[TOC]
0x00 前言简述
基础简述
在前面的章节中我们介绍过Pod是K8s进行创建、调度管理的最小单位,在同一个Pod内的Container不会垮主机,每个Pod都有独立的Pod IP (IP per Pod)并且该Pod包含的所有容器共享一个网络协议栈(或者网络名称空间), 例如容器之间通过localhost+port可以进行相互访问。即集群中的所有Pod都处于一个扁平互通的网络空间。

[TOC]
在前面的章节中我们介绍过Pod是K8s进行创建、调度管理的最小单位,在同一个Pod内的Container不会垮主机,每个Pod都有独立的Pod IP (IP per Pod)并且该Pod包含的所有容器共享一个网络协议栈(或者网络名称空间), 例如容器之间通过localhost+port可以进行相互访问。即集群中的所有Pod都处于一个扁平互通的网络空间。
[TOC]
在前面的章节中我们介绍过Pod是K8s进行创建、调度管理的最小单位,在同一个Pod内的Container不会垮主机,每个Pod都有独立的Pod IP (IP per Pod)并且该Pod包含的所有容器共享一个网络协议栈(或者网络名称空间), 例如容器之间通过localhost+port可以进行相互访问。即集群中的所有Pod都处于一个扁平互通的网络空间。1
2
3
4
5
6~$ kubectl get pod --all-namespaces -o json | jq '.items[] | select(.metadata.name=="kubernetes-dashboard-7448ffc97b-sd9bt")' | jq .status.podIP
"172.16.182.203"
~$ kubectl get endpoints --all-namespaces
kubernetes-dashboard dashboard-metrics-scraper 172.16.24.198:8000 59d
kubernetes-dashboard kubernetes-dashboard 172.16.182.203:8443 59d
Tips: 在Docker中我们使用Docker Bridge模型实现服务的跨节点访问,而在我们的Kubernets中则采用一个更优的IP-Per-Pod模型;
Linux网络名词解释
网络的命名空间:Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;Docker利用这一特性,实现不同容器间的网络隔离。
Veth设备对:Veth设备对的引入是为了实现在不同网络命名空间的通信。
Iptables/Netfilter:Netfilter负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核模式中;Iptables模式是在用户模式下运行的进程,负责协助维护内核中Netfilter的各种规则表;通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
网桥:网桥是一个二层网络设备,通过网桥可以将Linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
路由:Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。
描述: 容器网络发展的两大阵营即Docker的CNM容器网络模型(原生)和CoreOS、Google、K8s主导的CNI容器网络接口模型(网络管理插件),他们主要的作用是进行网络管理。即从架构角度来看他们是网络规范和网络体系,而从研发的角度他们就是一堆接口。
CNM 介绍
它是 Docker Libnetwork Container Network Model 的简称(Libnetwork 是 CNM 标准的实现) Libnetwork 提供 Docker 守护程序和网络驱动程序之间的接口。网络控制器负责将驱动程序与网络配对。每个驱动程序负责管理其拥有的网络,包括提供给该网络的服务。每个网络有一个驱动程序,多个驱动程序可以与连接到多个网络的容器同时使用。
优点: Docker 原生所以和Docker容器生命周期结合紧密。
缺点: Docker 原生所以被Docker绑架了没他不行。
实现插件: Docker Swarm Overlay 、Macvaln、 Calico、 Contiv、 Weave
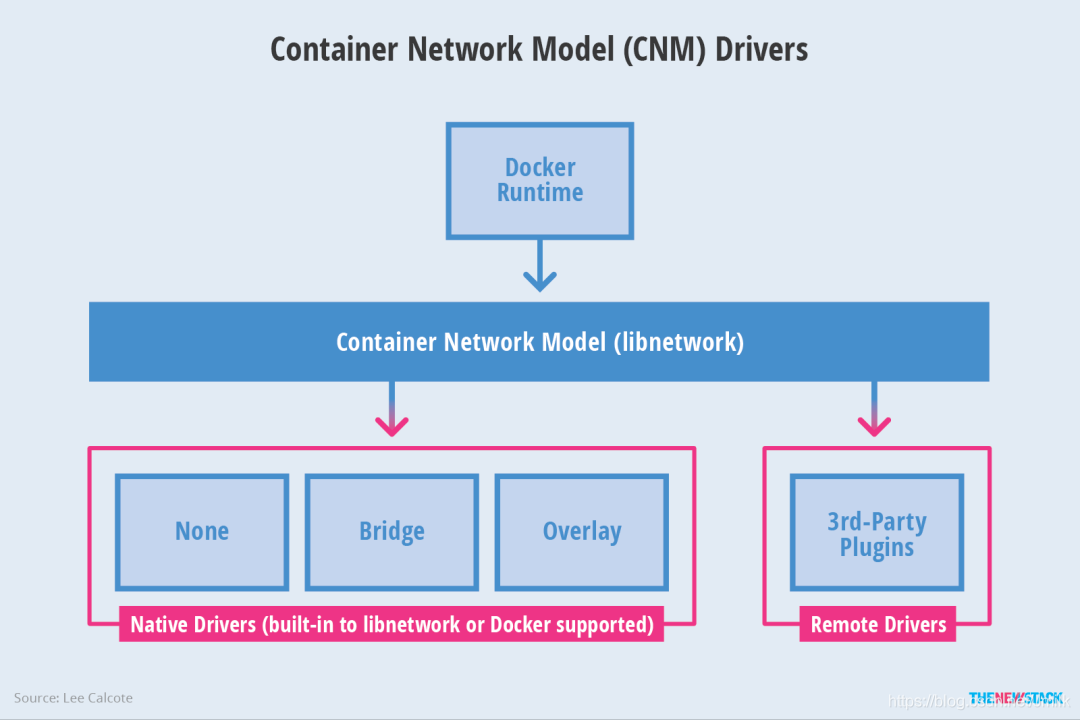
weiyigeek.top-CNM
CNI 介绍
它是 Container Network Interface 的简述(CNCF 的正式项目); 用于编写插件以配置 Linux 容器中的网络接口。CNI 仅关注容器的网络连接并在删除容器的同时删除分配的资源
优点: 提供了广泛的支持,并且规范易于实现,支持第三方插件。 简单的说兼容其它容器技术(Podman)以及上层编排系统(Kubernetes & Mesos等)并且社区活跃度高(CoreOS主推);
缺点: 非Docker原生与Docker容器没那么紧密。
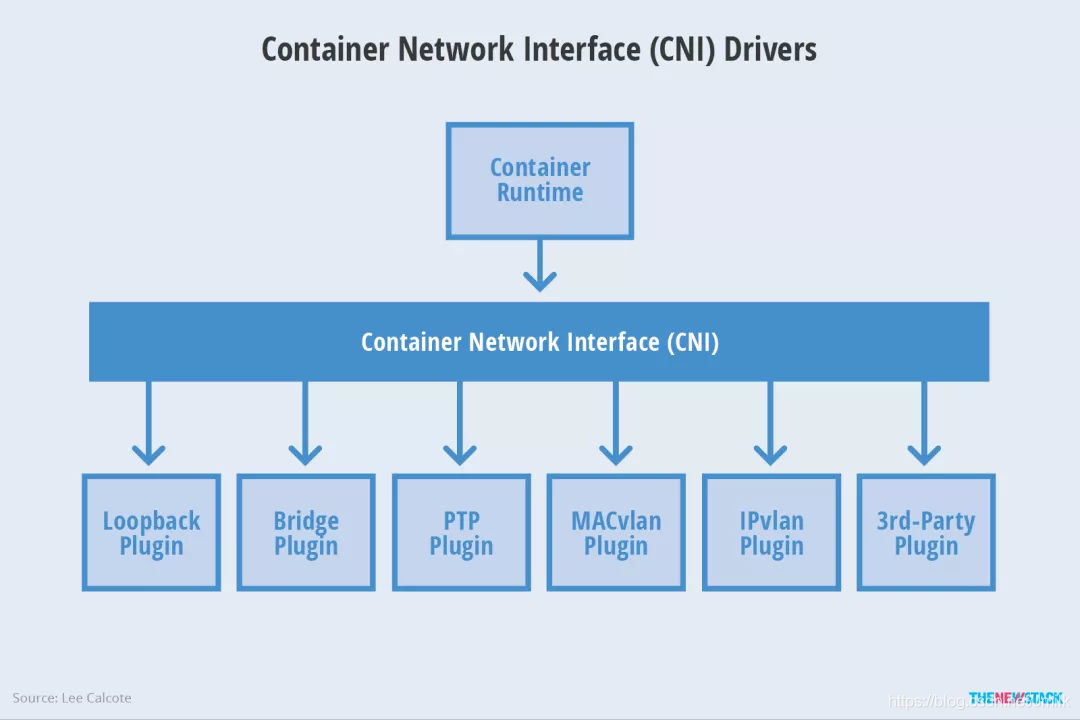
weiyigeek.top-CNI
常见的 CNI 网络插件有:
Calico(性能好、灵活性最强,目前的企业级主流):是一个基于 BGP 路由协议的纯 L3 的数据中心网络方案(不需要 Overlay),提供简单,可扩展的网络。除了可扩展的网络, Calico 还提供策略隔离。
Flannel(最成熟、最简单的选择):基于 Linux TUN/TAP,使用 UDP 封装 IP 数据包的方式来创建 Overlay 网络,并借助 etcd 来维护网络资源的分配情况,是一种简单易用的 Overlay 网络方案。
Weave Net:支持多主机容器网络可以跨越不同的云网络配置。独有的功能,是对整个网络的简单加密,会增加网络开销。
Cilium:是一个开源软件,基于 Linux Kernel BPF 技术,可以在 Linux Kernel 内部动态地插入具有安全性、可见性的网络控制逻辑。
kopeio-networking:是专为 Kubernetes 而设计的网络方案,充分利用了 Kubernetes API,因此更简单更可靠。
kube-router:是专为 Kubernetes 打造的专用网络解决方案,旨在提供操作简单性和性能。
CNI 插件项目 Forks 数量比较: weiyigeek.top-市场占有率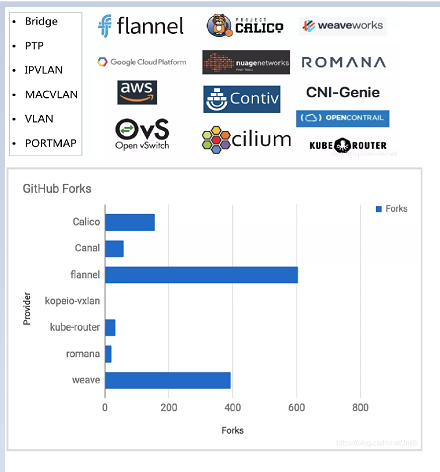
Tips : CNI 插件项目 10Gbit 网络下的 CPU 消耗比较 Calico < Cilium < Flannel < kube-router < Weave Net
描述: 在进行网络模型的讲解之前先来看看基础网络模型;
weiyigeek.top-
Kubernetes 网络中涉及以下几种类型的地址:
描述: 根据业务和需求的不同k8s在进行网络设计时主要考虑了下面几种通信场景
描述: Pod 内部的 Containers 间的通信(Container 模式),Pod 内部的 Containers 通过 localhost 进行通信,它们使用了同一个 Network Namespace。对 Container 而言hostname 就是 Pod 的名称。
weiyigeek.top-Pod 内部的 Containers 间的通信
Pod 内部的 Containers 共享同一个 IP 地址和端口区间,所以要为每个可以建立连接的 Container 分配不同的 Port 号。也就是说Pod 中的 “应用” 需要自己协调端口号的分配和使用。
举个例子:创建一个 Pod 包含两个 Containers 同一个 Pod 下属的两个 Containers 不能占有同一个 Port 号,因为 Port 区间也是共享的。
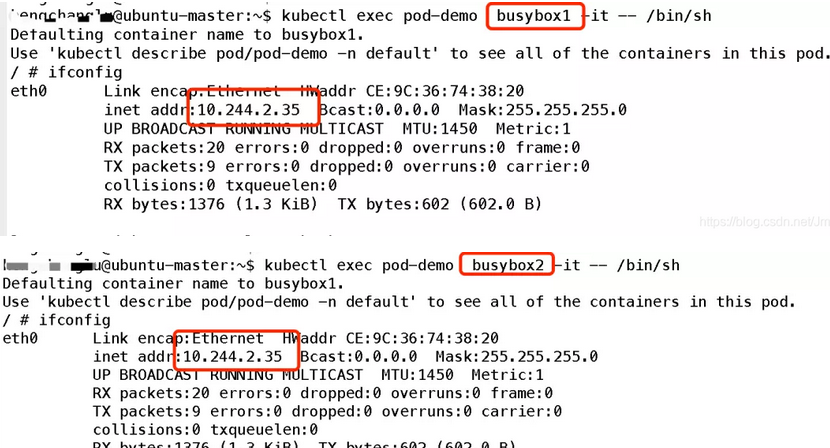
weiyigeek.top-Containers共享网络栈
所以,我们可以将 Pod 理解为一个小型的 “操作系统沙盒”,两个进程可以使用同一个操作系统 IP 地址,自然也就不可以使用同一个 Port 号了。
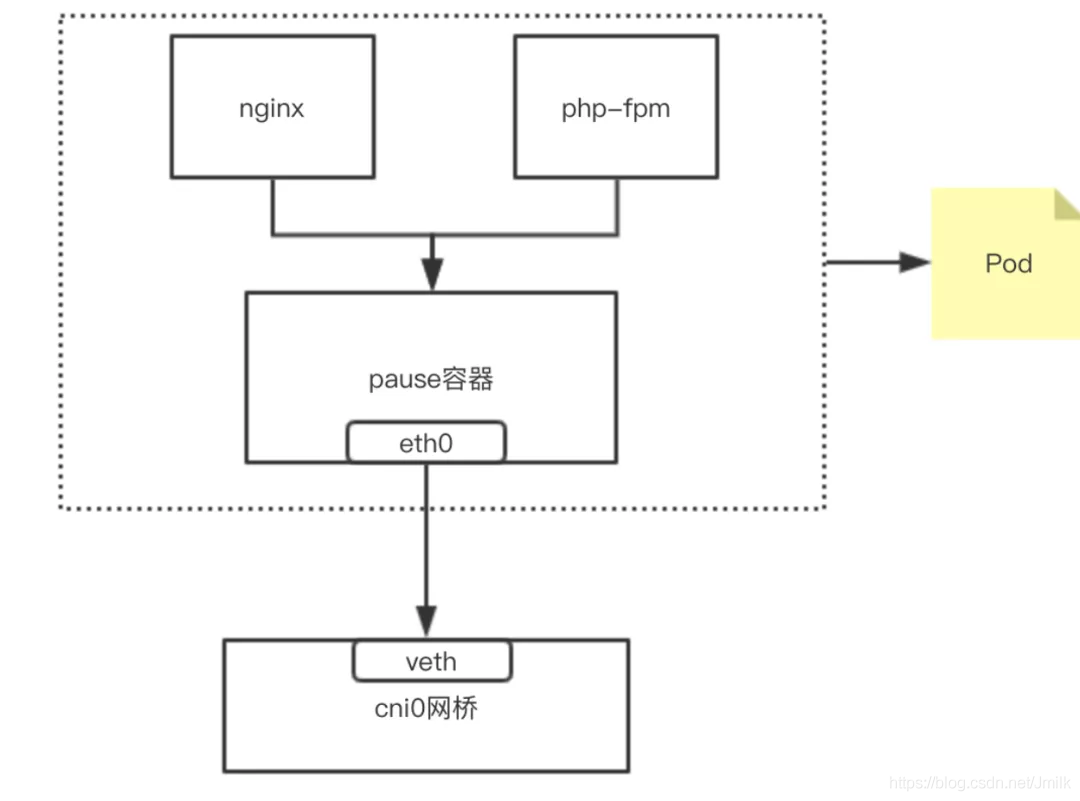
实现原理:同一个 Pod 内的 Containers 处于同一个 Network Namespace,因此使用了相同的 IP 地址和 Port 区间。该 Namespace 是由一个名为 Pause Container 实现的,每当一个 Pod 被创建,首先会创建一个 Pause Container。后续所有新的普通 Containers 都通过过共享 Pause Container 的网络栈,实现与外部 Pod 进行通信。因此对于同 Pod 下属的 Containers 而言,它们看到的网络视图是一样的。上述我们在 Container 中看的 IP 地址,实际就是 Pause Container 的 IP 地址,通过控制 Pause Container 的网络协议栈就可以影响所有同属 Pod 下的 Container 的网络协议栈了。
weiyigeek.top-Pause Container 的网络协议栈
Tips:这种新创建的容器和已经存在的一个容器(Pause)共享一个 Network Namespace(而不是和宿主机共享)的模式就是常说的 Container 模式。
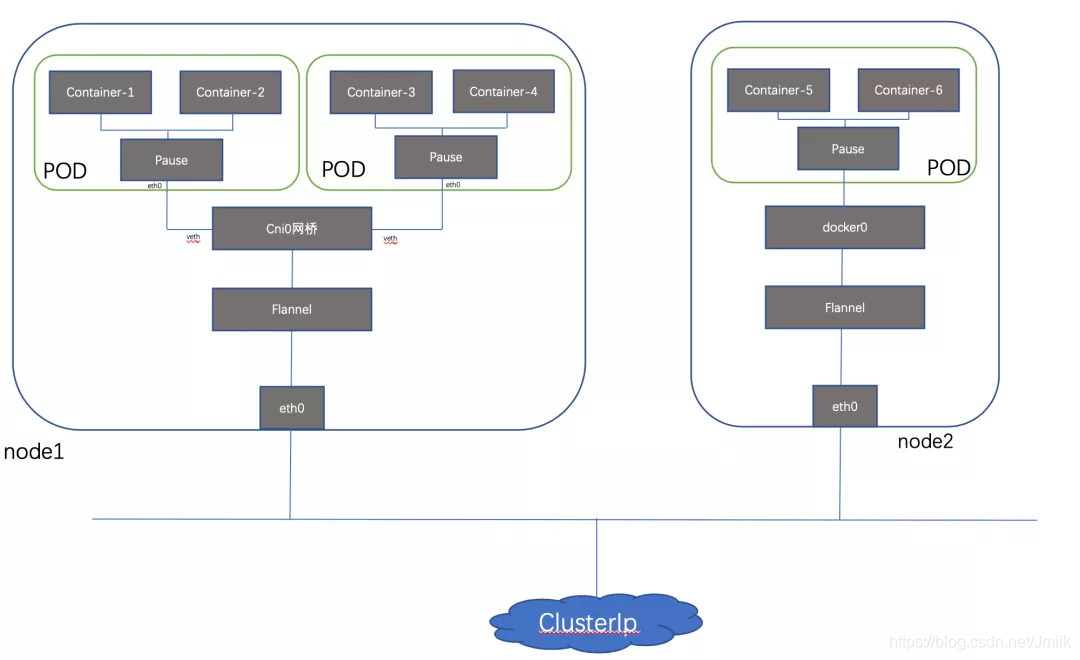
描述: 每个 Node 上的每个 Pod 都有自己专属的 Network Namespace,由此实现 Container 模型网络的隔离。而两个 Pod 之间即两个 Network Namespace 之间希望进行通信的话,就需要使用到 Linux 操作系统的网络虚拟化技术 Veth Pair(虚拟网线)了。
但是,如果有多个 Pod 都需要两两建立 Veth Pair 的话,扩展性就会非常的差,假如:有 N 个 Pod,就需要创建 n(n-1)/2 个 Veth Pair。可见,除了 Veth Pair(虚拟网线)之外,我们还需要一个二层的 “集线” 设备 Linux Bridge(虚拟交换机)。
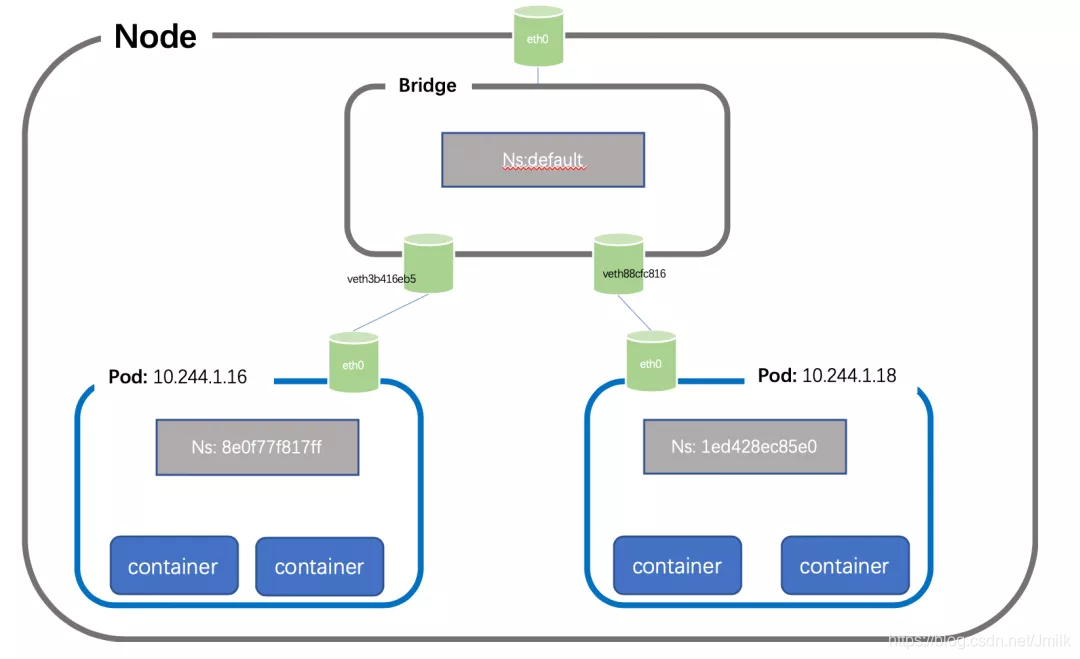
weiyigeek.top-同主机 Pod 间的通信
Tips: 在K8s节点中将会从Docker0虚拟网卡中的tunl0隧道接口子网中分配一个该网段IP给Pod进行使用并且此tunl0隧道接口地址即为Pod网关通信地址;
原理示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45# 方式1
$ ip addr
....
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 172.16.0.192/32 scope global tunl0 # 运行在该节点上的Pod的网关地址
valid_lft forever preferred_lft forever
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:e3:83:5e:a1 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:e3ff:fe83:5ea1/64 scope link
valid_lft forever preferred_lft forever
....
97: veth09836f7@if96: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 6e:e4:02:db:75:57 brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::6ce4:2ff:fedb:7557/64 scope link
valid_lft forever preferred_lft forever
117: veth867869c@if116: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 4a:62:4c:ba:c6:91 brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::4862:4cff:feba:c691/64 scope link
valid_lft forever preferred_lft forever
# 方式2
$ bridge -d link
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker0 docker0
97: veth09836f7@if96: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker0 state forwarding priority 32 cost 2
hairpin off guard off root_block off fastleave off learning on flood on mcast_flood on mcast_to_unicast off neigh_suppress off vlan_tunnel off isolated off veth09836f7
117: veth867869c@if116: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker0 state forwarding priority 32 cost 2
hairpin off guard off root_block off fastleave off learning on flood on mcast_flood on mcast_to_unicast off neigh_suppress off vlan_tunnel off isolated off veth867869c
# 例如本机的corednsPod
~$ kubectl get pod -n kube-system -o wide | grep "coredns"
coredns-6c76c8bb89-hr9b7 1/1 Running 2 61d 172.16.0.198 weiyigeek-107
coredns-6c76c8bb89-kgbdb 1/1 Running 2 61d 172.16.0.199 weiyigeek-107
# coredns 的端点情况
~$ kubectl get endpoints -n kube-system kube-dns
NAME ENDPOINTS AGE
kube-dns 172.16.0.198:53,172.16.0.199:53,172.16.0.198:53 + 3 more... 61d
# 路由跟踪就是本机
~$ tracepath -4 172.16.0.199
1?: [LOCALHOST] pmtu 1480
1: 172.16.0.199 0.063ms reached
1: 172.16.0.199 0.034ms reached
Resume: pmtu 1480 hops 1 back 1
补充说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 例如 jenkins-844756cf77-nvhmj pod 运行在weiyigeek-226节点的 172.16.182.205 中
~$ kubectl get pod -n devops -o wide
NAME READY STATUS RESTARTS AGE IP NODE
jenkins-844756cf77-nvhmj 1/1 Running 0 12d 172.16.182.205 weiyigeek-226
# 其次我们在宿主机上进行路由跟踪
~$ tracepath -4 172.16.182.205
1?: [LOCALHOST] pmtu 1480
1: 172.16.182.192 0.353ms # 实际上是weiyigeek-226节点的tunl0虚拟网卡;
1: 172.16.182.192 0.305ms
2: 172.16.182.205 0.304ms reached
# 验证结论
weiyigeek@weiyigeek-226:~$ ip addr | grep "172.16.182.192" -B 2
7: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 172.16.182.192/32 scope global tunl0
Tips : 这种借助于 Linux 操作系统原生的网络虚拟化技术实现的两个本地 Pods 之间的网络通信方式,称为 Host Virtual Network 模式。
描述: 总的来说跨主机通信无非是下面两种方式,本质是在网络上架设一层Overlay Network使容器的网络运行在Overlay网络上,前面提到K8s的网络对Pod的IP地址的规划是平面管理的。
从网络角度对 Flannel 和 Calico 进行简单对比(后面详细讲解)。
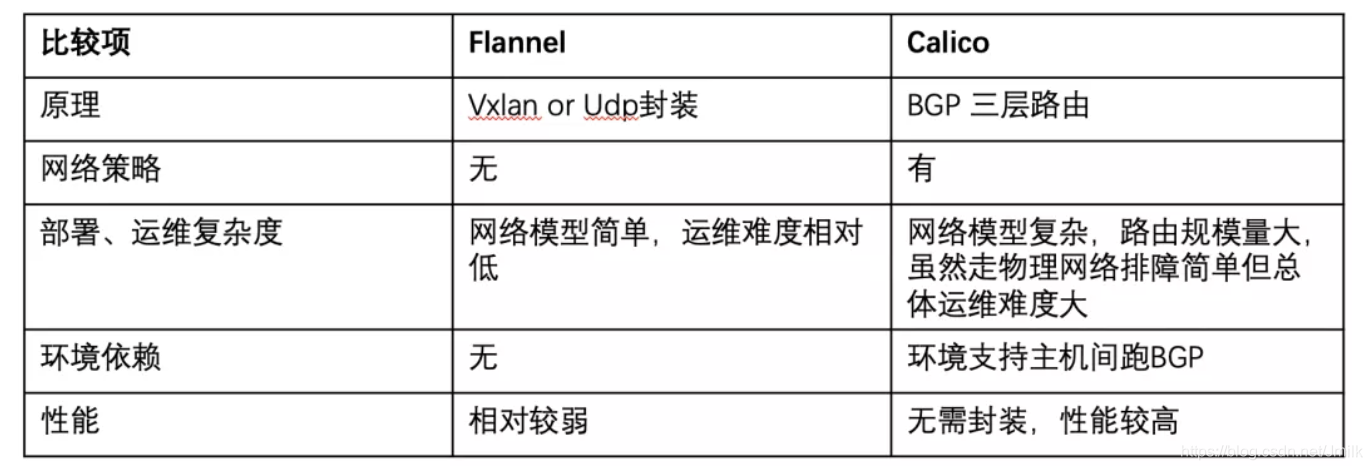
weiyigeek.top-Flannel 和 Calico对比
Tips: 可见对性能敏感、策略需求较高时偏向于 Calico 方案。否则采用 Flannel 会是更好的选择;
Tips: 跨主机Pod间通信的简单流程Pod1流出到Veth虚拟接口->到达Docker0网桥->通过宿主机物理网口->到达对方物理网口->对方Docker0网桥->Veth虚拟接口->Pod2
描述: Service 之于集群内部 Pods 之间的通信Pod 间可以直接通过 IP 地址通信,但前提是 Pod 知道对方的 IP。
在 Kubernetes Cluster 中,Pod 可能会频繁地销毁和创建,也就是说 Pod 的 IP 不是固定的。为了解决这个问题,Kubernetes Service 作为访问 Pod 的上层抽象。无论后端的 Pod 如何变化,Service 都作为稳定的前端对外提供服务(通过标签label方式进行绑定)。同时 Service 还提供了高可用和负载均衡功能,负责将请求转发给正确的 Pod。
描述: Service 之于集群外部与 Pod 的通信, 无论是 Pod IP 还是 Service 的 Cluster IP,它们都是只能在 Kubernetes Cluster 内部可见的私有 IP 地址。Kubernetes 提供了两种方式可以让外部网络访问 Service 的 Cluster IP继而与 Pod 进行通信:
ClusterIP : 默认类型自动分配一个仅Cluster内部可以访问的虚拟IP(常常由 flannel/Calico 网络插件进行管理)【service创建一个仅集群内部可访问的ip,集群内部其他的pod可以通过该服务访问到其监控下的pod】
NodePort:Service 通过 Node 的静态端口对外提供服务,外部网络可以通过 NodeIP:NodePort 访问 Service,根据不同的 NodePort 可以访问不同的 Service。
LoadBalancer:Service 利用自建的负载均衡器(反向代理)将流量导向 Service,例如:Nginx、OpenStack Octavia、Cloud Provider(GCP、AWS、 Azure)等。
Tips: NodePort 其工作原理与ClusterIP大致相同发送到某个NodeIP:NodePort时, 通过iptables重定向到kube-proxy对应的端口之中(固定或者随机由nodePort决定), 然后由Kube-proxy将请求发送到指定Pod的TargetPod端口之中。
Kube-proxy 原理简述
实现的两种Porxy Mode:
Service请求先会从用户空间进入内核的IPtables 然后回到用户空间,由kube-proxy完成后端的Endpoints的选择和代理工作,这样导致流量从用户空间进入内核带来的性能损耗是不可接受的。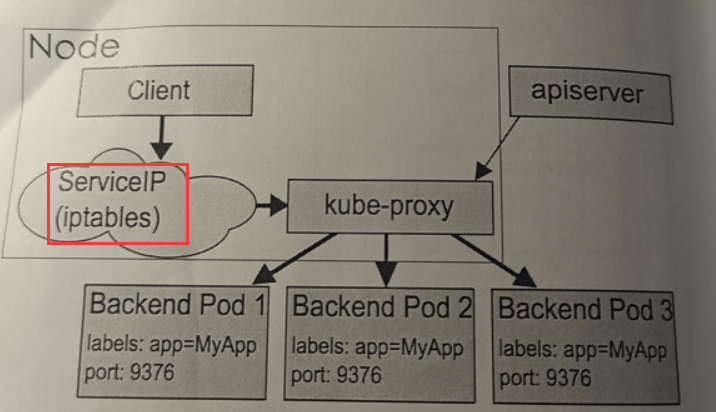
weiyigeek.top-UserSpace Mode
IPtables NAT来完成转发存在一定的且不可忽视的性能损耗。另外如果集群中存在上万的Service/Endpoint那么Node上的iptables rules将会非常庞大且性能还会再打折扣。所以常常在企业中通过Ingress Controller来集成HAproxy或者Nginx来替代Kube-proxy;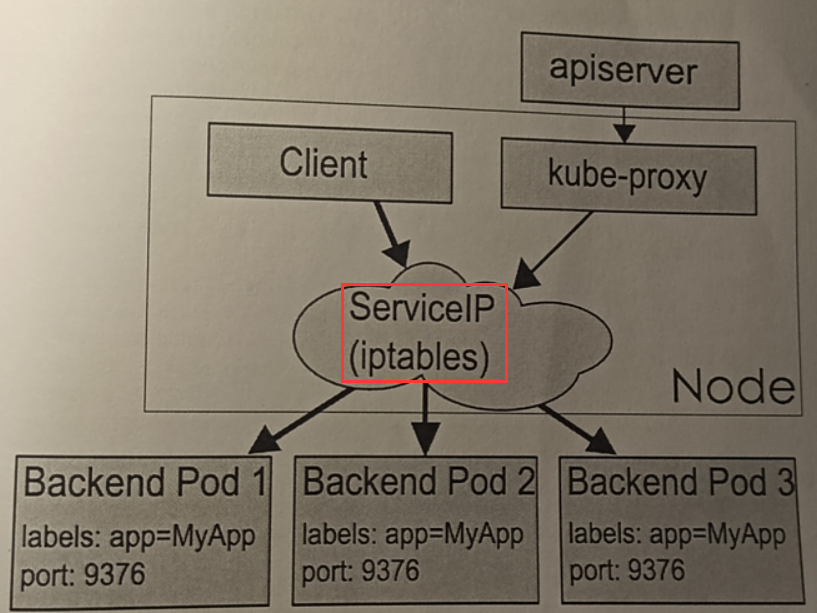
weiyigeek.top-IPtables mode
示例说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# (1) 获取ClusterIP与Endpoint端点可知 10.107.122.223 代理了后端 172.16.182.200:8080,172.16.183.89:8080,172.16.24.230:8080
~$ kubectl get endpoints deploy-maven-svc
# NAME ENDPOINTS AGE
# deploy-maven-svc 172.16.182.200:8080,172.16.183.89:8080,172.16.24.230:8080 9d #
~$ kubectl get svc deploy-maven-svc
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# deploy-maven-svc NodePort 10.107.122.223 <none> 8080:30089/TCP 9d
# (2) 内核中 iptables 转发列表查看
~$ sudo iptables -S -t nat
# -A KUBE-FIREWALL -j KUBE-MARK-DROP
# -A KUBE-LOAD-BALANCER -j KUBE-MARK-MASQ
# -A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
# -A KUBE-NODE-PORT -p tcp -m comment --comment "Kubernetes nodeport TCP port for masquerade purpose" -m set --match-set KUBE-NODE-PORT-TCP dst -j KUBE-MARK-MASQ
# -A KUBE-POSTROUTING -m comment --comment "Kubernetes endpoints dst ip:port, source ip for solving hairpin purpose" -m set --match-set KUBE-LOOP-BACK dst,dst,src -j MASQUERADE
# -A KUBE-POSTROUTING -m mark ! --mark 0x4000/0x4000 -j RETURN
# -A KUBE-POSTROUTING -j MARK --set-xmark 0x4000/0x0
# -A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -j MASQUERADE --random-fully
# # 此为 Pod 运行的的网段指向`KUBE-CLUSTER-IP`ClusterIP
# -A KUBE-SERVICES ! -s 172.16.0.0/16 -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
# -A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODE-PORT
# # 转发到 KUBE-SERVICES 链中匹配CLUSTER-IP地址进行通信
# -A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT
描述: Flannel 是 CoreOS 团队针对于Kubernetes设计的一个网络规划服务也可以为其它其它容器提供往来服务,简单来说它的功能是让集群中的不同节点主机创建的Docker容器都具有全集权唯一的虚拟IP地址,并且它能将这些IP地址之间建立一个覆盖网络(Overlay Network 将数据包原封不动的传递到目标容器内),即实现了跨主机的扁平化管理网络;
Tips: 所有容器在Flannel提供的网络平面上可以看作是同一个网段自由通信,其模型全部的容器使用一个Network然后在每个Host上从network中划分一个子网subnet,在为host上的容器创建网络时,将会从subnet中划分一个IP给容器,这样就大大提高了容器之间的工作效率并且不用考虑IP转换问题。
Tips: 由于K8s的模型为每一个Pod提供一个IP,Flannel的模型正好与之契合。因此Flannel是最简单易用的Kubernetes集群网络解决方案。
优缺点
优点: Flannel 模型与K8s默认模型一样都为每个Pod提供一个ip,其可以大大提升容器之间的工作效率。
缺点: 资源占用较高,且必须和etcd数据库一起使用。
原理解析与图示
描述: Flannel网络解决方案利用Overlay网络在报文进入实际物理网络之前会经过一层UDP封装作为Playload到达对端,对端拿到UDP报文后进行解包得到真实用户报文后转发给实际接收方。
原理图如下: weiyigeek.top-Flannel网络解决方案原理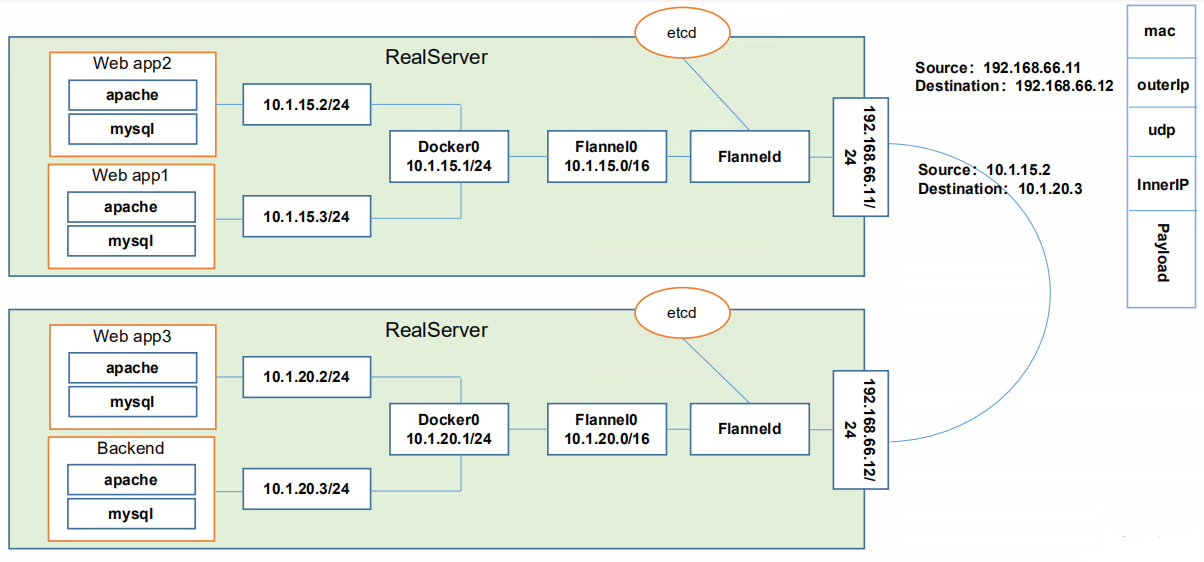
原理说明:
便于跨Pod间交流通信知道走哪里);囊括说明: Flannel 网络组件离不开etcd因为其存储了各个Node中Pod子网以及Service相关的IP地址,当需要对其它HOST进行数据转发时,从etcd数据库查询到目标host所在的子网IP,并将数据发往对应的host上的Flanneld交由其转发。
Tips : 官方图示为Docker0但出于地址规划的原因,实际上在K8s上会新创建一个CNI0网桥其负责本 Node 容器的IP分配(/24)。
Q: 每个Node都有自己的CNI0网桥如何保证地址不会重复分配呢?
答: 这就是使用了Flannel插件其会根据全局统一的etcd来为每一个Node分配全集群唯一的网段来避免地址分配冲突,即当cni0拿到报文后查询本机路由,将会匹配的是16位的掩码Flannel。
Q: linux 上用户态和内核态通信的手段?
1.Netlink Socket
2.syscall : 例如调用用户态的read/write接口。
3.IOCTL
4.procfs : 例如读取/proc目录下的ip统计计数。
5.TUN/TAP : 两种驱动程序实现了虚拟网卡的功能,Tun表示虚拟的是点对点的设备,tap表示虚拟的是以太网设备两种设备都是对网络包实施不同的封装。
地址分配 & 路由下发
描述: flanneld 守护进程第一次启动时,会从 etcd 获取配置的 Pod 网段信息,为本节点分配一个未使用的 IP 地址段,然后创建 flannedl.1 网络接口(也可能是其它名称),Flannel 将分配给自己的 Pod 网段信息写入 /run/flannel/docker 文件(不同 Kubernets 版本的文件名存在差异),Docker 后续使用这个文件中的环境变量设置 docker0 网桥,从而使这个地址段为本节点的所有。
1 | # 查看 Flannel 为 Docker 分配的地址段: |
Tips : 表示该 Node 上所有 Pod 的 IP 地址都从 Flannel Subnet 10.244.1.1/24 中分配,比如 node1 下属的 2 个 Pod 的 IP 地址:1
2
3
4
5
6~$ kubectl get pod -o wide | grep "Running"
# deploy-blog-html-0 1/1 Running 2 79d 10.244.1.19 weiyigeek-ubuntu
# deploy-java-maven-0 1/1 Running 2 40d 10.244.1.15 weiyigeek-ubuntu
# nfs-client-provisioner-58b5dc958d-pxhb7 1/1 Running 1 11d 10.244.1.20 weiyigeek-ubuntu
# nginx-app 1/1 Running 2 38d 10.244.1.14 weiyigeek-ubuntu
# web-0 1/1 Running 2 38d 10.244.1.16 weiyigeek-ubuntu
Tips : 路由下发 每个 Node 中的 flanneld 守护进程,可以创建 Kernel 的路由表,查看 node1 的路由表如下, 其中 Destination 10.244.2.0 为 node2 的目的网段出口为 flannel.1 interface;flannel.1 interface是 flanneld 创建的一个隧道接口。并且 flanneld 中央存储了 Container-Node 之间的映射关系到 etcd 中,以此来作为建立最外层隧道封装的 Tunnel ID,将两个 Nodes 中的两个 Containers 互联起来。
1 | ~$ route -n |
数据封装
描述: Flannel 知道外层封装的隧道对端 IP 地址后,对数据报文进行封装,SourceIP 采用本节点的 NodeIP,DestIP 采用对端的 VXLAN 外层的 UDP Port 8472,隧道的对端只需要监听这个 Port 即可,当该 Port 收到报文后将报文送到 flannedld 进程,进程将报文送到 flanned interface 进行封装,然后查询本地路由表,可以看到目的地址的 interface 为 cni01
2
3
4~$ route -n
# Kernel IP routing table
# Destination Gateway Genmask Flags Metric Ref Use Iface
# 10.244.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
实际流程
1) 假如 Web app3 访问 Backend , 其流程如下
1 | 1.Web APP3 发生请求记录目标的IP为10.1.20.3和请求地址的数据包 |
2) 假如 Web app2 访问 Backend , 其流程如下
1 | 1.Web APP3 发生请求生成数据包其中包括目标的IP(`10.1.20.3`)和源IP(10.1.15.2)以及自身的Mac |
Flannel跨Pod通信流程: Container A -> vethx(Pod IP) -> docker0 -> flannel(0CNI) -> Node A(物理网卡) --> Node B(物理网卡) -> flannel(0CNI) -> docker0 -> vethx (Pod IP) -> Container B
weiyigeek.top-Flannel跨Pod通信流程
补充说明:
(1) Docker 可以与 Flannel 网络模型进行集成配置;
1 | ~$ mkdir -vp /usr/lib/systemd/system/docker.service.d/ |
(2) Flannel 支持 2 种不同的后端实现,分别是:
描述: Calico 是一个纯三层的数据中心网络方案,而且无缝集成像OpenStack这种IaaS云架构,能够提供可控的VM/容器/裸机之间的IP通信。其采用虚拟路由替代虚拟交换,每台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心。
原理解析
描述: Calico 在每一个计算节点利用Linux Kernel 实现一个高效的vRouter来负责数据的转发,而每个vRouter通过BGP协议负责把自己运行的Workload的路由信息向整个Calico网络传播(小规模可以直接互联而在大规模下可通过指定的BGP Route Reflector来完成)。
Calico 架构
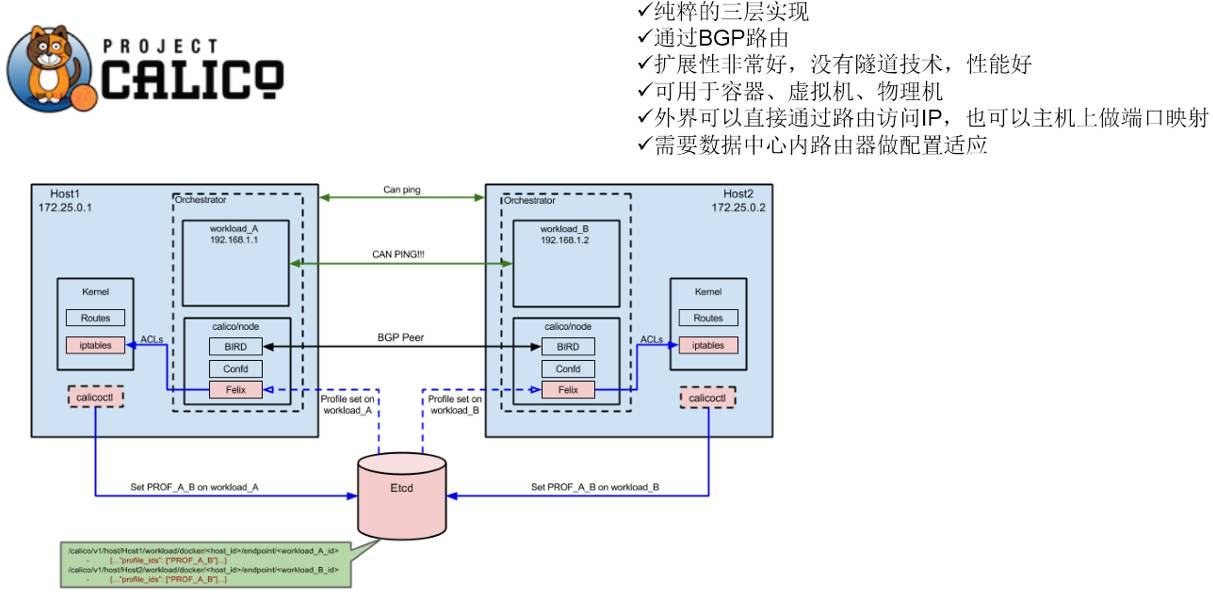
weiyigeek.top-架构图
Calico 组件功能(重点):
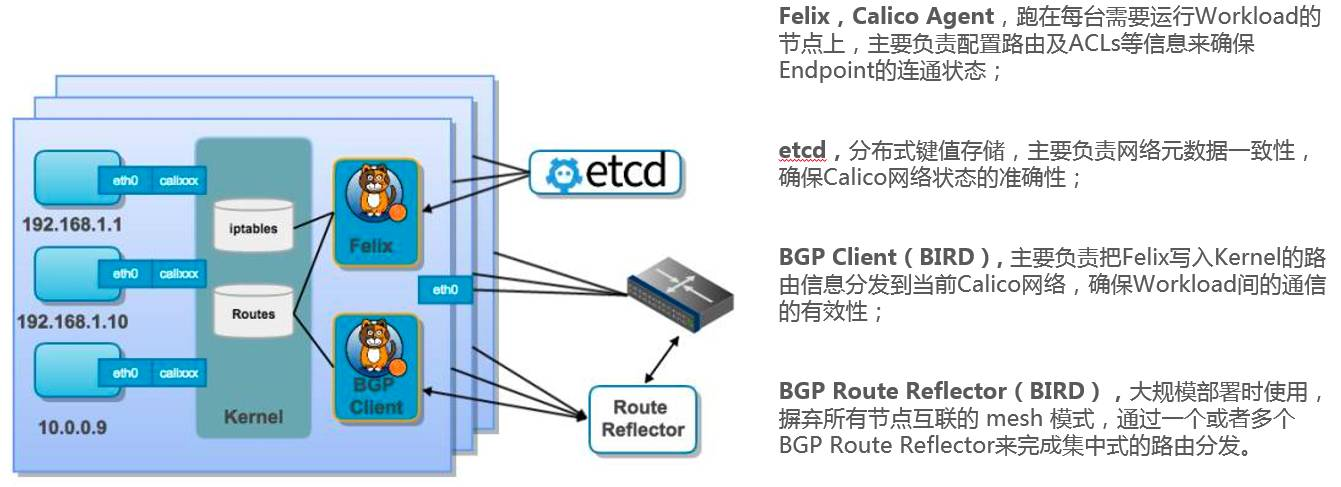
weiyigeek.top-组件功能图
Tips : Calico 其不使用重叠的网络比如Flannel 和 Libnetwork 网络驱动。
Tips : Calico 节点组网可直接利用数据中心的网络结果无论是(L2或者L3),不需要额外的NAT以及隧道或者Overlay Network;
Tips : Calico 基于IPtables还提供了丰富而又灵活的网络Policy, 保证通过各个节点上的ACLs来提供Workload的多租户隔离、安全组以及其它可达限制等功能。
Calico 支持 3 种路由模式:
这里主要介绍 Direct 模式,使用 BGP 路由协议宣告容器网段,使得全网所有的 Nodes 和网络设备都有到彼此的路由的信息,然后直接通过 Underlay 转发。
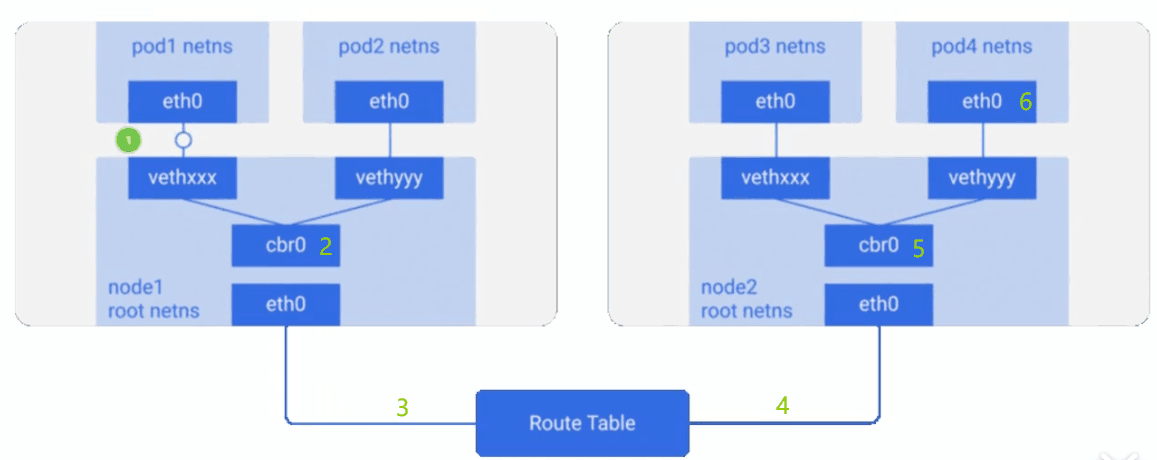
通信流程:
数据通信的流程为数据包先从 Veth Pair 的一端发出,到达 Node 上的以 Cali 为前缀的虚拟网卡上,也就到达了 Host 的内核网络协议栈, 然后查询路由表转发;因为本地节点通过 Bird 和 RR 建立 BGP 邻居关系,会将本地的容器地址发送到 RR 从而反射到网络中的其它 Nodes 上,同样其它 Nodes 的网络地址也会传送到本地,然后由 Felix 进程进行管理并下发到路由表中,报文匹配路由规则后正常进行转发即可(实际还有复杂的 iptables 规则这里不做展开)。
1 | # 虚拟接口 |
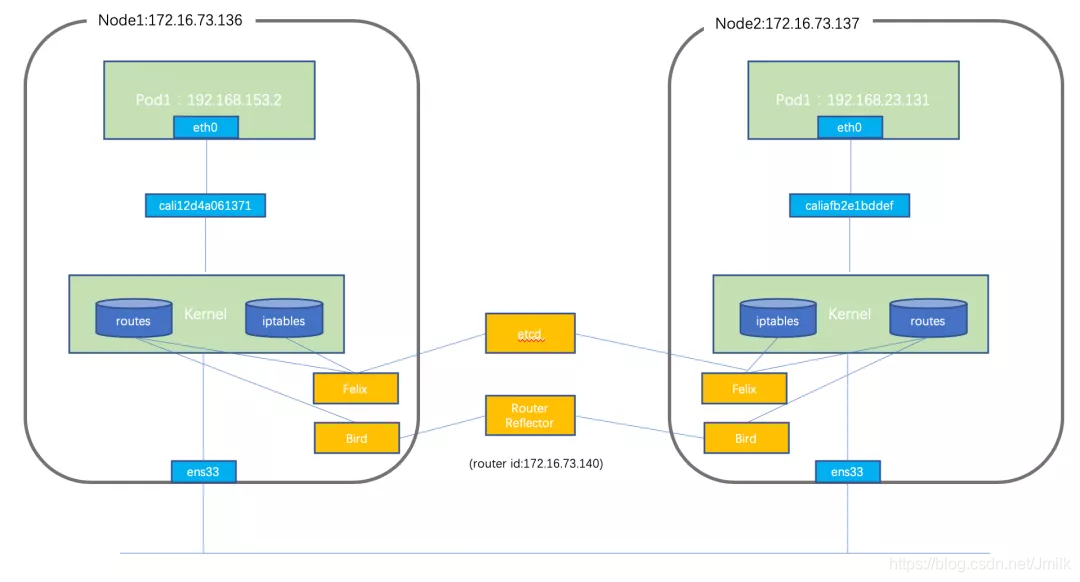
weiyigeek.top-通讯图示
描述: Kubernetes 就是通过使用容器卷映射的功能修改 /etc/resolv.conf,使集群的所有容器都使用集群 DNS 服务器(CoreDNS)进行 DNS 解析, 默认的集群DNS名称为svc.cluster.local。
文档参考地址: https://coredns.io/manual/toc/
应用场景: https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/
应用场景: https://kubernetes.io/docs/tasks/administer-cluster/dns-custom-nameservers/
Tips : 在 K8s 中它被用于提供服务发现功能; CoreDNS 最大的特点是灵活,可以很方便地给它编写插件以提供新功能。功能非常强大,相比传统 DNS 服务器,它非常“现代化”。
CoreDNS 应用在k8s场景
描述: 主流的本地 DNS 服务器中,提供 UI 界面的有 Windows DNS Server 和 群晖 DNS Server,很方便不过这两个都是操作系统绑定的。
在开源的 DNS 服务器里边儿BIND 好像是最有名的,各大 Linux 发行版自带的 dig/host/nslookup,最初都是 Bind 提供的命令行工具, 不过为了一举两得(DNS+K8s)咱还是直接学习 CoreDNS 的使用。。
示例1.在k8s中集群内部服务发现与绑定采用的是CoreDNS如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 1) 例如 我们设置 /etc/resolv.conf 如下
# nameserver 192.168.12.254
# search weiyigeek.top weiyigeek.cn
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
# ndots:5 是指少于 5 个 dots 的域名,都首先当作非 FQDN 看待优先在搜索域里面查找;
options ndots:5
# 2) 输入一个不存在的域名查看尝试过程
~$ host -v weiyigeek
# Trying "weiyigeek.default.svc.cluster.local"
# Trying "weiyigeek.svc.cluster.local"
# Trying "weiyigeek.cluster.local"
# Trying "weiyigeek"
# Host weiyigeek not found: 3(NXDOMAIN)
# Received 102 bytes from 10.96.0.10#53 in 47 ms
CoreDNS 配置外部DNS
描述: 接下来以 CoreDNS 为例,讲述如何配置一个 DNS 服务器,添加私有的 DNS 记录,并设置转发规则以解析公网域名。
1 | .:53 { |
Corefile 首先定义 DNS 域,域后的代码块内定义需要使用的各种插件。注意这里的插件顺序是没有任何意义的!插件的调用链是在 CoreDNS 编译时就定义好的,不能在运行时更改。
通过上述配置启动的 CoreDNS 是无状态的,它以 Kubernetes ApiServer 为数据源,CoreDNS 本身只相当于一个查询器/缓存,因此它可以很方便地扩缩容。
1 | # 定义可复用 Block |
上面的 Corefile 定义了两个本地域名 dev-env.local 和 test-env.local,它们的 DNS 数据分别保存在 file 指定的文件中。
这个 file 指定的文件和 bind9 一样,都是使用在 rfc1035 中定义的 Master File 格式,dig 命令输出的就是这种格式的内容。示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16;; 與整個領域相關性較高的設定包括 NS, A, MX, SOA 等標誌的設定處!
$TTL 30
@ IN SOA dev-env.local. devops.dev-env.local. (
20200202 ; SERIAL,每次修改此文件,都应该同步修改这个“版本号”,可将它设为修改时间。
7200 ; REFRESH
600 ; RETRY
3600000 ; EXPIRE
60) ; MINIMUM
@ IN NS dns1.dev-env.local. ; DNS 伺服器名稱
dns1.dev-env.local. IN A 192.168.23.2 ; DNS 伺服器 IP
redis.dev-env.local. IN A 192.168.23.21
mysql.dev-env.local. IN A 192.168.23.22
elasticsearch.dev-env.local. IN A 192.168.23.23
ftp IN A 192.168.23.25 ;
test-env.local 也是一样的格式,根据上面的模板修改就行, 将这两个配置文件和 Corefile 放在同一个目录下:1
2
3
4
5
6root@test-ubuntu:~/dns-server# tree
.
├── coredns # coredns binary
├── Corefile
├── dev-env.local
└── test-env.local
然后通过 ./coredns 启动 coredns。通过 dig 检验不出意外就可以看到 ftp.dev-env.local 已经被成功解析了。
可选插件(External Plugins)
CoreDNS 提供的预编译版本,不包含 External Plugins 中列出的部分,如果你需要,可以自行修改 plugin.cfg,然后手动编译。不得不说 Go 语言的编译,比 C 语言是方便太多了。自动拉取依赖一行命令编译!只要配好 GOPROXY,启用可选插件其实相当简单。
设置 DNS 集群
单台 DNS 服务器的性能是有限的,而且存在单点故障问题。因此在要求高可用或者高性能的情况下,就需要设置 DNS 集群。
虽然说 CoreDNS 本身也支持各种 DNS Zone 传输,主从 DNS 服务器等功能,不过我想最简单的,可能还是直接用 K8s。
直接用 ConfigMap 存配置,通过 Deployment 扩容就行,多方便。
要修改起来更方便,还可以启用可选插件:redis,直接把配置以 json 的形式存在 redis 里,通过 redis-desktop-manager 进行查看与修改。
1) CPU 压力 低 -> 高
对比结果: host < Calico (BGP) < Calico (IPIP) == Flannel (VXLAN) == Docker (VXLAN) < Flannel(UDP) < Weave (UDP)
2) 带宽(MB/Sec) 低 -> 高
对比结果: Weave (UDP) < Flannel(UDP) < Flannel (VXLAN) < Docker (Overlay) < Calico (BGP) < Calico (IPIP) < Host
3) 延迟(us) 低 -> 高
对比结果: Host < Calico (IPIP) < Calico (BGP) < Flannel (VXLAN) < Flannel (udp) < Docker(Overlay)
| 网络方案 | Calico | Flannel | Docker Overlay |
|---|---|---|---|
| 优势 | 性能好、可靠性及隔离性好 | 部署简单性能还可以 | Docker原生性能凑合 |
| 劣势 | 操作复杂对IPtbales依赖 | 无法实现固定IP的容器漂移以及无法子网隔离,对上层设计依赖度高,没有IPAM以及IP地址浪费对Docker启动方式有绑定 | 对内核版本有要求(>3.16)并且docker守护进程依赖于Consul或者Etcd, 本身驱动实现还是略差点。针对于Network以及多子网隔离局部交叉的需求还是比较麻烦的IPAM很差。 |
网络组件总结: Calico BGP方案最好不能用BGP也可以考虑Calico ipiptunnel方案;如果是CoreOS系又能开UDP Offload,Flannel是不错的选择, Docker原生Overlay还有很多需要改进的地方。
Q:A的Pod如何连接B的Pod? kube-dns起到什么作用? kube-dns如果调用kube-proxy?
A:这里说的A和B应当是指Service,A Service中Pod与B Service Pod之间的通信,可以在其容器的环境变量中定义Service IP或是Service Name来实现;由于Service IP提前不知道,使用引入kube-dns做服务发现,它的作用就是监听Service变化并更新DNS,即Pod通过服务名称可以查询DNS;kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负责service的实现,具体来说,就是实现了内部从Pod到Service和外部的从NodePort向Service的访问,可以说kube-dns和kube-proxy都是为Service服务的。
Q:网络问题docker default是网桥模式(NAT) 如果用路由的模式,所以Pod的网关都会是docker0 IP ? 那Pod 1与Pod 2之间也走路由 ,这会使路由表很大? Flannel 网络是不是可以把所有的Node上,相当于一个分布式交换机?
A:Docker实现跨主机通信可以通过桥接和路由的方式,桥接的方式是将docker0桥接在主机的网卡上,而路由直接通过主机网口转发出去;Kubernetes网络有Pod和Server,Pod网络实现的方式很多,可以参考CNI网络模型,Flannel实质上是一种`“覆盖网络(Overlay Network)”`,也就是`将TCP数据包装在另一种网络包里面进行路由转发和通信`。
Q:大规模容器集群如何保证安全? 主要从几个方面考虑?
Q:SVC如何进行客户端分流,A网段的访问Pod1 ,B网段的访问Pod2,C网段的访问Pod3,3个Pod都在SVC的Endpoint中?
A:内部从Pod到Service的实现是由kube-proxy(简单的网络代理和负载均衡器)来完成,kube-proxy默认采用轮询方法进行分配,也可以通过将service.spec.sessionAffinity设置为“ClientIP”(默认为“无”)来选择基于客户端IP的会话关联,目前还不能进行网段的指定。
Q:对于Ingress+HAProxy这种实现Service负载均衡的方式,Ingress controller轮询Service后面的Pods状态,并重新生成HAProxy配置文件,然后重启HAProxy,从而达到服务发现的目的。这种原理对于HAProxy来讲是不是服务会暂时间断。有没有好的替代方案?之前看到Golang实现的Træfik,可无缝对接Kubernetes,同时不需要Ingress了。方案可行么?
A:由于微服务架构以及Docker技术和Kubernetes编排工具最近几年才开始逐渐流行,所以一开始的反向代理服务器比如Nginx/HAProxy并未提供其支持,毕竟他们也不是先知,所以才会出现IngressController这种东西来做Kubernetes和前端负载均衡器如Nginx/HAProxy之间做衔接,即Ingress Controller的存在就是为了能跟Kubernetes交互,又能写 Nginx/HAProxy配置,还能 reload 它,这是一种折中方案;而最近开始出现的Traefik天生就是提供了对Kubernetes的支持,也就是说Traefik本身就能跟Kubernetes API交互,感知后端变化,因此在使用Traefik时就不需要Ingress Controller,此方案当然可行。
Q:1、一个POD里面的多个Container是同一个Service的?还是由不同的Service的组成? 是啥样的分配逻辑? 2、Flannel 是实现多个宿主机上的N多的Service以及Pod里面的各个Container的IP的唯一性么? 3、Kubernetes具备负载均衡的效果 。那是否就不用在考虑Nigix?
A:Pod是Kubernetes的基本操作单元,Pod包含一个或者多个相关的容器,Pod可以认为是容器的一种延伸扩展,一个Pod也是一个隔离体,而Pod内部包含的一组容器又是共享的(包括PID、Network、IPC、UTS);Service是Pod的路由代理抽象,能解决Pod之间的服务发现问题;Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信;Kubernetes kube-proxy实现的是内部L4层轮询机制的负载均衡,要支持L4、L7负载均衡,Kubernetes也提供了Ingress组件,通过反向代理负载均衡器(Nginx/HAProxy)+Ingress Controller+Ingress可以实现对外服务暴露,另外使用Traefik方案来实现Service的负载均衡也是一种不错的选择。
Q:kube-proxy是怎样进行负载? Service虚拟IP存在哪里?
A:kube-proxy有2个模式实现负载均衡,一种是userspace,通过Iptables重定向到kube-proxy对应的端口上,然后由kube-proxy进一步把数据发送到其中的一个Pod上,另一种是Iptables,纯采用Iptables来实现负载均衡,kube-proxy默认采用轮询方法进行分配,也可以通过将service.spec.sessionAffinity设置为“ClientIP”(默认为“无”)来选择基于客户端IP的会话关联;Service Cluster IP它是一个虚拟IP,是由kube-proxy使用Iptables规则重新定向到其本地端口,再均衡到后端Pod的,通过 apiserver的启动参数--service-cluster-ip-range来设置,由kubernetes集群内部维护。
Q:Kubernetes网络复杂,如果要实现远程调试,该怎么做,端口映射的方式会有什么样的隐患?
A:Kubernetes网络这块采用的是CNI规范,网络插件化,非常灵活,不同的网络插件调试的方法也是不一样的;端口映射方式的最大隐患就是很容易造成端口冲突。
Q:RPC的服务注册,把本机IP注册到注册中心,如果在容器里面会注册那个虚拟IP,集群外面没法调用,有什么好的解决方案吗?
A:Kubernetes Service到Pod的通信是由kube-proxy代理分发,而Pod中容器的通信是通过端口,不同Service间通信可以通过DNS,不一定要使用虚拟IP。
Q:我现在才用的是CoreOS作为底层,所以网络采用的是Flannel 但是上层用Calico作为Network Policy,最近有一个Canal的结构和这个比较类似,能介绍一下么,可以的话,能详细介绍一下CNI原理和Callico的Policy实现么?
A:Canal不是很了解;CNI并不是网络实现,它是网络规范和网络体系,从研发的角度它就是一堆接口,关心的是网络管理的问题,CNI的实现依赖于两种Plugin,一种是CNI Plugin负责将容器connect/disconnect到host中的vbridge/vswitch,另一种是IPAM Plugin负责配置容器Namespace中的网络参数;Calico 的policy是基于Iptables,保证通过各个节点上的 ACLs 来提供workload 的多租户隔离、安全组以及其他可达性限制等功能。
Q:CNI是怎么管理网络的?或者说它跟网络方案之间是怎么配合的?
A:CNI并不是网络实现,它是网络规范和网络体系,从研发的角度它就是一堆接口,你底层是用Flannel也好、用Calico也好,它并不关心,它关心的是网络管理的问题,CNI的实现依赖于两种plugin,一种是CNI Plugin负责将容器connect/disconnect到host中的vbridge/vswitch,另一种是IPAM Plugin负责配置容器Namespace中的网络参数。
Q:Service是个实体组件么?那些个Service配置文件,什么部件来执行呢?
A:Services是Kubernetes的基本操作单元,是真实应用服务的抽象,Service IP范围在配置kube-apiserver服务的时候通过--service-cluster-ip-range参数指定,由Kubernetes集群自身维护。
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/虚拟云容/云容器/Kubernetes/10-kubernetes进阶之网络设计实现方案.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2020/9-27-538.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议