[TOC]
0x00 前言简述 Q: 什么是ORM框架?它有何作用?
答:
Q: 什么是SQLAlchemy?它有何作用?
答:
Q: 什么是Flask-SQLAlchemy扩展?它有何作用?
答: 他是基于SQLAlchemy框架针对于Flask进行优化与封装的数据库框架, 可以帮助开发者快速进行应用开发与不同数据库之间的数据存储, 还能结合Flask-Migrate实现数据库的迁移与回滚;
官网地址:http://flask-sqlchemy.pocoo.org
设置数据库字段模型便于创建表以及追加字段和CURD
0x01 框架初识 1.安装与配置 Step 1.Flask-SQLAlchemy 扩展安装:
[TOC]
0x00 前言简述 Q: 什么是ORM框架?它有何作用?
答:
Q: 什么是SQLAlchemy?它有何作用?
答:
Q: 什么是Flask-SQLAlchemy扩展?它有何作用?
答: 他是基于SQLAlchemy框架针对于Flask进行优化与封装的数据库框架, 可以帮助开发者快速进行应用开发与不同数据库之间的数据存储, 还能结合Flask-Migrate实现数据库的迁移与回滚;
官网地址:http://flask-sqlchemy.pocoo.org
设置数据库字段模型便于创建表以及追加字段和CURD
0x01 框架初识 1.安装与配置 Step 1.Flask-SQLAlchemy 扩展安装:1 pip install flask-sqlalchemy
Step 2.Flask-SQLAlchemy 扩展配置:app = Flask(__name__) 进行 SQLAlchemy 对象构建, 在开发过程中常常使用懒加载方法 init_app 方法进行扩展的加载使用;
Step 3.配置数据库连接字符串说明与实例1 2 3 4 5 6 7 8 app.config['SQLALCHEMY_DATABASE_URI' ] = "sqlite:///sqlite.db" app.config['SQLALCHEMY_DATABASE_URI' ] = "mysql+pymysql://root:weiyigeek@localhost:3306/Flask_Hello"
Step 4.项目环境决定数据库链接自定义配置
(1) 开发环境(Development):开发人员把代码拉取到本地环境中进行开发,等开发完成后推送到开发环境中(让项目的开发人员查看)
(2) 测试环境(Testing):测试人员使用
(3) 演示环境(Staging): 产品经理查看以及正式上线前的彩排
(4) 生产环境(Product): 针对于广大的互联网使用者;
如下示例根据需要切换项目场景1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from redis import Redisdef get_db_uri (dbinfo) : engine = dbinfo.get("ENGINE" ) or "sqlite" driver = dbinfo.get("DRIVER" ) or "sqlite" user = dbinfo.get("USER" ) or "" password = dbinfo.get("PASSWORD" ) or "" host = dbinfo.get("HOST" ) or "" port = dbinfo.get("PORT" ) or "" name = dbinfo.get("NAME" ) or "" if engine == "sqlite" : return "{}:///{}" .format(engine,name) else : return "{}+{}://{}:{}@{}:{}/{}" .format(engine,driver,user,password,host,port,name) class DevelopConfig : DEBUG = True SQLALCHEMY_TRACK_MODIFICATIONS = False DBINFO = { "ENGINE" : "sqlite" , "NAME" : "sqlite.db" } DBURI = get_db_uri(DBINFO) class ProductConfig : DEBUG = False TESTING = False SQLALCHEMY_TRACK_MODIFICATIONS = False DBINFO = { "ENGINE" : "mysql" , "DRIVER" : "pymysql" , "USER" : "root" , "PASSWORD" : "Weiyi123456." , "HOST" : "10.20.72.24" , "PORT" : "3306" , "NAME" : "FlaskTest" } DBURI = get_db_uri(DBINFO) def init_param (app) : devconfig = DevelopConfig.DBURI proconfig = ProductConfig.DBURI app.config['SQLALCHEMY_DATABASE_URI' ] = proconfig app.config['SQLALCHEMY_TRACK_MODIFICATIONS' ] = False
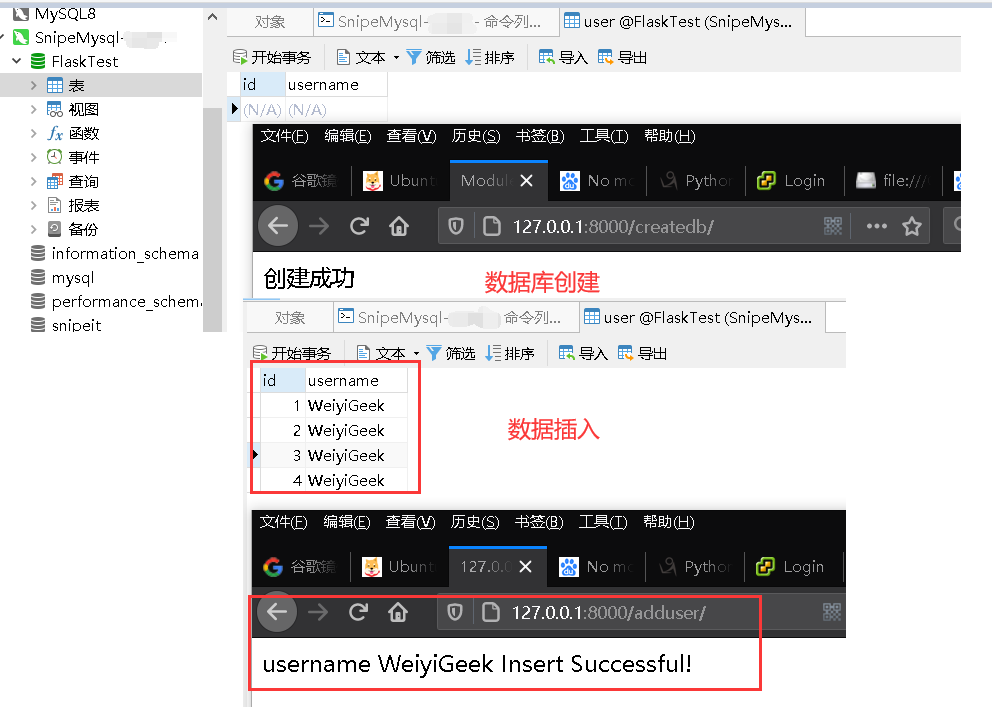
weiyigeek.top-Mysql正式环境
2.扩展基础使用
使用Models进行模型定义
使用Column创建字段
使用SQLAlchemy对象进行创建数据库(create_all)以及删除数据库(drop_all);
0x02 基础知识 0.模型信息 描述: 主要针对于模型信息的指定设置例如以下关键字方法;1 2 3 4 5 6 __tablename__ = "example" __abstract__ = True
1.字段类型 描述:其主要用于定制模型继承Model和创建字段时指定类型;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 Numeric decimal.Decimal Integer SmallInteger BigInteger Float Real String Text Unicode Unicode Text Boolean Date Time Datetime LargerBinary
2.字段选项 常用的SQLAlchemy中的列选项:
选项名
说明
primary_key
如果为True,代表表的主键
autoincrement
如果为Trye,表示该字段自增
unique
如果为True,代表这列不允许出现重复的值
index
如果为True,为这列创建索引,提高查询效率
nullable
如果为True,允许有空值,如果为False,不允许有空值
default
为这列定义默认值
Q: 模型中外键ForeignKey的构建?1 2 3 4 5 6 7 8 9 10 11 db.Column(db.类型, db.ForeignKey(模型类名称.字段)) class Animal(db.Model): Id = db.Column(db.Interger, primary_key=True, autoincrement=True) Type = db.Column(db.String(32), default="动物类型" ) class Dog(db.Model): DId = db.Column(db.Interger, db.ForeignKey(Animal.Id)) DName = db.Column(db.String("32" ), default="动物名称" )
Q: 模型中外键的反向引用级联查询如何构建?
答: 官方文档使用关系 relationship 进行 外键的反向引用即级联查询,注意点他不是映射在数据库之中的他实际上是Django的隐型属性; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 外键反向引用名称 = db.relationship('有外键的表(模型类名称)' , backref='自身模型类名称' , lazy=True ) class Dog (Animal) : __tablename__ = 'animal_dog' d_eat = db.Column(db.String(32 ), default="bone" ) d_age = db.Column(db.Integer, default=0 ) d_fdog = db.relationship('FDog' , backref='Dog' , lazy=True ) class FDog (db.Model) : __tablename__ = 'fdog' id = db.Column(db.Integer, primary_key=True , autoincrement=True ) comment = db.Column(db.String(255 ), default="备注描述说明" ) fid = db.Column(db.Integer, db.ForeignKey(Dog.id))
Q: 什么时候对字段使用Index索引?
答: 学过数据库的人都应该知道索引是为了加快在关系型数据库中数据的查找, 所以一般常常加在被搜索的字段之上;
3.常用方法
4.查询方法 常用查询数据结果集:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 模型类名.query.xxx all() first() get(index) filter(类名.属性[类名] 操作运算符 值) filter(类名.属性[类名].魔术方法("xx" )) filter_by(字段 数学运算符 值) offset() limit () order_by(text("-id" )) order_by(text("id desc" ))
常用运算符:
比较运算符1 2 3 4 5 6 7 8 __str__ __eq__,== __lt__,< __gt__,> __le__,<= __ge__,>=
逻辑运算:1 2 3 4 5 6 7 8 filter(and_(条件), 条件...) filter(or_(条件), 条件...) filter(not_(条件), 条件...)
1 2 3 4 5 6 7 contains # 包含 startswith # 开始匹配 endswith # 结束匹配 in_ # 包含在一个列表中 like # 找相似的字符串的数据
简单实例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Cat.query.filter(Cat.id.__eq__(2)) Cat.query.filter(Cat.id == 2) Cat.query.filter(Cat.name.contains("喵" )) Cat.query.offset(1).limit (2) Cat.query.order_by('-id' ).offset(1).limit (3) Cat.query.order_by(text("id desc" )).offset(1).limit (3) Cat.query.offset( (page_num -1) * count ).limit (count).all Cat.query.paginate(page=None, per_page=None, error_out=True, max_per_page=None).items Cat.query.filter(Cat.cid.__eq__(1)).filter(Cat.name.endswith('4' )) Cat.query.filter(and_(Cat.cid.__eq__(1), Cat.name.endswith('4' ))) Cat.query.filter(not_(or_(Cat.cid.__eq__(1), Cat.name.endswith('4' ))))
基础示例:
模板Templates:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 <!DOCTYPE html> <html lang ="en" > <head > <meta charset ="UTF-8" > <meta name ="viewport" content ="width=device-width, initial-scale=1.0" > <title > 分页测试</title > </head > <body > <h1 > 分页测试1</h1 > <table class ="table table-hover" style ="border: 1px solid black;" > <thead > <tr > <th > Index</th > <th > Name</th > <th > 食物</th > <th > 年龄</th > </tr > </thead > <tbody > {% for user in dogs %} <tr > <td > {{ user.id }}</td > <td > {{ user.name }}</td > <td > {{ user.d_eat }}</td > <td > {{ user.d_age}}</td > </tr > {% endfor %} </tbody > </table > <hr > <h1 > 分页测试2</h1 > <table class ="table table-hover" border ="1px solid red;" > <thead > <tr > <th > Index</th > <th > Name</th > <th > 食物</th > <th > 年龄</th > </tr > </thead > <tbody > {% for user in pagination.items %} <tr > <td > {{ user.id }}</td > <td > {{ user.name }}</td > <td > {{ user.d_eat }}</td > <td > {{ user.d_age}}</td > </tr > {% endfor %} </tbody > </table > {% macro render_pagination(pagination,current_page,current_count,end) %} <div class =pagination > {% if page != 1 %} <a href ="{{ url_for('demo3.get_dogs_paginate') }}?page=1&count={{ per_page }}" > 首页</a > {% endif %} {%- for page in pagination.iter_pages() %} {% if page %} {% if page != pagination.page %} <a href ="{{ url_for('demo3.get_dogs_paginate') }}?page={{ page }}&count={{ per_page }}" > {{ page }}</a > {% else %} <strong > {{ page }}</strong > {% endif %} {% else %} <span class =ellipsis > …</span > {% endif %} {%- endfor %} {% if current_page != end %} <a href ="{{ url_for('demo3.get_dogs_paginate') }}?page={{ end }}&count={{ per_page }}" > 尾页</a > {% endif %} <br > <br > <span > 数据共<b > {{ total }} </b > 条 , 跳转到<input type ="number" id ="page_num" min ="1" max ="{{ end }}" value ="{{ current_page }}" /> 页, 每页显示<input type ="number" min ="5" max ="100" id ="per_page_num" value ="{{ current_count }}" /> 条</span > <input type ="button" value ="跳转" id ="goto" onclick ="goto()" > </div > {% endmacro %} {{ render_pagination(pagination,page,per_page,end) }} <script > function goto () var page = document .getElementById("page_num" ).value; var per_page = document .getElementById("per_page_num" ).value; if ( page * per_page > {{ total }} ){ alert("显示超出返回值范围!" ); } else { window .location.href="{{ url_for('demo3.get_dogs_paginate') }}?page=" +page+"&count=" +per_page; } } </script > </body > </html >
蓝图视图代码1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from flask import Blueprint,render_template,requestfrom App.models import db,Dog,Catd3 = Blueprint("demo3" , __name__, url_prefix="/add" ) @d3.route('/getdogs/') def get_dogs () : page = request.args.get("page" ,1 ,type=int) per_page = request.args.get("count" ,10 ,type=int) Dogs = Dog.query.offset((page - 1 ) * per_page).limit(per_page).all() type(Dogs) return render_template('User/show.html' ,dogs=Dogs) @d3.route('/getpaginate/') def get_dogs_paginate () : page = request.args.get("page" ,1 ,type=int) per_page = request.args.get("count" ,10 ,type=int) Dogs = Dog.query.paginate(page,per_page) print("数据总条数:%d" % Dogs.total) return render_template('User/show.html' ,dogs=Dogs.items, total=Dogs.total, pagination=Dogs, per_page=per_page, page=page, end=round(Dogs.total/per_page))
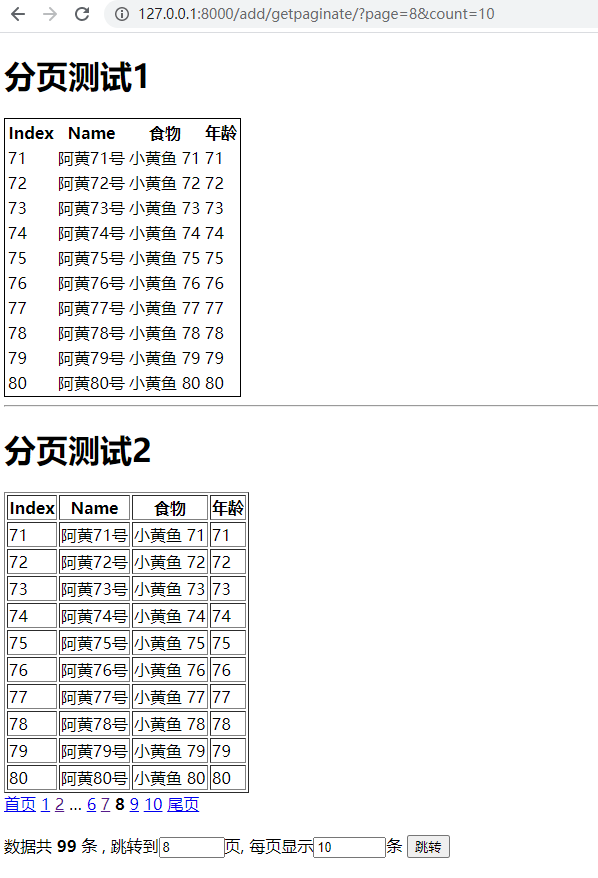
weiyigeek.top-paginate
补充说明:
(1) 在Flask-SQLAchemy里筛选中的all()只能放在最后且后面不能加filter()等过滤条件;
(2) 在筛选中offset与limit是不区分顺序的, 并且order_by必须放在前两者之前;
创建库表,库手动创建,而表采用SQLAlchemy对象 create_all ,删除则通过drop_all,其缺陷不能差量更新
数据库操作 - 存储 创建对象 即SQLAlchemy.session.add() 然后在执行commit()
补充SQLalchemy Query帮助文档
https://flask-sqlalchemy.palletsprojects.com/en/2.x/queries/ http://www.pythondoc.com/flask-sqlalchemy/quickstart.html
1 2 3 4 5 Users.query.filter('条件' ).order('字段名' ).all() db.session.query(TableName.colum1, func.count(TableName.colum1)).filter('条件' ).group_by('字段名' ).all()
0x03 进阶使用实例 1.模型继承 数据库的 Models 中字段定义:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 class Animal (db.Model) : __abstract__ = True id = db.Column(db.Integer, primary_key=True , autoincrement=True , index=True ) name = db.Column(db.String(16 )) class Dog (Animal) : __tablename__ = 'animal_dog' d_eat = db.Column(db.String(32 ), default="bone" ) d_age = db.Column(db.Integer, default=0 ) def commit (self) : save(self) class Cat (Animal) : __tablename__ = 'animal_cat' c_eat = db.Column(db.String(32 ), default="fish" ) c_age = db.Column(db.Integer, default=0 ) def commit (self) : save(self) from flask import Blueprint,render_templatefrom App.models import db,Dog,Cat@d3.route("/dog/") def add_dog () : dogs = [] for x in range(10 ): dog = Dog() dog.name = "阿黄%d号" % x dog.d_eat = "小黄鱼 %d" % x dog.d_age = x dogs.append(dog) db.session.add_all(dogs) db.session.commit() return "Dog add success" @d3.route("/cat/") def add_cat () : cat = Cat() cat.name = "阿喵" cat.c_age = 12 cat.commit() return "Cat add success"
执行结果:1 2 3 4 5 6 7 8 9 10 11 12 13 PS E:\githubProject\Study-Promgram\Python3\Flask\Day3> python .\Setup.py db migrate INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.autogenerate.compare] Detected added table 'animal_cat' INFO [alembic.autogenerate.compare] Detected added index 'ix_animal_cat_id' on '[' id']' INFO [alembic.autogenerate.compare] Detected added table 'animal_dog' INFO [alembic.autogenerate.compare] Detected added index 'ix_animal_dog_id' on '[' id']' Generating E:\githubProject\Study-Promgram\Python3\Flask\Day3\migrations\versions\6e1 cbc828430_.py ... done PS E:\githubProject\Study-Promgram\Python3\Flask\Day3> python .\Setup.py db upgrade INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non-transactional DDL. INFO [alembic.runtime.migration] Running upgrade a0e47b8e1d88 -> 6e1cbc828430, empty message PS E:\githubProject\Study-Promgram\Python3\Flask\Day3>
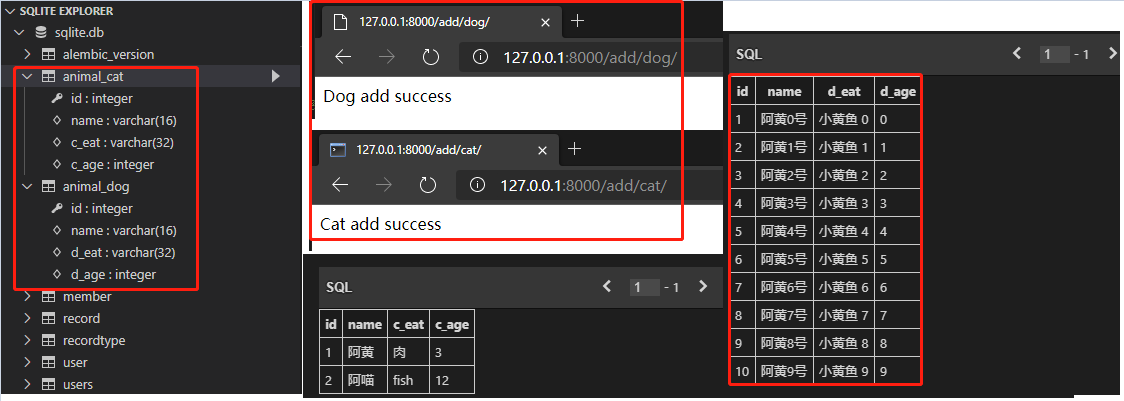
weiyigeek.top-模型继承
2.级联数据与外键 描述:级联数据之外键间的关系
1:1 ForeignKey + Unique
1:M ForeignKey
M:N 额外扩充的关系表即多个ForeignKey
基础实例:
1.外键与外键反向引用的模型构建
2.使用关系 relationship 进行外键的反向引用即级联查询;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Animal(db.Model): __abstract__ = True id = db.Column(db.Integer, primary_key=True, autoincrement=True, index=True) name = db.Column(db.String(16)) class Dog(Animal): __tablename__ = 'animal_dog' d_eat = db.Column(db.String(32), default="bone" ) d_age = db.Column(db.Integer, default=0) d_fdog = db.relationship('FDog' , backref='Dog' , lazy=True) class FDog(db.Model): __tablename__ = 'fdog' id = db.Column(db.Integer, primary_key=True, autoincrement=True) comment = db.Column(db.String(255), default="备注描述说明" ) fid = db.Column(db.Integer, db.ForeignKey(Dog.id))
创建外键后进行数据库字段迁移升级:1 2 3 4 5 PS E:\githubProject\Study-Promgram\Python3\Flask\Day3> python .\Setup.py db migrate INFO [alembic.autogenerate.compare] Detected added table 'fdog' Generating E:\githubProject\Study-Promgram\Python3\Flask\Day3\migrations\versions\27b381148478_.py ... done PS E:\githubProject\Study-Promgram\Python3\Flask\Day3> python .\Setup.py db upgrade INFO [alembic.runtime.migration] Running upgrade 6e1cbc828430 -> 27b381148478, empty message
视图View蓝图代码:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from App.models import db,Dog,Cat,FDogfrom random import randrangefrom sqlalchemy import textd3 = Blueprint("demo3" , __name__, url_prefix="/add" ) ... @d3.route('/add_fdog/') def add_fdog () : fdog = FDog() fdog.fid = Dog.query.order_by(text("id desc" )).first().id fdog.comment = "我是 %d 条记录" % randrange(1000 ) db.session.add(fdog) db.session.commit() print(fdog.fid,fdog.comment) return 'Insert Success fid = {}, fdog.comment = {}' .format(fdog.fid,fdog.comment) @d3.route('/get_fdog/') def get_fdog () : id = request.args.get('id' ,type=int) fdog = FDog.query.get_or_404(id) dog = Dog.query.get(fdog.fid) return "外键关联的数据 : id = %d , 名称 = %s , 年龄 = %d ,食物 = %s, 备注描述 = %s" % (dog.id,dog.name,dog.d_age,dog.d_eat, fdog.comment) @d3.route('/get_relationship/') def get_relationship () : id = request.args.get('id' ,type=int) dog = Dog.query.get(id) rdog = dog.d_fdog print("\n\n" ,type(rdog)) print("外键反向引用或者的数据:\n" ,rdog,end="\n\n" ) return 'get_relationship'
执行结果:
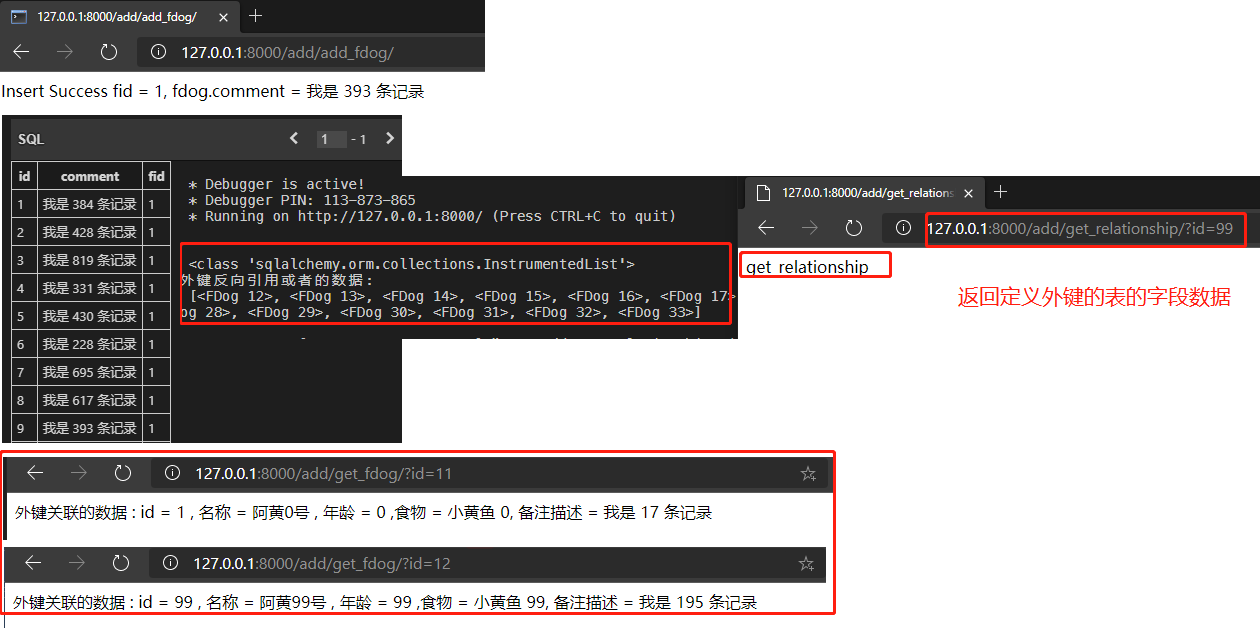
外键基础使用:http://127.0.0.1:8000/add/get_fdog/?id=12
外键反向引用:http://127.0.0.1:8000/add/get_relationship/?id=99 1 2 3 <class 'sqlalchemy.orm.collections.InstrumentedList' > 外键反向引用或者的数据(列表对象): [<FDog 12>, <FDog 13>, <FDog 14>, <FDog 15>, <FDog 16>, <FDog 17>, <FDog 18>, <FDog 19>, <FDog 20>, <FDog 21>, <FDog 22>, <FDog 23>, <FDog 24>, <FDog 25>, <FDog 26>, <FDog 27>, <FDog 28>, <FDog 29>, <FDog 30>, <FDog 31>, <FDog 32>, <FDog 33>]
weiyigeek.top-ForignKey
入坑出坑 问题1.在Flask中的SQLAlchemy设置数据模型的外键(ForeignKey)时候无法启动项目;
错误信息:1 2 3 File "D:\Program Files (x86)\Python37-32\lib\site-packages\sqlalchemy\orm\mapper.py" , line 1413 , in _configure_pks % (self, self.persist_selectable.description) sqlalchemy.exc.ArgumentError: Mapper mapped class FDog ->fdog could not assemble any primary key columns for mapped table 'fdog'
问题原因: 由于创建的模型之中没有创建主键字段
解决方法: 在该模型中创建一个字段主键即可
问题2.Textual SQL expression ‘-id’ should be explicitly declared as text(’-id’)
问题原因:使用的SQLalchemy版本不兼容导致
解决方法:1 2 3 4 原代码: projects = Project.query.filter_by(status=False).order_by("-id" ).all() from sqlalchemy import text 解决方法: projects = Project.query.filter_by(status=False).order_by(text("-id" )).all()