[TOC]
0x01 Redis 运行模式 Redis 哨兵模式 描述: 哨兵模式是主从的升级版,因为主从的出现故障后,不会自动恢复,需要人为干预,这就很蛋疼啊。在主从的基础上,实现哨兵模式就是为了监控主从的运行状况,对主从的健壮进行监控,就好像哨兵一样,只要有异常就发出警告,对异常状况进行处理。
Sentinel 介绍 描述: Redis从2.8开始发布了一个稳定版本的Redis Sentinel 。当前版本的 Sentinel 称为Sentinel 2。它是使用更强大和更简单的预测算法来重写初始Sentinel实现。
Redis Sentinel 是一个分布式系统,Redis Sentinel为Redis提供高可用性。可以在没有人为干预的情况下 阻止某种类型的故障。
Redis Sentinel 是redis的高可用实现方案,在实际生产环境中,对提高整个系统可用性是非常有帮助的。
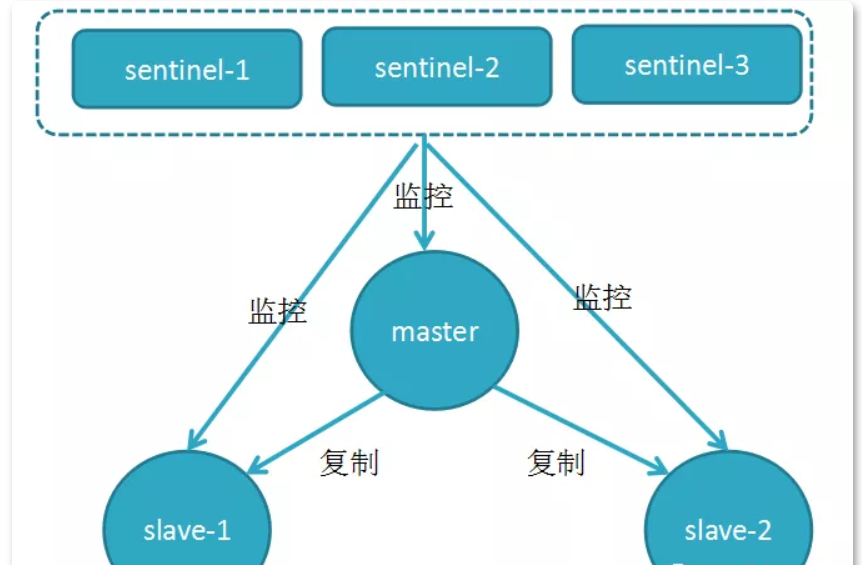
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。提醒(Notification): 当被监控的某个 Redis 服务器出现问题时,Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。自动故障迁移(Automatic failover):如果 master 没有按预期工作,Sentinel 可以启动一个故障转移过程,其中一个副本被提升为 master,其他额外的副本被重新配置为使用新的 master,并且使用 Redis 服务器的应用程序会被告知要使用的新地址连接时配置提供程序: Sentinel 充当客户端服务发现的权威来源:客户端连接到 Sentinel 以请求负责给定服务的当前 Redis 主节点的地址。如果发生故障转移,Sentinels 将报告新地址。
默认情况下,Sentinel 使用 TCP 端口 26379 运行(请注意,6379 是普通的 Redis 端口)。Sentinel 接受使用 Redis 协议的命令,因此您可以使用redis-cli或任何其他未修改的 Redis 客户端来与 Sentinel 对话。并且可以直接查询 Sentinel 以从其角度检查受监控 Redis 实例的状态,查看它知道的其他 Sentinel,等等。
Sentinel 高可用性 描述: 当主节点出现故障时redis sentinel 能自动完成故障发现和故障转移,并通知客户端从而实现真正的高可用。
Redis Sentinel是一个分布式架构,其中包含N个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其他Sentinel节点进行监控, 当它返现节点不可达时,会对节点做下线标识,如果被标识的是主节点,它还会和其他Sentinel及诶单进行“协商”,当大多数节点都认为主 节点不可达时,会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给redis的客户端,整个过程是自动的不需要人工干预,有效的解决了redis的高可用问题。
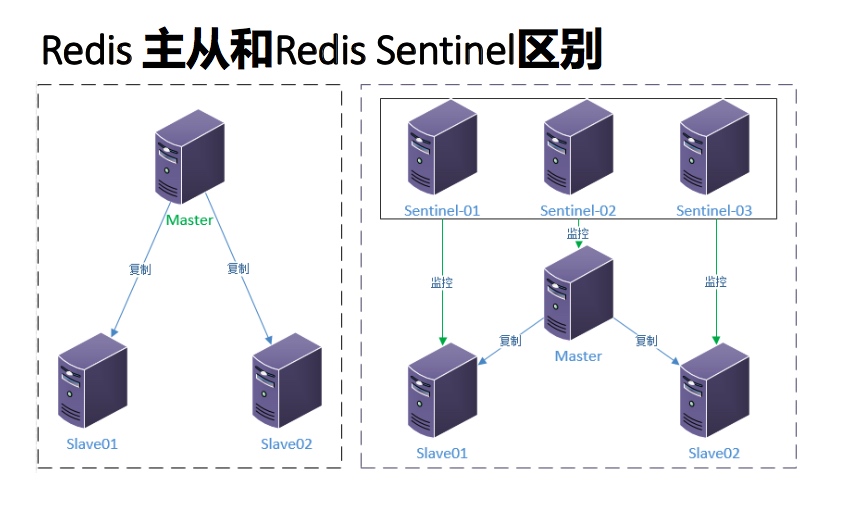
Redis 主从和Redis Sentinel 区别
同时看出,Redis Sentinel包含多个Sentinel节点,这样做带来两个好处:
对于节点的故障判断是由多个节点共同完成,这样可以有效的防止误判断
多个Sentinel节点出现个别节点不可用,也不会影响客户端的访问
Sentinel的仲裁会
不过,当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover。Objectively Down时,failover被触发后将尝试去进行failover的sentinel会去获得“大多数”sentinel的授权(如果票数比大多数还要大的时候,则询问更多的sentinel)
例如,当集群中有 5个sentinel 票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
如果票数被设置为5,要达到ODOWN状态,必须所有5个sentinel都主观认为master为不可用,要进行failover,那么得获得所有5个sentinel的授权。
weiyigeek.top-简单图示
选举算法
原来哨兵中首先选举出一个老大哨兵来进行故障恢复,选举老大哨兵的算法叫做「Raft算法」:
发现master下线的哨兵(sentinelA)会向其它的哨兵发送命令进行拉票,要求选择自己为哨兵大佬。
若是目标哨兵没有选择其它的哨兵,就会选择该哨兵(sentinelA)为大佬。
若是选择sentinelA的哨兵超过半数(半数原则),该大佬非sentinelA莫属。
如果有多个哨兵同时竞选,并且可能存在票数一致的情况,就会等待下次的一个随机时间再次发起竞选请求,进行新的一轮投票,直到大佬被选出来。
选出大佬哨兵后,大佬哨兵就会对故障进行自动回复,从slave中选出一名slave作为主数据库,选举的规则如下所示:
1) 所有的slave中slave-priority优先级最高的会被选中。
2) 若是优先级相同,会选择偏移量最大的,因为偏移量记录着数据的复制的增量,越大表示数据越完整。
3) 若是以上两者都相同,选择ID最小的。
Tips: 通过以上的层层筛选最终实现故障恢复,当选的slave晋升为master,其它的slave会向新的master复制数据,若是down掉的master重新上线,会被当作slave角色运行。
配置版本号
保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
节点通信 _sentinel_:hello频道。
该频道用于获取监控该master的其它哨兵的信息,并且还会建立一条定时向master发送INFO命令获取master信息的连接。
「当哨兵与master建立连接后,定期会向(10秒一次)master和slave发送INFO命令,若是master被标记为主观下线,频率就会变为1秒一次。」
但是一个faiover要想被成功实行的前提,sentinel必须能够向选为master的slave发送SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
并且,定期向_sentinel_:hello频道发送自己的信息,以便其它的哨兵能够订阅获取自己的信息,发送的内容包含「哨兵的ip和端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本」等信息。
以及,「定期的向master、slave和其它哨兵发送PING命令(每秒一次),以便检测对象是否存活」,若是对方接收到了PING命令,无故障情况下,会回复PONG命令。
所以,哨兵通过建立这两条连接、通过定期发送INFO、PING命令来实现哨兵与哨兵、哨兵与master之间的通信。
例子说明,假设有一个名为mymaster的地址为192.168.56.11:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。如果failover成功了,假设地址改为了192.168.56.12:6279,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel,由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
重要的事情说明三遍:
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
Tips: 这里涉及到一些概念需要理解,INFO、PING、PONG等命令,后面还会有MEET、FAIL命令,以及主观下线,当然还会有客观下线,这里主要说一下这几个概念的理解:
INFO:该命令可以获取主从数据库的最新信息,可以实现新结点的发现
PING:该命令被使用最频繁,该命令封装了自身节点和其它节点的状态数据。
MEET:该命令在新结点加入集群的时候,会向老节点发送该命令,表示自己是个新人
PONG:当节点收到MEET和PING,会回复PONG命令,也把自己的状态发送给对方。
FAIL:当节点下线,会向集群中广播该消息。
SLAVEOF NO ONE: 不属于任何节点的从节点。
上线和下线
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
Sentinel(哨兵) 与 master会定期一直保持联系,若是某一时刻哨兵发送的PING在指定时间内没有收到回复(配置sentinel down-after-milliseconds master-name milliseconds 字段),那么发送PING命令的哨兵就会认为该master「主观下线」(Subjectively Down)。
当sentinel发送PING后,以下回复之一都被认为是合法的, 除此之外其它任何回复(或者根本没有回复)都是不合法的。
[TOC]
0x01 Redis 运行模式 Redis 哨兵模式 描述: 哨兵模式是主从的升级版,因为主从的出现故障后,不会自动恢复,需要人为干预,这就很蛋疼啊。在主从的基础上,实现哨兵模式就是为了监控主从的运行状况,对主从的健壮进行监控,就好像哨兵一样,只要有异常就发出警告,对异常状况进行处理。
Sentinel 介绍 描述: Redis从2.8开始发布了一个稳定版本的Redis Sentinel 。当前版本的 Sentinel 称为Sentinel 2。它是使用更强大和更简单的预测算法来重写初始Sentinel实现。
Redis Sentinel 是一个分布式系统,Redis Sentinel为Redis提供高可用性。可以在没有人为干预的情况下 阻止某种类型的故障。
Redis Sentinel 是redis的高可用实现方案,在实际生产环境中,对提高整个系统可用性是非常有帮助的。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。提醒(Notification): 当被监控的某个 Redis 服务器出现问题时,Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。自动故障迁移(Automatic failover):如果 master 没有按预期工作,Sentinel 可以启动一个故障转移过程,其中一个副本被提升为 master,其他额外的副本被重新配置为使用新的 master,并且使用 Redis 服务器的应用程序会被告知要使用的新地址连接时配置提供程序: Sentinel 充当客户端服务发现的权威来源:客户端连接到 Sentinel 以请求负责给定服务的当前 Redis 主节点的地址。如果发生故障转移,Sentinels 将报告新地址。
默认情况下,Sentinel 使用 TCP 端口 26379 运行(请注意,6379 是普通的 Redis 端口)。Sentinel 接受使用 Redis 协议的命令,因此您可以使用redis-cli或任何其他未修改的 Redis 客户端来与 Sentinel 对话。并且可以直接查询 Sentinel 以从其角度检查受监控 Redis 实例的状态,查看它知道的其他 Sentinel,等等。
Sentinel 高可用性 描述: 当主节点出现故障时redis sentinel 能自动完成故障发现和故障转移,并通知客户端从而实现真正的高可用。
Redis Sentinel是一个分布式架构,其中包含N个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其他Sentinel节点进行监控, 当它返现节点不可达时,会对节点做下线标识,如果被标识的是主节点,它还会和其他Sentinel及诶单进行“协商”,当大多数节点都认为主 节点不可达时,会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给redis的客户端,整个过程是自动的不需要人工干预,有效的解决了redis的高可用问题。
Redis 主从和Redis Sentinel 区别
同时看出,Redis Sentinel包含多个Sentinel节点,这样做带来两个好处:
对于节点的故障判断是由多个节点共同完成,这样可以有效的防止误判断
多个Sentinel节点出现个别节点不可用,也不会影响客户端的访问
Sentinel的仲裁会
不过,当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover。Objectively Down时,failover被触发后将尝试去进行failover的sentinel会去获得“大多数”sentinel的授权(如果票数比大多数还要大的时候,则询问更多的sentinel)
例如,当集群中有 5个sentinel 票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
如果票数被设置为5,要达到ODOWN状态,必须所有5个sentinel都主观认为master为不可用,要进行failover,那么得获得所有5个sentinel的授权。
weiyigeek.top-简单图示
选举算法
原来哨兵中首先选举出一个老大哨兵来进行故障恢复,选举老大哨兵的算法叫做「Raft算法」:
发现master下线的哨兵(sentinelA)会向其它的哨兵发送命令进行拉票,要求选择自己为哨兵大佬。
若是目标哨兵没有选择其它的哨兵,就会选择该哨兵(sentinelA)为大佬。
若是选择sentinelA的哨兵超过半数(半数原则),该大佬非sentinelA莫属。
如果有多个哨兵同时竞选,并且可能存在票数一致的情况,就会等待下次的一个随机时间再次发起竞选请求,进行新的一轮投票,直到大佬被选出来。
选出大佬哨兵后,大佬哨兵就会对故障进行自动回复,从slave中选出一名slave作为主数据库,选举的规则如下所示:
1) 所有的slave中slave-priority优先级最高的会被选中。
2) 若是优先级相同,会选择偏移量最大的,因为偏移量记录着数据的复制的增量,越大表示数据越完整。
3) 若是以上两者都相同,选择ID最小的。
Tips: 通过以上的层层筛选最终实现故障恢复,当选的slave晋升为master,其它的slave会向新的master复制数据,若是down掉的master重新上线,会被当作slave角色运行。
配置版本号
保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
节点通信 _sentinel_:hello频道。
该频道用于获取监控该master的其它哨兵的信息,并且还会建立一条定时向master发送INFO命令获取master信息的连接。
「当哨兵与master建立连接后,定期会向(10秒一次)master和slave发送INFO命令,若是master被标记为主观下线,频率就会变为1秒一次。」
但是一个faiover要想被成功实行的前提,sentinel必须能够向选为master的slave发送SLAVEOF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
并且,定期向_sentinel_:hello频道发送自己的信息,以便其它的哨兵能够订阅获取自己的信息,发送的内容包含「哨兵的ip和端口、运行id、配置版本、master名字、master的ip端口还有master的配置版本」等信息。
以及,「定期的向master、slave和其它哨兵发送PING命令(每秒一次),以便检测对象是否存活」,若是对方接收到了PING命令,无故障情况下,会回复PONG命令。
所以,哨兵通过建立这两条连接、通过定期发送INFO、PING命令来实现哨兵与哨兵、哨兵与master之间的通信。
例子说明,假设有一个名为mymaster的地址为192.168.56.11:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。如果failover成功了,假设地址改为了192.168.56.12:6279,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel,由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
重要的事情说明三遍:
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
Tips: 这里涉及到一些概念需要理解,INFO、PING、PONG等命令,后面还会有MEET、FAIL命令,以及主观下线,当然还会有客观下线,这里主要说一下这几个概念的理解:
INFO:该命令可以获取主从数据库的最新信息,可以实现新结点的发现
PING:该命令被使用最频繁,该命令封装了自身节点和其它节点的状态数据。
MEET:该命令在新结点加入集群的时候,会向老节点发送该命令,表示自己是个新人
PONG:当节点收到MEET和PING,会回复PONG命令,也把自己的状态发送给对方。
FAIL:当节点下线,会向集群中广播该消息。
SLAVEOF NO ONE: 不属于任何节点的从节点。
上线和下线
主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
Sentinel(哨兵) 与 master会定期一直保持联系,若是某一时刻哨兵发送的PING在指定时间内没有收到回复(配置sentinel down-after-milliseconds master-name milliseconds 字段),那么发送PING命令的哨兵就会认为该master「主观下线」(Subjectively Down)。
当sentinel发送PING后,以下回复之一都被认为是合法的, 除此之外其它任何回复(或者根本没有回复)都是不合法的。1 2 3 * PING replied with +PONG. * PING replied with -LOADING error. * PING replied with -MASTERDOWN error.
有时 哨兵 与 master 之间的网络问题造成收发中断,而不是master本身的原因,所以哨兵同时会询问其它的哨兵是否也认为该master下线,若是认为该节点下线的哨兵达到一定的数量(「配置的quorum字段」),就会认为该节点「客观下线」(Objectively Down)。
从SDOWN切换到ODOWN不需要任何一致性算法,只需要一个gossip协议:如果一个sentinel收到了足够多的sentinel发来消息告诉它某个master已经down掉了,SDOWN状态就会变成ODOWN状态。如果之后master可用了,这个状态就会相应地被清理掉。
正如之前已经解释过了,真正进行failover需要一个授权的过程,但是所有的failover都开始于一个ODOWN状态。
ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
若是没有足够数量的sentinel同意该master下线,则该master客观下线的标识会被移除;若是master重新向哨兵的PING命令回复了客观下线的标识也会被移除。
每个 Sentinel 都需要定期执行的任务
每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主管下线状态就会被移除。
Sentinel之间和Slaves之间的自动发现机制
因为sentinel利用了master的发布/订阅机制(__sentinel__:hello)去自动发现其它也监控了统一master的sentinel节点。
同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的 __sentinel__:hello 频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。
每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的__sentinel__:hello频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。 当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel * 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。
Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
网络隔离时的一致性
描述: redis sentinel集群的配置的一致性模型为最终一致性,集群中每个sentinel最终都会采用最高版本的配置。然而,在实际的应用环境中,有三个不同的角色会与sentinel打交道: Redis实例/Sentinel实例/客户端
为了考察整个系统的行为我们必须同时考虑到这三个角色。
下面有个简单的例子,有三个主机,每个主机分别运行一个redis和一个sentinel:
1 2 3 4 5 6 7 8 9 10 +-------------+ | Sentinel 1 | <--- Client A | Redis 1 (M) | +-------------+ | | +-------------+ | +------------+ | Sentinel 2 |-----+-- / partition / ----| Sentinel 3 | <--- Client B | Redis 2 (S) | | Redis 3 (M)| +-------------+ +------------+
在这个系统中,初始状态下redis3是master, redis1和redis2是slave。之后redis3所在的主机网络不可用了,sentinel1和sentinel2启动了failover并把redis1选举为master。
Sentinel集群的特性保证了sentinel1和sentinel2得到了关于master的最新配置。但是sentinel3依然持着的是就的配置,因为它与外界隔离了。
当网络恢复以后,我们知道sentinel3将会更新它的配置。但是,如果客户端所连接的master被网络隔离,会发生什么呢?
客户端将依然可以向redis3写数据,但是当网络恢复后,redis3就会变成redis的一个slave,那么,在网络隔离期间,客户端向redis3写的数据将会丢失。
也许你不会希望这个场景发生:
如果你把redis当做缓存来使用,那么你也许能容忍这部分数据的丢失。
1 2 3 4 5 6 7 # redis.conf # min-replicas-to-write 3 # min-replicas-max-lag 10 # By default min-replicas-to-write is set to 0 (feature disabled) and min-slaves-to-write 1 min-slaves-max-lag 10
通过上面的配置,当一个redis是master时,如果它不能向至少一个slave写数据(上面的min-slaves-to-write指定了slave的数量),它将会拒绝接受客户端的写请求。由于复制是异步的,master无法向slave写数据意味着slave要么断开连接了,要么不在指定时间内向master发送同步数据的请求了(上面的min-slaves-max-lag指定了这个时间)。
故障转移步骤
一次故障转移操作由以下步骤组成:
发现主服务器已经进入客观下线状态。
对我们的当前纪元进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。
如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
选出一个从服务器,并将它升级为主服务器。
向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
1 每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel 使用以下规则来选择新的主服务器:
在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel状态持久化
snetinel的状态会被持久化地写入sentinel的配置文件中。每次当收到一个新的配置时,或者新创建一个配置时,配置会被持久化到硬盘中,并带上配置的版本戳。这意味着,可以安全的停止和重启sentinel进程。
优点
哨兵与哨兵之间、哨兵与master之间能够进行及时的监控,心跳检测,及时发现系统的问题,这都是弥补了主从的缺点。
缺点
增加了哨兵也增加了系统的复杂度,需要同时维护哨兵模式。
Sentinel 配置步骤 描述: 哨兵模式的监控配置信息,是通过配置从数据库的sentinel monitor <master-name> <ip> <redis-port> <quorum>来指定的,比如:1 2 3 4 5 6 sentinel monitor mymaster 10.20.172.108 6379 2 - mymaster 表示给master数据库定义了一个名字, - master的ip 和 端口 - 2 : 表示至少需要一个Sentinel进程同意才能将master判断为失效,如果不满足这个条件,则自动故障转移(failover)不会执行
运行哨兵的两种方式: 1 2 3 4 5 redis-sentinel /path/to/sentinel.conf redis-server /path/to/sentinel.conf --sentinel
Tips: 在运行 Sentinel 时必须使用配置文件,因为系统将使用该文件来保存在重启时将重新加载的当前状态。如果没有给出配置文件或配置文件路径不可写,Sentinel 将简单地拒绝启动。
Tips: Sentinel 默认运行侦听 TCP 端口 26379 的连接,因此要使Sentinel 工作,您的服务器的端口 26379必须打开以接收来自其他 Sentinel 实例的 IP 地址的连接。否则哨兵不能说话,也不能就该做什么达成一致,所以永远不会执行故障转移。
官方参考: https://redis.io/topics/sentinel
测试环境 1 2 3 10.20.172.108 Redis-Master 6379 |{Sentinel01} 26379 10.20.172.108 Redis-Slave 6380 |{Sentinel02} 36379 10.20.172.108 Redis-Slave 6381 |{Sentinel03} 46379
Tips: 此处演示只用了一台主机进行演示,在生产环境中搭建sentinel一定要在各redis服务器上配置监听,这才能真正的实现高可用。
流程步骤
Step 0.Redis主从服务配置文件并启动配置Redis主从服务。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 tee startRedisServer.sh <<'EOF' #!/bin/bash sed 's#6379#6380#g' /home/weiyigeek/redis/6379/redis-6379.conf > /home/weiyigeek/redis/6380/redis-6380.conf sed 's#6379#6381#g' /home/weiyigeek/redis/6379/redis-6379.conf > /home/weiyigeek/redis/6381/redis-6381.conf /usr/local /bin/redis-server /home/weiyigeek/redis/6379/redis-6379.conf /usr/local /bin/redis-server /home/weiyigeek/redis/6380/redis-6380.conf /usr/local /bin/redis-server /home/weiyigeek/redis/6381/redis-6381.conf EOF chmod +x startRedisServer.sh && ./startRedisServer.sh netstat -ano | egrep "(6379|6380|6381)" tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:6380 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:6381 0.0.0.0:* LISTEN echo "CONFIG set masterauth 123456\nCONFIG REWRITE" | redis-cli -p 6379 -a 123456 redis-cli -h 127.0.0.1 -p 6380 -a 123456 127.0.0.1:6380> SLAVEOF 10.20.172.108 6379 127.0.0.1:6380> CONFIG set masterauth 123456 127.0.0.1:6380> CONFIG REWRITE ➜ echo "SLAVEOF 10.20.172.108 6379\nCONFIG set masterauth 123456\nCONFIG REWRITE" | redis-cli -p 6381 -a 123456 OK OK OK grep "Generated by CONFIG REWRITE" -A 5 ~/redis/6380/redis-6380.conf .... masterauth "123456" user default on replicaof 10.20.172.108 6379 grep "Generated by CONFIG REWRITE" -A 5 ~/redis/6381/redis-6381.conf .... masterauth "123456" user default on replicaof 10.20.172.108 6379 redis-cli -p 6379 -a 123456 info replication | head -n 5
Step 1.Redis 哨兵Sentinel常用配置简单说明。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 bind 10.20.172.108port 26379 daemonize yes dir "/home/weiyigeek/redis" logfile "/home/weiyigeek/redis/sentinel_26379.log" sentinel monitor mymaster 10.20.172.108 6379 2 sentinel auth-pass mymaster 123456 sentinel down-after-milliseconds mymaster 3000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 5000
Step 2.sentinel 配置文件配置分别生成26379、36379、46379的监听端口,以及分别启动三个端口的哨兵服务。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 cat > /home/weiyigeek/redis/sentinel-26379.conf <<'EOF' bind 10.20.172.108port 26379 daemonize yes dir "/home/weiyigeek/redis" logfile "/home/weiyigeek/redis/sentinel_26379.log" sentinel monitor mymaster 10.20.172.108 6379 2 sentinel auth-pass mymaster 123456 sentinel down-after-milliseconds mymaster 5000 sentinel parallel-syncs mymaster 1 sentinel failover-timeout mymaster 10000 EOF sed 's#26379#36379#g' /home/weiyigeek/redis/sentinel-26379.conf > /home/weiyigeek/redis/sentinel-36379.conf sed 's#26379#46379#g' /home/weiyigeek/redis/sentinel-26379.conf > /home/weiyigeek/redis/sentinel-46379.conf ➜ ls && grep "port" sentinel-* tee startSentinel.sh <<'EOF' #!/bin/bash /usr/local /bin/redis-server /home/weiyigeek/redis/sentinel-26379.conf --sentinel /usr/local /bin/redis-server /home/weiyigeek/redis/sentinel-36379.conf --sentinel /usr/local /bin/redis-server /home/weiyigeek/redis/sentinel-46379.conf --sentinel EOF chmod +x startSentinel.sh && ./startSentinel.sh redis netstat -ano | egrep "0 0.0.0.0:([234]){0,1}(6379|6380|6381)" redis ps u -C "redis-server"
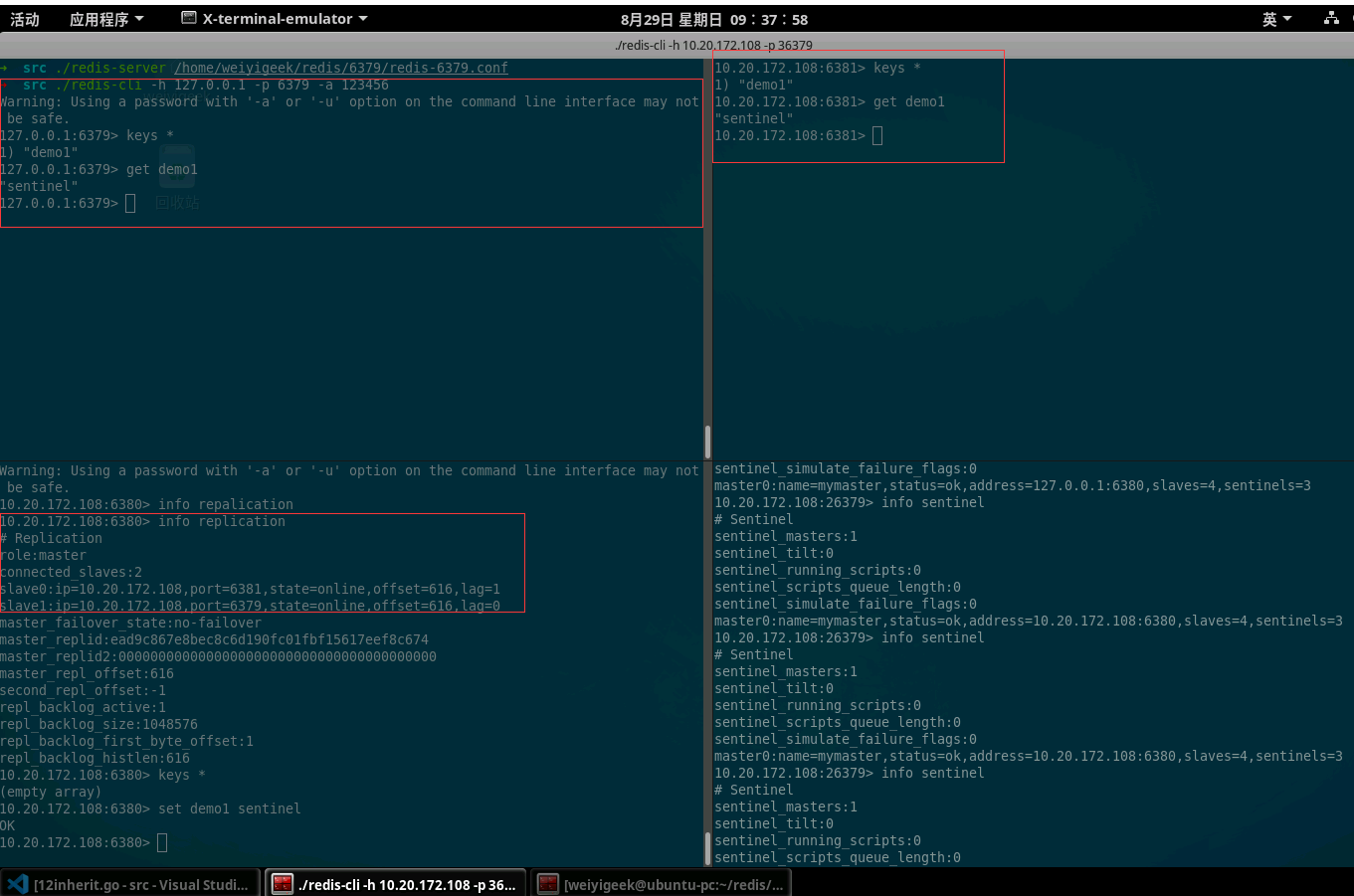
Step 3.验证Redis Sentine服务并通过查看哨兵相关信息1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 $ cat /home/weiyigeek/redis/6379/logs/6379.log 118725:M 05 Sep 2021 10:33:05.714 * Replica 10.20.172.108:6380 asks for synchronization 118725:M 05 Sep 2021 10:33:05.715 * Full resync requested by replica 10.20.172.108:6380 118725:M 05 Sep 2021 10:33:05.715 * Replication backlog created, my new replication IDs are '01bf2439d1606b8b74c2846ebb3dab02b1ab993c' and '0000000000000000000000000000000000000000' 118725:M 05 Sep 2021 10:33:05.715 * Starting BGSAVE for SYNC with target: disk 118725:M 05 Sep 2021 10:33:05.715 * Background saving started by pid 118816 118816:C 05 Sep 2021 10:33:05.756 * DB saved on disk 118816:C 05 Sep 2021 10:33:05.757 * RDB: 0 MB of memory used by copy-on-write 118725:M 05 Sep 2021 10:33:05.767 * Background saving terminated with success 118725:M 05 Sep 2021 10:33:05.767 * Synchronization with replica 10.20.172.108:6380 succeeded 118725:M 05 Sep 2021 10:34:58.126 - Accepted 10.20.172.108:36343 118725:M 05 Sep 2021 10:34:58.152 * Replica 10.20.172.108:6381 asks for synchronization 118725:M 05 Sep 2021 10:34:58.152 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '44d3228555abe04a02f979761bd534283d0d3613' , my replication IDs are '01bf2439d1606b8b74c2846ebb3dab02b1ab993c' and '0000000000000000000000000000000000000000' ) 118725:M 05 Sep 2021 10:34:58.152 * Starting BGSAVE for SYNC with target: disk 118725:M 05 Sep 2021 10:34:58.152 * Background saving started by pid 118865 118865:C 05 Sep 2021 10:34:58.184 * DB saved on disk 118865:C 05 Sep 2021 10:34:58.185 * RDB: 0 MB of memory used by copy-on-write 118725:M 05 Sep 2021 10:34:58.232 * Background saving terminated with success 118725:M 05 Sep 2021 10:34:58.233 * Synchronization with replica 10.20.172.108:6381 succeeded /redis$ more sentinel_26379.log 10:50:43.944 10:50:43.944 10:50:43.944 10:50:43.945 * Increased maximum number of open files to 10032 (it was originally set to 1024). 10:50:43.945 * Running mode=sentinel, port=26379. 10:50:44.026 10:50:44.026 10:50:44.027 * +slave slave 10.20.172.108:6380 10.20.172.108 6380 @ mymaster 10.20.172.108 6379 10:50:44.129 * +slave slave 10.20.172.108:6381 10.20.172.108 6381 @ mymaster 10.20.172.108 6379 10:50:45.990 * +sentinel sentinel 2e53ed2e7407064d08f09b5547615144d6e34159 10.20.172.108 36379 @ mymaster 10.20.172.108 6379 10:50:46.917 * +sentinel sentinel 1c12264f05132a5627620588752a07429a635198 10.20.172.108 46379 @ mymaster 10.20.172.108 6379 ~/redis$ redis-cli -h 10.20.172.108 -p 26379 -a 123456 info | grep -n "master" ~/redis$ redis-cli -h 10.20.172.108 -p 36379 -a 123456 info | grep -n "master" ~/redis$ redis-cli -h 10.20.172.108 -p 46379 -a 123456 info | grep -n "master" redis-cli -h 10.20.172.108 -p 26379 -a 123456 10.20.172.108:26379> sentinel masters 10.20.172.108:26379> sentinel master mymaster 10.20.172.108:26379> SENTINEL replicas mymaster 10.20.172.108:26379> SENTINEL sentinels mymaster 1) 1) "name" 2) "2e53ed2e7407064d08f09b5547615144d6e34159" 3) "ip" 4) "10.20.172.108" 5) "port" 6) "36379" 7) "runid" 8) "2e53ed2e7407064d08f09b5547615144d6e34159" 省略..... 2) 1) "name" 2) "1c12264f05132a5627620588752a07429a635198" 3) "ip" 4) "10.20.172.108" 5) "port" 6) "46379" 7) "runid" 8) "1c12264f05132a5627620588752a07429a635198" 省略..... 10.20.172.108:26379> SENTINEL get-master-addr-by-name mymaster 1) "10.20.172.108" 2) "6379"
Step 4.在Master节点上添加一个Keys验证主从正常同步1 2 3 4 5 6 7 8 9 10 11 10.20.172.108:6379> set username WeiyiGeek OK 10.20.172.108:6380> get username 10.20.172.108:6380> set demo redis echo "get username" | redis-cli -p 6381 -a 123456
Step 7.然后我们再来测试一下哨兵的自动故障恢复,直接kill掉6380服务端口的进程。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 ~/redis$ ps uax | grep "6380" weiyige+ 119353 0.4 0.0 146544 6168 ? Ssl 10:50 0:53 /usr/local /bin/redis-server 0.0.0.0:6380 ~/redis$ kill 119353 10.20.172.108:26379> SENTINEL get-master-addr-by-name mymaster 1) "10.20.172.108" 2) "6381" 13:58:50.367 13:58:50.451 13:58:50.451 13:58:50.451 13:58:50.504 13:58:50.693 13:58:50.719 13:58:50.727 13:58:50.727 13:58:50.803 13:58:50.803 * +failover-state-send-slaveof-noone slave 10.20.172.108:6381 10.20.172.108 6381 @ mymaster 10.20.172.108 6380 13:58:50.874 * +failover-state-wait-promotion slave 10.20.172.108:6381 10.20.172.108 6381 @ mymaster 10.20.172.108 6380 13:58:51.563 13:58:51.563 13:58:51.568 * +slave-reconf-sent slave 10.20.172.108:6379 10.20.172.108 6379 @ mymaster 10.20.172.108 6380 13:58:51.843 13:58:52.529 * +slave-reconf-inprog slave 10.20.172.108:6379 10.20.172.108 6379 @ mymaster 10.20.172.108 6380 13:58:52.529 * +slave-reconf-done slave 10.20.172.108:6379 10.20.172.108 6379 @ mymaster 10.20.172.108 6380 13:58:52.582 13:58:52.582 13:58:52.582 * +slave slave 10.20.172.108:6379 10.20.172.108 6379 @ mymaster 10.20.172.108 6381 13:58:52.582 * +slave slave 10.20.172.108:6380 10.20.172.108 6380 @ mymaster 10.20.172.108 6381 13:58:57.611 redis-cli -p 6381 -a 123456 info replication | head -n 5 role:master connected_slaves:1 slave0:ip=10.20.172.108,port=6379,state=online,offset=2456277,lag=0 echo "set newname weiyigeek" | redis-cli -h 10.20.172.108 -p 6381 -a 123456OK 10.20.172.108:6380> keys * 1) "newname" 2) "username" 3) "demo1" 10.20.172.108:6380> get newname "weiyigeek" ~/redis$ /usr/local /bin/redis-server /home/weiyigeek/redis/6380/redis-6380.conf ~/redis$ tail -f 50 /home/weiyigeek/redis/6381/redis-6381.conf masterauth "123456" user default on sanitize-payload 14:04:23.511 $ redis redis-cli -p 6381 -a 123456 info replication | head -n 5 role:master connected_slaves:2 slave0:ip=10.20.172.108,port=6379,state=online,offset=2456277,lag=0 slave1:ip=10.20.172.108,port=6380,state=online,offset=2456277,lag=0 ➜ redis redis-cli -p 6380 -a 123456 get newname "weiyigeek"
Step 8.至此哨兵的故障恢复实践完毕,下面是一些注意事项:
sentinel 节点不要部署在同一台机器。
至少不是三个且奇数个的 sentinel 节点,增加选举的准确性因为领导者选举需要至少一半加1个节点。
sentinel节点集合可以只监控一个主节点,也可以监控多个主节点,尽量使用一套sentinel监控一个主节点。
sentinel的数据节点与普通的 redis 数据节点没有区别。
客户端初始化连接的是 Sentinel节点集合,不再是具体的redis节点,但是Sentinel 是配置中心不是代理。
Sentinel 配置文件 描述:在redis源码包中自带一个sentinel.conf配置文件示例。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 # Example sentinel.conf # *** IMPORTANT *** # 默认情况下,无法从不同于本地主机的接口访问Sentinel,请使用“bind”指令绑定到网络接口列表,或通过将其添加到此配置文件来禁用带有“protected mode no”的protected mode。 bind 127.0.0.1 192.168.1.1 protected-mode no # port <sentinel-port> : The port that this sentinel instance will run on port 26379 # By default Redis Sentinel does not run as a daemon. # 设置yes后将生成 /var/run/redis-sentinel.pid daemonize yes # 自定义 pid file 在本地路径 pidfile /var/run/redis-sentinel.pid # 指定日志文件名。 # 如使用 "" 标准输出 # 如使用 daemonize 则日志将发送到 /dev/null. logfile "" # 由于NAT,Sentinel可以通过非本地地址从外部访问。当提供了通告ip时,Sentinel将在用于告知其存在的HELLO消息中声明指定的ip地址,而不是像通常那样自动检测本地地址。 # Example: # sentinel announce-ip 1.2.3.4 # sentinel announce-port 26379 # sentinel 数据相关文件存储目录 # dir <working-directory> dir /tmp # 设置要得监控主控名称以及服务地址端口、并设置quorum(票数) # 注意:主控名称不应包含特殊字符或空格,有效字符集为A-z 0-9和三个字符“-\”。 # sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 127.0.0.1 6379 2 # 设置用于向主机和副本进行身份验证的密码(与服务端的密码保持一致)。 # sentinel auth-pass <master-name> <password> sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # 对于向具有ACL功能的实例进行身份验证非常有用,并且运行Redis 6.0或更高版本,当提供了just auth pass时 它将使用 “AUTH<user><pass>” (一般情况下设置的是密码) # sentinel auth-user <master-name> <username> # user sentinel-user >somepassword +client +subscribe +publish \ # +ping +info +multi +slaveof +config +client +exec on # 主(或任何附加的副本或哨兵)应是不可达的(如在指定的时间段内连续不可接受的答复),以考虑它在Sy-DOWN状态(主观下线),默认30s. # sentinel down-after-milliseconds <master-name> <milliseconds> sentinel down-after-milliseconds mymaster 30000 # IMPORTANT NOTE: starting with Redis 6.2 ACL capability is supported for Sentinel mode, # 参考地址: https://redis.io/topics/acl # Sentinel's ACL users are defined in the following format: # user <username> ... acl rules ... # For example: # user worker +@admin +@connection ~* on >ffa9203c493aa99 # For more information about ACL configuration please refer to the Redis # website at https://redis.io/topics/acl and redis server configuration # template redis.conf. # ACL日志跟踪失败的命令和与ACL关联的身份验证事件, 在下面定义ACL日志的最大条目长度: acllog-max-len 128 # 使用外部ACL用户文件并且格式与redis.conf中用于描述用户的格式完全相同。 aclfile /etc/redis/sentinel-users.acl # requirepass 与 aclfile选项和ACL LOAD命令不兼容,在使用acl如设置该字段将被忽略。 # requirepass <password> # 建议新配置文件对传入连接(通过ACL)和传出连接(通过sentinel user和sentinel pass)使用单独的身份验证控制 # 将Sentinel配置为与具有特定用户名的其他Sentinel进行身份验证。 sentinel sentinel-user <username> # Sentinel与其他Sentinel进行身份验证的密码。如果未配置sentinel用户,sentinel将使用具有sentinel pass的“默认”用户进行身份验证。 sentinel sentinel-pass <password> # 在故障切换过程中,我们可以重新配置多少副本以同时指向新副本。如果使用副本来提供查询,请使用较低的数字,以避免在执行与主服务器的同步时,几乎同时无法访问所有副本。 # sentinel parallel-syncs <master-name> <numreplicas> sentinel parallel-syncs mymaster 1 # 以毫秒为单位指定故障转移超时(默认三分钟) # sentinel failover-timeout <master-name> <milliseconds> sentinel failover-timeout mymaster 180000 # SCRIPTS EXECUTION # sentinel通知脚本和sentinel reconfig脚本用于配置在故障转移后被调用以通知系统管理员或重新配置客户端的脚本。使用以下错误处理规则执行脚本: # 如果脚本以“1”退出,则稍后将重试执行(最大次数当前设置为10)。 # 如果脚本以“2”(或更高的值)退出,则不会重试脚本执行。 # 如果脚本因接收到信号而终止,则行为与退出代码1相同。 # 脚本的最大运行时间为60秒。达到此限制后,脚本将以SIGKILL终止,并重试执行。 # NOTIFICATION SCRIPT | 通知执行 # 为警告级别(例如-sdown、-odown等)中生成的任何sentinel事件调用指定的通知脚本 # Example: # sentinel notification-script <master-name> <script-path> sentinel notification-script mymaster /var/redis/notify.sh # CLIENTS RECONFIGURATION SCRIPT | 客户端重新配置脚本(可以多次调用) # 由于故障切换而更改主机时,可以调用脚本来执行特定于应用程序的任务,以通知客户端配置已更改且主机位于不同的地址。 # ip、from port、to ip、to port 的参数用于传递主机的旧地址和所选副本(现在是主机)的新地址。 # The following arguments are passed to the script: # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # <state> is currently always "failover" # <role> is either "leader" or "observer" # Example: # sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # SECURITY # 默认情况下,SENTINEL SET将无法在运行时更改通知脚本和客户端重新配置脚本。这避免了一个微不足道的安全问题,客户机可以将脚本设置为任何值,并触发故障转移以执行程序。 sentinel deny-scripts-reconfig yes # REDIS COMMANDS RENAMING # 有时 Redis服务器会将Sentinel正常工作所需的某些命令重命名为不可用字符串。在将Redis作为服务提供的提供者的上下文中,CONFIG和SLAVEOF通常是这种情况,并且不希望客户在管理控制台之外重新配置实例。 # 在这种情况下,可以告诉Sentinel使用不同的命令名,而不是普通的命令名。 # 例如,如果主机“mymaster”和相关副本的“CONFIG”全部重命名为“GUESSME”,我可以使用如下配置,设置好这样的配置后,Sentinel每次使用CONFIG时都会使用GUESSME。 SENTINEL rename-command mymaster CONFIG GUESSME # SENTINEL SET也可用于在运行时执行此配置。 # 为了将命令设置回其原始名称(撤消重命名),可以只将命令重命名为其自身: SENTINEL rename-command mymaster CONFIG CONFIG # HOSTNAMES SUPPORT # 通过启用解析主机名来启用主机名支持。请注意,您必须确保DNS配置正确,并且DNS解析不会引入很长的延迟。 SENTINEL resolve-hostnames no # 启用“解析主机名”时,Sentinel在向用户、配置文件等公开实例时仍使用IP地址。如果要在宣布时保留主机名,请启用下面的“宣布主机名”。 SENTINEL announce-hostnames no
Sentinel 常用命令 描述: Sentinel 常用API命令(https://redis.io/topics/sentinel#Sentinel%20API),以下列出的是Sentinel接受的命令:
常用命令
(1) 出于连接管理和管理目的,Sentinel 支持以下 Redis 命令子集:
PING :返回PONG。
COMMAND ( >= 6.2) 此命令返回有关命令的信息。有关详细信息,请参阅COMMAND 命令及其各种子命令。
INFO 返回有关 Sentinel 服务器的信息和统计信息。有关更多信息,请参阅INFO 命令。
ROLE 此命令返回字符串“sentinel”和受监控主站的列表。有关更多信息,请参阅ROLE 命令。
AUTH ( >= 5.0.1) 验证客户端连接。有关更多信息,请参阅AUTH 命令和使用身份验证配置 Sentinel 实例 部分
HELLO ( >= 6.0) 切换连接的协议。有关更多信息,请参阅HELLO 命令。
CLIENT 此命令管理客户端连接。有关更多信息,请参阅其子命令页面。
ACL ( >= 6.2) `此命令管理 Sentinel 访问控制列表。有关详细信息,请参阅ACL 文档页面和Sentinel 访问控制列表身份验证
SHUTDOWN 关闭 Sentinel 实例。
(2) SENTINEL命令是 Sentinel 的主要 API
(3) 动态获取修改Sentinel配置
SENTINEL CONFIG GET<name> ( >= 6.2) 获取全局 Sentinel 配置参数的当前值。指定的名称可以是通配符,类似于Redis CONFIG GET命令。SENTINEL CONFIG <name> <value>: SET命令与Redis的CONFIG SET命令非常相似,用于更改特定master 的配置参数。可以指定多个选项/值对(或根本不指定)。可以通过配置的所有配置参数也可以sentinel.conf使用 SET 命令进行配置。SENTINEL FLUSHCONFIG: 强制 Sentinel 在磁盘上重写其配置,包括当前 Sentinel 状态。通常 Sentinel 会在每次其状态发生变化时重写配置(在状态子集的上下文中,该子集在重新启动时保留在磁盘上)。但是有时可能会因为操作错误、磁盘故障、包升级脚本或配置管理器而导致配置文件丢失。在这些情况下,强制 Sentinel 重写配置文件的方法很方便。即使之前的配置文件完全丢失此命令也能工作。
Tips 可以操作的全局参数包括:
resolve-hostnames, announce-hostnames. 请参阅IP 地址和 DNS 名称。
announce-ip, announce-port. 请参阅Sentinel、Docker、NAT 和可能的问题。
sentinel-user, sentinel-pass. 请参阅使用身份验证配置 Sentinel 实例。
(4) 移除master监控服务或者删除旧的 master 或无法访问的副本
SENTINEL REMOVE <name> : 用于移除指定的master:master将不再被监控(放弃对某个master的监听)。SENTINEL RESET mastername: 从 Sentinels 监视的副本列表中永远删除一个副本(可能是旧的 master)。
(5) 添加或删除哨兵SENTINEL MASTER mastername 来检查所有 Sentinel 是否同意监视 master 的 Sentinel 总数。
移除 Sentinel 有点复杂:Sentinels 永远不会忘记已经看到的 Sentinels,即使它们很长时间无法访问,因为我们不想动态更改授权故障转移和创建新配置所需的多数数字。因此为了删除 Sentinel,应在没有网络分区的情况下执行以下步骤:
停止要移除的 Sentinel 的 Sentinel 进程。
SENTINEL RESET * 向所有其他 Sentinel 实例发送命令(*如果您只想重置一个主服务器,则可以使用确切的主服务器名称)。一个接一个,实例之间至少等待 30 秒。通过检查SENTINEL MASTER mastername 每个 Sentinel的输出,检查所有 Sentinel 是否同意当前活动的 Sentinel 数量。
发布/订阅消息
以下是您可以使用此 API 接收的频道和消息格式的列表。第一个字是通道/事件名称,其余的是数据的格式。<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>
标识 master 的部分(从 @ 参数到结尾)是可选的,并且仅在实例本身不是 master 时才指定。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 +reset-master <instance details> -- 主机被重置。 +slave <instance details> -- 检测到并附加了一个新副本。 +failover-state-reconf-slaves <instance details> -- 故障转移状态更改为reconf-slavesstate。 +failover-detected <instance details> --检测到由另一个 Sentinel 或任何其他外部实体启动的故障转移(一个附加的副本变成了一个主)。 +slave-reconf-sent <instance details> -- 领导哨兵向该实例发送REPLICAOF命令,以便为新副本重新配置它。 +slave-reconf-inprog <instance details> -- 正在重新配置的副本显示为新主 ip:port 对的副本,但同步过程尚未完成。 +slave-reconf-done <instance details> -- 副本现在与新的主服务器同步。 -dup-sentinel <instance details> -- 指定 master 的一个或多个 sentinel 被删除为重复的(例如,当 Sentinel 实例重新启动时会发生这种情况)。 +sentinel <instance details> -- 检测到并附加了此主人的新哨兵。 +sdown <instance details> -- 指定的实例现在处于主观关闭状态。 -sdown <instance details> -- 指定的实例不再处于主观关闭状态。 +odown <instance details> -- 指定的实例现在处于 Objectively Down 状态。 -odown <instance details> -- 指定的实例不再处于 Objectively Down 状态。 +new-epoch <instance details> -- 当前纪元已更新。 +try-failover <instance details> -- 正在进行新的故障转移,等待多数人选举。 +elected-leader <instance details> -- 赢得指定时期的选举,可以进行故障转移。 +failover-state-select-slave <instance details> -- 新的故障转移状态是select-slave:我们正在尝试寻找合适的副本进行升级。 no-good-slave <instance details> -- 没有好的副本可以推广。目前我们会在一段时间后尝试,但可能这会改变,在这种情况下状态机将完全中止故障转移。 selected-slave <instance details> -- 我们找到了要提升的指定好的副本。 failover-state-send-slaveof-noone -- <instance details>我们正在尝试将提升的副本重新配置为主副本,等待它切换。 failover-end-for-timeout -- <instance details>故障转移因超时而终止,副本最终将被配置为与新的主节点进行复制。 failover-end <instance details> -- 故障转移成功终止。所有副本似乎都被重新配置为使用新的主副本进行复制。 switch-master <master name> <oldip> <oldport> <newip> <newport> -- 主新 IP 和地址是配置更改后指定的。这是大多数外部用户感兴趣的消息。 +tilt -- 进入倾斜模式。 -tilt -- 退出倾斜模式。
Tips :-BUSY 状态的处理,当 Lua 脚本运行的时间超过配置的 Lua 脚本时间限制时,Redis 实例会返回 -BUSY 错误。在触发故障转移之前发生这种情况时,Redis Sentinel 将尝试发送SCRIPT KILL 命令,只有在脚本为只读时才会成功。如果在此尝试后实例仍处于错误状态,则最终将进行故障转移。
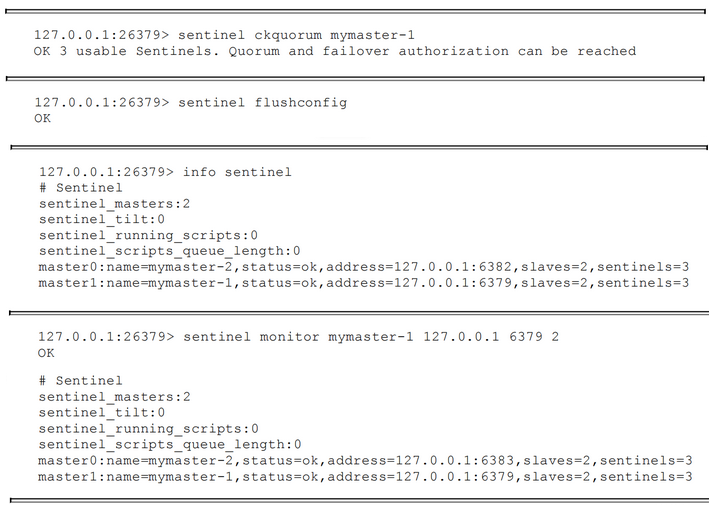
命令使用演示: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 > sentinel masters > sentinel master mymaster > sentinel slaves mymaster > sentinel sentinels mymaster > sentinel get-master-addr-by-name mymaster > sentinel reset mymaster > sentinel failover mymaster > sentinel ckquorum mymaster > sentinel flushconfig > sentinel remove mymaster > sentinel monitor mymaster 127.0.0.1 6379 2 > sentinel is-master-down-by-addr > sentinel set <master name>
weiyigeek.top-sentinel相关命令实践
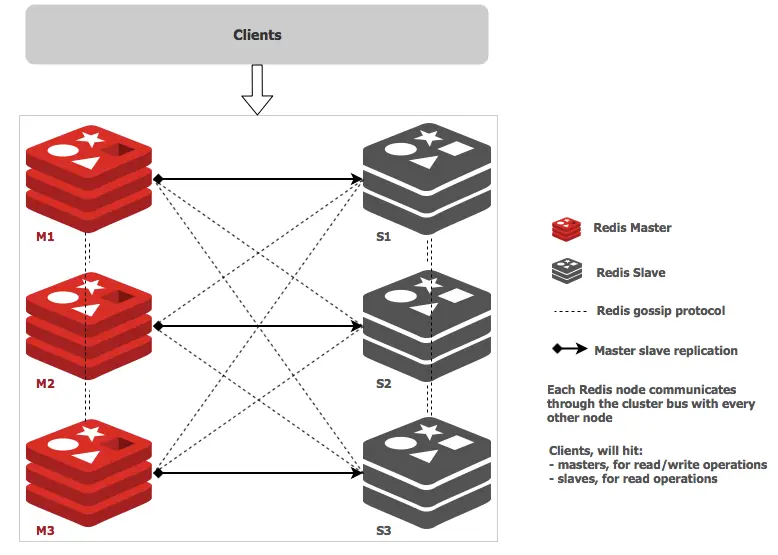
Redis Cluster 模式 描述: 在大型项目中Redis Cluster 集群模式被广泛应用,哨兵解决和主从不能自动故障恢复的问题,但是同时也存在难以扩容以及单机存储、读写能力受限的问题,并且集群之前都是一台redis的全量的数据,导致所有的redis都冗余一份,就会大大消耗内存空间,所以此时我们需要引入Redis 集群模式。
1.基础介绍 描述: 什么是Redis集群?
Redis集群是一个多Redis实例的集合,用于通过对数据库分区来扩展数据库,使其更具有弹性。集群中的每个成员,无论是主副本还是次级副本,都管理哈希槽的一个子集。如果一个主服务器出现不能访问的故障,那么它的从属服务器会提升为主服务器。在由三个主节点组成的最小的Redis集群中,每个主节点都有一个从属节点(为了至少能保证最低程度的故障转移),每个主节点分配一个范围在0至16383之间的哈希槽。节点A包含哈希槽范围为从0到5000,节点B为5001到10000,节点C从10001到18383。集群内部的通信则通过内部总线进行,使用gossip协议来传播关于集群的信息或者发现新节点。
Redis 集群采用了P2P的模式完全去中心化(分布式存储), 实现数据的分片把所有的 Key 分成了 16384 个 slot,每个 Redis 实例负责其中一部分slot, 并根据算法每个redis节点存储不同的内容; 集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新,同时解决了在线的节点收缩(下线)和扩容(上线)问题。
例如:Redis 客户端可以在任意一个 Redis 实例发出请求(读、写),如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
cluster 特性(已测试):
1): 节点自动发现
2): slave->master 选举,集群容错
3): Hot resharding:在线分片
4): 集群管理:cluster xxx
5): 基于配置(nodes-port.conf)的集群管理
6): ASK 转向/MOVED 转向机制.
优点
缺点 db select 0(无多个db)
Tips: 集群模式真正意义上实现了系统的高可用和高性能,但是集群同时进一步使系统变得越来越复杂,接下来我们来详细的了解集群的运作原理。
Q:什么是redis-cluster选举容错?
(1)选举过程是集群中所有master参与, 如果半数以上master节点与故障节点通信超过(cluster-node-timeout)时间, 则认为该节点故障,自动触发故障转移操作.
(2) 什么时候整个集群不可用(cluster_state:fail)? 1 2 3 a: 如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完整时进入fail状态.ps : redis-3.0.0.rc1 加入cluster-require-full-coverage 参数,默认关闭,打开集群兼容部分失败. b: 如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态. ps: 当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
2.集群架构 描述: redis-cluter 架构细节浅析
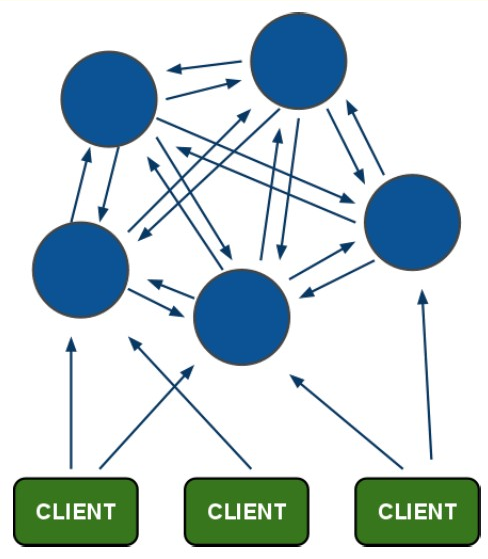
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
节点的fail是通过集群中超过半数的节点检测失效时才生效.
客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
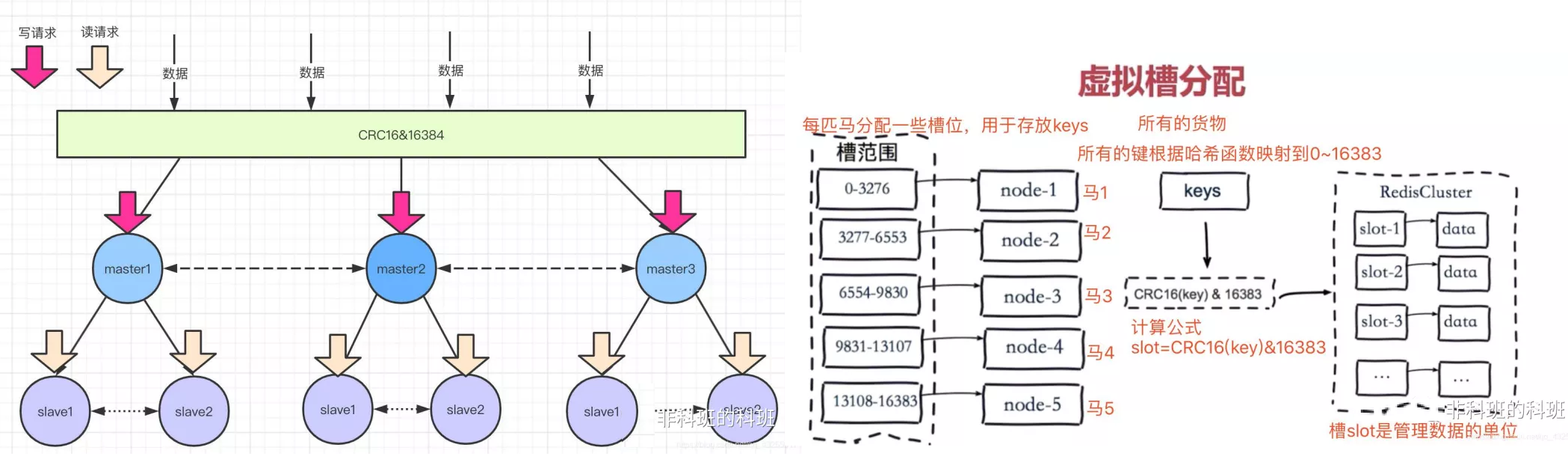
redis-cluster把所有的物理节点映射到\[0-16383]slot上, cluster 负责维护 node<->slot<->key
Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
weiyigeek.top-架构图
3.原理分析 3.1 数据分区原理
比如:下图所示三个master会把0-16383范围的槽可能分成三部分(0-5000)、(5001-11000)、(11001-16383)分别数据三个缓存节点的槽范围。
当客户端请求过来,会首先通过对key进行CRC16 校验并对 16384 取模(CRC16(key)%16383)计算出key所在的槽,然后再到对应的槽上进行取数据或者存数据,这样就实现了数据的访问更新。
weiyigeek.top-数据分区原理
Tips: 进行分槽存储是将一整堆的数据进行分片,防止单台的redis数据量过大,影响性能的问题。
3.2 节点通信
这个和前面哨兵模式讲的命令基本一样, 首先新上线的节点, 会通过 Gossip 协议向老成员发送Meet消息,表示自己是新加入的成员。
老成员收到Meet消息后,在没有故障的情况下会恢复PONG消息,表示欢迎新结点的加入,除了第一次发送Meet消息后,之后都会发送定期PING消息,实现节点之间的通信。
Redis集群节点间的通信机制有如下两种方式
集中式方式
gossip 方式
1) 优点:元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力。
2)缺点:元数据更新有延时可能导致集群的一些操作会有一些滞后。
gossip协议包含多种消息,包括ping,pong,meet,fail等等,流程示例:1 2 3 4 5 6 7 缓存节点2 -> Meet 消息 -< Pong 消息 -> Ping 消息 -< Pong 消息 -> fail 信息 缓存节点1
通信的过程中会为每一个通信的节点开通一条tcp通道,之后就是定时任务,不断的向其它节点发送PING消息,这样做的目的就是为了了解节点之间的元数据存储情况,以及健康状况,以便即使发现问题。
但如果节点通信网络抖动问题,网络通信中有时会因为一些客观原因使得网络突然中断或者波动而变得不可访问。
此时 Redis Cluster 提供了一种选项 cluster-node-timeout,表示当某个节点持续timeout的时间失联时,才可以认定该节点出现故障,需要进行主从切换。当没有此参数时候,网络抖动会导致主从频繁切换 【数据的重新复制】。
Tips: 每个节点都有一个专门用于节点间gossip通信的端口,默认得为自己提供服务的端口号+10000,即6379为redis服务端点则节点间通信的就是18000端口。
3.3 数据请求 unsigned char myslots[CLUSTER_SLOTS/8]一个数组存放每个节点的槽信息。
因为他是一个二进制数组,只有存储0和1值,如下所示:1 2 数组下标: 0 1 2 3 4 ..... 16382 16383 二进制值: 1 1 1 1 0 ..... 0 0
这样数组只表示自己是否存储对应的槽数据,若是1表示存在该数据,0表示不存在该数据,这样查询的效率就会非常的高,类似于布隆过滤器(二进制存储)。
比如:集群节点1负责存储0-5000的槽数据,但是此时只有0、1、2存储有数据,其它的槽还没有存数据,所以0、1、2对应的值为1。
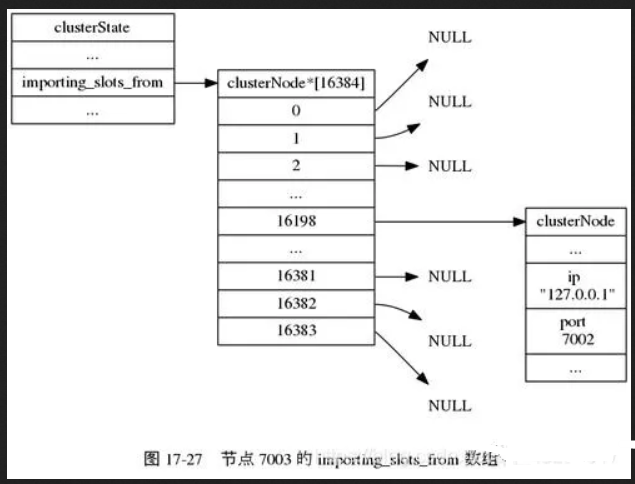
并且,每个redis底层还维护了一个clusterNode数组,大小也是16384,用于储存负责对应槽的节点的ip、端口等信息,这样每一个节点就维护了其它节点的元数据信息,便于及时的找到对应的节点。
当新结点加入或者节点收缩,通过PING命令通信,及时的更新自己clusterNode数组中的元数据信息,这样有请求过来也就能及时的找到对应的节点。
weiyigeek.top-clusterNode数组中的元数据信息
有两种其它的情况就是:
1) 若是请求过来发现,数据发生了迁移,比如新节点加入,会使旧的缓存节点数据迁移到新结点。
2) 请求过来发现旧节点已经发生了数据迁移并且数据被迁移到新结点,由于每个节点都有clusterNode信息,通过该信息的ip和端口。此时旧节点就会向客户端发一个MOVED 的重定向请求,表示数据已经迁移到新结点上,你要访问这个新结点的ip和端口就能拿到数据,这样就能重新获取到数据。
倘若正在发正数据迁移呢?
答: 旧节点就会向客户端发送一个ASK 重定向请求,并返回给客户端迁移的目标节点的ip和端口,这样也能获取到数据。
3.4扩容和收缩
描述: 扩容和收缩也就是节点的上线和下线,可能节点发生故障了,故障自动回复的过程(节点收缩)。
节点的收缩和扩容时,会重新计算每一个节点负责的槽范围,并发根据虚拟槽算法,将对应的数据更新到对应的节点。
还有前面的讲的新加入的节点会首先发送Meet消息,详细可以查看前面讲的内容,基本一样的模式。
以及发生故障后,哨兵老大节点的选举,master节点的重新选举,slave怎样晋升为master节点,可以查看前面哨兵模式选举过程。
Tips: 新节点加入集群时都是master节点,并且也是无法写数据的(没有slot槽位),需要从新分配槽位后才可以访问。
3.5高可用主从切换原理 slave发现自己的 master(主节点)变为 FAIL 状态时,便尝试进行 Failover 指向其它正常 master 节点。
有时由于挂掉的 master 可能会有多个slave 节点,从而存在多个 slave 节点 竞争成为 master节点 的过程,其过程如下:
1.slave 发现自己的 master 变为FAIL
2.将自己记录的集群 currentEpoch 进行 +1,并广播 FAILOVER_AUTH_REQUEST 信息.
3.其他节点收到该信息只有 master 响应判断请求者的合法性, 并发送 FAILOVER_AUTH_ACK,对每一个 epoch 只发送一次 ack
4.尝试 failover 的 slave 收集 FAILOVER_AUTH_ACK.
5.超过半数后变成新Master.
6.广播 Pong 通知其他集群节点。
所以 Redis Cluster 既能够实现主从的角色分配,又能够实现主从切换,相当于集成了Replication 和Sentinal 的功能。
3.6 跳转重定位节点与卡槽
客户端收到指令后除了跳转到正确的节点上去操作,还会同步更新纠正本地的槽位映射表缓存,后续所有key将使用新的槽位映射表。
4.集群搭建 描述: Redis集群中要求奇数节点,至少要有三个节点,并且每个节点至少有一备份节点,所以至少需要6个redis服务实例。
4.1 安装环境 1 2 3 4 5 6 7 8 9 10 11 12 OS: Centos7.10 / Centos6.10 Reids版本:5.0.4 Centos7:192.168.1.99/24 {7000,7001,7002} Centos6-1:192.168.1.100/24 {7000,7001,7002} Centos6-2:192.168.1.101/24 {7000,7001,7002} $ yum update -y && yum uograde -y lib / zlib / ruby / rubugems
4.2 安装流程
Step 2.准备目录结构和redis配置。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 $ mkdir -p /data/redis/redis-cluster/{7000,7001,7002} $ touch /data/redis/redis-cluster/7000/redis.conf $ mkdir -p /etc/redis/cluster/run/ tee /data/redis/redis-cluster/7000/redis.conf <<'EOF' port 7000 bind 0.0.0.0protected-mode no daemonize yes masterauth 123456 requirepass 123456 dir /data/redis/redis-cluster/7000 pidfile /var/run/redis_7000.pid logfile /var/log /redis_7000.log loglevel verbose maxclients 10000 timeout 60 dbfilename "dump.rdb" save 300 10 save 60 10000 rdbcompression yes rdbchecksum yes appendonly yes appendfilename "appendonly.aof" appendfsync everysec rename-command FLUSHDB b840fc02d524045429941cc15f59e41cb7be6c53 rename-command FLUSHALL b840fc02d524045429941cc15f59e41cb7be6c54 rename-command EVAL b840fc02d524045429941cc15f59e41cb7be6c55 rename-command DEBUG b840fc02d524045429941cc15f59e41cb7be6c56 cluster-enabled yes cluster-config-file /etc/redis/cluster/run/nodes-7000.conf cluster-node-timeout 5000 min‐replicas‐to‐write 1 EOF
Step 3.将配置文件分别复制到其他目录并修改端口号。1 2 3 4 5 cp /data/redis/redis-cluster/7000/redis.conf /data/redis/redis-cluster/7001/redis.conf cp /data/redis/redis-cluster/7000/redis.conf /data/redis/redis-cluster/7002/redis.conf sed -i 's/7000/7001/g' /data/redis/redis-cluster/7001/redis.conf sed -i 's/7000/7002/g' /data/redis/redis-cluster/7002/redis.conf
Step 4.编写开启与关闭集群脚本 cluster-control.sh,并启动集群1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 tee cluster-control.sh <<'EOF' #!/bin/bash function start_cluster(){ for i in {0..2} do /usr/bin/redis-server /data/redis/redis-cluster/700$i /redis.conf; done } function stop_cluster(){ for i in {0..2} do /usr/bin/redis-cli -a 123456 -c -p 700${i} shutdown save; done } if [ $# -eq 0 ];then echo "Usage: cluster-control.sh [start|sop]" else case $1 in start) echo "开启redis集群" start_cluster ;; stop) echo "停止Redis集群" stop_cluster ;; esac fi EOF $ chmod +x ./cluster_control.sh && ./cluster_control.sh start $ ps -ef | grep "redis"
Step 5.Redis 官方提供了 redis-trib.rb 工具(/opt/redis/redis-5.0.4/utils/create-cluster),我们可以进行手动进行创建Redis集群。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 ./redis-trib.rb create --replicas 1 192.168.1.99:7000 192.168.1.99:7001 192.168.1.99:7002 192.168.1.100:7000 192.168.1.100:7001 192.168.1.100:7002 192.168.1.101:7000 192.168.1.101:7001 192.168.1.101:7002 -a [密码] redis-cli --cluster create 192.168.1.99:7000 192.168.1.99:7001 192.168.1.99:7002 192.168.1.100:7000 192.168.1.100:7001 192.168.1.100:7002 192.168.1.101:7000 192.168.1.101:7001 192.168.1.101:7002 --cluster-replicas 1 -a [密码] >>> Performing hash slots allocation on 9 nodes... Master[0] -> Slots 0 - 4095 Master[1] -> Slots 4096 - 8191 Master[2] -> Slots 8192 - 12287 Master[3] -> Slots 12288 - 16383 Adding replica 192.168.1.101:7001 to 192.168.1.99:7000 Adding replica 192.168.1.99:7002 to 192.168.1.100:7000 Adding replica 192.168.1.100:7002 to 192.168.1.101:7000 Adding replica 192.168.1.101:7002 to 192.168.1.99:7001 Adding replica 192.168.1.100:7001 to 192.168.1.99:7000 M: 8c5a037999975a052e422bc030c3fc72053d059e 192.168.1.99:7000 slots:[0-4095] (4096 slots) master M: 4877856114a8efc62325dc0d32adede6256eb9ef 192.168.1.99:7001 slots:[12288-16383] (4096 slots) master S: 3bd40f9a2d95a9865f58706b55f4559e6c43dd7e 192.168.1.99:7002 replicates 6df7e2ad828ba148239dd4465235d17ce0e0af10 M: 6df7e2ad828ba148239dd4465235d17ce0e0af10 192.168.1.100:7000 slots:[4096-8191] (4096 slots) master S: 35756a64813b68bf5fea92b6ee2b1a7020b8cc7a 192.168.1.100:7001 replicates 8c5a037999975a052e422bc030c3fc72053d059e S: f467098bffa3761868842556eb4cfff7cc8bc363 192.168.1.100:7002 replicates 660590807a4417e901c6d2277b29a306c1ea07e3 M: 660590807a4417e901c6d2277b29a306c1ea07e3 192.168.1.101:7000 slots:[8192-12287] (4096 slots) master S: cd7fb4d0a48a114629c1f34e0f75da5235910995 192.168.1.101:7001 replicates 8c5a037999975a052e422bc030c3fc72053d059e S: 8d1cab296fe88e1809e550ecd482f6df67c61e7b 192.168.1.101:7002 replicates 4877856114a8efc62325dc0d32adede6256eb9ef >>> Performing Cluster Check (using node 192.168.1.99:7000) M: 8c5a037999975a052e422bc030c3fc72053d059e 192.168.1.99:7000 slots:[0-4095] (4096 slots) master 2 additional replica(s) S: cd7fb4d0a48a114629c1f34e0f75da5235910995 192.168.1.101:7001 slots: (0 slots) slave replicates 8c5a037999975a052e422bc030c3fc72053d059e S: 35756a64813b68bf5fea92b6ee2b1a7020b8cc7a 192.168.1.100:7001 slots: (0 slots) slave replicates 8c5a037999975a052e422bc030c3fc72053d059e M: 4877856114a8efc62325dc0d32adede6256eb9ef 192.168.1.99:7001 slots:[12288-16383] (4096 slots) master 1 additional replica(s) M: 6df7e2ad828ba148239dd4465235d17ce0e0af10 192.168.1.100:7000 slots:[4096-8191] (4096 slots) master 1 additional replica(s) S: 3bd40f9a2d95a9865f58706b55f4559e6c43dd7e 192.168.1.99:7002 slots: (0 slots) slave replicates 6df7e2ad828ba148239dd4465235d17ce0e0af10 S: f467098bffa3761868842556eb4cfff7cc8bc363 192.168.1.100:7002 slots: (0 slots) slave replicates 660590807a4417e901c6d2277b29a306c1ea07e3 S: 8d1cab296fe88e1809e550ecd482f6df67c61e7b 192.168.1.101:7002 slots: (0 slots) slave replicates 4877856114a8efc62325dc0d32adede6256eb9ef M: 660590807a4417e901c6d2277b29a306c1ea07e3 192.168.1.101:7000 slots:[8192-12287] (4096 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
Step 6.验证Redis集群是否正常工作1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 $ redis-cli --cluster check 192.168.1.99:7000 $ redis-cli -c -p 7000 -h 192.168.1.99 192.168.1.99:7000> auth 123456 OK 192.168.1.99:7000> get name 192.168.1.100:7000> auth 123456 OK 192.168.1.100:7000> get name "weiyi" 192.168.1.100:7000> cluster info 192.168.1.100:7000> cluster nodes 192.168.1.100:7000> CLUSTER SLOTS 1) 1) (integer ) 0 2) (integer ) 4095 3) 1) "192.168.1.99" 2) (integer ) 7000 3) "8c5a037999975a052e422bc030c3fc72053d059e" 4) 1) "192.168.1.101" 2) (integer ) 7001 3) "cd7fb4d0a48a114629c1f34e0f75da5235910995" 5) 1) "192.168.1.100" 2) (integer ) 7001 3) "35756a64813b68bf5fea92b6ee2b1a7020b8cc7a" 2) 1) (integer ) 8192 2) (integer ) 12287 3) 1) "192.168.1.101" 2) (integer ) 7000 3) "660590807a4417e901c6d2277b29a306c1ea07e3" 4) 1) "192.168.1.100" 2) (integer ) 7002 3) "f467098bffa3761868842556eb4cfff7cc8bc363" 3) 1) (integer ) 4096 2) (integer ) 8191 3) 1) "192.168.1.100" 2) (integer ) 7000 3) "6df7e2ad828ba148239dd4465235d17ce0e0af10" 4) 1) "192.168.1.99" 2) (integer ) 7002 3) "3bd40f9a2d95a9865f58706b55f4559e6c43dd7e" 4) 1) (integer ) 12288 2) (integer ) 16383 3) 1) "192.168.1.99" 2) (integer ) 7001 3) "4877856114a8efc62325dc0d32adede6256eb9ef" 4) 1) "192.168.1.101" 2) (integer ) 7002 3) "8d1cab296fe88e1809e550ecd482f6df67c61e7b"
5.集群命令 5.1 命令行式 语法格式: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 $ redis-cli --cluster help create host1:port1 ... hostN:portN --cluster-replicas <arg> check host:port --cluster-search-multiple-owners info host:port fix host:port --cluster-search-multiple-owners --cluster-fix-with-unreachable-masters add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id id del-node host:port node_id reshard host:port --cluster-from <arg> --cluster-to <arg> --cluster-slots <arg> --cluster-yes --cluster-timeout <arg> --cluster-pipeline <arg> --cluster-replace rebalance host:port --cluster-weight <node1=w1...nodeN=wN> --cluster-use-empty-masters --cluster-timeout <arg> --cluster-simulate --cluster-pipeline <arg> --cluster-threshold <arg> --cluster-replace import host:port --cluster-from <arg> --cluster-from-user <arg> --cluster-from-pass <arg> --cluster-from-askpass --cluster-copy --cluster-replace call host:port command arg arg .. arg --cluster-only-masters --cluster-only-replicas backup host:port backup_directory set -timeout host:port milliseconds --cluster-yes Automatic yes to cluster commands prompts (在脚本实现自动化的时候非常有用)
Tips: 对于check、fix、reshard、del node、set timeout,您可以指定群集中任何工作节点的主机和端口。
实践使用: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 /usr/local /bin/redis-cli -h 192.168.1.2 -a weiyigeek.top --cluster create --cluster-replicas 1 [192.168.1.2:6379 ~ 192.168.1.7:6379] redis-cli -h 172.16.243.97 -a weiyigeek --cluster check 172.16.243.97:6379 --cluster-search-multiple-owners redis-cli -h 172.16.243.97 -a weiyigeek --cluster info 172.16.24.214:6379 redis-cli -h 172.16.243.97 -a weiyigeek --cluster del-node 172.16.100.116:6379 436c6a1d7e4c5f782e1e0620b831211ebb0a41a4 redis-cli -h 172.16.243.97 -a weiyigeek --cluster del-node 172.16.24.214:6379 2674f21a88a9573f51ec46f9dc248ad4a5c5974d redis-cli -h 172.16.243.97 -a weiyigeek --cluster add-node 172.16.100.116:6379 172.16.243.97:6379 --cluster-slave ~$ redis-cli -h 172.16.243.97 -a weiyigeek --cluster add-node 172.16.24.214:6379 172.16.243.97:6379 --cluster-master-id 94b8d3748dc47053454e657da8d6bb90e0081f2c ~$ redis-cli -h 172.16.243.97 -a weiyigeek --cluster fix --cluster-fix-with-unreachable-masters 172.16.24.214:6379 ..... ~$ redis-cli -h 172.16.243.97 -a weiyigeek -c cluster nodes ~$ redis-cli -h 172.16.24.214 -a weiyigeek --cluster del-node 172.16.183.95:6379 94b8d3748dc47053454e657da8d6bb90e0081f2c ~$ redis-cli -h 172.16.24.214 -a weiyigeek --cluster del-node 172.16.243.97:6379 d97cb5b15b7130ca0bd5322758e0c2dce061fd7b ~$ redis-cli -h 172.16.24.214 -a weiyigeek --cluster add-node 172.16.183.95:6379 172.16.24.214:6379 ~$ redis-cli -h 172.16.24.214 -a weiyigeek --cluster add-node 172.16.243.97:6379 172.16.24.214:6379 ~$ redis-cli -h 172.16.24.214 -a weiyigeek --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters --cluster-pipeline 10 172.16.243.97:6379 ~$ redis-cli -h 172.16.24.214 -a weiyigeek -c cluster nodes ~$ redis-cli -a weiyigeek --cluster reshard 172.16.24.214:6379 ~$ redis-cli -a weiyigeek --cluster reshard 172.16.24.214:6379 --cluster-from d97cb5b15b7130ca0bd5322758e0c2dce061fd7b --cluster-to 2674f21a88a9573f51ec46f9dc248ad4a5c5974d --cluster-slots 50 --cluster-yes --cluster-timeout 5000 --cluster-pipeline 50 --cluster-replace redis-cli -a weiyigeek --cluster backup 172.16.243.97:6379 . redis-cli --cluster import 192.168.75.187:6379 --cluster-from 192.168.1.187:6379 redis-cli -a weiyigeek --cluster set -timeout 172.16.24.214:6379 10000 redis-cli -a weiyigeek --cluster call 172.16.243.97:6379 info keyspace
Tips : 通过--cluster import从其它集群导入数据到当前集群中的流程说明。
1、通过load_cluster_info_from_node方法加载集群信息,check_cluster方法检查集群是否健康;
2、连接外部redis节点,如果外部节点开启了cluster_enabled,则提示错误;
3、通过scan命令遍历外部节点,一次获取1000条数据;
4、遍历这些key,计算出key对应的slot;
5、执行migrate命令,源节点是外部节点,目的节点是集群slot对应的节点,如果设置了–copy参数,则传递copy参数,如果设置了–replace,则传递replace参数;
6、不停执行scan命令,直到遍历完全部的key;
7、至此完成整个迁移流程。
5.2 交互式命令 描述: 在我们以-c集群模式连接到集群中的任意一台主机时,可以通过交互魔术执行如下命令。
语法格式: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 redis-cli --cluster help cluster help 1) CLUSTER <subcommand> [<arg> [value] [opt] ...]. Subcommands are: CLUSTER BUMPEPOCH - CLUSTER SET-CONFIG-EPOCH config-epoch CLUSTER COUNT-FAILURE-REPORTS node-id CLUSTER GETKEYSINSLOT slot count CLUSTER COUNTKEYSINSLOT slot CLUSTER SLOTS - CLUSTER ADDSLOTS slot [slot ...] CLUSTER SETSLOT slot IMPORTING|MIGRATING|STABLE|NODE [node-id] CLUSTER DELSLOTS slot [slot ...] CLUSTER FLUSHSLOTS - CLUSTER KEYSLOT key CLUSTER INFO - CLUSTER MYID - CLUSTER NODES - CLUSTER FAILOVER [FORCE|TAKEOVER] CLUSTER FORGET node-id CLUSTER MEET ip port CLUSTER RESET [HARD|SOFT] CLUSTER SLAVES node-id CLUSTER REPLICAS node-id CLUSTER REPLICATE node-id CLUSTER SAVECONFIG -
使用实践: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 $ redis-cli -h 172.16.243.97 -a weiyigeek -c CLUSTER INFO CLUSTER NODES CLUSTER SLOTS CLUSTER MEET 172.16.24.215 6379 CLUSTER FORGET <node_id> CLUSTER REPLICATE <node_id> CLUSTER SAVECONFIG CLUSTER ADDSLOTS <slot> [slot ...] CLUSTER DELSLOTS <slot> [slot ...] CLUSTER SETSLOT <slot> NODE <node_id> CLUSTER SETSLOT <slot> MIGRATING <node_id> CLUSTER SETSLOT <slot> IMPORTING <node_id> CLUSTER SETSLOT <slot> STABLE CLUSTER FLUSHSLOTS CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。 CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。 CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
常用命令示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 redis-cli -h 127.0.0.1 -a weiyigeek --cluster create --cluster-replicas 1 172.16.182.219:6379 172.16.183.72:6379 172.16.24.202:6379 172.16.100.65:6379 172.16.135.193:6379 172.16.243.65:6379 redis-cli -a weiyigeek --cluster add-node 192.168.1.100:7000 192.168.1.99:7000 redis-cli -a weiyigeek --cluster add-node --cluster-slave --cluster-master-id a7b511330bffe28357cd21d6ee543e59f0a38dea 192.168.1.100:7000 redis-cli -a weiyigeek --cluster check 192.168.1.100:7000 redis-cli -h 192.168.1.100 -p 7000 -a weiyigeek -c cluster info redis-cli -h 192.168.1.100 -p 7000 -a weiyigeek -c cluster nodes redis-cli --cluster del-node 127.0.0.1:7000 f467098bffa3761868842556eb4cfff7cc8bc363 -a 123456 redis-cli --cluster rebalance -a 123456 --cluster-threshold 1 127.0.0.1:8007 redis-cli -–cluster reshard 127.0.0.1:7000 -–cluster-from a7b511330bffe28357cd21d6ee543e59f0a38dea -–cluster-to a7ab1aa24c9030d1fb42bbac3ad72c15bf683ef4 –-cluster-slots 10 –cluster-yes
6.集群补充 (1) Redis集群和哨兵的区别
(2) Redis集群脑裂产生的问题 此时主节点是存活的,只是网络问题导致无法同步)而后网络恢复导致该小集群出现2个主节点对外提供服务。
规避方式: 在redis.conf配置文件下更改min‐replicas‐to‐write 1参数配置,该配置意思是主节点写数据完成后,最少需要同步的slave数量。
举例说明: 比如1主2从的机制,原来的主节点因为网络波动被判定为挂了,此时新的从节点想上位,那么它必须要能给另外1个从节点进行redis写的同步,它才能成为主节点。此时对于这个从节点除了自己以外他还有一个从节点对其进行数据同步,那么1+1>2/3符合半数选举机制。
Tips: 非常注意该配置在一定程度上会影响集群的可用性,比如slave要是少于1个,那么没有从节点写入数据,就满足不了这个配置,那就不能对外提供服务了。
(3) Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
描述: 因为新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中 一个挂了,是达不到选举新master的条件的。
示例: 3个master,挂了1个,则挂了的master其对应的slave若是获得了另外两个master的支持【2>3/2】,则它就可以成为master。
反例: 2个master,挂了1个,那么就算另外一个master选出一个slave作为新的master,此时票数也不够【1=2/2】,达不到半数效果。
反例: 4个master,如果挂了1个,选举方式和3个master的方式类似,可以达到半数选举的效果。但如果挂了2个,场景和上面的类似,也一样无法选出新的master。
总结: 为什么至少需要3个master节点,因为主从切换需要满足半数选举机制。
(4) 集群是否完整才能对外提供服务? cluster-require-full-coverage no参数,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
(5) 为啥redis.cond文件内部要写集群信息?
(6) 集群内部主从为啥不放在一台机器上?