[TOC]
0x00 前言 描述:本文章主要针对于本人日常运维所遇到的一些性能问题并进行总结解决思路流程;
无论是 CPU 使用率,还是平均负载,都只是反映系统健康状态的度量指标,而不是问题的根因;
因此它们的价值主要体现在两个方面:
一是综合反映当前系统的健康程度,结合监控告警产品,实现快速响应;
二是初步定位问题方向,缩小排查范围,降低故障恢复时间。
比如当 CPU iowait 高时,应优先排查磁盘 I/O;当 CPU steal 高时,就优先排查宿主机状态。
#### 0x01 Linux信息收集
描述:当我们对异常系统进行处理,必须先进行主机基础信息的收集,以防出错后可以更快的恢复或者求助;
CentOS系列:
[TOC]
0x00 前言 描述:本文章主要针对于本人日常运维所遇到的一些性能问题并进行总结解决思路流程;
无论是 CPU 使用率,还是平均负载,都只是反映系统健康状态的度量指标,而不是问题的根因;
因此它们的价值主要体现在两个方面:
一是综合反映当前系统的健康程度,结合监控告警产品,实现快速响应;
二是初步定位问题方向,缩小排查范围,降低故障恢复时间。
比如当 CPU iowait 高时,应优先排查磁盘 I/O;当 CPU steal 高时,就优先排查宿主机状态。
#### 0x01 Linux信息收集
描述:当我们对异常系统进行处理,必须先进行主机基础信息的收集,以防出错后可以更快的恢复或者求助;
CentOS系列:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #!/bin/bash echo "系统版本:$(cat /etc/redhat-release) " echo "内核信息:$(uname -a) " echo "SeLinux values 设置情况:$(getenforce) " echo -e "用户信息:\n$(getent passwd) " echo -e "密码信息:\n$(getent shadow) " echo -e "网络信息:\n$(ip addr show) " echo "CPU信息:$(cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c) " echo "物理CPU数:$(cat /proc/cpuinfo |grep 'physical id'|sort |uniq|wc -l) " echo "逻辑CPU数:$(cat /proc/cpuinfo |grep "processor"|wc -l) " echo "CPU核心数:$(cat cat /proc/cpuinfo |grep "cores"|uniq) " echo "CPU综合信息:\n$(lscpu) " echo -e "磁盘UUID信息:\n$(blkid) " echo -e "磁盘信息:\n$(fdisk -l | egrep '/dev|Disk') " echo -e "磁盘分区信息:\n$(lsblk) " echo -e "磁盘空间信息:\n$(df -h) " echo -e "挂载信息:\n$(mount -l) " echo -e "挂载配置文件:\n$(cat /etc/fstab | egrep -v '#|^$') "
CPU:通过下面的脚本来打印出当前机器的socket,core和thread的数量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 #!/bin/bash function get_nr_processor(){ grep '^processor' /proc/cpuinfo | wc -l } function get_nr_socket(){ grep 'physical id' /proc/cpuinfo | awk -F: '{ print $2 | "sort -un"}' | wc -l} function get_nr_siblings(){ grep 'siblings' /proc/cpuinfo | awk -F: '{ print $2 | "sort -un"}' } function get_nr_cores_of_socket(){ grep 'cpu cores' /proc/cpuinfo | awk -F: '{ print $2 | "sort -un"}' } echo '===== CPU Topology Table =====' echo echo '+--------------+---------+-----------+' echo '| Processor ID | Core ID | Socket ID |' echo '+--------------+---------+-----------+' while read line; do if [ -z "$line " ]; then printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id echo '+--------------+---------+-----------+' continue fi if echo "$line " | grep -q "^processor" ; then p_id=`echo "$line " | awk -F: '{print $2}' | tr -d ' ' ` fi if echo "$line " | grep -q "^core id" ; then c_id=`echo "$line " | awk -F: '{print $2}' | tr -d ' ' ` fi if echo "$line " | grep -q "^physical id" ; then s_id=`echo "$line " | awk -F: '{print $2}' | tr -d ' ' ` fi done < /proc/cpuinfoecho awk -F: '{ if ($1 ~ /processor/) { gsub(/ /,"",$2); p_id=$2; } else if ($1 ~ /physical id/){ gsub(/ /,"",$2); s_id=$2; arr[s_id]=arr[s_id] " " p_id } } END{ for (i in arr) printf "Socket %s:%s\n", i, arr[i]; }' /proc/cpuinfoecho echo '===== CPU Info Summary =====' echo nr_processor=`get_nr_processor` echo "Logical processors: $nr_processor " nr_socket=`get_nr_socket` echo "Physical socket: $nr_socket " nr_siblings=`get_nr_siblings` echo "Siblings in one socket: $nr_siblings " nr_cores=`get_nr_cores_of_socket` echo "Cores in one socket: $nr_cores " let nr_cores*=nr_socketecho "Cores in total: $nr_cores " if [ "$nr_cores " = "$nr_processor " ]; then echo "Hyper-Threading: off" else echo "Hyper-Threading: on" fi echo echo '===== END ====='
0x02 异常解决 如何排查用户态 CPU 使用率高?
问题1.业务服务器 CPU 占用负载高问题
排查思路:1 2 3 4 5 6 7 8 9 10 $top -n 1$top -Hp [PID]printf "0x%x" [PID] jstack 1040|vim +/0x431 - pwdx [PID]
weiyigeek.top-CPU占用率高
关于centos启动报错:Failed to start Crash recovery kernel arming的解决方案 在VMware中安装了centos,重启时报错:Failed to start Crash recovery kernel arming
本质是kdump服务启动失败
先来说一下,什么是kdump
Kdump是一个内核崩溃转储机制,在系统崩溃的时候,Kdump将捕获系统信息,这对于针对崩溃的原因非常有帮助。注意,Kdump需要预留一部分系统内存,而且这部分内存对于其他用户是不可用的。
启动失败的原因
查看 /etc/grub.conf 文件,发现crashkernel=auto,问题就出在这儿:
注:centos7 后为:vi /etc/grub2.cfg
系统对crashkernel=auto的定义为:
如果系统的内存 <= 8 GB 对kdump kernel不会保留任何内容;也就是说,crashkernel=auto 等
于关掉了机器上的kdump功能;
安装虚拟机时,给虚拟机设置的内存为1G,所以说系统关掉了kdump功能,造成了kdump服务启动失败。
找到了原因,重新给crashkernel设置参数即可:
在 kdump 的配置中,往往困惑于 crashkernel 的设置。“crashkernel=X@Y”,X 应该多大? Y
又应该设在哪里呢?实际我们可以完全省略“@Y”这一部分,这样,kernel 会为我们自动选择
一个起始地址。而对于 X 的大小,般对 i386/x86_64 的系统, 设为 128M 即可;对于 powerpc
的系统,则要设为 256M。
将crashkernel=auto 改为crashkernel=128M 后保存,如果还不能解决问题,改为256m试试
重新启动系统,kdump服务启动成功。
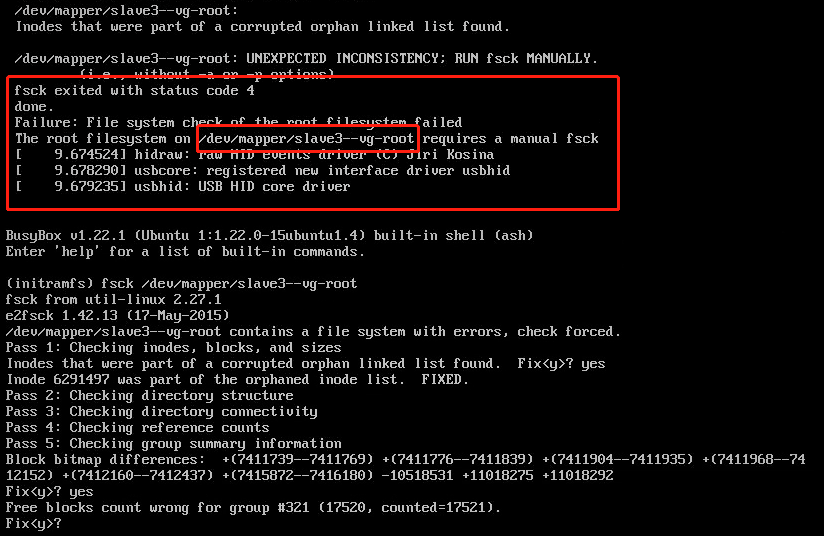
Ubuntu 宕机之Failure:File system check of the root filesystem failed错误。 描述: Linux宕机后重启系统开机报Failure:File system check of the root filesystem failed,由于公司测试的ESXi因为意外断电重启后发现Ubuntu进行入了initramfs模式。1 2 fsck -yf /dev/mappeer/slave3–vg-root ctrl+d
weiyigeek.top-