[TOC]
0x00 前言简述 后续补充….
Q: 爬虫(Spdier)步骤解析?
1.数据爬取;
2.数据提取;
3.数据存储;
Q: 反爬虫爬取方法技巧? (实际上提高了破解成本而已!)
1.数据加密反扒:在服务端对数据进行特定算法的加密, 在客户端利用JS进行动态输出解密(如何保护前度解密文件是重点!);
JSON - https://www.cnblogs.com/lanston1/p/11024147.html
Selenium + ChormeDriver 爬虫:https://www.cnblogs.com/caizheng/p/7344561.html
0x01 反扒开发实战 (1) 后端base64编码前端JS动态解密反扒取; Q: 我们为什么要用base64编码?
描述: 它是网络上最常见的用于传输8bit字节代码的编码方式之一, 采用base64编码具有不可读性即所编码的数据不会被人直接看出;放在请求头响应头进行传输
补充: Javascript 原生的 BASE64(ASCII) window.atob() 解码 与 window.btoa() 转码 但是他们并不支持中文的Base64编码需要下面自己写的 utf-8 decode 的实现;
[TOC]
0x00 前言简述 后续补充….
Q: 爬虫(Spdier)步骤解析?
1.数据爬取;
2.数据提取;
3.数据存储;
Q: 反爬虫爬取方法技巧? (实际上提高了破解成本而已!)
1.数据加密反扒:在服务端对数据进行特定算法的加密, 在客户端利用JS进行动态输出解密(如何保护前度解密文件是重点!);
JSON - https://www.cnblogs.com/lanston1/p/11024147.html
Selenium + ChormeDriver 爬虫:https://www.cnblogs.com/caizheng/p/7344561.html
0x01 反扒开发实战 (1) 后端base64编码前端JS动态解密反扒取; Q: 我们为什么要用base64编码?
描述: 它是网络上最常见的用于传输8bit字节代码的编码方式之一, 采用base64编码具有不可读性即所编码的数据不会被人直接看出;放在请求头响应头进行传输
补充: Javascript 原生的 BASE64(ASCII) window.atob() 解码 与 window.btoa() 转码 但是他们并不支持中文的Base64编码需要下面自己写的 utf-8 decode 的实现;1 2 Window.atob() window.btoa()
反扒开发流程:
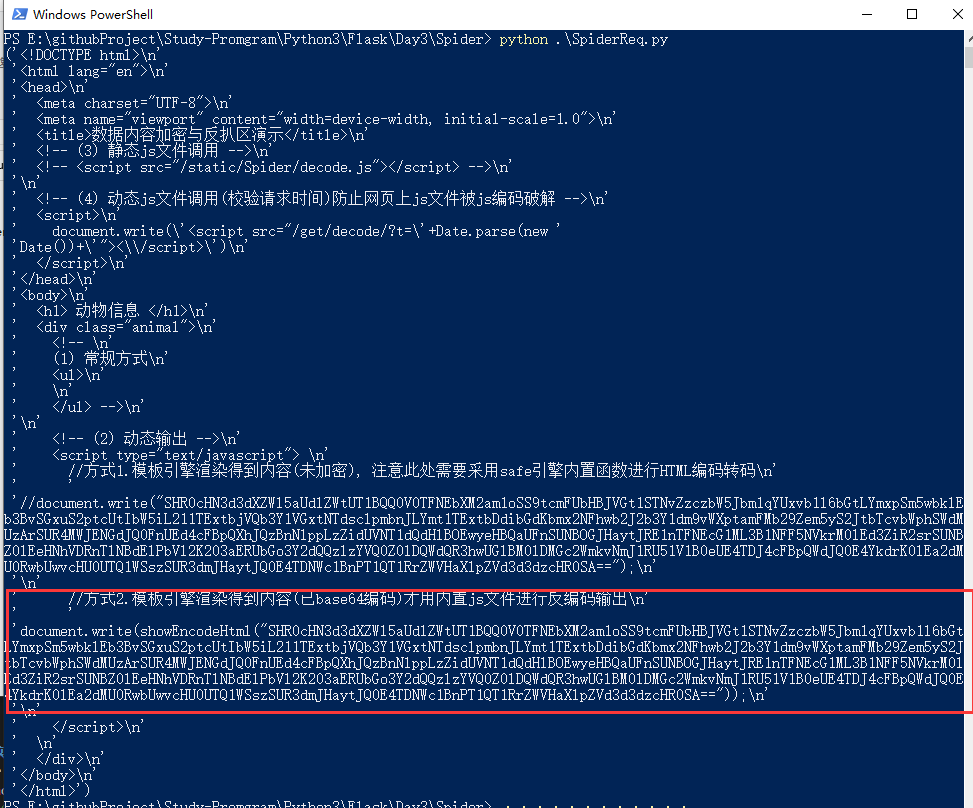
(1) 前台数据采用渲染JS(document.write)加密输出内容;
(2) 前台加载JS文件进行解码后动态输出内容;
(3) 请求的JS解密文件被其它请求响应路径所替代,并设置有失效期1000毫秒;
项目实践 Spider Example Request 1 2 3 4 5 6 7 8 9 10 11 import requestsfrom pprint import pprint def get_data () : response = requests.get('http://127.0.0.1:8000/get/info' ) pprint(response.content.decode('utf-8' )) if __name__ == "__main__" : get_data()
Javascript Base64 decode 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 <script type ="text/javascript" > function BASE64 () _keyStr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=" ; this .encode = function (input) var output = "" ; var chr1, chr2, chr3, enc1, enc2, enc3, enc4; var i = 0 ; input = _utf8_encode(input); while (i < input.length) { chr1 = input.charCodeAt(i++); chr2 = input.charCodeAt(i++); chr3 = input.charCodeAt(i++); enc1 = chr1 >> 2; enc2 = ((chr1 & 3) << 4 ) | (chr2 > > 4); enc3 = ((chr2 & 15) << 2 ) | (chr3 > > 6); enc4 = chr3 & 63; if (isNaN (chr2)) { enc3 = enc4 = 64; } else if (isNaN (chr3)) { enc4 = 64; } output = output + _keyStr.charAt(enc1) + _keyStr.charAt(enc2) + _keyStr.charAt(enc3) + _keyStr.charAt(enc4); } return output; } this .decode = function (input) var output = "" ; var chr1, chr2, chr3; var enc1, enc2, enc3, enc4; var i = 0 ; input = input.replace(/[^A-Za-z0-9\+\/\=]/g , "" ); while (i < input.length) { enc1 = _keyStr.indexOf(input.charAt(i++)); enc2 = _keyStr.indexOf(input.charAt(i++)); enc3 = _keyStr.indexOf(input.charAt(i++)); enc4 = _keyStr.indexOf(input.charAt(i++)); chr1 = (enc1 << 2 ) | (enc2 > > 4); chr2 = ((enc2 & 15) << 4 ) | (enc3 > > 2); chr3 = ((enc3 & 3) << 6) | enc4; output = output + String .fromCharCode(chr1); if (enc3 != 64 ) { output = output + String .fromCharCode(chr2); } if (enc4 != 64 ) { output = output + String .fromCharCode(chr3); } } output = _utf8_decode(output); return output; } _utf8_encode = function (string) string = string.replace(/\r\n/g ,"\n" ); var utftext = "" ; for (var n = 0 ; n < string.length; n++) { var c = string.charCodeAt(n); if (c < 128 ) { utftext += String .fromCharCode(c); } else if ((c > 127 ) && (c < 2048 )) { utftext += String .fromCharCode((c >> 6 ) | 192 ); utftext += String .fromCharCode((c & 63 ) | 128 ); } else { utftext += String .fromCharCode((c >> 12 ) | 224 ); utftext += String .fromCharCode(((c >> 6 ) & 63 ) | 128 ); utftext += String .fromCharCode((c & 63 ) | 128 ); } } return utftext; } _utf8_decode = function (utftext) var string = "" ; var i = 0 ; var c = c1 = c2 = 0 ; while ( i < utftext.length ) { c = utftext.charCodeAt(i); if (c < 128 ) { string += String .fromCharCode(c); i++; } else if ((c > 191 ) && (c < 224 )) { c2 = utftext.charCodeAt(i+1); string += String .fromCharCode(((c & 31 ) << 6 ) | (c2 & 63 )); i += 2; } else { c2 = utftext.charCodeAt(i+1); c3 = utftext.charCodeAt(i+2); string += String .fromCharCode(((c & 15 ) << 12 ) | ((c2 & 63 ) << 6 ) | (c3 & 63 )); i += 3; } } return string; } } function showEncodeHtml (content) var base64=new BASE64(); return base64.decode(base64.decode(content)["\x72\x65\x70\x6c\x61\x63\x65" ]('\x48\x74\x74\x70\x73\x77\x77\x77\x57\x65\x69\x79\x69\x47\x65\x65\x6b\x54\x4f\x50' ,'' )["\x72\x65\x70\x6c\x61\x63\x65" ]('\x50\x4f\x54\x6b\x65\x65\x47\x69\x79\x69\x65\x57\x77\x77\x77\x73\x70\x74\x74\x48' ,'' )); } </script >
脚本解析:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 HttpswwwWeiyiGeekTOP => 487474707377777757656979694765656b544f50 => \x48\x74\x74\x70\x73\x77\x77\x77\x57\x65\x69\x79\x69\x47\x65\x65\x6b\x54\x4f\x50 POTkeeGiyieWwwwspttH => 504f546b65654769796965577777777370747448 => \x50\x4f\x54\x6b\x65\x65\x47\x69\x79\x69\x65\x57\x77\x77\x77\x73\x70\x74\x74\x48 var reverse = function ( str ){ return str.split('' ).reverse().join('' ); }; reverse('HttpswwwWeiyiGeekTOP' ); var string = "504f546b65654769796965577777777370747448" ; var res = "" ; for (i = 0; i < string.length; i+=2){ res += "\\x" +string.slice(i,i+2); } console.log(res) base64.decode( base64.decode(context)["replace" ]('HttpswwwWeiyiGeekTOP' ,'' )["replace" ]('POTkeeGiyieWwwwspttH' ,'' ) )
Flask - Templates
Flask - View (蓝图)
Day3\App\views\Spider\demo1.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from flask import Blueprint,render_template,request,make_responsefrom App.models import db,Dogimport base64import osimport timepocket = Blueprint('pocket' , __name__, url_prefix='/get' ) @pocket.route('/info/') def get_info () : dogs = Dog.query.filter(Dog.id.in_([1 ,3 ,5 ,7 ,9 ])).all() info = render_template('/Spider/info.html' , Info = dogs).replace('\n' ,'' ) encode_content = base64.standard_b64encode(info.encode('utf-8' )).decode('utf-8' ) splice_content = "HttpswwwWeiyiGeekTOP" + encode_content + "POTkeeGiyieWwwwspttH" mutil_encode = base64.standard_b64encode(splice_content.encode('utf-8' )).decode('utf-8' ) print("Base64 编码:" ,encode_content) return render_template('/Spider/index.html' , Title = '数据内容加密与反扒区演示' , Info = mutil_encode) @pocket.route('/decode/') def get_decode () : try : t = request.args.get('t' ) t = int(t) except : resp = make_response("alert('请求参数超时')" ) resp.headers["Content-type" ]="text/javascript;charset=UTF-8" return resp c = time.time() * 1000 if ( c - t <= 1000 ) and c > t: BASE_DIR = os.path.dirname(__file__) with open(os.path.join(BASE_DIR, '..\..\static\Spider\decode.js' ),encoding='utf-8' ) as file: jsdecode=file.read() resp = make_response(jsdecode) resp.headers["Content-type" ]="text/javascript;charset=UTF-8" else : resp = make_response("alert('请求超时')" ) resp.headers["Content-type" ]="text/javascript;charset=UTF-8" return resp
效果反馈:
weiyigeek.top-Request Spider
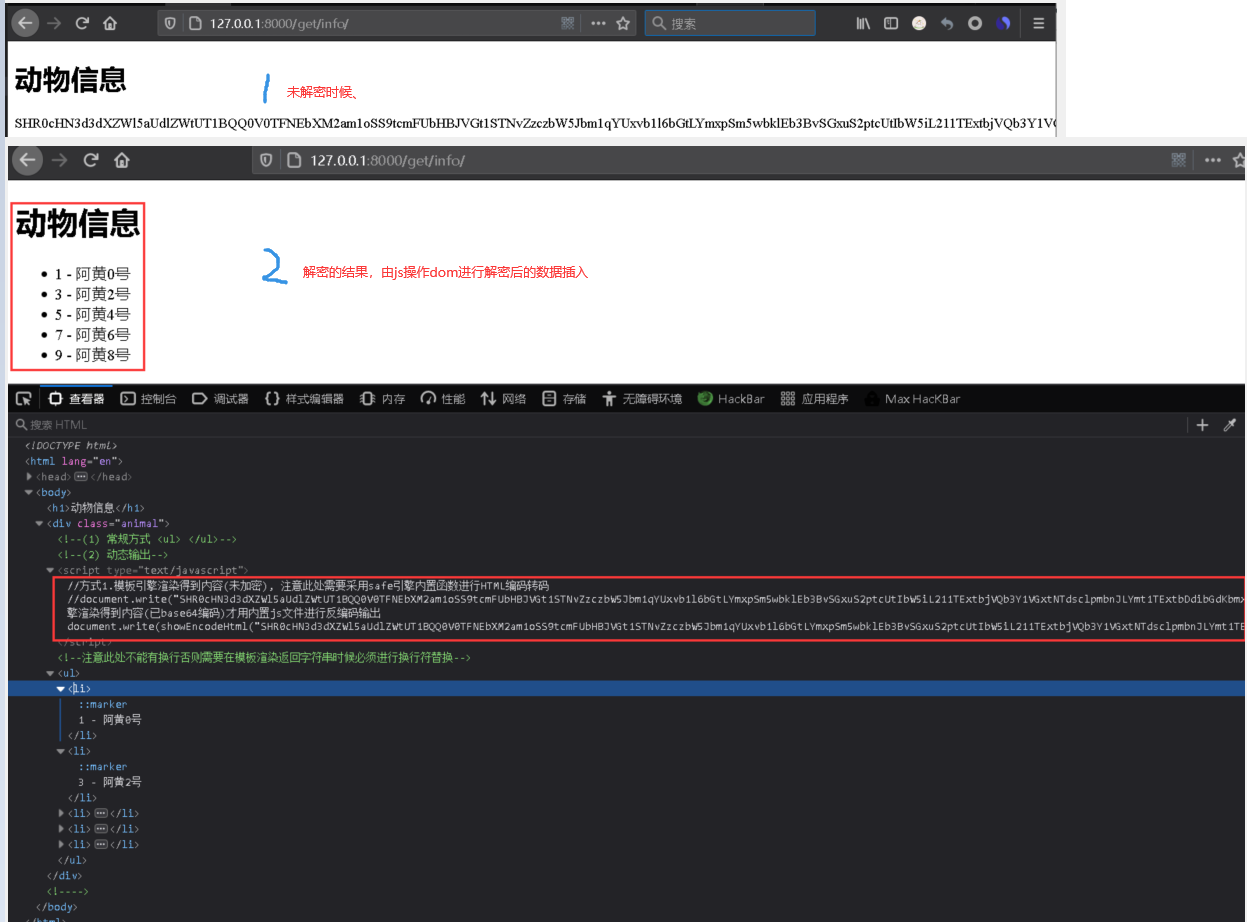
(2) 前端网页显示 : http://127.0.0.1:8000/get/info 1 Base64 编码: PCEtLSDms6jmhI/mraTlpITkuI3og73mnInmjaLooYzlkKbliJnpnIDopoHlnKjmqKHmnb/muLLmn5Pov5Tlm57lrZfnrKbkuLLml7blgJnlv4Xpobvov5vooYzmjaLooYznrKbmm7/mjaIgLS0+IDx1bD4gICAgPGxpPiAxIC0g6Zi/6buEMOWPtyA8L2xpPiAgICA8bGk+IDMgLSDpmL/pu4Qy5Y+3IDwvbGk+ICAgIDxsaT4gNSAtIOmYv+m7hDTlj7cgPC9saT4gICAgPGxpPiA3IC0g6Zi/6buENuWPtyA8L2xpPiAgICA8bGk+IDkgLSDpmL/pu4Q45Y+3IDwvbGk+ICA8L3VsPg==
weiyigeek.top-Web Visit
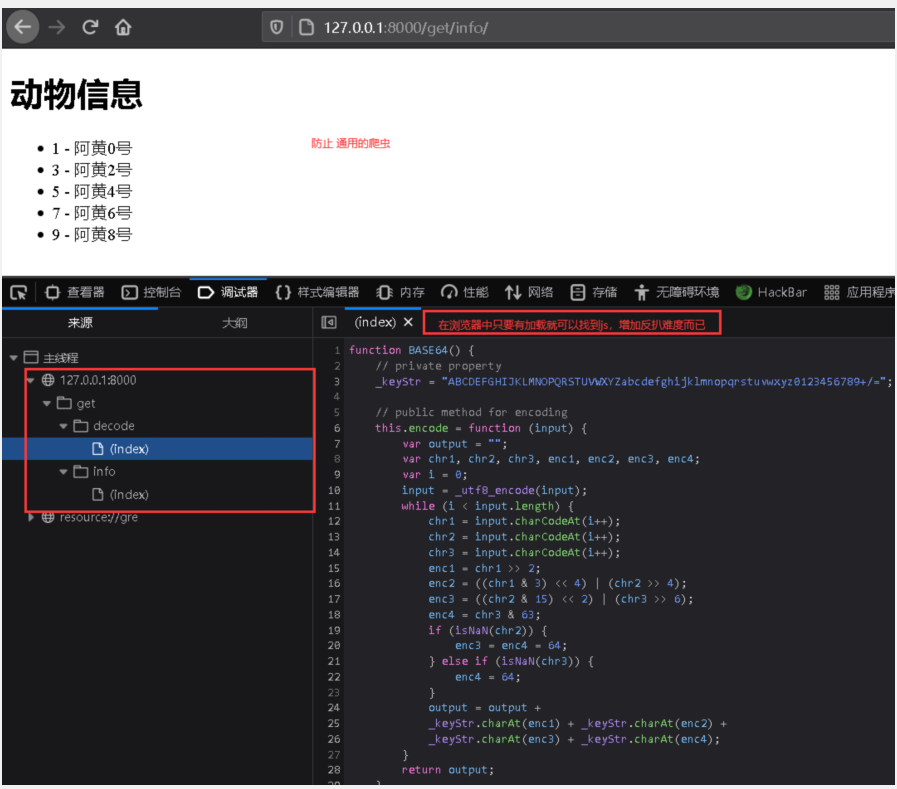
weiyigeek.top-封装JS访问
方式缺陷与对应解决办法:
(1) 采用浏览器中的网页交互式(Console)控制台获取JS加密的函数从而逆向解密网页内容(建议加上JS混淆有一定程度上的作用);
weiyigeek.top-只能说增加一点爬取难度
(2) 采用 Selenium + ChormeDriver 它是一个用于Web应用程序测试的工具,它可以操控浏览器来爬取网上的数据是爬虫的终极利器;
(3) 采用 Phantomjs 分析html代码,基于队列的爬虫、数据存储、数据拆分、爬虫限速、网页跟踪,脚本注入等技术。