[TOC]
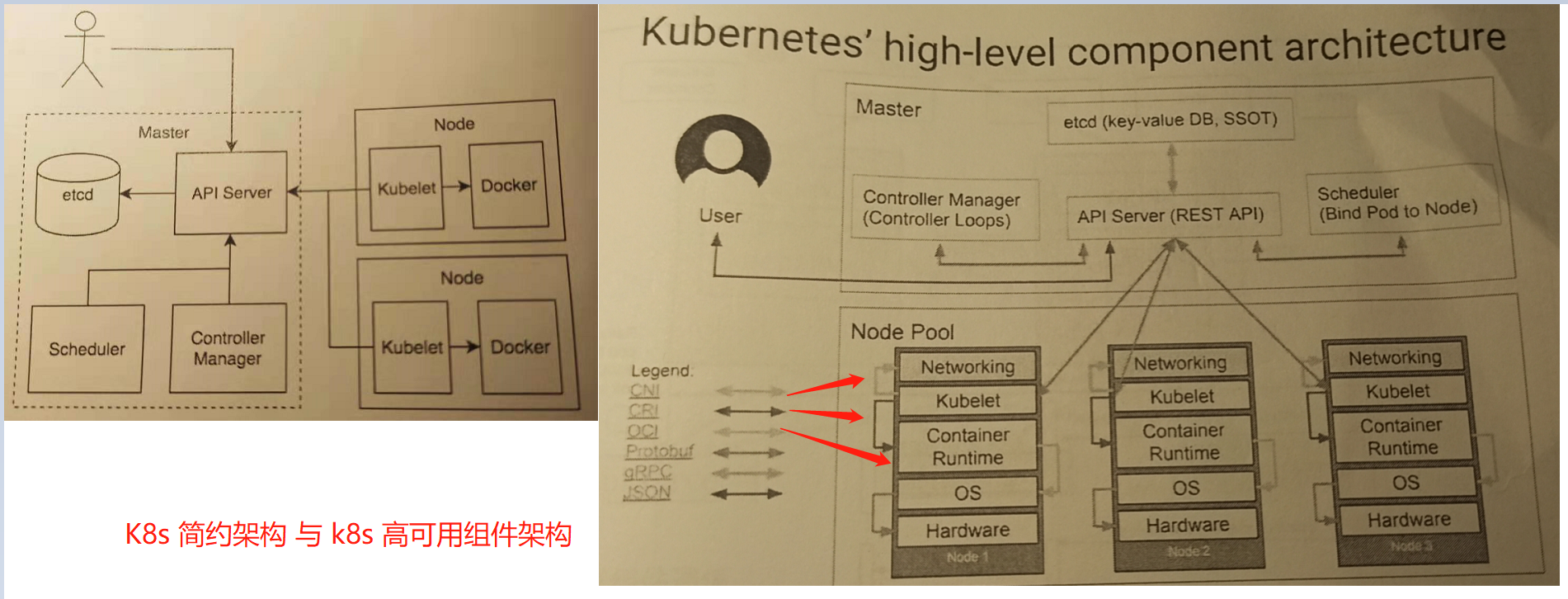
0x01 核心组件 基础架构 描述: 说过kubernetes架构中介绍到 k8s Master 由三个组件组成, 分别是API Server、Controller Manager 与 Scheduler
图示1.k8s架构图示
weiyigeek.top-k8s架构
基础知识 1.节点状态 Q:什么是节点? 由 master 组件管理,并包含了运行 Pod(容器组)所需的服务包括:容器引擎 / kubelet / kube-proxy
节点的状态包含如下信息:
Conditions:节点的状态正常的如下面的节点信息,实际在文件中是以JSON对象的形式存在;1 2 3 4 5 6 Ready OutOfDisk MemoryPressure PIDPressure DiskPressure NetworkUnvailable
Addresses
Capacity and Allocatable : 描述了节点上的可用资源的情况即CPU,内存,该节点可调度的最大 pod 数量
Capacity 中的字段表示节点上的资源总数
Allocatable 中的字段表示该节点上可分配给普通 Pod 的资源总数。
Info : 描述了节点的基本信息该信息以信息由节点上的 kubelet 收集。1 2 3 4 * Linux 内核版本 * Kubernetes 版本(kubelet 和 kube-proxy 的版本) * Docker 版本 * 操作系统名称
Q:如何查看节点状态? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 $kubectl get nodes -o widekubectl describe node <your-node-name> $kubectl describe node node-1Name: node-1 Roles: <none> Labels: beta.kubernetes.io/arch=amd64 beta.kubernetes.io/os=linux kubernetes.io/arch=amd64 kubernetes.io/hostname=node-1 kubernetes.io/os=linux Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock node.alpha.kubernetes.io/ttl: 0 projectcalico.org/IPv4Address: 10.20.172.82/24 projectcalico.org/IPv4IPIPTunnelAddr: 10.100.84.128 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Tue, 16 Jun 2020 15:15:11 +0800 Taints: <none> Unschedulable: false Lease: HolderIdentity: node-1 AcquireTime: <unset > RenewTime: Wed, 17 Jun 2020 00:01:37 +0800 Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkUnavailable False Tue, 16 Jun 2020 23:17:13 +0800 Tue, 16 Jun 2020 23:17:13 +0800 CalicoIsUp Calico is running on this node MemoryPressure False Tue, 16 Jun 2020 23:57:26 +0800 Tue, 16 Jun 2020 23:15:44 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Tue, 16 Jun 2020 23:57:26 +0800 Tue, 16 Jun 2020 23:15:44 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Tue, 16 Jun 2020 23:57:26 +0800 Tue, 16 Jun 2020 23:15:44 +0800 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Tue, 16 Jun 2020 23:57:26 +0800 Tue, 16 Jun 2020 23:16:35 +0800 KubeletReady kubelet is posting ready status Addresses: InternalIP: 10.20.172.82 Hostname: node-1 Capacity: cpu: 2 ephemeral-storage: 47285700Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 2037168Ki pods: 110 Allocatable: cpu: 2 ephemeral-storage: 43578501048 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 1934768Ki pods: 110 System Info: Machine ID: 6e65e151c0ef4248b78d6be0fb63eb58 System UUID: 564d504e-4027-b5c3-9c49-11f2de69bf26 Boot ID: 90c3795b-4823-41de-9893-ef6b89db9614 Kernel Version: 5.7.0-1.el7.elrepo.x86_64 OS Image: CentOS Linux 7 (Core) Operating System: linux Architecture: amd64 Container Runtime Version: docker://19.3.9 Kubelet Version: v1.18.3 Kube-Proxy Version: v1.18.3 PodCIDR: 10.100.1.0/24 PodCIDRs: 10.100.1.0/24 Non-terminated Pods: (2 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE --------- ---- ------------ ---------- --------------- ------------- --- kube-system calico-node-jp55x 250m (12%) 0 (0%) 0 (0%) 0 (0%) 46m kube-system kube-proxy-kglgh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 46m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 250m (12%) 0 (0%) memory 0 (0%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Starting <invalid> kubelet, node-1 Starting kubelet. Normal NodeHasSufficientMemory <invalid> (x2 over <invalid>) kubelet, node-1 Node node-1 status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure <invalid> (x2 over <invalid>) kubelet, node-1 Node node-1 status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID <invalid> (x2 over <invalid>) kubelet, node-1 Node node-1 status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced <invalid> kubelet, node-1 Updated Node Allocatable limit across pods Normal Starting <invalid> kube-proxy, node-1 Starting kube-proxy. Normal NodeReady <invalid> kubelet, node-1 Node node-1 status is now: NodeReady
注意事项:
1) 如果 Ready 类型Condition 的 status 持续为 Unkown 或者 False超过 pod-eviction-timeout(kube-controller-manager 的参数)所指定的时间(默认5分钟),节点控制器(node controller)将对该节点上的所有 Pod 执行删除的调度动作; 然而在某些特殊情况下(例如,节点网络故障)apiserver 不能够与节点上的 kubelet 通信导致删除 Pod 的指令不能下达到该节点的 kubelet 上,直到 apiserver 与节点的通信重新建立指令才下达到节点, 意味着虽然对Pod执行了删除的调用指令, 但是这些Pod仍然在失联的节点上运行。1 2 3 4 5 6 7 < kubernetes v1.5 : 节点控制器将从 apiserver 强制删除这些失联节点上的 Pod >= kubernetes v1.5 : 节点控制器将不会强制删除这些 Pod,直到已经确认他们已经停止运行为止,此时发现失联节点上的Pod仍然是在运行的(在该节点上运行docker ps即可以看见容器的运行状态), 然而 apiserver 中他们的状态已经变为 Terminating 或者 Unknown; == Kubernetes v1.12 : TaintNodesByCondition 特性利用node lifecycle controller 将自动创建该 Condition 对应的 污点。相应地调度器在选择合适的节点时,不再关注节点的 Condition而是检查节点的污点和 Pod 的容忍 kubectl delete node your-node-name
2.节点管理 描述:前面我们说过Node(节点)可以是一台物理主机或者虚拟机的资源池再或者云供应商创建的,在向 Kubernetes 中创建节点时,仅仅是创建了一个描述该节点的 API 对象。
注意事项:
Kubernetes 在 APIServer 上创建一个节点 API 对象(节点的描述),并且基于 metadata.name 字段对节点进行健康检查.节点有效(节点组件正在运行),则可以向该节点调度 Pod;否则该节点 API 对象将被忽略,直到节点变为有效状态。
Kubernetes 将保留无效的节点 API 对象,并不断地检查该节点是否有效。除非您使用 kubectl delete node my-first-k8s-node 命令删除该节点。
1 2 3 4 5 6 7 apiVersion: v1 kind: Node metadata: name: "10.240.79.157" labels: name: "my-first-k8s-node"
节点控制器(Node Controller) 负责管理节点的 Kubernetes master 组件;
工作流程:
1.首先节点控制器在注册节点时为节点分配 CIDR 地址块1 2 3 4 5 6 7 $kubectl describe node node-1Addresses: InternalIP: 10.20.172.82 projectcalico.org/IPv4Address: 10.20.172.82/24 projectcalico.org/IPv4IPIPTunnelAddr: 10.100.84.128 PodCIDR: 10.100.1.0/24 PodCIDRs: 10.100.1.0/24
2.第二,节点控制器通过(Kube-controller-manager)和云供应商(cloud-controller-manager)接口检查节点列表中每一个节点对象对应的虚拟机是否可用。
在云环境中只要节点状态异常,节点控制器检查其虚拟机在云供应商的状态,如果虚拟机不可用自动将节点对象从 APIServer 中删除。
在本地局域网环境中如果节点状态异常它会不断地检查该节点是否有效,并不会将点对象从 APIServer 中删除,除非您手动删除;
3.节点控制器监控节点的健康状况,每隔 --node-monitor-period 秒检查一次节点的状态;当节点变得不可触达时(例由于节点已停机,节点控制器不再收到来自节点的心跳信号),默认40秒未收到心跳,此时节点控制器将节点API对象的NodeStatus Condition取值从 NodeReady 更新为 Unknown;然后在等待 pod-eviction-timeout 为 5分钟 时间后,将节点上的所有 Pod 从节点驱逐。1 2 3 4 5 - 1.1) NodeStatus 的更新频率远高于 node lease ,因为是每次节点向 master 发出心跳信号NodeStatus 都将被更新, 只有在 NodeStatus 发生改变,或者足够长的时间未接收到 NodeStatus 更新时,节点控制器才更新 node lease(默认为1分钟,比节点失联的超时时间40秒要更长) - 1.2) 由于 node lease 比 NodeStatus 更轻量级,该特性显著提高了节点心跳机制的效率,并使 Kubernetes 性能和可伸缩性得到了提升; - 1.3) 在v1.4 中优化了节点控制器的逻辑以便更好的处理大量节点不能触达 master 的情况;主要的优化点在于节点控制器在决定是否执行 Pod 驱逐的动作时,会检查集群中所有节点的状态。默认情况下节点控制器限制了驱逐 Pod 的速率为 `--node-eviction-rate (默认值是0.1)每秒`即每10s驱逐一个Pod; - 1.4) 当节点所在的高可用区出现故障时,节点控制器驱逐 Pod 的方式将不一样;
节点自注册(Self-Registration) --register-node 为 true(默认为 true),kubelet 会尝试将自己注册到 API Server。
–kubeconfig:向 apiserver 进行认证时所用身份信息的路径
–cloud-provider:向云供应商读取节点自身元数据
–register-node:自动向 API Server 注册节点
–register-with-taints:注册节点时,为节点添加污点(逗号分隔,格式为 <key>=<value>:<effect>)
–node-ip:节点的 IP 地址
–node-labels:注册节点时,为节点添加标签
–node-status-update-frequency:向 master 节点发送心跳信息的时间间隔
如果 Node authorization mode 和 NodeRestriction admission plugin 被启用,kubelet 只拥有创建/修改其自身所对应的节点 API 对象的权限。
手动管理节点 --register-node 设置为 false,管理员可以修改节点API对象不管是否设置了该参数。增加/减少标签,标记节点为不可调度(unschedulable)
执行如下命令可将节点标记为不可调度(unschedulable),此时将阻止新的 Pod 被调度到该节点上,但是不影响任何已经在该节点上运行的 Pod。1 2 3 4 $ kubectl cordon $NODENAME $ kubectl cordon node-1 node/node-1 cordoned
Tips: DaemonSet Controller 创建的 Pod 将绕过 Kubernetes 调度器,并且忽略节点的 unschedulable 属性。因为我们假设 Daemons 守护进程属于节点,尽管该节点在准备重启前,已经排空了上面所有的应用程序。
节点容量(Node Capacity)
如果您手动管理节点,您需要在添加节点时自己设置节点的容量。
K8s调度器在调度 Pod 到节点上时,将确保节点上有足够的资源。
具体来说调度器检查节点上所有容器的资源请求之和不大于节点的容量。此时只能检查由 kubelet 启动的容器,不包括直接由容器引擎启动的容器,更不包括不在容器里运行的进程。
3.控制器 Q: 什么是控制器?
在恒温器上设定好目标温度,就是在告诉该控制循环你想要的目标状态。
房间里的实际温度,是当前状态。
恒温器通过打开或关闭加热装置,不断地使当前状态接近于目标状态。
在 Kubernetes 中控制器就是上面所说的 控制循环,它不断监控着集群的状态,并对集群做出对应的变更调整。每一个控制器都不断地尝试着将 当前状态 调整到 目标状态。作为一个底层设计原则Kubernetes使用了大量的控制器,每个控制器都用来管理集群状态的某一个方面。普遍来说任何一个特定的控制器都使用一种 API 对象作为其目标状态,并使用和管理多种类型的资源,以达到目标状态。使用许多个简单的控制器比使用一个全能的控制器要更加有优势。控制器可能会出故障,而这也是在设计 Kubernetes 时要考虑到的事情。
1.可能存在多种控制器可以创建或更新相同类型的 API 对象,为了避免混淆,Kubernetes 控制器在创建新的 API 对象时,会将该对象与对应的控制 API 对象关联,并且只关注与控制对象关联的那些对象。
例如,Deployment 和 Job,这两类控制器都创建 Pod。Job Controller 不会删除 Deployment Controller 创建的 Pod,因为控制器可以通过标签信息区分哪些 Pod 是它创建的。
2.目标状态 vs 当前状态,Kubernetes 使用了 云原生(cloud-native)的视角来看待系统,并且可以持续应对变化。您的集群在运行的过程中,任何时候都有可能发生突发事件,而控制器则自动地修正这些问题。这就意味着,本质上,您的集群永远不会达到一个稳定不变的状态。
例如,通过控制器监控集群状态并利用负反馈原理不断接近目标状态的系统,相较于那种完成安装后就不再改变的系统,是一种更高级的系统形态,尤其是在您将运行一个大规模的复杂集群的情况下。
控制器模式
理论上控制器可以自己直接执行调整动作,实际上控制器发送消息到 API Server 而不是直接自己执行调整动作。
(1) API-Server 控制
Job 是一种 Kubernetes API 对象,一个 Job 将运行一个(或多个)Pod,执行一项任务,然后停止。当新的 Job 对象被创建时,Job Controller 将确保集群中有合适数量的节点上的 kubelet 启动了指定个数的 Pod,以完成 Job 的执行任务。Job Controller 自己并不执行任何 Pod 或容器,而是发消息给 API Server,由其他的控制组件配合 API Server,以执行创建或删除 Pod 的实际动作。
当新的 Job 对象被创建时,目标状态是指定的任务被执行完成。Job Controller 调整集群的当前状态以达到目标状态:创建 Pod 以执行 Job 中指定的任务, 控制器同样也会更新其关注的 API 对象。
例如:一旦 Job 的任务执行结束,Job Controller 将更新 Job 的 API 对象,将其标注为 Finished。(这有点儿像是恒温器将指示灯关闭,以表示房间里的温度已经到达指定温度。)
(2) 直接控制
例如:您想用一个控制器确保集群中有足够的节点,此时控制器需要调用云供应商的接口以创建新的节点或移除旧的节点。这类控制器将从 API Server 中读取关于目标状态的信息,并直接调用外部接口以实现调整目标。
4.集群内部通信 描述:我们知道 Kubernetes集群和Master节点(实际上是API Server)之间的通信路径;
Master-Node 之间的通信可以分为如下两类:
(1) Cluster to Master:所有从集群访问 Master 节点的通信,都是针对 apiserver 的(没有任何其他 master 组件发布远程调用接口),得益于下面这些措施,从集群(节点以及节点上运行的 Pod)访问 master 的连接是安全的,因此,可以通过不受信的网络或公网连接 Kubernetes 集群
API Server监听的HTTPS端口是您在安装k8s的时候进行设置的,并配置了一种或多种客户端认证方式 authentication;注意至少需要配置一种形式的 授权方式 authorization ,尤其是 匿名访问 anonymous requests 或 Service Account Tokens 被启用的情况下;
节点上必须配置集群(apiserver)的公钥根证书(public root certificate),此时,在提供有效的客户端身份认证的情况下,节点可以安全地访问 APIServer;
对于需要调用 APIServer 接口的 Pod,应该为其关联 Service Account,此时,Kubernetes将在创建Pod时自动为其注入公钥根证书(public root certificate)以及一个有效的 bearer token(放在HTTP请求头Authorization字段)。所有名称空间中,都默认配置了名为 kubernetes Kubernetes Service,该 Service对应一个虚拟 IP(默认为 10.96.0.1),发送到该地址的请求将由 kube-proxy 转发到 apiserver 的 HTTPS 端口上;
(2) Master to Cluster: 存在着两条主要的通信路径前者是apiserver 访问集群中每个节点上的 kubelet 进程,后者是使用 apiserver 的 proxy 功能,从 apiserver 访问集群中的任意节点、Pod、Service;
apiserver 会访问 kubelet 情况如下抓取 Pod 的日志时,通过 kubectl exec -it 指令(或 kuboard 的终端界面)获得容器的命令行终端时,提供 kubectl port-forward 功能时,连接访问端点是 kubelet 的 HTTPS 端口,但是默认情况下apiserver 不校验 kubelet 的 HTTPS 证书,此时链接可能会收到 man-in-the-middle 攻击,如果在不受信网络或者公网上运行时是不安全的;如果要校验 kubelet 的 HTTPS 证书,可以通过 --kubelet-certificate-authority 参数为 apiserver 提供校验 kubelet 证书的根证书。如果不能完成这个配置,又需要通过不受信网络或公网将节点加入集群,则需要使用 SSH隧道 连接 apiserver 和 kubelet。同时,Kubelet authentication/authorization需要激活,以保护 kubelet AP
apiserver 访问 nodes, pods, services 的连接使用的是 HTTP 连接,没有进行身份认证也没有进行加密传输,此时可以通过增加 https 作为 节点/Pod/Service 请求 URL 的前缀,但是 HTTPS 证书并不会被校验,也无需客户端身份认证,因此该连接是无法保证一致性的
Kubernetes 支持 SSH隧道(tunnel)来保护 Master –> Cluster 访问路径(对于公网加入集群需要通信的情况下),SSH隧道当前已被不推荐使用(deprecated),Kubernetes 正在设计新的替代通信方式。
5.集群高可用 Tips: 高可用区出现故障时节点控制器驱逐Pod,将检查高可用区里故障节点的百分比(NodeReady Condition 的值为 Unknown 或 False);
如果故障节点的比例不低于 --unhealthy-zone-threshold(默认为 0.55) 则降低驱逐 Pod 的速率;
如果集群规模较小(少于等于 --large-cluster-size-threshold 个节点,默认值为 50),则停止驱逐 Pod;
如果集群规模大于 --large-cluster-size-threshold 个节点,则驱逐 Pod 的速率降低到 --secondary-node-eviction-rate (默认值为 0.01)每秒;
针对每个高可用区使用这个策略的原因是,某一个高可用区可能与 master 隔开了,而其他高可用区仍然保持连接。如果您的集群并未分布在云供应商的多个高可用区上,此时,您只有一个高可用区(即整个集群)。
将集群的节点分布到多个高可用区最大的原因是,在某个高可用区出现整体故障时,可以将工作负载迁移到仍然健康的高可用区。因此,如果某个高可用区的所有节点都出现故障时,节点控制器仍然使用正常的驱逐 Pod 的速率(–node-eviction-rate)。
最极端的情况是,所有的高可用区都完全不可用(例如,集群中一个健康的节点都没有),此时节点控制器 master 节点的网络连接出现故障,并停止所有的驱逐 Pod 的动作,直到某些连接得到恢复。
简单的集群配置文件:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 vim kubeadm-config.yaml apiServer: certSANs: - k8s-master-01 - k8s-master-02 - k8s-master-03 - master.k8s.io - 192.168.9.80 - 192.168.9.81 - 192.168.9.82 - 192.168.9.83 - 127.0.0.1 extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta1 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controlPlaneEndpoint: "master.k8s.io:16443" controllerManager: {} dns: type : CoreDNS etcd: local : dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: v1.16.3 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 serviceSubnet: 10.1.0.0/16 scheduler: {}
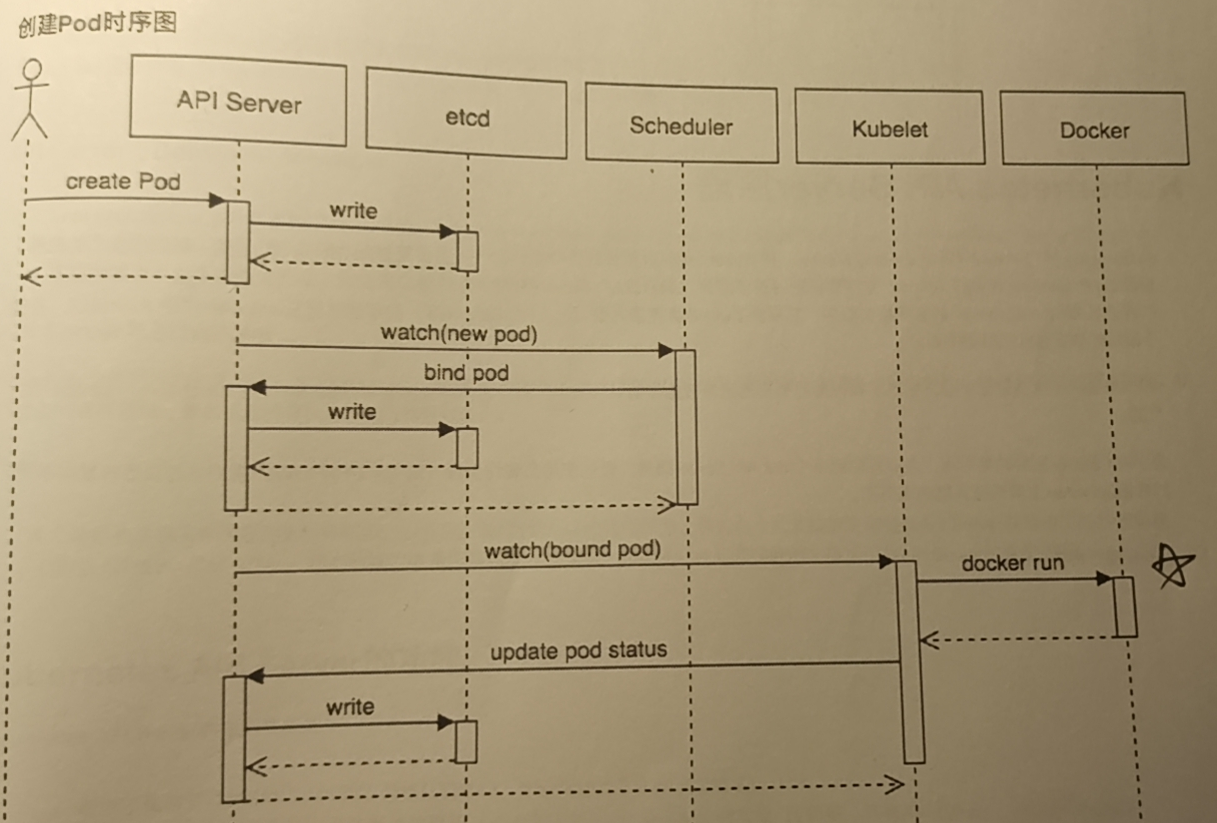
0x02 原理剖析 Pod 操作时序图 1) 创建
1.用户通过kubectl创建Pod请求通知API SERVER,并写入到etcd数据库中;
2.然后通过API SERVER与Scheduler联系,将该Pod绑定在指定的Node节点之上;
3.API Server 进行记录相关节点与Pod绑定信息,并且将该绑定信息写入到etcd数据库之中;
4.kubelet 通过 CRI 调用 Docker 进行管理容器,同时更新Pod状态;
5.将 Pod 状态同步到 etcd数据库中;
weiyigeek.top-Pod创建时序图
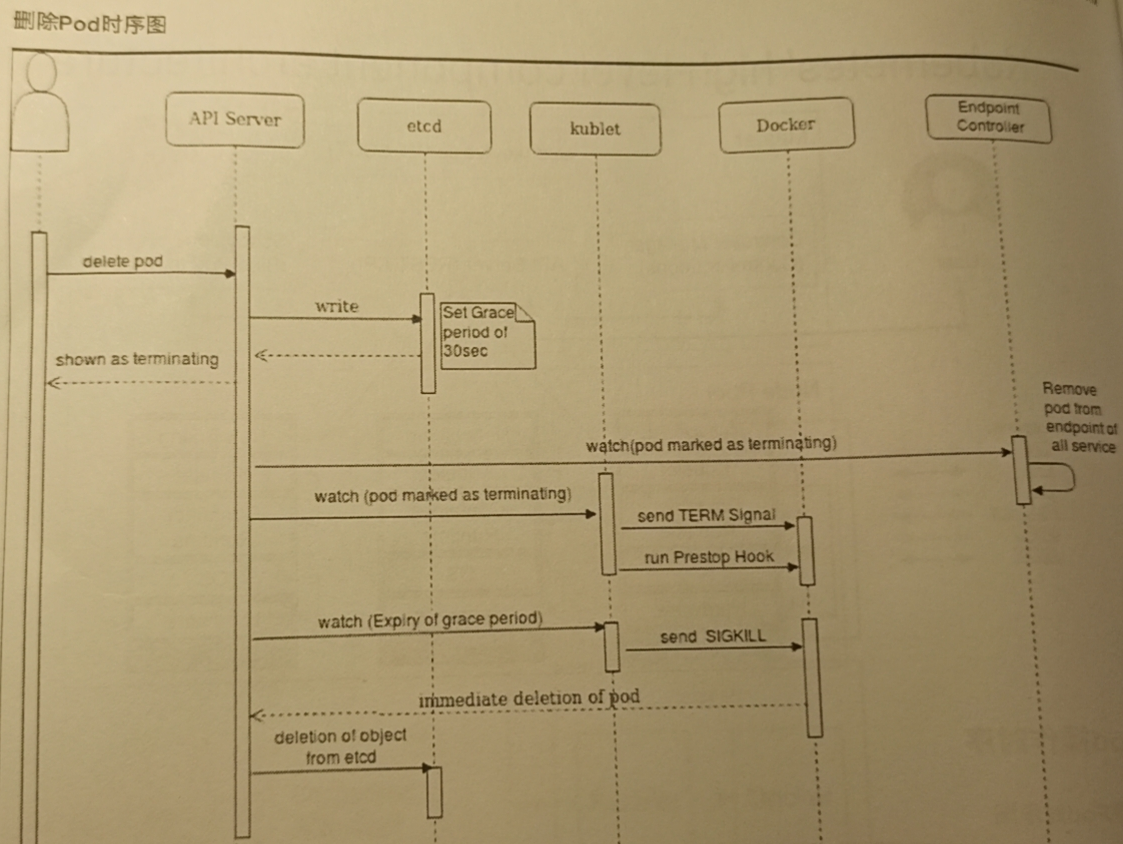
2) 删除
1.用户通过kubectl发送删除Pod请求,并且将该请求写入到etcd之中
2.等待30s后删除该Pod, 并回显到终端之中
3.Endport Controller 将该Pod的端点进行回收
4.Api Server 发送Term Signal信号,并触发运行Prestop Hook
5.此时Docker接收到Hook后发送SigKill信号此时将会立即删除容器,并通知Api Server
6.将写入到Etcd数据库之中该Pod信息进行删除
weiyigeek.top-Pod删除时序图
K8s 集群架构 Api-Server 描述: K8S API Server 简称Kubernetes Master是k8s最重要的核心组件之一负责集群内各个模块的通信。其通过kube-apiserver的进程提供服务,它提供了k8s各类资源对象(Pod/RC/Server)等的增删改查以及Watch等HTTP Rest接口,它是整个系统的数据总线和数据中心;
原理: 集群中各个功能模块通过API Server将信息存入etcd之中,当需要获取这些信息时则通过API Server提供的REST接口实现, 从而实现各个组件之间的交互; 即API Server本身是无状态服务,通过将资源数据存储到etcd中,后续业务则是由Sheduler与Controller-manager进行执行;
高可用: K8s Api Server 服务高可用可以同时起多个K8S API Server服务,通过使用负载均衡器(Nginx / HAProxy)把客户端的流量转发到不同的后端ApiServer从而实现接入层的高可用;
API Server 功能: 提供了集群管理的REST API 接口(包括认证授权、数据校验及集群状态变更)和提供其它模块之间的数据交互和通信枢纽(只有API Server才能直接操作etcd数据库)、资源配额控制的入口、拥有完备的集群安全机制;
API Server 应用场景:
1) 基于Kubernetes的管理平台
2) 基于Pod中调用Api Server的请求
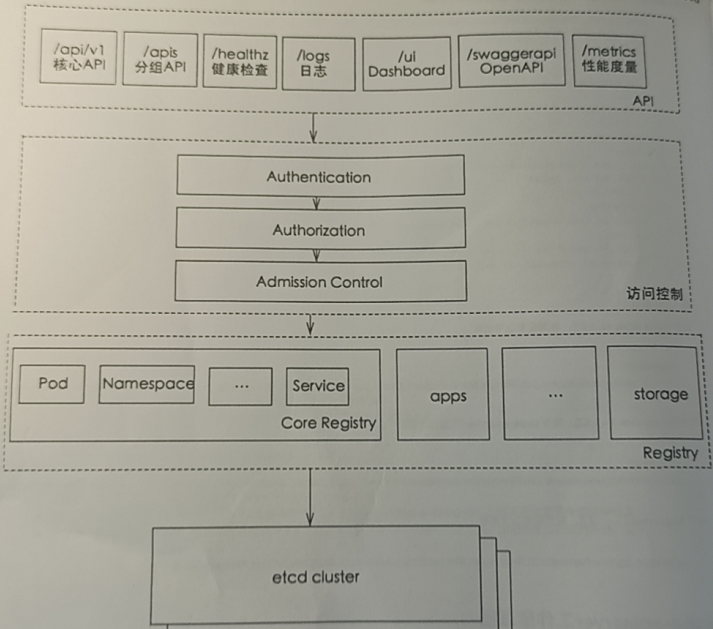
API Server 工作原理图: 认证、授权、准入等安全校验功能,同时负责集群状态的存储(ETCD)操作;
weiyigeek.top-API-Server工作原理图
Tips : 分成四个部分一是API、二是访问控制、三是Registry(Pod Namespace Services)、四是Etcd Cluster集群
Api Server 与 集群三大组件通信介绍:
(1) API Server 与 Kubelet 介绍: 在 Node节点 上的k8s进程定期调用 API Server 的REST接口报告自身状态,API Server 收到信息后会将节点状态存储在etcd数据库之中,另外 kubelet 还会调用API Server 的Watch接口监听Pod信息,正对于Pod增删改查分别执行相应逻辑;
(2) API Server 与 Controller-Manager介绍: 该组件对应的进程名为kube-controller-manager。其调用API Server的Watch接口,实时监控Node信息并做出相应的处理;
(3) API Server 与 Scheduler 介绍: 该组件对应的进程名kube-scheduler其通过API Server的Watch接口,监听到新创建Pod请求后会根据设定的策略执行相应的调度逻辑,最后成功将Pod绑定在目标节点之上;
Tips: 各个功能模块都会定期从API Server获取指定的资源对象然后通过LIST 或者 Watch采用缓存来缓存数据到本地之中,然后通过访问缓存的方式来减少对Api Server访问的压力;
API-Server 启动参数: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 kube-apiserver - --advertise-address=192.168.12.107 - --allow-privileged=true - --authorization-mode=Node,RBAC - --client-ca-file=/etc/kubernetes/pki/ca.crt - --enable -admission-plugins=NodeRestriction - --enable -bootstrap-token-auth=true - --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt - --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt - --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key - --etcd-servers=https://127.0.0.1:2379 - --insecure-port=0 - --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt - --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt - --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key - --requestheader-allowed-names=front-proxy-client - --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt - --requestheader-extra-headers-prefix=X-Remote-Extra- - --requestheader-group-headers=X-Remote-Group - --requestheader-username-headers=X-Remote-User - --secure-port=6443 - --service-account-key-file=/etc/kubernetes/pki/sa.pub - --service-cluster-ip-range=10.96.0.0/12 - --tls-cert-file=/etc/kubernetes/pki/apiserver.crt - --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
REST API 描述: Kube-apiserver 同时支持提供https(默认监听在6443端口)以及http(默认监听127.0.0.1的8080端口),其中后者是非安全接口,不做任何认证授权机制生产环境中不建议启用,注意两个接口REST API 格式一致;
Q: 如果查询API调用格式? 1 2 3 4 5 6 7 8 9 10 11 12 $ kubectl -v 8 get pod
Swagger && Swagger-UI /swagger.json查看OpenAPI;
操作流程:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 $ kubectl proxy Starting to serve on 127.0.0.1:8001 curl http://127.0.0.1:8001/swagger.json { "paths" : [ "/apis" , "/apis/" , "/apis/apiextensions.k8s.io" , "/apis/apiextensions.k8s.io/v1" , "/apis/apiextensions.k8s.io/v1beta1" , "/healthz" , "/healthz/etcd" , "/healthz/log" , "/healthz/ping" , "/healthz/poststarthook/crd-informer-synced" , "/healthz/poststarthook/generic-apiserver-start-informers" , "/healthz/poststarthook/max-in-flight-filter" , "/healthz/poststarthook/start-apiextensions-controllers" , "/healthz/poststarthook/start-apiextensions-informers" , "/livez" , "/livez/etcd" , "/livez/log" , "/livez/ping" , "/livez/poststarthook/crd-informer-synced" , "/livez/poststarthook/generic-apiserver-start-informers" , "/livez/poststarthook/max-in-flight-filter" , "/livez/poststarthook/start-apiextensions-controllers" , "/livez/poststarthook/start-apiextensions-informers" , "/metrics" , "/openapi/v2" , "/readyz" , "/readyz/etcd" , "/readyz/informer-sync" , "/readyz/log" , "/readyz/ping" , "/readyz/poststarthook/crd-informer-synced" , "/readyz/poststarthook/generic-apiserver-start-informers" , "/readyz/poststarthook/max-in-flight-filter" , "/readyz/poststarthook/start-apiextensions-controllers" , "/readyz/poststarthook/start-apiextensions-informers" , "/readyz/shutdown" , "/version" ] }c ~$ curl http://127.0.0.1:8001 { "paths" : [ "/api" , "/api/v1" , "/apis" , "/apis/" , "/apis/admissionregistration.k8s.io" , "/apis/admissionregistration.k8s.io/v1" , "/apis/admissionregistration.k8s.io/v1beta1" , "/apis/apiextensions.k8s.io" , "/apis/apiextensions.k8s.io/v1" , "/apis/apiextensions.k8s.io/v1beta1" , "/apis/apiregistration.k8s.io" , "/apis/apiregistration.k8s.io/v1" , "/apis/apiregistration.k8s.io/v1beta1" , "/apis/apps" , "/apis/apps/v1" , "/apis/authentication.k8s.io" , "/apis/authentication.k8s.io/v1" , "/apis/authentication.k8s.io/v1beta1" , "/apis/authorization.k8s.io" , "/apis/authorization.k8s.io/v1" , "/apis/authorization.k8s.io/v1beta1" , "/apis/autoscaling" , "/apis/autoscaling/v1" , "/apis/autoscaling/v2beta1" , "/apis/autoscaling/v2beta2" , "/apis/batch" , "/apis/batch/v1" , "/apis/batch/v1beta1" , "/apis/certificates.k8s.io" , "/apis/certificates.k8s.io/v1" , "/apis/certificates.k8s.io/v1beta1" , "/apis/coordination.k8s.io" , "/apis/coordination.k8s.io/v1" , "/apis/coordination.k8s.io/v1beta1" , "/apis/discovery.k8s.io" , "/apis/discovery.k8s.io/v1beta1" , "/apis/events.k8s.io" , "/apis/events.k8s.io/v1" , "/apis/events.k8s.io/v1beta1" , "/apis/extensions" , "/apis/extensions/v1beta1" , "/apis/networking.k8s.io" , "/apis/networking.k8s.io/v1" , "/apis/networking.k8s.io/v1beta1" , "/apis/node.k8s.io" , "/apis/node.k8s.io/v1beta1" , "/apis/policy" , "/apis/policy/v1beta1" , "/apis/rbac.authorization.k8s.io" , "/apis/rbac.authorization.k8s.io/v1" , "/apis/rbac.authorization.k8s.io/v1beta1" , "/apis/redis.kun" , "/apis/redis.kun/v1alpha1" , "/apis/scheduling.k8s.io" , "/apis/scheduling.k8s.io/v1" , "/apis/scheduling.k8s.io/v1beta1" , "/apis/storage.k8s.io" , "/apis/storage.k8s.io/v1" , "/apis/storage.k8s.io/v1beta1" , "/healthz" , "/healthz/autoregister-completion" , "/healthz/etcd" , "/healthz/log" , "/healthz/ping" , "/healthz/poststarthook/aggregator-reload-proxy-client-cert" , "/healthz/poststarthook/apiservice-openapi-controller" , "/healthz/poststarthook/apiservice-registration-controller" , "/healthz/poststarthook/apiservice-status-available-controller" , "/healthz/poststarthook/bootstrap-controller" , "/healthz/poststarthook/crd-informer-synced" , "/healthz/poststarthook/generic-apiserver-start-informers" , "/healthz/poststarthook/kube-apiserver-autoregistration" , "/healthz/poststarthook/max-in-flight-filter" , "/healthz/poststarthook/rbac/bootstrap-roles" , "/healthz/poststarthook/scheduling/bootstrap-system-priority-classes" , "/healthz/poststarthook/start-apiextensions-controllers" , "/healthz/poststarthook/start-apiextensions-informers" , "/healthz/poststarthook/start-cluster-authentication-info-controller" , "/healthz/poststarthook/start-kube-aggregator-informers" , "/healthz/poststarthook/start-kube-apiserver-admission-initializer" , "/livez" , "/livez/autoregister-completion" , "/livez/etcd" , "/livez/log" , "/livez/ping" , "/livez/poststarthook/aggregator-reload-proxy-client-cert" , "/livez/poststarthook/apiservice-openapi-controller" , "/livez/poststarthook/apiservice-registration-controller" , "/livez/poststarthook/apiservice-status-available-controller" , "/livez/poststarthook/bootstrap-controller" , "/livez/poststarthook/crd-informer-synced" , "/livez/poststarthook/generic-apiserver-start-informers" , "/livez/poststarthook/kube-apiserver-autoregistration" , "/livez/poststarthook/max-in-flight-filter" , "/livez/poststarthook/rbac/bootstrap-roles" , "/livez/poststarthook/scheduling/bootstrap-system-priority-classes" , "/livez/poststarthook/start-apiextensions-controllers" , "/livez/poststarthook/start-apiextensions-informers" , "/livez/poststarthook/start-cluster-authentication-info-controller" , "/livez/poststarthook/start-kube-aggregator-informers" , "/livez/poststarthook/start-kube-apiserver-admission-initializer" , "/logs" , "/metrics" , "/openapi/v2" , "/readyz" , "/readyz/autoregister-completion" , "/readyz/etcd" , "/readyz/informer-sync" , "/readyz/log" , "/readyz/ping" , "/readyz/poststarthook/aggregator-reload-proxy-client-cert" , "/readyz/poststarthook/apiservice-openapi-controller" , "/readyz/poststarthook/apiservice-registration-controller" , "/readyz/poststarthook/apiservice-status-available-controller" , "/readyz/poststarthook/bootstrap-controller" , "/readyz/poststarthook/crd-informer-synced" , "/readyz/poststarthook/generic-apiserver-start-informers" , "/readyz/poststarthook/kube-apiserver-autoregistration" , "/readyz/poststarthook/max-in-flight-filter" , "/readyz/poststarthook/rbac/bootstrap-roles" , "/readyz/poststarthook/scheduling/bootstrap-system-priority-classes" , "/readyz/poststarthook/start-apiextensions-controllers" , "/readyz/poststarthook/start-apiextensions-informers" , "/readyz/poststarthook/start-cluster-authentication-info-controller" , "/readyz/poststarthook/start-kube-aggregator-informers" , "/readyz/poststarthook/start-kube-apiserver-admission-initializer" , "/readyz/shutdown" , "/version" ] } $ curl http://127.0.0.1:8001/version { "major" : "1" , "minor" : "19" , "gitVersion" : "v1.19.6" , "gitCommit" : "fbf646b339dc52336b55d8ec85c181981b86331a" , "gitTreeState" : "clean" , "buildDate" : "2020-12-18T12:01:36Z" , "goVersion" : "go1.15.5" , "compiler" : "gc" , "platform" : "linux/amd64" }
如果想保留部分的 REST API 可以通过加入 --reject-paths="^/api/v1/pods",如果想限制非法的客户端访问则采用--accept-host="^127\\.0\\.0\\.1$,^\\[::1\\]$" (注意支持正则表达式)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 ~$ curl -si http://127.0.0.1:8001/api/v1/pods | more HTTP/1.1 200 OK Cache-Control: no-cache, private Content-Type: application/json Date: Sun, 28 Feb 2021 07:02:56 GMT Vary: Accept-Encoding Transfer-Encoding: chunked ~$ kubectl proxy --reject-paths="^/api/v1/pods" --accept-hosts="^127\\.0\\.0\\.1$,^\\[::1\\]$" --port 8888 -v 2 Starting to serve on 127.0.0.1:8888 ~$ curl -si http://127.0.0.1:8888/api/v1/pods | more HTTP/1.1 403 Forbidden Content-Type: text/plain; charset=utf-8 X-Content-Type-Options: nosniff Date: Sun, 28 Feb 2021 07:07:20 GMT Content-Length: 10 Forbidden ~$ curl -si http://192.168.12.107:8888/version | more ~$ curl -s http://127.0.0.1:8888/api/v1 | head -n 13 { "kind" : "APIResourceList" , "groupVersion" : "v1" , "resources" : [ { "name" : "bindings" , "singularName" : "" , "namespaced" : true , "kind" : "Binding" , "verbs" : [ "create" ] }, ...... ~$ curl -s http://127.0.0.1:8888/api/v1/pods ~$ curl -s http://127.0.0.1:8888/api/v1/servics ~$ curl -s http://127.0.0.1:8888/api/v1/deployments
下面我们可以通过访问Swagger-UI接口查看REST API接口,但是首先需要配置启用swagger-ui具有操作流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 - --enable -swagger-ui=true - --insecure-bind-address=0.0.0.0 - --insecure-port=30999 /etc/kubernetes/manifests$ kubectl get pod -n kube-system -o wide | grep "kube-apiserver-weiyigeek-107" kube-apiserver-weiyigeek-107 1/1 Running 0 87s 192.168.12.107 weiyigeek-107 $ curl -si http://127.0.0.1:30999 HTTP/1.1 200 OK Cache-Control: no-cache, private Content-Type: application/json Date: Sun, 28 Feb 2021 08:24:07 GMT Transfer-Encoding: chunked
Controller-Manager 描述: Controller Manager 作为集群的管理控制中心(大脑),负责整个集群内的Node、Pod Replica、Endpoint、Namespace、ServiceAccout以及ResourceQuota; 它通过API Server监控整个集群状态,并确保集群处于预期的工作状态;
Controller-Manager 分类由一系列的控制器组成:
Node (实时获取Node相关信息,实现管理和监控集群中各个节点的相关控制功能)
Namespace
Replication (副本控制器 - 弹性伸缩Scalling、滚动升级RollingUpdate)
Deployment (无状态推荐使用)
StatefulSet (有状态持久卷推荐使用)
Daemon
Cronjob
Job
Service Controller (与外部云平台的接口控制器)
ServiceAccount Controller
Endport Controller (集群中Service对应的全部Pod副本访问地址)
Garbage Controller
Volume Control
ResourceQuota Controller (资源配额管理指定的资源对象对资源消费的限制,避免由于服务缺陷导致系统资源被过分消费)
而云Controller-Manager用来配合云服务提供商的控制,也包括一系列的控制器如:
Node Controller
Route Controller
Service Controller
Scheduler 描述: 优良的调度是分布式系统的核心,承载着整个集群的调度功能,其根据特定的调度算法和策略,将Pod调度到最优工作节点之上,从而更合理与更充分的利用集群计算资源,使得资源更好的服务于业务服务的需求;
Tips : Scheduler 是一个调度器, 普通用户可以将其理解为一个黑盒(里面是待调度的Pod和全部计算节点的信息),经过黑盒内部的调度算法和策略处理输出为最优的节点,而后将Pod调度在该节点之上;
Q: 上述过程看似简单但在实际的生产环境的调度过程中,由很多问题需要进行考虑;
如何保证全部计算机节点调度的公平性?
如何保证每个节点都能被分配资源?
计算资源如何能够被高效利用?
集群所有计算资源如何才能最大化的使用?
如何保证Pod调度的性能和效率
如何能够快速对大批量的Pod完成调度到较优的计算机节点之上?
是否可以根据实际需求进行定制自己的调度逻辑和策略?
Tips: 用户可以自定义调度器并以插件的形式与Kubernetes集成或集成其他调度器,便于调度不同类型的任务。
K8s调度器的源码位于kubernetes/plugin中而创建和运行的过程对应的代码在plugin/pkg/scheduler/scheduler.go。其大体的代码目录结构如下所示:1 2 3 4 5 6 7 8 kubernetes/plugin/pkg/ `-- scheduler //调度相关的具体实现 |-- algorithm | |-- predicates //节点筛选策略 | `-- priorities //节点打分策略 | `-- util |-- algorithmprovider | `-- defaults //定义默认的调度器
上面初步介绍了Kubernetes调度器。具体的说,调度器是Kubernetes容器集群管理系统中加载并运行的调度程序,负责收集、统计分析容器集群管理系统中所有Node的资源使用情况,然后以此为依据将新建的Pod发送到优先级最高的可用Node上去建立。
Kubernetes调度器使用Predicates和Priorites来决定一个Pod应该运行在哪一个节点上, 即调度分为以下几个部分:
首先是预选过程,过滤掉不满足条件的节点,称为 Predicates (回答“能不能”的问题-强制性规则)
然后是优选过程,对通过的节点按照优先级排序,称为 Priorities (回答“哪个更适合的问题”-非强制性规则)
最后从中选择优先级最高的节点。
注意: 如果中间任何一步骤有错误,就直接返回错误。
Tips : 如果在预选(Predicates)过程中,如果所有的节点都不满足条件,Pod 会一直处在Pending 状态,直到有节点满足条件,这期间调度器会不断的重试。经过节点过滤后,如多个节点满足条件,会按照节点优先级(priorities)大小对节点排序,最后选择优先级最高的节点部署Pod。
具体的调度过程:
1) 首先客户端通过API Server的REST API/kubectl/helm创建pod/service/deployment/job等,支持类型主要为JSON/YAML/helm tgz。
2) 接下来API Server收到用户请求,存储到相关数据到etcd。
3) 调度器通过API Server查看未调度(bind)的Pod列表,循环遍历地为每个Pod分配节点,尝试为Pod分配节点。调度过程分为2个阶段:
4) 选择主机:选择打分最高的节点,进行binding操作,结果存储到etcd中。
5) 所选节点对于的kubelet根据调度结果执行Pod创建操作。
Predicates是用来形容主机匹配Pod所需要的资源,如果没有任何主机满足该Predicates,则该Pod会被挂起,直到有节点
预选(Predicates)与优选(Priorites)的策略罗列如下:
预选(Predicates)
优选(Priorites): Kubernetes用一组优先级函数处理每一个通过预选的节点,每一个优先级函数会返回一个0-10的分数,分数越高表示节点越优, 同时每一个函数也会对应一个表示权重的值 finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
1.LeastRequestedPriority: 节点的优先级就由节点空闲资源与节点总容量的比值,即由(总容量-节点上Pod的容量总和-新Pod的容量)/总容量)来决定。即CPU和内存具有相同权重,资源空闲比越高的节点得分越高。1 2 3 cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
2.BalancedResourceAllocation : CPU和内存使用率越接近的节点权重越高,该策略不能单独使用,必须和LeastRequestedPriority组合使用,尽量选择在部署Pod后各项资源更均衡的机器。
3.InterPodAffinityPriority : 通过迭代 weightedPodAffinityTerm 的元素计算和,并且如果对该节点满足相应的PodAffinityTerm,则将 “weight” 加到和中,具有最高和的节点是最优选的。
4.SelectorSpreadPriority:为了更好的容灾,对同属于一个service、replication controller或者replica的多个Pod副本,尽量调度到多个不同的节点上。
5.NodeAffinityPriority:Kubernetes调度中的亲和性机制。
6.NodePreferAvoidPodsPriority(权重1W):如果 节点的 Anotation 没有设置 key-value:scheduler. alpha.kubernetes.io/ preferAvoidPods = ".",则节点对该 policy 的得分就是10分,加上权重10000,那么该node对该policy的得分至少10W分
7.TaintTolerationPriority : 使用 Pod 中 tolerationList 与 节点 Taint 进行匹配,配对成功的项越多,则得分越低。
8.ImageLocalityPriority: 根据Node上是否存在一个pod的容器运行所需镜像大小对优先级打分,分值为0-10。
9.EqualPriority : EqualPriority 是一个优先级函数,它给予所有节点相等权重。
10.MostRequestedPriority : 在 ClusterAutoscalerProvider 中,替换 LeastRequestedPriority,给使用多资源的节点,更高的优先级1 (cpu(10 sum(requested) / capacity) + memory(10 sum(requested) / capacity)) / 2
最后会把表格中按照节点把优先级函数的权重列表相加,得到最终节点的分值。上面代码就是这个过程,中间过程可以并发计算(下文图中的workQueue)以加快速度。
…
node1
node2
…
Noden
PriorityFunc1
S(1,1)
S(1,2)
…
S(1,N)
PriorityFunc2
S(2,1)
S(1,2)
…
S(2,N)
…
…
…
…
…
PriorityFuncM
S(2,1)
S(1,2)
…
S(2,N)
Result
Score1
Score2
…
ScoreN
自定义调度
方式1.定制预选和优选策略组装Predicates和Priority函数,即可以选择不同的过滤含税和优先级函数,控制优先级含税的权限,调整过滤函数的顺序都会影响调度过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 "kind" : "Policy" ,"apiVersion" : "v1" ,"predicates" : [ {"name" : "PodFitsHostPorts" }, {"name" : "PodFitsResources" }, {"name" : "NoDiskConflict" }, {"name" : "NoVolumeZoneConflict" }, {"name" : "MatchNodeSelector" }, {"name" : "HostName" } ], "priorities" : [ {"name" : "LeastRequestedPriority" , "weight" : 1}, {"name" : "BalancedResourceAllocation" , "weight" : 1}, {"name" : "ServiceSpreadingPriority" , "weight" : 1}, {"name" : "EqualPriority" , "weight" : 1} ], "hardPodAffinitySymmetricWeight" : 10
方式2.自定义Priority和Predicate: 即Kubernetes还允许用户编写自己的Priority 和 Predicate函数,而并非上面的方式一是对已有的调度模块进行组合。
1 2 3 4 // FitPredicate is a function that indicates if a pod fits into an existing node. // The failure information is given by the error. type FitPredicate func(pod *v1.Pod, meta PredicateMetadata, nodeInfo *schedulercache.NodeInfo) (bool, []PredicateFailureReason, error)
在plugin/pkg/scheduler/algorithm/predicates/predicates.go文件中编写对象实现上面接口。
编写完过滤函数之后进行注册,让 kube-scheduler 启动的时候知道它的存在,注册部分可以在 plugin/pkg/scheduler/algorithmprovider/defaults/defaults.go完成,可以参考其他过滤函数(例如PodFitsHostPorts)的注册代码:kubernetes/plugin/pkg/scheduler/algorithmprovider/defaults/defaults.gofactory.RegisterFitPredicate("PodFitsPorts", predicates.PodFitsHostPorts)。
在 –policy-config-file把自定义过滤函数写进去,kube-scheduler运行时可以执行自定义调度逻辑了。
自定义优先级函数,实现过程和过滤函数类似。
方式3.编写自己的调度器: Kubernetes也允许用户编写自己的调度器组件,并在创建资源的时候引用它。多个调度器可以同时运行和工作,只要名字不冲突。
调度器最核心的逻辑并不复杂 : Scheduler首先监听apiserver ,获取没有被调度的Pod和全部节点列表,而后根据一定的算法和策略从节点中选择一个作为调度结果,最后向apiserver中写入binding 。
简单调度脚本:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #!/bin/bash SERVER='localhost:8001' while true ;do for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"' ) ; do NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"' )) NUMNODES=${#NODES[@]} CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]} curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "' $PODNAME '"}, "target": {"apiVersion": "v1", "kind" : "Node", "name": "' $CHOSEN '"}}' http://$SERVER /api/v1/namespaces/default/pods/$PODNAME /binding/ echo "Assigned $PODNAME to $CHOSEN " done sleep 1 done $ kubectl get nodes -o json | jq '.items[].metadata.name' | tr -d '"' weiyigeek-107 weiyigeek-108 weiyigeek-109 weiyigeek-223 weiyigeek-224 weiyigeek-225 weiyigeek-226
spec.schedulerName 是my-scheduler,并且spec.nodeName 为空),同样地,用kubectl从apiserver获取nodes的信息,然后随机选择一个node作为调度结果,并写入到apiserver中。我们可通过kubectl describe pod pod_name查看一个Pod采用的调度器;
Tips: 当然要想编写一个生产级别的调度器,要完善的东西还很多比如:
调度器总结:
描述: 没有什么事情是完美的,调度器也一样,用户可结合实际业务服务特性和需求,利用或定制Kubernetes调度策略,更好满足业务服务的需求。
0x03 服务质量(QoS) 描述: 什么是QoS?
resources - 配额限制 描述: Kubernetes 对 资源的限制实际上是通过 cgroup 来控制的,cgroup是容器的一组用来控制内核如何运行进程的相关属性集合,针对内存、CPU 和network、存储以及各种设备都有对应的 cgroup。
默认情况下,Pod运行没有CPU和内存的限额,意味着系统中的任何Pod将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU和内存。在生产环境中一般会针对某些特定应用的 pod 资源进行资源限制,常常资源限制是通过resources的 requests 和 limits来实现;
Tips: Requests 申请的范围是0到Node节点的最大配置(0<= request<=NodeAllocatable) ,而Limit申请范围是Request到无限(Request<=limit<=Infinity)
Kuberneters 资源限制可以针对以下对象:
Container 层面 : 对容器使用的CPU与内存的限制;
Pod 层面 : Pod 内所有容器进行限制;
Namespace 层 : 限制一个名称空间全部资源对象使用总和,包括Pod数量、RC数量、Service数量、ResourceQuota数量,Secret数量以及PV数量等
Tips :ResourceQuota / LimitRange - 在名称空间那节讲述过
QoS 分类
1.Guaranteed: Pod清单中的所有容器都必须统一设置Limits, 并且如果设置了Reuqest所用容器都需设置一样;
2.Burstable: Pod 清单中只要有一个容器的Reuquests与Limits的设置不同即为它
3.Best-Effort: 缺省如果Pod清单中的container对象中resources未设置requests与Limit即为它
Tips :如果一个容器只指明Limit而未设定Request则其值为Limit的值
基础示例
示例1.对于Pod资源的请求(requests)与限制(limits),可以简单理解为初始值和最大值1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 spec: containers: - image: nginx:latest imagePullPolicy: Always name: auth ports: - containerPort: 8080 protocol: TCP resources: limits: cpu: "4" memory: 2 Gi requests: cpu: 250 m memory: 250 Mi
示例2.对于名称空间的资源限制1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources namespace: spark-cluster spec: hard: pods: "20" requests.cpu: "20" requests.memory: 100 Gi limits.cpu: "40" limits.memory: 200 Gi apiVersion: v1 kind: ResourceQuota metadata: name: object-counts namespace: spark-cluster spec: hard: configmaps: "10" persistentvolumeclaims: "4" replicationcontrollers: "20" secrets: "10" services: "10" services.loadbalancers: "2" apiVersion: v1 kind: LimitRange metadata: name: mem-limit-range spec: limits: - default: memory: 50 Gi cpu: 5 defaultRequest: memory: 1 Gi cpu: 1 type: Container
资源压缩 描述: k8s将资源压缩分为两类,一类是可压缩资源,另外一类是不可压缩资源。
可压缩资源: 例如CPU资源当Pod容器超过设置的Limit值, Pod中进程使用CPU会被限制但不会被Kill;
不可压缩资源: 例如内存资源与磁盘资源当资源不足时其会先Kill掉优先级较低的Pod。
上面的方式在实际使用过程中是通过OOM分数值来实现的 OOM 分数值从 0-1000 区间范围之内, 其分值是根据OOM_ADJ参数计算得出;
Guranteed 级别的Pod其OOM_ADJ参数设置为-998, 如果系统用完全部内存且没有Burstable与BestEffort类型的容器可以被Kill时将会被Kill
Burstable 级别的Pod其OOM_ADJ参数设置为2-999, 如果系统用完全部内容且没有BestEffort可以被Kill时将被Kill;
BestEffort 级别的Pod其OOM_ADJ参数设置为1000, 当系统全部内存被用完时将会被Kill;
Tips :对于K8s的保留资源比如Kubelet、docker其OOM_ADJ参数设置为-999 (表示永远不会被Kill)
Tips : 对于OOM_ADJ参数来说如果其越大则计算出的OOM分数越高,则表明该Pod优先级就越低当出现资源竞争时就会被越早Kill;
QoS优先级: 从低到高的有 BestEffort < Burstable < Guranteed Pod
Tips : 如果Pod进程因使用超过预先设定的Limit而非Node资源紧张,系统一般倾向于其原所在的机器上重启该Container或者本机以及其它节点上创建一个Pod。
QoS 使用建议