[TOC]
0x00 前言简述 0.学习导读 Q: 什么是监控?
1.告警: 掌握故障的发生时间并通知相应人员(监控的重要目标)。
Q: 监控采集数据存储量优化解决方案?
1.剖析: 在无法提供事件的完整上下文时,可以截取某一段有限时间内的上下文作为剖析对象。(主要用作计算调试)
Q: 日志分类说明?
1.事务日志: 关键业务记录需要永久保存,主要涉及金钱和面向用户的关键性功能。
1.开源监控系统简史 描述: 下面列举出比较常用的开源监控系统Nagios ['negos']、Cacti 英 [ˈkæktaɪ]、Ganglia 英 [ˈgæŋglɪə]、Zabbix、Openfalcon、Prometheus
监控软件发展历史简述:
1994 年 - MRTG 1.0 由 Tobias Oetiker 编写主要是通过SNMP协议来监控网络。
1996 年 - NetSaint 由 Ethan Galstad 创建的作为一个MS-DOS应用来执行ping命令
1997 年 - MRTG 1.0 改进而来采用C进行重写并创造了用于存储指标数据的RRD(Round Robin Database)。
2002 年 - Nagios 由 NetSaint 重命名
2006 年 - Graphite 使用与 RRD 类似的设计的Whisper来做指标数的存储。(其本身不会收集数据而是将数据发送给收集工具)
cacti : 一套基于PHP,MySQL,SNMP及RRDTool开发的网络流量监测图形分析工具。
2012 年 - zabbix 发布 2.x 版本,基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。
2012 年 - Prometheus 由Sound Cloud开发者进行维护开发后2016年加入到CNCF成为了第二个成员。
Nagios
优点:通过安装插件和编写监控脚本,可以实现对目标灵活的监控
缺点:无法查询历史数据
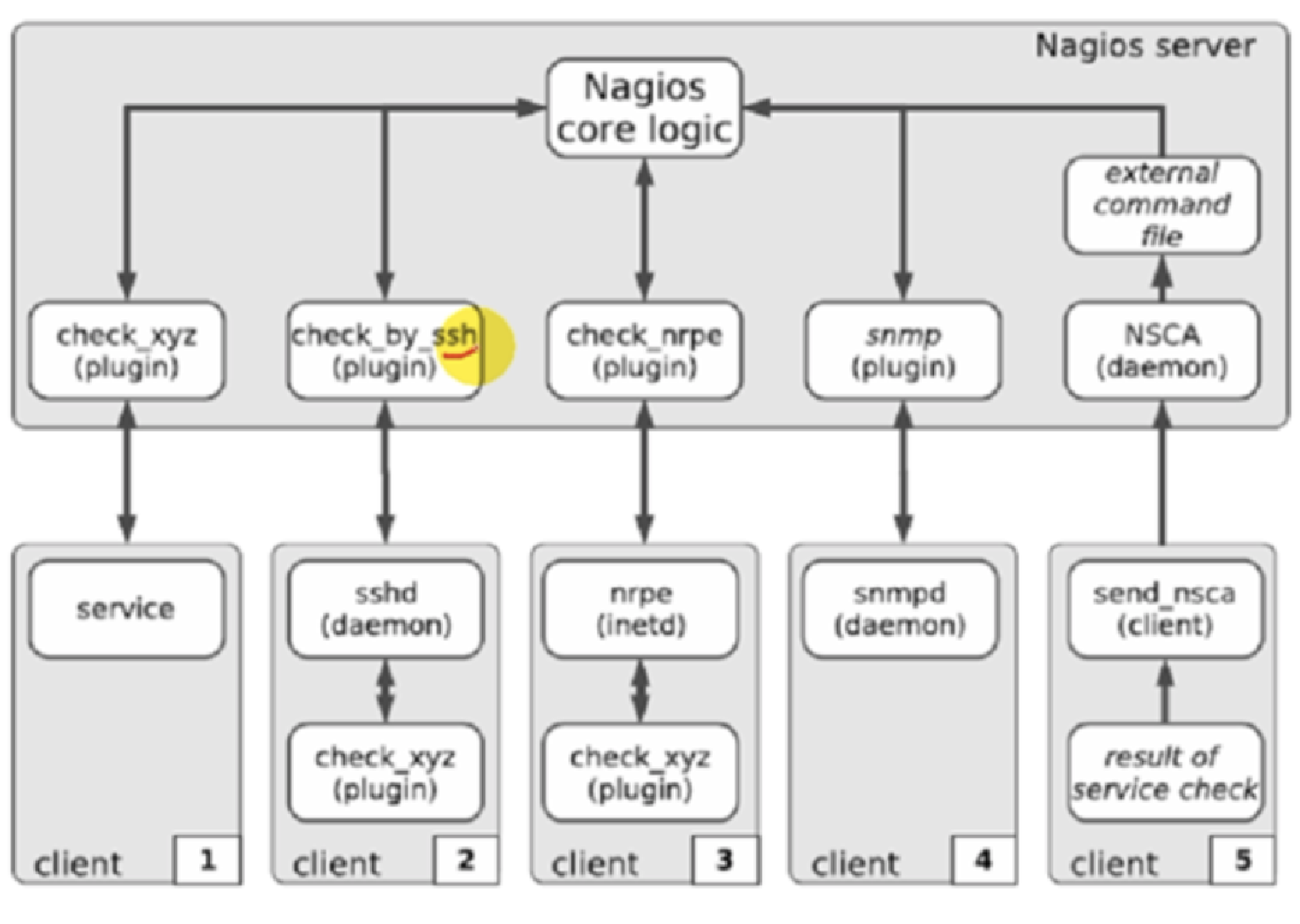
weiyigeek.top-Nagios架构
Cacti php/mysql/snmp及rrdtool开发的网络流量监测图形分析工具
优点:机房、流量监控方面应用较广泛
缺点:报警比较简陋
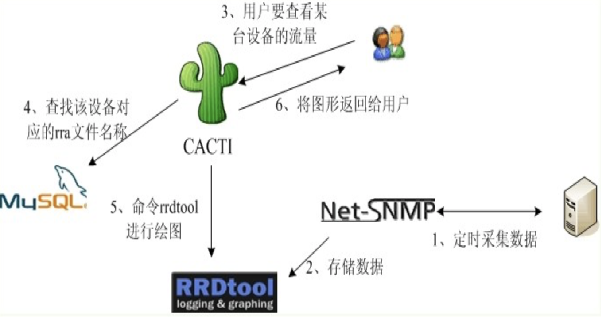
weiyigeek.top-Catic架构
Ganglia
优点:部署方便,用不同分层管理上万台机器,无需逐个添加配置;ganglia服务端能通过一台客户端收集到同一个网段的所有客户端的数据;ganglia集群服务端能够通过一台服务端收集到它下属的所有客户端数据。
缺点:没有内置的消息系统,无法报警
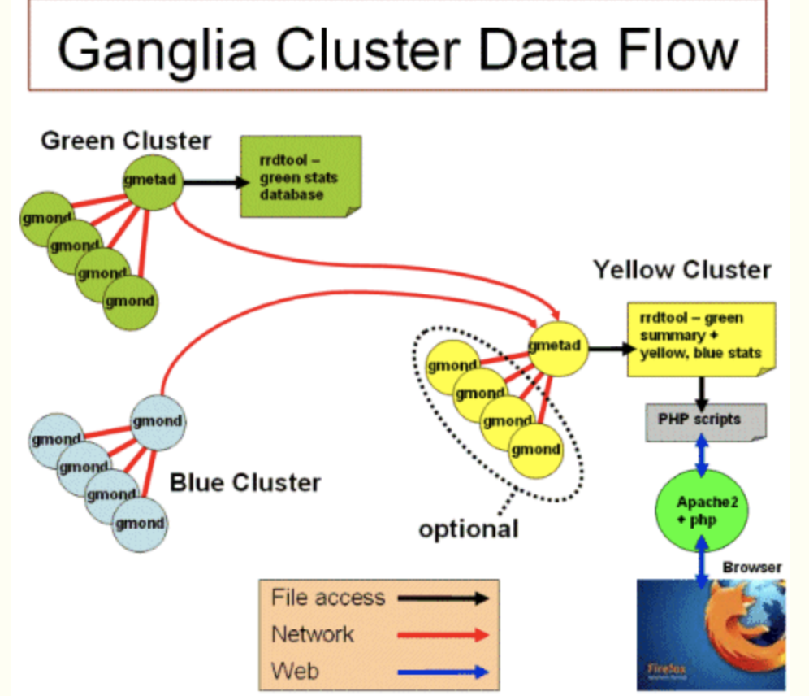
weiyigeek.top-Ganglia架构
Openfalcon (企业使用较多)。
优点: 支持多种方式报警,且会对警告进行合并处理,不会进行短信轰炸。
缺点: 社区支持不完善、基础软件监控不支持
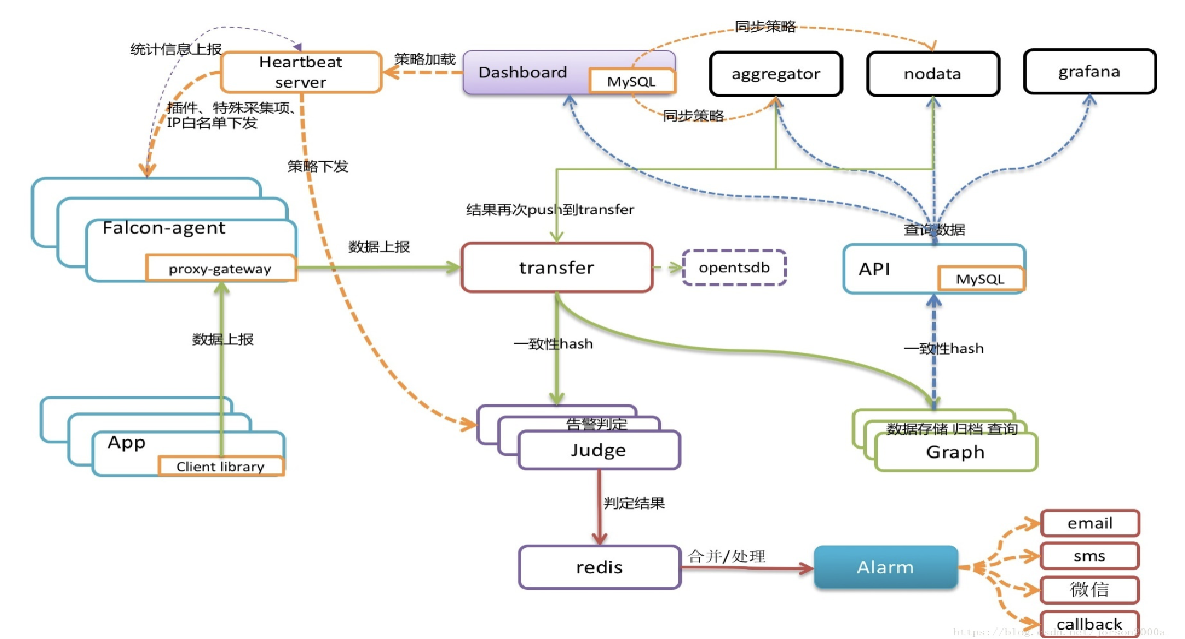
weiyigeek.top-OpenFalcon
Zabbix (个人、企业使用较多)。
优点: 使用成本低安装部署简单,百分之95%的功能都可以在Web UI界面上进行操作,主机监控添加方便。
缺点: 自定义监控脚本编写复杂
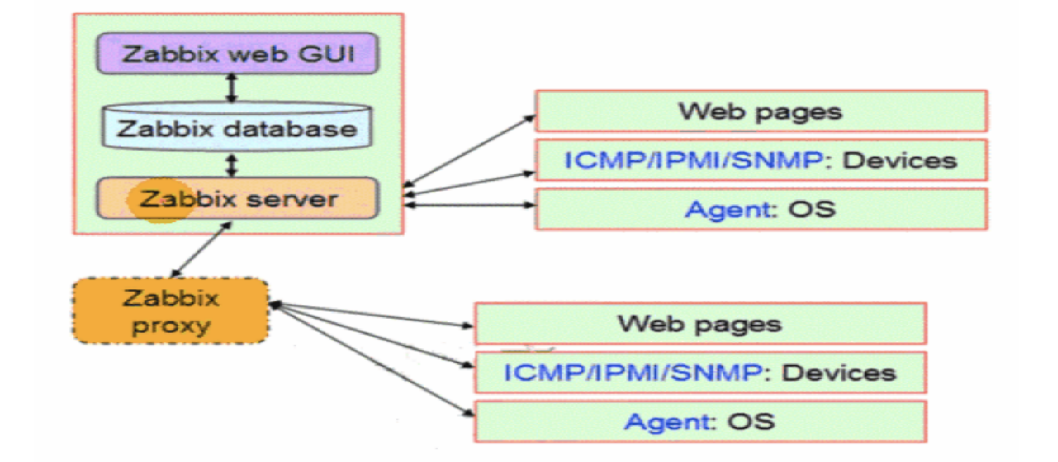
weiyigeek.top-Zabbix架构
Why use Prometheus?
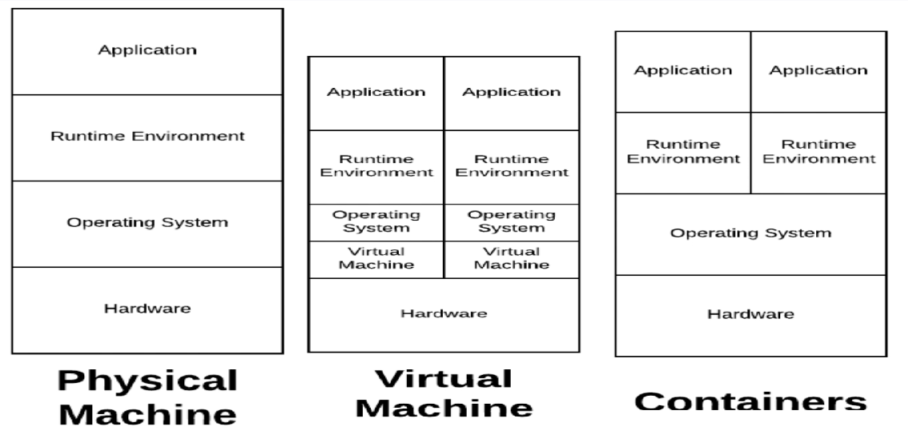
1.最初人们直接使用物理机,将进程直接跑在物理机上面
2.后来人们开始在物理机中进行虚拟化来安装多台虚拟机例如(VMware/kvm)
从监控角度来讲:相对比较复杂,我们要知道哪台机器上跑了哪些虚拟机,同时还要知道每个虚拟机里面跑了什么程序
3.最后由于docker容器的出现进行了,翻起了新一轮的技术革命。
从监控角度来讲:监控起来复杂度非常高,我们要知道每台机器上跑了哪些docker,和每个docker的资源使用情况,(很难用静态方法去监控)
4.现在由于云环境的火热常采用 Kubernetes 对 Docker 容器进行编排,极大的提高了运维效率;
从监控角度来讲:Prometheus是在Kubernetes孕育而来,在原生支持上面提到的各种工具的监控。
weiyigeek.top-基础环境
总结说明:
Prometheus并不是最好的监控系统,它不适用于存储事件日志或者单一的事件以及敏感信息采集,选择它的主要原因是他对云环境的原生支持;
Promethus 专门运行监控而设计存在由于某些因素(例如内核调度和抓取故障)导致一些数据不准确和资源竞争的现象,即并不能保证数据的绝对准确性。
恰好现在云环境是当前最火,应用最广泛的解决方案;
监控是应用于服务的,不同的服务场景选择不同的监控软件,切勿盲从;
2.Prometheus 基础简介 简介: Prometheus 是一个开源的云原生基于指标的监控系统以及告警系统,泛义上包括监控,告警,时序数据库(TSDB),各种指标收集器(Exporter)组成。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控, 所以它主要用于容器监控和k8s集群监控以及云环境的监控(OpenStack)。
2016年 Prometheus 加入了云原生计算基金会(Cloud Native Computing Foundation,CNCF),成为kubernetes之后的第二个托管项目 google SRE 的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。
官网介绍: 从度量到洞察使用领先的开源监控解决方案。
Dimensional data (高维数据) : Prometheus implements a highly dimensional data model. Time series are identified by a metric name and a set of key-value pairs.
Powerful queries (强大的查询) : PromQL allows slicing and dicing of collected time series data in order to generate ad-hoc graphs, tables, and alerts.
Great visualization (UI-视觉效果) : Prometheus has multiple modes for visualizing data: a built-in expression browser, Grafana integration, and a console template language.
Efficient storage (高效的存储) : Prometheus stores time series in memory and on local disk in an efficient custom format. Scaling is achieved by functional sharding and federation.
Simple operation (操作简单) : Each server is independent for reliability, relying only on local storage. Written in Go, all binaries are statically linked and easy to deploy.
Precise alerting (精确报警) :
Many client libraries (众多客户端库) : Client libraries allow easy instrumentation of services. Over ten languages are supported already and custom libraries are easy to implement.
Many integrations (许多集成监控指标) : Existing exporters allow bridging of third-party data into Prometheus. Examples: system statistics, as well as Docker, HAProxy, StatsD, and JMX metrics.
优点说明:
定制化难度低,后端采用Go语言开发、前端可用Grafana直接进行Json编辑
开箱即用的各种服务发现机制,可以自动发现监控端点
专为监控指标数据设计的高性能时序数据库TSDB ,单机单实例支持数十万监控项/每秒
强大易用的查询语言PromQL 以及丰富的聚合函数 便于对已有数据进行新的聚合
生态完善有各种现成的开源Exporter实现,自定义的监控指标也非常简单
配置灵活的告警规则,支持告警分组、抑制、静默、路由 等等高级功能
高可用的架构核心组件都有高可用解决方案
强大的功能除了云平台之外还支持主机、各种db资源、web网站、dns、网络延时、端口连通性、各种语言写的程序监控等等
成熟的社区和健全的生态
缺点说明:
安装相对复杂、监控、告警和界面都分属于不同的组件。
没有任何监控告警之外的功能(用户/角色/权限控制等等),需要多配置必须在配置文件中修改。
通过 HTTP 拉取监控数据效率不够高
Tips: 保有量最多的三种监控系统(Zabbix、Openfalcon、Promethes)方式对比;
weiyigeek.top-三者对比
3.Prometheus 架构组件 描述: Prometheus 架构由客户端在被监控系统上利用导出器采集指标数据,在服务端配置静态目标或者动态的服务发现,此时Prometheus 根据抓取频率进行数据的拉取(exporter)和推送(pushgateway), 然后将抓取的数据存储到时序数据库(TSDB)之中,再利用Grafana的仪表盘展示Prometheus服务中的数据,同时设定记录规则(PromQL表达式)和告警规则(频率)并发送给alertmanager进行发送报警事件到运维人员手中,最终可能还需要进行数据的持久化默认的是本地存储但可以通过远程读写的API让其他系统也可接入采集存储数据。
Prometheus 架构
Prometheus 监控体系如下图几大部分构成:
1.Prometheus server : 主要负责数据采集和存储,提供PromQL查询语言的支持 (默认端口: 9090)
2.exporters : 监控指标采集器,支持数据库、硬件、消息中间件、http 服务器、jmx 等 (默认端口:)
3.alertmanager : 用来进行报警、prometheus_cli:命令行工具 (默认端口: 9093)
4.Web UI : 原生UI功能较为单一,常常采用Grafana这个跨平台的开源的分析和可视化工具 (默认端口: 3000)
5.PushGateWay : 跨网段被监控主机指标采集数据转发到网关代理等待Server的Pull。
6.Time Series DataBase : 时序数据库(TSDB)用于保存时间序列(按时间顺序变化)的数据,每条记录都有完整的时间戳,基于时间的操作都比较方便.
Q:采用时序数据库(TSDB)的优点?
1.时间作为他的主轴,数据按顺序到达。
2.大多数操作是插入新数据,偶尔伴随查询,更新数据比较少。
3.时间序列数据累计速度非常快,更高的容纳率、更快的大规模查询以及更好的数据压缩。
4.TSDB 通常还包括一些共通的对时间序列数据分析的功能和操作:数据保留策略、连续查询、灵活的时间聚合等。
Q:什么是微服务架构?
他的组件是可以独立工作的,每个组件都不依赖其他的组件
配置文件来将不同的模块关联到一起,实现整个监控的功能
4.Prometheus 基本原理 描述: Prometheus 基本工作流程步骤如下:
Setp 1.Prometheus Server 读取配置解析静态监控端点(static_configs),以及服务发现规则(xxx_sd_configs)自动收集需要监控的端点
Setp 2.Prometheus Server 周期刮取(scrape_interval)监控端点通过HTTP的Pull方式采集监控数据
Step 3.Prometheus Server HTTP 请求到达 Node Exporter,Exporter 返回一个文本响应,每个非注释行包含一条完整的时序数据:Name + Labels + Samples(一个浮点数和一个时间戳构成), 数据来源是一些官方的exporter或自定义sdk或接口;
weiyigeek.top-Exporter-Metrics
Step 4.Prometheus Server 收到响应,Relabel处理之后(relabel_configs)将其存储在TSDB中并建立倒排索引
Step 5.Prometheus Server 另一个周期计算任务(evaluation_interval)开始执行,根据配置的Rules逐个计算与设置的阈值进行匹配,若结果超过阈值并持续时长超过临界点将进行报警,此时发送Alert到AlertManager独立组件中。
Step 6.AlertManager 收到告警请求,根据配置的策略决定是否需要触发告警,如需告警则根据配置的路由链路依次发送告警,比如邮件、微信、Slack、PagerDuty、WebHook等等。
Step 7.当通过界面或HTTP调用查询时序数据利用PromQL表达式查询,Prometheus Server 处理过滤完之后返回瞬时向量(Instant vector, N条只有一个Sample的时序数据),区间向量(Range vector,N条包含M个Sample的时序数据),或标量数据 (Scalar, 一个浮点数)
Step 8.采用Grafana开源的分析和可视化工具进行数据的图形化展示。
weiyigeek.top-Grafana
5.Prometheus 数据模型和类型 描述: metrics name & label 指标名称和标签(key=value)的形式组成的数据模型,其次是Prometheus惯例是使用基本单元如字节(Byte)和秒(s);
metrics name : 一般由字母和下划线构成 prometheus_http_requests_total(应用名称=name_监测对像=object_数值类型=int_单位=ok)。
基础示例:
[TOC]
0x00 前言简述 0.学习导读 Q: 什么是监控?
1.告警: 掌握故障的发生时间并通知相应人员(监控的重要目标)。
Q: 监控采集数据存储量优化解决方案?
1.剖析: 在无法提供事件的完整上下文时,可以截取某一段有限时间内的上下文作为剖析对象。(主要用作计算调试)
Q: 日志分类说明?
1.事务日志: 关键业务记录需要永久保存,主要涉及金钱和面向用户的关键性功能。
1.开源监控系统简史 描述: 下面列举出比较常用的开源监控系统Nagios ['negos']、Cacti 英 [ˈkæktaɪ]、Ganglia 英 [ˈgæŋglɪə]、Zabbix、Openfalcon、Prometheus
监控软件发展历史简述:
1994 年 - MRTG 1.0 由 Tobias Oetiker 编写主要是通过SNMP协议来监控网络。
1996 年 - NetSaint 由 Ethan Galstad 创建的作为一个MS-DOS应用来执行ping命令
1997 年 - MRTG 1.0 改进而来采用C进行重写并创造了用于存储指标数据的RRD(Round Robin Database)。
2002 年 - Nagios 由 NetSaint 重命名
2006 年 - Graphite 使用与 RRD 类似的设计的Whisper来做指标数的存储。(其本身不会收集数据而是将数据发送给收集工具)
cacti : 一套基于PHP,MySQL,SNMP及RRDTool开发的网络流量监测图形分析工具。
2012 年 - zabbix 发布 2.x 版本,基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。
2012 年 - Prometheus 由Sound Cloud开发者进行维护开发后2016年加入到CNCF成为了第二个成员。
Nagios
优点:通过安装插件和编写监控脚本,可以实现对目标灵活的监控
缺点:无法查询历史数据
weiyigeek.top-Nagios架构
Cacti php/mysql/snmp及rrdtool开发的网络流量监测图形分析工具
优点:机房、流量监控方面应用较广泛
缺点:报警比较简陋
weiyigeek.top-Catic架构
Ganglia
优点:部署方便,用不同分层管理上万台机器,无需逐个添加配置;ganglia服务端能通过一台客户端收集到同一个网段的所有客户端的数据;ganglia集群服务端能够通过一台服务端收集到它下属的所有客户端数据。
缺点:没有内置的消息系统,无法报警
weiyigeek.top-Ganglia架构
Openfalcon (企业使用较多)。
优点: 支持多种方式报警,且会对警告进行合并处理,不会进行短信轰炸。
缺点: 社区支持不完善、基础软件监控不支持
weiyigeek.top-OpenFalcon
Zabbix (个人、企业使用较多)。
优点: 使用成本低安装部署简单,百分之95%的功能都可以在Web UI界面上进行操作,主机监控添加方便。
缺点: 自定义监控脚本编写复杂
weiyigeek.top-Zabbix架构
Why use Prometheus?
1.最初人们直接使用物理机,将进程直接跑在物理机上面
2.后来人们开始在物理机中进行虚拟化来安装多台虚拟机例如(VMware/kvm)
从监控角度来讲:相对比较复杂,我们要知道哪台机器上跑了哪些虚拟机,同时还要知道每个虚拟机里面跑了什么程序
3.最后由于docker容器的出现进行了,翻起了新一轮的技术革命。
从监控角度来讲:监控起来复杂度非常高,我们要知道每台机器上跑了哪些docker,和每个docker的资源使用情况,(很难用静态方法去监控)
4.现在由于云环境的火热常采用 Kubernetes 对 Docker 容器进行编排,极大的提高了运维效率;
从监控角度来讲:Prometheus是在Kubernetes孕育而来,在原生支持上面提到的各种工具的监控。
weiyigeek.top-基础环境
总结说明:
Prometheus并不是最好的监控系统,它不适用于存储事件日志或者单一的事件以及敏感信息采集,选择它的主要原因是他对云环境的原生支持;
Promethus 专门运行监控而设计存在由于某些因素(例如内核调度和抓取故障)导致一些数据不准确和资源竞争的现象,即并不能保证数据的绝对准确性。
恰好现在云环境是当前最火,应用最广泛的解决方案;
监控是应用于服务的,不同的服务场景选择不同的监控软件,切勿盲从;
2.Prometheus 基础简介 简介: Prometheus 是一个开源的云原生基于指标的监控系统以及告警系统,泛义上包括监控,告警,时序数据库(TSDB),各种指标收集器(Exporter)组成。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控, 所以它主要用于容器监控和k8s集群监控以及云环境的监控(OpenStack)。
2016年 Prometheus 加入了云原生计算基金会(Cloud Native Computing Foundation,CNCF),成为kubernetes之后的第二个托管项目 google SRE 的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。
官网介绍: 从度量到洞察使用领先的开源监控解决方案。
Dimensional data (高维数据) : Prometheus implements a highly dimensional data model. Time series are identified by a metric name and a set of key-value pairs.
Powerful queries (强大的查询) : PromQL allows slicing and dicing of collected time series data in order to generate ad-hoc graphs, tables, and alerts.
Great visualization (UI-视觉效果) : Prometheus has multiple modes for visualizing data: a built-in expression browser, Grafana integration, and a console template language.
Efficient storage (高效的存储) : Prometheus stores time series in memory and on local disk in an efficient custom format. Scaling is achieved by functional sharding and federation.
Simple operation (操作简单) : Each server is independent for reliability, relying only on local storage. Written in Go, all binaries are statically linked and easy to deploy.
Precise alerting (精确报警) :
Many client libraries (众多客户端库) : Client libraries allow easy instrumentation of services. Over ten languages are supported already and custom libraries are easy to implement.
Many integrations (许多集成监控指标) : Existing exporters allow bridging of third-party data into Prometheus. Examples: system statistics, as well as Docker, HAProxy, StatsD, and JMX metrics.
优点说明:
定制化难度低,后端采用Go语言开发、前端可用Grafana直接进行Json编辑
开箱即用的各种服务发现机制,可以自动发现监控端点
专为监控指标数据设计的高性能时序数据库TSDB ,单机单实例支持数十万监控项/每秒
强大易用的查询语言PromQL 以及丰富的聚合函数 便于对已有数据进行新的聚合
生态完善有各种现成的开源Exporter实现,自定义的监控指标也非常简单
配置灵活的告警规则,支持告警分组、抑制、静默、路由 等等高级功能
高可用的架构核心组件都有高可用解决方案
强大的功能除了云平台之外还支持主机、各种db资源、web网站、dns、网络延时、端口连通性、各种语言写的程序监控等等
成熟的社区和健全的生态
缺点说明:
安装相对复杂、监控、告警和界面都分属于不同的组件。
没有任何监控告警之外的功能(用户/角色/权限控制等等),需要多配置必须在配置文件中修改。
通过 HTTP 拉取监控数据效率不够高
Tips: 保有量最多的三种监控系统(Zabbix、Openfalcon、Promethes)方式对比;
weiyigeek.top-三者对比
3.Prometheus 架构组件 描述: Prometheus 架构由客户端在被监控系统上利用导出器采集指标数据,在服务端配置静态目标或者动态的服务发现,此时Prometheus 根据抓取频率进行数据的拉取(exporter)和推送(pushgateway), 然后将抓取的数据存储到时序数据库(TSDB)之中,再利用Grafana的仪表盘展示Prometheus服务中的数据,同时设定记录规则(PromQL表达式)和告警规则(频率)并发送给alertmanager进行发送报警事件到运维人员手中,最终可能还需要进行数据的持久化默认的是本地存储但可以通过远程读写的API让其他系统也可接入采集存储数据。
Prometheus 架构
Prometheus 监控体系如下图几大部分构成:
1.Prometheus server : 主要负责数据采集和存储,提供PromQL查询语言的支持 (默认端口: 9090)
2.exporters : 监控指标采集器,支持数据库、硬件、消息中间件、http 服务器、jmx 等 (默认端口:)
3.alertmanager : 用来进行报警、prometheus_cli:命令行工具 (默认端口: 9093)
4.Web UI : 原生UI功能较为单一,常常采用Grafana这个跨平台的开源的分析和可视化工具 (默认端口: 3000)
5.PushGateWay : 跨网段被监控主机指标采集数据转发到网关代理等待Server的Pull。
6.Time Series DataBase : 时序数据库(TSDB)用于保存时间序列(按时间顺序变化)的数据,每条记录都有完整的时间戳,基于时间的操作都比较方便.
Q:采用时序数据库(TSDB)的优点?
1.时间作为他的主轴,数据按顺序到达。
2.大多数操作是插入新数据,偶尔伴随查询,更新数据比较少。
3.时间序列数据累计速度非常快,更高的容纳率、更快的大规模查询以及更好的数据压缩。
4.TSDB 通常还包括一些共通的对时间序列数据分析的功能和操作:数据保留策略、连续查询、灵活的时间聚合等。
Q:什么是微服务架构?
他的组件是可以独立工作的,每个组件都不依赖其他的组件
配置文件来将不同的模块关联到一起,实现整个监控的功能
4.Prometheus 基本原理 描述: Prometheus 基本工作流程步骤如下:
Setp 1.Prometheus Server 读取配置解析静态监控端点(static_configs),以及服务发现规则(xxx_sd_configs)自动收集需要监控的端点
Setp 2.Prometheus Server 周期刮取(scrape_interval)监控端点通过HTTP的Pull方式采集监控数据
Step 3.Prometheus Server HTTP 请求到达 Node Exporter,Exporter 返回一个文本响应,每个非注释行包含一条完整的时序数据:Name + Labels + Samples(一个浮点数和一个时间戳构成), 数据来源是一些官方的exporter或自定义sdk或接口;
weiyigeek.top-Exporter-Metrics
Step 4.Prometheus Server 收到响应,Relabel处理之后(relabel_configs)将其存储在TSDB中并建立倒排索引
Step 5.Prometheus Server 另一个周期计算任务(evaluation_interval)开始执行,根据配置的Rules逐个计算与设置的阈值进行匹配,若结果超过阈值并持续时长超过临界点将进行报警,此时发送Alert到AlertManager独立组件中。
Step 6.AlertManager 收到告警请求,根据配置的策略决定是否需要触发告警,如需告警则根据配置的路由链路依次发送告警,比如邮件、微信、Slack、PagerDuty、WebHook等等。
Step 7.当通过界面或HTTP调用查询时序数据利用PromQL表达式查询,Prometheus Server 处理过滤完之后返回瞬时向量(Instant vector, N条只有一个Sample的时序数据),区间向量(Range vector,N条包含M个Sample的时序数据),或标量数据 (Scalar, 一个浮点数)
Step 8.采用Grafana开源的分析和可视化工具进行数据的图形化展示。
weiyigeek.top-Grafana
5.Prometheus 数据模型和类型 描述: metrics name & label 指标名称和标签(key=value)的形式组成的数据模型,其次是Prometheus惯例是使用基本单元如字节(Byte)和秒(s);
metrics name : 一般由字母和下划线构成 prometheus_http_requests_total(应用名称=name_监测对像=object_数值类型=int_单位=ok)。
基础示例:1 2 3 4 5 http_requests_total{status="200" ,method="GET" }@1434417560938 => 94355 go_info{instance="localhost:9090" , job="prometheus" , version="go1.16.2" }
数据类型 Counter(计数器类型) 、Gauge(仪表盘类型) 、Histogram(直方图类型)、Summary(摘要类型);
Counter 英 [ˈkaʊntə(r)] 类型 :该指标的工作方式和计数器一样,只增不减(除非系统发生了重置)。Counter一般用于累计值,例如记录请求次数、任务完成数、错误发生次数,通常来讲许多指标counter本身并没有什么意义,有意义的是counter随时间的变化率如采用rate函数能计算出每秒增长,由 <basename>_total组成。
Gauge 英 [ɡeɪdʒ] 类型 : 可增可减的指标类,可以用于反应当前应用的状态。比如机器内存,磁盘可用空间大小node_memory_MemAvailable_bytes/node_filesystem_avail_bytes等等;
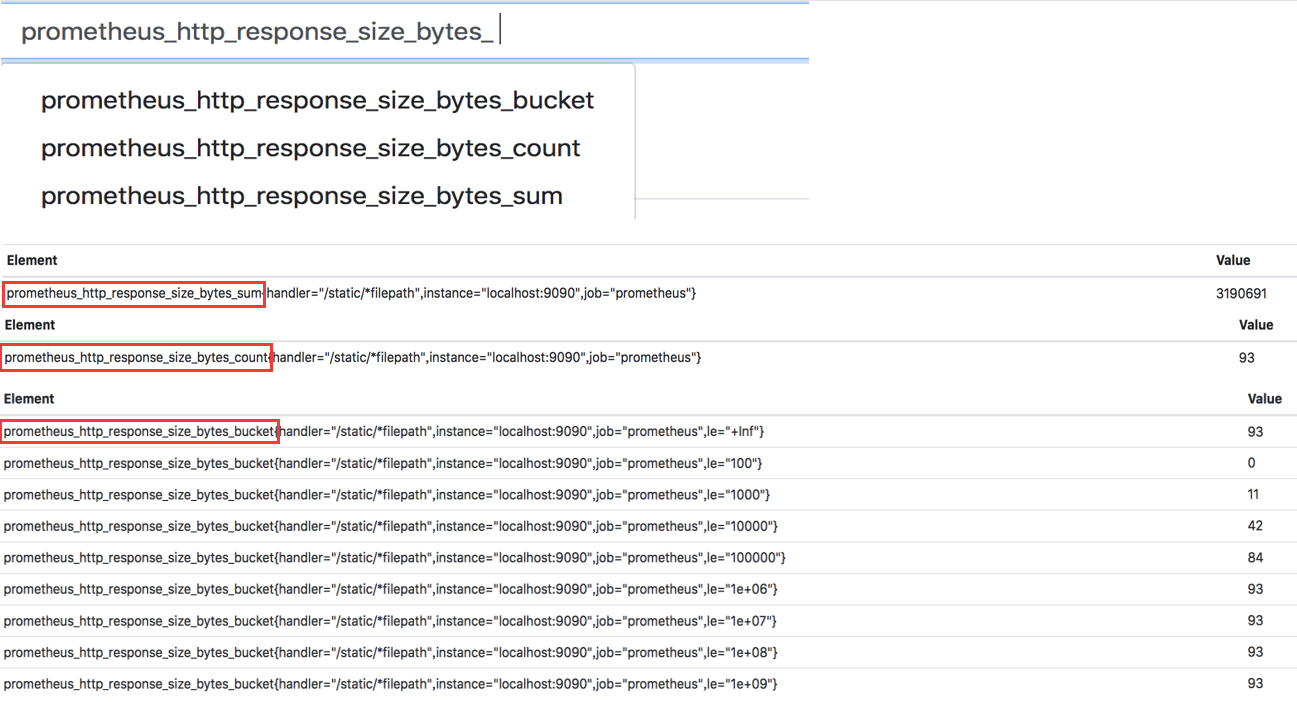
Histogram 英 [ˈhɪstəɡræm] 类型 : 客户端计算主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。由 <basename>_bucket, <basename>_sum, <basename>_count 组成;
1 2 3 所有事件产生值的大小的总和: basename_sum 事件发生的总次数: basename_count 事件产生的值分布: basename_bucket
weiyigeek.top-Histogram
Summary 英 [ˈsʌməri] 类型 : 与Histogram类型相似主要用于表示一段时间内数据采样结果(通常时请求持续时间或响应大小),它直接存储了分位数据,而不是根据统计区间计算出来的, 由< basename>_sum,< basename>_count,<basename>{quantile="<φ>"}组成;
weiyigeek.top-Summary
Q: Histogram 与 Sumamry 的两者区别?
Histogram 指标: 直接反应了在不同区间内样本的个数,区间通过标签len进行定义,同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数。
因此Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。反之对于客户端而言Histogram消耗的资源更少。
6.Prometheus 学习参考 描述: 当前2021年4月30日Prometheus Server版本: v2.26.0下载地址:https://prometheus.io/download/ https://prometheus.io/
帮助文档: https://prometheus.io/docs/prometheus/latest/getting_started/
0x01 环境安装配置 1.Prometheus 安装方式 描述: 上面的prometheus组件里常规的安装方式有如下几种;
Using pre-compiled binaries :二进制可执行文件
From source : 源码编译(需要安装gcc 和 g++ 和 Make)1 2 3 4 5 6 7 8 9 10 11 12 13 $ mkdir -p $GOPATH /src/github.com/prometheus $ cd $GOPATH /src/github.com/prometheus $ git clone https://github.com/prometheus/prometheus.git $ cd prometheus $ make build $ ./prometheus -config.file=your_config.yml $ git clone https://github.com/prometheus/alertmanager.git $ cd alertmanager $ make build $ ./alertmanager -config.file=<your_file>
Using Docker : 依赖于Docker进行安装,注意在Quay.io 或Docker Hub 上Docker图像的形式提供。
Using configuration management systems : 使用配置管理系统进行安装;
参考地址: https://prometheus.io/docs/prometheus/latest/installation/
2.Prometheus 服务安装 描述: 此次为了方便部署和测试我在Docker容器环境中利用 docker-compose 的方式部署 prometheus、 alertmanager 、grafana进行安装以及准备好文件,以及相应服务的配置文件。
Step 1.准备好持久化数据目录的创建与权限赋予1 2 3 4 5 6 7 8 9 10 11 /nfsdisk-31/monitor chown 472:root -R /nfsdisk-31/monitor/grafana/data chmod 777 /nfsdisk-31/monitor/prometheus/data
Step 2.配置文件目录1 2 3 4 5 6 7 8 9 10 11 tree -L 3 . ├── docker-compose.yml ├── grafana │ └── data └── prometheus ├── conf │ ├── alertmanager.yaml │ ├── alert.rules │ └── prometheus.yml └── data
Step 3.docker 创建指定网络名称monitor;1 2 3 4 5 6 7 8 docker network create -d bridge monitor docker network ls
Step 4.Docker-compose 资源清单描述进行prometheus以及grafana容器的创建, 以及相应的配置文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 tee /nfsdisk-31/monitor/prometheus/conf/docker-compose.yml <<'END' version: '3.2' services: prometheus: image: prom/prometheus:v2.26.0 container_name: prometheus_server environment: TZ: Asia/Shanghai volumes: - /nfsdisk-31/monitor/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml - /nfsdisk-31/monitor/prometheus/conf/alert.rules:/etc/prometheus/alert.rules - /nfsdisk-31/monitor/prometheus:/prometheus - /etc/localtime:/etc/localtime command: - '--config.file=/etc/prometheus/prometheus.yaml' - '--storage.tsdb.path=/prometheus/data' - '--web.enable-admin-api' - '--web.enable-lifecycle' ports: - '30090:9090' restart: always networks: - monitor pushgateway: image: prom/pushgateway container_name: prometheus_pushgateway environment: TZ: Asia/Shanghai volumes: - /etc/localtime:/etc/localtime ports: - '30091:9091' restart: always networks: - monitor alertmanager: image: prom/alertmanager:v0.21.0 container_name: prometheus_alertmanager environment: TZ: Asia/Shanghai volumes: - /nfsdisk-31/monitor/prometheus/conf/alertmanager.yaml:/etc/alertmanager.yaml - /nfsdisk-31/monitor/prometheus/alertmanager:/alertmanager - /etc/localtime:/etc/localtime command: - '--config.file=/etc/alertmanager.yaml' - '--storage.path=/alertmanager' ports: - '30093:9093' restart: always networks: - monitor grafana: image: grafana/grafana:7.5.5 container_name: grafana user: "472" environment: - TZ=Asia/Shanghai - GF_SECURITY_ADMIN_PASSWORD=weiyigeek volumes: - /nfsdisk-31/monitor/grafana/data:/var/lib/grafana ports: - '30000:3000' restart: always networks: - monitor dns: - 223.6 .6 .6 - 192.168 .12 .254 networks: monitor: external: true END
Step 5.prometheus 和 alertmanager 依赖的相关配置文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 cd /nfsdisk-31/monitor/prometheus/conf/tee prometheus.yml <<'EOF' global: scrape_interval: 120s scrape_timeout: 15s external_labels: monitor: 'current-monitor' scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090' ] rule_files: - 'alert.rules' EOF tee alertmanager.yaml <<'EOF' route: group_by: ['alertname' ] receiver: 'default-receiver' receivers: - name: 'default-receiver' webhook_configs: - url: 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=4e1165c3-55c1-4bc4-8493-ecc5ccda9275' EOF tee alert.rules <<'EOF' groups: - name: node-alert rules: - alert: service_down expr: up == 0 for : 3m - alert: high_load expr: node_load1 > 1.0 for : 5m EOF
Step 6.根据需求配置好相关信息之后使用 docker-compose up -d 启动容器,注意进行相应端口的防火墙规则调整通行。
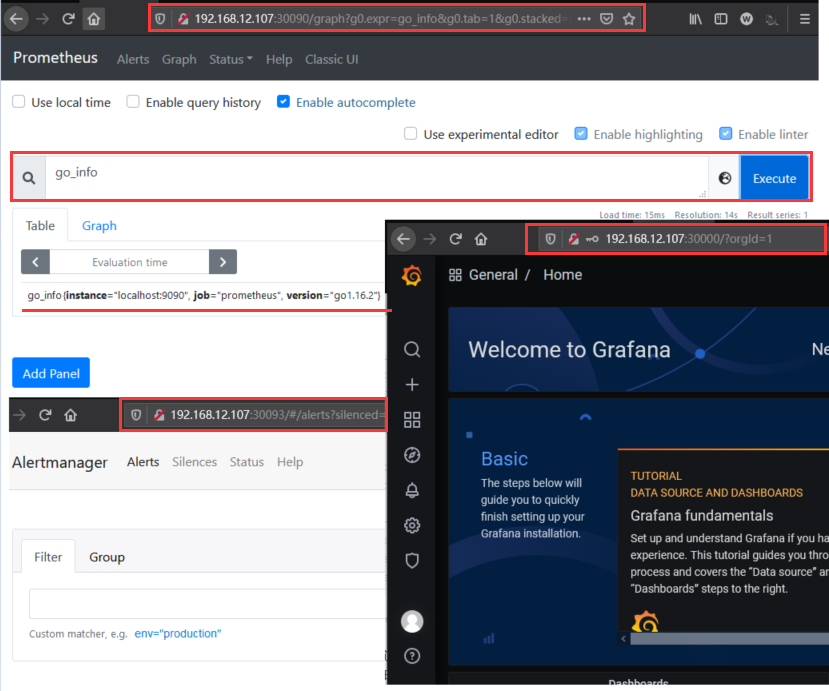
Step 7.所有的容器状态都 UP 之后,打开浏览器访问以下服务查看是否正常。
1 2 3 4 5 6 7 8 http://192.168.12.107:30090/ http://192.168.12.107:30093/ http://192.168.12.107:30000/login
点击 - insert metric at cursor 选择框,选额 go_info ,再点击 Execute 按钮查看是否有监控指标输出即安装成功go_info{instance="localhost:9090", job="prometheus", version="go1.16.2"}。
weiyigeek.top-服务验证
3.Node Exporter 节点导出器安装 描述: 该组件主要用于机器指标导出。
Step 1.在Github的Release中下载node_exporter可直接运行的二进制包。
1 2 3 4 5 6 7 8 9 10 11 12 13 cd /optwget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz tar -xvf node_exporter-1.1.2.linux-amd64.tar.gz sudo cp -a node_exporter /usr/local /bin/node_exporter sudo mkdir /etc/node_exporter/ sudo tee /etc/node_exporter/exporter.conf <<'EOF' EOF
Step 2.创建 /usr/lib/systemd/system/node_exporter.service systemd unit 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 sudo tee /usr/lib/systemd/system/node_exporter.service <<'EOF' [Unit] Description=Node Exporter Clinet Documentation=https://prometheus.io/ After=network.target [Service] Type=simple StandardError=journal ExecStart=/usr/local /bin/node_exporter --web.listen-address=:9100 Restart=on-failure RestartSec=3s [Install] WantedBy=multi-user.target EOF sudo chmod 754 /usr/lib/systemd/system/node_exporter.service
Step 3.重载systemd与开机自启node_exporter服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 sudo systemctl daemon-reload sudo systemctl enable node_exporter.service sudo systemctl start node_exporter.service sudo systemctl status node_exporter.service ● node_exporter.service - Node Exporter Clinet Loaded: loaded (/lib/systemd/system/node_exporter.service; disabled; vendor preset: enabled) Active: active (running) since Fri 2021-04-30 22:49:33 CST; 10s ago Main PID: 1238901 (node_exporter) Tasks: 12 (limit : 19111) Memory: 11.4M CGroup: /system.slice/node_exporter.service └─1238901 /usr/local /bin/node_exporter --collector.systemd Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller =node_exporter.go:113 collector=thermal_zone ...... Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller =node_exporter.go:113 collector=zfs Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.154Z caller =node_exporter.go:195 msg="Listening on" address=:9100 Apr 30 22:49:33 weiyigeek-107 node_exporter[1238901]: level=info ts=2021-04-30T14:49:33.155Z caller =tls_config.go:191 msg="TLS is disabled." http2=false netstat -tlnp | grep "9100" (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp6 0 0 :::9100 :::* LISTEN -
Step 4.通过node exporter的http服务查看该主机的metrics信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 curl -s http://192.168.12.107:9100/metrics | head -n 20 go_gc_duration_seconds{quantile="0" } 2.4814e-05 go_gc_duration_seconds{quantile="0.25" } 5.1128e-05 go_gc_duration_seconds{quantile="0.5" } 9.3675e-05 go_gc_duration_seconds{quantile="0.75" } 0.000131435 go_gc_duration_seconds{quantile="1" } 0.000767665 go_gc_duration_seconds_sum 0.015132517 go_gc_duration_seconds_count 135 go_goroutines 8 go_info{version="go1.15.8" } 1 go_memstats_alloc_bytes 3.019424e+06
Step 5.配置 prometheus.yml 添加如下Job工作
1 2 3 4 5 vi /nfsdisk-31/monitor/prometheus/conf/prometheus.yml - job_name: 'node-resources' scrape_interval: 120s static_configs: - targets: ['192.168.12.107:9100' ]
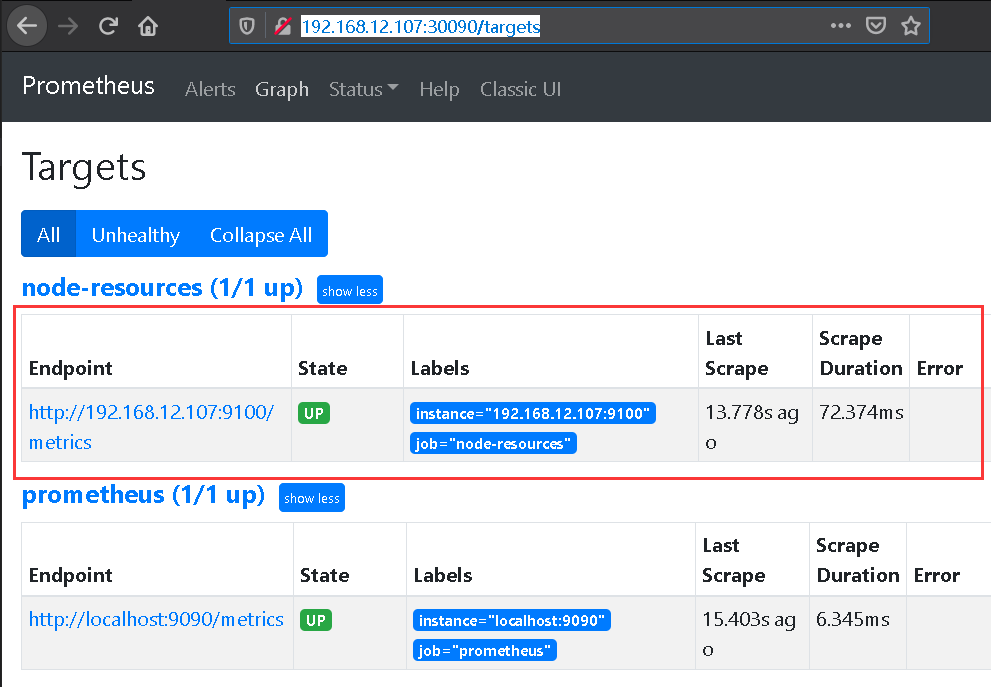
Step 6.重新prometheus容器进行更新配置,之后访问http://192.168.12.107:30090/targets页面查看目标是否可以正常监控了(UP上线)。
weiyigeek.top-Target-node-resources
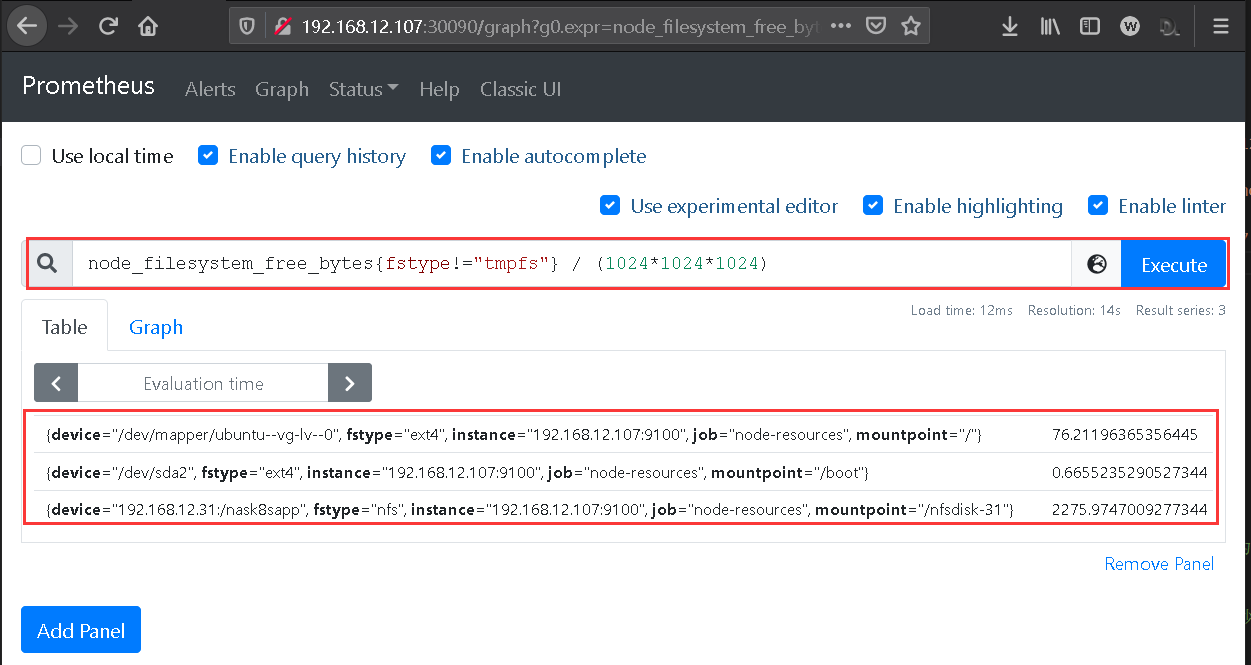
Step 7.监控该主机系统相关信息,我们可以在UI首页进行系统空闲磁盘大小查看1 2 3 4 5 6 7 8 9 10 node_filesystem_free_bytes{fstype!="tmpfs" } / (1024*1024*1024) {device="/dev/mapper/ubuntu--vg-lv--0" , fstype="ext4" , instance="192.168.12.107:9100" , job="node-resources" , mountpoint="/" } 76.21196365356445 {device="/dev/sda2" , fstype="ext4" , instance="192.168.12.107:9100" , job="node-resources" , mountpoint="/boot" } 0.6655235290527344 {device="192.168.10.30:/nask8sapp" , fstype="nfs" , instance="192.168.12.107:9100" , job="node-resources" , mountpoint="/nfsdisk-31" } 2275.9747009277344
weiyigeek.top-PromQL 表达式数据查询
4.cAdvisor 容器监控安装 描述: cAdvisor 英 [Kədˈvaɪzə]使用Go语言开发,利用Linux的cgroups获取容器的资源使用信息, 可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取.
cAdvisor原生支持Docker容器,并且对任何其他类型的容器能够开箱即用,它也是基于lmctfy的容器抽象,所以容器本身是分层嵌套的。
优缺点:
优点:谷歌开源产品,监控指标齐全,部署方便,而且有官方的docker镜像。
缺点:是集成度不高,默认只在本地保存1分钟数据,但可以集成InfluxDB等存储
项目地址: https://github.com/google/cadvisor/ https://docs.huihoo.com/apache/mesos/chrisrc.me/dcos-admin-monitoring-docker.html
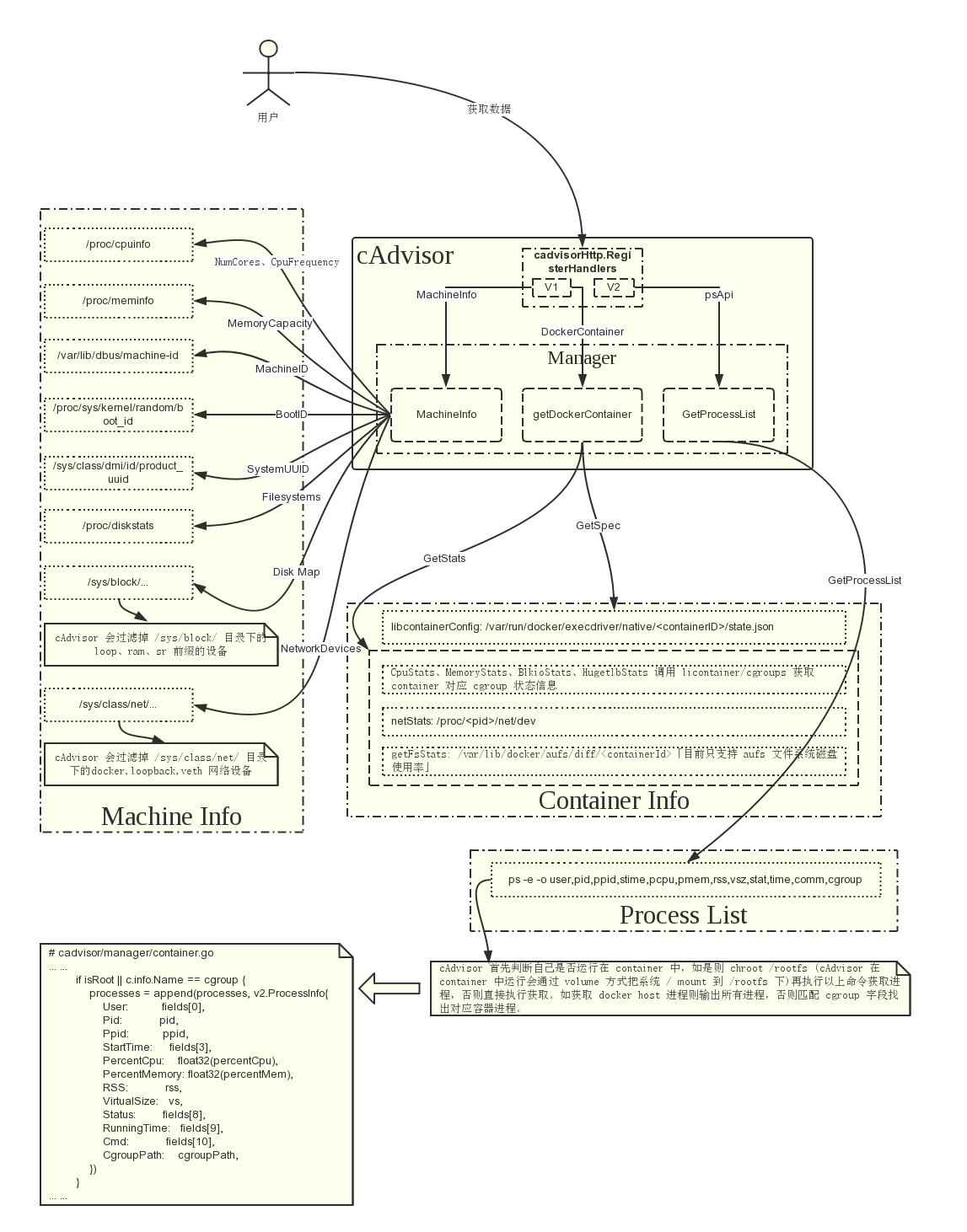
cAdvisor 结构图:
weiyigeek.top-cAdvisor 结构图
安装方式:
weiyigeek.top-CAvisor-containers
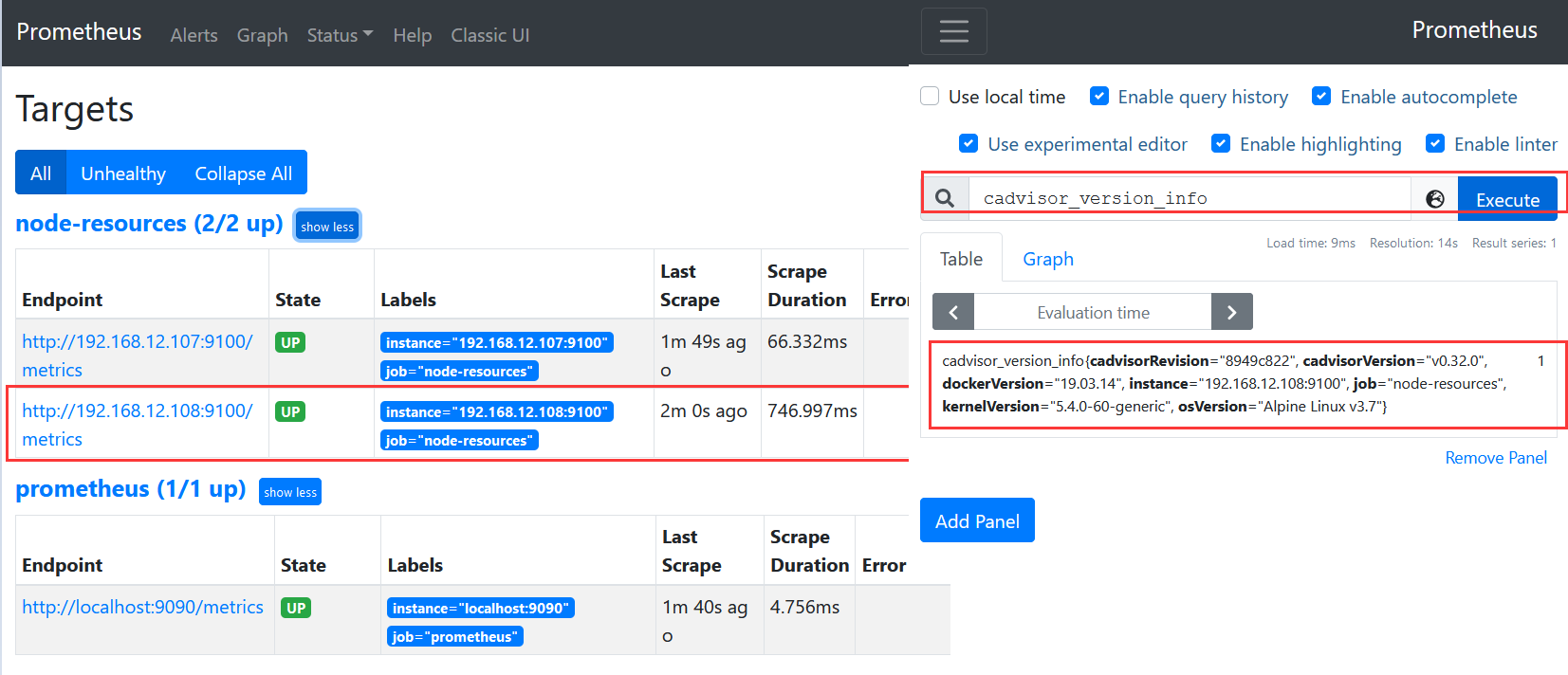
4) 然后访问: http://192.168.12.108:9100/metrics 查看其暴露给 Prometheus 的所有数据;
1 2 3 4 5 6 7 cadvisor_version_info{cadvisorRevision="8949c822" ,cadvisorVersion="v0.32.0" ,dockerVersion="19.03.14" ,kernelVersion="5.4.0-60-generic" ,osVersion="Alpine Linux v3.7" } 1 container_cpu_load_average_10s{container_label_annotation_io_kubernetes_container_hash="" ,container_label_annotation_io_kubernetes_container_ports="" ,container_label_annotation_io_kubernetes_container_restartCount="" ,container_label_annotation_io_kubernetes_container_terminationMessagePath="" ,container_label_annotation_io_kubernetes_container_terminationMessagePolicy="" , .......
5) 我们将cAdvisor配置接入到prometheus之中,修改后重新启动容器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim /nfsdisk-31/monitor/prometheus/conf/prometheus.yml scrape_configs: - job_name: 'node-resources' scrape_interval: 120s static_configs: - targets: ['192.168.12.107:9100' ,'192.168.12.108:9100' ] docker restart prometheus_server
6) 访问Prometheus后台页面查看target以及查询验证。
weiyigeek.top-cadvisor_version_info
Tips : 在CentOS上运行cAdvisor时,需要添加 --privileged=true 和 --volume=/cgroup:/cgroup:ro 两项配置。
Tips : 如果碰到Invalid Bindmount /错误,可能是由于Docker版本较低所致,可以在启动cAdvisor时不挂载--volume=/:/rootfs:ro。
Tips :总结正是因为 cadvisor 与 Prometheus 的完美结合,所以它成为了容器监控的第一选择,或者cadvisor + influxdb + grafna搭配使用。
5.Grafana 图像化展示接入 描述: 在简单的配置好node-export被监控主机以及cAdvisor容器监控之后,将其监控采集的数据接入到Grafana进行展示。
Step 1.点击首页 Create a data source 按钮选择 Prometheus 导入 Prometheus 监控数据源(注:由于搭建的版本不同位置名称可能由些许不同)
weiyigeek.top-
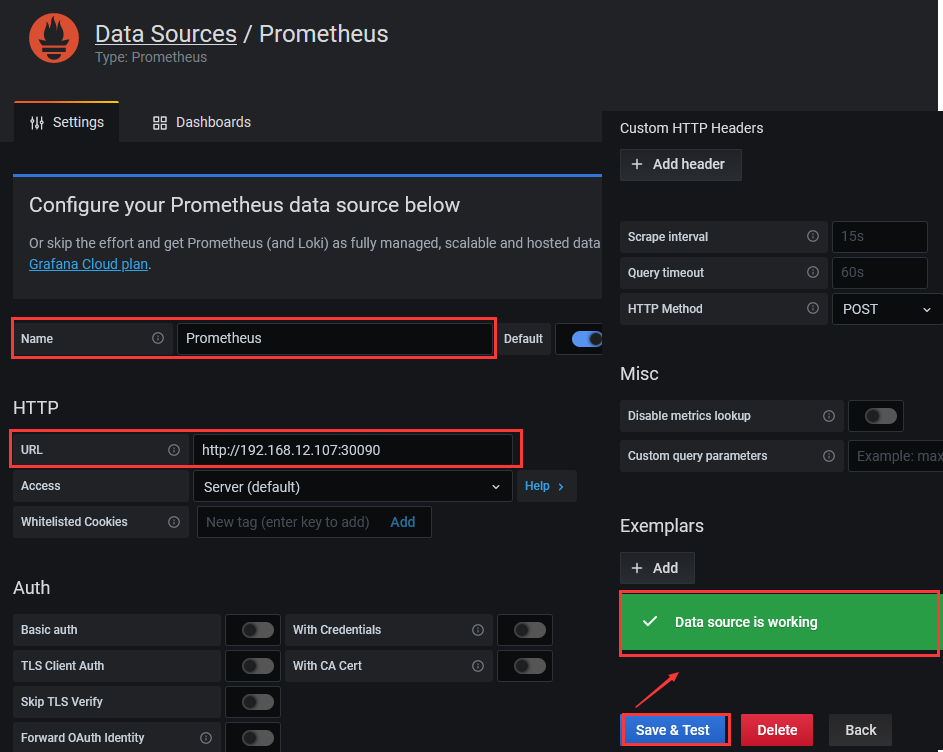
Step 2.进入 Prometheus 的 Data Sources 设置页面之后, 设置 URL 为的 http://192.168.12.107:30090, 其余的默认即可 Auth 方式稍后使用 nginx 进行用户访问权限验证处理。
Step 3.配置好信息之后点击底部的 Save & test 按钮,测试是否能正常获取的Prometheus 监控数据源
weiyigeek.top-Prometheus监控数据源
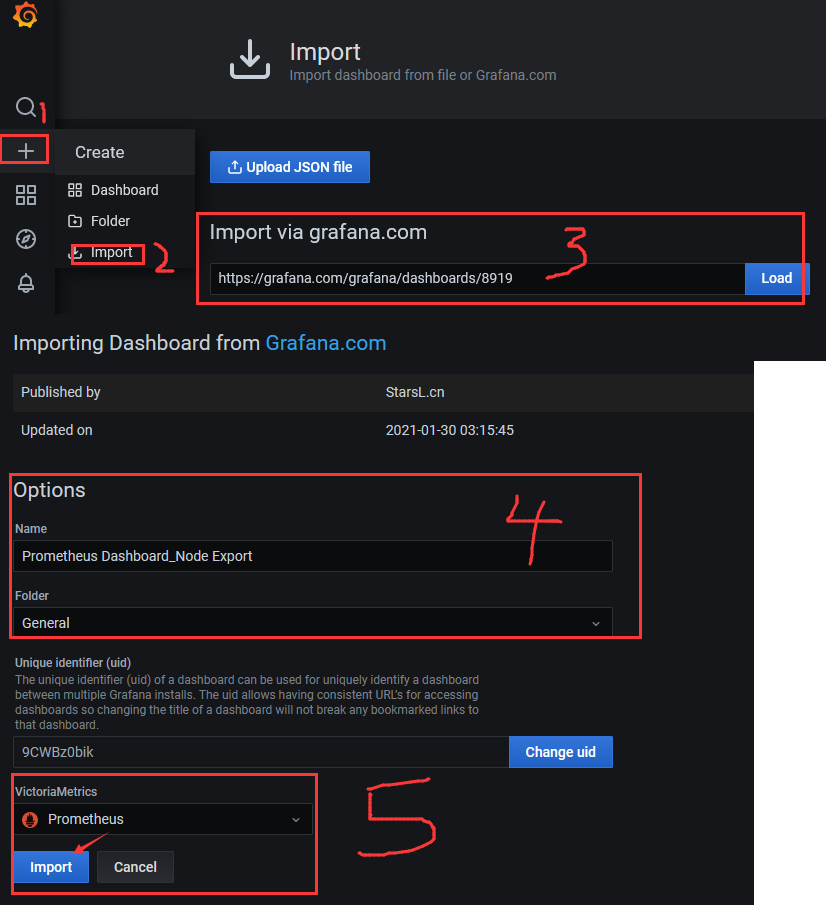
Step 4.点击右上角 + 按钮 —> Import dashboard 然后在 Import via grafana.com 输入栏中输入 https://grafana.com/grafana/dashboards/8919 再点击 Load ,之后会自动跳转到该 dashboard 的配置页面。
Step 5.设置好名称,并在 Prometheus Data Source 选择之前配置好的数据源,然后点击 import 即可。
weiyigeek.top-import-prometheus-dashboard
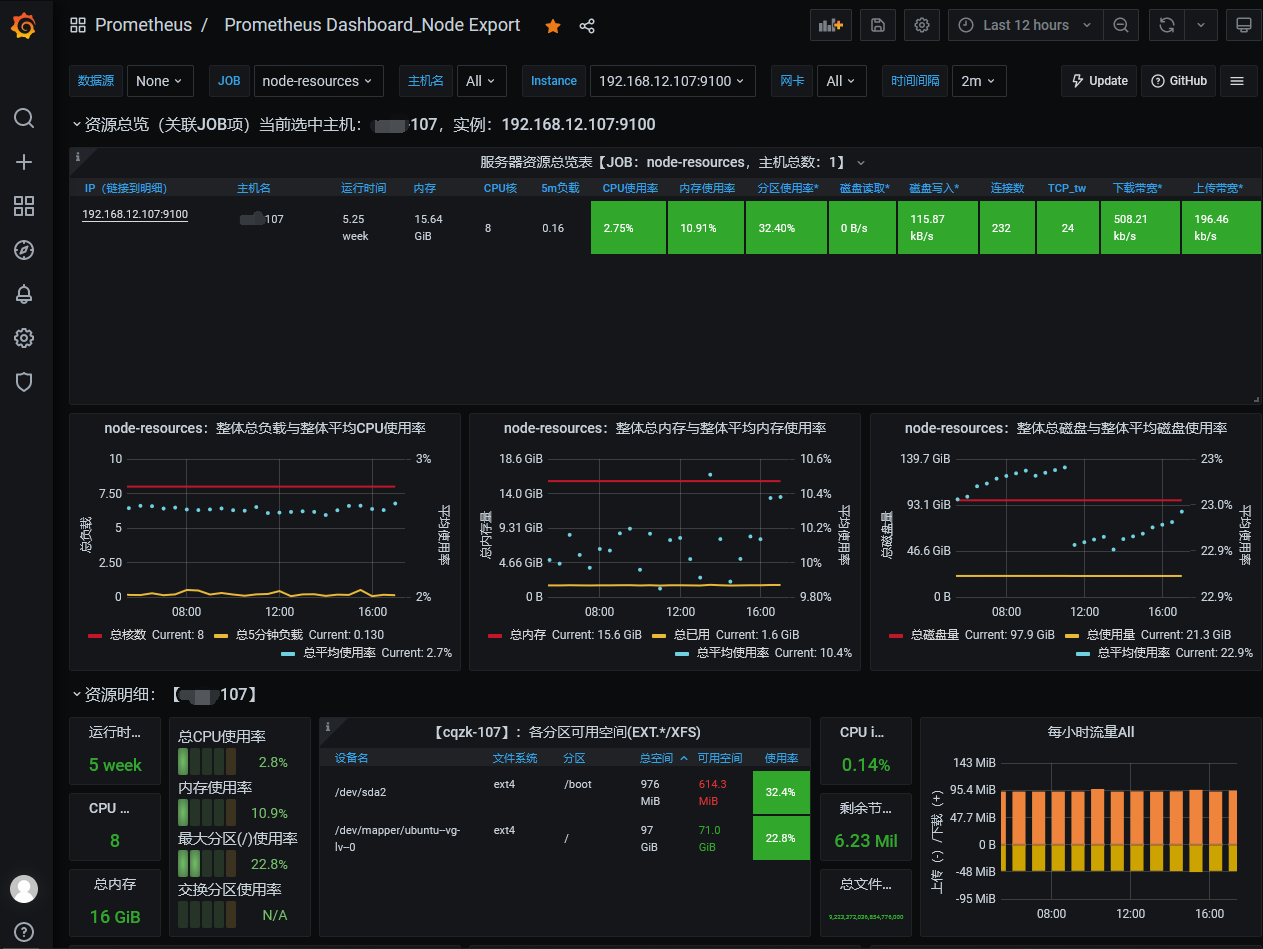
Step 6.回到 grafana 的主页面,页面 Recently viewed dashboards 会有出现我们刚刚导入的 dashboard, 点击进入后会出现以下监控信息。
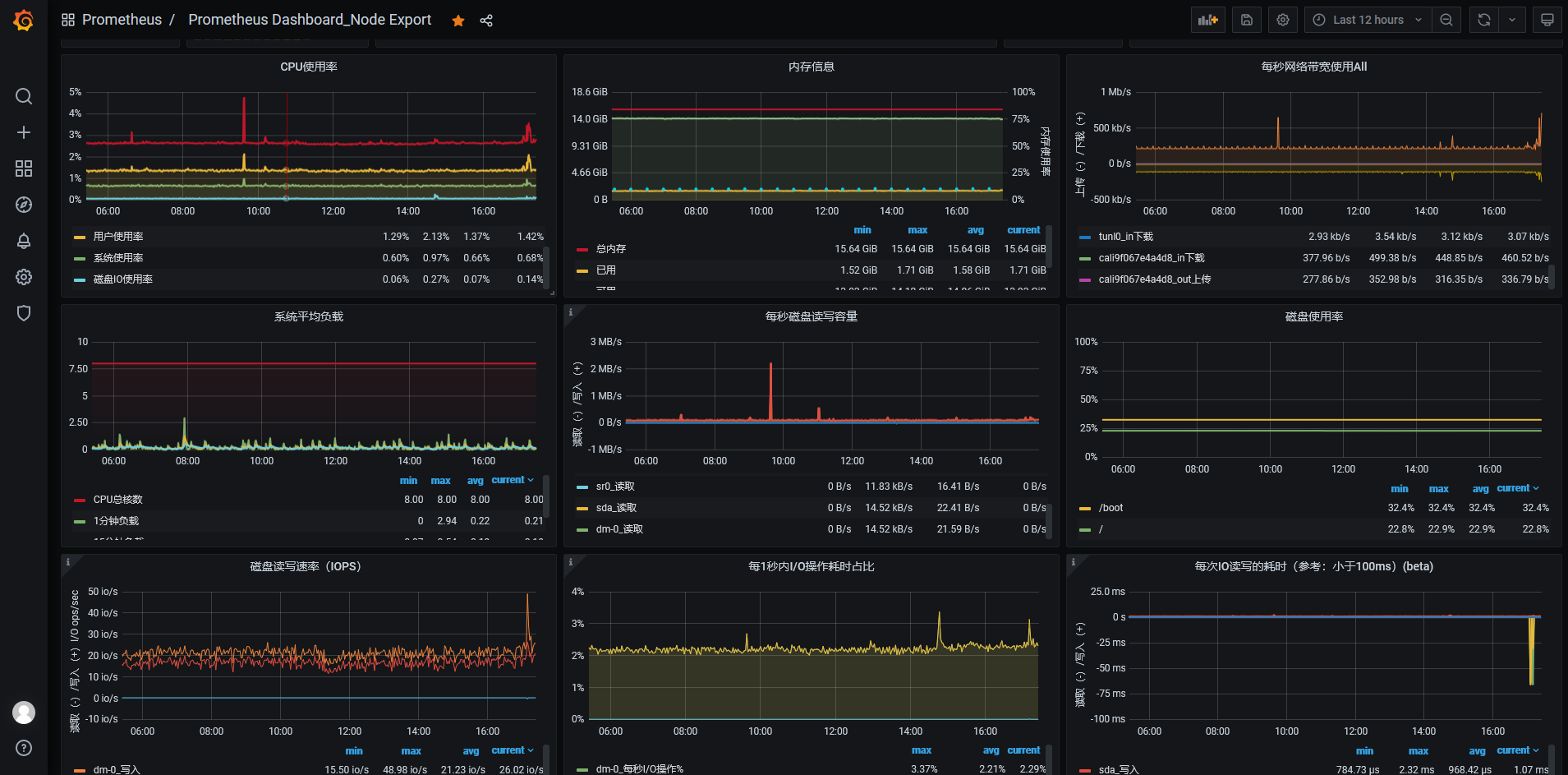
weiyigeek.top-prometheus-dashboard-1
weiyigeek.top-prometheus-dashboard-2
6.在k8s中安装部署上述组件 描述: 该存储库将Kubernetes清单、Grafana仪表板和Prometheus规则与文档和脚本结合起来,通过Prometheus使用Prometheus操作符来提供易于操作的端到端Kubernetes集群监控。https://github.com/prometheus-operator/kube-prometheus#quickstart https://github.com/coreos/kube-prometheus
组件说明:
1.MetricServer: 是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如 kubectl,hpa,scheduler等。
2.PrometheusOperotor:是一个系统监测和警报工具箱,用来存储监控数据
3.NodeExporter:用于各node的关键度量指标状态数据。
4.KubeStateMetrics:收集kubernetes集群内资源对象数 据,制定告警规则。
5.Prometheus::采用pull方式收集apiserver, scheduler, controller-mandger, kubelet组件数 据,通过http协议传输。
6.Grafana:是可视化数据统计和监控平台。
操作流程:
Step 0.拉取 kube-prometheus 在 Github 中的项目文件;1 2 3 4 5 6 7 8 git config --global http.proxy 'socks5://127.0.0.1:1080' git config --global https.proxy 'socks5://127.0.0.1:1080' git clone https://github.com/coreos/kube-prometheus.git ~/K8s/Day10/kube-prometheus$ ls build.sh DCO example.jsonnet experimental go.sum jsonnet jsonnetfile.lock.json LICENSE manifests OWNERS scripts tests code-of-conduct.md docs examples go.mod hack jsonnetfile.json kustomization.yaml Makefile NOTICE README.md sync-to-internal-registry.jsonnet test.sh
Step 1.由于GFW的原因我们需要将资源清单中的quay.io仓库以及k8s.gcr.io仓库镜像地址进行换成国内(PS:建议在国外买VPS然后PULL下载后打包回国内)以及type访问类型1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 ~/K8s/Day10/kube-prometheus/manifests/setup$ grep "quay.io/" * ~/K8s/Day10/kube-prometheus/manifests/setup$ sed -i "s#quay.io/#quay.mirrors.ustc.edu.cn/#g" * ~/K8s/Day10/kube-prometheus/manifests/$ sed -i "s#quay.io/#quay.mirrors.ustc.edu.cn/#g" * apiVersion: v1 kind: Service metadata: labels: alertmanager: main name: alertmanager-main namespace: monitoring spec: type : NodePort ports: - name: web port: 9093 targetPort: web nodePort: 30070 selector: alertmanager: main app: alertmanager sessionAffinity: ClientIP apiVersion: v1 kind: Service metadata: labels: prometheus: k8s name: prometheus-k8s namespace: monitoring spec: type : NodePort ports: - name: web port: 9090 targetPort: web nodePort: 30090 selector: app: prometheus prometheus: k8s sessionAffinity: ClientIP apiVersion: v1 kind: Service metadata: labels: app: grafana name: grafana namespace: monitoring spec: ports: - name: http port: 3000 targetPort: http nodePort: 30080 selector: app: grafana type : NodePort
Step 2.使用manifests/setu的清单目录中的配置创建监视堆栈1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ~/K8s/Day10/kube-prometheus/manifests/setup$ kubectl create -f . ~/K8s/Day10/kube-prometheus/manifests/setup$ kubectl get pod -n monitoring -o wide --show-labels
Step 3. 完成上一步资源清单的创建后继续进行manifests中grafana、alertmanager、node-exporter资源清单的建立1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ~/K8s/Day10/kube-prometheus$ kubectl create -f manifests/ ...... ~/K8s/Day10/kube-prometheus$ kubectl get pod -n monitoring -o wide
Step 4.查看Services资源清单得到prometheus、grafana、alertmanager暴露的端口1 2 3 4 5 6 7 8 9 10 11 ~/K8s/Day10/kube-prometheus/manifests$ kubectl get svc -n monitoring -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR prometheus-adapter ClusterIP 10.100.45.247 <none> 443/TCP 122m name=prometheus-adapter prometheus-operator ClusterIP None <none> 8443/TCP 5h42m app.kubernetes.io/component=controller,app.kubernetes.io/name=prometheus-operator kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 122m app.kubernetes.io/name=kube-state-metrics prometheus-operated ClusterIP None <none> 9090/TCP 122m app=prometheus alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 122m app=alertmanager node-exporter ClusterIP None <none> 9100/TCP 122m app.kubernetes.io/name=node-exporter alertmanager-main NodePort 10.100.233.132 <none> 9093:30070/TCP 122m alertmanager=main,app=alertmanager prometheus-k8s NodePort 10.103.33.255 <none> 9090:30090/TCP 122m app=prometheus,prometheus=k8s grafana NodePort 10.104.211.111 <none> 3000:30080/TCP 122m app=grafana
应用IP端口访问列表:
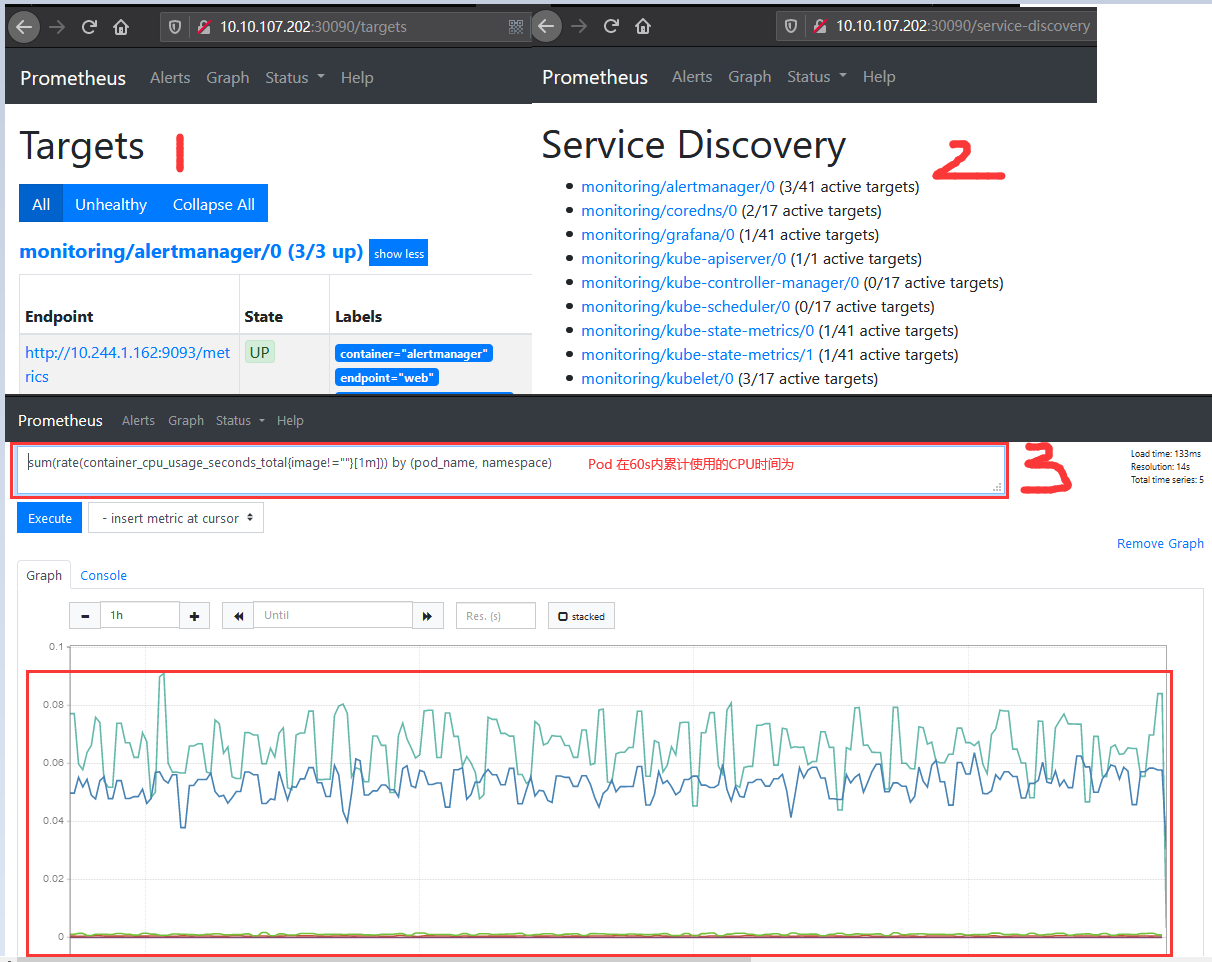
PS : 下面验证上述服务能否正常访问
PS : 上述的查询有出现数据说明node-exporter往Prometheus中写数据是正常的,接下来查看你我们的grafana组件实现更友好的数据展示
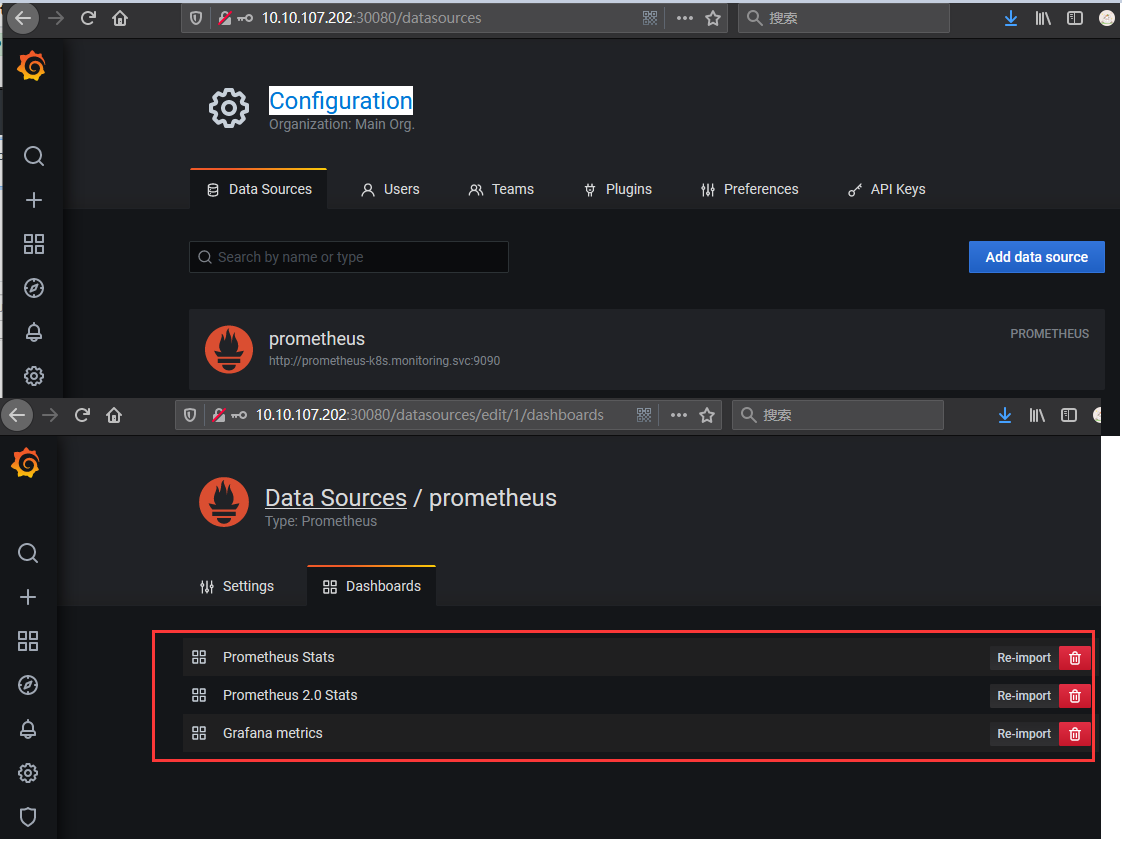
Step 6.访问grafana Web UI进行数据图形化展示,缺省账号密码admin、admin,登录后要设置新的密码weiyigeek;
随后在Grafana中添加Prometheus数据源进行数据的展示: Configuration -> Data Source -> prometheus -> 导入指定 prometheus;
weiyigeek.top-grafana-import
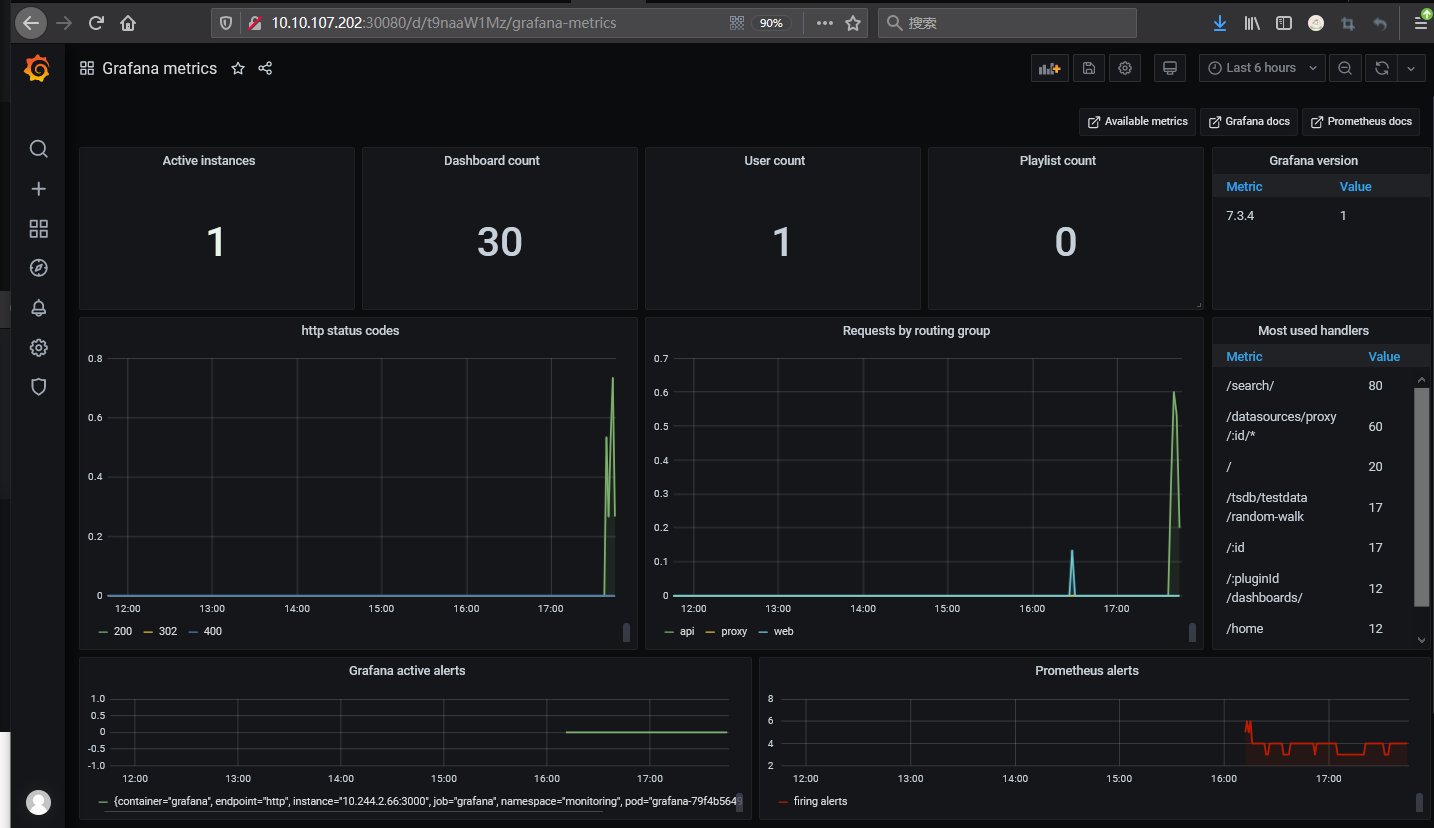
采用 Grafana 展示的 Prometheus 数据:
weiyigeek.top-Grafana metrics
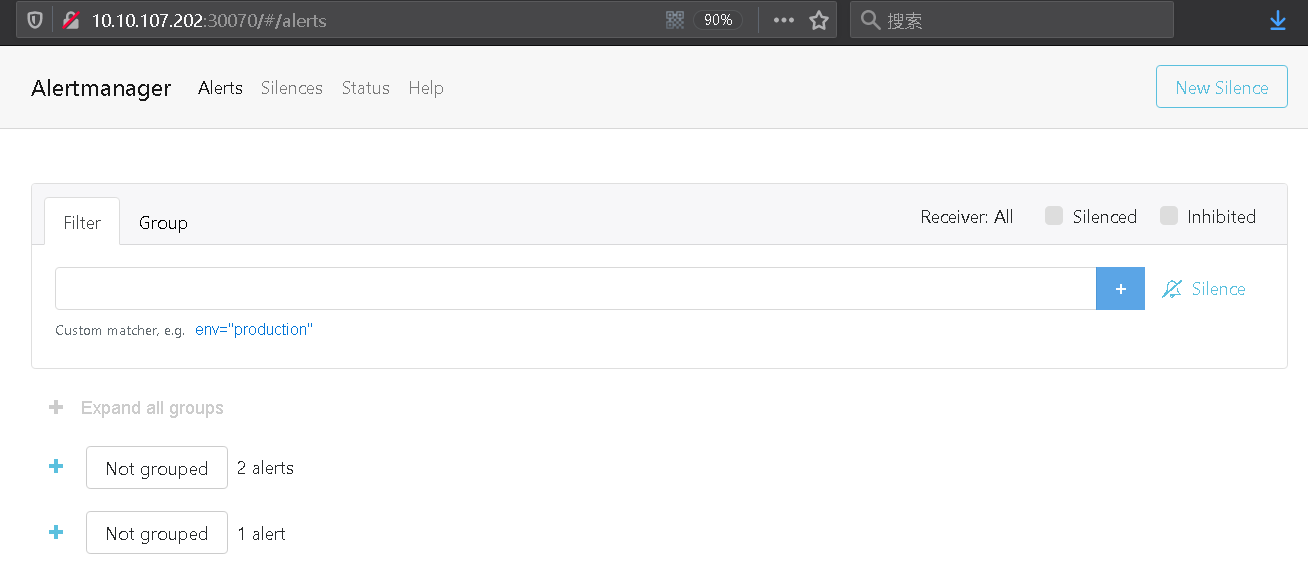
Step 7.访问 alertmanager 的 Web UI 进行查看预警;
weiyigeek.top-alertmanager
Step 8.至此采用Helm安装Prometheus完成,但是它仅仅是个示例我们需要对其做完整的安全保护(访问限制、访问认证可以在Nginx中进行配置)