[TOC]
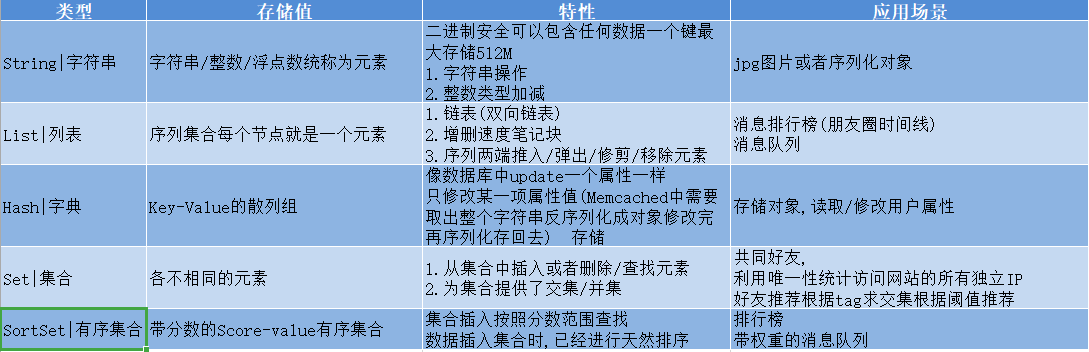
0x01 Redis 数据类型 描述: Redis常见五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(Sorted set 有序集合)。
其还支持其它类型例如Bit arrays (or simply bitmaps)(处理位数组一样处理字符串值)、HyperLogLogs(概率数据)、Streams类型(抽象日志)。
参考地址: https://redis.io/topics/data-types-intro
Key 管理 描述:键命令用于管理 redis 的键
[TOC]
0x01 Redis 数据类型 描述: Redis常见五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(Sorted set 有序集合)。
其还支持其它类型例如Bit arrays (or simply bitmaps)(处理位数组一样处理字符串值)、HyperLogLogs(概率数据)、Streams类型(抽象日志)。
参考地址: https://redis.io/topics/data-types-intro
Key 管理 描述:键命令用于管理 redis 的键1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 > keys p* 1) "python" 2) "php" > set test redis > del test (integer ) 1 > type php string > exists test (integer ) 1 > dump test "\x00\x05redis\t\x00\x15\xa2\xf8=\xb6\xa9\xde\x90" > MOVE test 1 (integer ) 1 > expire python 600 (integer ) 1 > PTTL python (integer ) 592072 > TTL python (integer ) 583 > EXPIREAT runoobkey 1293840000 (integer ) 1 > pexpire test 6000 (integer ) 1 > PEXPIREAT runoobkey 1555555555005 (integer ) 1 > persist test > randomkey > rename key python > renamenx key newksy (integer ) 1
String (字符串) 描述: String 是 redis 最基本的类型(是二进制安全的) 且字符串类型的值最大能存储 512MB 。
基于语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 (1)SET key value (2)GET key (3)GETRANGE key start end (4)GETSET key value (5)GETBIT key offset (6)MGET key1 \[key2..] (7)SETBIT key offset value (8)SETEX key seconds value (9)SETNX key value (10)SETRANGE key offset value (11)STRLEN key (12)MSET key value [key value ...] (13)MSETNX key value [key value ...] (14)PSETEX key milliseconds value (15)INCR key (16)INCRBY key increment (17)INCRBYFLOAT key increment (18)DECR key (19)DECRBY key decrement (20)APPEND key value
使用示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 > SET name "runoob" > GET name > type name > set test stringdemo > getrange test 0 4 > strlen test > getset stringdemo stringdemo > setex demo 15 "value15seconds" > psetex key4 10000 "value10seconds" > setnx demo1 demo1 > setrange demo1 2 weiyigeek > APPEND key1 valuakey1 > get key1 > mset key1 value1 key2 value2 > mget key1 key2 1) "value1" 2) "value2" > msetnx key2 value2 key3 value3 > set key5 1 > incr key5 (integer ) 2 > incr key5 (integer ) 3 > incrby key5 3 (integer ) 6 > incrbyfloat key5 4.5 "10.5" > set key6 10 > decr key6 (integer ) 9 > decrby key6 5 (integer ) 4 > strlen key1 (integer ) 15 redis> EXISTS bit (integer ) 0 redis> GETBIT bit 10086 (integer ) 0 redis> SETBIT bit 10086 1 (integer ) 0 redis> GETBIT bit 10086 (integer ) 1
Hash (哈希) 描述:hash 是一个键值(key=>value)对集合,是一个string类型的 field 和 value 的映射表,hash 特别适合用于存储对象,每个 hash 可以存储 2^32 -1键值对(40多亿)。
基础语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 (1) HDEL key field1 \[field2] (2) HEXISTS key field (3) HGET key field (4) HGETALL key (5) HINCRBY key field increment (6) HINCRBYFLOAT key field increment (7) HKEYS key (8) HLEN key (9) HMGET key field1 \[field2] (10)HMSET key field1 value1 [field2 value2 ] (11)HSET key field value (12)HSETNX key field value (14)HVALS key (15)HSCAN key cursor [MATCH pattern] [COUNT count]
使用示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 > HSET hash1 field1 "hello" > HMSET hash1 field2 "world" field3 "redis" > hkeys hash1 1) "field1" 2) "field2" 3) "field3" > hlen hash1 > hexists hash1 field1 > hget hash1 field1 > hmget hash1 field1 field2 1) "hello" 2) "world" > HSETNX hash1 field4 "study" > hvals hash1 1) "hello" 2) "world" 3) "redis" 4) "study" > hgetall hash1 1) "field1" 2) "hello" 3) "field2" 4) "world" 5) "field3" 6) "redis" > hdel hash1 field4 (integer ) 1 > hdel hash1 field5 (integer ) 0 > hset hash2 field1 1 (integer ) 1 > hincrby hash2 field1 3 (integer ) 4 > hincrbyfloat hash2 field1 3 "7" > hincrbyfloat hash2 field1 3.5 "10.5"
List (列表) 描述: Redis 列表是简单的字符串列表,按照插入顺序排序(类似于栈);你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
基础语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 (1) BLPOP key1 [key2 ] timeout (2) BRPOP key1 [key2 ] timeout (3) BRPOPLPUSH source destination timeout (4) LINDEX key index (5) LINSERT key BEFORE|AFTER pivot value (6) LLEN key (7) LPOP key (8) LPUSH key value1 \[value2] (9) LPUSHX key value (10) LRANGE key start stop (11) LREM key count value (12) LSET key index value (13) LTRIM key start stop (14) RPOP key (15) RPOPLPUSH source destination (16) RPUSH key value1 \[value2] (17) RPUSHX key value
基础格式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 [1]> lpush list1 1 2 3 (integer ) 3 [1]> lpushx list1 0 (integer ) 4 [1]> llen list1 (integer ) 4 [1]> rpush list2 0 1 2 3 4 (integer ) 5 [1]> rpushx list2 5 (integer ) 6 [1]> lset list2 5 7 OK [1]> lrange list1 0 4 1) "0" 2) "3" 3) "2" 4) "1" [1]> lrange list2 0 5 1) "0" 2) "1" 3) "2" 4) "3" 5) "4" 6) "7" [1]> lpop list1 "0" [1]> rpop list1 "1" [1]> blpop list1 10 1) "list1" 2) "3" [1]> brpop list1 10 1) "list1" 2) "2" [1]> lindex list2 0 "0" [1]> lindex list2 5 "5" redis> BRPOPLPUSH list1 list2 500 "hello moto" (3.38s) redis> LLEN list2 (integer ) 1 redis> LRANGE list2 0 0 1) "hello moto" redis> BRPOPLPUSH msg list2 1 (nil) (1.34s) [1]> rpoplpush list2 list3 "4" redis> RPUSH mylist "Hello" (integer ) 1 redis> RPUSH mylist "World" (integer ) 2 redis> LINSERT mylist BEFORE "World" "There" (integer ) 3 redis> LRANGE mylist 0 -1 1) "Hello" 2) "There" 3) "World" redis > RPUSH mylist "hello" (integer ) 1 redis > RPUSH mylist "hello" (integer ) 2 redis > RPUSH mylist "foo" (integer ) 3 redis > RPUSH mylist "bar" (integer ) 4 redis > LTRIM mylist 1 -1 OK redis > LRANGE mylist 0 -1 1) "hello" 2) "foo" 3) "bar" redis> RPUSH mylist "hello" (integer ) 1 redis> RPUSH mylist "hello" (integer ) 2 redis> RPUSH mylist "foo" (integer ) 3 redis> RPUSH mylist "hello" (integer ) 4 redis> LREM mylist -2 "hello" (integer ) 2 redis> LRANGE mylist 0 -1 1) "hello" 2) "foo"
Set (集合) 描述: Set是string类型的无序集合,集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1),集合成员是唯一的所以集合中不能出现重复的数据; 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
基础语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 (1) SADD key member1 [member2] (2) SCARD key (3) SDIFF key1 [key2] (4) SDIFFSTORE destination key1 [key2] (5) SINTER key1 [key2] (6) SINTERSTORE destination key1 [key2] (7) SISMEMBER key member (8) SMEMBERS key (9) SMOVE source destination member (10) SPOP key (11) SRANDMEMBER key [count] (12) SREM key member1 [member2] (13) SUNION key1 [key2] (14) SUNIONSTORE destination key1 [key2] (15) SSCAN key cursor [MATCH pattern] [COUNT count]
基础示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 [2]> sadd set1 1 2 3 4 5 6 [2]> sadd set2 1 3 5 7 9 [2]> scard set1 (integer ) 6 [2]> sismember set1 1 (integer ) 1 [2]> sismember set1 0 (integer ) 0 [2]> sdiff set1 set2 1) "2" 2) "4" 3) "6" [2]> sdiffstore set3 set1 set2 [2]> sinter set1 set2 1) "1" 2) "3" 3) "5" [2]> sinterstore set4 set1 set2 [2]> smove set1 set4 2 [2]> smembers set4 1) "1" 2) "2" 3) "3" 4) "5" [2]> spop set1 [2]> srandmember set1 10 1) "1" 2) "3" 3) "5" 4) "6" [2]> srandmember set1 1 1) "6" [2]> srem set1 1 3 [2]> sunion set1 set2 1) "1" 2) "3" 3) "5" 4) "6" 5) "7" 6) "9" [2]> sunionstore set5 set1 set2 [2]> sscan set5 1 match * 1) "0" 2) 1) "1" 2) "3" 3) "5" 4) "6" 5) "7" 6) "9"
Zset (sorted set 有序集合) 描述: Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员,集合是通过哈希表实现的;
不同的是每个元素都会关联一个double类型的分数
redis正是通过分数来为集合中的成员进行从小到大的排序
zset的成员是唯一的,但分数(score)却可以重复
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
其实在redis sorted sets里面当items内容大于64的时候同时使用了hash和skiplist两种设计实现。这也会为了排序和查找性能做的优化,所以如上可知:
添加和删除都需要修改skiplist,所以复杂度为O(log(n))。
但是如果仅仅是查找元素的话可以直接使用hash,其复杂度为O(1)
其他的range操作复杂度一般为O(log(n))
当然如果是小于64的时候,因为是采用了ziplist的设计,其时间复杂度为O(n)
基础语法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 (1) ZADD key score1 member1 [score2 member2] (2) ZCARD key (3) ZCOUNT key min max (4) ZINCRBY key increment member (5) ZINTERSTORE destination numkeys key [key ...] (6) ZLEXCOUNT key min max (7) ZRANGE key start stop \[WITHSCORES] (8) ZRANGEBYLEX key min max [LIMIT offset count] (9) ZRANGEBYSCORE key min max \[WITHSCORES] \[LIMIT] (10)ZRANK key member (11)ZREM key member [member ...] (12)ZREMRANGEBYLEX key min max (13)ZREMRANGEBYRANK key start stop (14)ZREMRANGEBYSCORE key min max (15)ZREVRANGE key start stop \[WITHSCORES] (16)ZREVRANGEBYSCORE key max min \[WITHSCORES] (17)ZREVRANK key member (18)ZSCORE key member (19)ZUNIONSTORE destination numkeys key [key ...] (20)ZSCAN key cursor [MATCH pattern] [COUNT count]
基础示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 [3]> zadd zset 1 redis 1 python 1 php [3]> zadd zset 2 java 2 javascript 2 node.js (integer ) 3 [3]> zcard zset [3]> zcount zset 0 2 [3]> zincrby zset 1 redis [3]> zrank zset redis [3]> zincrby zset 7 redis [3]> zlexcount zset 0 6 [3]> zrange zset 0 -1 withscores 1) "php" 2) "1" 3) "python" 4) "1" 5) "java" 6) "2" 7) "javascript" 8) "2" 9) "node.js" 10) "2" 11) "redis" 12) "9" [3]> zrangebyscore zset 0 2 1) "php" 2) "python" 3) "java" 4) "javascript" 5) "node.js" [3]> zrangebyscore zset 9 9 1) "redis" [3]> zadd zset 0 php 1 php2 2 php3 3 php4 [3]> zrevrange zset 0 5 withscores 1) "php4" 2) "3" 3) "php3" 4) "2" 5) "node.js" 6) "2" 7) "php2" 8) "1" 9) "php" 10) "0" [3]> zrevrangebyscore zset 0 -1 1) "php" [3]> zrevrank zset php (integer ) 4 [4]> zscore zset node.js "2" [3]> zrem zset redis [3]> zrem zset redis [3]> zremrangebyrank zset 0 1 [3]> zremrangebyrank zset 0 1 "" "" "" "" redis > ZADD myzset 0 a 0 b 0 c 0 d 0 e (integer ) 5 redis > ZADD myzset 0 f 0 g (integer ) 2 redis > ZLEXCOUNT myzset - + (integer ) 7 redis > ZLEXCOUNT myzset [b [f (integer ) 5 "" "" "" "" redis > ZADD myzset 0 a 0 b 0 c 0 d 0 e 0 f 0 g (integer ) 7 redis > ZRANGEBYLEX myzset - [c 1) "a" 2) "b" 3) "c" redis > ZRANGEBYLEX myzset - (c 1) "a" 2) "b" redis > ZRANGEBYLEX myzset [aaa (g 1) "b" 2) "c" 3) "d" 4) "e" 5) "f" "" " # [重点]:给定的一个或多个有序集的交集,其中给定 key 的数量必须以 numkeys 参数指定,并将该交集(结果集)储存到 destination 。 " "" redis > ZADD mid_test 70 "Li Lei" (integer ) 1 redis > ZADD mid_test 70 "Han Meimei" (integer ) 1 redis > ZADD mid_test 99.5 "Tom" (integer ) 1 redis > ZADD fin_test 88 "Li Lei" (integer ) 1 redis > ZADD fin_test 75 "Han Meimei" (integer ) 1 redis > ZADD fin_test 99.5 "Tom" (integer ) 1 redis > ZINTERSTORE sum_point 2 mid_test fin_test redis > ZRANGE sum_point 0 -1 WITHSCORES 1) "Han Meimei" 2) "145" 3) "Li Lei" 4) "158" 5) "Tom" 6) "199"
HyperLogLog (基数统计) 描述: 在2.8.9版本添加了HyperLogLog结构是是用来做基数统计的算法;
Q:什么是基数?
HyperLogLog 的优点:
输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数
根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
基础语法: 1 2 3 1) PFADD key element [element ...] 2) PFCOUNT key [key ...] 3) PFMERGE destkey sourcekey [sourcekey ...]
基础示例: 1 2 3 4 5 6 7 8 9 10 11 12 [5]> pfadd hyper "redis" "mongodb" "mysql" "python" (integer ) 1 [5]> pfadd log "java" "javascript" "web" (integer ) 1 [5]> pfcount hyper log (integer ) 7 [5]> pfcount hyper (integer ) 4 [5]> pfmerge descLog hyper log OK [5]> pfcount descLog (integer ) 7
0x02 Redis 进阶学习 1.选择数据库号 描述: Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Tips: Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。
这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是一个从0..15(默认16个)开始的递增数字命名,
Redis默认支持16个数据库(可以通过配置文件支持更多无上限), 可以通过配置databases来修改这一数字。
客户端与Redis建立连接后会自动选择0号数据库,当然我们可以指定库连接。1 2 redis-cli -n 1 127.0.0.1:6379[1]> ping
可以随时使用SELECT命令更换数据库,1 2 3 4 redis> SELECT 1 OK redis [1] > GET foo (nil)
补充说明:
首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。
另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。
最重要的一点是多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。
综上所述 redis 数据库 更像是一种命名空间,而不适宜存储不同应用程序的数据。
比如:可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。
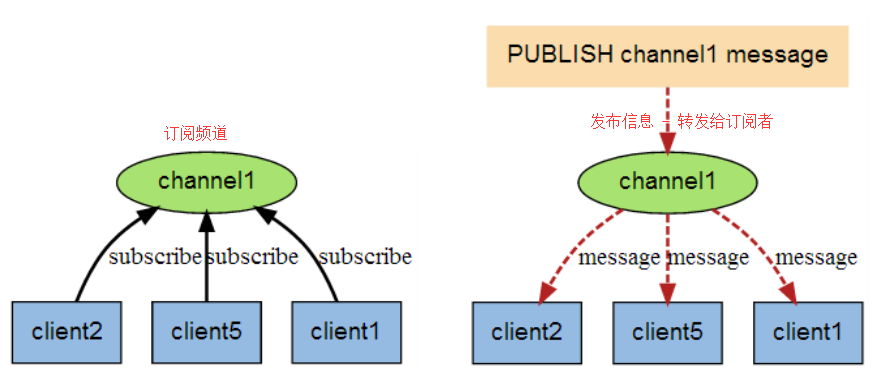
2.Redis 发布订阅 Q: 什么是pub/sub?
Tips: 同样 Redis 的 pub/sub 是一种消息通信模式,主要的目的是解除消息发布者和消息订阅者之间的耦合,Redis 作为一个 pub/sub的 server, 在订阅者和发布者之间起到了消息路由的功能。
描述: 类似于MQTT协议一样,Redis也支持发布订阅(pub/sub)消息通信模式(发送者(pub)发送消息,订阅者(sub)接收消息),Redis客户端可以订阅任意数量的频道
weiyigeek.top-redis发布订阅
基础语法:
(1) PSUBSCRIBE pattern [pattern …] #订阅一个或多个符合给定模式的频道。(可以采用通配符)
(5) SUBSCRIBE channel [channel …] #订阅给定的一个或多个频道的信息。
(2) PUBSUB subcommand [argument [argument …]] #查看订阅与发布系统状态。
(3) PUBLISH channel message #将信息发送到指定的频道。
(6) UNSUBSCRIBE [channel [channel …]] #指退订给定的频道。
(4) PUNSUBSCRIBE [pattern [pattern …]] #退订所有给定模式的频道。
基础实例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [6]> subscribe redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat" 3) (integer ) 1 1) "message" 2) "redisChat" 3) "Redis pub/sub" 1) "message" 2) "redisChat" 3) "Hello World!MQTT" 192.168.1.100:6379> publish redisChat "Redis pub/sub" (integer ) 1 192.168.1.100:6379> publish redisChat "Hello World!MQTT" (integer ) 1 192.168.1.100:6379> publish redisChat "Hello World!Redis Channel" (integer ) 1 192.168.1.100:6379> pubsub CHANNELS redis* 1) "redisChat" [6]> psubscribe redis* Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redis*" 3) (integer ) 1 "Hello World!Redis Channel"
3.Redis 事物处理 描述: 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
批量操作在发送 EXEC 命令前被放入队列缓存。
收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
以下命令是实现事务的基石:1 2 3 4 5 (1)MULTI (2)EXEC (3)DISCARD (4)WATCH key [key ...] (5)UNWATCH 取消 WATCH 命令对所有 key 的监视。
Redis事务特征:
1.在事务执行中所有命令都将会被串行化的顺序执行(效率低但是由于操作的是内存所以忽略不计),并且在该事务执行期间Redis不会再为其它客户端的请求提供任何服务(保证了事务中的所有命令被原子执行);
2.在事务执行失败后其后面的命令任然会继续执行,此点与关系型数据库事务相比有些许不同
3.在事务执行中命令MULTI可以看做关系型数据库中BEGIN TRANSACTION,而EXEC与DISCARD命令来提交/回滚事务内的所有操作等同于COMMIT 与 ROLLBACK 语句;
4.在事务执行过程中如果Client与Server出现通讯故障并导致网络断开,其后所执行的语句将不会被服务器指向,但是如果网络中断事件发生在EXEC命令之后则任然执行;
5.在事务执行中使用Append-Only模式此时Redis会调用系统函数write将该事务内的所有写操作在本次调用中全部写入硬盘;但是如果在写入过程中出现系统崩溃导致数据写不完整,此时在Redis重启后会进行一致性检测如果发现问题将会提示;
PSTips: 当Redis进行错误提示我们可以利用Redis-check-aof工具帮助我们定位到数据不一致的错误,并将已经写入部分数据进行回滚,之后重启数据库即可;
示例1.事务处理提交 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 192.168.1.100:6379[7]> multi 192.168.1.100:6379[7]> set book-name "redis 入门到放弃" QUEUED 192.168.1.100:6379[7]> get book-name QUEUED 192.168.1.100:6379[7]> sadd tag "redis" "数据库" "基础入门" QUEUED 192.168.1.100:6379[7]> smembers tag QUEUED 192.168.1.100:6379[7]> exec 1) OK 2) "redis \xe5\x85\xa5\xe9\x97\xa8\xe5\x88\xb0\xe6\x94\xbe\xe5\xbc\x83" 3) (integer ) 3 4) 1) "\xe6\x95\xb0\xe6\x8d\xae\xe5\xba\x93" 2) "redis" 3) "\xe5\x9f\xba\xe7\xa1\x80\xe5\x85\xa5\xe9\x97\xa8\xef\xbc\xe2\x80"
示例2.事务处理回滚 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 > SELECT 1 OK [1]> set name WeiyiGeek OK [1]> get name "WeiyiGeek" [1]> MULTI OK [1]> set name Redis QUEUED [1]> get name QUEUED [1]> DISCARD OK [1]> get name "WeiyiGeek"
示例3.失败命令自动剔除执行案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 > set num 10 OK > get num "10" > MULTI OK > INCRBY num 5 QUEUED > INCRBY num x QUEUED > INCRBY num 5 QUEUED > exec 1) (integer ) 15 2) (error) ERR value is not an integer or out of range 3) (integer ) 20 > get num "20"
0x03 使用场景 描述:复习Redis的五种数据类型:String、List、Hash、Set、Sorted-set, 前面我们简单的了解了一下Redis各个使用操作,这一部分我们主要来说说Redis的应用场景;
List 类型 (1) 取最新N个数据操作 1 2 3 4 LPUSH latest.comments ID LTRIM latest.comments 0 5000
(2) 构建队列系统
Set 类型 (1) Uniq操作获取某段时间所有数据排重置
Zset 类型 (1) 排行榜应用TOP N操作 sorted set类型,将您需要排序的key名称以及其具体数据设置成相应的value,每次只需要执行ZADD命令即可;
(2) 需要精准设定过期时间应用 sorted set类型的score值设置成为过期时间的时间戳,就可以通过过期时间排序以及定时清除过期数据;
Incr、Decr (1) 事物统计 INCR与DECR命令来构建计算统计系统
means Publish, Subscribe (1) 在线聊天室
示例演示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 > set Weiyi Geek > get Weiyi > hmset hash love1 "Python" love2 "C++" > lpush list redis (integer ) 1 > lpush list python (integer ) 2 > lrange list 0 10 1) "python" 2) "redis" > sadd run redis (integer ) 1 > sadd run redis1 (integer ) 1 > sadd run redis2 (integer ) 1 > smembers run 1) "redis2" 2) "redis1" 3) "redis" > zadd test 0 redis (integer ) 1 > zadd test 0 python (integer ) 1 > zrangebyscore runoob 0 1000 (empty list or set ) > zrangebyscore test 0 1000 1) "python" 2) "redis"
weiyigeek.top-数据类型应用场景