[TOC]
文章目录 (1) Heartbeat 高可用解决方案
0x00 Heartbeat 高可用 Q:什么是高可用技术呢?
1) Heartbeat 介绍 1.1 Heartbeat作用
heartbeat和keepalived(近年来使用增加,但是某些场景还是不及hb)有很多相同之处,但是也有区别:
Keepalived
使用的vrrp协议方式,虚拟路由冗余协议 (Virtual Router Redundancy Protocol,简称VRRP)
目的是模拟路由器的双机
常常与lvs负载均衡的高可用中使用结合
ka主要控制IP飘移,配置应用简单,而且分层,layer3,4,5,各自配置极为简单
Heartbeat
基于主机或网络的服务的高可用方式;
目的是用户service的双机
中间件业务的高可用中使用但是与lvs负载均衡配置比较麻烦需要其他脚本介入(ldirectord),常常与drbd进行联合使用
hb不但可以控制IP飘移,更擅长对资源服务的控制,配置,应用于比较复杂场景
1.2 Heartbeat工作原理
Heartbeat支持模式:
一般故障转移切换时间在5~20s之间(hearbeat需要进行arp广播,资源收缩等);和keepalived的服务一样,heartbeat高可用是服务器级别的,不是服务级别的 。
切换漂移的条件:
主服务器物理宕机(硬件损坏,操作系统故障)
heartbeat软件故障
两台主备服务器之间心跳连接故障
1.3 Heartbeat心跳连接 Q:如何进行心跳连接与监控?
穿行电缆,所谓的串口Serial(首先,缺点是距离不能太远)
一根以太网电缆两网卡直连(常用方式)
以太网电缆,通过交换机等网络设备连接。(交换机可能出现问题,心跳数据容易受到影响等)
1.4 Heartbeat应用场景
Nginx/haproxy高可用
数据库主从库主的高可用
LVS-DR负载均衡高可用
共享存储高可用
实际工作中两种高可用问题:
其他架构参考:
Tips:
一般来说只有内网机器很多的情况下,才有可能使用heartbeat,几台机器是没有必要的;
如果VIP正常httpd服务宕掉这时候它有可能不做高可用切换;需要自己写个脚本判断httpd服务,如果有问题则停止hb使业务转到另外一台服务器上;
2) Heartbeat 脑裂介绍 裂脑(splitbrain)原理:
2.1 裂脑原因
心跳链路故障(心跳线老化,接触不良,网卡驱动问题等等),导致无法正常通信
开启了防火墙阻挡了心跳信息传输;
心跳网卡地址等配置不正确;
服务配置错误,心跳方式异常,心跳广播冲突,软件bug;
2.2 裂脑解决
同时使用串行电缆和以太网电缆连接,同时使用两条心跳线(推荐)
检测到裂脑时,强制关闭一个节点(需要特殊设备支持,如stonish和fence), 相当于程序上的备节点发现心跳故障,发送关机指令到主节点
监控预警(短信电话通知运维人员),报警在服务器接管之前给人员处理留足时间,报警后不直接服务器此时接管而是由人员来控制操作
启用磁盘锁,做冗余
仲裁机制(确定让那个节点接管服务), 通过第三方软件仲裁谁获得资源;
2.3 fence介绍
不同服务器对应Fence设备名称:
IBM:RSA II
HP:ILO 2
DELL:iDRAC 3
外部fence设备:有APC(UPS电源生产商)生产的PowerSwitch
3) Heartbeat 消息列表 高可用软件工作过程中,一般来说由三种消息类型:
心跳信息:150字节的数据包,可能为单播,广播或多播方式;可以控制心跳频率与出现故障的等待时间;
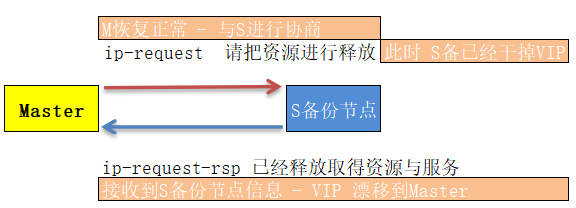
集群转换消息: ip-request (Master 恢复在线状态时) / ip-request-rsp (Slave 释放主服务器失败时取得的资源及服务),主服务器收到备节点的该消息则提供正常访问;
重传消息:rexmit-request 控制重传心跳请求
提示:以上心跳控制消息都使用UDP协议发生到/etc/ha.d/ha.cf 文件指定的任意端口或者指定多播地址;
3.1 IP地址接管和故障转移 确保客户端和新的服务器对话 ;
3.2 VIP/IP 别名/辅助IP
真实IP又称为管理/物理ip,一般指配置在物理网卡上面的ip。在负载均衡高可用环境中,管理IP是不对外提供访问服务的。仅仅作为管理服务器使用,如SSH可以通过这个进行服务连接管理。
VIP是虚拟ip,实际上就是eth0:X,x为0~255的任意数字,你可以在一个网卡上面绑定多个别名。VIP当主服务器故障时,可以自动漂移到备用服务器。
注意区别辅助ip和别名ip,keepalived和heartbeat3都是用辅助ip的形式;在实际生产环境中需要在DNS配置中把网站域名地址解析到VIP地址而并发非真实IP地址;
[TOC]
文章目录 (1) Heartbeat 高可用解决方案
0x00 Heartbeat 高可用 Q:什么是高可用技术呢?
1) Heartbeat 介绍 1.1 Heartbeat作用
heartbeat和keepalived(近年来使用增加,但是某些场景还是不及hb)有很多相同之处,但是也有区别:
Keepalived
使用的vrrp协议方式,虚拟路由冗余协议 (Virtual Router Redundancy Protocol,简称VRRP)
目的是模拟路由器的双机
常常与lvs负载均衡的高可用中使用结合
ka主要控制IP飘移,配置应用简单,而且分层,layer3,4,5,各自配置极为简单
Heartbeat
基于主机或网络的服务的高可用方式;
目的是用户service的双机
中间件业务的高可用中使用但是与lvs负载均衡配置比较麻烦需要其他脚本介入(ldirectord),常常与drbd进行联合使用
hb不但可以控制IP飘移,更擅长对资源服务的控制,配置,应用于比较复杂场景
1.2 Heartbeat工作原理
Heartbeat支持模式:
一般故障转移切换时间在5~20s之间(hearbeat需要进行arp广播,资源收缩等);和keepalived的服务一样,heartbeat高可用是服务器级别的,不是服务级别的 。
切换漂移的条件:
主服务器物理宕机(硬件损坏,操作系统故障)
heartbeat软件故障
两台主备服务器之间心跳连接故障
1.3 Heartbeat心跳连接 Q:如何进行心跳连接与监控?
穿行电缆,所谓的串口Serial(首先,缺点是距离不能太远)
一根以太网电缆两网卡直连(常用方式)
以太网电缆,通过交换机等网络设备连接。(交换机可能出现问题,心跳数据容易受到影响等)
1.4 Heartbeat应用场景
Nginx/haproxy高可用
数据库主从库主的高可用
LVS-DR负载均衡高可用
共享存储高可用
实际工作中两种高可用问题:
其他架构参考:
Tips:
一般来说只有内网机器很多的情况下,才有可能使用heartbeat,几台机器是没有必要的;
如果VIP正常httpd服务宕掉这时候它有可能不做高可用切换;需要自己写个脚本判断httpd服务,如果有问题则停止hb使业务转到另外一台服务器上;
2) Heartbeat 脑裂介绍 裂脑(splitbrain)原理:
2.1 裂脑原因
心跳链路故障(心跳线老化,接触不良,网卡驱动问题等等),导致无法正常通信
开启了防火墙阻挡了心跳信息传输;
心跳网卡地址等配置不正确;
服务配置错误,心跳方式异常,心跳广播冲突,软件bug;
2.2 裂脑解决
同时使用串行电缆和以太网电缆连接,同时使用两条心跳线(推荐)
检测到裂脑时,强制关闭一个节点(需要特殊设备支持,如stonish和fence), 相当于程序上的备节点发现心跳故障,发送关机指令到主节点
监控预警(短信电话通知运维人员),报警在服务器接管之前给人员处理留足时间,报警后不直接服务器此时接管而是由人员来控制操作
启用磁盘锁,做冗余
仲裁机制(确定让那个节点接管服务), 通过第三方软件仲裁谁获得资源;
2.3 fence介绍
不同服务器对应Fence设备名称:
IBM:RSA II
HP:ILO 2
DELL:iDRAC 3
外部fence设备:有APC(UPS电源生产商)生产的PowerSwitch
3) Heartbeat 消息列表 高可用软件工作过程中,一般来说由三种消息类型:
心跳信息:150字节的数据包,可能为单播,广播或多播方式;可以控制心跳频率与出现故障的等待时间;
集群转换消息: ip-request (Master 恢复在线状态时) / ip-request-rsp (Slave 释放主服务器失败时取得的资源及服务),主服务器收到备节点的该消息则提供正常访问;
重传消息:rexmit-request 控制重传心跳请求
提示:以上心跳控制消息都使用UDP协议发生到/etc/ha.d/ha.cf 文件指定的任意端口或者指定多播地址;
3.1 IP地址接管和故障转移 确保客户端和新的服务器对话 ;
3.2 VIP/IP 别名/辅助IP
真实IP又称为管理/物理ip,一般指配置在物理网卡上面的ip。在负载均衡高可用环境中,管理IP是不对外提供访问服务的。仅仅作为管理服务器使用,如SSH可以通过这个进行服务连接管理。
VIP是虚拟ip,实际上就是eth0:X,x为0~255的任意数字,你可以在一个网卡上面绑定多个别名。VIP当主服务器故障时,可以自动漂移到备用服务器。
注意区别辅助ip和别名ip,keepalived和heartbeat3都是用辅助ip的形式;在实际生产环境中需要在DNS配置中把网站域名地址解析到VIP地址而并发非真实IP地址;
1 2 3 4 5 6 7 ip addr add 192.168.12.1/24 broadcast 192.168.12.255 dev eth1 ip addr del 192.168.12.1/24 broadcast 192.168.12.255 dev eth1 ifconfig eth0:1 192.168.12.1 netmask 255.255.255.224 up ifconfig eth0:1 192.168.12.1 netmask 255.255.255.224 down
管理IP/VIP对比:
管理IP来回迁移非常难做到
VIP 方便管理与配置
4) Heartbeat 安装与配置 1.环境需求介绍
在实际生产环境中,也可以配置主备模式,即只在主的一端配置VIP,备的一端仅处于热备状态;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 系统:CentOS release 6.10 (Final) 内核:Linux WeiyiGeek 2.6.32-754.10.1.el6.i686 2019 GNU/Linux 虚拟软件:VirtualBOX (管理-> 全局设定 -> NAT 网络 -> 配置两个1/2网段将自动获取IP去掉) 管理IP :192.168.1.100 心跳连接:192.168.2.100 VIP :192.168.1.10 管理IP :192.168.1.101 心跳连接:192.168.2.101 VIP :192.168.1.11 [root@Master-data1/2 ~] Disabled
Tips:
建议大家把内外网IP最后8位配置成为相同的方式,容易记忆方便管理;
另外存储服务器之间,存储服务器和交换机之间可配置成双千兆网卡绑定(bonding)来提升网卡性能;
在部署进行主机规划意义重大,它让我们思路清晰;
2.Heartbeat版本和配置 http://www.linux-ha.org/wiki/Download
Heartbeat 3.0.6 //心跳主程序包
Cluster Glue 1.0.12 //可重复使用的群集组件(光盘)
Resource Agents 3.9.6 //集群实验资源代理(光盘)
Pacemaker-1.1.9-1512.el6.src.rpm //起搏器(光盘镜像)
weiyigeek.top-Heartbeat下载
HA默认配置文件目录/etc/ha.d/,常用配置文件:1 2 3 4 5 ha.cf 参数配置文件 配置heartbeat一些基本参数 authkey 认证文件 高可用服务器对之间根据对端的authkey(对端进行相互认证-防止第三者插足) haresource 资源配置文件 配置启动IP资源及脚本程序/服务等
环境配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 vim /etc/sysconfig/network-scripts/ifcfg-eth2 DEVICE=eth2 TYPE=Ethernet UUID=c3f35428-3740-4791-bc38-8e0d69707d4b ONBOOT=yes NM_CONTROLLED=no BOOTPROTO=static IPADDR=192.168.2.100 NETMASK=255.255.255.0 ; GATEWAY=192.168.1.1 心跳线IP配置不用配网关和DNS $ ifconfig eth2 192.168.2.100 $ ifdown eth2 ETH1:inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0 ETH2:inet addr:192.168.2.100 ETH1:inet addr:192.168.1.101 Bcast:192.168.1.255 Mask:255.255.255.0 ETH2:inet addr:192.168.2.101 [root@WeiyiGeek ~]$ hostname Master-data1 [root@WeiyiGeek ~]$ sed -i 's/HOSTNAME=WeiyiGeek/HOSTNAME=Master-data1/g' /etc/sysconfig/network [root@WeiyiGeek ~]$ sed -i 's/HOSTNAME=WeiyiGeek/HOSTNAME=Master-data2/g' /etc/sysconfig/network cat >> /etc/hosts<<eof 192.168.1.100 Master-data1 192.168.1.101 Master-data2 eof [root@Master-data1 ] 64 bytes from Master-data2 (192.168.1.101): icmp_seq=1 ttl=64 time=0.415 ms 64 bytes from Master-data2 (192.168.1.101): icmp_seq=2 ttl=64 time=0.545 ms [root@Master-data2 ] 64 bytes from Master-data1 (192.168.1.100): icmp_seq=1 ttl=64 time=1.04 ms 64 bytes from Master-data1 (192.168.1.100): icmp_seq=2 ttl=64 time=0.796 ms
Tips: hosts配置在heartbeat服务中会用到,后文的drbd及存储高可用性能配置都会用到;在实际的生产环境中会把所有机器名对应上所有的机器IP地址;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 route add -host 192.168.2.101 dev eth2 route add -host 192.168.2.100 dev eth2 echo '/sbin/route add -host 192.168.2.101 dev eth2' >> /etc/rc.local $ route -n Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.2.101 0.0.0.0 255.255.255.255 UH 0 0 0 eth2 Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.2.100 0.0.0.0 255.255.255.255 UH 0 0 0 eth2 TIPS:先yum search heartbeat看看是否有相关可以下载的包;没有的话下载安装epel扩展 (注意选中对应的版本) mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup yum install -y epel-release rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6 [root@Master-data[1/2] ~] epel-release-6-8.noarch TIPS:yum 安装rpm包安装后本地不清除的方法 sed -i "s/keepcache=0/keppcache=1/g" /etc/yum.conf $ yum install heartbeat* -y [root@Master-data1 ha.d]$ cd /usr/share/doc/heartbeat-3.0.4/ $ cp ha.cf haresources authkeys /etc/ha.d/ [root@Master-data1 ha.d]$ vim ha.cf [root@Master-data1 ha.d] debugfile /var/log /ha-debug logfile /var/log /ha-log logfacility local0 keepalive 2 deadtime 30 warntime 10 initdead 120 mcast eth1 225.0.0.11 694 1 0 auto_failback on node Master-data1 node Master-data2 [root@Master-data1 ha.d]$ chmod 600 authkeys [root@Master-data1 ha.d]$ vim authkeys auth 2 2 sha1 HI! [root@Master-data1 ha.d]$ vim haresources 45 Master-data1 IPaddr::192.168.1.10/24/eth1 46 Master-data2 IPaddr::192.168.1.11/24/eth1 [root@Master-data1 ha.d]$ tar -zcvf test.tar.gz ha.cf authkeys haresources [root@Master-data2 ha.d]$ scp root@192.168.1.100:/etc/ha.d/test.tar.gz /etc/ha.d/ $ tar -zxvf test.tar.gz [root@Master-data1 ha.d]$ /etc/init.d/heartbeat start [root@Master-data2 ha.d]$ /etc/init.d/heartbeat start Starting High-Availability services: INFO: Resource is stopped INFO: Resource is stopped Done. 正常情况需要等待120s来恢复网络: [root@Master-data1 ha.d]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.100/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.2.100/24 brd 192.168.2.255 scope global eth2 [root@Master-data2 ha.d]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.101/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.2.101/24 brd 192.168.2.255 scope global eth2 [root@Master-data1 ha.d]$ /etc/init.d/heartbeat stop $ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.100/24 brd 192.168.1.255 scope global eth1 [root@Master-data2 ha.d]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.101/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth1
5) 实战案例 目的:通过一个WEB服务高可用案例熟悉heartbeat软件的使用,在上面基础之上进行实现;
步骤流程: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 1. 配置httpd首页将Master-data1 / Master-data2分别写入index.html [root@Master-data1 ~]$ echo "Master-data1 192.168.1.100" > /var/www/html/index.html [root@Master-data2 ~]$ echo "Master-data2 192.168.1.101" > /var/www/html/index.html 2. 配置host域名来解析(判断VIP是不是被漂移) [root@Master-data2 ~]$ echo '192.168.1.10 www.demo.org' >> /etc/hosts [root@Master-data2 ~]$ ping www.demo.org PING www.demo.org (192.168.1.10) 56(84) bytes of data. 3.开启主备的httpd与heartbeat服务 [root@Master-data1 ~]$ /etc/init.d/heartbeat start $ service httpd start Starting httpd: [ OK ] [root@Master-data2 ~]$ /etc/init.d/heartbeat start $ /etc/init.d/httpd start Starting httpd: [ OK ] 4.模式释放 [root@Master-data1 html]$ /usr/share/heartbeat/hb_standby Going standby [all]. 5.实现的效果 [root@Master-data2 ~]$ curl www.demo.org Master-data1 192.168.1.100 [root@Master-data2 ~]$ curl www.demo.org Master-data2 192.168.1.101 6.此时以将漂移到Master-data2上 [root@Master-data2 ~]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.101/24 brd 192.168.1.255 scope global eth3 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth3 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth3 7.恢复接管 /usr/share/heartbeat/hb_takeover [root@Master-data1 html]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.100/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth1
第二种方式: 让heartbeat负责httpd启动同时负责vip启动1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 chkconfig httpd off [root@Master-data1 ha.d]$ cp /etc/init.d/httpd /etc/ha.d/resource.d [root@Master-data1 ha.d]$ vim haresources Master-data1 IPaddr::192.168.1.10/24/eth1 httpd Master-data2 IPaddr::192.168.1.11/24/eth1 [root@Master-data1 ha.d]$ netstat -tlnp | grep "httpd" [root@Master-data1 ha.d]$ /etc/init.d/heartbeat start [root@Master-data1 resource.d]$ netstat -tlnp | grep "httpd" tcp 0 0 :::80 :::* LISTEN 12984/httpd [root@Master-data2 ha.d]$ curl www.demo.org Master-data1 192.168.1.100 [root@Master-data2 ha.d]$ netstat -tlnp | grep "httpd" tcp 0 0 :::80 :::* LISTEN 12063/httpd [root@Master-data2 ha.d]$ curl www.demo.org Master-data2 192.168.1.101 ResourceManager(default)[14023]: 2019/04/09_23:32:35 info: Releasing resource group: master-data1 IPaddr::192.168.1.10/24/eth1 httpd ResourceManager(default)[14023]: 2019/04/09_23:32:35 info: Running /etc/ha.d/resource.d/httpd stop
注意事项:
脚本路径要放入/etc/init.d/httpd 或 /etc/ha.d/resource.d/
脚本执行需要支持 stop/start方式脚本具备可执行权限,且与haresource 中脚本名称一致
如果httpd服务被卡死,会自己重启系统(进行进程自杀)
常用git/svn进行配置heartbeat配置文件,重要的事情说三遍(备份/备份/备份);
在正式的环境中建议先进行测试(找个流量低谷),手动配置临时网卡来测试网络方面的问题;
补充(附录) 0.heartbeat释放模拟脚本 1 2 3 4 5 6 7 /usr/lib64/heartbeat/hb_standby /usr/share/heartbeat/hb_standby /usr/lib64/heartbeat/hb_takeover /usr/share/heartbeat/hb_takeover
1.配置文件讲解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 vim /etc/ha.d/ha.cf 24 debugfile /var/log /ha-debug 29 logfile /var/log /ha-log 34 ogfacility local0 48 keepalive 2 56 deadtime 30 61 warntime 10 71 initdead 120 76 udpport 694 91 113 mcast eth0 225.0.0.1 694 1 0 121 157 auto_failback on 211 node Master-data1 212 node Master-data2 220 ping 192.186.1.254 253 respawn hacluster /usr/libexec/heartbeat/ipfail 259 apiauth ipfail gid=haclient uid=hacluster 157 auto_failback on
1 2 3 4 5 6 7 8 data-1-1 IPaddr::10.0.0.100/24/eth0 data-1-2 IPaddr::10.0.0.101/24/eth0 data-1-1 : 主机名 IPaddr :Resources.d/ 中的脚本文件 10.0.0.100/24/eth0 : 集群对外服务的VIP,24为子网掩码,eth0为IP绑定的实际物理网卡;为heartbeat提供对外服务的通信接口;
weiyigeek.top-MYSQL集群运维
2.Heartbaet入坑计 Q:日志分析接管过程? 1 2 3 4 5 6 7 8 1.pacemaker support 情况 2.logging daemon 3.heartbeat 版本信息 4.glib:UDP 多播信息发送 5.运行/etc/ha.d/rc.d/status 脚本查看对端的状态; 6.服务异常则接管资源,通过IPaddr脚本 7.广播UDP及VIP地址 8.如果检测对端正常则将结果的资源释放并返回给它 ip-request (请求发送) / ip-request-rsep (请求发送)
Q:两边都显示漂移的VIP地址? 1 2 3 4 5 6 7 8 9 10 11 [root@Master-data1 ha.d]$ ip addr | grep -v -E "link|inet6" | grep "192.168" inet 192.168.1.100/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth1 inet 192.168.2.100/24 brd 192.168.2.255 scope global eth3 [root@Master-data2 ha.d] inet 192.168.1.101/24 brd 192.168.1.255 scope global eth3 inet 192.168.1.10/24 brd 192.168.1.255 scope global secondary eth3 inet 192.168.1.11/24 brd 192.168.1.255 scope global secondary eth3 inet 192.168.2.101/24 brd 192.168.2.255 scope global eth5
Q:一个LAN中是多组heartbeat服务同时开启的问题?
weiyigeek.top-实时同步共享存储
Q:Filesystem脚本问题 1 2 3 4 Filesystem(Filesystem_/dev/drbd0)[18085]: 2019/05/14_17:12:48 ERROR: Setup problem: couldn't find command: fuser' yum install psmisc
Q:从机虚拟机复制的主机开启heartbeat时候报uuid错误 1 2 3 4 May 15 13:29:21 Szabbix heartbeat: [4467]: WARN: nodename mzabbix uuid changed to szabbix [root@Szabbix ~]
3.Centos7安装heartbeat在epel源不存在问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i s reboot hostname data-1 echo "data-1" >> /etc/hostnameecho -e "192.168.1.100 data-1 node1\n192.168.1.100 data-1 node2" >> /etc/hostsssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa ssh-copy-id root@192.168.1.100 yum install gcc gcc-c++ autoconf automake libtool glib2-devel libxml2-devel bzip2 bzip2-devel e2fsprogs-devel libxslt-devel libtool-ltdl-devel asciidoc wget psmisc groupadd haclient useradd -g haclient hacluster wget http://hg.linux-ha.org/heartbeat-STABLE_3_0/archive/958e11be8686.tar.bz2 -O /opt/heartbeat3.tar.bz2 wget http://hg.linux-ha.org/glue/archive/0a7add1d9996.tar.bz2 -O /opt/glue.tar.bz2 wget https://github.com/ClusterLabs/resource-agents/archive/v3.9.6.tar.gz -O /opt/resource-agents.tar.bz2 tar xf glue.tar.bz2 ./autogen.sh ./configure --prefix=/usr/local /heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable -fatal-warnings=no LIBS='/lib64/libuuid.so.1' make && make install echo $?tar xf resource-agents.tar.bz2 cd resource-agents-3.9.6/./autogen.sh ./configure --prefix=/usr/local /heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable -fatal-warnings=no LIBS='/lib64/libuuid.so.1' make && make install echo $?tar xf heartbeat3.tar.bz2 ./bootstrap export CFLAGS="$CFLAGS -I/usr/local/heartbeat/include -L/usr/local/heartbeat/lib" ./configure --prefix=/usr/local /heartbeat --with-daemon-user=hacluster --with-daemon-group=haclient --enable -fatal-warnings=no LIBS='/lib64/libuuid.so.1' make && make install echo $?mkdir -pv /usr/local /heartbeat/usr/lib/ocf/lib/heartbeat/ cp /usr/lib/ocf/lib/heartbeat/ocf-* /usr/local /heartbeat/usr/lib/ocf/lib/heartbeat/ ln -svf /usr/local /heartbeat/lib64/heartbeat/plugins/RAExec/* /usr/local /heartbeat/lib/heartbeat/plugins/RAExec/ ln -svf /usr/local /heartbeat/lib64/heartbeat/plugins/* /usr/local /heartbeat/lib/heartbeat/plugins/ heartbeat configuration: Version = "3.0.6" Executables = "/usr/local/heartbeat/sbin" Man pages = "/usr/local/heartbeat/share/man" Libraries = "/usr/local/heartbeat/lib64" Header files = "/usr/local/heartbeat/include" Arch-independent files = "/usr/local/heartbeat/share" Documentation files = "/usr/local/heartbeat/share/doc/heartbeat" State information = "/usr/local/heartbeat/var" System configuration = "/usr/local/heartbeat/etc" Init (rc) scripts = "/etc/rc.d/init.d" Init (rc) defaults = "/etc/sysconfig" Use system LTDL = "yes" HA group name = "haclient" HA group id = "1001" HA user name = "hacluster" HA user user id = "1001" Build dopd plugin = "yes" Enable times kludge = "yes" cp /usr/local /heartbeat/share/doc/heartbeat/{ha.cf,haresources,authkeys} /usr/local /heartbeat/etc/ha.d/ vim /usr/local /heartbeat/etc/ha.d/ha.cf mcast eth2 225.0.0.200 694 1 0 ucast eth2 192.168.2.100 ucast eth2 192.168.2.101 vim /usr/local /heartbeat/etc/ha.d/authkeys vim /usr/local /heartbeat/etc/ha.d/haresources node1 192.168.1.200 apache::/etc/httpd/conf/httpd.conf data1 IPaddr::192.168.1.200/24/eth1 data2 IPaddr::192.168.1.201/24/eth1 chmod 600 /usr/local /heartbeat/etc/ha.d/authkeys chown -R root:haclient /usr/local /heartbeat/ [root@data1 heartbeat] inet 192.168.1.100/24 brd 192.168.1.255 scope global eth1 inet 192.168.1.201/24 brd 192.168.1.255 scope global secondary eth1:0 inet 192.168.1.200/24 brd 192.168.1.255 scope global secondary eth1:1 inet 192.168.2.100/24 brd 192.168.2.255 scope global noprefixroute eth2
weiyigeek.top-测试接管
4.如何配置nfs的高可用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 yum install nfs-utils rpcbind systemctl start rpcbind systemctl start nfs cat /etc/exports /data 192.168.146.0/24(ro) mkdir /data echo '<h1>nfs server</h1>' > /data/index.htmlnode1.pjy.com IPaddr::192.168.146.222/24/ens33 Filesystem::192.168.146.151:/data::/var/www/html::nfs::ro apache::/etc/httpd/conf/httpd.conf pz142 IPaddr::192.168.146.222/24/eth0 drbddisk::nfddrbd Filesystem::/dev/drbd0::/data/image::ext4 killnfsd systemctl restart heartbeat ssh node2 'systemctl restart heartbeat' ip addr netstat -lntup mount /usr/local /heartbeat/share/heartbeat/hb_standby