[TOC]
0x00 前言简述 描述: 每个业务系统都有自己的日志, 日志的重要作用在于当系统出现问题时可以准确快速排查和解决问题, 所以日志收集整理显得尤为重要, 在系统机器比较少时(单台)通常可以直接在服务器中查看即可, 而在大规模的机分布式环境中, 还采用此种方式就会显得不切实际(耗费大量的时间), 那有木有什么方法可以将分布式应用的日志进行统一收集呢?
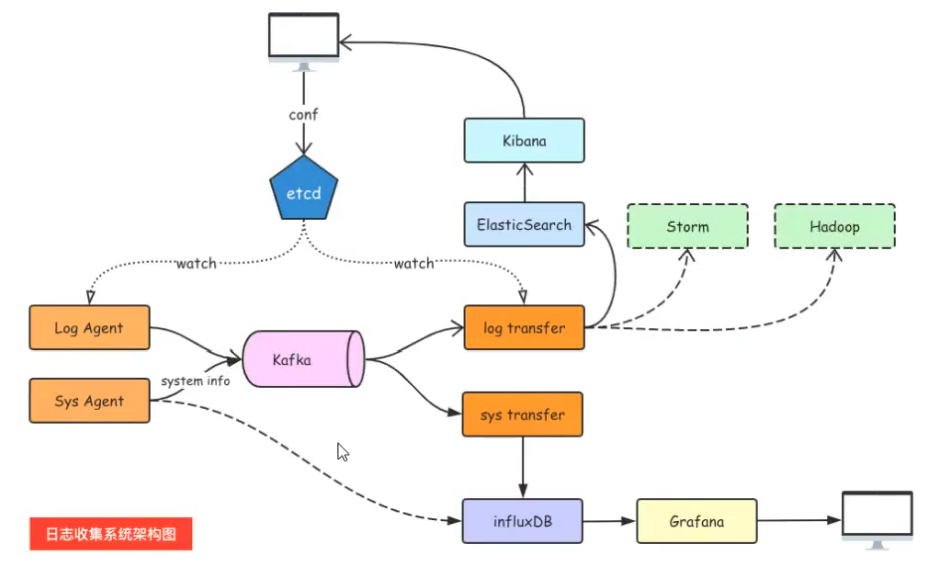
解决方案: 我们可将机器上的日志进行实时收集并统一存储到中心系统, 在针对存储的日志建立索引, 后续我们便可通过在Web页面搜索找到并显示对应的日志记录。但是同样也面临着一些问题,例如实时日志量大(成千上万多得上亿条), 日志准时收集延迟控制在分钟级别, 系统架构设计能够支持水平扩展方式,业界方案大致有如下:运维成本高(没增加一个日志收集项都需要手动修改配置), 监控缺失(无法准确获取Logstash状态), 社区版本无法做到定制化开发与维护。ElasticSearch 和 Kibana 基础之上加入 etc 和重写 Log Agent 并通过 kafka 实现自定义日志收集可视化展示解决方案。
weiyigeek.top-自设计日志收集系统架构图
你需要需要掌握和学习的技能:
Kafka和Zookeeper的安装使用
ES和Kibana的安装使用
Etcd的安装使用
服务端Agent开发流程
后端服务组件开发
1.kafka 快速介绍 Apache Kafka 是由Linkedin公司采用Scala语言开发编写的,最初设计用于解决其公司内部的海量日志传输等问题, 于2021年开源并进入Apache孵化器项目, 并于2012年10月正式毕业, 现在为Apache顶级项目。
Apache Kafka 是一个分布式数据流平台, 可单实例或者集群部署, 它提供了发布Publish和订阅SubscribeTopic功能, 使用者可发送数据(应用、流进程、DB等)到Kafka中,也可从Kafka中读取数据(以便进行后续处理)。
Apache Kafka 特点: 高吞吐、低延迟、高容错等特点。
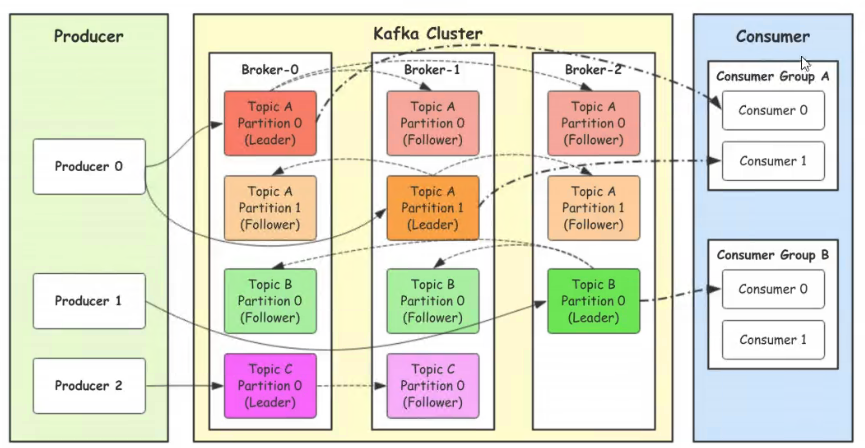
Apache Kafka 集群架构图浅析:
Producer: 生产者即消息的生产者是消息的入口。
Cluster: kafka集群模式由一台或者多台服务器组成。
Broker: kafka集群中每一个节点被称为Broker(是指部署的Kafka实例的服务器节点),集群内的broker都有一个不重复的编号,例如 broker-0、broker-1等。
Topic: 消息的主题(消息的分类),在每个Borker上都可以创建多个topic,在实际应用中通常是一个业务线建立一个Topic。
Partition: Topic 可以有多个分区其作用是负载提高kafka的吞吐量, 同一个Topic在不同的分区的数据是不重复的,其表现形式就是一个一个文件夹。
Replication: 每个分区都有多个副本(备份), 当主分区(Leader)出现故障时会选择一个备胎(Fllower)上位成为Leader, 注意Follower和leader绝对是在不同的机器上,同一台机器对同一个分区也只能存放一个副本(包括自己)。
Leader: 领导者(分区主节点)
Follower: 跟随者(分区从节点、备):默认副本的最大数量是10个。
Consumer: 消费者即消息的消费方,是消息的出口。
Group: 可将多个消费者组合成为一个消费组, 在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费, 同一个消费者组的消费者可以消费同一个Topic的不同分区的数据, 这样设计也是为提高吞吐量。
weiyigeek.top-Kafka Cluster
Tips: 消息队列的通信模型通常分为两种一种是点对点模式(Queue)、另外一种就是发布/订阅(Topic)模式:
Queue: 由一个生产者生成并由一个消费者消费, 当一条信息被消费后该队列则不存在该条信息,即不存在重复消费。
Topic:由消息生产者(发布)将信息发布到Topic中, 同时有多个消息消息者(订阅)消费该消息,其类似于关注了我的WeiyiGeek微信公众号,当我发送文章时关注我的人都可以收到推送的文章。
Tips:Topic 是同一类别的消息记录(Record)的集合。
工作流程浅析
P(生产者)从Kafka集群获取分区Leader信息。
P(生产者)将信息发送给Leader。
Leader将消息写入磁盘。
F(跟随者)从Leader处拉取消息数据。
F(跟随者)将消息写入本地磁盘后想Leader发送ACK信号。
Leader收到F(跟随者)的ACK之后向P(生成者)发送ACK信号。
weiyigeek.top-生产者向Kafka发送数据的流程
分区存储选取原则 在Kafka中如果某个Topic有多个Partition时,P(生产者)如何知道该数据将发往那个分区呢?
指定写入的Partition。
如没有指定Partition但设置了数据Key时,则会根据Key的值Hash出一个Partition。
如没有指定Partition又没有设置key,则会采用轮询的方式,即每次取一小段时间的数据写入某个分区,下一小段的时间写入下一个分区。
Tips : Partition(分区)结构在服务器上的表现形式是一个文件夹,每个Partition的文件夹下面会有多组segment文件, 每组segment文件中又包含.index文件、.log文件、和.timeindex文件, 其中.log文件就是实际存储message的地方, 而.index和.timeindex文件为索引文件用于检索消息。
应答机制浅析 在P(生产者)向Kafka写入消息的时候可以设置参数来确定Kafka是否接收到数据, 该参数可设置值为0、1、all。
0: 表示P往集群发送数据不需要等到集群的返回,不确保信息发送成功,其安全性最低但是效率最高。1: 表示P往集群发送数据只要Leader应答就可以发送下一条,只确保Leader发送成功。All: 表示P往集群发送数据需要所有的Follower都完成从Leader的同步才会发送下一条,确保Leader发送成功以及所有的副本都完成备份, 安全性最高但是效率最低。
非常注意: 如果往不存在的Topic写数据, Kafka就会自动创建Topic主题。
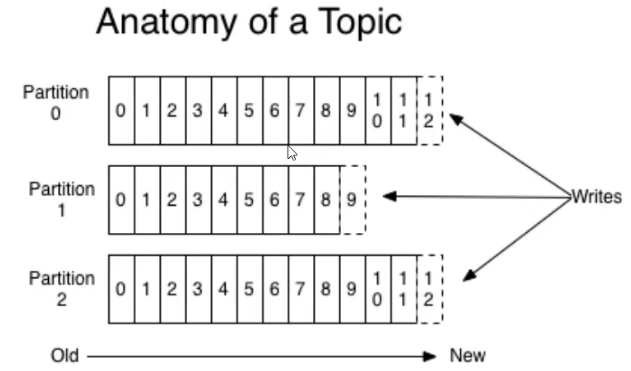
数据日志文件结构 描述: 对于每个主题(Topic) 由 Kafka 集群维护了一个分区数据日志文件结构,如下图所示。
每个Partition(分区)都是一个有序并且不可变的消息记录集合, 当新的数据写入时, 就被追加到Partition的末尾。
每个Partition(分区)中每条信息都会被分配一个顺序的标识,该标识被称为Offset(即偏移量)。
在Kafka可配置一个保留期限, 用于标识日志在Kafka集群内保留多长时间, 当超过设定的期限后数据将会被清空,以便为后续的数据腾出空间。
weiyigeek.top-分区数据日志文件结构
Tips: Kafka 只保证在同一个Partition内部消息是有序的, 在不同的Partition之间并不能保证消息是有序的。
Tips: 由于Kafka会将数据进行持久化存储(即写入到硬盘上), 所以保留的数据大小可以设置为一个比较大的值。
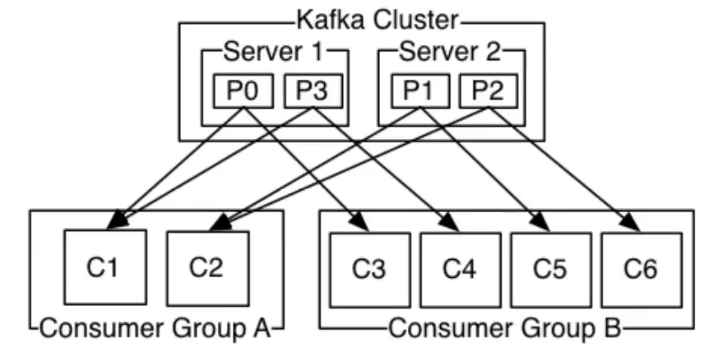
消费者消费数据说明 描述: 前面说过多个消费者实例可以组成一个消费者组, 并使用一个标签来标识该消费者组,一个消费者组中的不同消费者实例可以运行在不同的进程甚至不同的服务器上。
如所有的消费者实例都在同一个消费者组中, 那么消息记录会被很好的均衡发送到每个消费者实例中。
如所有的消费者实例都在不同的消费者组中, 那么每条消息记录会被广播发送到每个消费者实例中。
举个例子, 如图所示两个节点的Kafka集群上拥有四个Partition(P0-P3)的Topic, 并有两个消费者组都在消费该Topic中的数据,在组A中有两个消费者实例,在组B中有四个消费实例。最多只能被消费者组里其中一个消费者实例进行消费。简单得说如果有一个四个分区的Topic, 那么消费者组中最多只能够有四个消费者实例去消费。
weiyigeek.top-消费者消费示例
应用场景说明 上面介绍了Kafka的基本概念和原理, 那么它到底可以做什么呢?
目前主流的使用场景如下所示:
1) 消息队列: MQ(Message Queue),它是一种跨进程的通信机制, 用于上下游的信息传递使得程序解耦, 其常用于流量削峰、数据驱动的任务依赖等。除开Kafka产品外还有ActiveMQ、RabbitMQ。
2) 记录网络活动: 网站活动记录例如 PV、UV以及搜索记录等, 以及事件分类。
3) 记录指标: 传输监控数据, 用来聚合分布式应用程序的统计数据, 将数据集中后进行统一的分析和展示等。
4) 日志聚合: 将不同服务器上的日志收集起来并放入一个日志中心。
2.zookeeper 快速介绍 描述: Zookeeper 是一个分布式的、开源的分布式应用程序协调服务, 是基于Google的Chubby项目的开源实现, 它是集群的管理者, 监视着集群中各个节点的状态, 并根据节点提交的反馈进行下一步合理操作。
其最终目的是将简易的接口和性能高效、功能稳定的系统提供给用户。
0x01 环境安装 1.安装说明 Kafaka 环境所需依赖说明:
[TOC]
0x00 前言简述 描述: 每个业务系统都有自己的日志, 日志的重要作用在于当系统出现问题时可以准确快速排查和解决问题, 所以日志收集整理显得尤为重要, 在系统机器比较少时(单台)通常可以直接在服务器中查看即可, 而在大规模的机分布式环境中, 还采用此种方式就会显得不切实际(耗费大量的时间), 那有木有什么方法可以将分布式应用的日志进行统一收集呢?
解决方案: 我们可将机器上的日志进行实时收集并统一存储到中心系统, 在针对存储的日志建立索引, 后续我们便可通过在Web页面搜索找到并显示对应的日志记录。但是同样也面临着一些问题,例如实时日志量大(成千上万多得上亿条), 日志准时收集延迟控制在分钟级别, 系统架构设计能够支持水平扩展方式,业界方案大致有如下:运维成本高(没增加一个日志收集项都需要手动修改配置), 监控缺失(无法准确获取Logstash状态), 社区版本无法做到定制化开发与维护。ElasticSearch 和 Kibana 基础之上加入 etc 和重写 Log Agent 并通过 kafka 实现自定义日志收集可视化展示解决方案。
weiyigeek.top-自设计日志收集系统架构图
你需要需要掌握和学习的技能:
Kafka和Zookeeper的安装使用
ES和Kibana的安装使用
Etcd的安装使用
服务端Agent开发流程
后端服务组件开发
1.kafka 快速介绍 Apache Kafka 是由Linkedin公司采用Scala语言开发编写的,最初设计用于解决其公司内部的海量日志传输等问题, 于2021年开源并进入Apache孵化器项目, 并于2012年10月正式毕业, 现在为Apache顶级项目。
Apache Kafka 是一个分布式数据流平台, 可单实例或者集群部署, 它提供了发布Publish和订阅SubscribeTopic功能, 使用者可发送数据(应用、流进程、DB等)到Kafka中,也可从Kafka中读取数据(以便进行后续处理)。
Apache Kafka 特点: 高吞吐、低延迟、高容错等特点。
Apache Kafka 集群架构图浅析:
Producer: 生产者即消息的生产者是消息的入口。
Cluster: kafka集群模式由一台或者多台服务器组成。
Broker: kafka集群中每一个节点被称为Broker(是指部署的Kafka实例的服务器节点),集群内的broker都有一个不重复的编号,例如 broker-0、broker-1等。
Topic: 消息的主题(消息的分类),在每个Borker上都可以创建多个topic,在实际应用中通常是一个业务线建立一个Topic。
Partition: Topic 可以有多个分区其作用是负载提高kafka的吞吐量, 同一个Topic在不同的分区的数据是不重复的,其表现形式就是一个一个文件夹。
Replication: 每个分区都有多个副本(备份), 当主分区(Leader)出现故障时会选择一个备胎(Fllower)上位成为Leader, 注意Follower和leader绝对是在不同的机器上,同一台机器对同一个分区也只能存放一个副本(包括自己)。
Leader: 领导者(分区主节点)
Follower: 跟随者(分区从节点、备):默认副本的最大数量是10个。
Consumer: 消费者即消息的消费方,是消息的出口。
Group: 可将多个消费者组合成为一个消费组, 在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费, 同一个消费者组的消费者可以消费同一个Topic的不同分区的数据, 这样设计也是为提高吞吐量。
weiyigeek.top-Kafka Cluster
Tips: 消息队列的通信模型通常分为两种一种是点对点模式(Queue)、另外一种就是发布/订阅(Topic)模式:
Queue: 由一个生产者生成并由一个消费者消费, 当一条信息被消费后该队列则不存在该条信息,即不存在重复消费。
Topic:由消息生产者(发布)将信息发布到Topic中, 同时有多个消息消息者(订阅)消费该消息,其类似于关注了我的WeiyiGeek微信公众号,当我发送文章时关注我的人都可以收到推送的文章。
Tips:Topic 是同一类别的消息记录(Record)的集合。
工作流程浅析
P(生产者)从Kafka集群获取分区Leader信息。
P(生产者)将信息发送给Leader。
Leader将消息写入磁盘。
F(跟随者)从Leader处拉取消息数据。
F(跟随者)将消息写入本地磁盘后想Leader发送ACK信号。
Leader收到F(跟随者)的ACK之后向P(生成者)发送ACK信号。
weiyigeek.top-生产者向Kafka发送数据的流程
分区存储选取原则 在Kafka中如果某个Topic有多个Partition时,P(生产者)如何知道该数据将发往那个分区呢?
指定写入的Partition。
如没有指定Partition但设置了数据Key时,则会根据Key的值Hash出一个Partition。
如没有指定Partition又没有设置key,则会采用轮询的方式,即每次取一小段时间的数据写入某个分区,下一小段的时间写入下一个分区。
Tips : Partition(分区)结构在服务器上的表现形式是一个文件夹,每个Partition的文件夹下面会有多组segment文件, 每组segment文件中又包含.index文件、.log文件、和.timeindex文件, 其中.log文件就是实际存储message的地方, 而.index和.timeindex文件为索引文件用于检索消息。
应答机制浅析 在P(生产者)向Kafka写入消息的时候可以设置参数来确定Kafka是否接收到数据, 该参数可设置值为0、1、all。
0: 表示P往集群发送数据不需要等到集群的返回,不确保信息发送成功,其安全性最低但是效率最高。1: 表示P往集群发送数据只要Leader应答就可以发送下一条,只确保Leader发送成功。All: 表示P往集群发送数据需要所有的Follower都完成从Leader的同步才会发送下一条,确保Leader发送成功以及所有的副本都完成备份, 安全性最高但是效率最低。
非常注意: 如果往不存在的Topic写数据, Kafka就会自动创建Topic主题。
数据日志文件结构 描述: 对于每个主题(Topic) 由 Kafka 集群维护了一个分区数据日志文件结构,如下图所示。
每个Partition(分区)都是一个有序并且不可变的消息记录集合, 当新的数据写入时, 就被追加到Partition的末尾。
每个Partition(分区)中每条信息都会被分配一个顺序的标识,该标识被称为Offset(即偏移量)。
在Kafka可配置一个保留期限, 用于标识日志在Kafka集群内保留多长时间, 当超过设定的期限后数据将会被清空,以便为后续的数据腾出空间。
weiyigeek.top-分区数据日志文件结构
Tips: Kafka 只保证在同一个Partition内部消息是有序的, 在不同的Partition之间并不能保证消息是有序的。
Tips: 由于Kafka会将数据进行持久化存储(即写入到硬盘上), 所以保留的数据大小可以设置为一个比较大的值。
消费者消费数据说明 描述: 前面说过多个消费者实例可以组成一个消费者组, 并使用一个标签来标识该消费者组,一个消费者组中的不同消费者实例可以运行在不同的进程甚至不同的服务器上。
如所有的消费者实例都在同一个消费者组中, 那么消息记录会被很好的均衡发送到每个消费者实例中。
如所有的消费者实例都在不同的消费者组中, 那么每条消息记录会被广播发送到每个消费者实例中。
举个例子, 如图所示两个节点的Kafka集群上拥有四个Partition(P0-P3)的Topic, 并有两个消费者组都在消费该Topic中的数据,在组A中有两个消费者实例,在组B中有四个消费实例。最多只能被消费者组里其中一个消费者实例进行消费。简单得说如果有一个四个分区的Topic, 那么消费者组中最多只能够有四个消费者实例去消费。
weiyigeek.top-消费者消费示例
应用场景说明 上面介绍了Kafka的基本概念和原理, 那么它到底可以做什么呢?
目前主流的使用场景如下所示:
1) 消息队列: MQ(Message Queue),它是一种跨进程的通信机制, 用于上下游的信息传递使得程序解耦, 其常用于流量削峰、数据驱动的任务依赖等。除开Kafka产品外还有ActiveMQ、RabbitMQ。
2) 记录网络活动: 网站活动记录例如 PV、UV以及搜索记录等, 以及事件分类。
3) 记录指标: 传输监控数据, 用来聚合分布式应用程序的统计数据, 将数据集中后进行统一的分析和展示等。
4) 日志聚合: 将不同服务器上的日志收集起来并放入一个日志中心。
2.zookeeper 快速介绍 描述: Zookeeper 是一个分布式的、开源的分布式应用程序协调服务, 是基于Google的Chubby项目的开源实现, 它是集群的管理者, 监视着集群中各个节点的状态, 并根据节点提交的反馈进行下一步合理操作。
其最终目的是将简易的接口和性能高效、功能稳定的系统提供给用户。
0x01 环境安装 1.安装说明 Kafaka 环境所需依赖说明:1 2 3 Linux & Windows 操作系统: 此处 Ubuntu 20.04 LTS (ip: 10.10.10.225) JDK 环境 (Java 运行环境-此处不在累述) kafka 二进制包
kafka 官网地址: https://kafka.apache.org/ https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
Tips: 下载使用国外软件时需要注意对其签名或者摘要进行比对校验。1 2 3 4 5 6 7 8 9 10 11 12 13 14 % gpg --import KEYS % gpg --verify 下载文件.asc 下载文件 % gpg --print -md SHA256 下载文件 % md5sum 下载文件 % certUtil -hashfile 下载文件
2.安装流程 步骤 01.下载 kafka_2.13-3.0.0.tgz 并准备数据目录。1 2 3 cd /opt/software/ && mkdir -vp /data/{zookeeper,kafka-logs}wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz tar zxf kafka_2.13-3.0.0.tgz
步骤 02.kafka 简单配置,此处只是为了后续Go语言使用演示,所以为了简单只安装单节点。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 $ grep -v -E '^#' /opt/software/kafka_2.13-3.0.0/config/zookeeper.properties dataDir=/data/zookeeper clientPort=2181 maxClientCnxns=0 admin.enableServer=false $ grep -v -E '^#' /opt/software/kafka_2.13-3.0.0/config/server.properties broker.id=0 listeners=PLAINTEXT://:9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.dirs=/data/kafka-logs log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 num.partitions=1 num.recovery.threads.per.data.dir=1 zookeeper.connect=10.10.107.225:2181 zookeeper.connection.timeout.ms=18000
步骤 03.分别启动zookeeper和kafka服务(注意启动顺序,如果连接zookeeper服务超时18s则会报错)1 2 3 4 5 6 7 8 9 10 11 12 /opt/software/kafka_2.13-3.0.0 /opt/software/kafka_2.13-3.0.0
Tips : zookeeper 默认服务端口为2181,而kafka 默认的服务端口为9092。
0x02 LogAgent 实践开发 描述: LogAgent 工作流程大致有如下两个方面。
读日志: 读取系统日志, 此处我们利用tail包进行持续读取文件中的内容。
写日志: 将读取到的日志向 kafka 写入,此处我们利用sarama包连接到kafka进行生产数据和消费数据。
1.使用tail包进行日志文件读取 tail包项目地址: github.com/hpcloud/tail
拉取tail包及其依赖到本地 1 2 3 ➜ weiyigeek.top $ go get github.com/hpcloud/tail go: downloading github.com/hpcloud/tail v1.0.0 go: downloading gopkg.in/fsnotify.v1 v1.4.7
tail包使用示例代码: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package mainimport ( "fmt" "time" "github.com/hpcloud/tail" ) func main () fileName := "./access.log" config := tail.Config{ ReOpen: true , Follow: true , Location: &tail.SeekInfo{Offset: 0 , Whence: 2 }, MustExist: false , Poll: true , } tailObj, err := tail.TailFile(fileName, config) if err != nil { fmt.Printf("Tail file failed, Err:%v" , err) return } var ( msg *tail.Line status bool ) for { msg, status = <-tailObj.Lines if !status { fmt.Printf("Tail file Close Reopen filename: %s\n" , tailObj.Filename) time.Sleep(time.Second) continue } fmt.Println(string (msg.Text)) } }
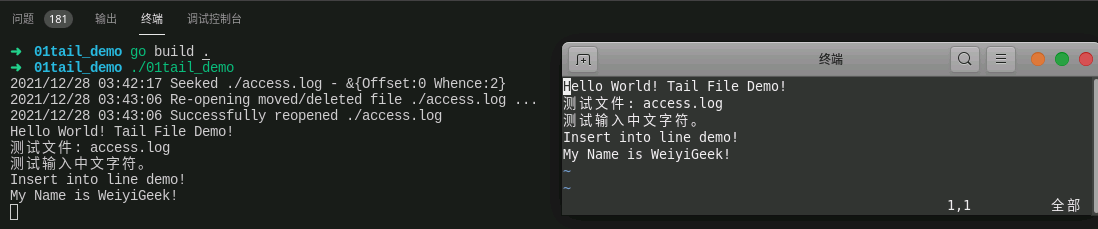
1 2 3 4 5 6 7 8 9 10 ➜ 01tail_demo go build . ➜ 01tail_demo ./01tail_demo 2021/12/28 03:42:17 Seeked ./access.log - &{Offset:0 Whence:2} 2021/12/28 03:43:06 Re-opening moved/deleted file ./access.log ... 2021/12/28 03:43:06 Successfully reopened ./access.log Hello World! Tail File Demo! 测试文件: access.log 测试输入中文字符。 Insert into line demo! My Name is WeiyiGeek!
weiyigeek.top-Tail包读取日志结果
2.使用sarama包连接到kafka进行数据生产和消费 描述: Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展等特点, 本节将介绍如何使用Go语言发送和接收kafka消息。
Go操作kafka常用的包主要有如下两个,此处我们使用sarama包进行演示。
Kafka 概念复习
Broker : Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic : 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition : Partition 是物理上的概念,每个Topic包含一个或多个Partition.
Producer : 负责发布消息到Kafka broker
Consumer : 消息消费者,向Kafka broker读取消息的客户端。
Consumer Group : 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
在项目中 sarama 第三方库下载及安装 1 2 3 4 5 6 7 8 ➜ weiyigeek.top $ go get github.com/Shopify/sarama go: downloading github.com/Shopify/sarama v1.30.1 ..... go: downloading github.com/pierrec/lz4 v1.0.1 go get: added github.com/Shopify/sarama v1.30.1 ..... go get: added gopkg.in/jcmturner/rpc.v1 v1.1.0
GO kafka sarama 生产者 消费者 简单实现
生成配置文件(生产者基础配置文件、指定生产者回复消息等级 0 1 all、指定生产者消息发送成功或者失败后的返回通道是什么、指定发送到哪一个分区(本文为 随机分区 正常有三种: 通过partiton、通过key 去 Hash出一个分区、轮询))
构建消息(msg := &sarama.Message{} 这里为指针 1.消息可更改 2. 下面的 发送消息SendMessage() 需要指针类型的参数)
连接kafka
发送消息
producer.go 代码示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 package mainimport ( "fmt" "log" "os" "os/signal" "sync" "time" "github.com/Shopify/sarama" ) var ( wg sync.WaitGroup enqueued, successes, errors int ) func main () config := sarama.NewConfig() config.Producer.Partitioner = sarama.NewRandomPartitioner config.Producer.RequiredAcks = sarama.WaitForAll config.Producer.Return.Successes = true config.Producer.Partitioner = sarama.NewHashPartitioner client, err := sarama.NewClient([]string {"10.10.107.225:9092" }, config) if err != nil { fmt.Println("producer closed, err:" , err) return } defer client.Close() producer, err := sarama.NewAsyncProducerFromClient(client) if err != nil { panic (err) } signals := make (chan os.Signal, 1 ) signal.Notify(signals, os.Interrupt) wg.Add(1 ) go func () defer wg.Done() for range producer.Successes() { successes++ } }() wg.Add(1 ) go func () defer wg.Done() for err := range producer.Errors() { log.Println(err) errors++ } }() ProducerLoop: for { msg := &sarama.ProducerMessage{} msg.Topic = "my_topic" msg.Key = sarama.StringEncoder("sarama" ) message := fmt.Sprintf("This is a sarama test log!By WeiyiGeek! UnixTime:%v" , time.Now().Unix()) msg.Value = sarama.StringEncoder(message) fmt.Println(message) select { case producer.Input() <- msg: enqueued++ time.Sleep(time.Second * 2 ) if enqueued >= 5 { producer.AsyncClose() break ProducerLoop } case <-signals: producer.AsyncClose() break ProducerLoop } } wg.Wait() log.Printf("Successfully, enqueued: %v ,produced: %d; errors: %d\n" , enqueued, successes, errors) }
消费者步骤:
生成消费者 对象 连接对应的 地址 config 可以为nil。
拿到所有对应主题下的所有分区。
遍历每一个分区 调用 消费者对象 传入 对应的 主题 哪一个具体的分区 从什么位置开始读取文件 Return:消息对象。
通过 消息对象.Message() 可以取到对应的消息。
consumber.go 代码示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package mainimport ( "fmt" "sync" "github.com/Shopify/sarama" ) func main () consumer, err := sarama.NewConsumer([]string {"10.10.107.225:9092" }, nil ) if err != nil { fmt.Printf("fail to start consumer, err:%v\n" , err) return } partitionList, err := consumer.Partitions("my_topic" ) if err != nil { fmt.Printf("fail to get list of partition:err%v\n" , err) return } fmt.Println("分区信息:" , partitionList) var wg sync.WaitGroup wg.Add(1 ) for partition := range partitionList { pc, err := consumer.ConsumePartition("my_topic" , int32 (partition), sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d,err:%v\n" , partition, err) return } defer pc.AsyncClose() go func (sarama.PartitionConsumer) defer wg.Done() for msg := range pc.Messages() { fmt.Printf("Topic: %v ,Partition:%d ,Offset:%d ,Key: %v ,Value: %v \n" , msg.Topic, msg.Partition, msg.Offset, string (msg.Key), string (msg.Value)) } }(pc) } wg.Wait() }
执行结果:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ➜ 02sarama_producer go build producer.go ➜ 02sarama_producer ./producer This is a sarama test log !By WeiyiGeek! UnixTime:1640635641 This is a sarama test log !By WeiyiGeek! UnixTime:1640635643 This is a sarama test log !By WeiyiGeek! UnixTime:1640635645 This is a sarama test log !By WeiyiGeek! UnixTime:1640635647 This is a sarama test log !By WeiyiGeek! UnixTime:1640635649 2021/12/28 04:07:31 Successfully, enqueued: 5 ,produced: 5; errors: 0 ➜ Day11 go build consumer.go ➜ Day11 ./consumer 分区信息: [0] Topic: my_topic ,Partition:0 ,Offset:379686590 ,Key: sarama ,Value: This is a sarama test log !By WeiyiGeek! UnixTime:1640635641 Topic: my_topic ,Partition:0 ,Offset:379686591 ,Key: sarama ,Value: This is a sarama test log !By WeiyiGeek! UnixTime:1640635643 Topic: my_topic ,Partition:0 ,Offset:379686592 ,Key: sarama ,Value: This is a sarama test log !By WeiyiGeek! UnixTime:1640635645 Topic: my_topic ,Partition:0 ,Offset:379686593 ,Key: sarama ,Value: This is a sarama test log !By WeiyiGeek! UnixTime:1640635647 Topic: my_topic ,Partition:0 ,Offset:379686594 ,Key: sarama ,Value: This is a sarama test log !By WeiyiGeek! UnixTime:1640635649
weiyigeek.top-sarama producer&consumer
使用consumer-group进行消费简单实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 package mainimport ( "context" "fmt" "github.com/Shopify/sarama" "os" "os/signal" "sync" ) type consumerGroupHandler struct { name string } func (consumerGroupHandler) Setup (_ sarama.ConsumerGroupSession) error return nil }func (consumerGroupHandler) Cleanup (_ sarama.ConsumerGroupSession) error return nil }func (h consumerGroupHandler) ConsumeClaim (sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error for msg := range claim.Messages() { fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s\n" ,h.name, msg.Topic, msg.Partition, msg.Offset, string (msg.Value)) sess.MarkMessage(msg, "" ) } return nil } func handleErrors (group *sarama.ConsumerGroup,wg *sync.WaitGroup ) wg.Done() for err := range (*group).Errors() { fmt.Println("ERROR" , err) } } func consume (group *sarama.ConsumerGroup,wg *sync.WaitGroup, name string ) fmt.Println(name + "start" ) wg.Done() ctx := context.Background() for { topics := []string {"my_topic" } handler := consumerGroupHandler{name: name} err := (*group).Consume(ctx, topics, handler) if err != nil { panic (err) } } } func main () var wg sync.WaitGroup config := sarama.NewConfig() config.Consumer.Return.Errors = false config.Version = sarama.V0_10_2_0 client,err := sarama.NewClient([]string {"localhost:9192" ,"localhost:9292" ,"localhost:9392" }, config) defer client.Close() if err != nil { panic (err) } group1, err := sarama.NewConsumerGroupFromClient("c1" , client) if err != nil { panic (err) } group2, err := sarama.NewConsumerGroupFromClient("c2" , client) if err != nil { panic (err) } group3, err := sarama.NewConsumerGroupFromClient("c3" , client) if err != nil { panic (err) } defer group1.Close() defer group2.Close() defer group3.Close() wg.Add(3 ) go consume(&group1,&wg,"c1" ) go consume(&group2,&wg,"c2" ) go consume(&group3,&wg,"c3" ) wg.Wait() signals := make (chan os.Signal, 1 ) signal.Notify(signals, os.Interrupt) select { case <-signals: } }
入坑与出坑
参考地址:
https://blog.csdn.net/zhang123456456/article/details/78881733
overrunsroot@10.41.40 .${i} ‘ifconfig | grep “overruns”‘;done;root@10.41.40 .${i} ‘netstat -i | column -t’;done;root@10.41.40 .${i} ‘netstat -i | column -t’;done;
RX errors:表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
RX dropped:表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
RX overruns:表示了 fifo 的 overruns,这是由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,而 CPU 无法即使的处理中断是造成 Ring Buffer 满的原因之一,上面那台有问题的机器就是因为 interruprs 分布的不均匀(都压在 core0),没有做 affinity 而造成的丢包。
RX frame:表示 misaligned 的 frames。
一台机器经常收到丢包的报警,先看看最底层的有没有问题:
ethtool eth2 | egrep ‘Speed|Duplex’
cat /proc/net/dev | column -t
问题:接受队列溢出产生错误,当抵达的包多于内核可以处理的包时,计算机会产生漫溢(overruns)。输入队列达到其上限(max_backlog)时,多抵达的那些包会全部被丢弃掉。@读者 achlice 补充:
补充一下, 对于overrun的包,修改了ring buffer之后,重启主机后会失效,1,需要将配置添加到网卡配置文件例如 rhel系列是在/etc/sysconfig/network-scripts/ifcfg-* , 例如网卡是enp3, 在 ifcfg-enp3 配置文件添加 ‘ETHTOOL_OPTS=’-G ${DEVICE} rx 4096; -A ${DEVICE} autoneg on’ 2,如果网卡配置ETHTOOL_OPTS 参数不生效,请确保initscripts 这个软件包是最新版本.
找了一些国外的文章,可以通过ethtool来修改网卡的buffer size ,首先要网卡支持,我的服务器是是INTEL 的1000M网卡,我们看看ethtool说明
-g –show-ringQueries the specified ethernet device for rx/tx ring parameter information.
-G –set-ringChanges the rx/tx ring parameters of the specified ethernet device.
查看当前网卡的buffer size情况ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
由于我的是rx包会有droped的情况我们用ethtool -G eth0 rx 2048
同样对于eth1也是如此ethtool -G eth1 rx 2048
再看看修改过后的ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 2048
RX Mini: 0
RX Jumbo: 0
TX: 2048
几个小时后,已经没有丢包增加的情况了
正常情况下,RX-ERR/TX-ERR、RX-DRP/TX-DRP和RX-OVR/TX-OVR的值都应该为0,如果这几个选项的值不为0,并且很大,那么网络质量肯定有问题,网络传输性能也一定会下降。
生产案例
范例10-29:统计各个状态的网络连接个数。
[root@Backend-184 ~]# netstat -n |awk ‘/^tcp/ {++oldboy[$NF]} END {for(a in oldboy) print a, oldboy[a]}’ #<==这个题目利用了awk数组的功能,awk的使用请参考本书第四章。
TIME_WAIT 6163
FIN_WAIT1 42
FIN_WAIT2 1056
ESTABLISHED 4542
SYN_RECV 53
LAST_ACK 30
root@weiyigeek-21:~# lspci -vvv | grep -A 100 “Ether”SERR- <PERR- INTx-
00:0a.0 Unclassified device [00ff]: Red Hat, Inc. Virtio memory balloonSERR- <PERR- INTx-
00:1f.0 PCI bridge: Red Hat, Inc. QEMU PCI-PCI bridge (prog-if 00 [Normal decode])SERR- <PERR- INTx-Reset- FastB2B-
root@weiyigeek-21:~# ethtool -l ens9
https://bbs.huaweicloud.com/blogs/140990