[TOC]
0.MySQL语法 描述:学习MySQL除了一些基本的SQL语句以外,我们还需要学习MySQL扩展部分的知识;通过前面的学习我们知道SQL类型大致分为四类,在后面的学习采用这四类来入门了解使用MySQL 8.0;
语法定义 语法定义说明:
1.SQL关键字不区分大小写,可以用任何字母大写(建议大写),每条语句后加上’;’结束;
2.在语法描述中,方括号 [ 关键字 ]表示可选的关键字参数;
3.当语法元素由多个替代项组成时,替代项由竖线[ 关键字 | 关键字 ]分隔,表示里面的参数关键字赛可以被选择使用的;如:TRIM([[BOTH | LEADING | TRAILING] [remstr] FROM] str)
4.当必须从一组选项中选择一个成员时在用 { 关键字 }中列出,如{DESCRIBE | DESC} tbl_name [col_name | wild];
5.省略号(…)表示省略了语句的一部分,通常是为了提供较短版本的更复杂的语法例如:SELECT ... INTO OUTFILE是SELECT语句形式的简写,该语句的INTO OUTFILE后面还有一个 子句。
6.省略号还可以指示可以重复执行语句的前面的语法元素;比如reset_option可以给出多个值,每个值后面的第一个值前都带有逗号:RESET reset_option [,reset_option] ...
7.注释采用-- 或者 /****/进行SQL语句注释
表约束定义 描述:表的约束在定义表结构中是非常常用的我们需要对其进行深入的了解和学习;
表关键字和约束1 2 3 4 5 6 7 8 9 10 11 12 13 IF EXISTS IF NOT EXISTS CONSTRAINT REFERENCES AUTO_INCREMENT PRIMARK KEY FOREIGN KEY NOT NULL UNIQUE DEFAULT '值'
(1) 主键约束
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 CREATE TABLE t1 ( id INT PRIMARY KEY , ); CREATE TABLE t2 ( id INT (10 ), uid INT (10 ), PRIMARY KEY (id ,uid) ); CREATE TABLE IF NOT EXISTS t3 ( id SMALLINT PRIMARY KEY AUTO_INCREMENT, );
注意事项:
在设置了某一字段为主键自增长的时候,插入时候可以指定NULL但是实际也是插入的非NULL值;
主键约束:默认就是不能为空并且唯一,一张表只能有一个主键,常常供外键使用
(2) 外键约束
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE TABLE t1 ( uid INT (100 ) PRIMARY KEY , name VARCHAR (255 ) ); CREATE TABLE t2 ( fid INT (100 ), phone VARCHAR (16 ), CONSTRAINT fk_t1 FOREIGN KEY (fid) REFERENCES t1(uid) );
注意事项:
主键是不可以有空值的,而外键是可以有空值的;1 2 3 4 5 6 7 8 9 10 11 MySQL [Demo]> desc t1; + | Field | Type | Null | Key | Default | Extra | + | uid | int(100) | NO (关键点) | PRI | NULL | MySQL [Demo]> desc t2; + | Field | Type | Null | Key | Default | Extra | + | fid | int(100) | YES (关键点) | MUL | NULL |
t2表中插入的数据fid依赖于t1表中uid的值,它必须是uid的子集才能插入或者更新1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 MySQL [Demo]> INSERT INTO t1 VALUES (1,'Admin'),(2,'WeiyiGeek'); MySQL [Demo]> INSERT INTO t2 VALUES (1,'18888888888'),(2,'19999999999'); MySQL [Demo]> INSERT INTO t2 VALUES (NULL,'15555555555'); -- 可以插入空值 MySQL [Demo]> INSERT INTO t2 VALUES (3,'16666666666'); -- 执行错误,由于fid插入值非t1表uid字段的子集; MySQL [Demo]> SELECT * FROM t2;
(3) 非空约束 1 2 3 4 5 6 7 8 9 10 11 CREATE TABLE IF NOT EXISTS t5 ( id INT PRIMARY KEY , name VARCHAR (10 ) NOT NULL ) ENGINE =MEMORY CHARACTER SET utf8; MySQL [Demo]> INSERT INTO t5 VALUE (1,'Weiyi'),(2,''); -- 关键点 '' 不是空值而是空格 Query OK, 2 rows affected (0.08 sec) Records: 2 Duplicates: 0 Warnings: 0 MySQL [Demo]> INSERT INTO t5 VALUE (3,NULL); ERROR 1048 (23000): Column 'name' cannot be null
(4) 唯一性约束 1 2 3 CREATE TABLE IF NOT EXISTS t1 ( certid INT UNIQUE ) ENGINX=MYISAM CHARACTER SET utf8;
注意事项:
唯一约束列的内容必须是唯一,不能出现重复情况;
唯一约束不可以作为其它表的外键,但是可以有多个唯一约束字段;
(5) 默认约束 1 2 3 4 CREATE TABLE IF NOT EXISTS T2 ( name VARCHAR (10 ) NOT NULL , sex ENUM('F' ,'M' ,'UN' ) DEFAULT 'UN' );
1.DQL 数据查询语句 SELECT 语句 基础语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY ] [STRAIGHT_JOIN ] [SQL_SMALL_RESULT ] [SQL_BIG_RESULT ] [SQL_BUFFER_RESULT ] [SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS ] select_expr [, select_expr] ... [into_option] [FROM table_references [PARTITION partition_list]] [WHERE where_condition] [GROUP BY {col_name | expr | position }, ... [WITH ROLLUP ]] [HAVING where_condition] [WINDOW window_name AS (window_spec) [, window_name AS (window_spec)] ...] [ORDER BY {col_name | expr | position } [ASC | DESC ], ... [WITH ROLLUP ]] [LIMIT {[offset ,] row_count | row_count OFFSET offset }] [into_option] [FOR {UPDATE | SHARE } [OF tbl_name [, tbl_name] ...] [NOWAIT | SKIP LOCKED ] | LOCK IN SHARE MODE ] [into_option] into_option: { INTO OUTFILE 'file_name' [CHARACTER SET charset_name] export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name] ... }
基础语法说明: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 SELECT [*] [列名1 ,列名2 ] FROM 表名 [WHERE 条件] 字段 比较运算符 列值; IN (列值1,列值2) ; BETWEEN 10 AND 20; LIKE '%Nord_' NOT LIKE '%Nord_' LIMIT 0,10 REGEXP '正则表达式' SELECT [DISTINCT ] [*] [列名1 ,列名2 ] FROM 表名 [WHERE 条件] SELECT 聚合函数(自字段) FROM 表名 [WHERE 条件] SELECT name AS '字段别名' , grade AS '字段别名' FROM 表名 [WHERE 条件] SELECT [列名1 ,列名2 ] FROM 表名 [WHERE 条件] ORDER BY 列名1 ,列名2 [DESC | ASC ] SELECT [列名1 ,列名2 ] FROM 表名1 AS 表别名1 ,表名2 AS 表别名2 [WHERE 条件] GROUP BY 组名 HAVING 条件 SELECT [列名1 ,列名2 ] FROM 表名1 AS 表别名1 ,表名2 AS 表别名2 [WHERE 条件] GROUP BY 组名 WITH ROLLUP ; SELECT 字段1 ,聚合函数(字段) FROM 表 GROUP BY 需要分组的字段名称 HAVING [聚合函数(字段)] 分组显示条件
基础示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT * FROM table LIMIT 5 ; SELECT * FROM table LIMIT 5 ,10 ; SELECT product_name,price,(price * 80 ) AS discount WHERE product;SELECT Id ,Name ,Population FROM City WHERE ID IN (100 ,101 );SELECT id ,name ,Country FROM city REGEXP '^c' AND quxian REGEXP 'g$' ; SELECT avg (price) FROM product; SELECT * FROM product WHERE price > (SELECT avg (price) FROM product) SELECT product_type,count (*) FROM product GROUP BY product_type;SELECT * FROM city WHERE id < 10 GROUP BY ConuntryCode,District;SELECT product_type,avg (price) FROM product GROUP BY product_type HAVING avg (price) > 60 ;
注意事项:
注:WHERE 子句后不能直接接聚合函数需要在分组之前选择数据(WHERE排除的数据不参加分组),而分组中的HAVING可以直接接聚合函数在分组之后过滤数据;
注:总结出查询的SQL语句的编写顺序:SELECT . FROM . WHERE . GROUP BY . HAVING . ORDER BY;
注:总结出执行顺序FROM . WHERE . GROUP BY . HAVING . SELECT . ORDEY BY;
注:AND 和 OR 可以一起使用,但是前者的优先级大于后者优先级;
注:多列排序安装选后进行排序,中间用逗号进行分隔;
注:进行SELECT查询语句的时候避免出现*,而是选出您想查询的字段并且在SELECT语句中清除的写出来;
注:当表中的数据量很大时候慎用集合函数,并且使用Group BY 和 Order By 语句也会大大增加执行查询的效率;
注:对于经常出现了WHERE条件中的字段进行建立索引,以提高速度;
2.DDL 数据定义语句 描述:原子数据定义语句支持也叫原子DDL语句,通过在MySQL 8.0中引入MySQL数据字典,可以实现原子DDL。事务在操作期间停止,事务也可以提交,并在数据字典,存储引擎和二进制日志中保留适用的更改,或者回滚。
支持的DDL语句
1.原子DDL功能支持表DDL语句和非表DDL语句(当前仅InnoDB存储引擎支持原子DDL),与表相关的DDL操作需要存储引擎支持,而非表DDL操作则不需要;
2.表DDL语句:CREATE,ALTER和 DROP 数据库,表空间,表和索引以及TRUNCATE TABLE语句;
3.非表DDL语句: CREATE和DROP 语句,以及(如果适用)ALTER 存储程序,触发器,视图和用户定义函数(UDF)的语句, 账户管理语句: CREATE,ALTER, DROP,如果适用RENAME报表用户和角色,以及GRANT 和REVOKE报表。
原子DDL特性
1.在DDL操作期间SQL层没有中间提交, 元数据更新,二进制日志写入和存储引擎操作(如果适用)组合为一个事务。
2.DDL操作的可见行为是原子的,这会更改某些DDL语句的行为。注意:DDL语句(原子的或其他方式)隐式结束当前会话中处于活动状态的任何事务,就好像您COMMIT在执行该语句之前已执行了。
DDL语句行为的变化
存储引擎支持
查看DDL日志
CREATE 语句 描述:CREATE 语句主要是用来创建数据库、表、视图、
CREATE DATABASE
CREATE TABLE
CREATE VIEW
CREATE DATABASE 语句 基础语法:1 2 3 4 5 6 7 8 9 10 CREATE {DATABASE | SCHEMA } [IF NOT EXISTS ] db_name [create_specification] ... [DEFAULT ] CHARACTER SET [=] charset_name | [DEFAULT ] COLLATE [=] collation_name | DEFAULT ENCRYPTION [=] {'Y' | 'N' } CREATE {DATABASE | SCHEMA } [IF NOT EXISTS ] 数据库名称 DEFAULT CHARACTER SET = 字符集 COLLATE = 校队规则 ENCRYPTION = 'Y'
基础实例:1 2 3 4 5 6 7 8 9 SHOW CHARACTER SET ;SHOW COLLATION LIKE 'UTF8%' ;CREATE DATABASE IF NOT EXISTS black_hack DEFAULT CHARACTER SET = 'utf8mb4' COLLATE = 'utf8mb4_bin' ;SHOW CREATE DATABASE black_hack;
注意事项:
注1:如果数据库存在并且您未指定IF NOT EXISTS则会发生错误
注2:在LOCK TABLES语句的会话中不允许使用CREATE DATABASES;
注3:如果不指定校队规则就默认采用 utf8mb4_0900_ai_ci
CREATE TABLE 语句 基础语法:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 CREATE [TEMPORARY ] TABLE [IF NOT EXISTS ] tbl_name (create_definition,...) [table_options] [partition_options] CREATE [TEMPORARY ] TABLE [IF NOT EXISTS ] tbl_name [(create_definition,...)] [table_options] [partition_options] [IGNORE | REPLACE ] [AS ] query_expression CREATE [TEMPORARY ] TABLE [IF NOT EXISTS ] tbl_name { LIKE old_tbl_name | (LIKE old_tbl_name) } create_definition: col_name column_definition | {INDEX |KEY } [index_name] [index_type] (key_part,...) [index_option] ... | {FULLTEXT|SPATIAL} [INDEX |KEY ] [index_name] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] UNIQUE [INDEX |KEY ] [index_name] [index_type] (key_part,...) [index_option] ... | [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (col_name,...) reference_definition | check_constraint_definition column_definition: data_type [NOT NULL | NULL ] [DEFAULT {literal | (expr)} ] [AUTO_INCREMENT] [UNIQUE [KEY ]] [[PRIMARY] KEY ] [COMMENT 'string' ] [COLLATE collation_name] [COLUMN_FORMAT {FIXED |DYNAMIC|DEFAULT }] [STORAGE {DISK|MEMORY }] [reference_definition] [check_constraint_definition] | data_type [COLLATE collation_name] [GENERATED ALWAYS ] AS (expr) [VIRTUAL | STORED ] [NOT NULL | NULL ] [UNIQUE [KEY ]] [[PRIMARY] KEY ] [COMMENT 'string' ] [reference_definition] [check_constraint_definition] data_type: (see Chapter 11 , Data Types) key_part: {col_name [(length )] | (expr)} [ASC | DESC ] index_type: USING {BTREE | HASH } index_option: KEY_BLOCK_SIZE [=] value | index_type | WITH PARSER parser_name | COMMENT 'string' | {VISIBLE | INVISIBLE } check_constraint_definition: [CONSTRAINT [symbol]] CHECK (expr) [[NOT ] ENFORCED ] reference_definition: REFERENCES tbl_name (key_part,...) [MATCH FULL | MATCH PARTIAL | MATCH SIMPLE] [ON DELETE reference_option] [ON UPDATE reference_option] reference_option: RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT table_options: table_option [[,] table_option] ... table_option: AUTO_INCREMENT [=] value | AVG_ROW_LENGTH [=] value | [DEFAULT ] CHARACTER SET [=] charset_name | CHECKSUM [=] {0 | 1 } | [DEFAULT ] COLLATE [=] collation_name | COMMENT [=] 'string' | COMPRESSION [=] {'ZLIB' |'LZ4' |'NONE' } | CONNECTION [=] 'connect_string' | {DATA |INDEX } DIRECTORY [=] 'absolute path to directory' | DELAY_KEY_WRITE [=] {0 | 1 } | ENCRYPTION [=] {'Y' | 'N' } | ENGINE [=] engine_name | INSERT_METHOD [=] { NO | FIRST | LAST } | KEY_BLOCK_SIZE [=] value | MAX_ROWS [=] value | MIN_ROWS [=] value | PACK_KEYS [=] {0 | 1 | DEFAULT } | PASSWORD [=] 'string' | ROW_FORMAT [=] {DEFAULT |DYNAMIC|FIXED |COMPRESSED|REDUNDANT|COMPACT } | STATS_AUTO_RECALC [=] {DEFAULT |0 |1 } | STATS_PERSISTENT [=] {DEFAULT |0 |1 } | STATS_SAMPLE_PAGES [=] value | TABLESPACE tablespace_name [STORAGE {DISK|MEMORY }] | UNION [=] (tbl_name[,tbl_name]...) partition_options: PARTITION BY { [LINEAR] HASH (expr) | [LINEAR] KEY [ALGORITHM={1 |2 }] (column_list) | RANGE {(expr) | COLUMNS (column_list)} | LIST {(expr) | COLUMNS (column_list)} } [PARTITIONS num ] [SUBPARTITION BY { [LINEAR] HASH (expr) | [LINEAR] KEY [ALGORITHM={1 |2 }] (column_list) } [SUBPARTITIONS num ] ] [(partition_definition [, partition_definition] ...)] partition_definition: PARTITION partition_name [VALUES {LESS THAN {(expr | value_list) | MAXVALUE} | IN (value_list)}] [[STORAGE ] ENGINE [=] engine_name] [COMMENT [=] 'string' ] [DATA DIRECTORY [=] 'data_dir' ] [INDEX DIRECTORY [=] 'index_dir' ] [MAX_ROWS [=] max_number_of_rows] [MIN_ROWS [=] min_number_of_rows] [TABLESPACE [=] tablespace_name] [(subpartition_definition [, subpartition_definition] ...)] subpartition_definition: SUBPARTITION logical_name [[STORAGE ] ENGINE [=] engine_name] [COMMENT [=] 'string' ] [DATA DIRECTORY [=] 'data_dir' ] [INDEX DIRECTORY [=] 'index_dir' ] [MAX_ROWS [=] max_number_of_rows] [MIN_ROWS [=] min_number_of_rows] [TABLESPACE [=] tablespace_name] query_expression: SELECT ... (Some valid select or union statement ) CREATE TABLE [IF NOT EXISTS ] 数据库名称 ( 列名1 类型(长度) 约束 COMMENT '描述1' , 列名2 类型(长度) 约束 COMMENT '描述2' , PRIMARY KEY (列名1 ) INDEX (列名1 ) ) ENGINE =引擎 AUTO_INCREMENT=自增起始 DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_0900_ai_ci ;
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 CREATE TABLE `Persons` ( `ID` int (11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID序号' , `LastName` varchar (255 ) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '名称' , PRIMARY KEY (`ID` ) ) ENGINE =InnoDB AUTO_INCREMENT=112 DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_0900_ai_ci CREATE TABLE t1 ( id INT PRIMARY KEY , name VARCAHR(255 ), INDEX mul_index (id ,name ) ); create table record ( id int (11 ) NOT NULL PRIMARY KEY AUTO_INCREMENT, wybug_id longtext NOT NULL , rtime datetime, INDEX mul_index (wybug_id) ); mysql> SHOW TABLES; mysql> SHOW CREATE TABLE Persons; mysql> DESC Persons;
注意事项:
1.默认情况下表是使用InnoDB存储引擎在默认数据库中创建的;
2.如果该表存在没有默认数据库或该数据库不存在则会发生错误。
3.MySQL对表的数量没有限制。基础文件系统可能会对表示表的文件数量有所限制。
CREATE VIEW 语句 描述:它可以创建或者替换现有的视图它将会始时的刷新拉取数据,视图定义受以下限制:
1.SELECT语句不能引用系统变量或用户定义的变量
2.存储的程序SELECT语句不能引用程序参数或局部变量
3.SELECT语句不能引用准备好的语句参数
4.定义中引用的任何表或视图都必须存在
5.不能引用TEMPORARY 表,也不能创建TEMPORARY 视图;
6.无法将触发器与视图关联。
7.SELECT语句中列名的别名将根据最大列长度64个字符(而不是最大别名长度256个字符)进行检查。
基础语法:1 2 3 4 5 6 7 8 9 10 CREATE [OR REPLACE ] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] [DEFINER = user ] [SQL SECURITY { DEFINER | INVOKER }] VIEW view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL ] CHECK OPTION ] CREATE VIEW 视图名称 AS SELECT 字段1 ,字段2 FROM 数据库;
基础示例:
1 2 3 4 5 6 7 8 9 10 11 12 CREATE VIEW login_log AS SELECT id ,userLogin,loginTime FROM user_log ORDER BY id DESC ; SHOW CREATE TABLE login_log;SELECT * FROM login_log;| View | Create View | character_set_client | collation_connection | | | login_lo | CREATE ALGORITHM=UNDEFINED DEFINER=`root` @`%` SQL SECURITY DEFINER VIEW `login_log` AS select `user_log` .`id` AS `id` ,`user_log` .`userLogin` AS `userLogin` ,`user_log` .`loginTime` AS `loginTime` from `user_log` order by `user_log` .`id` desc | utf8mb4 | utf8mb4_0900_ai_ci |
CREATE INDEX 语句 描述:除了采用在CREATE TABLE 和 ALTER TABLE 添加索引外此原语句也是没有问题的;
基础语法:1 CREATE INDEX 索引名称 ON 表(字段)
实际案例:1 CREATE INDEX name_ind ON t4(name );
CREATE USER 语句 描述:
基础语法:1 2 3 4 5 6 CREATE USER 'username' @'host' IDENTIFIED BY 'password' ;username host password
ALTER 语句 描述:修改数据库,修改表和列(修改表的字符集)添加add列,修改modify列,修改change列名,删除drop列,需要注意如果表中已有数据时候慎用;
1.ALLTER DATABASE
2.ALLTER TABLE
ALTER DATABASE 语句 基础语法:1 2 3 4 5 6 7 ALTER {DATABASE | SCHEMA } [db_name] alter_specification ... alter_specification: [DEFAULT ] CHARACTER SET [=] charset_name | [DEFAULT ] COLLATE [=] collation_name | DEFAULT ENCRYPTION [=] {'Y' | 'N' }
ALTER TABLE 语句 基础语法:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 ALTER TABLE tbl_name [alter_specification [, alter_specification] ...] [partition_options] alter_specification: table_options | ADD [COLUMN ] col_name column_definition [FIRST | AFTER col_name] | ADD [COLUMN ] (col_name column_definition,...) | ADD {INDEX |KEY } [index_name] [index_type] (key_part,...) [index_option] ... | ADD {FULLTEXT|SPATIAL} [INDEX |KEY ] [index_name] (key_part,...) [index_option] ... | ADD [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (key_part,...) [index_option] ... | ADD [CONSTRAINT [symbol]] UNIQUE [INDEX |KEY ] [index_name] [index_type] (key_part,...) [index_option] ... | ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (col_name,...) reference_definition | ADD [CONSTRAINT [symbol]] CHECK (expr) [[NOT ] ENFORCED ] | DROP {CHECK |CONSTRAINT } symbol | ALTER {CHECK |CONSTRAINT } symbol [NOT ] ENFORCED | ALGORITHM [=] {DEFAULT |INSTANT|INPLACE|COPY} | ALTER [COLUMN ] col_name {SET DEFAULT {literal | (expr)} | DROP DEFAULT } | ALTER INDEX index_name {VISIBLE | INVISIBLE } | CHANGE [COLUMN ] old_col_name new_col_name column_definition [FIRST |AFTER col_name] | [DEFAULT ] CHARACTER SET [=] charset_name [COLLATE [=] collation_name] | CONVERT TO CHARACTER SET charset_name [COLLATE collation_name] | {DISABLE |ENABLE } KEYS | {DISCARD|IMPORT } TABLESPACE | DROP [COLUMN ] col_name | DROP {INDEX |KEY } index_name | DROP PRIMARY KEY | DROP FOREIGN KEY fk_symbol | FORCE | LOCK [=] {DEFAULT |NONE |SHARED |EXCLUSIVE} | MODIFY [COLUMN ] col_name column_definition [FIRST | AFTER col_name] | ORDER BY col_name [, col_name] ... | RENAME COLUMN old_col_name TO new_col_name | RENAME {INDEX |KEY } old_index_name TO new_index_name | RENAME [TO |AS ] new_tbl_name | {WITHOUT |WITH } VALIDATION partition_options: partition_option [partition_option] ... partition_option: ADD PARTITION (partition_definition) | DROP PARTITION partition_names | DISCARD PARTITION {partition_names | ALL } TABLESPACE | IMPORT PARTITION {partition_names | ALL } TABLESPACE | TRUNCATE PARTITION {partition_names | ALL } | COALESCE PARTITION number | REORGANIZE PARTITION partition_names INTO (partition_definitions) | EXCHANGE PARTITION partition_name WITH TABLE tbl_name [{WITH |WITHOUT } VALIDATION ] | ANALYZE PARTITION {partition_names | ALL } | CHECK PARTITION {partition_names | ALL } | OPTIMIZE PARTITION {partition_names | ALL } | REBUILD PARTITION {partition_names | ALL } | REPAIR PARTITION {partition_names | ALL } | REMOVE PARTITIONING key_part: {col_name [(length )] | (expr)} [ASC | DESC ] index_type: USING {BTREE | HASH } index_option: KEY_BLOCK_SIZE [=] value | index_type | WITH PARSER parser_name | COMMENT 'string' | {VISIBLE | INVISIBLE } table_options: table_option [[,] table_option] ... table_option: AUTO_INCREMENT [=] value | AVG_ROW_LENGTH [=] value | [DEFAULT ] CHARACTER SET [=] charset_name | CHECKSUM [=] {0 | 1 } | [DEFAULT ] COLLATE [=] collation_name | COMMENT [=] 'string' | COMPRESSION [=] {'ZLIB' |'LZ4' |'NONE' } | CONNECTION [=] 'connect_string' | {DATA |INDEX } DIRECTORY [=] 'absolute path to directory' | DELAY_KEY_WRITE [=] {0 | 1 } | ENCRYPTION [=] {'Y' | 'N' } | ENGINE [=] engine_name | INSERT_METHOD [=] { NO | FIRST | LAST } | KEY_BLOCK_SIZE [=] value | MAX_ROWS [=] value | MIN_ROWS [=] value | PACK_KEYS [=] {0 | 1 | DEFAULT } | PASSWORD [=] 'string' | ROW_FORMAT [=] {DEFAULT |DYNAMIC|FIXED |COMPRESSED|REDUNDANT|COMPACT } | STATS_AUTO_RECALC [=] {DEFAULT |0 |1 } | STATS_PERSISTENT [=] {DEFAULT |0 |1 } | STATS_SAMPLE_PAGES [=] value | TABLESPACE tablespace_name [STORAGE {DISK|MEMORY }] | UNION [=] (tbl_name[,tbl_name]...) partition_options: (see CREATE TABLE options) ALTER TABLE 表名 ADD [COLUMN ] 列名 类型 约束 [FIRST |AFTER ] 已存在的字段名;ALTER TABLE 表名 MODIFY [COLUMN ] 列名 类型 约束 [FIRST |AFTER ] 已存在的字段名;ALTER TABLE 表名 CHANGE [COLUMN ] 旧列名 新列名 类型 约束;ALTER TABLE 表名 DROP [COLUMN ] 列名;ALTER TABLE 表名 DROP FOREIGN KEY 外键名; ALTER TABLE 表名 ENGINE =存储引擎;ALTER TABLE 表名 CHARACTER SET 字符集;ALTER TABLE 旧表名 RENAME 新表名;ALTER TABLE 表名 ADD INDEX 索引名称 (需要添加索引的字段)ALTER TABLE 表名 DROP INDEX 索引名称;
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 mysql> ALTER TABLE Persons CHARACTER SET = 'gbk'; MySQL [Demo]> ALTER TABLE Person RENAME Per; MySQL [Demo]> ALTER TABLE Per ENGINE=MYISAM; MySQL [Demo]> SHOW CREATE TABLE Per\G; Table: Per Create Table : CREATE TABLE `Per` ( `id` int (11 ) NOT NULL COMMENT 'Desc' , PRIMARY KEY (`id` ) ) ENGINE =MyISAM DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_0900_ai_ci 1 row in set (0.05 sec)ALTER TABLE t4 ADD INDEX name_ind (name (20 ));ALTER TABLE t4 DROP INDEX name_ind;ALTER TABLE t4 ADD UNIQUE INDEX name_ind1 (name (20 ));ALTER TABLE t4 DROP UNIQUE INDEX name_ind1;
RENAME TABLE 语句 描述:RENAME TABLE重命名一个或多个表,您必须具有ALTER与 DROP原始表的权限以及CREATE与INSERT新表的权限。
1 2 3 4 5 6 7 RENAME TABLE tbl_name TO new_tbl_name [, tbl_name2 TO new_tbl_name2] ... RENAME TABLE 旧表名1 TO 新表名1 ,旧表名2 TO 新表名2 ;
基础示例:1 2 3 4 5 6 LOCK TABLE old_table1 WRITE;RENAME TABLE old_table1 TO new_table1,new_table1 TO new_table2;RENAME TABLE current_db.tbl_name TO other_db.tbl_name;
DROP 语句 描述:删除数据库或者表,注意删除后无法通过日志恢复;
基础语法1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 DROP {DATABASE | SCHEMA } [IF EXISTS ] 数据库名称DROP [TEMPORARY ] TABLE [IF EXISTS ] 数据库表名称1 [, 数据库表名称2 ] ... [RESTRICT | CASCADE ] DROP INDEX index_name ON tbl_name [algorithm_option | lock_option] ... algorithm_option: ALGORITHM [=] {DEFAULT |INPLACE|COPY} lock_option: LOCK [=] {DEFAULT |NONE |SHARED |EXCLUSIVE} DROP VIEW [IF EXISTS ] view_name [, view_name] ... [RESTRICT | CASCADE ]
基础示例:1 2 DROP INDEX name_ind ON t4;
TRUNCATE 语句 描述:TRUNCATE TABLE完全清空一张表它需要DROP 特权,从逻辑上讲它类似于DELETE删除所有行的语句或DROP TABLE 语句的序列,但是其中实现过程以及性能耗费的时间是不同的;
基础语法:1 TRUNCATE [TABLE ] tbl_name
补充知识点:
它与DELETE语句块的异同(前者先删除表再重建表,而后者一条一条删除表中的数据):执行速度,隐式提交因此无法回滚,只要表定义有效即使数据或索引文件已损坏也能重新创建空白表,将AUTO_INCREMENT值重置为其初始值,不调用ON DELETE触发器。
如果数据少DELETE效率高,否则数据多的话建议采用TRUNCATE;
3.DML 数据操纵语句 INSERT 语句 描述:批量插入比单条插入效率高,如果数据处理不好容易出现BUG;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [(col_name [, col_name] ...)] { {VALUES | VALUE } (value_list) [, (value_list)] ... | VALUES row_constructor_list } [AS row_alias[(col_alias [, col_alias] ...)]] [ON DUPLICATE KEY UPDATE assignment_list] INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [AS row_alias[(col_alias [, col_alias] ...)]] SET assignment_list [ON DUPLICATE KEY UPDATE assignment_list] INSERT [LOW_PRIORITY | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [(col_name [, col_name] ...)] [AS row_alias[(col_alias [, col_alias] ...)]] {SELECT ... | TABLE table_name} [ON DUPLICATE KEY UPDATE assignment_list] value : {expr | DEFAULT } value_list: value [, value ] ... row_constructor_list: ROW (value_list)[, ROW (value_list)][, ...] assignment: col_name = [row_alias.]value assignment_list: assignment [, assignment] ...
基础语法:1 2 3 4 INSERT INTO 表名 SET 列名1 =Value1,列名2 =Values2;INSERT INTO 表名(列名1 ,列名2 ,列名3 ) VALUES (value1,value2,value3,...),(value1,value2,value3,...);
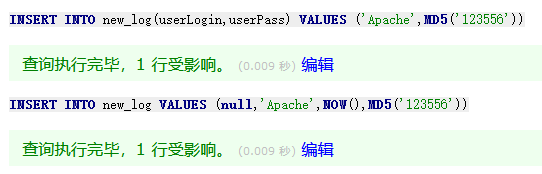
基础示例:1 2 3 4 5 6 7 8 INSERT INTO new_log SET userLogin='Admin' ,userPass='123456' ;INSERT INTO new_log(userLogin,userPass) VALUES ('Apache' ,MD5 ('123556' ));INSERT INTO new_log VALUES (null ,'Apache' ,NOW (),MD5 ('123556' ));
weiyigeek.top-INSERT数据插入
注意事项:
当字段设置了非NULL约束的时候,在插入时需要进行指定其值,否则插入报错;
INSERT…SELECT 语句 描述:从SELECT
基础语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 INSERT [LOW_PRIORITY | HIGH_PRIORITY ] [IGNORE ] [INTO ] tbl_name [PARTITION (partition_name [, partition_name] ...)] [(col_name [, col_name] ...)] {SELECT ... | TABLE table_name} [ON DUPLICATE KEY UPDATE assignment_list] value : {expr | DEFAULT } assignment: col_name = value assignment_list: assignment [, assignment] ... INSERT INTO 表名 (字段1 ,字段2 ,字段3 ) SELECT 字段1 ,字段2 ,字段3 FROM tbl_temp1 WHERE 条件;
基础示例:1 2 3 4 5 6 7 INSERT INTO Persons(lastName,userPass) SELECT userLogin,userPass FROM user_log查询执行完毕,3 行受影响。 CREATE TABLE new_log LIKE user_log; INSERT INTO new_log SELECT * FROM user_log;
注意事项:
从MySQL 8.0.19开始,您可以使用 TABLESELECT1 INSERT INTO ta TABLE tb;
要求数据库,表,存在并且,字段类型数量是一致的
UPDATE 语句 描述:UPDATE 是DML语句,用于修改表中的行用于更新表记录,需要注意如果不加添条件加则会修改表中指定字段的所有值;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 UPDATE [LOW_PRIORITY ] [IGNORE ] table_reference SET assignment_list [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ] value : {expr | DEFAULT } assignment: col_name = value assignment_list: assignment [, assignment] .. UPDATE [LOW_PRIORITY ] [IGNORE ] table_references SET assignment_list [WHERE where_condition] UPDATE 表名 SET 列名=列值,列名2 =列值 [WHERE 条件]
基础案例:
DELETE 语句 描述:删除表中的数据会在日志中记录,并且需要注意如果不加上WHERE条件默认是整表数据库删除删除;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] FROM tbl_name [[AS ] tbl_alias] [PARTITION (partition_name [, partition_name] ...)] [WHERE where_condition] [ORDER BY ...] [LIMIT row_count ] DELETE [LOW_PRIORITY ] [QUICK ] [IGNORE ] tbl_name[.*] [, tbl_name[.*]] ... FROM table_references [WHERE where_condition] DELETE FROM 表名 [WHERE 条件]
基础示例:1 2 DELETE new_log,user_log FROM user_log LEFT JOIN new_log ON new_log.id = user_log.id WHERE user_log.id = new_log.id;
4.DCL 数据控制语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 mysql> show CHARACTER SET; + | Charset | Description | Default collation | Maxlen | + | ascii | US ASCII | ascii_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 | | utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 | mysql> SHOW COLLATION LIKE 'UTF8%'; + | Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute | + | utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE | mysql> SHOW CREATE DATABASE black_hack; | Database | Create Database | black_hack | CREATE DATABASE `black_hack` mysql> SHOW TABLES ; + | Tables_in_Demo | + | Aggregate | mysql> SHOW CREATE TABLE Persons; | Persons | CREATE TABLE `Persons` ( `ID` int (11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID序号' , `LastName` varchar (255 ) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '名称' , PRIMARY KEY (`ID` ) ) ENGINE =InnoDB AUTO_INCREMENT=112 DEFAULT CHARSET =utf8mb4 COLLATE =utf8mb4_0900_ai_ci |