[TOC]
文章目录 (1) Keepalive 高可用解决方案
0x00 快速入门 Q:什么是高可用集群(Cluster)?
系统故障分类:
硬件故障:设计缺陷、wearout(损耗)、自然灾害、不可抗力等等
软件故障:设计缺陷
集群类型:
LB : LVS / NGINX (http/upstream,stream / upstrem)
HA 高可用性 SPoF : SinglePointofFailure,高可用的是“服务”并且资源组成一个高可用服务的“组件”(vip/nginx process shared storage)
HPC 高性能计算(High Performance Computing)
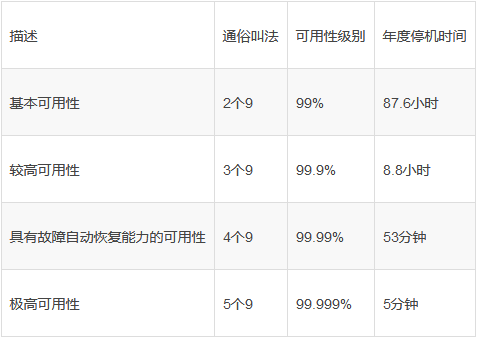
1)高可用集群的衡量标准
可用性被定义为:HA = MTTF/(MTTF+MTTR)*100%。
系统可用性的公式:HA = MTBF/(MTBF+MTTR)(0,1), 95%几个9(指标):99%,…,99.999%,99.9999%
具体HA衡量标准:
weiyigeek.top-衡量标准
补充:提升系统高用性的解决方案之降低MTTR手段就是冗余redundant
2)高可用集群实现原理
自动侦测(Auto-Detect)/ 故障检查
自动切换/故障转移(FailOver)
自动恢复/故障回转(FailBack)
其他关注点Q:如果节点不再成为集群节点成员时(不合法),如何处理运行于当前节点的资源?
[TOC]
文章目录 (1) Keepalive 高可用解决方案
0x00 快速入门 Q:什么是高可用集群(Cluster)?
系统故障分类:
硬件故障:设计缺陷、wearout(损耗)、自然灾害、不可抗力等等
软件故障:设计缺陷
集群类型:
LB : LVS / NGINX (http/upstream,stream / upstrem)
HA 高可用性 SPoF : SinglePointofFailure,高可用的是“服务”并且资源组成一个高可用服务的“组件”(vip/nginx process shared storage)
HPC 高性能计算(High Performance Computing)
1)高可用集群的衡量标准
可用性被定义为:HA = MTTF/(MTTF+MTTR)*100%。
系统可用性的公式:HA = MTBF/(MTBF+MTTR)(0,1), 95%几个9(指标):99%,…,99.999%,99.9999%
具体HA衡量标准:
weiyigeek.top-衡量标准
补充:提升系统高用性的解决方案之降低MTTR手段就是冗余redundant
2)高可用集群实现原理
自动侦测(Auto-Detect)/ 故障检查
自动切换/故障转移(FailOver)
自动恢复/故障回转(FailBack)
其他关注点Q:如果节点不再成为集群节点成员时(不合法),如何处理运行于当前节点的资源? 1 2 3 4 1、stop:直接停止服务; 2、ignore:忽略,以前运行什么服务现在还运行什么(双节点集群需要配置该选项); 3、Freeze:冻结,保持事先建立的连接,但不再接收新的请求; 4、suicide:kill 掉服务。
(重要知识点)集群脑裂(Split-Brain)和资源隔离(Fencing)
脑裂后果:这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。
脑裂解决:上面3-1-1、3-1-2的方法也能一定程度上解决脑裂的问题,但完全解决还需要资源隔离(Fencing)。
资源隔离(Fencing):当不能确定某个节点的状态时,通过fencing把对方干掉,确保共享资源被完全释放,前提是必须要有可靠的fence设备。
3) 高可用集群工作模型
4)高可用集群架构层次
Messaging(消息) and Membership Layer(成员关系)
信息传递层,传递集群信息的一种机制,通过监听UDP 694号端口,可通过单播、组播、广播的方式,实时快速传递信息,传递的内容为高可用集群的集群事务,例如:心跳信息,资源事务信息等等,只负责传递信息,不负责信息的计算和比较。
成员关系(Membership)层,这层最重要的作用是主节点(DC)通过Cluster Consensus Menbership Service(CCM或者CCS)这种服务由Messaging层提供的信息,来产生一个完整的成员关系。这层主要实现承上启下的作用,承上将下层产生的信息生产成员关系图传递给上层以通知各个节点的工作状态;启下将上层对于隔离某一设备予以具体实施。
Messaging Layer 集群信息层软件: heartbeat (v1, v2) 、heartbeat V3 (可以拆分为:heartbeat, pacemaker, cluster-glue) ,
4)高可用集群架共享存储
共享存储的类型:
DAS(Direct attached storage,直接附加存储):存储设备直接连接到主机总线上的,距离有限,而且还要重新挂载,之间有数据传输有延时;常用的存储设备:RAID 阵列、SCSI 阵列。
这是设备块级别驱动上实现的共享,持有锁是在节点主机本地上的,无法通知其他节点,所以如果多节点活动模型的集群同时写入数据,会发生严重的数据崩溃错误问题,主备双节点模型的集群在分裂的时候了会出现问题;
NAS(network attached storage,网络附加存储):文件级别交互的共享,各存储设备通过文件系统向集群各节点提供共享存储服务,是用C/S框架协议来实现通信的应用层服务。
常用的文件系统:NFS、FTP、CIFS等,如使用NFS实现的共享存储,各节点是通过NFS协议来向共享存储请求文件的。
SAN(storage area network、存储区域网络)
块级别的将通信传输网络模拟成SCSI(Small Computer System Interface)总线来使用,节点主机(initiator)和SAN主机(target)都需要SCSI驱动,并借助网络隧道来传输SAN报文,所以接入到SAN主机的存储设备不一定需要是SCSI类型的。
常用的SAN:FC光网络(交换机的光接口超贵,代价太高)、IPSAN(iscsi、存取快,块级别,廉价)。
集群高可用常常使用的组合:
0x02 Keepalived 介绍与组成 Keepalived是Linux下一个轻量级别的高可用解决方案;
高可用(High Avalilability,HA),其实两种不同的含义:
广义来讲, 是指整个系统的高可用行
狭义的来, 讲就是之主机的冗余和接管
Keepalived是什么?
Keepalived功能作用:
一方面具有服务器状态检测和故障隔离功能
另一方面也有 HA cluster功能
Keepalived 安全认证有简单字符认证,预共享密钥MD5;
术语解释:
虚拟路由器:Virtual Router 由一个Master路由器和多个Backup路由器组成。通俗讲就是一个路由器集群。
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器物理路由器,如果多个路由器有相同的VRID,那么这些路由器就组成了一个虚拟路由器。
master:主设备,虚拟路由器中真正承担报文转发的节点。
backup:备用设备,虚拟路由器中某一时刻除Master路由器的其他都有节点。
priority:优先级,VRRP根据每个节点的优先级确定节点在虚拟路由器中的地位。如果优先级相同则根据节点的IP地址大小进行比较。
VIP:Virtual IPV:虚拟路由器的IP,VIP是用于客户接入的IP地址。
MAC:Virutal MAC:虚拟路由器拥有的MAC地址(00-00-5e-00-01-VRID)
抢占方式和非抢占方式:
抢占方式中只要优先级最高才会成为Master路由器
非抢占方式中只要Master路由器没有出现故障,则Baskup路由器的优先级再高也不会成为Master路由器。
它与HeartBeat相比较?
安全认证:1 2 简单字符认证、HMAC机制,只对信息做认证 MD5(leepalived不支持)
1) VRRP协议
其中涉及到两个概念:
VRRP虚拟路由冗余,可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,并且每个虚拟路由器都有一个唯一的标识号称为VRID,一个VRID与一组IP地址构成一个虚拟路由器;这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务;
物理路由设备成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等;
在VRRP协议中所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
2) 工作原理
网络层:运行4个重要协议,互联网络IP协议,互联网络可控制报文协议ICMP、地址转换协议ARP、反向地址转换协议RARP;
传输层:提供两个主要的协议,传输控制协议TCP和用户数据协议UDP,传输控制协议TCP可以提供可靠的数据输出服务、IP地址和端口,代表TCP的一个连接端,要获得TCP服务,需要在发送机的一个端口和接收机的一个端口上建立连接,而Keepalived在传输层里利用了TCP协议的端口连接和扫描技术来判断集群节点的端口是否正常,比如对于常见的WEB服务器80端口。
Keepalived一旦在传输层探测到这些端口号没有数据响应和数据返回,就认为这些端口发生异常,然后强制将这些端口所对应的节点从服务器集群中剔除掉。
在应用层:可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议,Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived工作方式,例如:可以通过编写程序或者脚本来运行Keepalived,而Keepalived将根据用户的设定参数检测各种程序或者服务是否允许正常,如果Keepalived的检测结果和用户设定的不一致时,Keepalived将把对应的服务器从服务器集群中剔除;
工作模式:1 2 主/备:单虚拟路径器; 主/主:主/备(虚拟路径器),备/主(虚拟路径器)
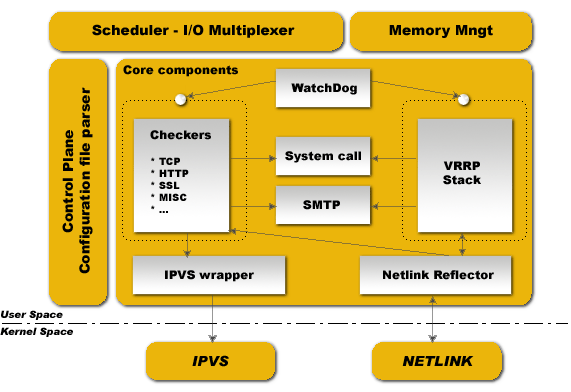
3) 结构体系
从下面的图可以看出用户空间层,是建立在内核空间层之上:
用户空间层主要有4个部分:
Scheduler I/O Multiplexer 是一个I/O复用分发调度器,它负载安排Keepalived所有内部的任务请求,
Memory Mngt 是一个内存管理机制,这个框架提供了访问内存的一些通用方法
Control Plane 是keepalived的控制版面,可以实现对配置文件编译和解析
Core componets 这部分主要保护呢了5个部分
WatchDog:负载监控checkers和VRRP进程的状况
VRRP Stack:负载负载均衡器之间的失败切换FailOver,如果只用一个负载均稀器,则VRRP不是必须的。
Checkers:负责真实服务器的健康检查healthchecking,是keepalived最主要的功能。换言之,可以没有
VRRP Stack,但健康检查healthchecking是一定要有的。
IPVS wrapper:用户发送设定的规则到内核ipvs代码
Netlink Reflector:用来设定vrrp的vip地址等。
内核空间,主要有两个部分:
IPVS 实现复制均衡
NetLINK 模块主要用于实现一些高级路由框架和一些相关参数的网络功能,完成用户空间层Netlink Reflector模块发来的各种网络请求。
weiyigeek.top-结构体系
keepalived启动后会有三个进程
0x03 Keepalived 环境与实例 项目需求:利用Keepalived实现httpd的高可用(主/备模式)
KeppAlive项目高可用流程:
项目需求分析,IP及VIP资源分配
开启keepAlived服务与httpd服务;
vrrp协议单播检测完成地址流动,vip地址所在的节点生成ipvs规则(在配置文件中预先定义,这里是默认)并且为ipvs集群的各RS做健康状态检测;
启动keepalived后VIP漂移到主节点上,备节点热备(随时准备切换),这里默认是可以抢占即(Master恢复后VIP将漂移回来)
基于脚本调用接口通过执行脚本完成脚本中定义的功能,通过VIP访问httpd服务;
模拟环境:CentOS Linux release 7.6.1810 (Core) / Keepalived v1.3.5 (03/19,2017)1 2 3 4 5 6 7 8 9 10 11 systemctl stop firewalld systemctl stop iptables yum install -y ntpdate && ntpdate us.pool.ntp.org 10.10.107.222 master 10.10.107.221 slave
IP
用途
10.10.107.222
Master / httpd
10.10.107.221
Slave / httpd
10.10.107.236
VIP 漂移
实例流程: 1 2 3 4 5 6 7 8 9 10 11 12 $ sudo yum install -y httpd echo “10.10.107.222” >/var/www/html/index.htmlecho “10.10.107.221” >/var/www/html/index.html$ sudo systemctl start httpd $ sudo systemctl enable httpd
weiyigeek.top-httpd安装成功验证
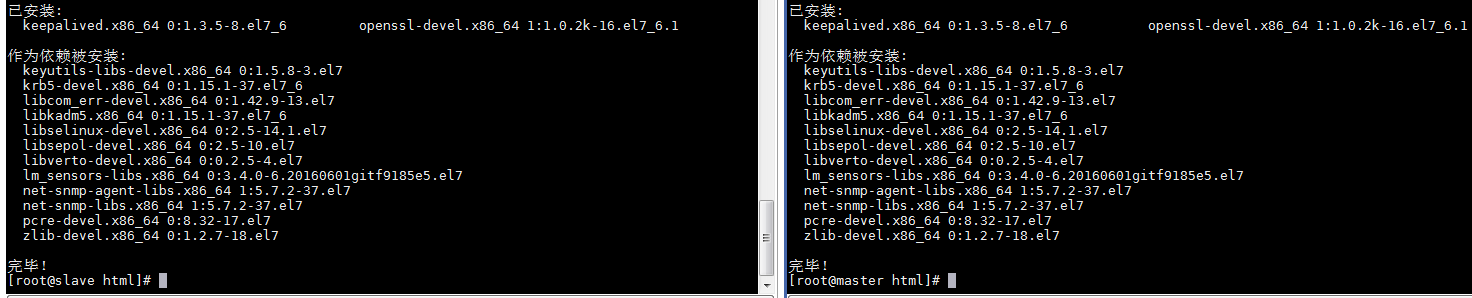
Step2.两台keepalived主机的设置1 2 3 $ sudo yum install -y openssl openssl-devel keepalived
weiyigeek.top-keepalived
Step3.keepalived配置文件修改:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 vim /etc/keepalived/keepalived.conf global_defs { router_id master } vrrp_instance VI_1 { state MASTER interface ens192 virtual_router_id 51 priority 100 virtual_ipaddress { 10.10.107.236/24 dev ens192 } } global_defs { router_id slave } vrrp_instance VI_1 { state BACKUP interface ens192 virtual_router_id 51 priority 90 virtual_ipaddress { 10.10.107.236/24 dev ens192 } } global_defs { } virtual_server 10.10.107.236 80 { delay_loop 6 lb_algo rr lb_kind NAT nat_mask 255.255.255.0 persistence_timeout 50 protocol TCP real_server 10.10.107.222 80 { weight 1 } real_server 10.10.107.221 80 { weight 1 } }
以上配置state表示主节点为10.10.107.222,副节点为10.10.107.221。虚拟为IP10.10.107.236。
后端的真实服务器为10.10.107.222和10.10.107.221,当通过10.10.107.236访问web服务器时,自动转到后端真实服务器,后端节点的权重相同,类似轮询的模式。
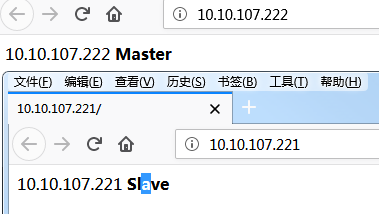
Step4.keepalived的启动与测试1 2 3 4 systemctl start httpd keepalived systemctl status keepalived httpd $ ip addr show ens192
weiyigeek.top-VIP
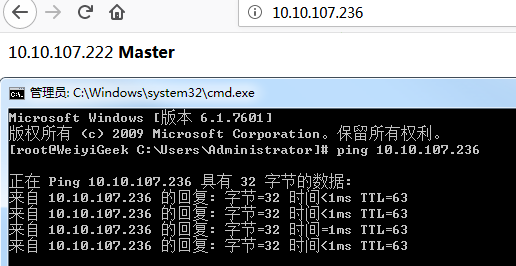
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 http://10.10.107.236/ 10.10.107.222 Master [root@master ~] [root@slave sec] 2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:b3:6d:fd brd ff:ff:ff:ff:ff:ff inet 10.10.107.221/24 brd 10.10.107.255 scope global noprefixroute ens192 valid_lft forever preferred_lft forever inet 10.10.107.236/24 scope global secondary ens192 valid_lft forever preferred_lft forever inet6 fe80::25f6:1911:3d05:2922/64 scope link noprefixroute valid_lft forever preferred_lft forever http://10.10.107.236/ 10.10.107.221 Slave [root@master ~] http://10.10.107.236/ 10.10.107.222 Master
weiyigeek.top-漂移案例
0x04 命令详解 参考:https://www.keepalived.org/doc/programs_synopsis.html 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 -f,-use-file = FILE 使用指定的配置文件。默认配置文件是“/etc/keepalived/keepalived.conf”。 -P,-vrrp 只运行VRRP子系统。这对于不使用IPVS负载平衡器的配置非常有用。 -C, - 检查 只运行健康检查子系统。这对于使用IPVS负载均衡器和单个导向器而不进行故障切换的配置非常有用。 -l,-log -console 将消息记录到本地控制台。默认行为是将消息记录到系统日志。 -D,-log -detail 详细的日志消息。 -S,-log -facility = [0-7] 将syslog工具设置为LOG_LOCAL [0-7]。默认的系统日志工具是LOG_DAEMON。 -V,-dont-release-vrrp 不要在守护进程中删除VRRP VIP和VROUTE。默认行为是在keepalived退出时删除所有VIP和VROUTE -I,-dont-release-ipvs 不要在守护进程停止时移除IPVS拓扑。它在keepalived退出时从IPVS虚拟服务器表中删除所有条目的默认行为。 -R,不要重生 不要重新生成子进程。默认行为是在任何进程退出时重新启动VRRP和检查器进程。 -n,-dont-fork 不要分解守护进程。该选项将导致keepalived在前台运行。 -d,-dump-conf 转储配置数据。 -p,-pid = FILE 父指定的进程使用指定的pidfile。 keepalived的默认pid文件是“/var/run/keepalived.pid”。 -r,-vrrp_pid = FILE 为VRRP子进程使用指定的pidfile。 VRRP子进程的默认pid文件是“/var/run/keepalived_vrrp.pid”。 -c,-checkers_pid = FILE 针对检查者子进程使用指定的pidfile。检查器子进程的默认pid文件是“/var/run/keepalived_checkers.pid”。 -x,-snmp 启用SNMP子系统。
genhash实用程序:二进制文件用于生成摘要字符串。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 -use-ssl,-S 使用SSL连接到服务器。 -server <host>,-s 指定要连接的IP地址。 -port <port>,-p 指定要连接的端口。 -url <url>,-u 指定要生成散列的文件的路径。 -use-virtualhost <host>,-V 指定要与HTTP标头一起发送的虚拟主机。 -hash <alg>,-H 指定散列算法以制作目标页面的摘要。请查看帮助屏幕中的可用列表,并标记默认标记。 -verbose,-v 请输出详细信息。 -help ,-h 显示程序帮助屏幕并退出。 -release, -r 显示版本号(版本)并退出。
0x05 配置文件 配置文件:1 2 3 4 5 6 主配置文件:/etc/keepalived/keepalived.conf 主程序文件:/usr/sbin/keepalived 提供校验码:/usr/bin/genhash Unit File:/usr/lib/systemd/system/keepalived.service Unit File的环境配置文件:/etc/sysconfig/keepalived keepalived的日志默认在:tailf /var/log /messages
配置文件的结构层次: 1 2 3 4 5 6 7 8 9 10 11 12 13 Global Configuration:全局配置部分 Global definition static routes/address VRRPD Configuration:VRRPD配置部分 1. vrrp_script : 添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的VRRP Instance记录 2. vrrp_sync_group : VRRP synchronization group:VRRP同步组 3. garp_group : 当检测到组里面任意服务发生变化时候,将进行主从切换 4. vrrp_instance : VRRP instance:VRRP实例配置 LVS Configuration:LVS配置部分 Virtual server: ipvs的RS和VS
实际配置文件说明: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 ! Configuration File for keepalived global_defs { notification_email { sysadmin@firewall.net } notification_email_from sender@firewall.net smtp_server 192.168.200.1 smtp_connect_timeout 30 router_id LVS_DEVEL vrrp_mcast_group4 224.1.101.33 vrrp_mcast_group6 ff02::12 lvs_sync_daemon <INTERFACE> <VRRP_INSTANCE> [id <SYNC_ID>] [maxlen <LEN>] [port <PORT>] [ttl <TTL>] [group <IP ADDR>] 设置LVS同步服务的相关内容。可以同步LVS的状态信息。 INTERFACE:指定同步服务绑定的接口。 VRRP_INSTANCE:指定同步服务绑定的VRRP实例。 id <SYNC_ID>:指定同步服务所使用的SYNCID,只有相同的SYNCID才会同步。范围是0-255. maxlen:指定数据包的最大长度。范围是1-65507 port:指定同步所使用的UDP端口。 group:指定组播IP地址。 lvs_flush:在keepalived启动时,刷新所有已经存在的LVS配置。 vrrp_version 2|3: vrrp_check_unicast_src:在单播模式中,开启对VRRP数据包的源地址做检查,源地址必须是单播邻居之一。 vrrp_skip_check_adv_addr vrrp_strict vrrp_garp_interval 0 vrrp_gna_interval 0 vrrp_iptables vrrp_priority <-20 -- 19> checker_priority <-20 -- 19> vrrp_no_swap checker_no_swap script_user <username> [groupname] enable_script_security nopreempt } vrrp_sync_group VG_1 { group { http mysql } notify_master /path/to/to_master.sh notify_backup /path_to/to_backup.sh notify_fault "/path/fault.sh VG_1" notify /path/to/notify.sh smtp_alert } vrrp_script check_running { script "/usr/local/bin/check_running" interval 10 weight 10 rise <INTEGER> fall <INTEGER> user <USERNAME> [GROUPNAME] init_fail } vrrp_instance VI_1 { state MASTER interface ens192 use_vmac [<VMAC_INTERFACE>] vmac_xmit_base native_ipv6 lvs_sync_daemon_inteface eth1 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 11111111 } virtual_ipaddress { 10.10.107.236/24 dev ens192 label eth192 10.10.107.237 } virtual_routes { src 192.168.100.1 to 192.168.109.0/24 via 192.168.200.254 dev eth1 192.168.110.0/24 via 192.168.200.254 dev eth1 192.168.111.0/24 dev eth2 192.168.112.0/24 via 192.168.100.254 } nopreempt preemtp_delay 300 debug notify master track_script { <SCRIPT_NAME> weight <-254-254> check_running weight 20 } } vrrp_instance VI_2{ state BACKUP interface ens193 virtual_router_id 34 priority 96 advert_int 1 authentication { auth_type PASS auth_pass a6b7c8d9 } virtual_ipaddress { 172.16.15.99/16 dev eth0 } } 1. virtual server IP port 2. virtual server fwmark int 3. virtual server group string virtual_server 10.10.107.236 80 { delay_loop 6 lb_algo rr|wrr|lc|wlc|lblc|sh|dh lb_kind NAT|DR|TUN persistence_timeout 50 protocol TCP|UDP|SCTP real_server 10.10.107.221 80 { weight 1 inhibit_on_failure notify_up <STRING> | <QUOTED-STRING> notify_down <STRING> | <QUOTED-STRING> HTTP_GET|SSL_GET { url { path /testurl/test.jsp digest 640205b7b0fc66c1ea91c463fac6334d status_code 200 } connect_ip <IP ADDRESS> connect_port <PORT> bindto <IP ADDRESS> bind_port <PORT> connect_timeout 3 nb_get_retry 3 delay_before_retry 2 fwmark <INTEGER> warmup <INT> } } real_server 10.10.107.33 3306 { weight 1 TCP_CHECK { connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } SMTP_CHECK host { connect_ip <IP ADDRESS> connect_port <PORT> 14 KEEPALIVED bindto <IP ADDRESS> } connect_timeout <INTEGER> retry <INTEGER> delay_before_retry <INTEGER> helo_name <STRING>|<QUOTED-STRING> } MISC_CHECK { misc_path <STRING>|<QUOTED-STRING> misc_timeout <INT> misc_dynamic } DNS_CHECK { connect_ip <IP ADDRESS>:连接的IP地址。默认是real server的ip地址。 connect_port <PORT>:连接的端口。默认是real server的端口。 默认是25端口 bindto <IP ADDRESS>:发起连接的接口的地址。 bind_port <PORT>:发起连接的源端口。 connect_timeout <INT>:连接超时时间。默认是5s。 fwmark <INTEGER>:使用fwmark对所有出去的检查数据包进行标记。 warmup <INT>:指定一个随机延迟,最大为N秒。可防止网络阻塞。如果为0,则关闭该功能。 retry <INT>:重试次数。默认是3次。 type <STRING>:DNS query type 。A/NS/CNAME/SOA/MX/TXT/AAAA name <STRING>:DNS查询的域名。默认是(.) } }
总结:
VRRP脚本(vrrp_script)和VRRP实例(vrrp_instance)属于同一个级别
VRRP脚本中的weight权重:
如果脚本执行成功(退出状态码为0),weight大于0,则priority增加。
如果脚本执行失败(退出状态码为非0),weight小于0,则priority减少。
其他情况下,priority不变。
脚本文件要加上x权限同时指令最好写绝对路径。
0x06 入坑记 问题1:keepalived漂移的VIP无法ping通? 1 2 3 4 5 6 关闭防火墙 注释:keepalived.conf配置中 [root@slave sec] PING 10.10.107.236 (10.10.107.236) 56(84) bytes of data. 64 bytes from 10.10.107.236: icmp_seq=1 ttl=64 time=0.056 ms
问题2:查看vrrp通信信息 1 2 3 4 5 6 tcpdump -i ens192 vrrp -vv -c 2 tcpdump: listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes 11:21:31.013073 IP (tos 0xc0, ttl 255, id 64656, offset 0, flags [none], proto VRRP (112), length 40) 10.10.107.254 > vrrp.mcast.net: vrrp 10.10.107.254 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 5, prio 120, authtype none, intvl 1s, length 20, addrs: gateway 11:21:31.357117 IP (tos 0xc0, ttl 255, id 223, offset 0, flags [none], proto VRRP (112), length 40) master > vrrp.mcast.net: vrrp master > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 100, authtype simple, intvl 1s, length 20, addrs: master auth "11111111"
问题3:arp缓存问题? 1 2 arp -n | awk '/^[1-9]/{system("arp -d "$1)}'
问题4:在备用节点上抓包测试(在启用多播的情况下):
haproxy的故障转移 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [root@localhost ~] ! Configuration File for keepalived global_defs { router_id teacher } vrrp_script chk_haproxy { script "lsof -i:80 | grep haproxy || exit 1" interval 2 fail 1 } vrrp_instance lvs_inst { state MASTER interface ens33 virtual_router_id 51 priority 250 nopreempt advert_int 1 authentication { auth_type PASS auth_pass 1111 } track_script { chk_haproxy } virtual_ipaddress { 10.18.42.124 } }
主从节点都必须有的检测haproxy服务状态的文件(注:该文件必须有可执行权限!!!):1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #!/bin/bash if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then systemctl start haproxy fi sleep 2 if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then systemctl stop keepalived 自动漂移到另外一台haproxy机器,实现了对haproxy的高可用 fi
mysql 与 keepalived https://blog.51cto.com/gaowenlong/1888036
1)、实现master与slave1两台主机的复制(AA复制)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 [root@localhost ~] ! Configuration File for keepalived global_defs { router_id teacher } vrrp_instance lvs_inst { state MASTER interface ens33 virtual_router_id 51 priority 250 nopreempt advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.18.42.123 } } virtual_server 10.18.42.123 3306 { delay_loop 6 lb_algo rr lb_kind DR protocol TCP real_server 10.18.42.251 3306 { weight 1 notify_down /etc/keepalived/kill.sh TCP_CHECK { connect_port 3306 connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } } [root@localhost ~] #!/bin/bash pkill keepalived ip addr del dev ens33 10.18.42.123/32