[TOC]
0x00 组件介绍
Prometheus
描述: 如果我们采用prometheus提供的二进制可执行文件进行搭建prometheus服务器,可以按照以下流程进行操作运行,二进制Release下载地址: https://github.com/prometheus/prometheus/releases
简单流程:

[TOC]
描述: 如果我们采用prometheus提供的二进制可执行文件进行搭建prometheus服务器,可以按照以下流程进行操作运行,二进制Release下载地址: https://github.com/prometheus/prometheus/releases
简单流程:
[TOC]
描述: 如果我们采用prometheus提供的二进制可执行文件进行搭建prometheus服务器,可以按照以下流程进行操作运行,二进制Release下载地址: https://github.com/prometheus/prometheus/releases
简单流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41# (1) 下载二进制可执行文件
wget https://github.com/prometheus/prometheus/releases/download/v2.26.0/prometheus-2.26.0.linux-amd64.tar.gz
tar -zxvf prometheus-2.26.0.linux-amd64.tar.gz -C /usr/local/
cd /usr/local/prometheus-2.26.0.linux-amd64
# (2) 后台启动并修改开放端口
nohup ./prometheus --config.file=prometheus.yml --web.enable-lifecycle --web.listen-address=:30090 &
# (3) 查看启动状态
ps -ef | grep prometheus
lsof -i:19908
# (4) 查看启动的命令行参数
./prometheus -h
# (5) 强行关闭 Prometheus
lsof -i:19908
kill -9 pid
# (6) 补充系统服务进行启动Prometheus
sudo tee /usr/lib/systemd/system/prometheus.service <<'EOF'
[Unit]
Description=Prometheus Server Systemd
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
StandardError=journal
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --web.listen-address=:9090 --storage.tsdb.path=/app/prometheus_data --storage.tsdb.retention.time=7d --web.enable-lifecycle --web.enable-admin-api
Restart=on-failure
RestartSec=3s
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload && systemctl restart prometheus.service
# (7) 自动发现日志文件配置
mkdir /etc/prometheus/ && touch /etc/prometheus/WeiyiGeek_linux_nodes.yml
启动参数: 运行后我们可以访问http://192.168.12.107:30090/classic/flags查看到自定义或者默认的启动参数。
| Command-Line Flags - 参数名称 | 参数值 | 参数说明 |
|---|---|---|
| alertmanager.notification-queue-capacity | 10000 | |
| alertmanager.timeout | ||
| config.file | /etc/prometheus/prometheus.yml | 指定 prometheus.yml配置文件 |
| enable-feature | ||
| log.format | logfmt | 设置打印日志的格式,若有自动化日志提取工具可以使用这个参数规范日志打印的格式logger:stderr |
| log.level | info | |
| query.lookback-delta | 5m | |
| query.max-concurrency | 20 | |
| query.max-samples | 50000000 | |
| query.timeout | 2m | |
| rules.alert.for-grace-period | 10m | |
| rules.alert.for-outage-tolerance | 1h | |
| rules.alert.resend-delay | 1m | |
| scrape.adjust-timestamps | true |
| storage.exemplars.exemplars-limit | 0 |
| storage.remote.flush-deadline | 1m |
| storage.remote.read-concurrent-limit | 10 |
| storage.remote.read-max-bytes-in-frame | 1048576 |
| storage.remote.read-sample-limit | 50000000 |
| storage.tsdb.allow-overlapping-blocks | false |
| storage.tsdb.max-block-duration | 1d12h |
| storage.tsdb.min-block-duration | 2h |
| storage.tsdb.no-lockfile | false | 如果用k8s的deployment 管理要设置为tue
| storage.tsdb.path | data/ | 指定tsdb数据存储路径(容器中默认是/prometheus/data)
| storage.tsdb.retention | 0s |
| storage.tsdb.retention.size | 0B | [EXPERIMENTAL]要保留的最大存储块字节数,最旧的数据将首先被删除默认为0或禁用。
| storage.tsdb.retention.time | 0s | 指定数据存储时间即何时删除旧数据(推荐7d)
| storage.tsdb.wal-compression | true | 启用压缩预写日志(WAL),根据您的数据您可以预期WAL大小将减少一半而额外的CPU负载却很少
| storage.tsdb.wal-segment-size | 0B |
| web.config.file | |
| web.console.libraries | console_libraries |
| web.console.templates | consoles |
| web.cors.origin | .* |
| web.enable-admin-api | false | 是否启用 admin api 的访问权限(TSDB管理API)
| web.enable-lifecycle | true | 是否启用 API,启用API后,可以通过 API指令完成 Prometheus 的 停止、热加载配置文件 等
| web.external-url | |
| web.listen-address | 0.0.0.0:9090 | 监听地址和提供服务端口
| web.max-connections | 512 |
| web.page-title | Prometheus Time Series Collection and Processing Server |
| web.read-timeout | 5m |
| web.route-prefix | / |
| web.user-assets | |
Tips : 当我们启用了 API 时我们可以使用它来看当前prometheus.yml中的配置和利用POST请求重载配置。1
2
3
4
5
6
7
8
9# 查看当前配置,如果使修改后的prometheus.yml配置生效可参照下面得方式(在也不用重启容器了)
curl http://192.168.12.107:30090/api/v1/status/config
# 方式1.如果在本机二进制可执行时可以通过使用SIGHUP来重载Prometheus而不用重启(ctrl+c)
kill -SIGHUP prometheus
# 方式2.Yes, sending SIGHUP to the Prometheus process or an HTTP POST request to the /-/reload endpoint
curl -X POST http://192.168.12.107:30090/-/reload
# level=info ts=2021-05-08T06:37:53.793Z caller=main.go:944 msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml
# level=info ts=2021-05-08T06:37:53.799Z caller=main.go:975 msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=6.025725ms remote_storage=2.732µs web_handler=617ns query_engine=1.456µs scrape=124.866µs scrape_sd=55.119µs notify=1.099µs notify_sd=1.377µs rules=4.424043ms
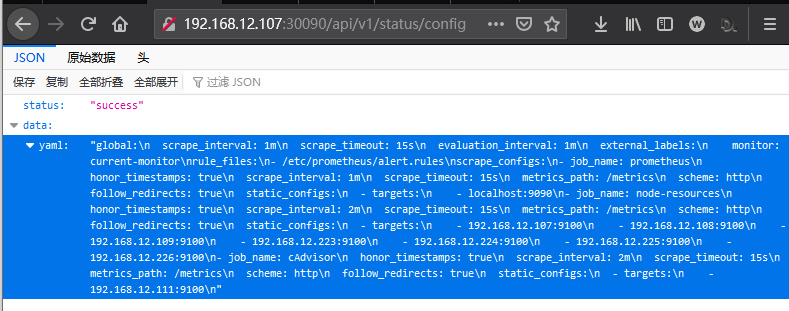
weiyigeek.top-status-config
描述: Prometheus 给我们提供了多种场景的监控程序,我们可以通过https://github.com/prometheus?q=_export&type=&language=&sort=Prometheus Gitlab项目中查看到。
1 | # 默认端口: 9100 |
补充:Linux配置Systemd服务启动1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31ftp -v -n 192.168.12.31<<EOF
user WeiyiGeektemp
binary
lcd /tmp
prompt
get node_exporter-1.1.2.linux-amd64.tar.gz
bye
EOF
echo "download from ftp successfully"
sudo tar -zxvf /tmp/node_exporter-1.1.2.linux-amd64.tar.gz -C /usr/local/
sudo ln -s /usr/local/node_exporter-1.1.2.linux-amd64/node_exporter /usr/local/bin/node_exporter
sudo tee /usr/lib/systemd/system/node_exporter.service <<'EOF'
[Unit]
Description=Node Exporter Clinet
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
StandardError=journal
ExecStart=/usr/local/bin/node_exporter --web.listen-address=:9100
Restart=on-failure
RestartSec=3s
[Install]
WantedBy=multi-user.target
EOF
sudo chmod 754 /usr/lib/systemd/system/node_exporter.service
sudo systemctl daemon-reload
sudo systemctl enable node_exporter.service
sudo systemctl start node_exporter.service
1 | # 默认端口: 9182 |
补充: 采用PowerShell和bat添加自启动服务和设置防火墙放行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55# - PowerShell
#####################################
# Prometheus Metrics Nodes Services #
# Prometheus Exporter firewall Rule #
# Author: WeiyiGeek #
# Desc: 需要将该脚本以及windows_exporter-${exporterVersion}-amd64.exe文件放入到d:\pro中
#####################################
$exporterVersion="0.16.0"
$currentPath=(Get-Location).path
$serviceName="prometheus_exporter_service"
@"
collectors:
enabled: cpu,cs,logical_disk,net,os,system,service,logon,process,tcp
collector:
service:
services-where: Name='windows_exporter'
log:
level: error
scrape:
timeout-margin: 0.5
telemetry:
addr: ":9100"
path: /metrics
max-requests: 5
"@ | Out-File config.yml -Encoding utf8
# 如果服务存在则停止以及删除旧服务
if (Get-Service -Name ${serviceName} -ErrorAction Ignore )
{
echo "注意: 操作时需要关闭系统中全部services.msc服务窗口"
sc stop ${serviceName}
sc delete ${serviceName}
}
# - 服务创建
$params = @{
Name = ${serviceName}
BinaryPathName = "$currentPath\windows_exporter-${exporterVersion}-amd64.exe --config.file=$currentPath\config.yml"
DisplayName = "prometheus_windows_exporter_service"
StartupType = "Automatic"
Description = "windows exporter service open 9100 port!"
}
New-Service @params
# - 启动及服务查看
Get-Service -Name "prometheus_windows_exporter_service" | Start-Service -PassThru
# - 防火墙规则设置(只允许10.0.30.200机器访问)
New-NetFirewallRule -Name "prometheus_windows_exporter_service" -DisplayName "prometheus_windows_exporter_service" -Description "prometheus_windows_exporter_service" -Direction Inbound -LocalPort 9100 -RemoteAddress 10.0.30.200 -Protocol TCP -Action Allow -Enabled True
Get-NetFirewallRule -Name "prometheus_windows_exporter_service" | Format-Table
# - bat
sc create prometheus_windows_exporter_service binPath= "d:\weiyigeek\windows_exporter-0.16.0-amd64.exe --config.file=d:\weiyigeek\config.yml" start= "auto" displayname= "prometheus_windows_exporter_service"
sc start prometheus_windows_exporter_service
netsh advfirewall firewall add rule name="prometheus_windows_exporter_service" dir=in protocol=tcp localport=9100 action=allow remoteip=10.0.30.2 enable=yes
补充:采用msi格式进行安装部署1
msiexec /i "D:\weiyigeek\windoes_exporter.msi" ENABELD_COLLECTORS="os,cpu,cs.logical_disk,net,system,process" LISTEN_PORT="9182" EXTRA_FLAGS="--collector.process.whitelist=abc|windows_exporter"
1 | # 默认端口: 9115 |
1 | # 默认端口: 9125 |
1 | # - 使用 StatsD : 要将指标从现有的StatsD环境导入Prometheus,请配置StatsD的转发器后端,以将所有接收到的指标重复到statsd_exporter 流程中。 |
1 | # 默认端口: 9116 |
Tips : SNMP OID Tree 构成说明, SNMP由OID树构成,由MIB描述,OID子树在树中的不同位置具有相同的顺序。1
2
3
4# 数字是OID,括号中的名称是MIB的名称
1.3.6.1.2.1.2.2.1.1 (ifIndex)
1.3.6.1.2.1.2.2.1.2 (ifDescr)
1.3.6.1.2.1.31.1.1.1.10 (ifHCOutOctets)
Tips: Prometheus能够将SNMP索引实例映射到标签。例如ifEntry指定的INDEX ifIndex。这成为ifIndexPrometheus中的标签。
1 | # 默认端口: 9107 |
1 | # 默认端口: 9400 |
MySQL >= 5.6和MariaDB >= 10.2。1 | # 默认端口: 9104 |
补充说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# - mysqld_exporter参数配置文件
sudo tee /etc/mysqld_exporter.cnf'EOF'
[client]
user=mysql_exporter
password=123456
EOF
# - 将mysqld_exporter作为系统服务进行启动。
sudo tee /usr/lib/systemd/system/mysqld_exporter.service <<'EOF'
[Unit]
Description=MySQL exporter Clinet
Documentation=https://github.com/prometheus/mysqld_exporter
After=network.target
[Service]
Type=simple
StandardError=journal
ExecStart=/usr/local/bin/mysqld_exporter --config.my-cnf=/etc/mysqld_exporter.cnf
Restart=on-failure
RestartSec=3s
[Install]
WantedBy=multi-user.target
EOF
chmod 754 /usr/lib/systemd/system/mysqld_exporter.service
systemctl daemon-reload && systemctl enable mysqld_exporter.service && systemctl start mysqld_exporter.service && systemctl status mysqld_exporter
systemctl daemon-reload && systemctl restart mysqld_exporter.service && systemctl status mysqld_exporter
systemctl status mysqld_exporter
1 | # 默认端口: 9150 |
/metrics/exporter。1 | # 默认端口: 9122 |
Tips : 请注意Telegraf已经支持通过HTTP通过HTTP输出Prometheus度量标准 outputs.prometheus_client,从而避免了也必须运行influxdb_exporter。
Tips : 如果多次提交或多次采集了该指标,则只会存储最后一个值和时间戳。
1 | # 默认端口: 9108 / 9109 (Tcp|Udp) |
1 | # 默认端口: 9103 、25826(UDP) |
1 | # 默认端口: 9101 |
1 | # 默认端口: 8080 |
项目地址: https://github.com/prometheus/exporter-toolkit
Redis 2.x, 3.x, 4.x, 5.x, and 6.x项目地址: https://github.com/oliver006/redis_exporter/
命令行参数参考: https://github.com/oliver006/redis_exporter/#command-line-flags
1 | # Build && Run Binary |
Configuration && 配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 基本构型
scrape_configs:
- job_name: redis_exporter
static_configs:
- targets: ['localhost:9121']
# 配置刮多个Redis主机
# 使用命令行标志redis.addr=运行导出程序,这样它就不会在每次刮取/metrics端点时都尝试访问本地实例。
scrape_configs:
- job_name: 'redis_exporter_targets'
file_sd_configs:
- files:
- targets-redis-instances.yml
metrics_path: /scrape
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: <<REDIS-EXPORTER-HOSTNAME>>:9121
## config for scraping the exporter itself
- job_name: 'redis_exporter'
static_configs:
- targets:
- <<REDIS-EXPORTER-HOSTNAME>>:9121
# targets-redis-instances.yml
- targets: [ "redis://redis-host-01:6379", "redis://redis-host-02:6379" ]
"labels": { 'env': 'prod' }
补充说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16cat > /usr/lib/systemd/system/redis_exporter.service << EOF
[Unit]
Description=redis_exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/redis_exporter-v1.20.0.linux-amd64/redis_exporter -redis.addr=IP:6379 -redis.password=passwd
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
chmod 754 /usr/lib/systemd/system/redis_exporter.service
systemctl daemon-reload && systemctl enable redis_exporter .service && systemctl start redis_exporter .service && systemctl status redis_exporter
systemctl daemon-reload && systemctl restart redis_exporter .service && systemctl status redis_exporter
systemctl status redis_exporter
描述: Alertmanager处理客户端应用程序(如Prometheus服务器)发送的警报。它负责重复数据消除、分组,并将它们路由到正确的接收器集成,如电子邮件、PagerDuty或OpsGenie,同时它还负责沉默和抑制警报。
项目地址: https://github.com/prometheus/alertmanager
文档帮助: http://prometheus.io/docs/alerting/alertmanager/

weiyigeek.top-Alertmanager-组件架构
标签 在 Alertmanager 主要关键作用:
Alertmanager中设置Silences静默。简单流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 默认端口: 9093
# Install
# - Docker images
$ docker run --name alertmanager -d -p 127.0.0.1:9093:9093 quay.io/prometheus/alertmanager
# - Compiling the binary
$ mkdir -p $GOPATH/src/github.com/prometheus
$ cd $GOPATH/src/github.com/prometheus
$ git clone https://github.com/prometheus/alertmanager.git
$ cd alertmanager
$ make build
$ ./alertmanager --config.file=<your_file>
# Usage
usage: alertmanager [<flags>]
# (6) 补充系统服务进行启动alertmanager
sudo tee /usr/lib/systemd/system/alertmanager.service <<'EOF'
[Unit]
Description=Prometheus Alertmanager Server Systemd
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
StandardError=journal
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --web.listen-address=:9093 --storage.path=/monitor/alertmanager/data
Restart=on-failure
RestartSec=3s
[Install]
WantedBy=multi-user.target
EOF
sudo systemctl daemon-reload && systemctl restart alertmanager.service
启动参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28# 1 nobody 7:47 /bin/alertmanager --config.file=/etc/alertmanager.yaml --storage.path=/alertmanager
Flags:
--config.file="alertmanager.yml" Alertmanager configuration file name.
--storage.path="data/" Base path for data storage.
--data.retention=120h How long to keep data for.
--alerts.gc-interval=30m Interval between alert GC.
--web.external-url=WEB.EXTERNAL-URL The URL under which Alertmanager is externally reachable (for example, if Alertmanager is served via a reverse proxy). Used for generating relative and
absolute links back to Alertmanager itself. If the URL has a path portion, it will be used to prefix all HTTP endpoints served by Alertmanager. If omitted,
relevant URL components will be derived automatically.
--web.route-prefix=WEB.ROUTE-PREFIX Prefix for the internal routes of web endpoints. Defaults to path of --web.external-url.
--web.listen-address=":9093" Address to listen on for the web interface and API.
--web.get-concurrency=0 Maximum number of GET requests processed concurrently. If negative or zero, the limit is GOMAXPROC or 8, whichever is larger.
--web.timeout=0 Timeout for HTTP requests. If negative or zero, no timeout is set.
--cluster.listen-address="0.0.0.0:9094" Listen address for cluster. Set to empty string to disable HA mode.
--cluster.advertise-address=CLUSTER.ADVERTISE-ADDRESS Explicit address to advertise in cluster.
--cluster.peer=CLUSTER.PEER ... Initial peers (may be repeated).
--cluster.peer-timeout=15s Time to wait between peers to send notifications.
--cluster.gossip-interval=200ms Interval between sending gossip messages. By lowering this value (more frequent) gossip messages are propagated across the cluster more quickly at the expenseof increased bandwidth.
--cluster.pushpull-interval=1m0s Interval for gossip state syncs. Setting this interval lower (more frequent) will increase convergence speeds across larger clusters at the expense of ncreased bandwidth usage.
--cluster.tcp-timeout=10s Timeout for establishing a stream connection with a remote node for a full state sync, and for stream read and write operations.
--cluster.probe-timeout=500ms Timeout to wait for an ack from a probed node before assuming it is unhealthy. This should be set to 99-percentile of RTT (round-trip time) on your network.
--cluster.probe-interval=1s Interval between random node probes. Setting this lower (more frequent) will cause the cluster to detect failed nodes more quickly at the expense of increased bandwidth usage.
--cluster.settle-timeout=1m0s Maximum time to wait for cluster connections to settle before evaluating notifications.
--cluster.reconnect-interval=10s Interval between attempting to reconnect to lost peers.
--cluster.reconnect-timeout=6h0m0s Length of time to attempt to reconnect to a lost peer.
--log.level=info Only log messages with the given severity or above. One of: [debug, info, warn, error]
--log.format=logfmt Output format of log messages. One of: [logfmt, json]
--version Show application version.
Tips :amtool是用于与Alertmanager API交互的cli工具,它与Alertmanager的所有版本捆绑在一起。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# 1.Install
go get github.com/prometheus/alertmanager/cmd/amtool
# 2.Examples
# - 查看所有当前触发的警报:
$ amtool alert
Alertname Starts At Summary
Test_Alert 2017-08-02 18:30:18 UTC This is a testing alert!
Test_Alert 2017-08-02 18:30:18 UTC This is a testing alert!
Check_Foo_Fails 2017-08-02 18:30:18 UTC This is a testing alert!
Check_Foo_Fails 2017-08-02 18:30:18 UTC This is a testing alert!
# - 通过扩展输出查看所有当前触发的警报:
amtool -o extended alert
Labels Annotations Starts At Ends At Generator URL
alertname="Test_Alert" instance="node0" link="https://example.com" summary="This is a testing alert!" 2017-08-02 18:31:24 UTC 0001-01-01 00:00:00 UTC http://my.testing.script.local
# - 使用Alertmanager提供的丰富查询语法:
$ amtool -o extended alert query alertname="Test_Alert"
$ amtool -o extended alert query alertname=~"Test.*" instance=~".+1"
# - 暂停警报(Silence an alert)与查看静音的警报
$ amtool silence add alertname="Test_Alert" instance=~".+0"
$ amtool silence query
ID Matchers Ends At Created By Comment
b3ede22e-ca14-4aa0-932c-ca2f3445f926 alertname=Test_Alert 2017-08-02 19:54:50 UTC kellel
$ amtool silence query
# - 启动警报(也可以进行匹配启动)或者终止所有沉默
$ amtool silence expire b3ede22e-ca14-4aa0-932c-ca2f3445f926
$ amtool silence expire $(amtool silence -q query instance=~".+0")
$ amtool silence expire $(amtool silence query -q)
描述: PushGateway 作为 Prometheus 生态中的一个重要一员,它允许任何客户端向其 Push 符合规范的自定义监控指标,并且可以允许临时任务和批处理作业向 Prometheus 公开其指标,再结合 Prometheus 统一收集监控。例如被采集的主机由于网络环境的限制无法直接到达Prometheus server,因此可以将其指标推送到 Pushgateway ,然后在由 Pushgateway 将这些指标公开给 Prometheus,其次是在监控业务数据的时候需要将不同数据汇总, 由 Prometheus 统一收集。
项目地址: https://github.com/prometheus/pushgateway
应用场景: Prometheus 采用定时 Pull 模式,可能由于子网络或者防火墙的原因,不能直接拉取各个 Target 的指标数据,此时可以采用各个 Target 往 PushGateway 上 Push 数据,然后 Prometheus 去 PushGateway 上定时 pull。其次在监控各个业务数据时,需要将各个不同的业务数据进行统一汇总,此时也可以采用 PushGateway 来统一收集,然后 Prometheus 来统一拉取。
Pushgateway 架构说明:1
Batch Job - "Single push before exiting" -> Pushgateway <- "Regular Scrapes - Prometheus
Pushgateway 安装配置说明:
1 | # 默认端口:9091 |
Pushgateway 补充说明:
push_to_gateway / pushadd_to_gateway / delete_from_gateway等函数,或者利用http请求进行上传例如linux中curl(后面实战部分会进行讲解)。/metrics看到指标的HELP(对指标含义的描述)和TYPE(该指标的格式)。1 | # HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served. |
1 | prometheus_test_seconds_sum{label="bar",baz="qu"} 0 |
1 | # HELP : 下处是换行和反斜杠 |
1 | $ curl -s http://10.10.107.249:9091/metrics | promtool check metrics |
PushGateway 常用 RestFul 接口:
描述: 常用方法有POST/PUT以及DELETE格式为http://10.10.107.249:9091/metrics/job/{工作名称}/标签名称/标签内容,注意<工作名称>是job标签的值,后面跟任意数量的标签对,instance标签可以有也可以没有。
简单示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# - 1) Push a single sample(单个) into the group identified by {job="some_job"} 以及指定指标的参数标签:
echo "some_metric 3.14" | curl --data-binary @- http://10.10.107.249:9091/metrics/job/some_job
echo "some_metric 3.14" | curl --data-binary @- http://10.10.107.249:9091/metrics/job/some_job/labels/demo_test
# 输出结果
# # TYPE some_metric untyped # 注意这里的类型。
# some_metric{instance="",job="some_job",labels="demo_test"} 3.14
# - 2) Push something more complex (复杂多个) into the group identified by {job="some_job",instance="some_instance"}:
cat <<EOF | curl --data-binary @- http://10.10.107.249:9091/metrics/job/some_job/instance/some_instance
# TYPE some_metric counter
some_metric{label="val1"} 42
# TYPE another_metric gauge
# HELP another_metric Just an example.
another_metric 2398.283
EOF
# - 3) 删除由标识的组中的所有度量 {job="some_job",instance="some_instance"} :
curl -X DELETE http://10.10.107.249:9091/metrics/job/some_job/instance/some_instance
# - 4) 删除由标识的组中的所有指标{job="some_job"}(请注意{job="some_job",instance="some_instance"},即使这些指标具有相同的作业标签,该示例中也不包括该组中的指标):
curl -X DELETE http://10.10.107.249:9091/metrics/job/some_job
# - 5) 删除所有组中的所有指标(要求通过命令行标志启用admin API --web.enable-admin-api)
curl -X PUT http://10.10.107.249:9091/api/v1/admin/wipe
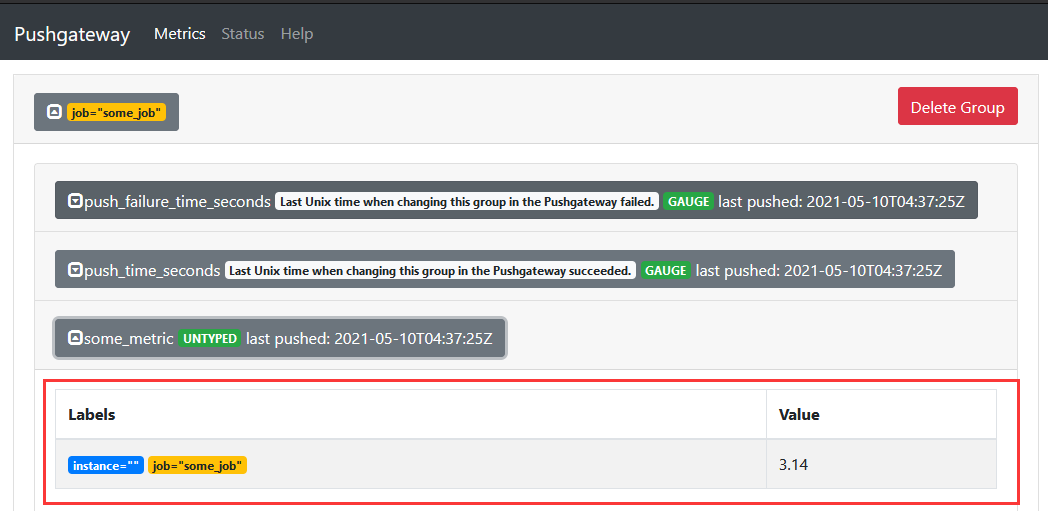
weiyigeek.top-利用CURL上传数据到pushgateway之中
Tips : Pushgateway显然不是聚合器或分布式计数器而是指标缓存,适用于服务级别指标。
Tips : Pushgateway必须被配置为一个目标,由Prometheus使用一种常用的方法进行抓取。但是您应该始终在scrape config中设置honor_labels: true
Tips : 为了防止 pushgateway 重启或意外挂掉,导致数据丢失,可以通过 -persistence.file 和 -persistence.interval 参数将数据持久化下来。
Tips : API所有的推送都是通过HTTP完成的界面有点像REST,例如:/metrics/job/<JOB_NAME>{/<LABEL_NAME>/<LABEL_VALUE>}, 参考地址:https://github.com/prometheus/pushgateway#api。
描述: 该配置文件为Prometheus的服务端配置文件,设置采集数据的主机以及采集器相关参数,在Prometheus启动时常常使用e --config.file 参数指定该配置文件的绝对路径。
帮助文档: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Tips : 该文件以YAML格式编写,由下面描述的方案定义。括号表示参数是可选的。对于非列表参数,该值设置为指定的默认值。
Configuration file 主要配置对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26* <scrape_config>
* <tls_config>
* <azure_sd_config>
* <consul_sd_config>
* <digitalocean_sd_config>
* <dockerswarm_sd_config>
* <dns_sd_config>
* <ec2_sd_config>
* <openstack_sd_config>
* <file_sd_config>
* <gce_sd_config>
* <hetzner_sd_config>
* <kubernetes_sd_config>
* <marathon_sd_config>
* <nerve_sd_config>
* <serverset_sd_config>
* <triton_sd_config>
* <eureka_sd_config>
* <scaleway_sd_config>
* <static_config>
* <relabel_config>
* <metric_relabel_configs>
* <alert_relabel_configs>
* <alertmanager_config>
* <remote_write>
* <remote_read>
Tips : 通用占位符定义如下:
<boolean>: a boolean that can take the values true or false<duration>: a duration matching the regular expression ((([0-9]+)y)?(([0-9]+)w)?(([0-9]+)d)?(([0-9]+)h)?(([0-9]+)m)?(([0-9]+)s)?(([0-9]+)ms)?|0), e.g. 1d, 1h30m, 5m, 10s<filename>: a valid path in the current working directory<host>: a valid string consisting of a hostname or IP followed by an optional port number<int>: an integer value<labelname>: a string matching the regular expression [a-zA-Z_][a-zA-Z0-9_]*<labelvalue>: a string of unicode characters<path>: a valid URL path<scheme>: a string that can take the values http or https<secret>: a regular string that is a secret, such as a password<string>: a regular string<tmpl_string>: a string which is template-expanded before usage1 | # - 全局配置指定在所有其他配置上下文中有效的参数 |
Tips : 文件必须包含使用以下格式的静态配置列表;1
2JSON json [ { "targets": [ "<host>", ... ], "labels": { "<labelname>": "<labelvalue>", ... } }, ... ]
YAML yaml - targets: [ - '<host>' ] labels: [ <labelname>: <labelvalue> ... ]
Tips : 在 Prometheus监控kubernetes允许从以下role之一方式进行目标的发现;
node : 为每个群集节点发现一个目标,其地址默认为Kubelet的HTTP端口,地址类型顺序: NodeInternalIP, NodeExternalIP, NodeLegacyHostIP, and NodeHostName.
1 | # Available meta labels: 此外instance节点的标签将设置为从API服务器检索到的节点名。 |
service : 为每个服务的每个服务端口发现一个目标。这对于服务的黑盒监视通常很有用。地址将设置为服务的Kubernetes DNS名称和相应的服务端口。
1 | __meta_kubernetes_namespace:服务对象的命名空间。 |
pod : 发现所有pod并将其容器作为目标公开。对于容器的每个声明端口,生成一个单独的目标。如果容器没有指定的端口,则为每个容器创建一个端口空闲目标,以便通过重新标记手动添加端口。
1 | __meta_kubernetes_namespace:pod对象的命名空间。 |
endpoints : 从服务的列出的终结点发现目标。对于每个endpointaddress,每个端口都会发现一个目标。如果端点由一个pod支持,那么pod的所有附加容器端口(未绑定到端点端口)也会被发现作为目标。
1 | __meta_kubernetes_namespace:endpoints对象的命名空间。 |
ingress : 为每个入口的每个路径发现一个目标。这通常对黑盒监控入口很有用地址将设置为入口规范中指定的主机。
1 | __meta_kubernetes_namespace:ingress对象的命名空间。 |
Tips : relabel_config 对象中<relabel_action>确定要执行的重新标记操作:
replace:匹配正则表达式针对串联的source_labels. 然后,集合目标_标签到replacement,具有匹配组引用(${1} ,${2},…)在替换被它们的价值所取代。如果regex不匹配,不进行替换keep为哪个目标删除正则表达式与连接的不匹配source_labels .drop为哪个目标删除正则表达式匹配连接的source_labels .hashmod:套目标_标签致modulus 连接的源代码标签 .labelmap:匹配正则表达式所有的标签名称,然后将匹配标签的值复制到replacement具有匹配组引用(${1} ,${2},…)在替换被它们的价值所取代labeldrop:匹配正则表达式所有的标签名称。任何匹配的标签都将从标签集中删除。labelkeep:匹配正则表达式所有的标签名称。任何不匹配的标签将从标签集中删除。必须小心labeldrop和labelkeep以确保一旦标签被移除,度量仍然是唯一的。
1 | # - 全局配置 |
2.2) kubernetes 集群监控服务发现配置: https://github.com/prometheus/prometheus/blob/release-2.26/documentation/examples/prometheus-kubernetes.yml
2.3) # - 补充: 实际工作任务示例19
1 | - job_name: 'prometheus' ###这个必须配置,这个地址抓取的所有数据会自动加上`job=prometheus`的标签 |
描述: Prometheus 在 2.0 版本以后已经提供了一个简单的管理接口,可以方便我们进行对Prometheus数据库的增删改查,注意如果要使用API就必须添加启动参数--web.enable-admin-api默认是关闭的。
下述是Prometheus常用的API RESTful接口示例,如果想要使用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# (1) 查询指定参数返回的指标名称和值
http://192.168.12.107:30090/api/v1/series?match[]=up
http://192.168.12.107:30090/api/v1/series?match[]={service_name=%22kube-state-metrics%22}
# (2) 查询指定标签的Values值
http://192.168.12.107:30090/api/v1/label/instance/values
# status "success"
# data […]
# (3) 删除tsdb中指定Job Name的metric
http://localhost:30090/api/v1/admin/tsdb/delete_series?match[]=up&match[]={job=~'kubernetes-kube-state'}"
# (4) 通过API接口进行重载Prometheus配置
http://localhost:30090/-/reload
描述: 该文件主要是记录(Recording)规则和警报(Alert)规则文件,将Prometheus服务端pull下来的监控指标参数进行匹配对比,如匹配上则报警或者例利用Alertmanager发送报警信息。
Prometheus 支持两种类型的规则可以配置然后定期评估:记录规则和警报规则, 要在Prometheus中包含规则请创建一个包含必要规则语句的文件, 并让Prometheus通过Prometheus配置中的rule_files字段加载该文件(YAML格式)。
Defining recording rules): 录制规则允许您预计算经常需要或计算代价高昂的表达式,并将其结果保存为一组新的时间序列。1 | # Syntax-checking rules |
Alerting rules):允许您基于 Prometheus expression语言表达式定义警报条件,并向外部服务发送有关触发警报的通知。每当警报表达式在给定的时间点产生一个或多个向量元素时,警报将对这些元素的标签集计为活动。1 | # Syntax |
1) Defining recording rules: A simple example rules file would be:
1 | groups: |
3) 实践环境中的报警规则
1 | groups: |
Tips : 规则检测频率时间是与全局变量中的evaluation_interval设置相关。
Tips : 标签和注释值可以使用控制台模板进行模板化。$labels变量保存警报实例的标签键/值对,可以通过$externalLabels变量访问配置的外部标签, $value变量保存警报实例的评估值。
Tips : 按照evaluation_interval配置该告警规则30s执行一次,如果持续for:2m即2分钟内收到数据则该警告会被触发,并且在达到设定得时间长度前该告警将处于pending状态。
描述: Alertmanager是通过命令行标志和配置文件配置的。当命令行标志配置不可变的系统参数时,配置文件定义禁止规则、通知路由和通知接收器(Prometheus的报警通知配置文件),要指定要加载的配置文件,请使用–config.file标志./alertmanager --config.file=alertmanager.yml。
Alertmanager.yml Configuration file 主要配置对象:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# - 全局配置: 包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
* <global>
* <http_config>
* <tls_config>
# - 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
* <route>
# - 抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)。
* <inhibit_rule>
* <templates>
# - 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
* <receiver>
* <email_config>
* <pagerduty_config>
* <image_config>
* <link_config>
* <pushover_config>
* <slack_config>
* <action_config>
* <field_config>
* <opsgenie_config>
* <responder>
* <victorops_config>
* <webhook_config>
* <wechat_config>
Tips: 通用占位符定义如下:
<duration>:与正则表达式匹配的持续时间 [0-9]+(ms|[smhdwy])<labelname>:与正则表达式匹配的字符串[a-zA-Z_][a-zA-Z0-9_]*<labelvalue>:一串unicode字符<filepath>:当前工作目录中的有效路径<boolean>:可以接受值的布尔值true或false<string>:常规字符串<secret>:是秘密的常规字符串,例如密码<tmpl_string>:使用前已模板扩展的字符串<tmpl_secret>:一个字符串,在使用前会进行模板扩展,这是一个秘密<int>:一个整数值1 | # - 全局配置指定在所有其他配置上下文中有效的参数,它们也可以作为其他配置部分的默认值。 |
1.官方示例: https://github.com/prometheus/alertmanager/blob/master/doc/examples/simple.yml
1 | global: |
2.自定义常用示例:
1 | global: |
Tips : 我们没有主动添加新的接收器,建议通过webhook接收器实现自定义通知集成。
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。