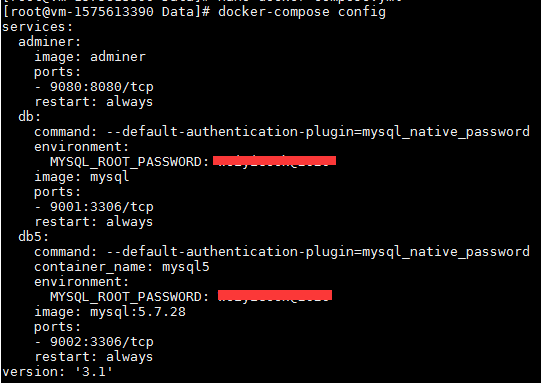
#手动运行容器 $ docker run --name mysql-test -e MYSQL_ROOT_PASSWORD=my-secret-pw --default-authentication-plugin=mysql_native_password -d mysql:tag $ docker run -it --network some-network --rm mysql mysql -hsome-mysql -uexample-user -p #对Docker网络中的MySQL进行连接 $ docker run -it --rm mysql mysql -hsome.mysql.host -usome-mysql-user -p #连接其他MySQL
#测试查询 docker ps # CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES # 4ba28666e63f adminer "entrypoint.sh doc..." 45 hours ago Up 44 hours 0.0.0.0:9080->8080/tcp data_adminer_1 # 2172955ddedc mysql "docker-entrypoint..." 45 hours ago Up 44 hours 33060/tcp, 0.0.0.0:9001->3306/tcp data_db_1 ...
/* SQL SELECT 语法 */ SELECT [DISTINCT] column_name,column_name FROM table_name WHERE column_name operatorvalue;
/* DISTINCT 语句用于返回唯一不同的值,在表中一个列可能会包含多个重复值仅仅列出不同的值 */ /* WHERE 子句用于提取那些满足指定标准的记录。*/ SELECTDISTINCT 字段名 FROM 表名 WHERE 查询条件;
/* LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式 */ SELECT column_name(s) FROM table_name WHERE column_name [LIKE|REGEXP] pattern;
/* BETWEEN AND (在之间的值) 字句在此之间的值*/ SELECT 字段名 FROM 表名 WHERE 字段名 BETWEEN 初始值 AND 终止值;
/* ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。(注意这里无WHERE)*/ /* DESC 降序 , ASC 升序(默认),即 desc 或者 asc 只对它紧跟着的第一个列名有效其他不受影响,仍然是默认的升序*/ SELECT column_name,column_name FROM table_name ORDERBY column_name1 ASC|DESC,column_name2 ASC|DESC;
/* SQL limit 子句,查询前n条/后n条记录(分页常用) */ SELECT 字段 FROM 表名 WHERE 查询条件 LIMIT 起始,结束
/* SQL 多表查询 */ SELECT 数据库.表,mysql.user FROM 数据库,mysql WHERE1
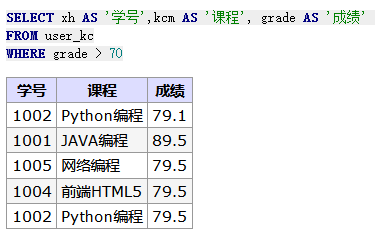
/* GROUP BY 语法 */ SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operatorvalue GROUPBY column_name;
/* HAVING 语法筛选分组后的各组数据*/ SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operatorvalue GROUPBY column_name HAVING aggregate_function(column_name) operatorvalue;
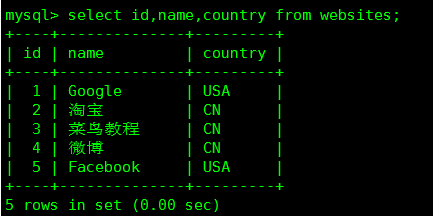
setnames utf8; /*命令用于设置使用的字符集(如果在配置文件中设置了Server或者Client端的字符集则不需要指定)*/ -- 查询用户数据库.表 mysql> select user,host from mysql.user; mysql> select id,name,country from websites;
-- 重复去掉 distinct: 从 "Websites" 表的 "country" 列中选取唯一不同的值,也就是去掉 "country" 列重复值 mysql> select distinct country from websites;
-- 比较运算符 mysql> SELECT * FROM websites WHERE country="CN"; mysql> SELECT * FROM websites WHERE id=1; /* SQL 可以直接输入 数字 表示数值**/ mysql> SELECT * FROM websites WHERE id <> 1; /*显示不包括id=1的数据;*/ mysql> SELECT * FROM websites WHERE id>=2 and country != "CN"; /**采用逻辑运算符和比较运算符连用*/
-- 不带比较运算符的 WHERE 子句 mysql> SELECT host FROM mysql.user WHERE 0; /*则会返回一个空集,因为每一行记录 WHERE 都返回 false。*/ mysql> SELECT host FROM mysql.user WHERE 1; /*返回MySQL表中host字段,因为每一行记录 WHERE 都返回 true。*/
-- 空值判断is null:打印编写满足列某值的某行是,如果不满足则返回该标字段及其字段的值为NULL;) mysql> SELECT * FROM information_schema.FILES WHERE CHECKSUM IS NULL mysql> SELECT * FROM information_schema.FILES WHERE CHECKSUM IS NOT NULL
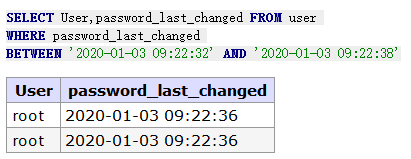
-- 条件语句between.and. :查询 emp 表中 SAL 列中大于等于 1500 的小于 3000 的值 mysql> SELECT * FROM emp WHERE sal between 1500 and 3000;
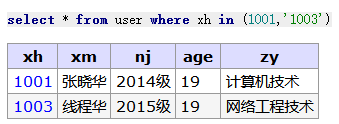
-- 运算符 In (包含运算). 查询 EMP 表 SAL 列中等于 5000,3000,1500 的值。 mysql> SELECT * FROM emp WHERE sal in (5000,3000,1500);
-- 模糊查询Like:查询 EMP 表中 Ename 列中有 M 的值,M 为要查询内容中的模糊信息。 mysql> SELECT * FROM emp WHERE ename like 'Java%'; mysql> SELECT * FROM tb_stu WHERE name like'%程序_'; mysql> SELECT * FROM tb_stu WHERE name like'%PHP%';
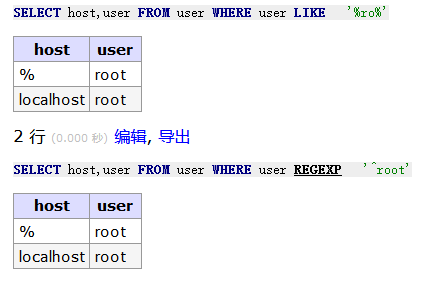
-- 模糊查询REGEXP:使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式查询匹配的模糊信息。 mysql> SELECT host,user FROM user WHERE user REGEXP '[^root]' mysql> SELECT host,user FROM user WHERE user REGEXP '^root'
-- 联合使用() 比较 条件 逻辑 运算符 SELECT * FROM websites WHERE alexa > 15AND (country='CN'OR country='USA'); SELECT * FROM websites WHERE (alexa > 15and alexa % 2 != 0) AND (country='CN'OR country='USA');
-- 排序语句 ORDER BY:多列排序的时候,先按照第一个column name排序,在按照第二个column name排序; SELECT * FROM tb_name WHERE address <> ''orderbyaddtimedesc, idasc; /**查询不为空的数据*/
-- 显示行数 limit语句:查询前n条/后n条记录 SELECT Host,User,password_last_changed FROM mysql.user WHERE1limit0,3; --前三条 SELECT Host,User,password_last_changed FROM mysql.user WHERE1ORDERBY HOST DESClimit0,3; --后三条
-- 子查询也叫内部查询如select avg(score) from studentscore就是子查询 -- 查询学生成绩表里分数低于平均成绩的学生姓名和成绩,并根据分数降序排列 selectname,score form studentscore where score < (selectavg(score) from studentscore) orderby score DESC
注:insert into select 和select into from 的区别(MySQL 数据库不支持,Mssql支持),前则要求行表scorebak 必须存在,后者要求表scorebak 不存在;
UPDATE 语句
描述:UPDATE 语句用于更新表中已存在的记录。
语法:
1 2 3
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
基础示例:
1 2
-- 假设我们要把 "菜鸟教程" 的 alexa 排名更新为 5000,country 改为 USA。 UPDATE websites SET alexa = '5000', country = 'CN'WHEREname = "菜鸟教程"; /* WHERE 语句很重要 */
补充说明:
1.在 MySQL 中可以通过设置 sql_safe_updates 这个自带的参数来解决,当该参数开启的情况下,你必须在update 语句后携带 where 条件,否则就会报错。
1 2 3 4 5 6 7 8 9
mysql> SHOW VARIABLES LIKE 'sql_safe_updates'; -- 值得(注意) Variable_name Value sql_safe_updates OFF
-- 表示开启该参数 set sql_safe_updates=ON; set sql_safe_updates=1; -- 开启后必须在更新语句后加入Where条件,否则在进行删除时候会产生错误; ERROR 1175 (HY000): You are using safe updatemodeand you tried toupdate a tablewithout a WHERE that uses a KEYcolumn
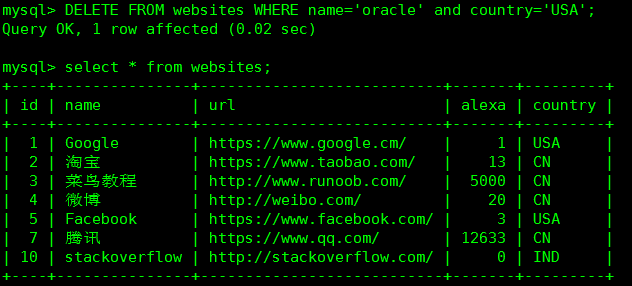
#3.删除整个表:仅删除表test内的所有内容,保留表的定义,不释放空间。 DELETE FROM test 或者 DELETE * FROM test ; @ #删除指定数据:删除表test中年龄等于30的且国家为US的数据 DELETE FROM test WHERE age=30 AND country='US';
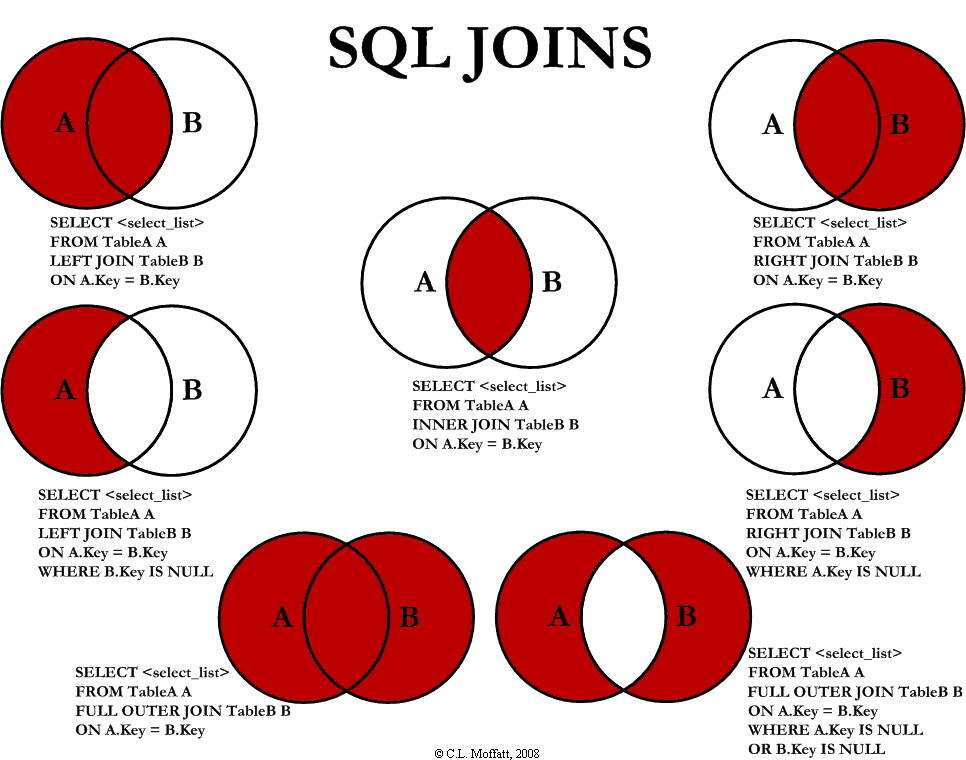
-- 在表中存在至少一个匹配时返回行。 SELECT column_name(s) FROM table1 INNERJOIN table2 ON table1.column_name=table2.column_name;
-- 或:(INNER JOIN 与 JOIN 是相同的)
SELECT column_name(s) FROM table1 JOIN table2 ON table1.column_name=table2.column_name;
基础示例:
1 2 3 4 5
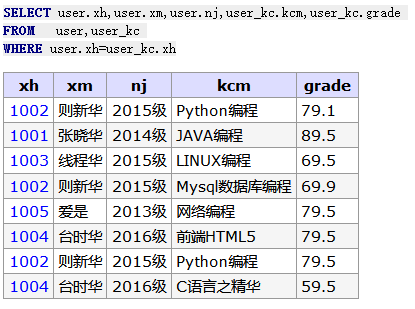
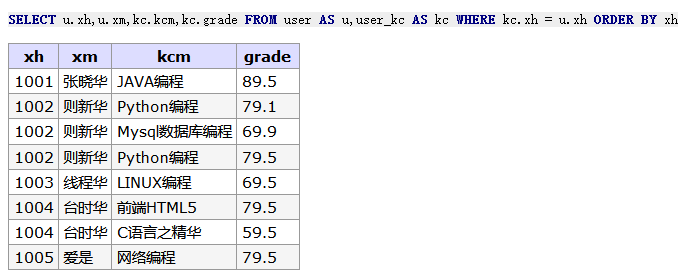
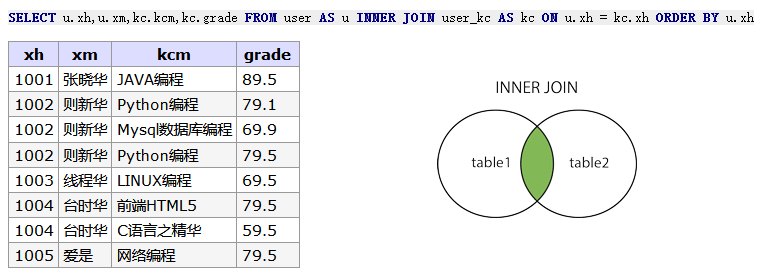
-- 显示满足ON条件的行,否则以左边基准表 + user_kc 每一条 SELECT u.xh,u.xm,kc.kcm,kc.grade FROMuserAS u INNERJOIN user_kc AS kc ON u.xh = kc.xh ORDERBY u.xh
weiyigeek.top-
LEFT JOIN 关键字 描述:LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SQL LEFT JOIN 语法
1 2 3 4 5 6 7 8 9 10
SELECT column_name(s) FROM table1 LEFTJOIN table2 ON table1.column_name=table2.column_name;
或: SELECT column_name(s) FROM table1 LEFTOUTERJOIN table2 ON table1.column_name=table2.column_name;
基础实例:
1 2 3 4 5 6 7
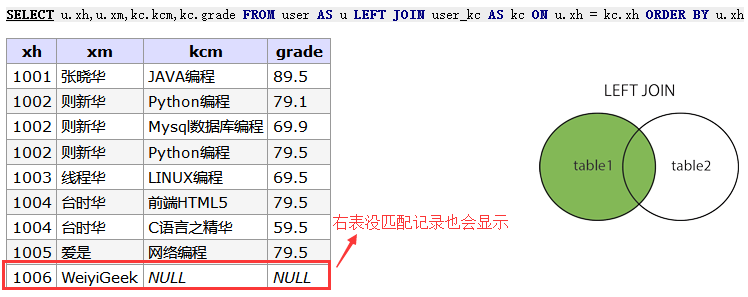
-- LEFT JOIN 关键字演示 INSERTINTOuserVALUES (1006,'WeiyiGeek','2019',21,'网络安全工程');
SELECT u.xh,u.xm,kc.kcm,kc.grade FROMuserAS u LEFTJOIN user_kc AS kc ON u.xh = kc.xh ORDERBY u.xh
weiyigeek.top-
RIGHT JOIN 关键字 描述:RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。实际就是与LEFT相似只不过是左边关联不上的为NULL
SQL RIGHT JOIN 语法:
1 2 3 4 5 6 7 8 9 10 11
SELECT column_name(s) FROM table1 RIGHTJOIN table2 ON table1.column_name=table2.column_name;
-- 或
SELECT column_name(s) FROM table1 RIGHTOUTERJOIN table2 ON table1.column_name=table2.column_name;
基础实例:
1 2 3 4 5
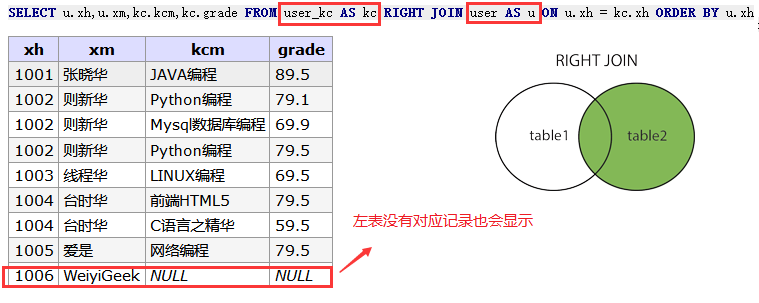
-- 这次将user_kc作为左表,而user作为右表 SELECT u.xh,u.xm,kc.kcm,kc.grade FROM user_kc AS kc -- 注意此处与上面是不同的 RIGHTJOINuserAS u ON u.xh = kc.xh ORDERBY u.xh
weiyigeek.top-
FULL OUTER JOIN 关键字 描述:FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行 它结合了 LEFT JOIN 和 RIGHT JOIN 的结果即 A 并 B。
FULL OUTER JOIN 语法:
1 2 3 4
SELECT column_name(s) FROM table1 FULLOUTERJOIN table2 ON table1.column_name=table2.column_name;
基础实例:
1 2 3 4 5 6
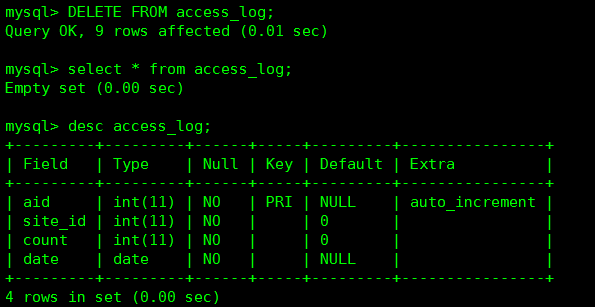
#MySQL中不支持 FULL OUTER JOIN,你可以在 SQL Server 测试以下实例。 SELECT Websites.name, access_log.count, access_log.date FROM Websites FULL OUTER JOIN access_log ON Websites.id=access_log.site_id ORDER BY access_log.count DESC;
inner join <= min(left join, right join) full join >= max(left join, right join) 当 inner join < min(left join, right join) 时 full join > max(left join, right join)
4.在使用 join 时,on 和 where 条件的区别如下:
1 2
- on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真都会返回左边表中的记录。 - where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
5.MySQL中不支持 FULL OUTER JOIN,你可以在 SQL Server 测试以下实例。
UNION 操作符
描述:SQL UNION 操作符合并两个或多个 SELECT 语句的结果。
1 2 3 4 5 6 7 8 9
-- SQL UNION 语法 SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2;
---SQL UNION ALL 语法 SELECT column_name(s) FROM table1 UNIONALL-- 默认地UNION 操作符选取不同的值。如果允许重复的值请使用 UNION ALL。 SELECT column_name(s) FROM table2;
基础实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
-- 从 "Websites" 和 "apps" 表中选取所有不同的country(只有不同的值): SELECT country FROM Websites UNION SELECT country FROM apps ORDERBY country;
-- 使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的中国(CN)的数据(也有重复的值): SELECT country, nameFROM Websites WHERE country='CN' UNIONALL SELECT country, app_name FROM apps WHERE country='CN' ORDERBY country;
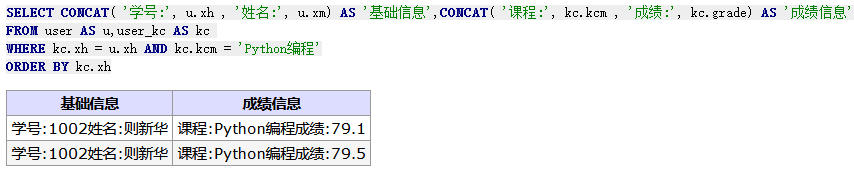
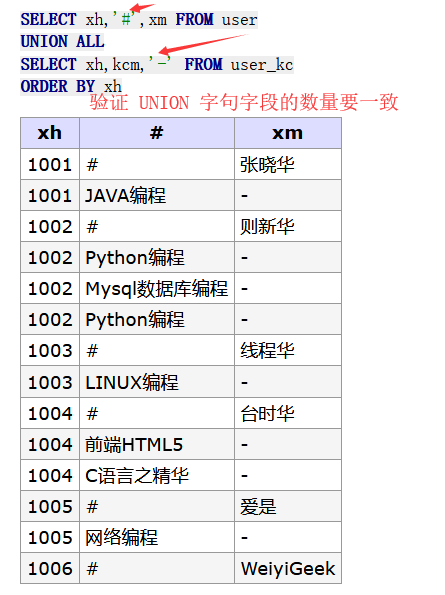
-- union 与 union all 在于前者可以剔除重复的字段的行,后者则是显示所有不管是否重复 SELECT xh,'#',xm FROMuser UNIONALL SELECT xh,kcm,'-'FROM user_kc ORDERBY xh
weiyigeek.top-
注意事项:
注:UNION 内部的每个 SELECT 语句必须拥有相同数量的列
注:列也必须拥有相似的数据类型,同时每个 SELECT 语句中的列的顺序必须相同。
注:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
GROUP BY 语句
描述:GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
基础语法:
1 2 3 4 5
-- SQL GROUP BY 语法 SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operatorvalue GROUPBY column_name;
-- 统计 access_log 各个 site_id 的访问量 SELECT site_id, SUM(counts) AS nums FROM access_log GROUPBY site_id;
-- SQL GROUP BY 多表连接统计有记录的网站的记录数量: SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log LEFTJOIN Websites -- 关键点-表字段结合 ON access_log.site_id=Websites.id GROUPBY Websites.name; -- 关键点
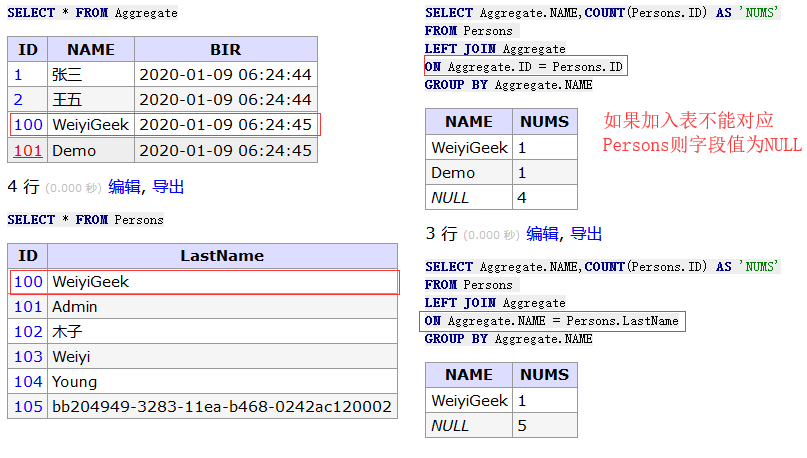
-- 基础实例 SELECT Aggregate.NAME,COUNT(Persons.ID) AS'NUMS' FROM Persons LEFTJOINAggregate ON Aggregate.ID = Persons.ID GROUPBY Aggregate.NAME;
SELECT Aggregate.NAME,COUNT(Persons.ID) AS'NUMS' FROM Persons LEFTJOINAggregate ON Aggregate.NAME = Persons.LastName GROUPBY Aggregate.NAME;
weiyigeek.top-
HAVING 语句
描述:HAVING 子句可以让我们筛选分组后的各组数据; 在 SQL 中增加 HAVING 子句原因是 WHERE 关键字无法与聚合函数一起使用。
1 2 3 4 5 6
-- SQL HAVING 语法 SELECT column_name, aggregate_function(column_name) FROM table_name WHERE column_name operatorvalue GROUPBY column_name HAVING aggregate_function(column_name) operatorvalue;
基础示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
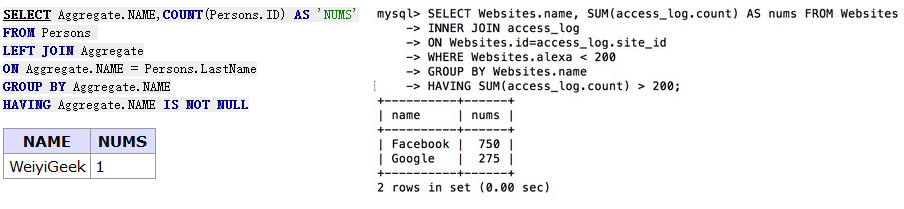
-- 查找总访问量大于 200 的网站,并且 alexa 排名小于 200。 SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites INNERJOIN access_log ON Websites.id=access_log.site_id WHERE Websites.alexa < 200 GROUPBY Websites.name HAVINGSUM(access_log.count) > 200;
-- 过滤掉分组结果为NULL的rows SELECT Aggregate.NAME,COUNT(Persons.ID) AS'NUMS' FROM Persons LEFTJOINAggregate ON Aggregate.NAME = Persons.LastName GROUPBY Aggregate.NAME HAVING Aggregate.NAME ISNOTNULL;
weiyigeek.top-HAVING
SELECT INTO 语句
描述:SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中,但是需要注意 MySQL 数据库不支持 SELECT ... INTO 语句,但支持 INSERT INTO ... SELECT , 当然你可以使用以下语句来拷贝表结构及数据(后面讲解CREATE会讲):
1 2 3
CREATETABLE 新表 AS SELECT * FROM 旧表
SELECT INTO 语法:
1 2 3 4 5 6 7 8 9
-- 复制所有的列插入到新表中: SELECT * INTO newtable [IN externaldb] FROM table1;
-- 只复制希望的列插入到新表中: SELECT column_name(s) INTO newtable [IN externaldb] FROM table1;
基础实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- 创建 Websites 的备份复件,只复制中国的网站插入到新表中: SELECT * INTO WebsitesBackup2016 FROM Websites; WHERE country='CN';
-- 复制多个表中的数据插入到新表中: SELECT Websites.name, access_log.count, access_log.date INTO WebsitesBackup2016 FROM Websites LEFTJOIN access_log ON Websites.id=access_log.site_id;
-- SELECT INTO 语句可用于通过另一种模式创建一个新的空表。 SELECT * INTO newtable FROM table1 WHERE1=0; -- 只需要添加促使查询没有数据返回的 WHERE 子句即可
注意事项:
注:新表将会使用 SELECT 语句中定义的列名称和类型进行创建。但是可以使用 AS 子句来应用新名称。
INSERT INTO SELECT 语句
描述:INSERT INTO SELECT 语句从一个表复制数据,目标表中任何已存在的行都不会受影响。然后把数据插入到一个已存在的表中(非常注意不同于SELECT INTO语句转存的表必须存在,而且字段类型一致)。
SQL INSERT INTO SELECT 语法:
1 2 3 4 5 6 7 8
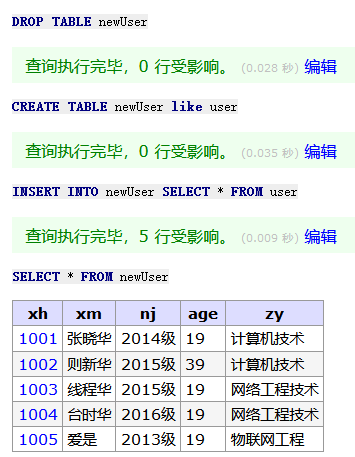
-- 从一个表中复制所有的列插入到另一个已存在的表中: INSERTINTO table2 SELECT * FROM table1;
-- 只复制希望的列插入到另一个已存在的表中: INSERTINTO table2 (column_name(s)) SELECT column_name(s) FROM table1;
基础实例:
1 2 3
-- 复制 "apps" 中的数据插入到 "Websites" 中: INSERTINTO Websites (name, country) SELECT app_name, country FROM apps;
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主, 将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!