[TOC]
0x00 快速入门 描述: 不管对于那一门编程语言,字符串类型都是及其重要的,所以在学习编程语言后会发现近40%左右都与字符串有关,特别是PHP当然在Linux中的shell脚本开发也同样存在;所以下面主要是字符串搜索命令采用正则匹配的命令,都是在shell编程中比较常用的;
grep 命令 描述:grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Tips:属于Linux三剑客之一(grep、sed、awk)
语法和参数:
[TOC]
0x00 快速入门 描述: 不管对于那一门编程语言,字符串类型都是及其重要的,所以在学习编程语言后会发现近40%左右都与字符串有关,特别是PHP当然在Linux中的shell脚本开发也同样存在;所以下面主要是字符串搜索命令采用正则匹配的命令,都是在shell编程中比较常用的;
grep 命令 描述:grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Tips:属于Linux三剑客之一(grep、sed、awk)
语法和参数: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 grep 【选项】"字符串" 文件名 -a 不要忽略二进制数据。 -A <显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。 -B <显示列数> 并显示该行之前的内容 -b 在显示符合范本样式的那一行之外,并显示该行之前的内容。 -c 计算符合范本样式的列数。 -C <显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。(中间开始上下列数) -d <进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。 -e, --regexp=PATTERN -E, --extended-regexp -G, --basic-regexp -P, --perl-regexp -f <范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。 -F 将范本样式视为固定字符串的列表。 -G 将范本样式视为普通的表示法来使用。 -h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。 -H 在显示符合范本样式的那一列之前,同时打印包括搜索字符串的文件。 (常用) -i 忽略字符大小写的差别,因为Linux严格区分大小写(常用) -l 列出文件内容符合指定的范本样式的文件名称。 -L 列出文件内容不符合指定的范本样式的文件名称。 -n 在显示符合范本样式的那一列之前,标示出该列的编号。 -q 不显示任何信息。 -R/-r 此参数的效果和指定“-d recurse”参数相同,递归搜索。(常用) -s 不显示错误信息。 -v 反转查找,即搜索不包含字符串的文件 (显示除字符串的其他类容)。 (常用) -w 只显示全字符合的列。 -x 只显示全列符合的列。 -y 此参数效果跟“-i”相同。 -Z 显示匹配的文件以及匹配字符 -o 只输出文件中匹配到的部分不会输出那一行,精确输出我想要的内容.(常用) --color=auto --include * --exclude * --exclude-from file
实际案例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 grep "match_pattern" file_name grep -q "test" filename grep -v "/" test.jsp grep -i "test" test.jsp grep -c "text" file_name grep "text" -n file_name echo this is a text line | grep -e "is" -e "line" -o echo aaa bbb ccc ddd eee | grep -f patfile.txt -ogrep "match_pattern" file_1 file_2 file_3 grep "text" -n file_1 file_2 grep -l "text" file1 file2 file3 grep -E "[1-9]+" grep -v -E "^#" sshd.conf | echo this is a test line. | grep -o -E "[a-z]+\." line. echo this is a test line. | egrep -o "[a-z]+\." line. grep "text" . -r -n echo -e "a\nb\nc\na\nb\nc" | grep 'a' -A 0a -- a grep -Eqi "Ubuntu" /etc/issue echo $?ps -p $$ | grep -siq bash echo $?
weiyigeek.top-正则与递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 echo gun is not unix | grep -b -o "not" grep "main()" . -r --include *.{php,html} grep "main()" . -r --exclude "README" grep "main()" . -r --exclude-from filelist.txt echo "aaa" > file1echo "bbb" > file2echo "aaa" > file3grep "aaa" file* -lZ | xargs -0 rm $grep "aaa" file* -lfile1 file3 $grep "aaa" file* -Zfile1aaa file3aaa
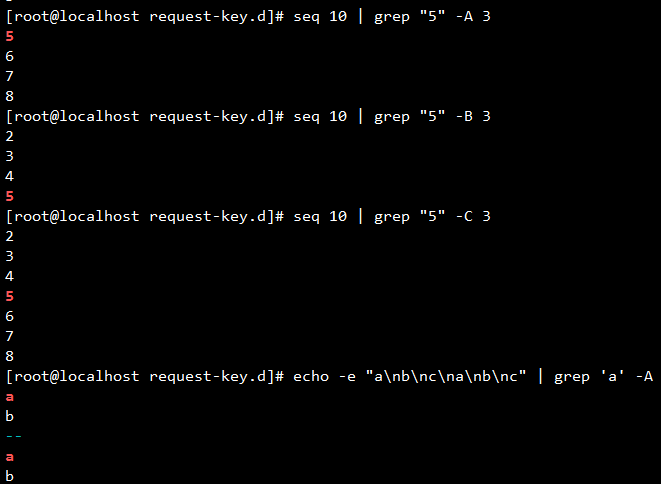
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 seq 10 | grep "5" -A 3 seq 10 | grep "5" -B 3 seq 10 | grep "5" -C 3 echo -e "a\nb\nc\na\nb\nc" | grep a -A 1grep -E -A 3 "^Cached" meminfo
weiyigeek.top-grep-ABC
补充示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 echo "WeiyiWeiyiGeek Whoami" | grep -oP "Weiyi(?=WeiyiGeek)" Weiyi echo "WeiyiGeek Whoami" | grep -oP "(?=WeiyiGeek)Weiyi" Weiyi grep -Po '(?<=^ID=")\w+' /etc/os-release grep -Po '500381200107070222|500108200311291522' /tmp/2023gkys.logs grep -A 100 "$(date -d '-1 minute' '+%Y-%m-%d %H:%M') " studentcenter.log cd /app/logs/StudentCenter && grep -E "21500140770323|21500113771228" info.2021-04-18.0.log | grep "yxmc=" | grep -oE "ksh=\d{14}" | sort | uniq -cgrep -ohr -E "https?://[a-zA-Z0-9\.\/_&=@$%?~#-]*" ./folder grep -oE '(https|http|ftp)?://[a-zA-Z0-9\.\/_&=@$%?~#-]*' demo.txt | grep -vE ".docx$|.pdf$|.jpg$|.gif$" | sort | uniq grep -L "pageid:" -R . | grep -E "md$" grep -o -P '[\p{Han}]{0,}' weiyigeek.top.log grep -o -P 'ksh=[0-9]{14}, xm=[\p{Han}]{0,3}, sfzh=[0-9xX]{18}' /tmp/weiyigeek.logs grep -w -oP "^\[2023-01-[0-9]{0,2} [0-9]{0,2}:[0-9]{0,2}:[0-9]{0,2}.[0-9]{0,3}\]|ksh=[0-9]{14}, xm=[\p{Han}]{0,}, sfzh=[0-9xX]{18}" /tmp/weiyigeek.logs | sed ':a;N;$!ba;s/]\n/] /g' grep "cj=" result.txt | grep -o -P '^\[2023-03-[0-9]{0,2} [0-9]{0,2}:[0-9]{0,2}:[0-9]{0,2}.[0-9]{0,3}\]|ksh=[0-9]{14}, xm=[\p{Han}]{0,3}' | sed ':a;N;$!ba;s/]\n/] /g' | sort -t "]" -k 2
Find命令与Grep命令的区别: 通配符匹配是完全匹配.正则表达式是包含匹配。
egrep 命令 描述:grep 默认仅支持基础正则表达式(Base Regular Expression),如果要使用扩展性正则表达式(Extended Regular Expression),使用egrep命令实际上grep -E == egrep ,extended regular expression比basic regular expression的表达更规范。
egrep用extended regular expression语法来解读的
grep用basic regular expression 语法解读
使用的语法及参数可参照grep指令,与grep的不同点在于解读字符串的方法。
1 2 3 4 5 egrep(选项)(查找模式)(文件名1,文件名2,……) -i
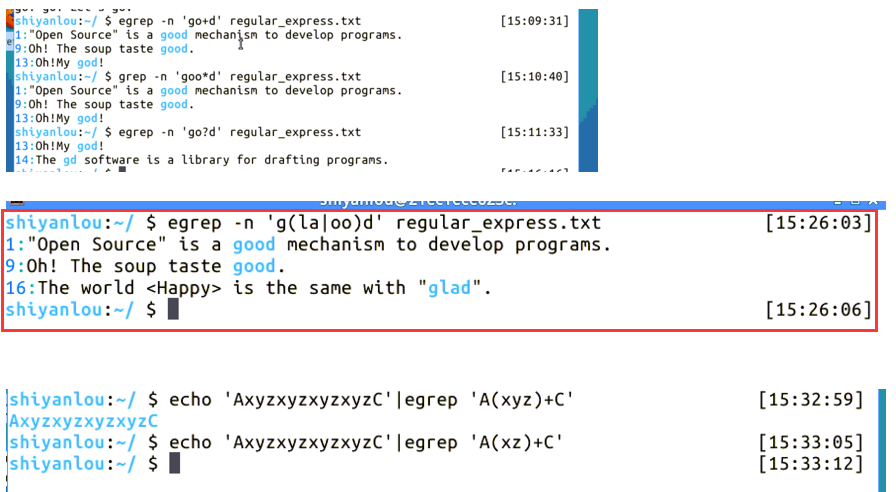
实际案例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ egrep -n 'goo*d' regular_express.txt $ egrep -n 'go+d' regular_express.txt $ egrep -n 'go?d' regular_express.txt $ egrep -n 'g(la|oo)d' regular_express.txt $echo 'AxyzxyzxyzxyzC' |egrep 'A(xyz)+C' $echo 'AxyzxyzxyzxyzC' |egrep 'A(xz)+C' egrep -i '^(From|Subject|Date): ' email.txt cd /app/logs/StudentCenter && egrep "18:(05|06|07|08|09|10)" info.2021-03-12.0.log | grep "cjxmc=总分" | egrep -o "sfzh=[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]" | sort -u | wc -l
weiyigeek.top-正则egrep案例