[TOC]
0x00 前言简述 本系列是从入门到转型之Linux性能优化实践学习指南,是博主学习Linux性能优化之路的精华版本,我将分享大量性能优化的思路和方法,并进行相应工具使用介绍和总结。
做过开发运维的工作应该知道, 性能优化一直都是大多数软件工程师头上的“紧箍咒”。
Q: 性能问题为什么这么难呢?
答: 我觉得主要是因为性能优化是个系统工程,总是牵一发而动全身。它涉及了从程序设计、算法分析、编程语言,再到系统、存储、网络等各种底层基础设施的方方面面。每一个组件都有可能出问题,而且很有可能多个组件同时出问题。
毫无疑问,性能优化是软件系统中最有挑战的工作之一,但是换个角度看,它也是最考验体现你综合能力的工作之一。
Q: 那我们究竟如何学习Linux性能优化?
在不断的实践和总结后,我终于知道最好的学习方式一定是带着问题学习。
即学习要会抓重点。其实只要你了解少数几个系统组件的基本原理和协作方式,掌握基本的性能指标和工具,学会实际工作中性能优化的常用技巧,你就已经可以准确分析和优化大多数的性能问题了。在这个认知的基础上,再反过来去阅读那些经典的操作系统或者其它图书,他将事半功倍。
即从资源使用的视角出发,带你分析各种 Linux 资源可能会碰到的性能问题,包括 CPU 性能、磁盘 I/O 性能、内存性能以及网络性能。
其实,性能问题并没有你想像得那么难,只要你理解了应用程序和系统的少数几个基本原理,再进行大量的实战练习,建立起整体性能的全局观,大多数性能问题的优化就会水到渠成。
有得DevOps工程师大佬,在分析应用程序所使用的第三方组件的性能时,并不熟悉这些组件所用的编程语言,却依然可以分析出线上问题的根源,并能通过一些方法进行优化,比如修改应用程序对它们的调用逻辑,或者调整组件的配置选项等。还是那句话你不需要了解每个组件的所有实现细节,只要能理解它们最基本的工作原理和协作方式,你也可以做到。
Q: 性能指标是什么?
答: 我相信“高并发”和“响应快”一定是最先出现在你脑海里的两个词,而它们也正对应着性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,直接影响了产品终端的用户体验。跟它们对应的是从系统资源的视角出发的指标,比如资源使用率、饱和度等。
weiyigeek.top-应用负载与系统资源视角(电梯原理)
随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。
实际上性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
Q: 性能分析是什么?
选择指标评估应用程序和系统的性能;
为应用程序和系统设置性能目标;
进行性能基准测试;
性能分析定位瓶颈;
优化系统和应用程序;
性能监控和告警。
Tips: 性能相关的基本指标和核心步骤。
Q: 性能优化学习的重点是什么?
描述: 如果想要学习好性能分析和优化,建立整体系统性能的全局观是最核心的话题。因而,理解最基本的几个系统知识原理;掌握必要的性能工具;通过实际的场景演练,贯穿不同的组件。
Q: 怎么学更高效?
技巧一:虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节。 你可以先学会我给你讲的这些系统工作原理,但不要去深究 Linux 内核是如何做到的,而是要把你的重点放到如何观察和运用这些原理上,
比如:有哪些指标可以衡量性能?指标,比如是内存还是CPU,亦或者io
使用什么样的性能工具来观察指标?比如io可以使用iostat 内存可以用mpstat
导致这些指标变化的因素等。比如io阻塞出现的问题有: 读取小文件过多,网络阻塞,长连接过多等
技巧二:边学边实践,通过大量的案例演习掌握 Linux 性能的分析和优化。
技巧三:勤思考,多反思,善总结,多问为什么。想真正学懂一门知识,最好的方法就是问问题。当你能提出好的问题时,就说明你已经深入了解了它。
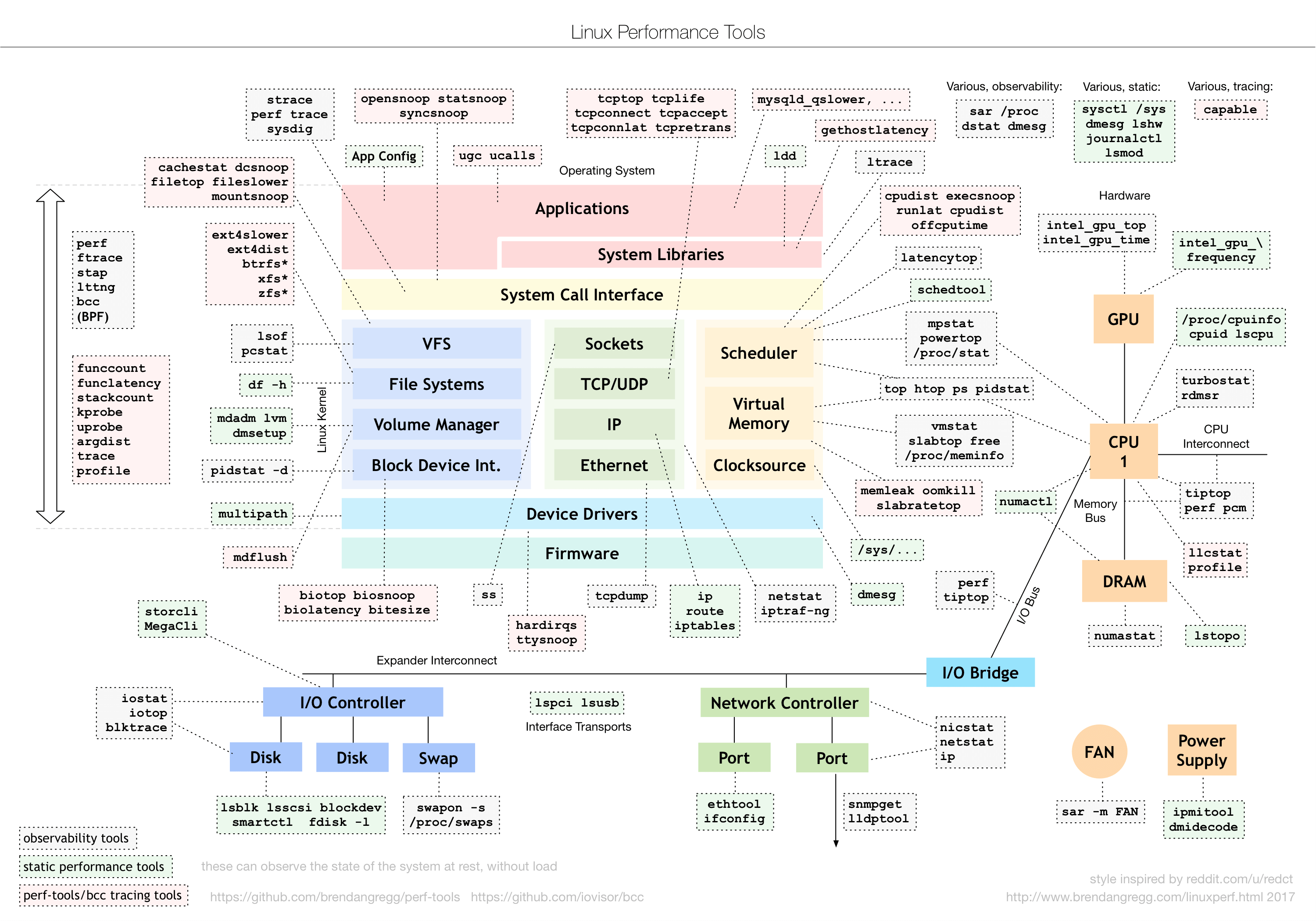
前面说到性能工具就不得不提到性能领域的大师布伦丹·格雷格(Brendan Gregg), 其个人博客主页(http://www.brendangregg.com)国内可访,他不仅是动态追踪工具 DTrace 的作者,还开发了许许多多的性能工具, 我相信你一定见过他所描绘的 Linux 性能工具图谱:
该图是 Linux 性能分析最重要的参考资料之一,它告诉你,在 Linux 不同子系统出现性能问题后,应该用什么样的工具来观测和分析。比如,当遇到 I/O 性能问题时,可以参考图片最下方的 I/O 子系统,使用 iostat、iotop、blktrace 等工具分析磁盘 I/O 的瓶颈
另外,我还要特别强调一点,就是性能工具的选用。有句话是这么说的,一个正确的选择胜过千百次的努力。虽然夸张了些,但是选用合适的性能工具,确实可以大大简化整个性能优化过程。在什么场景选用什么样的工具、以及怎么学会选择合适工具,都是我想教给你的东西。
但是切记,千万不要把性能工具当成学习的全部。工具只是解决问题的手段,关键在于你的用法。只有真正理解了它们背后的原理,并且结合具体场景,融会贯通系统的不同组件,你才能真正掌握它们。
weiyigeek.top-Linux性能优化学习路径
六步总结: 从正确的角度出发,设定目标(性能优化不是漫无目的的),基准测试(了解现有系统应用的运行时情况),根据情况分析瓶颈,优化它,设置监控和告警(其实可以再扩展比如达到一定的负载,采取降级等操作)
说一说你在日常生活中遇到的系统程序异常时排查流程 Grafana+Prometheus) -> 预警信息(AlertManager) -> 应用状态确认 -> 应用部署的系统(Linux) -> CPU使用率(top/htop) -> 内存使用率(free) -> 磁盘使用率(iostat) -> 网络吞吐(iftop) -> 应用进程Heap与Stack调用(jps/) -> 第三方外部系统(比如数据库、缓存、存储等)
激励Buff: “想要得到你就要学会付出,要付出还要坚持;如果你真的觉得很难,那你就放弃,如果你放弃了就不要抱怨。人生就是这样,世界是平衡的,每个人都是通过自己的努力,去决定自己生活的样子。”
0x01 CPU 性能篇 1.平均负载 系统的负载情况可执行 top 或者 uptime 命令来查看。
比如像下面这样,我在命令行里输入了 uptime 命令,系统也随即给出了结果。
[TOC]
0x00 前言简述 本系列是从入门到转型之Linux性能优化实践学习指南,是博主学习Linux性能优化之路的精华版本,我将分享大量性能优化的思路和方法,并进行相应工具使用介绍和总结。
做过开发运维的工作应该知道, 性能优化一直都是大多数软件工程师头上的“紧箍咒”。
Q: 性能问题为什么这么难呢?
答: 我觉得主要是因为性能优化是个系统工程,总是牵一发而动全身。它涉及了从程序设计、算法分析、编程语言,再到系统、存储、网络等各种底层基础设施的方方面面。每一个组件都有可能出问题,而且很有可能多个组件同时出问题。
毫无疑问,性能优化是软件系统中最有挑战的工作之一,但是换个角度看,它也是最考验体现你综合能力的工作之一。
Q: 那我们究竟如何学习Linux性能优化?
在不断的实践和总结后,我终于知道最好的学习方式一定是带着问题学习。
即学习要会抓重点。其实只要你了解少数几个系统组件的基本原理和协作方式,掌握基本的性能指标和工具,学会实际工作中性能优化的常用技巧,你就已经可以准确分析和优化大多数的性能问题了。在这个认知的基础上,再反过来去阅读那些经典的操作系统或者其它图书,他将事半功倍。
即从资源使用的视角出发,带你分析各种 Linux 资源可能会碰到的性能问题,包括 CPU 性能、磁盘 I/O 性能、内存性能以及网络性能。
其实,性能问题并没有你想像得那么难,只要你理解了应用程序和系统的少数几个基本原理,再进行大量的实战练习,建立起整体性能的全局观,大多数性能问题的优化就会水到渠成。
有得DevOps工程师大佬,在分析应用程序所使用的第三方组件的性能时,并不熟悉这些组件所用的编程语言,却依然可以分析出线上问题的根源,并能通过一些方法进行优化,比如修改应用程序对它们的调用逻辑,或者调整组件的配置选项等。还是那句话你不需要了解每个组件的所有实现细节,只要能理解它们最基本的工作原理和协作方式,你也可以做到。
Q: 性能指标是什么?
答: 我相信“高并发”和“响应快”一定是最先出现在你脑海里的两个词,而它们也正对应着性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,直接影响了产品终端的用户体验。跟它们对应的是从系统资源的视角出发的指标,比如资源使用率、饱和度等。
weiyigeek.top-应用负载与系统资源视角(电梯原理)
随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。
实际上性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
Q: 性能分析是什么?
选择指标评估应用程序和系统的性能;
为应用程序和系统设置性能目标;
进行性能基准测试;
性能分析定位瓶颈;
优化系统和应用程序;
性能监控和告警。
Tips: 性能相关的基本指标和核心步骤。
Q: 性能优化学习的重点是什么?
描述: 如果想要学习好性能分析和优化,建立整体系统性能的全局观是最核心的话题。因而,理解最基本的几个系统知识原理;掌握必要的性能工具;通过实际的场景演练,贯穿不同的组件。
Q: 怎么学更高效?
技巧一:虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节。 你可以先学会我给你讲的这些系统工作原理,但不要去深究 Linux 内核是如何做到的,而是要把你的重点放到如何观察和运用这些原理上,
比如:有哪些指标可以衡量性能?指标,比如是内存还是CPU,亦或者io
使用什么样的性能工具来观察指标?比如io可以使用iostat 内存可以用mpstat
导致这些指标变化的因素等。比如io阻塞出现的问题有: 读取小文件过多,网络阻塞,长连接过多等
技巧二:边学边实践,通过大量的案例演习掌握 Linux 性能的分析和优化。
技巧三:勤思考,多反思,善总结,多问为什么。想真正学懂一门知识,最好的方法就是问问题。当你能提出好的问题时,就说明你已经深入了解了它。
前面说到性能工具就不得不提到性能领域的大师布伦丹·格雷格(Brendan Gregg), 其个人博客主页(http://www.brendangregg.com)国内可访,他不仅是动态追踪工具 DTrace 的作者,还开发了许许多多的性能工具, 我相信你一定见过他所描绘的 Linux 性能工具图谱:
该图是 Linux 性能分析最重要的参考资料之一,它告诉你,在 Linux 不同子系统出现性能问题后,应该用什么样的工具来观测和分析。比如,当遇到 I/O 性能问题时,可以参考图片最下方的 I/O 子系统,使用 iostat、iotop、blktrace 等工具分析磁盘 I/O 的瓶颈
另外,我还要特别强调一点,就是性能工具的选用。有句话是这么说的,一个正确的选择胜过千百次的努力。虽然夸张了些,但是选用合适的性能工具,确实可以大大简化整个性能优化过程。在什么场景选用什么样的工具、以及怎么学会选择合适工具,都是我想教给你的东西。
但是切记,千万不要把性能工具当成学习的全部。工具只是解决问题的手段,关键在于你的用法。只有真正理解了它们背后的原理,并且结合具体场景,融会贯通系统的不同组件,你才能真正掌握它们。
weiyigeek.top-Linux性能优化学习路径
六步总结: 从正确的角度出发,设定目标(性能优化不是漫无目的的),基准测试(了解现有系统应用的运行时情况),根据情况分析瓶颈,优化它,设置监控和告警(其实可以再扩展比如达到一定的负载,采取降级等操作)
说一说你在日常生活中遇到的系统程序异常时排查流程 Grafana+Prometheus) -> 预警信息(AlertManager) -> 应用状态确认 -> 应用部署的系统(Linux) -> CPU使用率(top/htop) -> 内存使用率(free) -> 磁盘使用率(iostat) -> 网络吞吐(iftop) -> 应用进程Heap与Stack调用(jps/) -> 第三方外部系统(比如数据库、缓存、存储等)
激励Buff: “想要得到你就要学会付出,要付出还要坚持;如果你真的觉得很难,那你就放弃,如果你放弃了就不要抱怨。人生就是这样,世界是平衡的,每个人都是通过自己的努力,去决定自己生活的样子。”
0x01 CPU 性能篇 1.平均负载 系统的负载情况可执行 top 或者 uptime 命令来查看。
比如像下面这样,我在命令行里输入了 uptime 命令,系统也随即给出了结果。1 2 3 4 5 6 $ uptime 02:34:03 up 2 days, 20:14 1 user load average: 0.63, 0.83, 0.88
1.1 基础概念 Q: 什么是平均负载(Load Average)吗?
答: 平均负载是最常见、也是最重要的系统指标,但你真正的了解它吗,在博主在当时学习它时候也是一头雾水。 我猜一定有人会说,平均负载不就是单位时间内的 CPU 使用率吗?上面的 0.63,就代表 CPU 使用率是 63%。其实并不是这样,如果你方便的话,可以通过执行 man uptime 命令,来了解平均负载的详细解释。
简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
(1) 可运行状态的进程: 是指正在使用 CPU (处在【运行态】)或者正在等待 CPU (【就绪态】)的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
(2) 不可中断状态的进程 : 则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
简单理解为,平均负载其实就是平均活跃进程数(是被消耗掉的cpu个数)。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。
Tips: 这个“指数衰减平均”的详细含义你不用计较,这只是系统的一种更快速的计算方式,你把它直接当成活跃进程数的平均值也没问题。
Tips: 平均负载的理想情况,每个CPU上运行一个进程,这样每个 CPU 都得到了充分利用。
比如.当平均负载为 2 时,意味着什么呢?
在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。
例如,前面1分钟、5分钟、15分钟三个不同时间间隔的平均负载值有何作用。
打个比方,就像初秋时北京的天气,如果只看中午的温度,你可能以为还在 7 月份的大夏天呢。但如果你结合了早上、中午、晚上三个时间点的温度来看,基本就可以全方位了解这一天的天气情况了。
同样的,前面说到的 CPU 的三个负载时间段也是这个道理。
如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化了。
再举个例子,假设我们在一个单 CPU 系统上看到平均负载为 1.73,0.60,7.98,那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低。
Q: 平均负载为多少时是合理?
首先,你要知道系统有几个 CPU,这可以通过 nproc 命令 或 top 命令(按1) 或者从文件 /proc/cpuinfo 中读取,比如:grep 'model name' /proc/cpuinfo | wc -l
其次,当平均负载高于 CPU 数量 70% 的时候,当然这并不是绝对的最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。
Q: 平均负载与 CPU 使用率的区别 【等待IO】是【处于不可中断状态的进程】)。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
Tips: 一句话表明CPU负载高不代表使用率高,还有可能等待IO线程导致。
1.2 案例分析 此处我们需要准备一台Linux系统,我准备是 Ubuntu 20.04 后续案例都是基于此系统进行。
环境工具准备:
虚拟机 Ubuntu 20.04 , 4CPU , 8GB内存
预先安装 stress 和 sysstat 包,如 apt install -y stress sysstat。
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能,此处使用到是 mpstat 和 pidstat两个命令。
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
此外,每个场景都需要你开三个终端,登录到同一台 Linux 机器中。
场景一:CPU 密集型进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 $ stress --cpu 1 --timeout 600 stress: info: [13476] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd $ watch -d uptime Every 2.0s: uptime weiyigeek: Wed Nov 24 09:51:01 2021 09:51:01 up 4 days, 22:52, 3 users, load average: 1.03[关键点], 0.66, 0.29 $ mpstat -P ALL 5 09:51:42 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 09:51:47 AM all 25.01 0.00 0.10 0.00 0.00 0.15 0.00 0.00 0.00 74.74 09:51:47 AM 0 0.20 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.60 09:51:47 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 09:51:47 AM 2 0.00 0.00 0.20 0.00 0.00 0.60 0.00 0.00 0.00 99.20 09:51:47 AM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle Average: all 24.99 0.00 0.03 0.00 0.00 0.16 0.00 0.00 0.00 74.82 Average: 0 0.04 0.00 0.06 0.00 0.00 0.17 0.00 0.00 0.00 99.73 Average: 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: 2 0.03 0.00 0.04 0.00 0.00 0.37 0.00 0.00 0.00 99.56 Average: 3 0.02 0.00 0.03 0.00 0.00 0.09 0.00 0.00 0.00 99.86 $ pidstat -u 5 1 09:51:47 UID PID %usr %system %guest %wait %CPU CPU Command 09:51:48 0 3962 100.00 0.00 0.00 0.00 100.00 1 stress
从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.03,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明平均负载的升高正是由于 CPU 使用率为 100% 。
Tips : 执行stress进行系统压力测试时, 可以看见负载是以线性进行增长的特征。
场景二:I/O 密集型进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 $ stress -i 1 --timeout 600 stress: info: [14844] dispatching hogs: 0 cpu, 1 io, 0 vm, 0 hdd $ watch -n 10 -d uptime Every 10.0s: uptime weiyigeek: Wed Nov 24 11:35:03 2021 11:35:03 up 5 days, 36 min, 3 users, load average: 1.03, 0.68, 0.31 $ mpstat -P ALL 5 1 Linux 5.4.0-90-generic (weiyigeek) 11/24/2021 _x86_64_ (4 CPU) 11:35:18 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 11:35:23 AM all 1.04 0.00 23.68 0.00 0.00 1.38 0.00 0.00 0.00 73.90 11:35:23 AM 0 4.20 0.00 95.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11:35:23 AM 1 0.00 0.00 0.00 0.00 0.00 1.19 0.00 0.00 0.00 98.81 11:35:23 AM 2 0.00 0.00 0.00 0.00 0.00 4.21 0.00 0.00 0.00 95.79 11:35:23 AM 3 0.00 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.80 Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle Average: all 1.04 0.00 23.68 0.00 0.00 1.38 0.00 0.00 0.00 73.90 Average: 0 4.20 0.00 95.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00 Average: 1 0.00 0.00 0.00 0.00 0.00 1.19 0.00 0.00 0.00 98.81 Average: 2 0.00 0.00 0.00 0.00 0.00 4.21 0.00 0.00 0.00 95.79 Average: 3 0.00 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.80 $ pidstat -u 5 1 Linux 5.4.0-90-generic (weiyigeek) 11/24/2021 _x86_64_ (4 CPU) 11:37:09 AM UID PID %usr %system %guest %wait %CPU CPU Command 11:37:14 AM 0 738 0.20 0.00 0.00 0.00 0.20 0 vmtoolsd 11:37:14 AM 1000 14845 3.59 96.21 0.00 0.20 99.80 1 stress
从这里可以看到,1 分钟的平均负载会慢慢增加到 1.03,第一个 CPU 使用率升高了%system 为 95.80%,%iowait 为 0.0%(虚拟机的影响)。通常情况下如果是磁盘性能不好 %iowait 值应该是偏高的,上面种种特征表明平均负载的升高是由于 iowait 的升高。
Tips : 经过测试如果是虚拟机,此时 iowait 是没有变化的,但是物理机的情况下数值是可变化的。。
场景三:大量进程的场景 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 $ stress -c 8 --timeout 600 stress: info: [15174] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd 由于系统只有 4 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态,平均负载高达 6.84: $ watch -n 10 -d uptime Every 10.0s: weiyigeek: Wed Nov 24 12:02:17 2021 12:02:17 up 5 days, 1:03, 3 users, load average: 6.84, 3.24, 1.55 $ mpstat -P ALL 5 1 Linux 5.4.0-90-generic (weiyigeek) 11/24/2021 _x86_64_ (4 CPU) 12:02:17 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 12:02:22 PM all 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:02:22 PM 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:02:22 PM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:02:22 PM 2 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:02:22 PM 3 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 $ pidstat -u 5 1 Linux 5.4.0-90-generic (WeiyiGeek) 11/24/2021 _x86_64_ (4 CPU) 12:02:50 PM UID PID %usr %system %guest %wait %CPU CPU Command 12:02:55 PM 0 15175 49.90 0.00 0.00 49.90 49.90 3 stress 12:02:55 PM 0 15176 49.90 0.00 0.00 49.90 49.90 2 stress 12:02:55 PM 0 15177 49.90 0.00 0.00 50.10 49.90 1 stress 12:02:55 PM 0 15178 50.10 0.00 0.00 49.70 50.10 1 stress 12:02:55 PM 0 15179 50.10 0.00 0.00 49.90 50.10 2 stress 12:02:55 PM 0 15180 49.70 0.00 0.00 50.10 49.70 0 stress 12:02:55 PM 0 15181 49.90 0.00 0.00 49.90 49.90 0 stress 12:02:55 PM 0 15182 49.70 0.00 0.00 50.10 49.70 3 stress 12:02:55 PM 0 15215 0.00 0.20 0.00 0.20 0.20 3 pidstat
从上述结果,可以看出 8 个进程在争抢 4 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达50.10%, 这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
Tips: 上面用三了个案例展示了不同场景下平均负载升高的分析方法。
本节总结: 平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时也需要注意:
1) 平均负载高有可能是 CPU 密集型进程导致的;
2) 平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
3) 当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
更为简洁的说明: 平均负载是是平均活跃进程数(是被消耗掉的cpu个数), 其表示针对 CPU + IO 两者消耗性的集合:
针对CPU消耗性的进程。
针对IO消耗性的进程。
针对CPU+IO消耗性:例如大量的进程调度
2.上下文切换 本节主题,经常说的 CPU 上下文切换是什么意思?
2.1 基础概念 Q: 进程在竞争 CPU 的时候并没有真正运行,为什么还会导致系统的负载升高呢?
答: 因为多进程竞争CPU会导致上下文的切换, 所以CPU 上下文切换就是罪魁祸首(本节主题)。
我们都知道 Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。
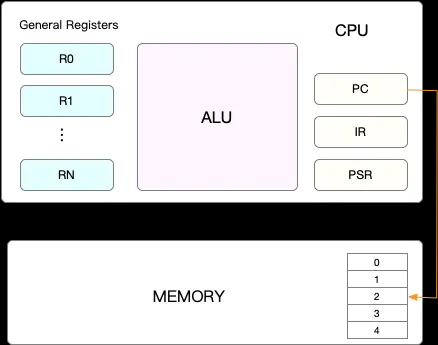
在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说需要系统事先帮它设置好 CPU 寄存器(Register)和程序计数器(Program Counter,PC)。
CPU 寄存器(Register) : 是 CPU 内置的容量小、但速度极快的内存。(Program Counter,PC) : 用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
Tips : 它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
weiyigeek.top-CPU寄存器&内存
Q: 那什么是cpu上下文切换?
答: 就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来, 然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来, 这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
Tips: 保存的上下文是存储在系统内核(OS kernel)中的。
我猜肯定会有人说,CPU 上下文切换无非就是更新了 CPU 寄存器的值嘛,但这些寄存器,本身就是为了快速运行任务而设计的,为什么会影响系统的 CPU 性能呢?操作系统管理的这些“任务”到底是什么呢?
答: 进程和线程正是最常见的任务, 而硬件通过触发信号会导致中断处理程序的调用这也是任务。
所以根据任务的不同,CPU 的上下文切换就可以分为进程上下文切换、线程上下文切换以及中断上下文切换等几种不同的场景。
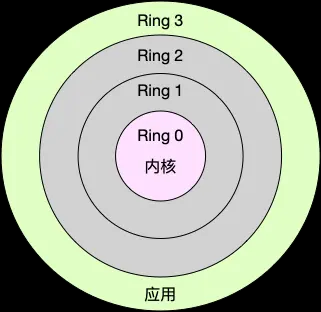
(1) 进程上下文切换 Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中 CPU 特权等级的 Ring 0 和 Ring 3(保存在某一个寄存器中),CPU进行切换会根据这个值进行区分。
内核空间(Ring 0): 具有最高权限,可以直接访问所有资源;
用户空间(Ring 3): 只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
weiyigeek.top-Linux特权等级
换个角度看,也就是说进程既可以在用户空间运行,又可以在内核空间中运行。
进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态, 他们之间的转变需要通过系统调用来完成。
比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容,并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。
系统调用的过程是发生了 CPU 上下文的切换的, CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。
所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换(用户态 -->> 内核态,内核态 -->> 用户态)。
Tips: 需要注意的是系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源也不会切换进程,跟我们通常所说的进程上下文切换是不一样的:进程上下文切换,是指从一个进程切换到另一个进程运行,而系统调用过程中一直是同一个进程在运行。
Tips: 系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
Q: 进程切换可类比在银行柜台办理业务的那几种情形?
1) 银行分配各个窗口给来办理业务的人。
Q: 进程上下文切换跟系统调用又有什么区别呢?
答: 进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成.
weiyigeek.top-进程间的上下文切换
频繁上下文切换导致性能问题 : 每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。
Linux 通过 TLB(Translation Lookaside Buffer-变换索引缓冲)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
Q: 什么是TLB(translation lookaside buffer)?
答: CPU里有一个TLB,用于缓存虚拟内存到物理内存映射关系的页表,如果发生上下文切换,会导致该部分缓冲的上一个进程的页表映射关系成为脏页,此时CPU会刷新整个TLB为新进程的页表。在多核处理器中TLB是它们共享的,频繁刷脏导致命中率下降,CPU会通过页表转换之后访问物理地址,此时性能是明显低于直接访问TLB里缓存的物理地址的。
Tips: 大内存页的使用还可以通过减少变换索引缓冲(translation lookaside buffer,TLB)的失败次数来提高性能。
Q: 究竟什么时候会切换进程上下文?
答: 显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。优先级最高和等待 CPU 时间最长的进程来运行。
Q: 进程在什么时候才会被调度到 CPU 上运行呢?
答: 最容易想到的一个时机,就是进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行。
其实还有很多其他场景,也会触发进程调度,在这里我给你逐个梳理下:
其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。(一个进程结束,需要从队列中重新选择一个)
其二,进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。 (如果不访问磁盘I/O等资源就不能继续,它会休眠直到资源可用。)
其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。(如果进程用完时间片或被抢占,则返回到运行队列。)
其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。(更高优先级进程进来)
其五, 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。(硬件坏了,会转移到内核中断程序)
Tips: 了解上述几个场景是非常有必要的,因为一旦出现上下文切换的性能问题,它们就是幕后凶手。
(2) 线程上下文切换 Q: 什么是进程和线程?之间区别是什么(老生常谈了)
进程 : 是系统资源分配的基本单位。
线程 : 是调度的基本单位。
说白了,所谓内核中的任务调度,实际上的调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
所以,对于线程和进程可以这么理解:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源(上下文切换时不需要修改)。
此外线程也有自己的私有数据,比如栈和寄存器等(上下文切换时需要保存私有数据)。
线程的上下文切换其实就可以分为两种情况:
第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
Tips:此时你会发现虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
(3) 中断上下文切换 描述: 为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
因为中断上下文切换并不涉及到进程的用户态。所以即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源,它其实只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断 参数等。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生(中断的优先级更高,中断的是进程)。
所以: 由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
注意: 中断上下文切换也需要消耗 CPU,切换次数过多也会耗费大量的 CPU,甚至严重降低系统的整体性能。(异常排查时非常注意中断次数过多带来的影响)
2.2 实践案例 Q: 用什么工具查看系统的上下文切换情况?
答: 首当其冲选择 vmstat 系统性能分析工具,来查询系统的上下文切换情况, 可用于分析系统内存和分析CPU上下文切换以及中断的次数。
1 2 3 4 5 $ vmstat 1 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 6995904 68004 677452 0 0 0 1 3 13 0 0 100 0 0
此处着重注意下面前四列的内容:
r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。
b(Blocked)则是处于不可中断睡眠状态的进程数。
in(interrupt)则是每秒中断的次数。
cs(context switch)是每秒上下文切换的次数。
例子中的上下文切换次数 cs 是 13 次,而系统中断次数 in 则是 3 次,而就绪队列长度 r 和不可中断状态进程数 b 都是 0。
Q: 用什么工具查看每个进程的详细情况?
答: 使用我们前面提到过的 pidstat 工具, 我们只需要加上 -w 选项即可查看每个进程上下文切换的情况了。
1 2 3 4 5 6 7 8 9 10 11 $ pidstat -w 5 1 Linux 5.4.0-90-generic (WeiyiGeek1) 11/24/2021 _x86_64_ (4 CPU) 05:29:33 PM UID PID cswch/s nvcswch/s Command 05:29:38 PM 0 11 21.20 0.00 rcu_sched 05:29:38 PM 0 12 0.20 0.00 migration/0 05:29:38 PM 0 17 0.20 0.00 migration/1 05:29:38 PM 0 18 0.20 0.00 ksoftirqd/1 05:29:38 PM 0 23 0.20 0.00 migration/2 05:29:38 PM 0 29 0.20 0.00 migration/3
此处着重关注以下两列的内容
cswch : 表示每秒自愿上下文切换(voluntary context switches)的次数. voluntary 英 ['vɒləntri]
nvcswch : 表示每秒非自愿上下文切换(non voluntary context switches)的次数。
下面两个概念意味着不同的性能问题:
自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
今天的案例,我们将使用 sysbench 是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况,此处用于模拟系统多线程调度切换的情况。
我们需要在前面的基础环境之上执行apt install sysbench进行安装基准测试工具,此处安装的版本sysbench 1.0.18。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 $ sysbench --threads=20 --time=300 threads run Number of threads: 20 Threads started! General statistics: total time: 300.5970s total number of events: 646476 Latency (ms): min: 0.44 avg: 9.30 max: 3359.40 95th percentile: 30.81 sum: 6011429.64 Threads fairness: events (avg/stddev): 32323.8000/246.36 execution time (avg/stddev): 300.5715/0.01 $ vmstat 1 2 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 14 0 0 6957600 70408 692940 0 0 0 0 63535 1484981 28 58 14 0 0 9 0 0 6957600 70408 692940 0 0 0 0 69282 1576618 29 61 10 0 0 发现 `cs列` 的上下文切换次数从之前的13骤然上升到了 157 万左右。 发现 `r列` 就绪从14到9远远超过系统CPU的个数4个所以存在大量的CPU竞争。 发现 `in 列` 中断次数也上升到了 6 万左右,说明中断处理也是个潜在的问题。 发现 `us(user)和 sy(system)列` , 这两列的 CPU 使用率加起来上升到了90%, 其中系统 CPU 使用率(sy)为61%,说明主要是被内核占用。 $ pidstat -w -u 1 Linux 5.4.0-90-generic (WeiyiGeek1) 11/24/2021 _x86_64_ (4 CPU) 09:09:25 PM UID PID %usr %system %guest %wait %CPU CPU Command 09:26:22 PM 0 16814 116.83 226.73 0.00 0.00 343.56 0 sysbench 09:26:22 PM 0 16837 0.00 0.99 0.00 0.00 0.99 3 pidstat 09:26:22 PM UID PID cswch/s nvcswch/s Command 09:26:22 PM 0 10 0.99 0.00 ksoftirqd/0 09:26:22 PM 0 11 34.65 0.00 rcu_sched 09:26:22 PM 0 30 2.97 0.00 ksoftirqd/3 09:26:22 PM 0 347 2.97 0.00 irq/16-vmwgfx 09:26:22 PM 0 691 0.99 0.00 multipathd 09:26:22 PM 0 738 8.91 0.00 vmtoolsd 09:26:22 PM 0 14042 2.97 0.00 kworker/0:1-events 09:26:22 PM 0 15931 3.96 0.00 kworker/u256:2-events_power_efficient 09:26:22 PM 0 15954 5.94 0.00 kworker/1:2-events 09:26:22 PM 0 15959 3.96 0.00 kworker/3:2-events 09:26:22 PM 0 16803 0.99 0.00 kworker/2:0-events 09:26:22 PM 1000 16622 308.00 0.00 sshd 09:26:22 PM 0 16803 2.00 0.00 kworker/2:0-events_freezable 09:26:22 PM 0 17060 1.00 320.00 pidstat $ pidstat -wt 1 1 Linux 5.4.0-90-generic (WeiyiGeek1) 11/24/2021 _x86_64_ (4 CPU) 09:09:55 PM UID TGID TID cswch/s nvcswch/s Command ... 09:09:56 PM 0 - 16815 19581.48 63652.78 |__sysbench 09:09:56 PM 0 - 16816 13800.93 46843.52 |__sysbench 09:09:56 PM 0 - 16817 16292.59 56557.41 |__sysbench 09:09:56 PM 0 - 16818 21408.33 59123.15 |__sysbench 09:09:56 PM 0 - 16819 15557.41 72369.44 |__sysbench 09:09:56 PM 0 - 16820 12700.00 65770.37 |__sysbench 09:09:56 PM 0 - 16821 18720.37 58808.33 |__sysbench 09:09:56 PM 0 - 16822 21382.41 64792.59 |__sysbench 09:09:56 PM 0 - 16823 16299.07 63200.00 |__sysbench 09:09:56 PM 0 - 16824 16655.56 65888.89 |__sysbench 09:09:56 PM 0 - 16825 20249.07 57767.59 |__sysbench 09:09:56 PM 0 - 16826 19690.74 55725.93 |__sysbench 09:09:56 PM 0 - 16827 20281.48 65908.33 |__sysbench 09:09:56 PM 0 - 16828 17264.81 70136.11 |__sysbench 09:09:56 PM 0 - 16829 13706.48 68283.33 |__sysbench 09:09:56 PM 0 - 16830 19050.00 68422.22 |__sysbench 09:09:56 PM 0 - 16831 14403.70 66034.26 |__sysbench 09:09:56 PM 0 - 16832 19878.70 59848.15 |__sysbench 09:09:56 PM 0 - 16833 18844.44 69676.85 |__sysbench 09:09:56 PM 0 - 16834 17438.89 76772.22 |__sysbench ... $watch -d cat /proc/interruptsEvery 2.0s: cat /proc/interrupts WeiyiGeek1: Wed Nov 24 21:12:52 2021 CPU0 CPU1 CPU2 CPU3 LOC: 11290842 8264060 8456662 11519861 Local timer interrupts .... RES: 8259277 9027295 9254487 9912950 Rescheduling interrupts
通过上面分析,我们可知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高,并且中断升高还是因为过多任务的调度问题导致得。
Tips: /proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信, 而 /proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
Tips: 友情提醒,sudo -i就可以快速切换到root啦😄 , 不加-i的话是以非登录模式切换sudo su root,不会拿到root的环境变量。
2.3 本章总结
Tips: 过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上。
上下文切换分几种?
进程上下文切换、线程上下文切换、中断上下文切换.
什么情况下会触发上下文切换?
系统调用、进程状态转换(运行、就绪、阻塞)、时间片耗尽、系统资源不足、sleep、优先级调度、硬件中断等.
线程上下文切换和进程上下文切换的最大区别?
线程是调度的基本单位,进程是资源拥有的基本单位,同属一个进程的线程,发生上下文切换,只切换线程的私有数据,共享数据不变,因此速度非常快。
中断上下文切换,如何理解?
为了快速响应硬件的事件(如USB接入),中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而打断其它进程执行时,需要进行上下文切换。中断事件过多,会无谓的消耗CPU资源,导致进程处理时间延长。
有哪些减少上下文切换的技术用例?
数据库连接池(复用连接)、合理设置应用的最大进程,线程数、直接内存访问DMA、零拷贝技术.
自愿与非自愿上下文切换的出现意味着那些性能问题?
自愿上下文切换变多(系统资源不足,进程在等待资源)以及 非自愿上下文切换变多(进程都在被强制调度,都在争抢CPU资源)。
系统中断详细以及中断发生类型如何查看?
中断只发生在内核态,如果中断次数变多,则说明CPU 被中断处理程序占用,在操作系统可通过查看/proc/interuppts的文件查询详细的中断信息(分析中断类型)。
每秒上下文切换多少次才算正常呢?
其实取决于系统本身的 CPU 性能,但是通常系统上下文切换次数比较稳定的区间在从数百到一万以内,但如果上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题(然后具体问题具体分析!)。
分析上下文切换次数过多问题的分析需要用到那些工具?
我们需要用到 vmstat(查看系统整体的平均上下文切换情况)、pidstat(查看进程或线程详细的上下文切换情况)以及/proc/interrupts()等工具,来辅助排查性能问题的根源。
Tips: 如果在 CentOS 中安装sysbench 执行后很快完事了的可以设置下 max-requests,执行命令如下sysbench --num-threads=10 --max-time=300 --max-requests=10000000 --test=threads run