[TOC]
0x00 快速入门
(1)外置模块一览表
描述:Python外置模块可以说是Python的强大之处的存在,使得Python语言扩展性高,使用方法众多并且使用也非常简单,在我们日常的运维开发学习中尤为重要;

[TOC]
(1)外置模块一览表
描述:Python外置模块可以说是Python的强大之处的存在,使得Python语言扩展性高,使用方法众多并且使用也非常简单,在我们日常的运维开发学习中尤为重要;
[TOC]
(1)外置模块一览表
描述:Python外置模块可以说是Python的强大之处的存在,使得Python语言扩展性高,使用方法众多并且使用也非常简单,在我们日常的运维开发学习中尤为重要;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#>>>dir(random) #查看与使用模块里的函数,前提必须引入模块,高阶用法 import 引入模块 as 模块别名;
#>>>help(random) #模块帮助
import urllib #网站请求模块
import lxml #xpath解析库模块 from lxml import etree
#表格Excel处理
import cvs #cvs表格模块
import xlwt #excel表格模块
import xlsxwriter #excel文件模块
#其他文章中介绍
import psutil #系统性能信息模块
import exifread #图片exif信息模块
import ruamel.yaml #YAML解析模块
import dnspython #DNS解析信息模块
import pycurl #web探测模块
urllib是一个包,下面有4个modules,主要进行网页请求;
文档地址
urllib.request 用于打开和读取url
urllib.error 包含由urllib.request引发的异常 (URLERROR(请求异常) -> HTTPERROR(网页响应码异常300~599))
urllib.parse 解析url
urllib.robotparser 用于解析robots.txt文件
案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55#语法
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None) #返回request配置请求的对象
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) #进行网站的请求
urllib.request.ProxyHandler(proxies=None) # 设置代理地址创建Proxyhandler 参数是一个字典 {'类型':'代理IP:端口'} 返回handler
urllib.request.build_opener([handler, ...]) # 创建Opener绑定代理资源,返回安装 opener开启工具对象
urllib.request.install_opener(opener) #安装Opener
#POST requestThe data argument must be a bytes object in standard application/x-www-form-urlencoded format;
urllib.parse.urlencode(data, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
urllib.parse.quote("网络安全") #解析中文URL
#案例
import urllib.request
import urllib.error
url = "http://weiyigeek.github.io"
data = {'action':'postValue'} #设置post请求参数
data = urllib.parse.urlencode(data).encode('utf-8') #等同于:application/x-www-form-urlencoded; charset=UTF-8
req = urllib.request.Request(url, data)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0') #设置请求头
#-----------------------------------------------------#
try:
res = urllib.request.urlopen("https://weiyigeek.github.io",context=ssl._create_unverified_context()) #支持SSL请求
print("请求URL:\n",res.geturl())
print("状态码:",res.getcode())
print("返回消息头:\n",res.info())
print("请求头信息:",req.headers) #注意这里是 Request() 类方法返回的对象
except HTTPError as e: #【注意】HTTPError 必须在URLError之上
print("服务器响应出错:",e.code)
print("打印出具体的错误页面",e.read().encode('utf-8'))
except URLError as e: # 包含了HTTPError
print("服务器链接失败:",e.reason)
else:
print("请求成功!")
############ 执行结果 ########################
# 请求URL:http://weiyigeek.github.io
# 状态码: 200
# 返回消息头:
# Server: nginx/1.15.9
# Date: Fri, 12 Apr 2019 10:57:51 GMT
# Content-Type: text/html; charset=utf-8
# Content-Length: 15278
# Last-Modified: Wed, 10 Apr 2019 01:12:59 GMT
# Connection: close
# ETag: "5cad431b-3bae"
# Accept-Ranges: bytes
# 请求头信息: {'User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0'}
使用xpath 必须首先下载lxml 库,xpath 只是一个元素选择器在python 的另外一个库lxml 中;
参考:https://cuiqingcai.com/2621.html1
2
3
4
5
6
7
8
9
10
11
12
13#使用pip进行下载lxml库
pip install lxml
from lxml import etree
##省略若干代码,dom_tree为我们解析之后的etree对象、
dom_tree = etree.HTML(html)
##语句一:
dom_tree.xpath('/html/body/div/a/@href')
##语句二:
dom_tree.xpath('//div/a/@href')
##语句二:
dom_tree.xpath('//div[@class="info-co"]/a/@href') 利用class属性
dom_tree.xpath('//div/a/@href') #将返回所有的链接网址
dom_tree.xpath('//div/a/text()') #将获取所有链接的名称
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#获取到request请求网站的html
dom_tree = etree.HTML(html)
links = dom_tree.xpath("//div/span[@class='info-col row2-text']/a") #返回一个xpath对象
for i in links:
print(i.text)
for index in range(len(links_yaoshi)):
print(index)
print(links[index].text)
print(links_yaoshi[index].text)
print(links_danjia[index].text)
# 一定注意 xpath 查找提取结果是可以用“|”来提取多个results, 所以最终的code 如下:
data = dom_tree.xpath("//div[@class='info-table']/li")
info = data[0].xpath('string(.)').extract()[0]
print(data[0].xpath('string(.)').strip()) # 只是打印第一行的结果
#值得学习
dataRes = dom_tree.xpath("//div/span[@class='info-col row2-text']/a | //div/span[@class='c-prop-tag2'] | //span[@class='info-col price-item minor']")
(1) csv.reader : 读取csv文件,返回的是迭代类型
(2) csv.writer(IO,dialect,delimiter):设置写入csv文件的模板
(3) DictReader:也是读取CSV文件,返回字典类型
(4) DictWriter:写入字典到CSV文件
(5) writerow:csv文件插入一行数据,把下面列表中的每一项放入一个单元格
案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51#!/usr/bin/python3
#python3使用csv模块读写csv文件
import csv
#案例1:输出数据写入CSV文件
data = [
("Mike", "male", 24),
("Lee", "male", 26),
("Joy", "female", 22)
]
data1 = [[x] for x in range(10) if x % 2 == 0]
data2 = ['测试','w','我是中文'] #字符间以,分割
#打开文件并设置模式用with打开可以不用去特意关闭file了
#Python3.4以后的新方式,解决空行问题
with open('demo.csv','w+',newline='',encoding='utf-8') as csvfile:
# dialect为打开csv文件的方式,默认是excel,delimiter="\t"参数指写入的时候的分隔符
csvwriter = csv.writer(csvfile,dialect=("excel"),delimiter=',')
for each in data:
print(">>>",each)
csvwriter.writerow(each)
csvwriter.writerow(data2) #写入一行之中
#csv文件插入一行数据,把下面列表中的每一项放入一个单元格(可以用循环插入多行)
csvwriter.writerow(["A","B","C","D"])
#案例2:打开csv文件读取数据
with open('demo.csv','r+',encoding='utf-8') as f:
res = csv.reader(f)
for x in res:
print(x[0])
#csv中有三列数据,遍历读取时使用三个变量分别对应
for title, year, director in reader:
list.append(year)
print(title, "; ", year , "; ", director)
with open("test.csv", "r", encoding = "utf-8") as f:
reader = csv.DictReader(f) #读取字典对象
column = [row for row in reader]
>python demo6.1.py
>>> ('Mike', 'male', 24)
>>> ('Lee', 'male', 26)
>>> ('Joy', 'female', 22)
Mike
Lee
Joy
测试
描述:对于execl表格数据的读取和写入插入删除等等,支丰富的计函数以及图表;
官网下载:http://pypi.python.org/pypi/xlwt
基础方法:1
2
3
4xlwt.Workbook(encoding = '编码格式')
workbook.add_sheet('表名称')
worksheet.write(0, 0, "写数据")
workbook.save('存储文件名称')
实际案例: weiyigeek.top-excel表格处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32#!/usr/bin/env python
# -*- coding: utf-8 -*-
import xlwt
def main():
workbook = xlwt.Workbook(encoding='utf-8') #创建workbook
worksheet = workbook.add_sheet('sheet名称') #创建workbook
#从0开始插入
worksheet.write(0, 0, 'Hello') # write_string()
worksheet.write(1, 0, 'World') # write_string()
worksheet.write(2, 0, 2) # write_number()
worksheet.write(3, 0, 3.00001) # write_number()
worksheet.write(4, 0, '=SIN(PI()/4)') # write_formula()
worksheet.write(5, 0, '') # write_blank()
worksheet.write(6, 0, None) # write_blank()
linenum = 7
#采用二维数组确定为主,往单元格内写入内容
worksheet.write(linenum, 0, "ID")
worksheet.write(linenum, 1, "根域名")
worksheet.write(linenum, 2, "绑定邮箱")
worksheet.write(linenum, 3, "DNS服务器1")
worksheet.write(linenum, 4, "DNS服务器2")
worksheet.write(linenum, 5, "状态")
#保存excel文档
workbook.save('Excel_Workbook.xls')
print("写入完成!")
if __name__ == '__main__':
main()
描述:操作EXCEL的xlsxwriterm模块,可以操作多个工作表的文字/数字/公式和图表等;
模块特点:
模块安装:1
2
3
4
5
6
7pip3 install xlsxwriter
#使用流程
1.创建excel文件对象
2.创建工作表对象
3.创建图表对象
4.定义excel的format格式对象
模块方法:1
2
3
4
5
6
7
8
9
10
11
12#1.workbook类
obj=Class.Workbook(filename[,options]) #该类创建一个XlsxWriter的Workbook对象,options为dict类型是可选参数,一般作为初始化工作表内容格式
worksheet=obj.dd_worksheet([sheetname]) #方法用于添加一个新的工作表,sheetname为工作表名称,默认是sheet1
format=obj.add_format([properties]) #方法用于在工作表中创建一个新的格式对象来格式化单元格 bold/normal
format.set_border(1) #定义format对象单元格边框加粗(1像素)的格式
format.set_bg_color('#999999') #定义对象的背景演示
format.set_blod() #显示粗体
format.set_num_format('0.00') #定义单元格边框加粗1像素的格式;
format.set_align('center')
chart=obj.add_chart(options) #用于在工作表中创建一个图表对象,内部是通过insert_chart()方法来实现的,参数为dict类型是为图标指定一个字典属性
obj.close() #作用是关闭工作表文件
1 | #2.Worksheet类: |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33#3.chart类实图表组件,支持包括面积、条形图、柱状图、折线图、散点图等
#一个图表对象是通过Workbook的add_chart方法创建,通过{type, ‘图表类型’}字典来制定图表类型
workbook.add_char({'type':"column"})
area:面积样式的图表
bar:条形图
column:柱状图
line:线条样式的图表
pie:饼形图
scatter:散点图
stock:股票样式的图表
radar:雷达样式的图表
#插入到指定位置
chart.add_series(options) #用于添加一个数据系列的图表参数options为字典类型,用于设置图表系列选项的字典
#常用方法:
categories:设置图表类别标签范围;
values:设置图表数据范围;
line:设置图表线条属性,包括宽度、颜色等;
name: "引用为图例表-即右方的柱形说明图"
#其他常用方法展示
chart.set_y_axis(options) #设置图表y轴小标题
chart.set_x_axis(options) #设置图表X轴小标题
# name:设置x轴名称
# name_font:设置x轴字体
# num_font:设置x轴数字字体属性;
chart.set_size(options) #设置图标大小{'width':'1024','height':768}
chart.set_title(options)#设置图表上方标题,参数options为字典类型,、用于设置图表系列选项的字典
chart.set_style(style_id)#用于设置图表样式,style_id为不同数字代表不同样式
chart.set_table(options) #设置x轴为数据表格式形式
worksheet.insert_chart(row,col,chartObj) #将设置的图表插入到工作簿中
简单示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28workbook = xlsxwriter.Workbook('Chart.xlsx')
worksheet =workbook.add_worksheet()
chart = workbook.add_chart({'type':'cloumn'})
format1 = workbook.add_format()
format1.set_border(1)
format2 = workbook.add_format()
format2.set_align('center')
worksheet.write_row('A1',写入的数据(单个字符/数组),format1) #从A1开始写入一行
worksheet.write_cloumn('A2',写入的数据(单个字符/数组),format2) #从A2开始写入一列)
for i in range(2,7)
worksheet.write_formula('I'+i,'=AVERAGE(B'+i+':H'+i+')'.format1) #从B2:H2的平均数
#对于图表添加数据也是一样的(重点之处)
chart.add_series({
'categories': '=Sheet1!B1:H1', #将作为图表x轴柱形下方说明
'values': '=Sheet1!$B$'+i+':$H$'+1, #图表数据区域赋值
'line': {'color': 'black'},
'name': u'引用为图例表-即右方的柱形说明图', #默认为系列1
})
chart.set_x_axis({'name':u' 星期数 '})
chart.set_y_axis({'name':u' Mb/s '})
worksheet.insert_chart('AB', chart)
workbook.close() #关闭文档
模块示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89#!/usr/bin/env python
# coding=utf-8
import xlsxwriter
#创建一个新的Excel文件并添加工作表
workbook = xlsxwriter.Workbook('demo.xlsx') #创建工作簿
#创建一个新的工作簿
worksheet1 = workbook.add_worksheet() #创建工作表 sheet1(默认表名称)
worksheet2 = workbook.add_worksheet('testSheet2') #创建工作表 testsheet2
#在工作表中创建一个新的格式对象来格式化单元格,实现加粗
bold = workbook.add_format({'bold': True}) #方式1
bold = workbook.add_format();bold.set_bold() #方式2
#数据写入到工作簿之中,注意:两种方式实际是一种只是别名而已可以采用 A1 和 (0,0) 方式定位
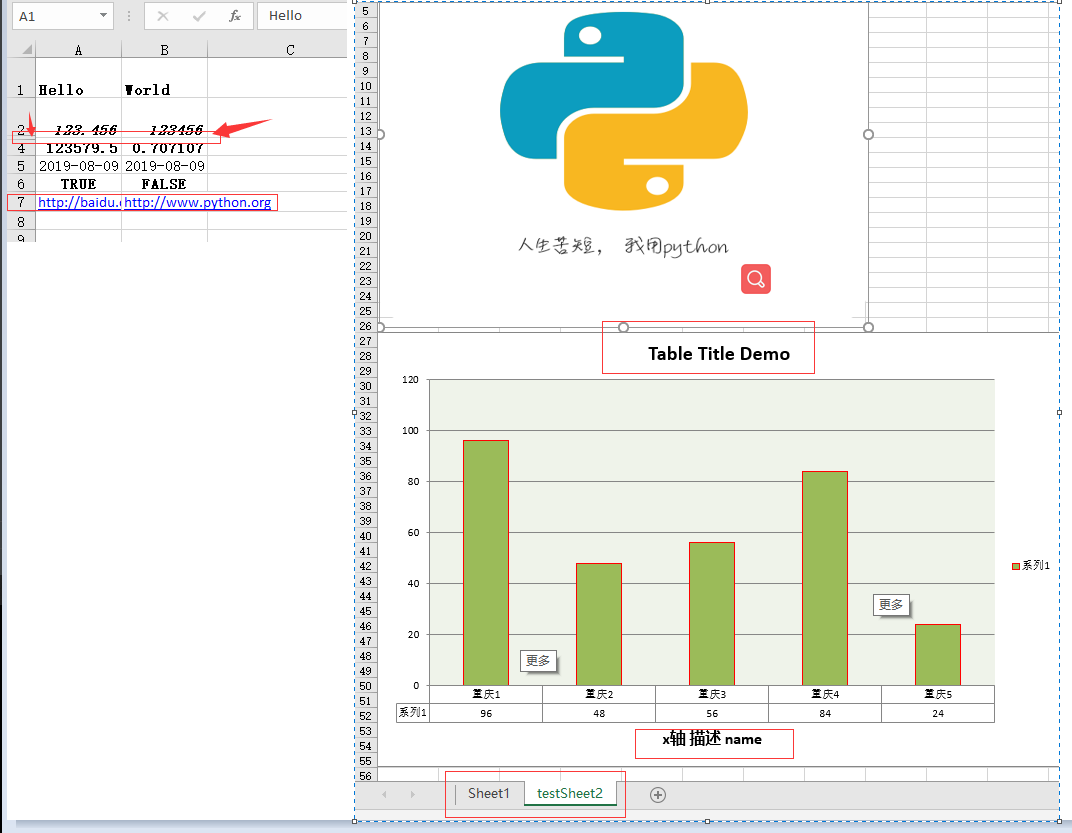
worksheet.write('A1', 'Hello') #总表写入简单文本
worksheet.write_string(0,1, 'World') #总表写入简单文本字符串类型数据
worksheet.write('A2', 123.456) #写入数字类型数据
worksheet.write_number(1, 1, 123456) #按照坐标写入
worksheet.write('A3', None) #写入空数据类型
worksheet.write_blank(2,1, '') #写入空数据类型
worksheet.write('A4', '=SUM(A1:B2)') #写入公式型数据
worksheet.write_formula(3,1, '=SIN(PI()/4)')
worksheet.write('A5', datetime.datetime.strftime('2019-08-09','y%-m%-d%'),workbook.add_format({'num_format': 'yyyy-mm-dd'})) #写入日期型数据
worksheet.write_datatime(4,1,datetime.datetime.strftime('2019-08-09','y%-m%-d%'),workbook.add_format({'num_format': 'yyyy-mm-dd'}))
worksheet.write('A6', True) #写入逻辑类型数据
worksheet.write_boolean(5,1, False)
worksheet.write('A7', 'http://baidu.com') #写入超链接数据类型
worksheet.write_url(6,1, 'http://www.python.org')
#设置一列或者多列单元属性
worksheet1.set_column(0, 1, 10, bold) #设定列A到B单元格宽度10像素加粗
worksheet1.set_column('C:D', 20) # 设置C到D单元格宽度20像素
worksheet1.set_column('E:G', None, None, {'hidden': 1}) #隐藏E到G单元格
#设置一行或者多行单元属性
worksheet1.set_row(0, 30,bold) #设置都1行单元个高度30像素定义加粗
worksheet1.set_row(1, 30,workbook,add_format({'italic':True})) #设置都1行单元个高度30像素定义斜体
worksheet1.set_row(6, None, None, {'hidden': 1}) #隐藏第6行
#在第二个单元簿地单元格插入python-logo.png图片超链接为http://python.org
worksheet2.insert_image('A1', 'python-logo.jpg', {'url': 'http://python.org'})
worksheet2.insert_image('A3', 'python-logo.jpg') #插入图片
#Char类图表示例
chart = workbook.addchart({type,'column'}) #创建一个column(柱形)图标
#为图表添加数据
chart.add_series({
'categories': '=testSheet2!$A$1:$A$5',
'values': '=testSheet2!$B$1:$B3',
'line': {'color': 'red'},
'name':
})
#设置图表X轴显示
chart.set_x_axis({
'name': 'x name',
'name_font': {'size': 14, 'bold': True}
'num_font': {'italic': True}
})
#设置x轴为数据表格式
chart.set_table()
#图表大小
chart.set_size({'width': 720, 'height': 576})
#图表标题
chart.set_title({'name':"Table Title Demo"})
#图表样式
chart.set_style(37)
#插入图表到工作簿中
worksheet2.insert_chart('A7', chart)
workbook.close() #关闭工作薄
weiyigeek.top-
PDFMiner是一个专注于从PDF文档中提取、分析文本信息的工具。它不仅可以获取特定页码特定位置处的信息,也能获得字体等信息。
安装模块说明:1
2
3
4
5
6#首先安装PDFMiner,注意Python3要安装pdfminer3k
#Windows下面安装pdfminer3k
pip install pdfminer3k
#Linux下面安装pdfminer
pip install pdfminer
工作原理图: weiyigeek.top-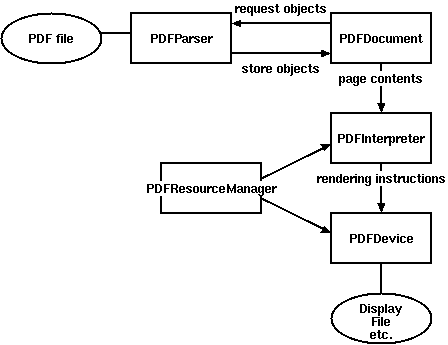
解析pdf文件用到的类:
Layout布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象形成一个树结构。
如图所示: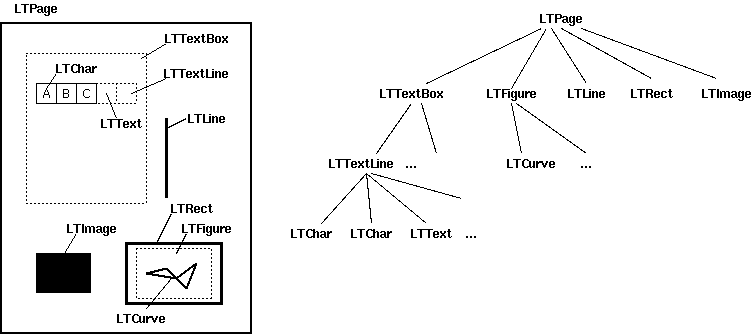
LTPage :表示整个页可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象。
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/编程世界/Python/模块函数/Python3外置模块使用.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/3-20-343.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议