[TOC]
0x00 Docker架构与底层实现原理浅析 通过前面的学习,我们基本掌握了Docker的配置使用,现在我们以 Docker 基础架构来探究Docke底层的核心技术,简单的包括:
Linux 上的命名空间(Namespaces)
控制组(Control groups)
Union 文件系统(Union file systems)
容器格式(Container format)
容器网络 (Container network)
容器存储驱动 (Container Storage)
1.基本架构
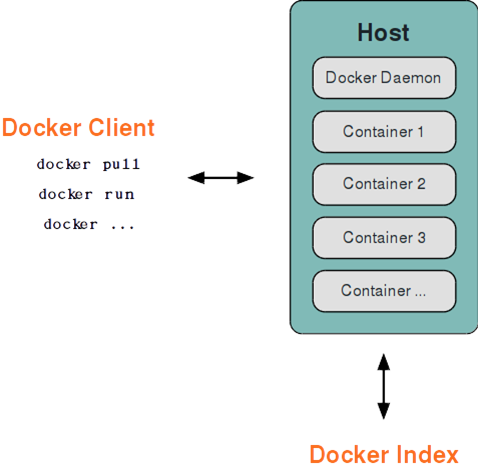
C/S 架构,包括客户端和服务端,既可以运行在一个机器上,也可通过 socket 或者 RESTful API 来进行通信。
Docker 守护进程 (Daemon)一般在宿主主机后台运行,作为服务端接受来自客户端的请求,并处理这些请求(创建、运行、分发容器)
Docker 客户端则为用户提供一系列可执行命令如docker run / ,用户用这些命令实现跟 Docker 守护进程交互。
传统虚拟机特点:
操作系统与资源共享
例如,以宿主机和虚拟机系统都为 Linux 系统为例,虚拟机中运行的应用其实可以利用宿主机系统中的运行环境(docker也是基于此)。
实现虚拟化的要求:
实现对内存memory(不可压缩)、CPU(可压缩)、网络IO、硬盘IO、存储空间等的限制外
实现文件系统、网络、PID、UID、IPC等等的相互隔离
Memory
OOME 介绍:在linux主机中如果kernel监测到当前宿主机没有充足的内存用于实现系统某些重要的功能,就会抛出OOME异常(Out
一旦发生OOME任何进程都有可能被杀死,包括docker daemon在内,为此Docker特定调整dockerdaemon的优先级以免被误杀,但是容器的优先级未被调整;
根据各种复杂的算法来算出进程的oom-score数越多就会被kill掉,有些您不想kill掉的容器需要采用oom_odj键来初始化指定即(–oom-kill-disable / –oom-score-adj int)
设置限制容器中内存大小的参数:–memory 与 –memory-swap N ,其中内存又被分为RAM、SWAP;必须先设置前则才能使用–memory-swap
weiyigeek.top-memory-swap
CPU
CFS scheduler : 完全公平调度系统在docker1.3以前使用,在1.3及以后使用的是realtime实时性的;
普通进程优先级调度是非实时的/内核级进程一般都是实时的;
优先级:CPU密集型、IO密集型
限制CPU的参数:–cpus 核数 / –cpu-shares (需要则按照比例进行分配)
使用docker的stress镜像压测实现资源限制:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 $docker pull lorel/docker-stress-nglorel/docker-stress-ng latest 1ae56ccafe55 3 years ago 8.1MB $docker run --name stress -it --rm lorel/docker-stress-ng:latest stress -help Example: stress-ng --cpu 8 --io 4 --vm 2 --vm-bytes 128M --fork 4 --timeout 10s [root@izwz9biz2m4sd3bb3k38pgz ~] $docker stats CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 36a41704053f stress 98.57% 140MiB / 256MiB (关键点) 54.69% 0B / 0B 0B / 0B 5 $docker run --name stress -it -m 256m --rm lorel/docker-stress-ng:latest stress --cpu 8 --io 4 $docker run --name stress --cpus 0.5 -it -m 256m --rm lorel/docker-stress-ng:latest stress --cpu 8 --io 4 $docker run --name stress --cpuset-cpus 0 -it --rm lorel/docker-stress-ng:latest stress --cpu 8 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 6d6cc81d6e26 stress 50.99% 15.93MiB / 256MiB 6.22% 0B / 0B 0B / 143kB 13
2.I/O设备简述 描述:Linux中I/O设备分为以下两类,两种设备本身没有严格限制,但是基于不同的功能进行分类;
字符设备: 提供连续的数据流支持按字节、字符来读写数据,应用程序需要按顺序进行读取,所以通常不支持随机存取; 比如:调制解调器就是典型的字符设备;
块设备: 应用程序可以随机访问设备数据,并且程序自己确定读取数据的位置;比如磁盘就是典型的块设备;
Q: 字符设备与块设备的区别?前者顺序读取写入,后者通过寻址磁盘上的任何位置进行读取写入,注意块设备数据的读写只能以块(通常是512B)的倍数进行,与字符设备另外一个区别就是块设备并不支持基于字符的寻址;
Linux 的设备管理和文件系统是紧密相关的(一切皆文件),以文件的格式存放于/dev/目录之下称为设备文件。
对于常用设备Linux有约定俗称的编号,如磁盘的主设备号是3;并且一个字符设备或者块设备都有一个主设备号和次设备号(统称为设备号);
Q: 什么是主设备号和次设备号?
3.底层原理浅析 1.命名空间 描述:容器(Container)利用Linux中内核(>=2.4.19)命名空间来做权限的隔离控制即将某个特定的全局系统资源通过抽象的方法使得namespace中的进程看起来拥有他们自己的隔离的全局系统资源,并且联合利用 cgroups 来做资源分配限制。
Docker 容器和 LXC 容器很相似,命名空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发现和作用。随着 Linux 系统对于命名空间功能的完善实现,程序员已经可以实现上面的所有需求,让某些进程在彼此隔离的命名空间中运行。大家虽然都共用一个内核和某些运行时环境(例如一些系统命令和系统库),但是彼此却看不到都以为系统中只有自己的存在
当使用docker run启动一个容器时候,后台Docker会为容器创建一个独立的命名空间和控制组集合;每个容器都有资源独有网络,意味着他们不能访问其他容器的sockets或接口。但能通过–links来连接 2 个容器时或者–net来自定义Docker容器网络(网桥接口相互通信),容器就可以相互通信了(可以根据配置来限制通信的策略);
命名空间(namespace)在Docker容器具体实现说明如下:
Namespace
隔离的全局系统资源
容器隔离效果
UTS (UNIX Time-sharing System )
主机名与域名
每个容器拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非主机上的一个进程。
User
用户和用户组
每个容器可以有不同的用户uid和组gid, 可以在容器内用容器内部的用户执行程序而非宿主主机上的用户。
IPC (Inter-Process Communication)
信号量、消息队列(POSIX message queues)以及共享内存
每个容器有其自己的System V IPC 和 POSIX 消息队列系统,从而只有在同一个IPC namespace的进程之间才能互相通信; 有唯一的32位id)申请时加入命名空间信息。
PID
进程编号
每个名称空间中pid中的进程可以有其独立的PID,即不同用户的进程通过 pid 命名空间隔离开的,且不同命名空间中可以有相同 pid号; 每个容器可以有其PID为1的root进程,也使得容器可以在不同的host之间进行迁移(因为namespace中的进程ID和host不是强绑定,使得容器中的每个进程有两个PID即容器中PID和host上的PID);
Network
网络设备、网络栈、端口等
每个 net 命名空间有独立的网络设备、IP地址、路由表、/proc/net目录、端口号等等,这也使得一个host上多个容器内的同一个应用都绑定到各自的80端口上,Docker 默认采用 veth 的方式,将容器中的虚拟网卡同 host 上的一 个Docker 网桥 docker0 连接在一起。
Mount (mnt)
文件系统挂载点
类似 chroot将一个进程放到一个特定的目录执行,与 chroot 不同是每个命名空间中的容器在 /proc/mounts 的信息只包含所在命名空间的 mount point,允许不同命名空间的进程看到的文件结构不同,使得进程间文件目录隔离开来。
基础示例1-mnt:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 mkdir /tmp/mnt_isolation unshare --mount /bin/bash mount -t tmpfs tmpfs /tmp/mnt_isolation cd /tmp/mnt_isolation && touch linux-mnt-{1..10}[root@localhost mnt_isolation]$ ls linux-mnt-1 linux-mnt-2 linux-mnt-4 linux-mnt-6 linux-mnt-8 linux-mnt-10 linux-mnt-3 linux-mnt-5 linux-mnt-7 linux-mnt-9 [root@localhost mnt_isolation]$ ls /tmp/mnt_isolation/
基础示例2-ipc:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 $ ipcmk --queue 消息队列 id:0 $ ipcs $echo $$78285 $unshare --ipc /bin/bash $echo $$ 78468 $ps aux | grep -E "78468|78285" root 78285 0.0 0.1 117460 3980 pts/1 Ss 00:01 0:00 -bash root 78468 0.0 0.1 117408 3956 pts/1 S 00:04 0:00 /bin/bash ipcs
2.控制组 描述:控制组(Control Group)是 Linux 内核(2.6.24)的一个特性也是容器机制的另外一个关键组件,主要用来对共享资源(内存、CPU、磁盘 IO 等资源)进行隔离、限制、审计等(用于资源控制)。Cgroup子系统或控制器,它可以控制内存的Memory控制器、控制进程调度的CPU控制器并且运行中的内核可以使用Cgroup子系统利用/proc/cgroup来管理;
实现原理:将一组进程放在一个控制组里,通过给这个控制组分配指定的可用资源,达到控制这一组进程可用资源的目的。所以只有能控制分配到容器的资源,才能避免当多个容器同时运行时的对系统资源的竞争。Cgroup Driver: cgroupfs 或者 systemd Cgroup Driver: systemd;
发展历史:
在Cgroup出现之前,只能针对一个进程做一些资源的控制,例如通过shed_setaffinity系统调用限定一个进程的CPU亲和性,或者用ulimit限制一个进程的文件上限、限大小等;
在Cgroup出现之后,可以对进程进行人员的分组这是用户自定义的,例如安卓的应用分为前台与后台应用;
注意:不同内核版本Cgroup中实现的子系统有些许不同,当用docker run启动一个容器的时候创建一个独立的名称空间和控制组集合;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 grep cgroup /proc/mounts | awk -F " " '{print $2 " = " $4}' /sys/fs/cgroup = ro,seclabel,nosuid,nodev,noexec,mode=755 /sys/fs/cgroup/systemd = rw,seclabel,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd /sys/fs/cgroup/freezer = rw,seclabel,nosuid,nodev,noexec,relatime,freezer /sys/fs/cgroup/net_cls,net_prio = rw,seclabel,nosuid,nodev,noexec,relatime,net_prio,net_cls /sys/fs/cgroup/cpu,cpuacct = rw,seclabel,nosuid,nodev,noexec,relatime,cpuacct,cpu /sys/fs/cgroup/cpuset = rw,seclabel,nosuid,nodev,noexec,relatime,cpuset /sys/fs/cgroup/perf_event = rw,seclabel,nosuid,nodev,noexec,relatime,perf_event /sys/fs/cgroup/hugetlb = rw,seclabel,nosuid,nodev,noexec,relatime,hugetlb /sys/fs/cgroup/pids = rw,seclabel,nosuid,nodev,noexec,relatime,pids /sys/fs/cgroup/memory = rw,seclabel,nosuid,nodev,noexec,relatime,memory /sys/fs/cgroup/blkio = rw,seclabel,nosuid,nodev,noexec,relatime,blkio /sys/fs/cgroup/devices = rw,seclabel,nosuid,nodev,noexec,relatime,devices grep cgroup /proc/mounts | awk -F " " '{print $2 " = " $4}' /sys/fs/cgroup = ro,nosuid,nodev,noexec,mode=755 /sys/fs/cgroup/systemd = rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd /sys/fs/cgroup/cpu,cpuacct = rw,nosuid,nodev,noexec,relatime,cpu,cpuacct /sys/fs/cgroup/memory = rw,nosuid,nodev,noexec,relatime,memory /sys/fs/cgroup/devices = rw,nosuid,nodev,noexec,relatime,devices /sys/fs/cgroup/blkio = rw,nosuid,nodev,noexec,relatime,blkio /sys/fs/cgroup/net_cls,net_prio = rw,nosuid,nodev,noexec,relatime,net_cls,net_prio /sys/fs/cgroup/freezer = rw,nosuid,nodev,noexec,relatime,freezer /sys/fs/cgroup/rdma = rw,nosuid,nodev,noexec,relatime,rdma /sys/fs/cgroup/hugetlb = rw,nosuid,nodev,noexec,relatime,hugetlb /sys/fs/cgroup/perf_event = rw,nosuid,nodev,noexec,relatime,perf_event /sys/fs/cgroup/cpuset = rw,nosuid,nodev,noexec,relatime,cpuset /sys/fs/cgroup/pids = rw,nosuid,nodev,noexec,relatime,pids
由上面可知cgroups分为多个子系统,每个系统代表一种设施或者说是资源控制器,用来调度某一类的资源使用(cpu,内存,块设备),在实现上cgroups并没有增加新的系统调用,而是表现为一个cgroup文件系统,可以把一个或者多个子系统挂载到某一个目录之中;1 2 3 4 5 mount -t cgroup -o cpu cpu /sys/fs/cgroup/cpu cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
基础实例:1 2 3 4 5 6 7 8 9 10 11 12 13 docker run -itd --cpus="1.5" --cpuset-cpus="0-1" --cpuset-mems="0" busybox sleep 6000 docker run -itd --memory 512m --memory-swap 1g busybox sleep 6000 docker run -itd --name=demo --device=/dev/sda3 busybox sleep 6000 docker exec -it demo ls /dev/sda3 docker run -itd calico/cni -c 512 --cpuset-cpus="0" docker run -itd busybox -c 1024 --cpuset-cpus="1,2" docker run -itd calico/cni --memory 512m --memory-swap 1g --cpu-period=1000000 --cpu-quota=950000 docker run -itd calico/cni --memory 512m --memory-swap 1g --cpu-rt-runtime 950000
子系统之Devices 描述:其作用于控制Cgroup的进程对那些设备具有访问的权限;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 cat /sys/fs/cgroup/devices/devices.list cat /sys/fs/cgroup/devices/docker/devices.list ls -l /sys/fs/cgroup/devices/devices.allow --w-------. 1 root root 0 6月 15 09:46 /sys/fs/cgroup/devices/devices.allow ls -l /sys/fs/cgroup/devices/devices.deny --w-------. 1 root root 0 6月 15 09:46 /sys/fs/cgroup/devices/devices.deny $docker ps25d2d645bfc9 test1 "top -b -d 2" 2 weeks ago cat /sys/fs/cgroup/devices/docker/25d2d645bfc9e6530039d6aac890f69dd9af33f8f966adc2d7287b74964678e3/devices.list c 1:5 rwm c 1:3 rwm c 1:9 rwm c 1:8 rwm c 5:0 rwm c 5:1 rwm c *:* m b *:* m c 1:7 rwm c 136:* rwm c 5:2 rwm c 10:200 rwm mkdir /sys/fs/cgroup/devices/testgroup ls /sys/fs/cgroup/devices/testgroup cat devices.list echo 'c 1:3 rwm' > /sys/fs/cgroup/devices/testgroup/devices.deny echo $$ > /sys/fs/cgroup/devices/testgroup/tasks echo "hello world" > /dev/null cat /sys/fs/cgroup/devices/testgroup/tasks echo $BASHPID
(1) devices.list: 只读文件下载当前允许被访问的设备列表(每个条母有三个域)
类型: a(所有设备),b(块设备),c(字符设备)
设备号: 格式为major:minor设备号
权限: r w m(创建设备节点mknod)
(2) devices.allow:只写文件不能读取,允许指定的设备访问权限;
(3) devices.deny: 与上周作用相反,禁止指定设备的访问权限;
子系统之cpuset 描述:其作用于分配指定的CPU和内存节点以此来限定进程可以使用的cpu核心和内存节点,现广泛用于KVM场景之中;
基础实例:1 2 3 4 5 6 7 8 9 10 11 mkdir /sys/fs/cgroup/cpuset/testgroup echo 0 > /sys/fs/cgroup/cpuset/testgroup/cpuset.memsecho 0,1 > /sys/fs/cgroup/cpuset/testgroup/cpuset.cpusecho $$ > /sys/fs/cgroup/cpuset/testgroup/taskscat /proc/$$/status | grep "_allowed_list" Cpus_allowed_list: 0-1 Mems_allowed_list: 0
子系统之cpu 描述:其作用是限制每个进程能够占用CPU多长时间进行设置;比如在机器上运行多个可能会消耗大量的系统资源的进程时候,我们不希望出现某个程序占据所有的系统资源而导致其它程序进程无法执行,从而导致程序假死的状态,此时使用cgroup对CPU的获取量便可以有效的进行控制;
常用的调度程序:
(1) 完全公平调度 Completely Fair Scheduler (CFS): 按照比例分配调度程序,可以根据任务优先级/权重或者cgroup获得份额,在任务群组(cgroup)间按比例分配CPU时间(cpu带宽)
(2) 实时调度 Real-Time Scheduler (RT):任务调度程序,可以对实时任务使用CPU的时间进行限定
cpu子系统接口一览:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 - cpu.shares: 资源组的CPU使用权重它不限制进程使用绝对的CPU而是控制各组之间的配额,默认情况下Docker容器中cpu shares权重都为1024; echo 512 > /sys/fs/cgroup/cpu/testgroup/cpu.sharesecho 1024 > /sys/fs/cgroup/cpu/testgroup1/cpu.shares- cpu.cfs_period_us: 完全公平调度策略,用于统计CPU使用的时间周期(时间片份数)它可以设定重新分配cgroup的可用CPU资源的时间间隔,单位为微秒us(值范围:1000us~1s); - cpu.cfs_quota_us: 完全公平调度策略,用于某周期内占用CPU的时间(指单核的时间,多核着需要设置时累加),此参数设定基于时间片份数某个cgroup中所有任务可运行的时间总量,单位为微秒us(默认值为-1); 简单来说:在CFS调度下period设置为1s并且quota设置为0.5s,那么在cgroup进程中最多可以运行0.5s然后被强制休眠只能等待下一秒才能继续运行; echo 1000000 > /sys/fs/cgroup/cpu/testgroup/cpu.cfs_period_usecho 1000000 > /sys/fs/cgroup/cpu/testgroup/cpu.cfs_quota_us- cpu.rt_period_us: 实时调度策略,设置某个时间段中每隔多久cgroup对CPU资源的存储就要重新分配,单位为微秒(注意:只可以用于实时调度的程序) - cpu.rt_runtime_us: 实时调度策略,设置某个时间段内cgroup中任务对CPU资源的最长连续访问时间,单位为微秒(注意:只可以用于实时调度的程序) sysctl -a | grep "sched_rt" kernel.sched_rt_period_us = 1000000 kernel.sched_rt_runtime_us = 950000
FAQ补充:
子系统之cpuacct 描述:CPU统计(CPU accounting)子系统会自动生成报告来显示cgroup任务所使用的cpu资源,其中包括子群组任务:1 2 3 4 5 6 7 8 9 10 ls /sys/fs/cgroup/cpu,cpuacct | grep "cpuacct" cpuacct.stat cpuacct.usage cpuacct.usage_percpu
子系统之memory 描述:其作用是用来限制Cgroup组所能使用的内存,主要接口:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ls /sys/fs/cgroup/memory | grep "memory." memory.kmem.limit_in_bytes memory.memsw.limit_in_bytes memory.stat memory.oom_control memory.swappiness memory.failcnt memory.force_empty memory.kmem.failcnt memory.kmem.max_usage_in_bytes memory.kmem.slabinfo memory.kmem.tcp.failcnt memory.kmem.tcp.limit_in_bytes memory.kmem.tcp.max_usage_in_bytes memory.kmem.tcp.usage_in_bytes memory.kmem.usage_in_bytes memory.limit_in_bytes memory.max_usage_in_bytes memory.memsw.failcnt memory.memsw.max_usage_in_bytes memory.memsw.usage_in_bytes memory.move_charge_at_immigrate memory.numa_stat memory.pressure_level memory.soft_limit_in_bytes memory.usage_in_bytes memory.use_hierarchy
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 mkdir /sys/fs/cgroup/memory/testcagroup echo 100M > /sys/fs/cgroup/memory/testcagroup/memory.limit_in_bytesecho 200M > /sys/fs/cgroup/memory/testcagroup/memory.memsw.limit_in_bytescat /sys/fs/cgroup/memory/testcagroup/memory.oom_control oom_kill_disable 1 under_oom 0 $echo $$ > /sys/fs/cgroup/memory/testcagroup/tasks$cat memory.statcache 0 rss 225280 rss_huge 0 mapped_file 0 swap 0 pgpgin 108 pgpgout 53 pgfault 584 pgmajfault 0 inactive_anon 0 active_anon 200704 inactive_file 0 active_file 0 unevictable 0 hierarchical_memory_limit 104857600 hierarchical_memsw_limit 209715200 total_cache 0 total_rss 225280 total_rss_huge 0 total_mapped_file 0 total_swap 0 total_pgpgin 108 total_pgpgout 53 total_pgfault 584 total_pgmajfault 0 total_inactive_anon 0 total_active_anon 200704 total_inactive_file 0 total_active_file 0 total_unevictable 0
子系统之blkio(块 I/O) 描述:其子系统可以控制并监控cgroup中任务对块设备I/O存取,对一些伪文件写入值可以限制存取次数或者带宽,从伪文件中读取值可以获得关于I/O操作系统信息。
块 I/O blkio子系统给出两种方式来控制对I/O的存取:
权重分配: 用于完全公平列队I/O调度程序(Completely Fair Queuing I/O Sheduler), 用此方法可以给指定的cgroup设置权重;意味着每个cgroup都有一个预留的I/O操作设定比例(即权重)
I/O 节流上限: 当一个指定设备执行I/O操作时,用此方法可为其操作次数设定上限;意味着一个设备的读或者写的操作次数是可以限定的;
基本示例:1 2 3 4 5 6 7 8 9 10 11 12 cat /sys/fs/cgroup/blkio/blkio.weight 1000 mkdir/sys/fs/cgroup/blkio/mygroup{1,2} echo 500 > /sys/fs/cgroup/blkio/mygroup1/blkio.weightecho 100 > /sys/fs/cgroup/blkio/mygroup2/blkio.weightcgexec -g "blkio:mygroup1" dd bs=1M count=4096 if =file1 of=/dev/null cgexec -g "blkio:mygroup2" dd bs=1M count=4096 if =file1 of=/dev/null
3.Union 文件系统 联合文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统也是 Docker 镜像的基础,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
Docker 目前支持的联合文件系统包括 OverlayFS, AUFS, Btrfs, VFS, ZFS 和 Device Mapper,在可能的情况下,推荐使用 overlay2 存储驱动它是目前 Docker 默认的存储驱动;
使用的好处:
Docker 中使用的 AUFS(AnotherUnionFS)就是一种联合文件系统。
AUFS 支持为每一个成员目录(类似 Git 的分支)设定只读(readonly)、读写(readwrite)和写出(whiteout-able)权限,
同时 AUFS 里有一个类似分层的概念, 对只读权限的分支可以逻辑上进行增量地修改(不影响只读部分的)。
4.容器格式 最初,Docker 采用了 LXC 中的容器格式。
Docker 与 LXC(Linux Container)有何不同?
移植性:通过抽象容器配置,容器可以实现从一个平台移植到另一个平台;
镜像系统:基于 AUFS 的镜像系统为容器的分发带来了很多的便利,同时共同的镜像层只需要存储一份,实现高效率的存储;
版本管理:类似于Git的版本管理理念,用户可以更方便的创建、管理镜像文件;
仓库系统:仓库系统大大降低了镜像的分发和管理的成本;
周边工具:各种现有工具(配置管理、云平台)对 Docker 的支持,以及基于 Docker的 PaaS、CI 等系统,让 Docker 的应用更加方便和多样化。
Docker 与 Vagrant 有何不同?
Vagrant 类似 Boot2Docker(一款运行 Docker 的最小内核),是一套虚拟机的管理环境。Vagrant 可以在多种系统上和虚拟机软件中运行,可以在 Windows,Mac 等非 Linux 平台上为 Docker 提供支持,自身具有较好的包装性和移植性。
原生的 Docker 自身只能运行在 Linux 平台上,但启动和运行的性能都比虚拟机要快,往往更适合快速开发和部署应用的场景。
简单说:
Docker 不是虚拟机,而是进程隔离,对于资源的消耗很少,但是目前需要 Linux 环境支持。
Vagrant 是虚拟机上做的封装,虚拟机本身会消耗资源。
一句话:Vagrant 适合用来管理虚拟机,而 Docker 适合用来管理应用环境。
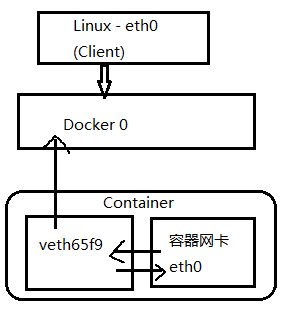
5.网络实现 描述:Docker 的网络实现其实就是利用了 Linux 上的网络命名空间和虚拟网络设备veth(Vritual Enternet Device),veth主要的目的是为了跨NetWork Namespace之间提供一种类似于Linux进程间通信技术,所以veth总数成对出现进行通信其工作在L2数据链路层,比如veth0与veth1他们分别在不同的Network Namespace,其中一端Veth设备任意一端上RX到的数据都会在另外一端上以Tx的方式发送出去;
前面我们说过Linux下的Docker容器网络通过Network Namespace机制(/proc/net, IP地址, 网卡, 路由)实现隔离网络资源,不同的Network Namespace有各自的网络设备,协议栈,路由器以及防火墙,同一个Namepsace下的进程共享同一个网络视图;所以veth-pair设备接口它在本地主机和容器内分别创建一个虚拟接口(即:在不同的网络命名空间中创建通道),并让它们彼此连通实现网络通信,该设备在转发数据包过程中并不篡改数据包内容;
基本原理: Docker 中的网络接口默认都是虚拟的接口), 然后Linux 通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包被直接复制到接收接口的接收缓存中,并且对于本地系统和容器内系统看来就像是一个正常的以太网卡,只是它不需要真正同外部网络设备通信,所以速度要快很多则转发效率较高;此外如果不同子网之间要进行通信,还需要路由机制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 yum install -y bridge-utils $brctl show$ip addr | grep "BROADCAST"
当通过docker run创建一个容器的时候便有了单独的网络命名空间,容器网络初始化流程:
1.创建一对虚拟接口,分别放到本地主机和新容器中;
2.本地主机一端桥接到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 veth985cbf0@if56;
3.容器一端放到新容器中,并修改名字作为 eth0,这个接口只在容器的命名空间可见;
4.从网桥可用地址段中获取一个空闲地址分配给容器的 eth0@if57 网卡名称@虚拟接口序号,并配置默认路由到桥接网卡 veth985cbf0@if56(57)1 2 3 4 5 6 7 8 9 10 11 12 13 ens192|eth0 <-> docker0 <-> veth985cbf0@56(虚拟网卡) <-> eth0@if57(容器内部)网卡 docker exec -it test1 sh -c ip addr
weiyigeek.top-虚拟接口原理图
Docker 中网络提供了五种模式:
Bridge 模式
Host 模式
Container 模式(即:指定容器之间通信的网络)
None 模式
Overtlay
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 docker network ls docker network inspect $(docker network ls -q)
Tips:
(1)通过 –net 参数来指定容器的网络配置,有4个可选值:1 2 3 4 5 6 7 --net=bridge 这个是默认值,连接到默认的网桥。 --net=host 告诉Docker不要将容器网络放到隔离的命名空间中,即不要容器化容器内的网络 - 此时容器使用本地主机的网络,它拥有完全的本地主机接口访问权(不安全), - 如果进一步的使用 --privileged=true ,容器会被允许直接配置主机的网络堆栈。 --net=container:NAME_or_ID 让Docker将新建容器的进程放到一个已存在容器的网络栈中,新容器进程有自己的文件系统、进程列表和资源限制,但会和已存在的容器共享 IP 地址和端口等网络资源,两者进程可以直接通过 lo 环回接口通信。 --net=none 让 Docker 将新容器放到隔离的网络栈中,但是不进行网络配置。之后用户可以自己进行配置。 - 用户可以使用 ip netns exec 命令来在指定网络命名空间中进行配置,从而配置容器内的网络。
Bridge 模式 描述: 该模式是Docker默认的一种网络通讯模式;
Bridge 网络模式原理:
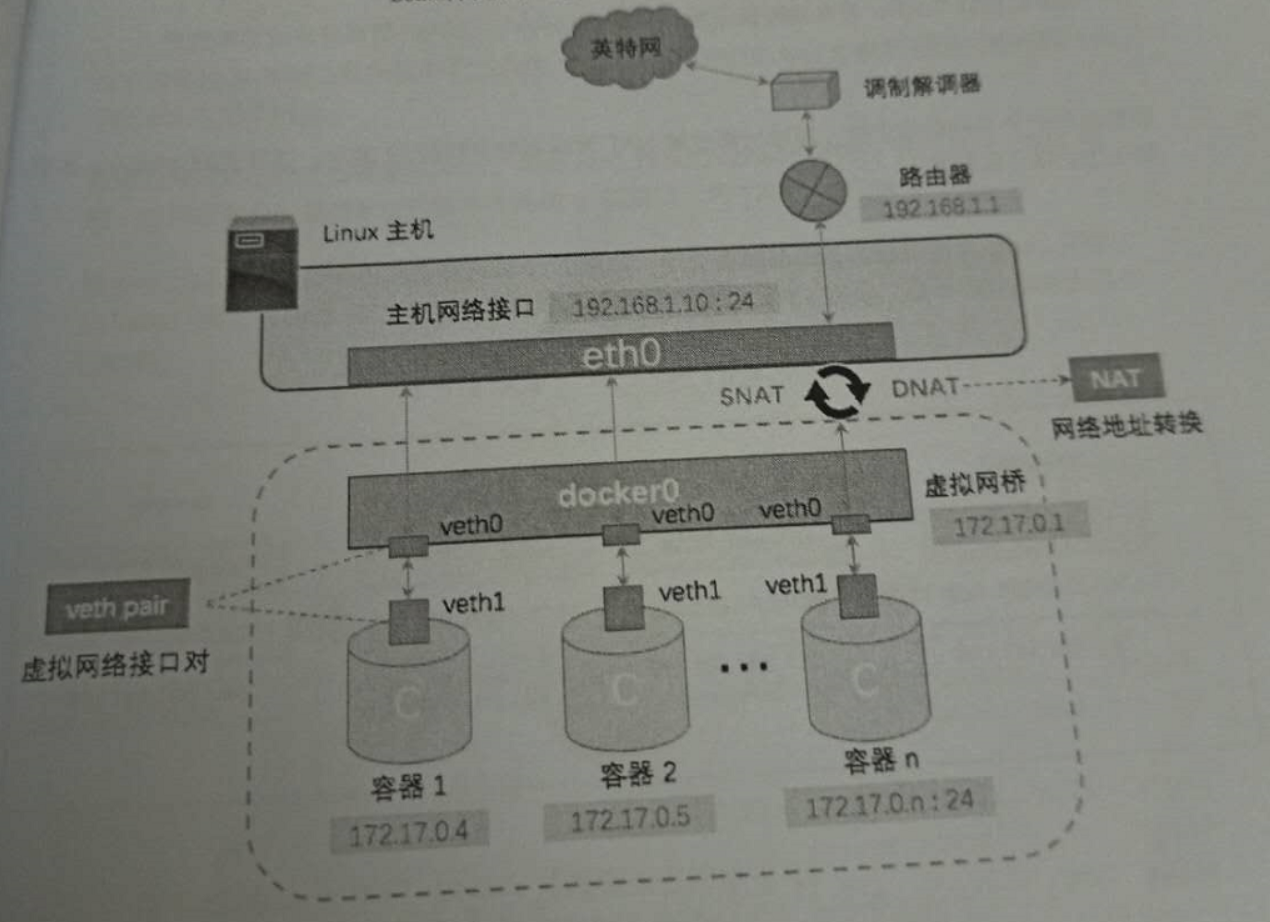
答:Docker Daemon 首次启动时候,会在其所在的宿主机上创建一个名为Docker0的虚拟网桥,然后利用veth pair技术创建一对虚拟网络接口分别接入到Docker0网桥中和相关容器的Network Namespace之中,即Docker0 <-> veth pair <-> Container[Namespace];
网络图示:1 2 3 4 5 6 7 8 9 10 11 ---------- ---------- |Container| |Container| |eth0@if57| |eth0@if70| ---------- ---------- | | ------------------------------------ veth985cbf0@if56 veth842b243@if69 | docker0 (bridge) | ------------------------------------ | ipv4_ip_forward (iptales) (eth0|ens192)
基础实例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 $docker exec -it test1 ip addr56: eth0@if57: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever $iptables -t nat -L Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL Chain INPUT (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination DOCKER all -- anywhere !loopback/8 ADDRTYPE match dst-type LOCAL Chain POSTROUTING (policy ACCEPT) target prot opt source destination MASQUERADE all -- 172.18.0.0/16 anywhere MASQUERADE tcp -- 172.18.0.2 172.18.0.2 tcp dpt(destination port):http Chain DOCKER (2 references) target prot opt source destination RETURN all -- anywhere anywhere RETURN all -- anywhere anywhere DNAT tcp -- anywhere anywhere tcp dpt:tproxy to:172.18.0.2:80 127.0.0.1:80 -> NAT PREROUTING -> 172.18.0.2:80 -> FILTER FORWARD -> ACCEPT -> NAT POSTROUTING
Bridge网络中容器与宿主机通信示意图:
weiyigeek.top-容器宿主机
总结说明:
1) Veth-Pair技术在宿主机Docker0网桥上与容器的所属的网络命名空间(Network Namespace)上分别创建一个虚拟网络接口即veth985cbf0@if56 <---> eth0@if57,它保证了无论哪一个接口接收到网络报文,都会无条件的转发到另外一方之上;
2) 默认情况下容器可以访问外部网络(一般都会添加本地系统转发支持)采用是NATP(网络地址端口转换)的方式其包含两种转换方式SNAT(源地址) 和 DNAT(目的地址),容器连接外网是通过源NAT地址转换实现的,但是外部网络却无法访问到容器它也需要通过目的NAT转换(数据包的目的地址)才能与容器进行通信;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $sysctl -a | grep "ip_forward" net.ipv4.ip_forward = 1 sysctl -w net.ipv4.ip_forward = 1 dockerd -h | grep "ip_forward" --ip-forward Enable net.ipv4.ip_forward (default true ) |------------------------------------------------| 数据包(外界) -> Eth0 <-<- DNAT ->-> Docker0 —> veth985cbf0@if56 -> eth0@if57(容器内部) | 宿主机 | |------------------------------------------------| 数据包[eth0@if57](容器) -> veth985cbf0@if56 -> Docker0 <-<- SNAT ->-> Eth0 -> 外界网络 |--------------------宿主机------------------------|
Host 模式 描述:该网络模式与Bridge桥接的网络模式存在一定的差异,最大差异是没有为容器创建一个隔离的网络环境, 并且因为该host网络模式下的Docker容器与宿主机共享一个网络命名空间(namepace),拥有相同的网络设施并且容器的IP即为宿主机IP能直接与外界进行通信;
1 [Docker Container](host 模式) -> 宿主机 (eth0) -> 外界网络
Host网络模式优缺点:
1)优点: 效率高(直接采用宿主机IP与外界通信不经过NATP转换)、端口公用(容器可直接使用宿主机端口)
2)缺点: 安全性差(容器不在拥有隔离的和独立的网络栈)、端口限制(宿主机占用或者Bridge网络模式主机占用的端口不能被使用,即不在拥有容器中全部端口)
基础实例:1 2 3 4 5 6 7 8 docker run -it --net=host busybox ip addr
Container 模式 描述: 该模式通常用于自定义网络栈时候使用,它会重用另外一个容器的网络命名空间(例如Bridge);比如Kubernetes也是使用该模式进行内部分布式应用通信;
Container 网络模式示意图:1 2 3 4 5 6 7 Docker Container <-> Docker Container | eth0@if57 | ----------------- | Docker0 (Bridge) <-> [veth985cbf0@if56] | (ipv4.ip_forward) eth0
基础实例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 docker run -d -P --net=bridge --name nginx nginx:latest docker inspect nginx | grep "IPAddress" docker inspect nginx | grep "IPAddress" "SecondaryIPAddresses" : null,"IPAddress" : "172.17.0.3" ,docker run -d --name busybox --net=container:nginx busybox:latest top $docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 13d274350a28 busybox:latest "top" 3 seconds ago Up 2 seconds busybox 04074e2e85b4 nginx:latest "/docker-entrypoint.…" 4 minutes ago Up 3 minutes 0.0.0.0:32768->80/tcp nginx $docker exec -it busybox ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 72: eth0@if73: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever
none 模式 描述: 该模式不为Docker容器提供任何的网络环境可以说该模式只是对容器做了极少的设定,一旦设置none网络模式容器内部就只能使用loopback设备,不会再有其它的网络资源环境;
该模式下方便docker开发者基于此做出其他可能的网络定制开发, 实际上该模式关闭了容器的网络功能,应用场景如下;
容器并不需要网络(例如只需要写磁盘卷的批处理任务)
希望自定义网络
基础实例:1 2 3 4 5 docker run -itd --net=none --name=busybox-none busybox top docker exec -it busybox-none ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
Overlay 模式 描述:Overlay模式是Docker原生的跨主机网络方案(其他一些方案:Flannel/Weave和Calico K8s已默认使用),而Docker 又通过Libnetwork以及CNM将上述各种方案与docker集成在一起;
Q: 什么是Libnetwork库?
答: 他是Docker容器的网络库,其核心内容是其定义的Container Network Model (CNM)容器网络模型 他对容器网络进行了抽象;
1 2 3 | -> Native Drivers(None, Bridge, Overlay, Macvlan) Docker -> Libnetwork | -> | -> Remote Drivers(Flannel, Weave, Calico)
CNM 由以下三类组件组成:
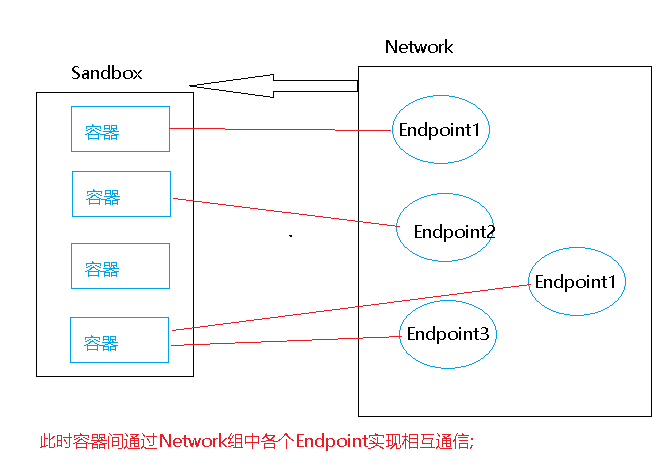
Sandbox: Linux Network Namespace 是基于 Sandbox的标准实现,它是容器的网络栈其囊括Interface, 路由器 和 DNS 设置,也就是说Sandbox将一个容器与另外容器通过Namespace进行隔离,一个容器包含一个Sandbox,它可以包含来自不同的Network的Endpoint,即每个Sandbox可以有多个Endpoint隶属于不同的网络;
Endpoint: 将Sandbox接入到Network之中,一个Endpoint只能属于一个网络与一个Sandbox,例如 Veth-pair 的实现;
Network: 包含一组Endpoint,同一个Network的Endpoint可以直接通信,其实现可以是Linux bridge vlan等
weiyigeek.top-CNM
总结:
(1) Sandbox 与 Endpoint 是一对多的关系,Endpoint将Sandbox绑定到Network之中,并且同一个Network间的Endpoint可以直接通信;
Overlay网络原理
基础实践:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 docker run -d -p 8500:8500 -h consul --name consul-net-overlay progrium/consul -server -bootstrap**docker run -d -p 8500:8500 -h consul --name consul-net-overlay progrium/consul -server -bootstrap --cluster-store=consul://10.10.107.245:8500 --cluster-advertise=ens192:2376 $ systemctl cat docker [root@worker-03 ~]$ systemctl daemon-reload [root@worker-03 ~]$ systemctl restart docker docker network create -d overlay overlay-net docker network create -d overlay overlay-net-sub --subnet 172.25.0.0/24 --gateway 172.25.0.1 docker run --network overlay-net busybox sleep 6000 docker run --network overlay-net busybox sleep 6000 $docker ps$docker network lsNETWORK ID NAME DRIVER SCOPE 5de5f196afda bridge bridge local 23d95a1bd969 docker_gwbridge bridge local 3a700c6af892 host host local 93a5b381ef0d none null local e437f4650c96 overlay-net overlay global $docker network inspect docker_gwbridge -f "{{.IPAM.Config}}" $docker network inspect overlay-net -f "{{.IPAM.Config}}" [root@worker-03 ~]$docker exec -it 090 ip addr 22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue link/ether 02:42:0a:00:00:02 brd ff:ff:ff:ff:ff:ff inet 10.0.0.2/24 brd 10.0.0.255 scope global eth0 valid_lft forever preferred_lft forever 25: eth1@if26: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff inet 172.18.0.2/16 brd 172.18.255.255 scope global eth1 valid_lft forever preferred_lft forever [root@worker-03 ~]$docker exec -it 430 ip addr 27: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue link/ether 02:42:0a:00:00:03 brd ff:ff:ff:ff:ff:ff inet 10.0.0.3/24 brd 10.0.0.255 scope global eth0 valid_lft forever preferred_lft forever 29: eth1@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff inet 172.18.0.3/16 brd 172.18.255.255 scope global eth1 valid_lft forever preferred_lft forever [root@worker-03 ~]$docker exec -it 090 sh / / PING 10.0.0.1 (10.0.0.1): 56 data bytes 64 bytes from 10.0.0.1: seq=0 ttl=64 time=0.540 ms / PING 10.0.0.2 (10.0.0.2): 56 data bytes 64 bytes from 10.0.0.2: seq=0 ttl=64 time=0.055 ms / PING 10.0.0.3 (10.0.0.3): 56 data bytes 64 bytes from 10.0.0.3: seq=0 ttl=64 time=0.110 ms
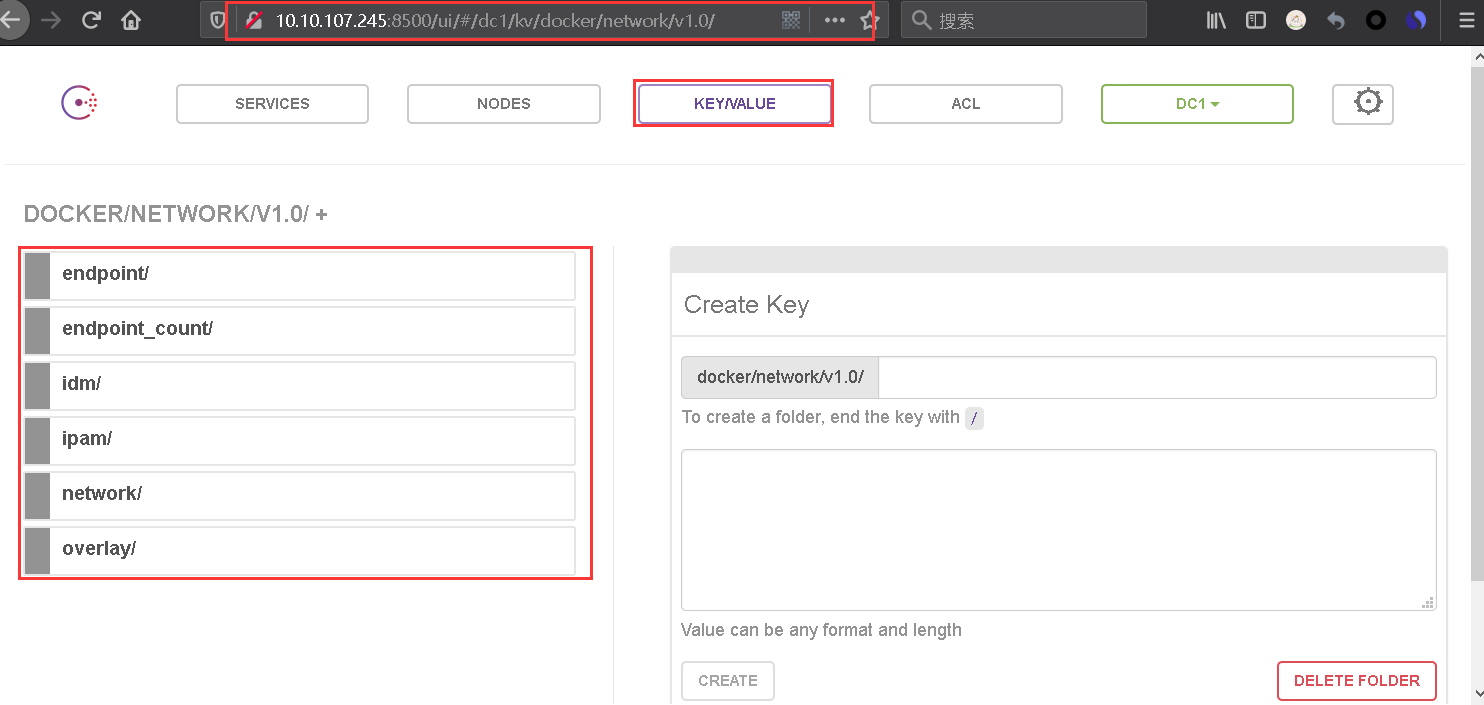
http://10.10.107.245:8500/ui/#/dc1/kv/docker/network/v1.0/
weiyigeek.top-Consul-docker-kv-network
总结: yum install -y bridge-utils && brctl show 进行查看得出结果, 当每创建一个网络类型为Overlay的容器,docker_gwbridge 下便会挂载一个veth***,这说明oveylay容器是通过此网桥来进行对外连接的;1 2 3 4 bridge name bridge id STP enabled interfaces docker0 8000.024274c0c574 no docker_gwbridge 8000.02422e73bb62 no vethae1f217 vethec87cb3
简单的说overlay网络数据还是从Bridge网络docker_gwbridge网桥出去的,由于Consul的作用记录leoverlay网络的CNM三大组件的信息,使得其它主机docker知道此网络类型为oveylay,并且可以在该网络下不同主机之间进行相互的通信访问,但是实际上出口还是Docker_gwbridge;
6.存储驱动 描述:Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享同一个image;Docker支持的存储驱动类型有overlay2、AUFS、Btrfs、Device mapper、OverlayFS、ZFS五种存储驱动,所有驱动都用到写时复制(CoW)的技术。
[2020年6月19日] - 目前最新版本的 docker 默认优先采用 overlay2 的存储驱动,对于已支持该驱动的 Linux 发行版,不需要任何进行任何额外的配置。devicemapper 存储驱动已经在 docker 18.09 版本中被废弃,docker 官方推荐使用 overlay2 替代devicemapper。1 2 3 docker info Server Version: 19.03.3 Storage Driver: overlay2
写时复制(CoW)什么是写时复制?
所以无论有多少个容器共享同一个image,所做的写操作都是对从image中复制到自己的文件系统中的复本上进行,并不会修改image的源文件,且多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响。使用CoW可以有效的提高磁盘的利用率。
用时分配(allocate-on-demand)
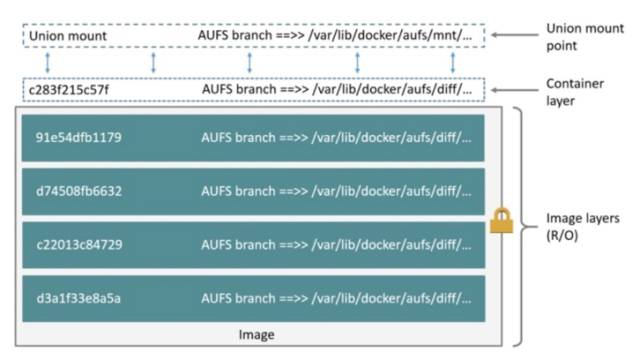
AUFS 什么是AUFS?
weiyigeek.top-AUFS
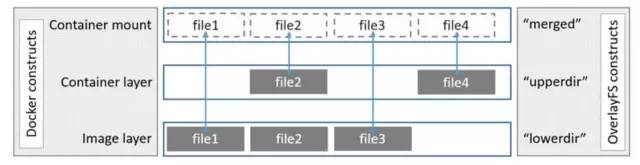
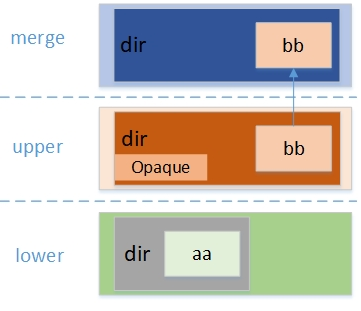
Overlay - 当前docker默认的存储驱动 描述:Overlay是Linux内核3.18后支持的,它也是一种UnionFS与AUFS不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的镜像层和容器层。
同样在Docker中底下的只读层就是image,可写层就是Container;
weiyigeek.top-Overlay
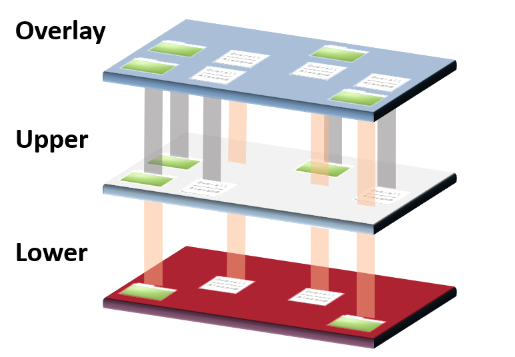
下图展示了overlayFS的两个特征:上下合并、同名遮盖
weiyigeek.top-overlay-Upper-Lower
采用一个挂载OverlayFS小例子深入理解其存储驱动:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 比如lower1下面common.txt内容是lower1,lower2下面common.txt内容是lower2,lower3下面common.txt内容是lower3,upper目录有个和lower2/ower2.sh同名的目录 $tree -L 2├── lower1 │ ├── common.txt │ └── ower1.sh ├── lower2 │ ├── common.txt │ └── ower2.sh ├── lower3 │ ├── common.txt │ └── ower3.sh ├── merged ├── upper │ ├── ower2.sh │ └── up.txt └── work └── work * lowerdir: 代表lower层,可以有多个,优先级依次降低,也就是说`lower1 > lower2 > lower3` * upperdir: 代表upper层,会覆盖lower层 * workdir: 工作目录,用于存放临时文件 * merged: 挂载点,我们看看操作之后的目录 $mount -t overlay overlay -o lowerdir=lower1:lower2:lower3,upperdir=upper,workdir=work merged├── lower1 │ ├── common.txt │ └── ower1.sh ├── lower2 │ ├── common.txt │ └── ower2.sh ├── lower3 │ ├── common.txt │ └── ower3.sh ├── merged │ ├── common.txt │ ├── ower1.sh │ ├── ower2.sh │ ├── ower3.sh │ └── up.txt ├── upper │ ├── ower2.sh │ └── up.txt └── work └── work
正如前面介绍的COW(写时复制)在overlayFS中也是只对于只读的lower层的操作,当用到它时候会把它复制到upper层然后再对upper的进行操作,我们演示几个对挂载后的目录的操作,就能很明白这个过程了:
1.删除的文件是upper的,并且这个文件在lower层不存在(up.txt) 直接删除就行了
2.删除的文件来自于lower层而upper层没有对应的文件(ower3.sh), overlayFS通过一种叫whiteout的机制它可以用于屏蔽底层的同名文件,在upper层创建一个主次设备号(mknod c 0 0)都是0的设备,当在merge层去找的时候,overlayFS会自动过滤掉和whiteout文件自身以及和他同名的lower层的文件,从而达到隐藏的目的;
3.删除的是upper覆盖lower的文件(ower2.sh) 依然创建一个whiteout文件;
4.创建一个upper和lower都没有的目录 直接在upper中新增一个;
5.创建一个在lower层已经存在且在upper层有whiteout文件的同名文件并删了whiteout文件,重新创建一个;
6.创建一个lower层存在并且upper层已经有对应whiteout文件的目录,如果这个时候单纯的删除whiteout文件,那么lower层对应目录里面的文件就会显示出来。
overlayFS引入了一种Opaque(不透明的)的属性,通过设置upper层上对应的目录上设置"trusted.overlay.opaque"为y来实现(前提是upper所在的文件系统支持xattr属性),overlayFS在读取上下层存在同名目录的时候,如果upper层的目录被设置了Opaque的属性,他会忽这个目录下层的所有同名目录项来保证新建的是个空目录。
weiyigeek.top-Opaque属性
映射器 (Device mapper) - 已经在 docker 18.09 版本中被废弃. 描述:Device mapper是Linux内核2.6.9后支持的,提供的一种从逻辑设备到物理设备的映射框架机制,在该机制下,用户可以很方便的根据自己的需要制定实现存储资源的管理策略;
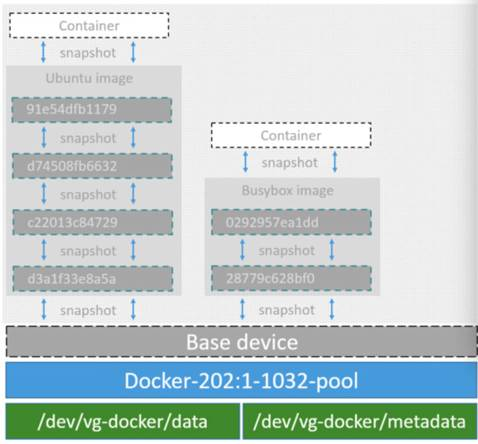
Device mapper驱动会先在块设备上创建一个资源池,然后在资源池上创建一个带有文件系统的基本设备,所有镜像都是这个基本设备的快照,而容器则是镜像的快照。所以在容器里看到文件系统是资源池上基本设备的文件系统的快照,并不有为容器分配空间。当要写入一个新文件时,在容器的镜像内为其分配新的块并写入数据(写时分配)
Device mapper存储驱动默认会创建一个100G的文件包含镜像和容器(其实就是资源存储池)。每一个容器被限制在10G大小的卷内,可以自己配置调整。它会默认会在/var/lib/docker/devicemapper/devicemapper目录下生成data和metadata两个稀疏文件,并将两个文件挂为loop设备作为块设备来使用(默认模式),它使用空闲文件来构建存储池,性能非常低。
注意事项:
1.当要修改已有文件时,再使用CoW为容器快照分配块空间,将要修改的数据复制到在容器快照中新的块里再进行修改,注意挂载后的磁盘UUID变化后则需要手动修改deviceset-metadata来指定BaseDeviceUUID;
weiyigeek.top-
2.在18.09版本之前在Docker初始化时候可以指定--storage-opt dm.loopdatasize=500G --storage-opt dm.loopmetadatasize=4G,将回收环境设备大小设置为500G(数据存储),元数据文件大小为4G(稀疏文件),然后分别附加到回环设备/dev/loop0和/dev/loop1,其次再基于回环块设备创建Thin Pool;
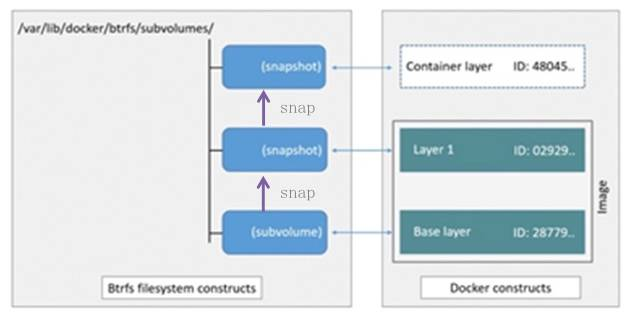
Btrfs 描述:Btrfs被称为下一代写时复制文件系统,并入Linux内核也是文件级级存储,但可以像Device mapper一直接操作底层设备。
Btrfs把文件系统的一部分配置为一个完整的子文件系统,称之为subvolume 。那么采用 subvolume,一个大的文件系统可以被划分为多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配,类似应用程序调用 malloc()分配内存一样。为了灵活利用设备空间,Btrfs 将磁盘空间划分为多个chunk 。每个chunk可以使用不同的磁盘空间分配策略。比如某些chunk只存放metadata,某些chunk只存放数据
模型优点:Btrfs支持动态添加设备,用户在系统中增加新的磁盘之后,可以使用Btrfs的命令将该设备添加到文件系统中。
Btrfs把一个大的文件系统当成一个资源池,配置成多个完整的子文件系统,还可以往资源池里加新的子文件系统,而基础镜像则是子文件系统的快照,每个子镜像和容器都有自己的快照,这些快照则都是subvolume的快照。
当写入一个新文件时,为在容器的快照里为其分配一个新的数据块,文件写在这个空间里,这个叫用时分配
当要修改已有文件时,使用CoW复制分配一个新的原始数据和快照,在这个新分配的空间变更数据,变结束再更新相关的数据结构指向新子文件系统和快照,原来的原始数据和快照没有指针指向,被覆盖。
weiyigeek.top-
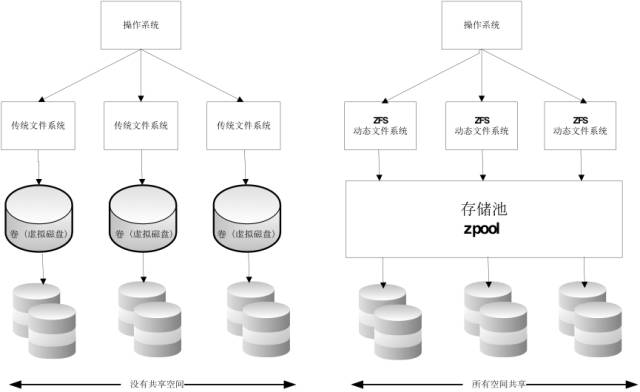
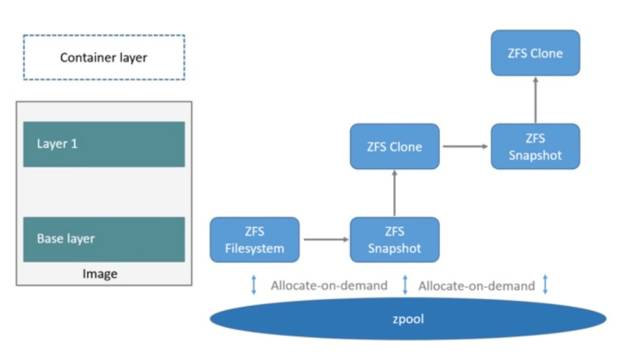
ZFS 描述:ZFS 文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,ZFS 完全抛弃了”卷管理”,不再创建虚拟的卷,而是把所有设备集中到一个存储池中来进行管理,用”存储池”的概念来管理物理存储空间。以前文件系统都是构建在物理设备之上的。为了管理这些物理设备,并为数据提供冗余,”卷管理”的概念提供了一个单设备的映像。而ZFS创建在虚拟的,被称为”zpools”的存储池之上。每个存储池由若干虚拟设备(virtual devices,vdevs)组成。这些虚拟设备可以是原始磁盘,也可能是一个RAID1镜像设备,或是非标准RAID等级的多磁盘组。于是zpool上的文件系统可以使用这些虚拟设备的总存储容量。
当要写一个新文件时使用按需分配,一个新的数据快从zpool里生成,新的数据写入这个块,而这个新空间存于容器(ZFS的克隆)里。
当要修改一个已存在的文件时使用写时复制WoC,分配一个新空间并把原始数据复制到新空间完成修改。
weiyigeek.top-ZFS
首先从zpool里分配一个ZFS文件系统给镜像的基础层,而其他镜像层则是这个ZFS文件系统快照的克隆,快照是只读的,而克隆是可写的,当容器启动时则在镜像的最顶层生成一个可写层。如下图所示:
weiyigeek.top-
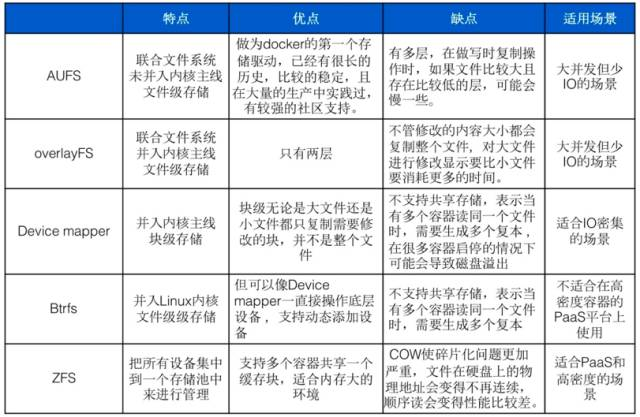
存储驱动的对比及适应场景
AUFS VS Overlay
Overlay VS Device mapper
Device mapper VS Btrfs Driver VS ZFS
weiyigeek.top-
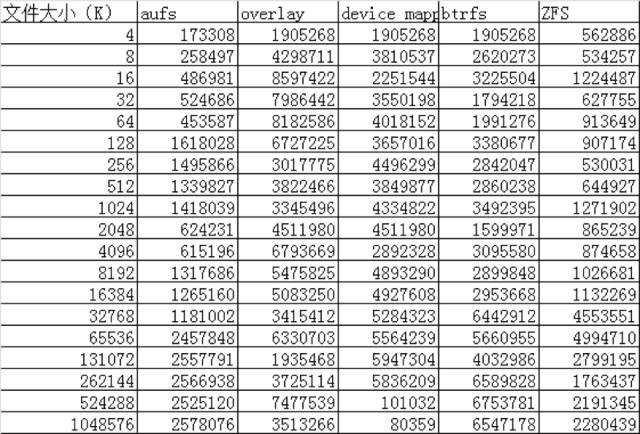
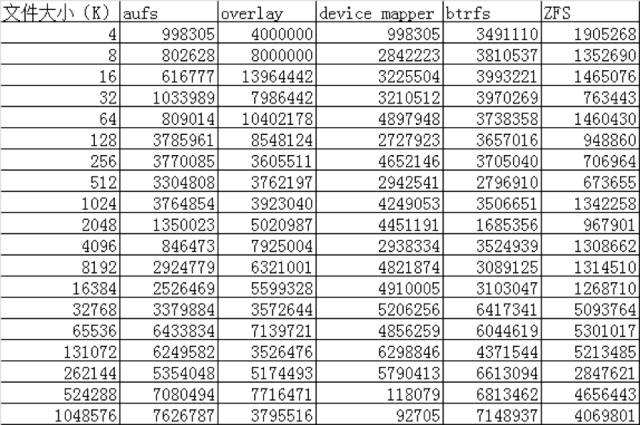
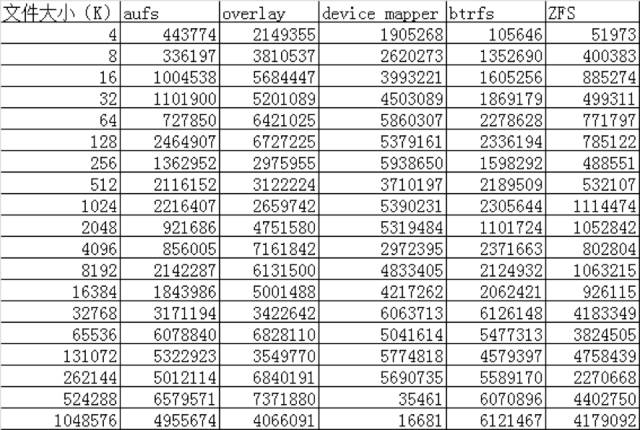
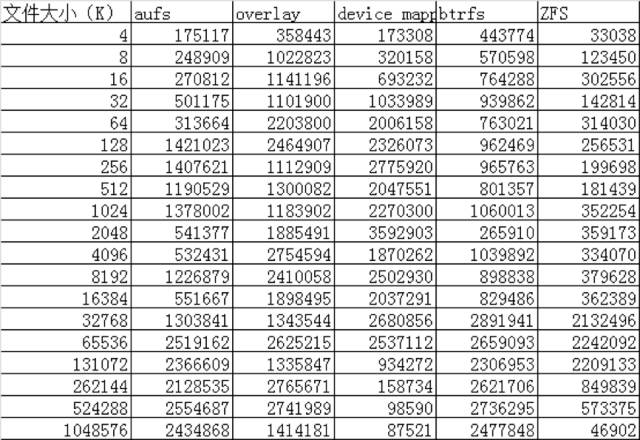
IO性能对比 ./iozone -a -n 4k -g 1g -i 0 -i 1 -i 2 -f /root/test.rar -Rb ./iozone.xls
测试项的定义和解释
Write:测试向一个新文件写入的性能。
Re-write:测试向一个已存在的文件写入的性能。
Read:测试读一个已存在的文件的性能。
Re-Read:测试读一个最近读过的文件的性能。
Random Read:测试读一个文件中的随机偏移量的性能。
Random Write:测试写一个文件中的随机偏移量的性能。
测试数据对比结果:
Write
weiyigeek.top-Write
Re-write
weiyigeek.top-Re-write
Read
weiyigeek.top-Read
Re-Read
weiyigeek.top-Re-Read
Random Read
weiyigeek.top-Random Read
Random Write
weiyigeek.top-Random Write
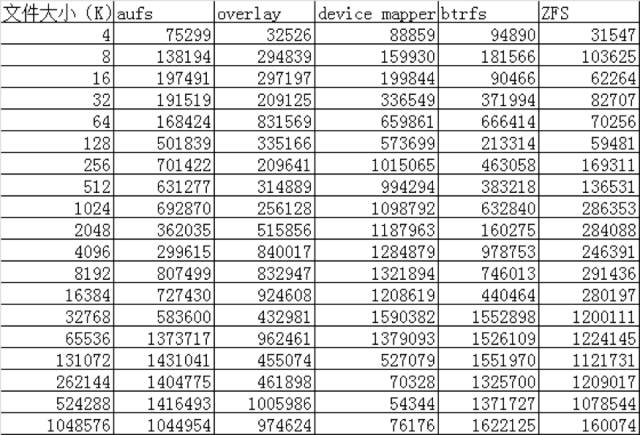
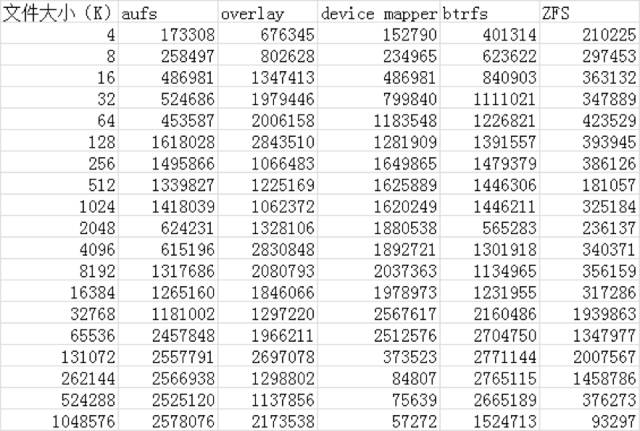
通过以上的性能数据可以看到:
AUFS在读的方面性能相比Overlay要差一些,但在写的方面性能比Overlay要好。
device mapper在512M以上文件的读写性能都非常的差,但在512M以下的文件读写性能都比较好。
btrfs在512M以上的文件读写性能都非常好,但在512M以下的文件读写性能相比其他的存储驱动都比较差。
ZFS整体的读写性能相比其他的存储驱动都要差一些
注意事项:
Centos系统上(默认不支持aufs需要查看AUFS是否加入Linux内核),推荐使用overlayfs存储驱动;
devicemapper默认会在/var/lib/docker/devicemapper/devicemapper目录下生成data和metadata两个稀疏文件,并将两个文件挂为loop设备作为块设备来使用。
Direct和LVM的最大不同是创建DM thin pool的不再是通过losetup挂载的两个稀疏文件,而是两个裸的真正的块设备。由于direct lvm的读写性能表现更加稳定,推荐生产环境上使用direct-lvm模式;
7.数据共享与持久化 描述:Docker 数据卷是被用于共享和持久化数据的,而且它的声明周期是独立于容器的,所以当容器宕掉或者删除并不会导致数据卷中的数据丢失;
Q: 数据卷的实现原理?
Docker 提供的几种数据卷的实现方式:
1.数据卷1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 docker run -itd -v /tmp/container/folder --name data-volume busybox top docker inspect data-volume -f 'Source:{{(index .Mounts 0).Source}}{{println}}Destination:{{(index .Mounts 0).Destination}}' $docker exec -it data-volume sh$ls /tmp/container/folder/ls^Cdocker run -itd -v /tmp/mnt_isolation:/tmp/tar/tmp/container/folder --name data-volume-1 busybox top docker inspect data-volume-1 -f 'Source:{{(index .Mounts 0).Source}}{{println}}Destination:{{(index .Mounts 0).Destination}}'
2.数据卷容器:支持多个容器通过某一个容器进行数据工程,PS:k8s是Pod采用的就是这种共享方式;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 docker run -itd --volumes-from data-volume --name data-volume-2 busybox top docker run -itd --volumes-from data-volume --name data-volume-3 busybox top $docker exec -it data-volume-3 touch /tmp/container/folder/$$.txt$docker exec -it data-volume-3 ls -alh /tmp/container/folder/-rw-r--r-- 1 root root 0 Jul 6 13:50 3758.txt $docker exec -it data-volume-2 ls -alh /tmp/container/folder/-rw-r--r-- 1 root root 0 Jul 6 13:50 3758.txt $docker exec -it data-volume ls -alh /tmp/container/folder/-rw-r--r-- 1 root root 0 Jul 6 13:50 3758.txt $docker stop data-volume data-volume-2 data-volume-3$docker rm -v data-volume data-volume-2 data-volume-3 data-volume
3.数据卷插件-v 源宿主机:目标容器),将卷中保存的数据保存在宿主机上,通过Volume Plugin机制能够很方便的整合第三方存储为Docker提供Volume;
Q: 什么是存储插件?
Q: 存储插件有哪些?常用的有以下几种插件:
Rancher Convoy 其后端支持devicemapper,NFS, EBS 等实现容器跨主机共享数据,并且支持卷的增量备份快照,备份恢复,而且用户也可以方便在不同的宿主机上共享卷,以及卷的迁移,实际实现原理还是将主机目录挂载到容器之中;
Q: 采用哪些方式进行容器数据备份?
1) 通过卷插件,在宿主机上采用手工的方式将分布式系统挂载到本地;
2) 通过容器内部或者外部数据收集程序(fluentd或filebeat)将存储于宿主机上的数据进行实时收集从而减少容器销毁导致的数据丢失带来的损失;