[TOC]
0x00 Kubernetes Etcd 数据备份与恢复
描述:Kubernetes 使用 Etcd 数据库实时存储集群中的数据,可以说 Etcd 是 Kubernetes 的核心组件,犹如人类的大脑。如果 Etcd 数据损坏将导致 Kubernetes 不可用,在生产环境中 Etcd 数据是一定要做好高可用与数据备份,这里介绍下如何备份与恢复 Etcd 数据。
Etcd 版本说明:

[TOC]
描述:Kubernetes 使用 Etcd 数据库实时存储集群中的数据,可以说 Etcd 是 Kubernetes 的核心组件,犹如人类的大脑。如果 Etcd 数据损坏将导致 Kubernetes 不可用,在生产环境中 Etcd 数据是一定要做好高可用与数据备份,这里介绍下如何备份与恢复 Etcd 数据。
Etcd 版本说明:
[TOC]
描述:Kubernetes 使用 Etcd 数据库实时存储集群中的数据,可以说 Etcd 是 Kubernetes 的核心组件,犹如人类的大脑。如果 Etcd 数据损坏将导致 Kubernetes 不可用,在生产环境中 Etcd 数据是一定要做好高可用与数据备份,这里介绍下如何备份与恢复 Etcd 数据。
Etcd 版本说明:1
2
3$ etcdctl version
etcdctl version: 3.4.13
API version: 3.4
1 | # 由于 k8s.gcr.io 镜像仓库国内被墙,所以使用的是阿里云的 etcd 镜像 |
语法格式: 运行 Etcd 镜像,并且使用镜像内部的 etcdctl 工具连接 etcd 集群,执行数据快照备份:1
2
3
4
5
6
7
8
9
10
11--rm : 运行结束后则删除
-v:docker 挂载选项,用于挂载 Etcd 证书相关目录以及备份数据存放的目录
--env:设置环境变量,指定 etcdctl 工具使用的 API 版本
/bin/sh -c:执行 shell 命令
etcdctl etcd客户端工具
--cacert:etcd CA 证书
--key:etcd 客户端证书 key
--cert:etcd 客户端证书 crt
--endpoints:指定 ETCD 连接地址
snapshot save etcd 数据备份
/backup/etcd-snapshot.db 数据备份名称
以 Docker 镜像 备份 Etcd 数据:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# 验证开放端口
$ netstat -ano | grep -e "192.168.12.226:2379"
# tcp 0 0 192.168.12.226:2379 0.0.0.0:* LISTEN off (0.00/0/0)
# tcp 0 0 192.168.12.226:34376 192.168.12.226:2379 ESTABLISHED keepalive (10.06/0/0)
# etcd 证书一览
$ ls /etc/kubernetes/pki/etcd
# ca.crt ca.key healthcheck-client.crt healthcheck-client.key peer.crt peer.key server.crt server.key
# etcd备份文件存储的目录
$ mkdir -vp /data/backup
$ docker run --rm \
-v /data/backup:/backup \
-v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \
--env ETCDCTL_API=3 \
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0 \
/bin/sh -c "etcdctl --endpoints=https://192.168.12.226:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--key=/etc/kubernetes/pki/etcd/healthcheck-client.key \
--cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
snapshot save /backup/etcd-snapshot.db"
# {"level":"info","ts":1626848337.5133626,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/backup/etcd-snapshot.db.part"}
# {"level":"info","ts":"2021-07-21T06:18:57.535Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
# {"level":"info","ts":1626848337.535256,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://192.168.12.226:2379"}
# {"level":"info","ts":"2021-07-21T06:18:57.600Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
# {"level":"info","ts":1626848337.6088023,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://192.168.12.226:2379","size":"3.8 MB","took":0.095346714}
# {"level":"info","ts":1626848337.6089203,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/backup/etcd-snapshot.db"}
# Snapshot saved at /backup/etcd-snapshot.db
/data/backup$ ls -alh etcd-snapshot.db
-rw------- 1 root root 3.7M Jul 21 14:18 etcd-snapshot.db
二进制 etcdctl 的安装
描述: etcdctl 二进制文件可以在 github.com/coreos/etcd/releases 选择对应的版本下载,例如可以执行以下 install_etcdctl.sh的脚本,修改其中的版本信息。
1 | #!/bin/bash |
1 | # 创建目录 |
描述: 在 Etcd 数据损坏时,可以通过 Etcd 备份数据进行数据恢复,先暂停 Kubernetes 相关组件,然后进入 Etcd 镜像使用 etcdctl 工具执行恢复操作。
1 | # 移除且备份 /etc/kubernetes/manifests 目录 |
/default.etcd/member/ 目录下,这里使用 mv 命令在移动到挂载目录 /var/lib/etcd/ 下。语法格式:1
2
3
4/bin/sh -c:执行 shell 命令
--env:设置环境变量,指定 etcdctl 工具使用的 API 版本
-v:docker 挂载选项,用于挂载 Etcd 证书相关目录以及备份数据存放的目录
etcdctl snapshot restore:etcd 数据恢复。
单节点恢复数据:1
2
3
4
5
6
7# 将db导入到 etcd 之中并将生成文件复制到 /var/lib/etcd/
$ docker run --rm \
-v /data/backup:/backup \
-v /var/lib/etcd:/var/lib/etcd \
--env ETCDCTL_API=3 \
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0 \
/bin/sh -c "etcdctl snapshot restore /backup/etcd-snapshot.db; mv /default.etcd/member/ /var/lib/etcd/"
1 | $ mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests |
1 | # 方式1.执行 etcdctl 命令进行检测 |
Tips : 补充说明kubernetes之etcd集群备份恢复, 将 Master-01 生成etcd备份分别复制到 Master-02 和 Master-03。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# Master-01
etcdctl snapshot restore /backup/etcd-snapshot.db \
--name etcd-0 \
--initial-cluster "etcd-0=https://192.168.1.101:2380,etcd-1=https://192.168.1.102:2380,etcd-2=https://192.168.1.103:2380" \
--initial-cluster-token etcd-cluster \
--initial-advertise-peer-urls https://192.168.1.101:2380 \
--data-dir=/var/lib/etcd/
# Master-02
etcdctl snapshot restore /backup/etcd-snapshot.db \
--name etcd-1 \
--initial-cluster "etcd-0=https://192.168.1.101:2380,etcd-1=https://192.168.1.102:2380,etcd-2=https://192.168.1.103:2380" \
--initial-cluster-token etcd-cluster \
--initial-advertise-peer-urls https://192.168.1.102:2380 \
--data-dir=/var/lib/etcd/
# Master-03
etcdctl snapshot restore /backup/etcd-snapshot.db \
--name etcd-2 \
--initial-cluster "etcd-0=https://192.168.1.101:2380,etcd-1=https://192.168.1.102:2380,etcd-2=https://192.168.1.103:2380" \
--initial-cluster-token etcd-cluster \
--initial-advertise-peer-urls https://192.168.1.103:2380 \
--data-dir=/var/lib/etcd/
描述: 本章节主要实践次版本的升级,实践从v1.19.10集群版本升级至1.19主版本中最新的v1.19.13集群版本,还是基于并采用的dockershim运行时。
环境说明:
升级前系统容器及其kubernetes集群相关版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# Container
操作系统 : linux
体系架构 : amd64
操作系统镜像 : Ubuntu 20.04.2 LTS
操作系统内核 : 5.4.0-73-generic
容器引擎 : docker://19.3.14
容器运行时 : containerd.io 1.4.4
# Kubernetes
cri-socket : /var/run/dockershim.sock
kubelet : v1.19.10
kubeadm : v1.19.10
kubectl : v1.19.10
kube proxy : v1.19.10
etcdctl version: 3.4.13
API version: 3.4
Step 1.备份 kubernetes 的 etcd 数据以及备份当前Kubernetes集群创建配置以及相关文件(集群信息、etcd配置、证书文件等)1
2
3
4
5
6
7
8
9
10
11
12
13$ mkdir -vp /data/backup
$ docker run --rm \
-v /data/backup:/backup \
-v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd \
--env ETCDCTL_API=3 \
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0 \
/bin/sh -c "etcdctl --endpoints=https://192.168.12.226:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--key=/etc/kubernetes/pki/etcd/healthcheck-client.key \
--cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
snapshot save /backup/etcd-snapshot.db"
$ tar -zcf kubernetes-cluster.tar.gz /etc/kubernetes/*
Step 2.下载指定版本的kubernetes集群相关工具1
2
3
4
5
6
7
8
9
10
11
12# 升级 1.19.10 ~ 1.19.13
apt update && apt-cache madison kubeadm | head -n 15
...
kubeadm | 1.19.13-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
...
# 下载指定版本的 kubeadm kubectl
apt-get install -y kubelet=1.19.13-00 kubeadm=1.19.13-00 kubectl=1.19.13-00
apt-mark hold kubelet kubeadm kubectl
# 禁用节点调度
kubectl cordon master-01
Step 3.检测当前节点是否能升级1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$ kubeadm upgrade plan
[upgrade/versions] Latest version in the v1.19 series: v1.19.13
# Upgrade to the latest version in the v1.19 series:
# COMPONENT CURRENT AVAILABLE
# kube-apiserver v1.19.10 v1.19.13
# kube-controller-manager v1.19.10 v1.19.13
# kube-scheduler v1.19.10 v1.19.13
# kube-proxy v1.19.10 v1.19.13
# CoreDNS 1.7.0 1.7.0
# etcd 3.4.13-0 3.4.13-0
# 要手动升级到的版本在“首选版本”列中表示。
# API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
# kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
# kubelet.config.k8s.io v1beta1 v1beta1 no
Step 4.下载所有的 v1.19.13 版本的组件镜像(此次CoreDNS和etcd其版本不用进行更新)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# kubernetes 重要组件镜像
$ docker images -a | cut -d ' ' -f 1 | grep "google_containers/kube-"
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver
# 下载指定版本的 kubernetes 重要组件镜像
version=v1.19.13
$ for i in $(docker images -a | cut -d ' ' -f 1 | grep "google_containers/kube-");do
docker pull ${i}:${version}
done
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0
Step 5.升级当前k8s集群版本到v1.19.3版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79# 将原集群创建配置文件导出。
# kubectl -n kube-system get cm kubeadm-config -oyaml > kubeadm-config.yaml
kubeadm config view > kubeadm-config.yaml
apiServer:
certSANs:
- 192.168.12.111
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: k8s-dev.weiyigeek:6443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.21.3
networking:
dnsDomain: cluster.local
podSubnet: 172.16.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
# 将集群创建配置文件中 kubernetesVersion 对象 v1.19.10 改变为 v1.19.13。
sed -i 's#1.19.10#1.19.13#g' kubeadm-config.yaml
# 将Kubernetes集群升级到指定版本。
kubeadm upgrade apply v1.19.3 --config kubeadm-config.yaml
# 阻塞日志一览:
# [upgrade] Running cluster health checks
# [upgrade/version] You have chosen to change the cluster version to "v1.19.13"
# [upgrade/confirm] Are you sure you want to proceed with the upgrade? [y/N]: y
# [upgrade/prepull] Pulling images required for setting up a Kubernetes cluster
# 更新相关组件的Pod
# [upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.19.13"...
# Static pod: kube-apiserver-master-k8s hash: a0d32a30af20b818a19ceda6f3c8e810
# Static pod: kube-controller-manager-master-k8s hash: 3746ba71bc8ae5f787c4d7954828e6bb
# Static pod: kube-scheduler-master-k8s hash: b5d76b6f8724c79709b04e03bfb169f7
# 对etcd 和各k8s组件证书续期
# [upgrade/etcd] Upgrading to TLS for etcd
# [upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests410267198"
# [upgrade/staticpods] Preparing for "kube-apiserver" upgrade
# [upgrade/staticpods] Renewing apiserver certificate、 apiserver-kubelet-client certificate 、front-proxy-client certificate 、apiserver-etcd-client certificate
# kube-apiserver 组件
# Static pod: kube-apiserver-master-k8s hash: a0d32a30af20b818a19ceda6f3c8e810
# [apiclient] Found 1 Pods for label selector component=kube-apiserver
# [upgrade/staticpods] Component "kube-apiserver" upgraded successfully!
# kube-controller-manage 组件
# Static pod: kube-controller-manager-master-k8s hash: 3746ba71bc8ae5f787c4d7954828e6bb
# [apiclient] Found 1 Pods for label selector component=kube-controller-manager
# [upgrade/staticpods] Component "kube-controller-manager" upgraded successfully!
# kube-scheduler 组件
# Static pod: kube-scheduler-master-k8s hash: b5d76b6f8724c79709b04e03bfb169f7
# [apiclient] Found 1 Pods for label selector component=kube-scheduler
# [upgrade/staticpods] Component "kube-scheduler" upgraded successfully!
# 设置主要组件相关配置文件
# [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
# [kubelet] Creating a ConfigMap "kubelet-config-1.19" in namespace kube-system with the configuration for the kubelets in the cluster
# [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
# [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
# [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
# [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
# [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
# [addons] Applied essential addon: CoreDNS
# [addons] Applied essential addon: kube-proxy
# [upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.19.13". Enjoy! # 出现该句则表示升级成功。
Step 6.查看升级后kubernetes集群相关信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 取消禁用节点调度
kubectl uncordon master-01
kubectl cluster-info
# Kubernetes master is running at https://k8s-dev.weiyigeek:6443
# KubeDNS is running at https://k8s-dev.weiyigeek:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubectl get nodes -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# master-k8s Ready master 91d v1.19.13 192.168.12.226 Ubuntu 20.04.2 LTS 5.4.0-73-generic docker://19.3.15
kubectl get pod -n kube-system -o wide
# NAME READY STATUS
# calico-kube-controllers-69496d8b75-2fr5p 1/1 Running
# calico-node-mmthr 1/1 Running
# coredns-6c76c8bb89-mhrnq 1/1 Running
# coredns-6c76c8bb89-zbxhh 1/1 Running
# etcd-master-k8s 1/1 Running
# kube-apiserver-master-k8s 1/1 Running
# kube-controller-manager-master-k8s 1/1 Running
# kube-proxy-m69p8 1/1 Running
# kube-scheduler-master-k8s 1/1 Running
# metrics-server-77b878fdb-rlqdx 1/1 Running
Tips : 在升级Kubernetes集群后证书相关的到期时间也会延长一年。
Tips : kubeadm upgrade 也会自动对 kubeadm 在节点上所管理的证书执行续约操作。 如果需要略过证书续约操作,可以使用标志 --certificate-renewal=false1
2
3
4
5
6
7# 升级后查看证书到期时间
$ openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep ' Not '
# Not Before: Apr 21 06:20:12 2021 GMT
# Not After : Jul 21 08:32:57 2022 GMT
# 证书信息批量查询
$ for crt in $(find /etc/kubernetes/pki/ -name "*.crt"); do echo ${crt};openssl x509 -in $crt -noout -dates;echo; done
Step 7.Kuboard 来管理我们升级后的k8s集群1
2
3
4
5
6
7
8
9# 删除老旧版本
$ curl -k 'http://192.168.12.108:30567/kuboard-api/cluster/k8s-dev.weiyigeek/kind/KubernetesCluster/k8s-dev.weiyigeek/resource/installAgentToKubernetes?token=AflKbsicsKegFpNruDsxWspvTHHh2HnX' > kuboard-agent.yaml && kubectl delete -f ./kuboard-agent.yaml
# 部署新版本
$ curl -k 'http://192.168.12.108:30567/kuboard-api/cluster/k8s-dev.weiyigeek/kind/KubernetesCluster/k8s-dev.weiyigeek/resource/installAgentToKubernetes?token=K2vCJXf9ANrFjnrFbduNBxXusK3DhvIH' > kuboard-agent.yaml && kubectl apply -f ./kuboard-agent.yaml
$ kubectl get pods -n kuboard -l "k8s.kuboard.cn/name in (kuboard-agent, kuboard-agent-2)"
# NAME READY STATUS RESTARTS AGE
# kuboard-agent-2-5597754bdf-phks5 1/1 Running 0 3m59s
# kuboard-agent-769876b499-cr7f7 1/1 Running 0 3m59s
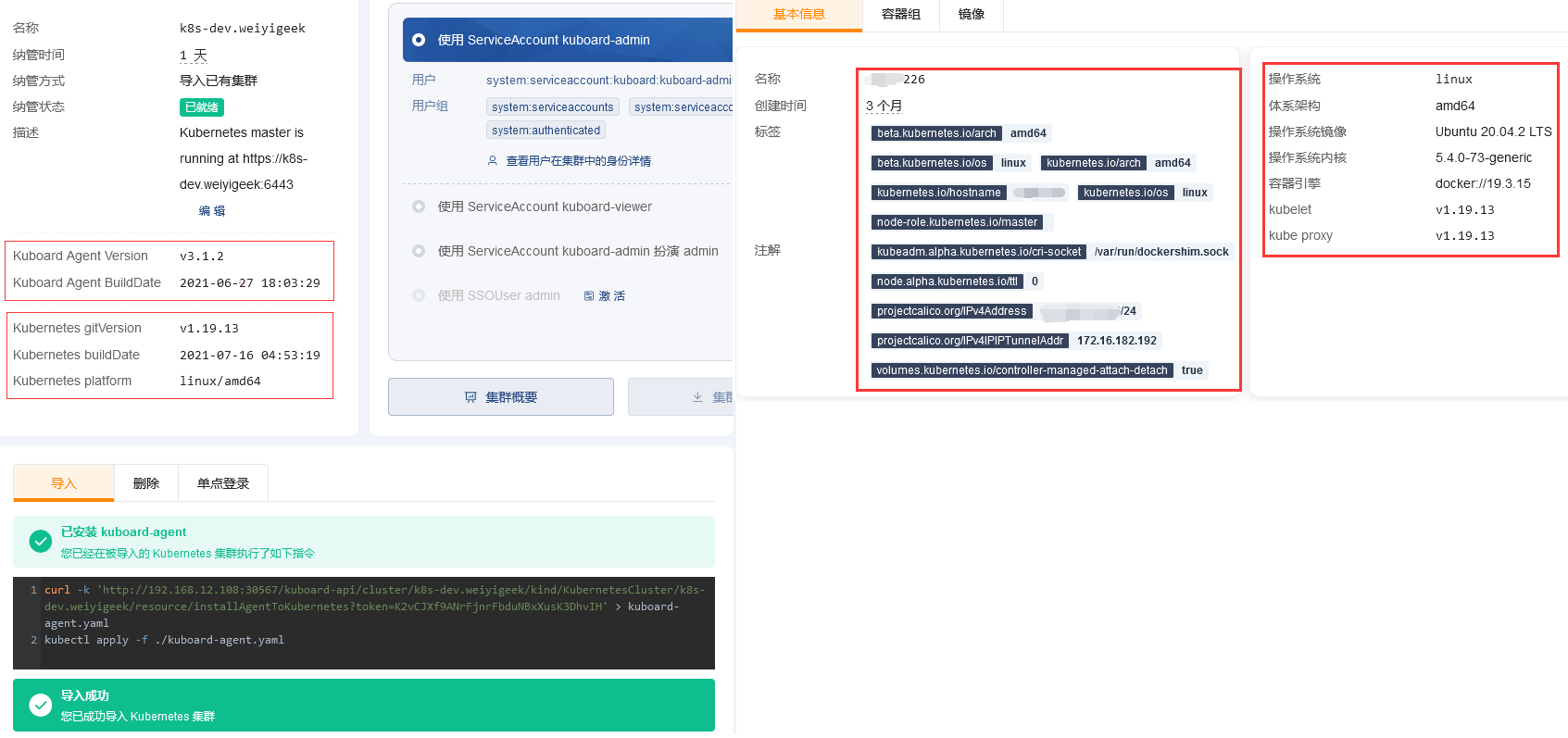
weiyigeek.top-Kuboard加入管理升级后k8s集群
描述: 本章节主要实践跨版本的升级,实践从v1.19.13集群版本升级至1.20主版本中可用的v1.20.9集群版本(与子版本升级差异不大),此处还是基于并采用的dockershim运行时,在下一章中我们将会把Kubernetes 集群从 dockershim 迁移到 Containerd.io 运行时。
环境说明:
升级前系统容器及其kubernetes集群相关版本:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# Container
操作系统 : linux
体系架构 : amd64
操作系统镜像 : Ubuntu 20.04.2 LTS
操作系统内核 : 5.4.0-73-generic
容器引擎 : docker://19.3.15
容器运行时 : containerd.io 1.4.4
# Kubernetes
cri-socket : /var/run/dockershim.sock
kubelet : v1.19.13
kubeadm : v1.19.13
kubectl : v1.19.13
kube proxy : v1.19.13
etcdctl version: 3.4.13
etcdctl API version: 3.4
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns : 1.7.0
registry.cn-hangzhou.aliyuncs.com/google_containers/pause : 3.2
2.1 第一步,同样是备份相关配置文件 (务必备份所有重要组件)。
备份kubernetes的etcd数据
1 | $ mkdir -vp /data/backup |
备份当前Kubernetes集群创建配置以及相关文件(集群信息、etcd配置、证书文件等)
1 | $ tar -zcf kubernetes-cluster-1.19.13.tar.gz /etc/kubernetes/* |
Tips : 务必备份所有重要组件,例如存储在数据库中应用层面的状态。
2.2 第二步,取消kubernetes相关软件包 held (使其可以升级)并升级到指定集群版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ apt-mark showhold
# kubeadm kubectl kubelet
$ apt-mark unhold kubeadm kubectl kubelet
# Canceled hold on kubeadm.
# Canceled hold on kubectl.
# Canceled hold on kubelet.
# 更新软件包索引以及锁定不进行更新,从 apt-get 1.1 版本起,你也可以使用下面的方法
$ apt update && \
apt-get install -y --allow-change-held-packages kubeadm=1.20.0-00 kubelet=1.20.0-00 kubectl=1.20.0-00 # 此处先下载1.20.x 第一个版本
$ apt-mark hold kubeadm kubectl kubelet
# 降级
# aptitude install kubeadm=1.20.0-00 kubelet=1.20.0-00 kubectl=1.20.0-00
# 验证下载操作的版本是否正常
$ kubeadm version # GitVersion:"v1.20.0"
# 封锁并释放节点以便重新调度工作负载(如果是负载节点还需设置drain污点)
$ kubectl cordon master-01
Tips : 注意此处为了成功迁移的兼容(可用性)我们先只下载v1.20.x 最初始 kubernetes 版本的各个组件版本(v1.20.x)
2.3 第三步, 验证升级计划(跨版本升级)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 此处跨版本升级的可用k8s集群是v1.20.9版本
$ kubeadm upgrade plan
# Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
# COMPONENT CURRENT AVAILABLE
# kubelet 1 x v1.20.0 v1.20.9
# Upgrade to the latest stable version:
# COMPONENT CURRENT AVAILABLE
# kube-apiserver v1.19.3 v1.20.9
# kube-controller-manager v1.19.3 v1.20.9
# kube-scheduler v1.19.3 v1.20.9
# kube-proxy v1.19.3 v1.20.9
# CoreDNS 1.7.0 1.7.0
# etcd 3.4.13-0 3.4.13-0
# 由上可以看出可用的版本为 v1.20.9 我们进行下载安装该版本的k8s相关组件
$ apt-get install -y --allow-change-held-packages kubeadm=1.20.9-00 kubelet=1.20.9-00 kubectl=1.20.9-00
$ kubelet --version
# Kubernetes v1.20.9
# 拉取 v1.20.9 版本的各个k8s组件
version=v1.20.9
for i in $(docker images -a | cut -d ' ' -f 1 | grep "google_containers/kube-");do
docker pull ${i}:${version}
done
2.4 第四步,同样我们需要准备集群创建配置文件,并升级到v1.20.9版本1
2
3
4
5
6
7
8
9# 导出旧集群配置文件
kubeadm config view > kubeadm-config-v1.20.9.yaml
# 将集群创建配置文件中 kubernetesVersion 对象 v1.19.13 改变为 v1.20.9
sed -i 's#1.19.13#1.20.9#g' kubeadm-config-v1.20.9.yaml
# 升级到v1.20.9版本 (v1.19.3 ==>>> v1.20.9)
kubeadm upgrade apply v1.20.9 --config kubeadm-config-v1.20.9.yaml
# upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.20.9". Enjoy!
2.5 第五步, 验证升级后的集群版本以及版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 取消静止调度恢复集群正常状态
$ kubectl uncordon master-01
$ kubectl cluster-info
# Kubernetes control plane is running at https://k8s-test.weiyigeek:6443
# KubeDNS is running at https://k8s-test.weiyigeek:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
$ kubectl get nodes -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# master-k8s Ready control-plane,master 93d v1.20.9 192.168.12.111 <none> Ubuntu 20.04.2 LTS 5.4.0-73-generic docker://19.3.14
$ kubectl get pods -n kube-system
# NAME READY STATUS RESTARTS AGE
# calico-kube-controllers-69496d8b75-pgrfj 1/1 Running 0 93d
# calico-node-fn4lf 1/1 Running 0 93d
# coredns-54d67798b7-7gc7x 1/1 Running 0 19m
# coredns-54d67798b7-nbf7b 1/1 Running 0 19m
# etcd-master-k8s 1/1 Running 0 21m
# kube-apiserver-master-k8s 1/1 Running 0 20m
# kube-controller-manager-master-k8s 1/1 Running 0 20m
# kube-proxy-ssdw5 1/1 Running 0 19m
# kube-scheduler-master-k8s 1/1 Running 0 20m
# metrics-server-77b878fdb-scdzx 1/1 Running 0 93d
至此集群版本升级成功。
描述: 自从 Kubernetes 1.20 宣布 弃用 dockershim, 不推荐使用对 Docker 的支持,并将在未来版本中删除。建议从 dockershim 迁移到其他替代的 Containerd.io 容器运行时, 但是各种问题可能也随之而来,比如对各类工作负载和 Kubernetes 在生产环境部署会产生什么影响。
Dockershim : Docker 的容器运行时接口 (CRI) shim 已被弃用。
Q: 为什么弃用 dockershim?
答: 维护 dockershim 已经成为 Kubernetes 维护者肩头一个沉重的负担, 创建 CRI 标准就是为了减轻这个负担,同时也可以增加不同容器运行时之间平滑的互操作性。此外与 dockershim 不兼容的一些特性,例如:控制组(cgoups)v2 和用户名字空间(user namespace),已经在新的 CRI 运行时中被实现。
Q: 人们总在谈论 OCI,那是什么?
答: OCI 代表开放容器标准, 它标准化了容器工具和底层实现(technologies)之间的大量接口。 他们维护了打包容器镜像(OCI image-spec)和运行容器(OCI runtime-spec)的标准规范。 他们还以 runc 的形式维护了一个 runtime-spec 的真实实现, 这也是 containerd 和 CRI-O 依赖的默认运行时。 CRI 建立在这些底层规范之上,为管理容器提供端到端的标准。
描述: 讲解你的集群把 Docker 用作容器运行时的运作机制,并提供使用 dockershim 时,它所扮演角色的详细信息, 继而展示了一组验证步骤,可用来检查弃用 dockershim 对你的工作负载的影响。
1.1 检查你的应用是否依赖于 Docker
判定你是否依赖于 Docker 的方法:
1.2 检查对比Docker依赖详解
容器运行时是一个软件,用来运行组成 Kubernetes Pod 的容器, 在每一个节点上 kubelet 使用抽象的容器运行时接口,所以你可以任意选用兼容的容器运行时。
在早期版本中 Kubernetes 提供的兼容性只支持一个容器运行时(Docker), 后续为了兼容更多的容器运行时设计出了CRI, 而 kubelet 亦开始支持 CRI。因为 Docker 在 CRI 规范创建之前就已经存在,此时k8s创建一个适配器组件dockershim (允许 kubelet 与 Docker交互) 就好像 Docker 是一个 CRI 兼容的运行时一样。
在1.20版本及其之后建议采用containerd运行时,此时我们将可以省去dockershim 和 docker这个中间商,并且遗留的容器可由 Containerd 这类容器运行时来运行和管理,操作体验也和以前一样。但是你不能再使用 docker ps 或 docker inspect 命令来获取容器信息。由于你不能列出容器,因此你不能获取日志、停止容器,甚至不能通过docker exec在容器中执行命令。
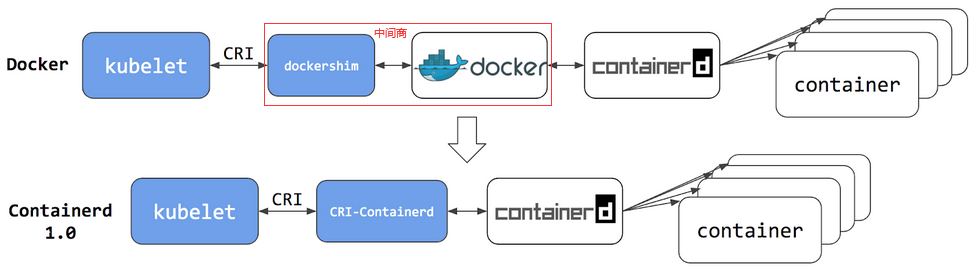
weiyigeek.top-DockerVSContainerd
1.3 识别依赖于 Docker 的 DaemonSet
描述: 如果某 Pod 想调用运行在节点上的 dockerd,该 Pod 必须满足以下两个条件之一:
举例来说:在 COS 镜像中,Docker 通过 /var/run/docker.sock 开放其 Unix 域套接字。 这意味着 Pod 的规约中需要包含 hostPath 卷以挂载 /var/run/docker.sock。
示例脚本: 用于查找包含直接映射 Docker 套接字的挂载点的 Pod。1
2
3kubectl get pods --all-namespaces \
-o=jsonpath='{range .items[*]}{"\n"}{.metadata.namespace}{":\t"}{.metadata.name}{":\t"}{range .spec.volumes[*]}{.hostPath.path}{", "}{end}{end}' \
| sort
Tips : 对于 Pod 来说,访问宿主机上的 Docker 还有其他方式。 例如可以挂载 /var/run 的父目录而非其完整路径 (就像这个例子), 上述脚本只检测最常见的使用方式。
1.4 弃用 Dockershim 的常见问题
Q: 在 Kubernetes 1.20 版本中,我还可以用 Docker 吗?
答: 当然可以, 在 1.20 版本中仅有的改变就是, 如果使用 Docker 运行时,启动 kubelet 的过程中将打印一条警告日志。
Q: 我现有的 Docker 镜像还能正常工作吗?
答: 当然可以, docker build 创建的镜像适用于任何 CRI 实现。所有你的现有镜像将和往常一样工作。
Q: 如何拉取私有镜像呢?
答: 当然可以, 所有 CRI 运行时均支持 Kubernetes 中相同的拉取 (pull) Secret 配置,不管是通过 PodSpec 还是通过 ServiceAccount 均可。
Q: 在生产系统中使用其他运行时的例子?
答:
containerd,CRI-O两个容器运行时是云原生基金会([CNCF])下的项目。例如:OpenShift 4.x 从 2019 年 6 月以来,就一直在生产环境中使用 CRI-O 运行时。
Q: 当切换 CRI 底层实现时,我应该注意什么?
答: Docker 和大多数 CRI(包括 containerd)的底层容器化代码是相同的,但其周边部分却存在一些不同。
- 日志配置
- 运行时的资源限制
- 直接访问 docker 命令或通过控制套接字调用 Docker 的节点供应脚本
- 需要访问 docker 命令或控制套接字的 kubectl 插件
- 需要直接访问 Docker 的 Kubernetes 工具, 例如:kube-imagepuller。
- 像 registry-mirrors 和不安全的注册表这类功能的配置
- 需要 Docker 保持可用、且运行在 Kubernetes 之外的,其他支持脚本或守护进程(例如:监视或安全代理)
- GPU 或特殊硬件,以及它们如何与你的运行时和 Kubernetes 集成
描述: 本章实践从dokcershim容器时(/var/run/dockershim.sock)迁移到containerd运行时(),并升级k8s集群v1.20.9到v1.21.3版本。
1 | # Container |
2.1 第一步,同样是备份相关配置文件 (务必备份所有重要组件)。
备份kubernetes的etcd数据
1 | $ mkdir -vp /data/backup |
备份当前Kubernetes集群创建配置以及相关文件(集群信息、etcd配置、证书文件等)
1 | $ tar -zcf kubernetes-cluster-1.19.13.tar.gz /etc/kubernetes/* |
Tips : 务必备份所有重要组件,例如存储在数据库中应用层面的状态
2.2 第二步,取消kubernetes相关软件包 held (使其可以升级)并升级到指定集群版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63# 更新软件包索引以及安装依赖的软件包
apt update && \
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
# - 添加Docker的官方GPG密钥为后续containerd.io 更新做准备
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# - 使用以下命令设置稳定存储库。要添加nightly或test存储库,请在下面的命令中的单词stable后面添加单词nightly或test(或两者)。
echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/container.list > /dev/null
# 查看是否有禁止软件自动更新安装的设置。
$ apt-mark showhold
# kubeadm kubectl kubelet
$ apt-mark unhold kubeadm kubectl kubelet
# Canceled hold on kubeadm.
# Canceled hold on kubectl.
# Canceled hold on kubelet.
# 锁定不进行更新,从 apt-get 1.1 版本起,你也可以使用下面的方法
# Tips : 注意此处为了成功迁移的兼容(可用性验证)我们先只下载`v1.21.x` 最初始 kubernetes 版本的各个组件版本(v1.21.x)
$ apt clean all && \
apt update && apt-get install -y --allow-change-held-packages kubeadm=1.21.0-00 kubelet=1.21.0-00 kubectl=1.21.0-00 # 此处先下载1.20.x 第一个版本
$ apt-mark hold kubeadm kubectl kubelet
# 验证可用的kubernetes版本以及组件的版本
kubeadm upgrade plan
# Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
# COMPONENT CURRENT TARGET
# kubelet 1 x v1.21.0 v1.21.3
# Upgrade to the latest stable version:
# COMPONENT CURRENT TARGET
# kube-apiserver v1.20.9 v1.21.3
# kube-controller-manager v1.20.9 v1.21.3
# kube-scheduler v1.20.9 v1.21.3
# kube-proxy v1.20.9 v1.21.3
# CoreDNS 1.7.0 v1.8.0 # 版本有变化需要重新拉取
# etcd 3.4.13-0 3.4.13-0
# 下载当前最新的版本组件(2021年7月23日 17:18:21)
apt update && apt-get install -y --allow-change-held-packages kubeadm=1.21.3-00 kubelet=1.21.3-00 kubectl=1.21.3-00
# 验证下载操作的版本是否正常
$ kubeadm version # GitVersion:"v1.21.3"
$ kubelet --version # Kubernetes v1.21.3
# 采用 docker 拉取 CoreDNS:v1.8.0 镜像
docker pull coredns/coredns:1.8.0
docker tag coredns/coredns:1.8.0 registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.0
# Tips : 使用cordon命令将标记 Master 节点主机为不可调度,等待迁移后再进行恢复;
kubectl cordon master-k8s
# Tips : 先采用dockershim更新到指定的 kubernetes 版本
kubeadm config view > kubeadm-config-v1.21.3.yaml && sed -i "s#v1.20.9#v1.21.3#g" kubeadm-config-v1.21.3.yaml
kubeadm upgrade apply v1.21.3 --config kubeadm-config-v1.21.3.yaml
Tips : 当集群升级成功后我们进行验证集群状态,待当kube-system名称空间中各组件都正常后(状态为Running),执行第三步。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16kubectl get nodes -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# master-k8s Ready control-plane,master 94d v1.21.3 192.168.12.111 Ubuntu 20.04.2 LTS 5.4.0-73-generic docker://19.3.15
kubectl get pod -n kube-system
# NAME READY STATUS RESTARTS AGE
# calico-kube-controllers-69496d8b75-pgrfj 1/1 Running 0 94d
# calico-node-fn4lf 1/1 Running 0 94d
# coredns-6f6b8cc4f6-gmpx8 1/1 Running 0 6m49s
# coredns-6f6b8cc4f6-j6lb4 1/1 Running 0 6m49s
# etcd-master-k8s 1/1 Running 0 133m
# kube-apiserver-master-k8s 1/1 Running 0 7m39s
# kube-controller-manager-master-k8s 1/1 Running 0 7m19s
# kube-proxy-6wrvs 1/1 Running 0 6m44s
# kube-scheduler-master-k8s 1/1 Running 0 7m4s
# metrics-server-77b878fdb-scdzx 1/1 Running 0 93d
2.3 第三步, 更新安装containerd.io及其配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# 备份 containerd 的 config.toml 配置文件
cp /etc/containerd/config.toml{,.bak}
# 查看当前版本以及可用的containerd版本
$ apt-cache madison containerd.io # 或者采用 apt-cache policy containerd.io
# containerd.io | 1.4.8-1 | https://download.docker.com/linux/ubuntu focal/stable amd64 Packages
# containerd.io | 1.4.6-1 | https://download.docker.com/linux/ubuntu focal/stable amd64 Packages
# containerd.io | 1.4.4-1 | https://download.docker.com/linux/ubuntu focal/stable amd64 Packages
# 此处可以按照kubernetes与containerd.io对应兼容版本进行选择,下面我指定了1.4.8-1版本的 containerd.io。
$ apt install -y containerd.io=1.4.8-1 # 升级containerd为指定版本
# 生成与修改 containerd 配置
containerd config default > /etc/containerd/config.toml
sed -i "s#k8s.gcr.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g" /etc/containerd/config.toml
sed -i '/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true' /etc/containerd/config.toml
sed -i "s#https://registry-1.docker.io#https://xlx9erfu.mirror.aliyuncs.com#g" /etc/containerd/config.toml
# 自动启动或启动 Containerd
systemctl daemon-reload
systemctl enable containerd && systemctl restart containerd
systemctl status containerd
# Jul 23 15:16:33 master-k8s systemd[1]: Started containerd container runtime.
# Jul 23 15:16:33 master-k8s containerd[1099972]: time="2021-07-23T15:16:33.539416544+08:00" level=info msg="Start event monitor"
# Jul 23 15:16:33 master-k8s containerd[1099972]: time="2021-07-23T15:16:33.539467558+08:00" level=info msg="Start snapshots syncer"
# Jul 23 15:16:33 master-k8s containerd[1099972]: time="2021-07-23T15:16:33.539482024+08:00" level=info msg="Start cni network conf syncer"
# Jul 23 15:16:33 master-k8s containerd[1099972]: time="2021-07-23T15:16:33.539490348+08:00" level=info msg="Start streaming server"
# 生成与修改 containerd 配置 crictl.yaml , 配置 crictl 工具
$ tee /etc/crictl.yaml <<'EOF'
runtime-endpoint: "unix:///run/containerd/containerd.sock"
image-endpoint: "unix:///run/containerd/containerd.sock"
timeout: 0
debug: false
EOF
# 采用 crictl 验证 cri 插件是否可用:
crictl pull docker.io/library/nginx:alpine
ctr -n k8s.io images ls | grep "nginx"
2.4 第四步, 验证v1.21.3集群所依赖的组件版本并利用containerd.io的ctr客户端命令行工具拉取新版本所需的镜像文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# 清空 ctr 中的所有镜像
# ctr -n k8s.io images remove $(ctr -n k8s.io images list -q)
$ kubeadm config images list --kubernetes-version=1.21.3 --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers -v 5
# registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.21.3
# registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.21.3
# registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.21.3
# registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.21.3
# registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.4.1
# registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0
# registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.0
# 手动需要单独下载的镜像
$ ctr -n k8s.io images pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
$ ctr -n k8s.io images pull docker.io/coredns/coredns:1.8.0
$ ctr -n k8s.io images tag docker.io/coredns/coredns:1.8.0 registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.0 # 更改镜像TAG名称
# registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.0
for i in $(kubeadm config images list --kubernetes-version=1.21.3 --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers -v 5);do
ctr -n k8s.io images pull ${i}
done
# 查看下载的镜像
$ ctr -n k8s.io images ls | grep "google_containers"
2.5 第五步,更改当前kubernetes集群的运行时
描述:编辑 /var/lib/kubelet/kubeadm-flags.env文件, 并将containerd运行时添加如下:1
2
3
4
5
6# kubeadm 集群启动参数配置
$ vim /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--network-plugin=cni --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock"
# 重载 systemd 并重启 kubelet 服务
systemctl daemon-reload && systemctl restart kubelet
2.6 第六步, 查看containerd与kubelet服务,并查看迁移为containerd后的集群状态1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44# 查看 containerd.service kubelet.service 服务状态
$ systemctl status containerd.service kubelet.service
# docker 运行的容器在moby名称空间之中
ctr -n moby c ls
# CONTAINER IMAGE RUNTIME
# 1cd434f886a25798f41fbb5986a64a33e98d70d51c08f5e1e368603dad6b6c35 - io.containerd.runtime.v1.linux
# 262633d2cabd7e53190d0bc57f03823d12798c84e5e76a934e42cbcaa6ea12d3 - io.containerd.runtime.v1.linux
# 3be8bd11443ffa7f2b4f76e50495b451179cdd637786a9c7623167906e086d7b - io.containerd.runtime.v1.linux
# 重启机器
$ reboot
# 节点维护完后取消禁止调度,集群此时应该恢复为正常
$ kubectl uncordon master-k8s
# 验证 kubernetes 集群状态
$ kubectl get node -o wide
# NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
# master-k8s Ready control-plane,master 94d v1.21.3 192.168.12.111 Ubuntu 20.04.2 LTS 5.4.0-80-generic containerd://1.4.8
# 验证 kube-system 名称空间中各个 Pods 状态
$ kubectl -n kube-system get pods
# NAME READY STATUS RESTARTS AGE
# calico-kube-controllers-69496d8b75-pgrfj 1/1 Running 1 94d
# calico-node-fn4lf 1/1 Running 24 94d
# coredns-6f6b8cc4f6-2l86r 1/1 Running 1 50m
# coredns-6f6b8cc4f6-l6k4s 1/1 Running 1 50m
# etcd-master-k8s 1/1 Running 22 47m
# kube-apiserver-master-k8s 1/1 Running 26 5h48m
# kube-controller-manager-master-k8s 1/1 Running 26 5h48m
# kube-proxy-6wrvs 1/1 Running 1 5h47m
# kube-scheduler-master-k8s 1/1 Running 26 4h44m
# metrics-server-77b878fdb-scdzx 1/1 Running 2 93d
# 此时再观察moby名称空间的容器已发现没有任何运行的容器
ctr -n moby c ls
# CONTAINER IMAGE RUNTIME
# 可以在k8s.io名称空间中查看运行的容器。
ctr -n k8s.io c ls
# CONTAINER IMAGE RUNTIME
# 05f0436d528550d46227da26a5ae7539439c4dea44d3840ef5ddfdba0f718d07 registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 io.containerd.runc.v2
......
2.7 第七步,在kuboard将该kubernetes单节点加入到其中进行管理,并查看相应的信息1
2
3
4
5# kuboard k8s集群管理管理运行 agent 的 Pod 状态
kubectl -n kuboard get pods
# NAME READY STATUS RESTARTS AGE
# kuboard-agent-2-576457f758-m2mts 1/1 Running 0 46s
# kuboard-agent-dbd689678-dgn7q 1/1 Running 0 46s
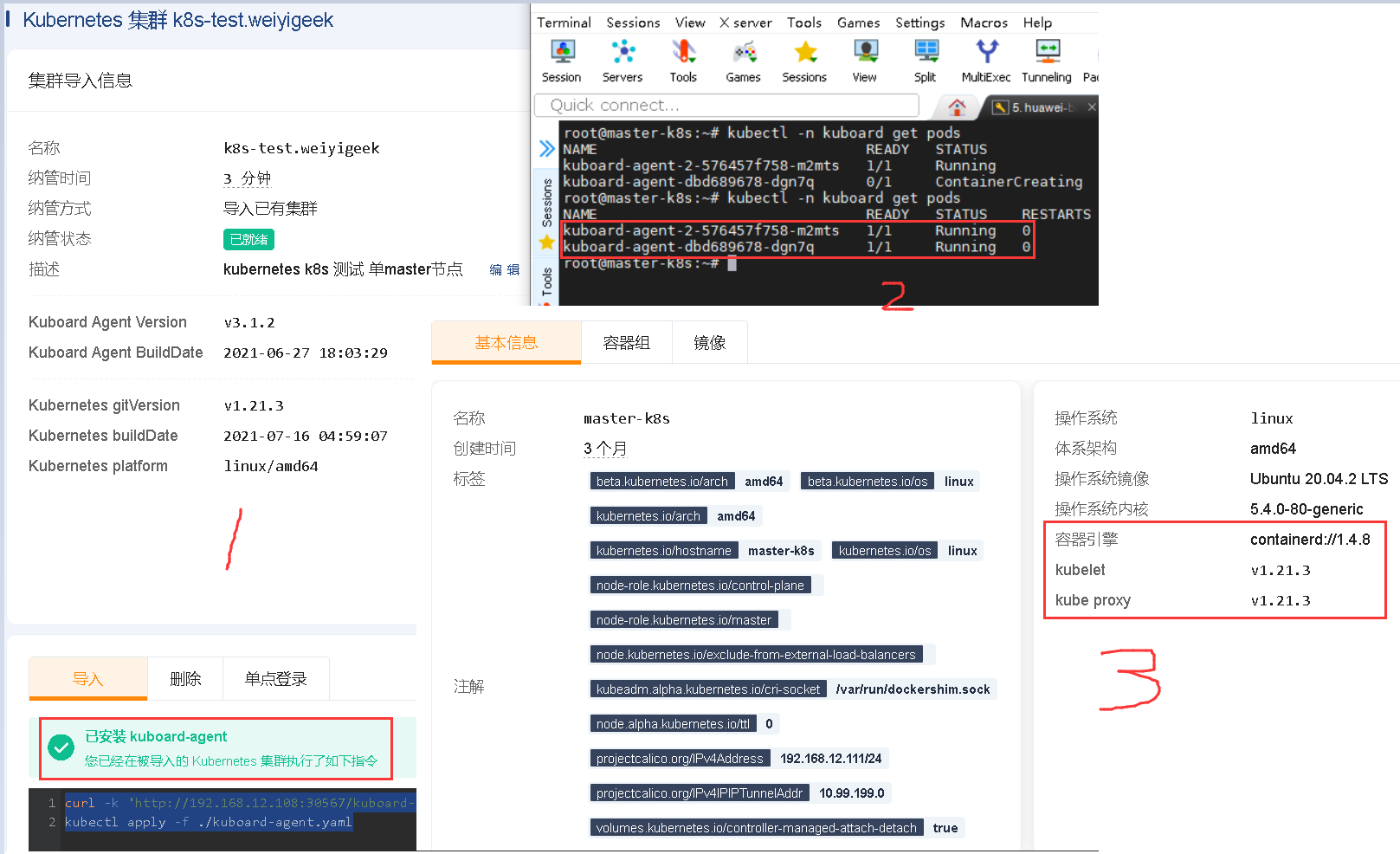
weiyigeek.top-kuboard管理k8s集群
Tips : kubernetes 集群升级其实流程大致相同,不同点在于先升级一部分工作节点,然后在升级一台Master节点,等待正常后,再升级后续节点。1
2
3
4
5
6
7# (1) 将节点为可调度状态和非可调度状态
kubectl cordon master-01
kubectl uncordon master-01
# (2) 驱逐节点与恢复节点
kubectl drain master-01 --ignore-daemonsets --delete-local-data --force
kubectl undrain master-01
3.1 第一步, 准备资源清单部署指定应用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60tee nginx-deployment.yaml <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-deploy
namespace: weiyigeek
spec:
replicas: 2
selector:
matchLabels:
app: nginx-test
template:
metadata:
labels:
app: nginx-test
spec:
initContainers:
- name: init-html
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ['sh', '-c', "echo environment;env;echo NginxWeb-v${VERSION}-${HOSTNAME} > /usr/share/nginx/html/index.html"]
env:
- name: "VERSION"
value: "1.23.1"
volumeMounts:
- name: web
mountPath: "/usr/share/nginx/html"
securityContext:
privileged: true
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: web
mountPath: "/usr/share/nginx/html"
volumes:
- name: web
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: weiyigeek
labels:
app: nginx-test
spec:
type: NodePort
ports:
- name: nginx
port: 80
targetPort: 80
nodePort: 30000
protocol: TCP
selector:
app: nginx-test
EOF
3.2 第二步, 利用资源清单进行部署并查看验证1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# (1) 利用 kubectl apply 部署 deployment 控制器
kubectl create ns weiyigeek
kubectl apply -f nginx-deployment.yaml
# deployment.apps/web-deploy created
# service/nginx-service created
# (2) 查看状态的nginx的pod与svc
kubectl -n weiyigeek get pod,svc -o wide
# NAME READY STATUS RESTARTS AGE IP NODE
# web-deploy-5865b8d579-8l2r5 1/1 Running 0 20s 10.99.199.52 master-k8s
# web-deploy-5865b8d579-hbvfm 1/1 Running 0 23s 10.99.199.51 master-k8s
kubectl -n weiyigeek get -o wide
# NAME TYPE CLUSTER-IP PORT(S) AGE SELECTOR
# nginx-service NodePort 10.103.63.67 80:30000/TCP 3m27s app=nginx-test
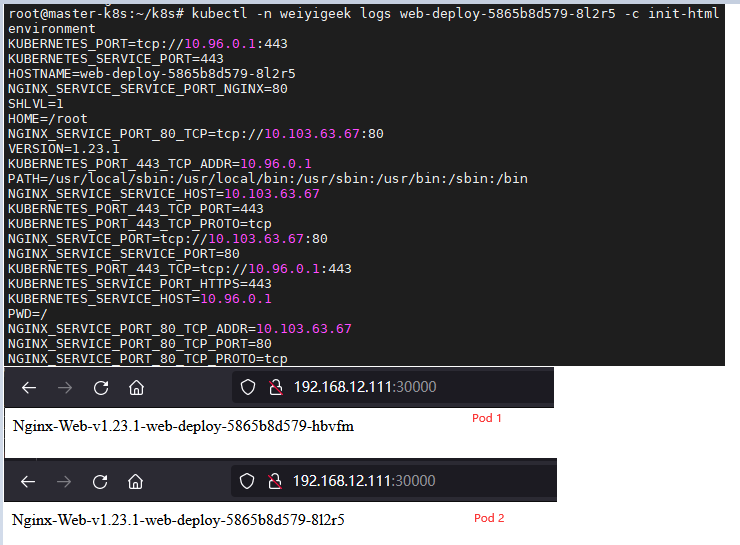
weiyigeek.top-nginx-deployment
至此 kubernetes 从 dockershim 运行时,迁移到 containerd.io 完毕。
1 | # 镜像拉取时 |
1 | # 排除网络情况后执行如下命令拉取镜像并更改名称 |
kubelet Back-off restarting failed container错误1 | $ kubectl -n kube-system describe pods etcd-master-k8s |
1 | $ kubectl -n kube-system logs etcd-master-k8s |
1 | $ ctr -n k8s.io i ls -q | grep "google_containers/etcd:3.4.13-0" |
Error syncing pod, skipping" err="failed to \"StartContainer\" for \"kuboard-agent\" with CrashLoopBackOff: \"back-off 10s restarting failed错误。1 | systemctl status kubelet |
KUBELET_POD_INFRA_CONTAINER 配置项配置如下1 | # 编辑 kubeadm-flags.env 文件进行修改 |
containernetworking-plugins conflicts with kubernetes-cni 错误1 | Selecting previously unselected package kubernetes-cni. |
https://github.com/containers/podman/issues/52961 | # podman 服务停止 |
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/虚拟云容/云容器/Kubernetes/17-Kubernetes进阶之集群升级迁移和维护实践.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2021/2-27-574.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议