baike.baidu.com/item/"+urllib.parse.quote(eachline[6:]);
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8') #解码操作
f = open('c:\\weiyigeek.txt','a+',encoding='utf-8') #打开
res = test1(html,str(eachline[6:]))
f.writelines(res)
f.close() #关闭
file.close()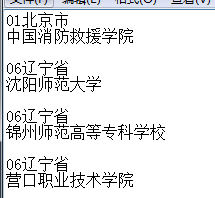
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/编程世界/Python/爬虫学习/Python3爬虫学习.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/4-12-345.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议