[TOC]
0x00 Redis 组件原理 Redis 客户端连接 描述:Redis 通过监听一个 TCP 端口或者 Unix socket(/var/run/redis/redis-server.sock)的方式来接收来自客户端的连接,当一个连接建立后Redis 内部会进行以下一些操作:
(1) 首先客户端 socket 会被设置为非阻塞模式,因为 Redis 在网络事件处理上采用的是非阻塞多路复用模型。
(2) 然后为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
(3) 然后创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
[TOC]
0x00 Redis 组件原理 Redis 客户端连接 描述:Redis 通过监听一个 TCP 端口或者 Unix socket(/var/run/redis/redis-server.sock)的方式来接收来自客户端的连接,当一个连接建立后Redis 内部会进行以下一些操作:
(1) 首先客户端 socket 会被设置为非阻塞模式,因为 Redis 在网络事件处理上采用的是非阻塞多路复用模型。
(2) 然后为这个 socket 设置 TCP_NODELAY 属性,禁用 Nagle 算法
(3) 然后创建一个可读的文件事件用于监听这个客户端 socket 的数据发送
1 2 3 4 5 6 7 8 9 10 11 > config get maxclients 1) "maxclients" 2) "4064" > CLIENT help > CLIENT LIST id=1256 addr=127.0.0.1:41306 fd=7 name= age=708 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client > CLIENT kill 127.0.0.1:41306 OK
Redis 管道技术 描述: Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。通常情况下一个请求会遵循以下步骤:
(1) 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式等待服务端响应。
(2) 服务端处理命令,并将结果返回给客户端。
管道技术的优势
(1) 提高了 redis 服务的性能/速度效率提升(特别在网页高速缓存应用开发中、脚本开发之中)
(2) 管道技术可以一次性读取所有服务端的响应。
示例演示: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 (echo -en "auth 123456\r\nPING\r\n SET runoobkey redis\r\nGET runoobkey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n" ; sleep 1) | nc localhost 6379 $(echo -en "auth 123456\r\nPING\r\n SET runoobkey redis\r\nGET runoobkey\r\nINCR visitor\r\nINCR visitor\r\nINCR visitor\r\n" ; sleep 1) | nc localhost 6379 tee redis-command.txt <<'EOF' SET username weiyigeek EOF cat redis-command.txt | redis -a weiyigeek --pipe
Redis 分区存储原理 描述: 分区是分割数据到多个Redis实例的处理过程,因此每个实例只保存key的一个子集
分区的优势:
利用多台计算机内存的和值,允许我们构造更大的数据库
通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
分区的不足:
涉及多个key的操作通常是不被支持的
涉及多个key的redis事务不能使用。
当使用分区时数据处理较为复杂
增加或删除容量也比较复杂(redis集群)
Redis 有两种类型分区: 有不同的系统来映射某个key到某个Redis服务
(1) 按范围分区
(2) 哈希分区
比如使用crc32 hash函数对key foobar 执行会输出类似93024922的整数;
对这个整数取模将其转化为0-3之间的数字,就可以将这个整数映射到4个Redis实例中的一个了。
93024922 % 4 = 2 ===>>> 就是说key foobar应该被存到R2实例中。
0x01 Redis 运行模式 Redis作为缓存的高效中间件,在我们日常的开发中被频繁的使用,今天就来说一说Redis的四种模式,分别是「单机版、主从复制、哨兵、以及集群模式」(本章显示单机版)。
在一般公司的程序员使用单机版基本都能解决问题,在Redis的官网给出的数据是10W QPS,这对于应付一般的公司绰绰有余了,再不行就来个主从模式,实现读写分离,性能又大大提高。并且作为程序员在学习Redis时你可能很少听过Redis的「哨兵」和「集群模式」
Redis 单机 描述: 在前面的基础学习中我们简单安装了单机的Redis-Server服务,在Java项目中使用Redis连接客户端时,我们可以采用官网推荐操作Redis的第三方依赖库是Jedis,在SpringBoot项目中,引入下面依赖就可以直接使用了:1 2 3 4 5 <dependency > <groupId > redis.clients</groupId > <artifactId > jedis</artifactId > <version > ${jedis.version}</version > </dependency >
模式优点
1.单机版的Redis也有很多优点,比如实现实现简单、维护简单、部署简单、维护成本非常低,不需要其它额外的开支。
模式缺点
1.单机版的Redis所以也存在很多的问题,比如最明显的单点故障问题,一个Redis挂了,所有的请求就会直接打在了DB上。
2.并且一个Redis抗并发数量也是有限的,同时要兼顾读写两种请求,只要访问量一上来,Redis就受不了了。
3.另一方面单机版的Redis数据量存储也是有限的,数据量一大,再重启Redis的时候,就会非常的慢,所以局限性也是比较大的。
测试环境: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ➜ ~ cat /etc/issue.net Ubuntu 20.04.2 LTS ➜ ~ uname -a Linux ubuntu-pc 5.11.0-27-generic ➜ ~ lsmem | grep "Total online memory" Total online memory: 12G ➜ ~ lscpu | head -n 10 架构: x86_64 CPU 运行模式: 32-bit, 64-bit 字节序: Little Endian Address sizes: 36 bits physical, 48 bits virtual CPU: 4 在线 CPU 列表: 0-3 每个核的线程数: 1 每个座的核数: 4 座: 1 NUMA 节点: 1
实操搭建
Step 1.Redis 单机版本的安装此处可以参照以下按照脚本,相信官网可以找到你想要得,1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #!/bin/bash groupadd redis && useradd -r -g redis redis -M sudo sysctl -w vm.overcommit_memory=1 sudo sysctl -w vm.swapniess=1 sudo sysctl -w net.ipv4.tcp_max_syn_backlog=2048 echo never > /sys/kernel/mm/transparent_hugepage/enabledREDIS_VERSION="redis-6.2.5" REDIS_URL_TAR="https://download.redis.io/releases/${REDIS_VERSION} .tar.gz" REDIS_TAR="${REDIS_VERSION} .tar.gz" REDIS_DIR="/usr/local/redis" wget ${REDIS_URL_TAR} -O /tmp/${REDIS_TAR} tar -zxf /tmp/${REDIS_TAR} -C /usr/local / mv /usr/local /${REDIS_VERSION} ${REDIS_DIR} cd ${REDIS_DIR} && makecp ${REDIS_DIR} /redis.conf /etc/redis/redis.conf for i in $(ls -F ${REDIS_DIR} /src | grep "*" | sed 's#*##g' );do sudo chmod +700 ${REDIS_DIR} /src/${i} sudo ln -s ${REDIS_DIR} /src/${i} /usr/local /bin/${i} done chmod +600 /etc/redis/redis.conf chown redis:redis /etc/redis/redis.conf chown redis:redis ${REDIS_DIR} setsid sudo -u redis redis-server /etc/redis/redis.conf sudo tee /usr/lib/systemd/system/redis.service <<'EOF' [Unit] Description=Redis-Server Systemd Documentation=https://redis.io After=network.target [Service] User=redis Group=redis Type=simple StandardError=journal ExecStart=/usr/local /bin/redis-server /etc/redis/redis.conf Restart=on-failure RestartSec=3s [Install] WantedBy=multi-user.target EOF systemctl deamon-reload systemctl redis status
Step 2.此Redis常用的redis.conf的配置项可参考编码包中的/etc/redis/redis.conf或者在第一篇<1.Redis数据库基础介绍与安装>文章之中。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 tee /etc/redis/redis.conf <<'EOF' bind 0.0.0.0port 6379 daemonize no supervised auto pidfile "/var/run/redis_6379.pid" protected-mode no requirepass "123456" dir "/home/redis/6379/datas" logfile "/home/redis/6379/logs/6379.log" loglevel verbose maxclients 10000 timeout 60 tcp-keepalive 60 dbfilename "dump.rdb" save 300 10 save 60 10000 rdbcompression yes rdbchecksum yes rdb-save-incremental-fsync yes appendonly yes appendfilename "appendonly.aof" appendfsync everysec rename-command FLUSHDB b840fc02d524045429941cc15f59e41cb7be6c53 rename-command FLUSHALL b840fc02d524045429941cc15f59e41cb7be6c54 rename-command EVAL b840fc02d524045429941cc15f59e41cb7be6c55 rename-command DEBUG b840fc02d524045429941cc15f59e41cb7be6c56 EOF
引言
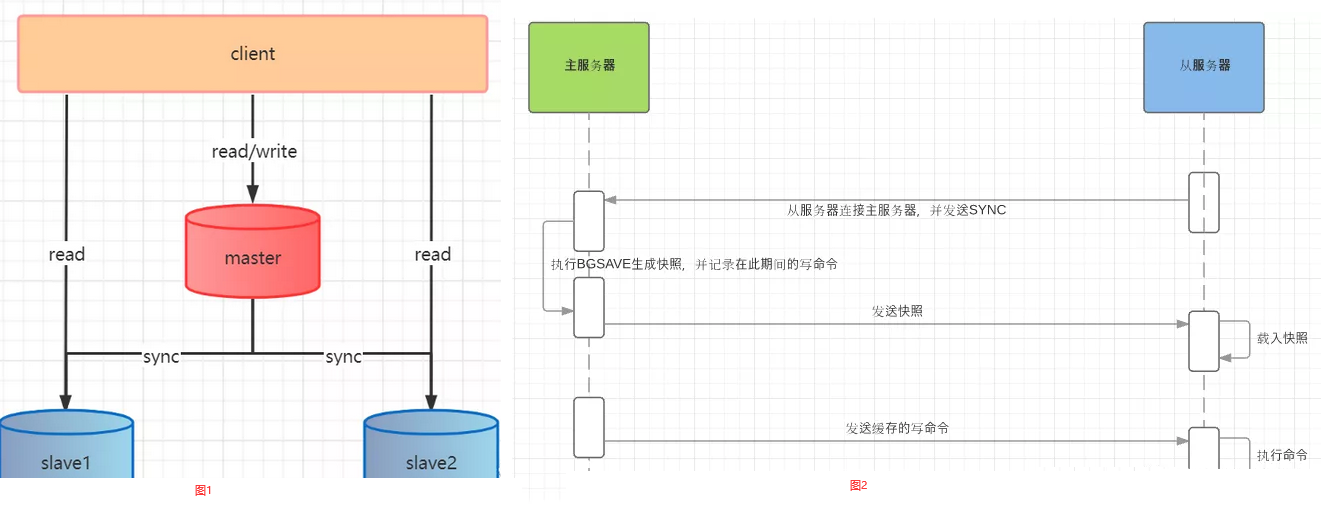
Redis 主从模式 描述: 主从的原理还算是比较简单的,一主多从「主数据库(master)可以读也可以写(read/write),从数据库仅读(only read)」。但是主从模式一般实现「读写分离」,「主数据库仅写(only write)」,减轻主数据库的压力.
下面一张图搞懂主从模式的原理以及其执行的过程(工作机制):
(1) 当slave启动后会向master发送SYNC命令,master节点收到从数据库的命令后通过bgsave保存快照「RDB持久化」,并且期间的执行的些命令会被缓存起来。
(2) master 会将保存的快照发送给slave,并且继续缓存期间的写命令。
(3) slave 收到主数据库发送过来的快照就会加载到自己的数据库中。
(4) 最后master讲缓存的命令同步给slave,slave收到命令后执行一遍,这样master与slave数据就保持一致了。
weiyigeek.top-工作机制
模式优点
1.主从一定程度上解决了单机版并发量大,导致请求延迟或者redis宕机服务停止的问题。
2.解决了单机版单点故障的问题,若是主数据库挂了,那么从数据库可以随时顶上来,综上来说,主从模式一定程度上提高了系统的可用性和性能,是实现哨兵和集群的基础。
3.从数据库分担主数据库的读压力,若是主数据库是只写模式,那么实现读写分离,主数据库就没有了读压力了。
4.主从同步以异步方式进行同步,期间Redis仍然可以响应客户端提交的查询和更新的请求, 保证业务不会被暂停。
模式缺点
1) 主从模式好是好,他也有自己的缺点,比如数据的一致性问题,假如主数据库写操作完成,那么他的数据会被复制到从数据库,若是还没有即使复制到从数据库,读请求又来了,此时读取的数据就不是最新的数据。
2) 若是从主同步的过程网络出故障了,导致主从同步失败,也会出现问题数据一致性的问题。
3) 主从模式不具备自动容错和恢复的功能,一旦主数据库,从节点晋升为主数据库的过程需要人为操作,维护的成本就会升高,并且主节点的写能力、存储能力都会受到限制。
实操搭建
Step 1.下面的我们来实操搭建一下主从模式,主从模式的搭建还是比较简单的,我这里一台Ubuntu虚拟机,使用开启redis多实例的方法搭建主从。
Step 2.redis中开启多实例的方法,首先创建一个文件夹,用于存放redis集群的配置文件, 复制三份配置文件, 一主两从,6379端口作为主数据库(master),6380、6381作为从数据库(slave)。
1 2 mkdir -vp /home/redis/{6379..6381}/{datas,logs}/ cp /etc/redis/redis.con /home/redis/6379/redis-6379.conf
Step 3.首先是配置主数据库的配置文件
1 $ cat /home/redis/6379/redis-6379.conf
Step 4.然后,就是修改从数据库的配置文件,在从数据库的配置文件中加入以下的配置信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 sed 's#6379#6380#g' /home/redis/6379/redis-6379.conf > /home/redis/6380/redis-6380.conf tee -a /home/redis/6380/redis-6380.conf <<'EOF' slaveof 10.20.172.108 6379 masterauth 123456 slave-serve-stale-data no EOF sed 's#6380#6381#g' /home/weiyigeek/redis/6380/redis-6380.conf > /home/weiyigeek/redis/6381/redis-6381.conf
Step 5.接下来就是启动三个redis实例,启动的命令,先cd到redis的src目录下,然后执行:
1 2 3 4 5 6 7 /usr/local /bin/redis-server /home/redis/6379/redis-6379.conf /usr/local /bin/redis-server /home/redis/6380/redis-6380.conf /usr/local /bin/redis-server /home/redis/6381/redis-6381.conf
Step 6.通过命令ps -aux | grep redis,查看启动的redis进程
1 2 3 4 ps -aux | grep redis-server
Step 7.如上图所示,表示启动成功,下面就开始进入测试阶段,此处我采用三个终端做为Redis连接的客户端,启动时指定端口以及密码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 $ redis-cli -h 10.20.172.108 -a 123456 10.20.172.108:6379> ping 10.20.172.108:6379> INFO replication role:master connected_slaves:2 slave0:ip=10.20.172.108,port=6380,state=online,offset=132754,lag=1 slave1:ip=10.20.172.108,port=6381,state=online,offset=132754,lag=0 master_failover_state:no-failover master_replid:f5664625474d54c9ce4198b279bce85e194bad42 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:132754 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:132754 10.20.172.108:6379> sync $ redis-cli -h 10.20.172.108 -p 6380 10.20.172.108:6380> ping (error) NOAUTH Authentication required. 10.20.172.108:6380> auth 123456 10.20.172.108:6380> ping 10.20.172.108:6380> role ./redis-cli -h 10.20.172.108 -p 6381 -a 123456 10.20.172.108:6381> ping 10.20.172.108:6381> info replication role:slave master_host:10.20.172.108 master_port:6379 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:42 slave_priority:100 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:3551023c88161ea3735435c95b58230ec15608a2 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:42 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:15 repl_backlog_histlen:28
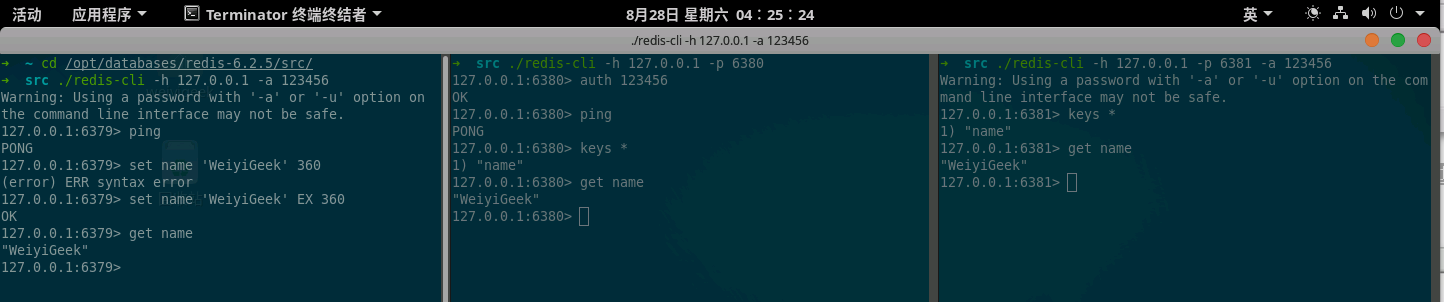
Step 8.启动后,在master服务端口为6379,输入:set name 'WeiyiGeek',在两个slave中通过 get name 可以查看:
weiyigeek.top-Redis主从
Step 9.如果有新增从节点或者移除当前从节点可以参考以下:1 2 3 4 5 6 7 redis> SLAVEOF 127.0.0.1 6379 OK redis> SLAVEOF NO ONE OK