[TOC]
计算机科学导论学习笔记 第 5 部分 数据安全与人工智能 此部分包含第15、16、17和18章,包含了计算机中传输的数据压缩(有损与无损)、网络数据在传输过程中如何保证其数据安全, 讨论计算理论,即哪些是可计算的,哪些是不可计算的,最后介绍当前热门的人工智能(AI)的观点,加深我们对计算机数据处理的的认识,为后续学习扩展基础认识。
原文地址: https://mp.weixin.qq.com/s/PCYbGRpnGXycczaMMJz3-A
第15章 数据压缩 15.1 前言简述 近年来,随着计算机技术以及硬件设备技术飞速发展,改变了我们传输和存储数据的方式。
例如,光纤电缆使我们能更加快速地传输数据,DVD技术使得在较小物理媒介上存储大量的数据成为可能, 此时人们的要求也正逐渐增加。
敲黑板:压缩数据通过部分消除数据中内在的冗余来减少发送或存储的数据量。
当我们产生数据的同时,冗余也就产生了。通过数据压缩,提高了数据传输和存储的效率,同时保护了数据的完整性。
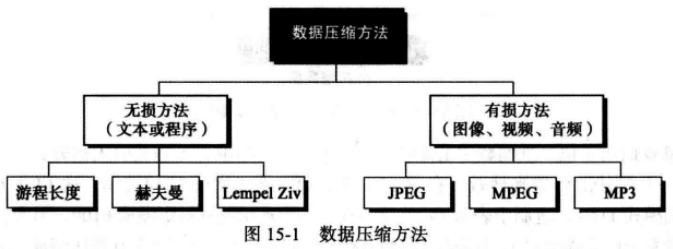
数据压缩意味着发送或是存储更少的位数,虽然有很多编码方式用于此目的,通常方法分为两大类无损压缩和有损压缩, 如下图所示两类以及每类中常用的一些方法。
weiyigeek.top-数据压缩方法
Q: 无损压缩和有损压缩有何区别?
15.2 无损压缩 Q: 什么是无损压缩?
无损压缩是一种数据存储技术,它可以把文件的大小缩小,同时保证文件的完整性和原始质量不变。
这是一种非常有用的技术,能够节省存储空间,减少上传和下载时间,还可以解决通过网络传输大文件时网络流量的问题。
简单的说: 在无损数据压缩中,数据的完整性是受到保护的,原始数据与压缩和解压后的数据完全一样。
常见三种无损压缩方法分别是 游程长度编码、赫夫曼编码 和 Lempel Ziv编码。
[TOC]
计算机科学导论学习笔记 第 5 部分 数据安全与人工智能 此部分包含第15、16、17和18章,包含了计算机中传输的数据压缩(有损与无损)、网络数据在传输过程中如何保证其数据安全, 讨论计算理论,即哪些是可计算的,哪些是不可计算的,最后介绍当前热门的人工智能(AI)的观点,加深我们对计算机数据处理的的认识,为后续学习扩展基础认识。
原文地址: https://mp.weixin.qq.com/s/PCYbGRpnGXycczaMMJz3-A
第15章 数据压缩 15.1 前言简述 近年来,随着计算机技术以及硬件设备技术飞速发展,改变了我们传输和存储数据的方式。
例如,光纤电缆使我们能更加快速地传输数据,DVD技术使得在较小物理媒介上存储大量的数据成为可能, 此时人们的要求也正逐渐增加。
敲黑板:压缩数据通过部分消除数据中内在的冗余来减少发送或存储的数据量。
当我们产生数据的同时,冗余也就产生了。通过数据压缩,提高了数据传输和存储的效率,同时保护了数据的完整性。
数据压缩意味着发送或是存储更少的位数,虽然有很多编码方式用于此目的,通常方法分为两大类无损压缩和有损压缩, 如下图所示两类以及每类中常用的一些方法。
weiyigeek.top-数据压缩方法
Q: 无损压缩和有损压缩有何区别?
15.2 无损压缩 Q: 什么是无损压缩?
无损压缩是一种数据存储技术,它可以把文件的大小缩小,同时保证文件的完整性和原始质量不变。
这是一种非常有用的技术,能够节省存储空间,减少上传和下载时间,还可以解决通过网络传输大文件时网络流量的问题。
简单的说: 在无损数据压缩中,数据的完整性是受到保护的,原始数据与压缩和解压后的数据完全一样。
常见三种无损压缩方法分别是 游程长度编码、赫夫曼编码 和 Lempel Ziv编码。
(1) 游程长度编码 它是最简单的压缩方法,可以用来压缩由任何符号组成的数据,它不需要知道字符出现频率的有关知识(赫夫曼编码则需要),并且当数据中由0和1表示时,该方式编码十分有效。
算法的大致思想是将数据中连续重复出现的符号用一个字符和这个字符重复的次数来代替。
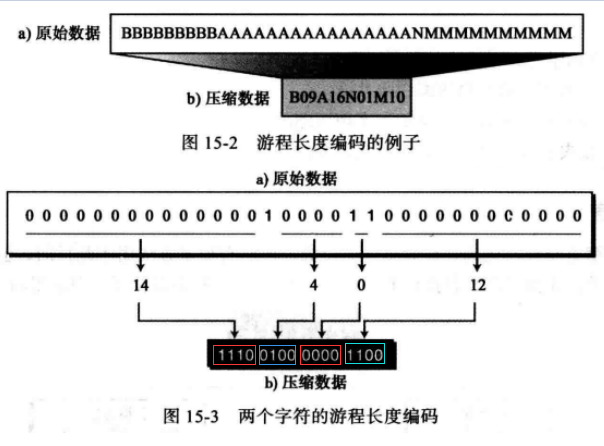
示例1 ,如AAAAAAAA可以用A08来代替,下图中显示此简单压缩方法,注意此处,我们使用固定位数(2位)的数字来表示数。示例2 ,在位模式中,如果数据只用两种符号(0和1),并且一种符号比另一种符号使用更为频繁,那么这种压缩方法就更有效。例如,假设一段数据里面有很多的0而1很少,那么,就可以通过在发送(或存储)时只标记在两个1中间有多少个0来减少数据的位数,注意此处,我们使用4位二进制数(无符号整数)计数。
weiyigeek.top-游程长度编码示例
温馨提示:用4位二进制压缩时,如果连续的0多于15个,它们将被分为2组或者更多的组。
总结:在游程长度编码中,重复出现的符号被该符号和表示该符号重复的数字所替换。
(2) 赫夫曼编码 赫夫曼编码是一种数据压缩编码技术,它利用变长编码来将信息转换成可编码的数据序列。它把比特表示为0或1,然后根据给定信息的出现次数以及其他一些给定的因素,来定义不同的编码长度。
例如,如果给定信息出现频率较高,则可以使用更短的编码,而较低频率的信息可以使用更长的编码。
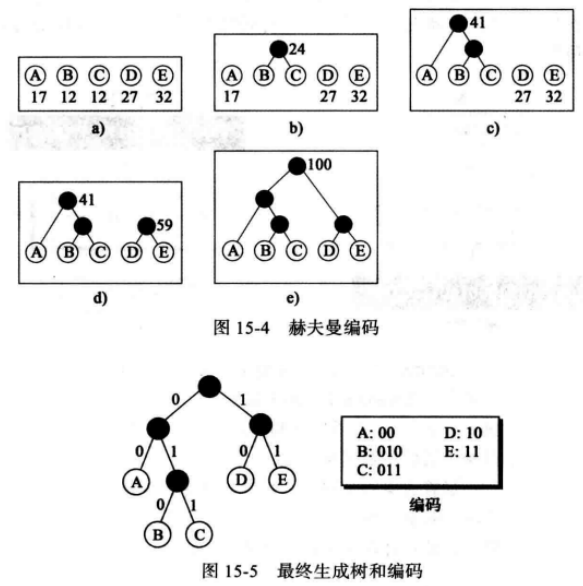
例如,假设有一篇文本文件只用到了5个字符(A, B, C, D, E),在给每个字符分配位模式前,首先根据每个字符的使用频率给它们分配相应的权值。
假定,字符A出现的频率为17%,字符B出现的频率为12%,字符C出现的频率为12%,字符D出现的频率为27%,字符E出现的频率为32%等
A - 17 , B - 12 , C - 12 , D - 27,E - 32;
一旦建立了各个字符的权值后,就可以根据这些值构造一棵树,它遵循以下三个基本步骤:
1)将全部字符排成一排。每个字符现在都是树的最底层节点。
2)找出权值最小的两个节点并由它们合成第三个节点,产生一棵简单的二层树。新节点的权值由最初的两个节点的权值结合而成。这个节点,在叶子节点的上一层,可以再与其他的节点结合。请记住,选择所结合的两个节点的权值和必须比其他所有可能的选择小。
3 )重复步骤2,直到各个层上的所有节点结合成为一棵树。
当树的构造完成后,利用它来给各个字符分配编码。
首先,给每个分支分配1位,从根(顶部节点)开始,给左分支分配0,给右分支分配1。
然后,在其他各个节点重复这一模式。
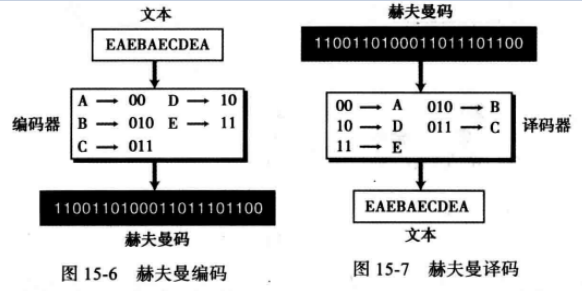
此时,字符的编码是这样得到的,首先从根开始,沿着分支到达字符所在的位置,该字符的编码就是所经过的路径上各分支位值的顺序排列。如下图所示,给出了最终的生成树和相对应的编码,注意我们移动了叶子节点以使整棵树更像一棵二叉树。
温馨提示: 频率高的字符(A、D和E)的编码要比出现频率低的字符(B和C)的编码短(层级少),此处可以通过比较分配给各个字符的编码适当的位长度看出。
其次,在这个编码系统中,没有一个编码是其他编码的前缀。图中2位编码00、10或者 11 都不是其他两种编码(010, 011)中任何一个的前缀。换句话说,不存在一个3位编码是以00、10或11开头的,这个特性使得赫夫曼编码是一种即时的编码,后续将会在讨论赫夫曼编码的编码和译码时解释这个问题。
1)编码 此处,假定也是使用5个字符的编码压缩文档,如下图所示是编码前后的文本EAEBAECDEA。
首先,注意,即使是这样小的不切实际的编码压缩也有其意义。如果想在不压缩成赫夫曼编码的情况下就发送这个文本,那么需要给每个字符一个3位编码,总共需传送30位,而用赫夫曼编码则只发送22位。
其次,注意,我们没有在每个字符的编码中间加上分隔符。我们只是一个接一个地写代码。赫夫曼编码的好处就是没有一个编码是其他编码的前缀,这样在编码过程中没有二义性,接收方接收到数据解压缩时也不会产生二义性。
2)解码(译码) 接收方译码十分容易,当接收方收到前2位数的时候,它不必等收到下一个位就可以译码。它知道应该译码为E。
其原因是,这两位不是任何3位码前缀(没有11开头的3位码)。同样,当接收方收到下两位时(00)时,它也知道应该翻译为A。再下两位以同样的方式翻译(11 一定是E)。然而,当收到第7和第8位时,计算机知道需要等下一位,因为编码01不在编码表里。当收到下一位(0)时,它将这3位连在一起(010)翻译为B。
这就是赫夫曼编码称为即时码的原因。译码器可以即时明确地翻译出编码(在最小位数下)。
总结: 在赫夫曼编码中,编码的长度是符号频率的函数,出现频率越高的符号相对于出现频率较低的符号编码长度越短(层级更浅)。
(3) Lempel Ziv 编码 Lempel-Ziv (LZ) 编码是由 Abraham Lempel 和 Jacob Ziv (用其开发者名字命名)在 1970 年代末开发的无损数据压缩算法的一类,此算法通常用于压缩和解压缩文件,如归档文件、图像和视频处理文件、文本和图形编辑文件以及音频和视频传输文件。该算法旨在通过创建一本密钥代码表来减少数据的大小,用于对数据进行编码和解码,这些代码是从数据本身生成的,通常用作熵编码的一种形式。
简单的说,该算法是基于字典的自适应编码的思想,在通信会话的时候它将产生一个字符串字典(一个表),如果接收和发送双方都有这样的字典,那么字符串可以由字典中的索引代替, 以减少通信的数据传输量。
尽管方案看似简单,但执行起来仍然有些困难。
首先,怎样为每一次通信会话产生一个字典(由于字符串的长度不定,很难找到通用的字典)?
其次,接收方怎样获得发送方的字典(如果同时发送字典,就增加了额外的数据,这样,与我们压缩的目的是相悖的)?
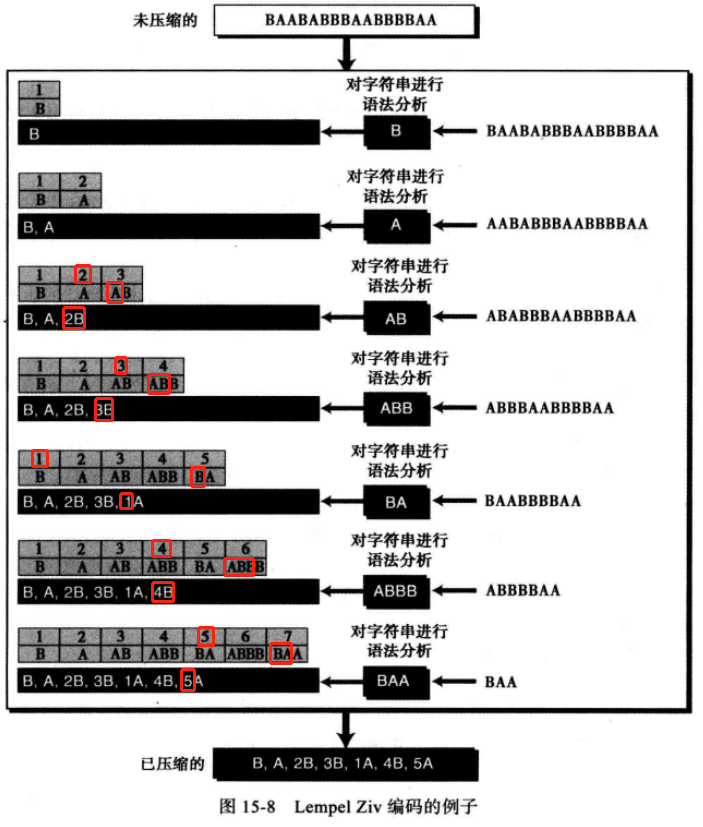
例如,针对 BAABABBBAABBBBAA 这个特殊的字符串进行讨论,使用LZ算法的简单版本,整个过程分为两个阶段,即压缩字符串和解压缩字符串。
1)压缩 此阶段,建立字典索引和压缩字符串。
首先,算法从未压缩的字符串中选取最小的子字符串,这些子字符串在字典中不存在。
然后,将这个子字符串复制到字典(作为一个新的记录)并为它分配一个索引值。压缩时,除了最后一个字母之外,其他所有字符被字典中的索引代替。
最后,将索引和最后一个字母插入压缩字符串,比如ABBB,在字典中找到ABB和它的索引4,得到的压缩字符串就是4B。
weiyigeek.top-Lempel-Ziv-编码示例
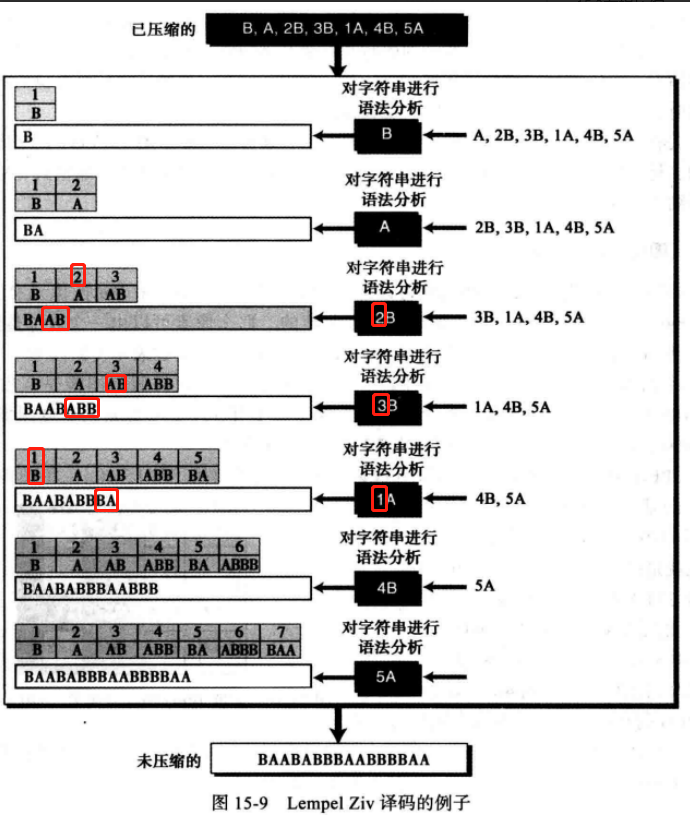
2)解压 解压是压缩的逆过程,该过程从压缩的字符串中取出子字符串,然后尝试按照字典中所列出的记录还原相应的索引号为对应的字符串。
字典开始为空,之后会逐渐地建立起来,该过程的总体思路是当一个索引号被接收时,在字典中已经存在了与其相应的记录。
weiyigeek.top-Lempel-Ziv 解码
总结:在LZ编码中,重复的字符串或字以变量形式保存,字符串或字用变量的索引号代替,LZ编码在接收方和发送方都需要一个字典和一个算法。
15.3 有损压缩 有损压缩是指在压缩文件的同时,会牺牲一部分文件的质量来节省存储空间,有损压缩的文件在解压缩后,质量会有损失,但这也是为了节省存储空间,所以有损压缩通常用于图像和音频文件。
常见三种有损压缩方法分别是联合图像专家组(JPEG)用来压缩图片和图像,运动图像专家组(MPEG)用来压缩视频,MPEG第三代音频压缩格式(MP3)则用来压缩声音。
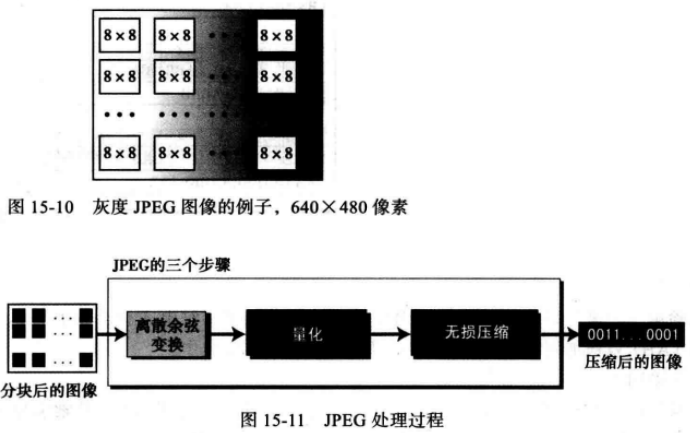
(1) 图像压缩-JPEG 通过前面学习,我们知道一幅图像可以通过一个二维数组(表)来表示图像元素(像素), 例如,在JPEG中,一幅灰度图像将被分成许多8X8的像素块,假设图片尺寸640(宽)X480(高)则像素为307 200。
然而,将图像划分成块的目的是考虑到减少计算量。显而易见,此时每幅图像的数学运算量是单元数的平方。也就是说,整个图像需要307 200^2次运算(94 371 840 000次运算),而如果使用JPEG则需要对每个块进行64^2次运算,总共是64^2X(640/8)X(480/8),即19 660 800 次运算,这将原来的运算量减少到4800分之一。
其图像处理简约过程如下所示:
weiyigeek.top-Jpeg处理过程
JPEG的整体思想是将图像变换成一个数的线性(矢量)集合来揭示冗余,这些冗余(缺乏变化的)可以通过使用前面学过的无损压缩的方法来除去。
1)离散余弦变换 Q: 什么是离散余弦变换?
离散余弦变换(Discrete Cosine Transform,DCT)是一类函数变换,可以将一个信号(或图像)转换为其傅里叶变换(或频域)的一种类似形式,即此种变换改变了64个值以使相邻像素之间的关系得以保持,但同时又能够揭示冗余。
它是一种非常高效的图像压缩技术,具有良好的信号表示性能。它的数学表达式为:
F[u][v] = 2/N * sum(sum(f[x][y]*cos[(2*x+1)*u*(pi/2*N)),(2*y+1)*v*(pi/2*N)))
其中,F[u][v]是变换后的矩阵,f[x][y]是原矩阵,N是矩阵的大小,u,v是矩阵的行和列号。
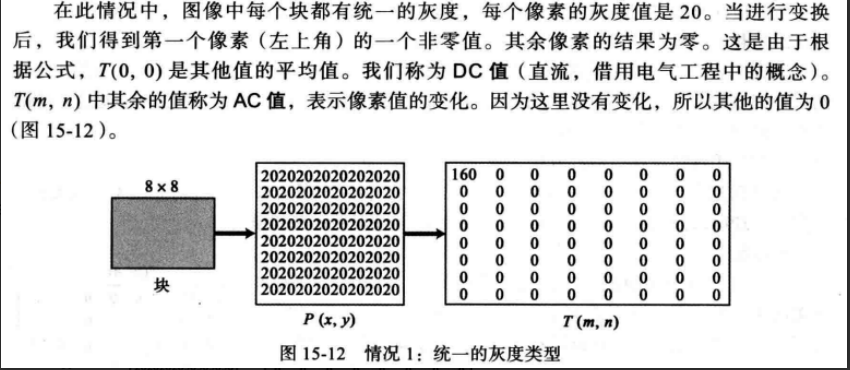
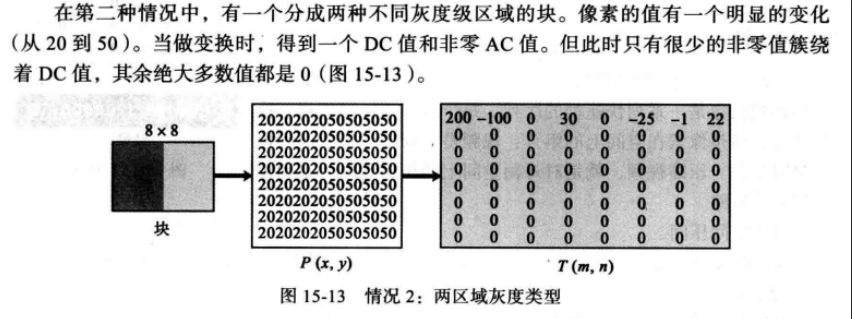
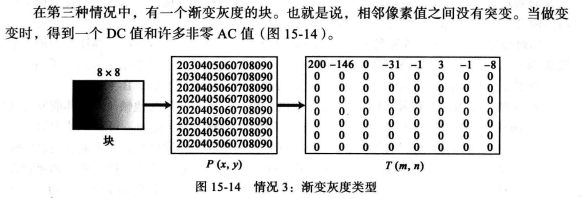
为了理解该变换的本质,让我们研究以下三种情况变换后的结果,其中P(x,y)定义了每个块上的值;T(m, n)则定义了变换后的块的值。
weiyigeek.top-情况1
weiyigeek.top-情况2
weiyigeek.top-情况3
从上述图中可知,转换从P表生成T表,DC值是像素的平均值,AC值显示变化,邻近像素缺少变化的生成0,但需要注意DCT是可逆的。
2)量化 生成T表后,这些值将被量化以减少需要编码的位数。量化过程用一个常量来除位数,然后舍弃小数部分。这样可以更加减少需要编码的位数。在大多数实现方法中,通过一张量化表(8X8 )定义了如何量化每个值,其中除数取决于T表位置上的值。这样做可以对每一个特殊的应用程序优化位数和0的个数。
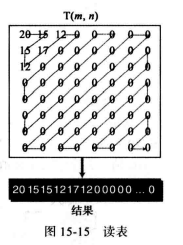
3)压缩 量化后,将表中的值读出并去掉多余的0。但是,为了把0 聚集起来,整个压缩过程以z字形按对角线读取表,而不是按行或列。原因是如果图像没有很好的变化,T表底部的右下角将全为0。
例如,下图所示JPEG在压缩阶段通常使用游程长度编码来压缩从Z字形线性化读取的位模式。
weiyigeek.top-压缩读表
总结:联合图像专家组(JPEG)是一种用来压缩图形和图像的方法,JPEG过程包括划分块、离散余弦变换、量化以及无损压缩。
(2) 视频压缩-MPEG 在讲解前,我们需要先了解视频压缩(减少文件大小)有那些方式,其大致如下:
降低视频的分辨率:主要通过降低水平和垂直像素分辨率来降低视频的分辨率,用较低的分辨率来表现相同的画面,节省视频文件的大小。
降低视频的帧率:也就是每秒钟播放多少张图像,通常情况下每秒钟播放的帧数越高,画面质量也越高,但是要想节省视频文件大小,可以选择降低帧率来节省视频的文件大小。
使用编码器压缩视频:视频文件随着视频画面的复杂性会变得越来越大,这种情况下可以使用编码器对视频进行压缩,通常可以采用H.264和H.265等编码器进行压缩,此方法可以明显地节省视频文件的大小。
空间与时间压缩 今天讲解的运动图像专家组(MPEG,Moving Picture Experts Group)属于其中之一,它是一种专业的图像和视频编码标准,其原理是视频每一帧每个帧都是一幅图像,帧是像素在空间上的组合,视频是一幅接一幅发送的帧的时间组合,而压缩视频,就是对每帧空间上的压缩和对一系列帧时间上的压缩。
空间压缩: 每一帧的空间压缩使用JPEG,每一帧都是一幅画可以独立压缩。
时间压缩: 在此压缩中多余的镇将被丢弃,一般来说,人类可以感知15-30帧每秒的视频,而视频编辑常用的标准是24-30帧每秒,所以大多数连续帧几乎是一样的。
例如,一个 20:1 的 Jpeg 压缩图像每帧需要发送 368 640 位,每秒 30 帧则需要传输11 059 200 bit/s,显然我们需要减少该数量。
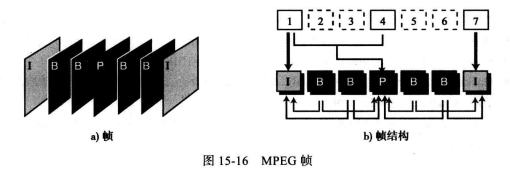
为了压缩时间数据,MPEG方法首先把帧分为三类:I-帧、P-帧、B-帧。
I-帧 :即内部编码(I-帧 ),是一个独立帧,该帧与任何其他帧(即在其前发送的帧或者在其后发送的帧)无关。它们以周期性间隔出现(比如:每9个帧中有一个I-帧)。I- 帧必须周期性出现,因为该帧的突然变化将使得其前面的帧和后面的帧不能正常显示。同样,当播放视频的时候,观众可能会随时调整接收机。如果仅仅在播放开始时有一个1- 帧,那么随后调整频道的观众将不能收到完整的画面。I-帧独立于其他帧之外,而且不能由其他帧构造。
P-帧:即预(P-帧)与前面的 I-帧或者P-帧有关联。话说,每个P-帧都从前面帧变化而来,不过变化不能覆盖大的部分。
例如,对于一个快速移动的目标,新变化也许没有记录在P-帧中,P-帧可以通过先前I-帧的或P-帧产生。P-帧携带的信息比其他类型的帧少,而且压缩后会更少。
B-帧:即双向帧(B-帧),与前面和后续的I-帧或P-帧有关系,换句话说,每个B顿都与过去和将来有关系,注意 B-帧不会与另一个 B -帧有关系。
下图显示了的样本序列以及它们是如何构造的,需注意一下译码,译码过程应该在 B-帧之前接收到 P-帧,基于这个原因,发送的顺序与它们显示在接收应用中的顺序不同。帧发送顺序为:I,P,B,B,P,B,B,I。
weiyigeek.top-MPEG帧
MPEG 编码过程 分为三个主要步骤:图像或视频的量化、分块和编码。
1.量化:将图像或视频信号采样,并将所得信号转换成数字,消除不必要的量化误差。
2.分块:将图像或视频划分为不同的块,以便于编码。
3.编码:使用现有的压缩算法和编码器,按照设定的标准,将分块的图像或视频信号压缩,生成最终的数据流。
MPEG 版本 上面我们讨论的是 MPEG-1版本,除此之外MPEG 有许多版本如下所示:
MPEG-1:用于CD存储
MPEG-2:用于DVD存储
MPEG-3:用于HDTV存储
MPEG-4:用于多媒体应用,支持包括视频和音频在内的多种媒体格式
MPEG-7:用于多媒体数据中提取信息和特征的标准,使用XML描述元数据和对视频中所含内容的描述的标准。
MPEG-21:用于在多媒体环境下分享和交换数据的标准
总结:运动图像专家组(MPEG)是一种用来压缩视频的方法,MPEG包括空间和时间压缩,前者和JPEG相似,后者则去掉了多余的帧。
(3) 音频压缩 音频压缩可以用来处理语音和音乐,对于语音,我们需要压缩一个64 kHz的数字化信号,而对于音乐我们需要压缩一个1.411 MHz的信号。
有两类技术用来进行音频压缩:预测编码和感知编码。
预测编码: 将样本间的差别被编码,而不是对所有的样本值进行编码,通常应用与语言之上,已经定义的标准有GSM (13 kbps)、G.729 (8 kbps)和G.723.3(6.4 kbps 或5.3 kbps)。
感知编码: 感知编码是基于心理声学的,心理声学是一门研究人类是如何感知声音的科学,用来创建CD质量音频最常用的压缩技术是基于感知编码技术的,此类型音频至少为1.411 Mbps,MP3 (MPEG第三代音频压缩格式,PS: 它是MPEG标准的一部分:card_index_dividers: )使用的就是这种技术,MP3使用这两种现象(频率掩盖和时间掩盖)来压缩音频信号,该技术分析音谱并把音谱分成几个组,0位被赋给了那些频率范围被完全掩盖的,小数值的位被赋给了那些频率范围部分被掩盖的。
例如,在一个有高音重金属演出的房间内,我们就不能听见我们舞伴的说话声。在时间掩盖中,一个高音可以短时间内降低我们听觉的灵敏度,甚至在声音停止之后。
MP3有三种速率:96 kbps、128 kbps和160 kbps,速率是基于原始模拟音频的频率范围的。
音频压缩方式
当前音频压缩方式有那些(PS:我们在前面第二章讨论过):
MP3(MPEG-1 Layer 3);
AAC(Advanced Audio Coding);
WMA(Windows Media Audio);
OGG(Ogg Vorbis);
FLAC(Free Lossless Audio Codec);
ALAC(Apple Lossless Audio Codec);
ATRAC3(Adaptive Transform Acoustic Coding 3);
WV(WavPack);
APE(Monkey’s Audio)。
总结: MPEG第三代音频压缩格式(MP3)是MPEG标准的一部分。MP3使用感知编码技术压缩CD质量音频。