[TOC]
0x00 文件查看
cat 命令 - 从第一行完整显示文件内容
描述:cat命令(Concatenate)连接文件并打印到标准输出设备上(显示、读取或拼接文件内容),他经常用来显示文件的内容,类似于下的type命令。
当文件较大的时候建议采用more或者less命令进行查看文件:
- Ctrl+S:停止滚屏
- Ctrl+Q:恢复滚屏
- Ctrl+C:(中断)可以终止该命令执行,并返回shell提示符
语法参数:

[TOC]
描述:cat命令(Concatenate)连接文件并打印到标准输出设备上(显示、读取或拼接文件内容),他经常用来显示文件的内容,类似于下的type命令。
当文件较大的时候建议采用more或者less命令进行查看文件:
语法参数:
[TOC]
描述:cat命令(Concatenate)连接文件并打印到标准输出设备上(显示、读取或拼接文件内容),他经常用来显示文件的内容,类似于下的type命令。
当文件较大的时候建议采用more或者less命令进行查看文件:
语法参数:1
2
3
4
5
6
7
8
9-n/--number:显示文本行号从1开始
-b/--number-noblank:不对空白行编号
-s/--squeeze-blank:当遇到连续两行以上的空白行就代替为1行的空白行
-A:显示不可打印字符,行尾显示“$”;
-E: 将行尾的断行字符$显示出来
-T: 将[Tab]按键以^I显示出来
-v: 列出一些看不出来的特殊字符
-e:等价于"-vE"选项;
-t:等价于"-vT"选项;
实际案例: weiyigeek.top-cat案例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# 示例1.常见示例
cat -n time.sh
cat -b time.sh
cat m1 m2 (同时显示文件ml和m2的内容)
cat m1 m2 > file (将文件ml和m2合并后放入文件file中)
# 示例2.特殊字符的显示
cat -A /etc/pam.conf
# ---------------------------------------------------------------------------#$
# /etc/pam.conf^I^I^I^I^I^I^I^I #$
# ---------------------------------------------------------------------------#$
#$
# NOTE$
# ----$
#$
# 示例2.从命令行中获取字符串以及变量写入文件之中。
cat << EOF > es.env
ES_HOME=${ES_HOME}
EOF
# 示例3.使用cat输出变量到文件时如果是"EOF"并不会将该变量进行赋值改变(小差别值得注意)。
demo="WeiyiGeek"
cat > demo1.yaml <<"EOF"
name=${demo}
EOF
# 执行结果: name=${demo}
# 可解析变量
cat > demo2.yaml <<EOF
name=${demo}
EOF
# 执行结果: name=WeiyiGeek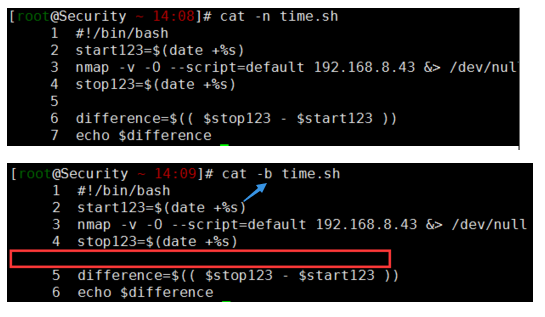
描述: 该命令实际是cat的反向显示的命令;
基础示例:1
2
3
4
5
6
7
8
9
10# 1.cat 与 tac 对比显示;
❯ cat /etc/resolv.conf
nameserver 223.5.5.5
nameserver 223.6.6.6
nameserver fec0:0:0:ffff::1
❯ tac /etc/resolv.conf
nameserver fec0:0:0:ffff::1
nameserver 223.6.6.6
nameserver 223.5.5.5
描述: 该命令是添加行号打印;
语法参数:1
2
3
4
5
6
7
8
9
10
11nl [-bnw] 文件
# 参数:
-b :指定行号指定的方式主要两个中方式;
a : 不论是否有空行页列出行号
t : 对于空行不列出行号进行跳过
- n : 列出行号的表示方法主要有三种;
ln : 行号在屏幕最左方显示
rn : 行号在屏幕最右方显示,且不加0
rz : 行号在屏幕最右方显示,且加0
- w : 行号字段占用的位数;
基础示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 示例1.用nl列出/etc/issue的内容包括空行
❯ nl -b a /etc/issue
1 Ubuntu 20.04 LTS \n \l
2 Windows WSL
3
# 示例2.行号格式设置
❯ nl -b a -n rz /etc/issue # 缺省
000001 Ubuntu 20.04 LTS \n \l
000002 Windows WSL
000003
❯ nl -b a -n rz -w 3 /etc/issue # 指定行号宽度
001 Ubuntu 20.04 LTS \n \l
002 Windows WSL
003
描述:用于显示文件的开头的内容,在默认情况下,head命令显示文件的头10行内容。
如果指定了多于一个文件在每一段输出前会给出文件名作为文件头,如果不指定文件,或者文件为”-“,则从标准输入读取数据。
语法参数:1
2
3
4
5-数字 :显示行数
-n <数字> :指定文件头部要显示内容的行数;
-c <字符数> :指定显示头部内容的字符数;
-v :总是显示文件名的头信息;
-q : 不显示文件名信息;
操作示例: weiyigeek.top-heade示例1
2
3
4
5
6
7
8
9
10
11
12
13
14#示例1.基础示例
head /etc/passwd #显示开头前10行
head -1 /etc/passwd #显示开头前 -k 行
head -2 run.js
# const { exec } = require('child_process')
# exec('hexo server -p 80 -d',(error, stdout, stderr) => {
#示例2. #除最后k行外,显示剩余全部内容
head -n -k /etc/passwd
head -n -10 10.txt #不打印后10行及开头到倒数10行被打印
# 示例3.1个字符占1个字节,注意回车换行各算一个字节
head -c 100 /etc/passwd #显示前100字节的字符
head -c -100 /etc/passwd #显示从0到倒数第100字节的字符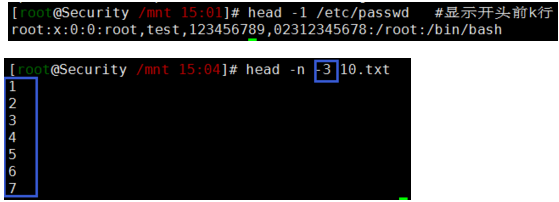
描述:用于输入文件中的尾部内容,命令也可以指定开始点将文件标准输出,默认在屏幕上显示指定文件的末尾10行。
如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题,如果没有指定文件或者文件名为“-”,则读取标准输入。
语法参数:1
2
3
4
5
6
7
8
9
10
11
12tail(选项)(参数)
# 参数
--retry:即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。使用此选项时需要与选项“——follow=name”连用;
-c<N>或——bytes=<N>:输出文件尾部的N(N为整数)个字节内容;
-f<name/descriptor>或 ;--follow<nameldescript>:显示文件最新追加的内容。“name”表示以文件名的方式监视文件的变化。“-f”与“-fdescriptor”等效;(常用)
-F:与选项“-follow=name”和“--retry"连用时功能相同"
-n<N>或——line=<N>:输出文件的尾部N(N位数字)行内容。 (常用)
--pid=<进程号>:与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令;
-q或——quiet或——silent:当有多个文件参数时,不输出各个文件名;
-s<秒数>或——sleep-interal=<秒数>:与“-f”选项连用,指定监视文件变化时间隔的秒数; (常用)
-v或——verbose:当有多个文件参数时,总是输出各个文件名;
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 示例1.简单监控查看更新文件3行
tail -f -n 3 -s 3 /var/log/messages #每3秒更新
Jun 26 08:01:01 master systemd: Removed slice User Slice of root.
Jun 26 09:01:01 master systemd: Created slice User Slice of root.
Jun 26 09:01:01 master systemd: Started Session 25 of user root.
# 示例2.简单使用
tail file # 默认显示文件file的最后10行
tail +20 file # 显示文件file的内容,从第20行至文件末尾
tail -c 10 file # 显示文件file的最后10个字符
tail -n 4 file # 显示文件file的最后四行
# 示例3.head与tail联合使用取文件的11行到20行
head -n 20 demo.txt | tail -n 10
# 示例4.从第二行显示到末尾
cat /etc/passwd | tail -n+2
注意事项:
描述:监测一个命令的运行结果,省的你一遍遍的手动运行,在Linux下,watch是周期性的执行下个程序,并全屏显示执行的结果;
语法参数:1
2
3
4
5
6#命令格式:
watch[ 参数 ][命令]
#命令参数:
-n或--interval watch 缺省每2秒运行一下程序,多用于周期性执行命令/定时执行命令。
-d或-differences watch 会高亮显示变化的区域,而-d = cumulative 选项会把变动过的地方(不管最近的那次有没有变动)都会高亮显示出来。
-t或-no-title 会关闭watch 命令在顶部的时间间隔命令,
实际案例: weiyigeek.top-watch示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17watch -n 2 tail -20 /var/log/messages 每隔两秒钟跳一下最后20行的内容查看事实的信息
#实例1:每隔一秒高亮显示网络链接数的变化情况 (重要)
命令 watch -n 1 -d netstat -ant
#实例2:每隔一秒高亮显示命令链接数的变化情况
命令 watch -n 1 -d ' pstree | grep http ' #每隔一秒高亮显示http 链接数的变化情况,后面接的命令若带有管道符,需要加“将命令区域归整”。
#实例3:实时查看模拟攻击客户机建立起来的链接数
命令 watch 'netstat -an | grep:21 | \grep<模拟攻击客户机的IP> wc -1'
#实例4:检测当前目录中 scf ' 的文件的变化
命令:watch -d 'ls -l | grep scf'
#实例5:10秒一次输出系统的平均负载
命令:watch -n 10 ' cat /proc/loadavg'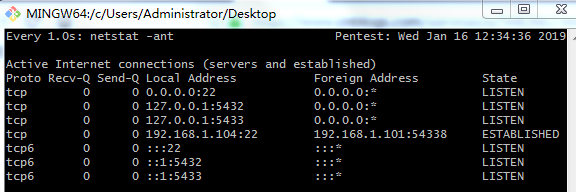
描述:用于统计文本中行数的单词数以及字节数;
参数:1
2
3
4
5
6
7wc【选项】【文件名】 #字符/行数/字节所统计
#选项:
-l 统计行数
-w 统计单词数
-c 统计字节数
-m 统计字符数(对于中文)
-L 统计字符串长度
实际操作: weiyigeek.top-wc示例1
2
3
4
5
6
7
8
9
10
11
12#示例1.显示文件的内容信息
$wc run.js
9 26 251 run.js #'行数' '单词数' '字节数' install.log
#其他示例
wc -c test.txt #显示字节数中午也显示1个字节
wc -m test.txt #主要针对于中午字符(两个字节)
#示例3.验证文件字符长度
$ echo 1234567890 > www.txt
$ echo 1234567890 | wc -L # 长度为10 (重点)
$ cat www.txt | wc -L #长度为10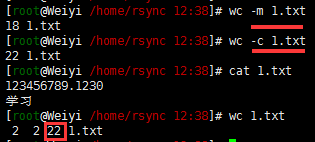
描述:显示文件或文件系统的状态,显示出文件的大小以及块大写所属权限用户组和创修访问时间。
语法和参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57stat [选项]... 文件
# 必选参数对长短选项同时适用。
-L, --dereference 跟随链接
-f, --file-system 显示文件系统状态而非文件状态
-c --format=FORMAT use the specified FORMAT instead of the default;output a newline after each use of FORMAT
--printf=FORMAT Like --format, but interpret backslash escapes,and do not output a mandatory trailing newline; if you want a newline, include \n in FORMAT
-t, --terse 以简洁方式输出信息;
# 格式化字符串
The valid format sequences for files (without --file-system):
%a access rights in octal
%A access rights in human readable form
%b number of blocks allocated (see %B)
%B the size in bytes of each block reported by %b
%C SELinux security context string
%d device number in decimal
%D device number in hex
%f raw mode in hex
%F file type
%g group ID of owner
%G group name of owner
%h number of hard links
%i inode number
%m mount point
%n file name
%N quoted file name with dereference if symbolic link
%o optimal I/O transfer size hint
%s total size, in bytes
%t major device type in hex, for character/block device special files
%T minor device type in hex, for character/block device special files
%u user ID of owner
%U user name of owner
%w time of file birth, human-readable; - if unknown
%W time of file birth, seconds since Epoch; 0 if unknown
%x time of last access, human-readable
%X time of last access, seconds since Epoch
%y time of last modification, human-readable
%Y time of last modification, seconds since Epoch
%z time of last change, human-readable
%Z time of last change, seconds since Epoch
Valid format sequences for file systems:
%a free blocks available to non-superuser
%b total data blocks in file system
%c total file nodes in file system
%d free file nodes in file system
%f free blocks in file system
%i file system ID in hex
%l maximum length of filenames
%n file name
%s block size (for faster transfers)
%S fundamental block size (for block counts)
%t file system type in hex
%T file system type in human readable form
--terse 等同于以下格式: %n %s %b %f %u %g %D %i %h %t %T %X %Y %Z %W %o %C
--terse --file-system 等同于以下格式: %n %i %l %t %s %S %b %f %a %c %d
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46#实例1.常规形式打印文件的详细信息
stat weiyigeek.txt
文件:weiyigeek.txt
# 大小:15 块:8 IO 块:4096 普通文件
# 设备:fe00h/65024d Inode:2105407 硬链接:1
# 权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
# 最近访问:2026-07-22 01:29:48.574588495 +0800 Access Time
# 最近更改:2026-07-22 01:29:45.246588379 +0800 Modifiy Time
# 最近改动:2026-07-22 01:29:45.246588379 +0800 Change Time
#示例2.显示文件系统的详细信息
stat -f /etc/passwd
# 文件:"/etc/passwd"
# ID:fd0000000000 文件名长度:255 类型:xfs
# 块大小:4096 基本块大小:4096
# 块:总计:11821425 空闲:10717632 可用:10717632
# Inodes: 总计:23654400 空闲:23573486
#实例3.用简洁的形式打印信息
stat -t weiyigeek.txt
# weiyigeek.txt 15 8 81a4 0 0 fe00 2105407 1 0 0 1784654988 1784654985 1784654985 0 4096
#示例4.-c选项的妙用
stat -c "%a %A %u %U %g %G" /etc/passwd #文件权限完整显示文件的权限以八进制
# 644 -rw-r--r-- 0 root 0 root
stat -c "%i %f %F %h" /etc/passwd #文件信息完整显示
# 33582780 81a4 普通文件 1
stat -c "%s %b %B" /etc/passwd #文件大小以byte以及块大小和个块的字节大小
# 1034 8 512
#示例5.-L,跟踪显示链接文件信息
ls -alh phantomjs
# lrwxrwxrwx. 1 root root 38 5月 29 11:41 phantomjs -> /usr/local/src/phantomjs/bin/phantomjs
stat -L phantomjs
# 文件:"phantomjs"
# 大小:67932064 块:132680 IO 块:4096 普通文件
# 设备:fd00h/64768d Inode:34604541 硬链接:1
# 权限:(0755/-rwxr-xr-x) Uid:( 0/ root) Gid:( 0/ root)
# 环境:unconfined_u:object_r:admin_home_t:s0
# 最近访问:2020-07-01 08:30:01.326875354 +0800
# 最近更改:2016-01-25 09:01:06.000000000 +0800
# 最近改动:2020-05-29 11:41:42.369696124 +0800
# 创建时间:-
描述:jq它能轻松地把你拥有的数据转换成你期望的格式,而且需要写的程序通常也比你期望的更加简短。它可以对json数据进行分片、过滤、映射和转换,和sed、awk、grep等命令一样,都可以让你轻松地把玩文本。
基础语法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Usage: jq [options] <jq filter> [file...]
-c 单行输出json字符串;
-n 使用“null”作为单个输入值;
-e 设置输出时候的退出状态码;
-s read (slurp) all inputs into an array; apply filter to it;
-r output raw strings, not JSON texts; 输出原始字符串,而不是JSON文本;
-R read raw strings, not JSON texts;
-C colorize JSON;
-M monochrome (dont colorize JSON);
-S sort keys of objects on output;
--tab use tabs for indentation;
--arg a v set variable $a to value <v>;
--argjson a v set variable $a to JSON value <v>;
--slurpfile a f set variable $a to an array of JSON texts read from <f>;
--rawfile a f set variable $a to a string consisting of the contents of <f>;
--args remaining arguments are string arguments, not files;
--jsonargs remaining arguments are JSON arguments, not files;
注意事项:
基础示例:例子文件在文件json.txt中保存如下内容1
[{"name":"WeiyiGeek","url":"http://tool.chinaz.com","address":{"city":"xiameng","country":"China"},"arrayBrowser":[{"name":"Google","url":"http://www.google.com"},{"name":"Baidu","url":"http://www.baidu.com"}]},{"name":"WeiyiGeek","url":"http://tool.zzhome.com","address":{"city":"dalian","country":"China"},"arrayBrowser":[{"name":"360","url":"http://www.so.com"},{"name":"bing","url":"http://www.bing.com"}]}]
最简单的jq程序是表达式”.” 个人理解为根,它不改变输入,但可以将其优美地输出便于阅读和理解
1 | echo '{"foo": 0,"bar":1}' | ./jq . |
输出列表中的第一个元素,可以使用[index],也可以输出指定字符:
1 | cat json.txt | jq '.' #方式1.可以采用管道符传递数据 |
jq支持管道线|,它如同linux命令中的管道线——把前面命令的输出当作是后面命令的输入
1 | cat json.txt | jq '.[0] | {name:.name,city:.address.city}' |
如果希望把jq的输出当作一个数组,可以在前后加上[]:
1 | cat json.txt | jq "[.[] | {name:.arrayBrowser[1].name,city:.address.city}]" |
自定义key在{}中冒号前面的名字是映射的名称,你可以任意修改
1 | cat json.txt | jq "[.[] | {name_001:.arrayBrowser[1].name,city_002:.address.city}]" |
内建函数jq还有一些内建函数如 key,has(用来是判断是否存在某个key)
1 | #比如key是用来获取JSON中的key元素的: |
提取指定的多个json字段(重点),遍历数组采用[]
1 | $ jq -r '.[1].name+","+(.[1].url|tostring)' json.txt |
调用数组的join方法,来将数组转换成拼接字符串,
1 | jq -r "[.[].name]" json.txt |
指定格式输出
1 | jq -r '[.[].name,.[].url]|@text' json.txt |
补充说明:
[]形式,[]表示遍历整个数组,如果你只想访问数组中的第2个元素(下标从0开始),你可以使用[1];如果想要访问第3个到第5个元素,可以使用[2:4];附录
官方文档:https://stedolan.github.io/jq/manual
表达式在线测试器:https://jqplay.org/
教程:https://github.com/stedolan/jq/wiki/Cookbook
描述:lslocks列出有关的所有信息在Linux系统中已保存的文件锁;
1 | # 示例1.列出当前系统中被加锁的文件 |
描述:比较给定的两个文件不同之处,并以所在行的形式进行显示;默认是以逐行的方式进行比较文本文件的异同处,比较两个文件的内容 (源文件 和 目标文件),如果使用“-”代替“文件”参数,则要比较的内容将来自标准输入。
基础语法1
diff [选项] … [文件1或目录1] [文件2或目录2](四种组合方式)
命令参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115-a,--text 把所有文件当做文本文件逐行比较
-b,--ignore-space-change 忽略空格产生的变化
-B,--ignore-blank-lines 忽略空白行的变化
-c,–C NUM,--context[=NUM] 使用上下文输出格式(文件1在上,文件2在下,在差异点会标注出来),输出NUM(默认3)行的上下文(上下各NUM行,不包括差异行)
-d,--minimal 使用不同的算法,努力寻找一个较小的变化集合。这会使diff变慢(有时更慢)
-D NAME,--ifdef=NAME 合并if-then-else格式输出,预处理宏(由NAME参数提供)条件
-e,--ed 输出一个ed格式的脚本文件
-E,--ignore-all-space 忽略由于Tab扩展而导致的变化
-F RE,--show-function-line=RE 在上下文输出格式(文件1在上,文件2在下)和统一输出格式中,对于每一大块的不同,显示出匹配RE(regexp正则表达式)最近的行
-i,--ignore-case 忽略大小写的区别
-I RE,--ignore-matching-lines=RE 忽略所有匹配RE(regexp正则表达式)的行的更改
-l,--paginate 通过pr编码传递输出,使其分页
-n,--rcs 输出RCS格式差异
-N,--new-file 把缺少的文件当做空白文件处理
-p,--show-c-function 显示带有C函数的变化
-q,--brief 仅输出文件是否有差异,不报告详细差异
-r,--recursive 当比较目录时,递归比较所有找到的子目录
-s,--report-identical-files 当两个文件相同时报告
-S FILE,--starting-file=FILE 在比较目录时,从FILE开始。用于继续中断的比较
-t,--expand-tabs 将输出时扩展Tab转换为空格,保护输入文件的tab对齐方式
-T,--initial-tab 通过预先设置的tab使选项卡对齐(???)
-u,-U NUM,--unified[=NUM] 使用统一输出格式(输出一个整体,只有在差异的地方会输出差异点,并标注出来),输出NUM(默认3)行的上下文(上下各NUM行,不包括差异行)
-v,--version 输出版本号
-w,--ignore-all-space 比较时忽略所有空格
-W NUM,--width=NUM 在并列输出格式时,指定列的宽度为NUM(默认130)
-x PAT,--exclude=PAT 排除与PAT(pattern样式)匹配的文件
-X FILE,--exclude-from=FILE 排除与FILE中样式匹配的文件
-y,--side-by-side 使用并列输出格式
--from-file=FILE1 FILE1与所有操作对象比较,FILE1可以是目录
--help 输出帮助信息
--horizon-lines=NUM 保留NUM行的公共前缀和后缀
--ignore-file-name-case 比较时忽略文件名大小写
--label LABEL 使用LABEL(标识)代替文件名
--left-column (在并列输出格式中)只输出左列的公共行
--no- ignore-file-name-case 比较时考虑文件名大小写
--normal 输出一个正常的差异
--speed-large-files 假设文件十分大,而且有许多微小的差异
--strip-trailing-cr 去掉在输入时尾随的回车符
--suppress-common-lines 不输出公共行
--to-file=FILE2 所有操作对象与FILE2比较,FILE2可以是目录
--unidiredtional-newfile 将缺少的第一个文件视为空文件
--GTYPE-group-format=GFMT 以GFMT格式化GTYPE输入组
--line-format=LFMT 以LFMT格式化输入所有行
--LTYPE-line-format=LFMT 以LFMT格式化LTYPE输入行
LTYPE可以是’old’,’new’或’unchanged’。GTYPE可以是LTYPE选项或’changed’
GFMT包括:
%< 该行属于FILE1
%> 该行属于FILE2
%= 该行属于FILE1和FILE2公共行
%[-][WIDTH(宽度)][.[PREC(精确度)]]{doxX}LETTER(字母) printf格式规范LETTER。如下字母表示属于新的文件,小写表示属于旧的文件:
F 行组中第一行的行号
L 行组中最后一行的行号
N 行数(=L-F+1)
E F-1
M L+1
LFMT可包含:
%L 该行内容
%l 该行内容,但不包括尾随的换行符
%[-][WIDTH][.[PREC]]{doxX}n printf格式规范输入行编号
GFMT或LFMT可包含:
%% %
%c’C’ 单个字符C
%c’\000’ 八进制000所代表的字符
特殊字符含义:
实际案例:1
2
3
4
5
6
7
8
9#示例1.将目录/usr/li下的文件"test.txt"与当前目录下的文件"test.txt"进行比较
diff /usr/li test.txt #使用diff指令对文件进行比较
n1 a n3,n4
n1,n2 d n3
n1,n2 c n3,n4
#示例2.比较两个文件夹不同和和递归比较
diff -r myweb/ html
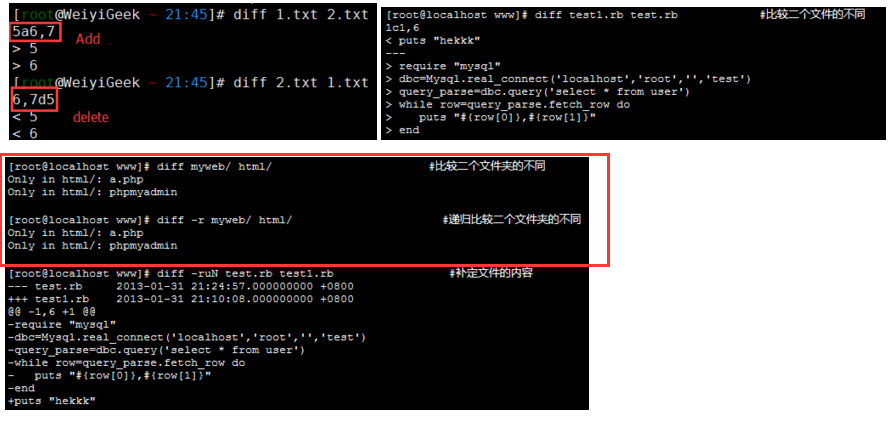
weiyigeek.top-示例2
1 | #示例3.将补定文件进行输入到新文件夹中 |
注意事项:
源文件 是一个目录和 目标文件 不是(目录), diff 会比较在 源文件(目录) 里的文件的中和目标文件同名的(文件) , 反过来也一样非目录文件不能是 - .描述:可以用于两个文件之间的比较( 逐行比较两个已排序的文件),它有一些选项可以用来调整输出,以便执行交集、求差、以及差集操作。
基础语法:1
2
3
4
5
6
7
8
9comm(选项)(参数)
#选项
-1:不显示在第一个文件出现的内容;
-2:不显示在第二个文件中出现的内容;
-3:不显示同时在两个文件中都出现的内容。
--check-order check that the input is correctly sorted, even if all input lines are pairable
--nocheck-order do not check that the input is correctly sorted
--output-delimiter=STR separate columns with STR
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45#示例1.输出的第一列只包含在aaa.txt中出现的行,第二列包含在bbb.txt中出现的行,第三列包含在aaa.txt和bbb.txt中相同的行。各列是以制表符(\t)作为定界符。
$ comm aaa.txt bbb.txt
aaa
bbb
ccc
aaa
ddd
eee
111
222
hhh
ttt
jjj
第一列 第二列 第三列
#示例2. 交集 打印两个文件的交集,需要删除第一列和第二列:
comm aaa.txt bbb.txt -1 -2 #即自显示第三列
# bbb
# ccc
#示例3. 求差 打印出两个文件中不相同的行,需要删除第三列:
comm aaa.txt bbb.txt -3 | sed 's/^\t//' # 连续的bbb,ccc可以匹配, 是将制表符(\t)删除,以便把两列合并成一列。
comm -3 t1.txt t2.txt --nocheck-order | tr -d '\t'
aaa
aaa
ddd
eee
111
222
hhh
ttt
jjj
comm -3 t1.txt t2.txt --nocheck-order | tr -d '\t' | uniq -u #删除重复的行
#示例3.差集通过删除不需要的列,可以得到aaa.txt和bbb.txt的差集:
$comm aaa.txt bbb.txt -1 -3 #aaa.txt的差集
$comm aaa.txt bbb.txt -2 -3 #bbb.txt的差集
aaa
ddd
eee
111
222
描述: split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等
语法参数:1
2
3
4
5
6
7
8
9
10
11
12
13-d 使用数字而不是字母作为切割后的小文件的后缀;
-a <number>,后缀的length
-v 显示详细的处理信息
-b <字节> 每个分割文件的大小
-C <数字> 指定输出到每一个文件的每一行的大小,数字后缀可以是
b: 512(blocks) #非常注意
K: 1024(kibiBytes)
KB: 1000(kiloBytes)
M: 1024*1024(mebiBytes)
MB: 1000*1000(megaBytes)
G: 1024*1024*1024(gibiBytes)
GB: 1000*1000*1000(gibaBytes) #T, P, E, Z, Y
-l<行数> 指定切割的行数作为切割文件的单位;
实际案例: weiyigeek.top-split分割1
2
3
4
5
6
7
8# 示例1.生成一个大小为100KB的测试文件,然后将其进行分割,并恢复为原始文件。
dd if=/dev/zero bs=100k count=1 of=date.file
# 使用split命令将上面创建的date.file文件分割成大小为10KB的小文件 data_split{a,b,c……}
split -b 10k date.file data_split
# 以下是将各个块重新构建到原始文件中new_date.file
cat data_split* > new_date.file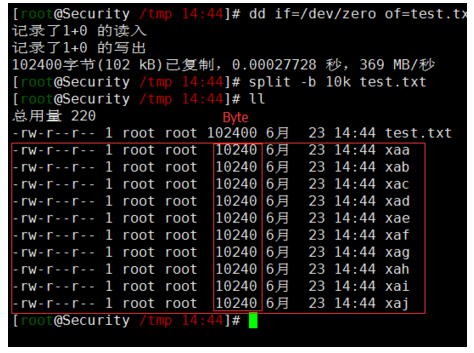
1 | # 示例2.文件被分割成多个带有字母的后缀文件,如果想用数字后缀可使用-d参数,同时可以使用-a length来指定后缀的长度: |
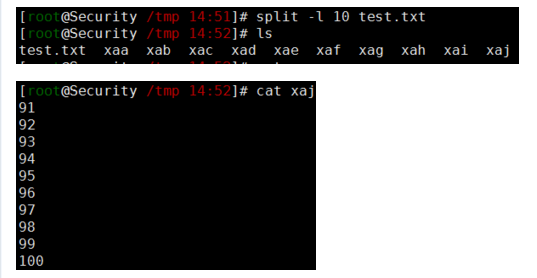
weiyigeek.top-split使用示例示例
描述:用于将一个大文件分割成小的碎片,并且将分割后的每个碎片保存成一个文件。碎片文件的命名类似“xx00”,“xx01”,同时每个分块文件的字节数也将被输出到标准输出。
csplit命令是split的一个变体,他们的不同点:
语法参数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18csplit [选项]... 文件or格式 #如果文件为"-",则读取标准输入
csplit [-kqsz][-b<输出格式>][-f<输出字首字符串>][-n<输出文件名位数>][文件][范本样式...]
#长选项必须使用的参数对于短选项时也是必需使用的:
-b, --suffix-format=格式 使用sprintf 格式代替%02d.log,与-n连用形成后缀;
-f, --prefix=前缀 使用指定前缀代替"xx",“hello”,则输出的文件名称会变成hello00,hello、
-k, --keep-files 不移除错误的输出文件
-n, --digits=数位 使用指定的进制数位代替二进制,“3”,则输出的文件名称会变成xx000,xx001等
-z, --elide-empty-files 删除空的输出文件
#格式"可以是,一个行的偏移量需要在正整数值之后声明"+" 或 "-"
整数 不包括指定的行,并以其为文件分块边界
/表达式/[偏移量] 不包括匹配到的行,并以其为文件分块边界
%表达式%[偏移量] 预先跳过匹配的行数,以其为文件分块边界
-s, --quiet, --silent 不显示输出文件的尺寸计数
{整数} 将之前指定的模式重复指定的次数
{*} 将之前指定的模式重复尽可能多的次数。
实际案例: weiyigeek.top-内容分割1
2
3
4
5#示例1。需要将server.log分割成server1.log、server2.log、server3.log,这些文件的内容分别取自原文件中不同的SERVER部分:
csplit server.log /SERVER/ -n2 -s {*} -f server -b "%02d.log"; rm server00.log ; ls #匹配SERVER边界每次以它作为分割界限
$csplit textfile /"Chapter X"/ #把文件以字符串"Chapter X"为分界符,分成两部分
#承上例, 但分割文件时以"Chapter X"字符串往下4行才是分割点
$csplit textfile /"Chapter X"/+4server01.log server02.log server03.log server.log
1 | #示例3.按行分割 |
注意事项:
描述:用来显示行中的指定部分,删除文件中指定字段,在文件的每一行中提取片断,在 每个文件 FILE 的 各行 中, 把 提取的片断显示在标准输出.
cut命令有两项功能:
参数语法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15-b, --bytes=LIST:仅显示行中指定直接范围的内容;
-c, --characters=LIST:仅显示行中指定范围的字符;
-d, --delimiter=DELIM:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f, --fields=LIST:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;(取反显示)
--output-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
#使用且只使用 -b, -c 或 -f 中的一个选项. LIST 由 一个 范围 (range) 或 逗号 隔开的多个范围组成. 范围是下列形式 之一:
N : 第 N 个 字节, 字符 或 字段, 从 1 计数 起
N- : 从 第 N 个 字节, 字符 或 字段 直至 行尾
N-M:从 第 N 到 第 M (并包括 第M) 个 字节, 字符 或 字段
-M : 从 第 1 到 第 M (并包括 第M) 个 字节, 字符 或 字段
#如果 没有 指定 文件 FILE, 或 FILE 是 -, 就从 标准输入 读取 数据.
实际操作: weiyigeek.top-cut示例1融合1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17cat test.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
#示例1:采用默认的<tab>分割然后使用-f来提取指定字段
cut -f 1 test.txt
# No
# 01
# 02
# 以:分割文件,输出第一,二,三个字段(指定分隔符)
cat /etc/passwd | cut -f 1,2,3 -d ":" | head -5
#示例2.输出passwd中得第一个字符
cat /etc/passwd | cut -b 1
cat /etc/passwd | cut -b 1-4 | head -5 #输出文件的前四个字符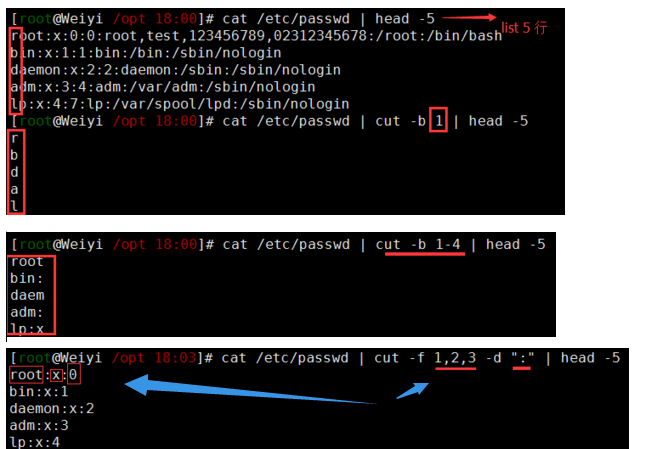
1 | #示例3.以特殊符号进行分割时 $'\n' (换行), $'\t'(Tab建),按照反斜杠控制的字符转换进行转换(printf 输出格式): |
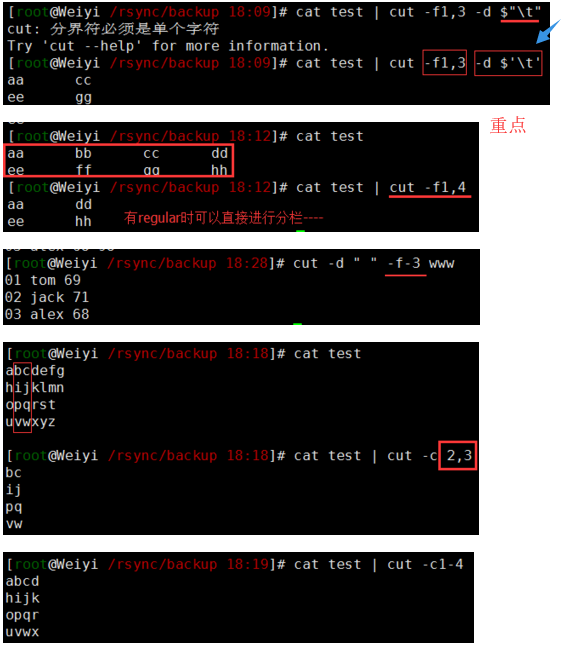
weiyigeek.top-cut示例
注意事项:
需要采用''单引号否则会报错;描述:在Linux里非常有用,它将文件进行排序,并将排序结果标准输出,sort命令既可以从特定的文件,也可以从stdin中获取输入。
参数语法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47用法:sort [选项]... [文件]... 或: sort [选项]... --files0-from=F
#串联排序所有指定文件并将结果写到标准输出,如果不指定文件,或者文件为"-",则从标准输入读取数据。
#排序选项:
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort 按照常规数值排序
-i, --ignore-nonprinting 只排序可打印字符
-M, --month-sort 比较 (未知) < "一月" < ... < "十二月" 在LC_ALL=C 时为(unknown) < 'JAN' < ... < '`DEC'
-h, --human-numeric-sort 使用易读性数字(例如: 2K 1G-即文件大小排序)
-n, --numeric-sort 根据字符串数值比较(数字排序,默认是升序)
-R, --random-sort 根据随机hash 排序
--random-source=文件 从指定文件中获得随机字节
-r, --reverse 逆序输出排序结果
--sort=WORD 按照WORD 指定的格式排序:一般数字-g,高可读性-h,月份-M,数字-n,随机-R,版本 "general-numeric" - "human-numeric" - "month" - "numeric" - "random" - "version"
-V, --version-sort 在文本内进行自然版本排序
#其他选项:
--batch-size=NMERGE 一次最多合并NMERGE 个输入;如果输入更多则使用临时文件
-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作
-C, --check=quiet, --check=silent 类似-c,但不报告第一个无序行
--compress-program=程序 使用指定程序压缩临时文件;使用该程序的-d 参数解压缩文件
--debug 为用于排序的行添加注释,并将有可能有问题的用法输出到标准错误输出
--files0-from=文件 从指定文件读取以NUL 终止的名称,如果该文件被指定为"-"则从标准输入读文件名
-k, --key=位置1[,位置2] 在位置1 开始一个key,在位置2 终止(默认为行尾)参看POS语法
#补充-k选项的具体语法格式:
# FStart(字段).CStart(列) Modifie,FEnd.CEnd Modifier
# -------Start--------,-------End--------
# FStart.CStart 选项 , FEnd.CEnd 选项
# Start部分也由三部分组成于End部分以`,`分割,其中的Modifier部分就是我们之前说过的类似n和r的选项部分;,
# - 其中FStart就是表示使用的域,而CStart则表示在FStart域中从第几个字符开始算“排序首字符”。
# - 如果你省略.CEnd,则表示结尾到“域尾”,即本域的最后一个字符。或者如果你将CEnd设定为0(零),也是表示结尾到“域尾”。
-u, --unique # 配合-c,严格校验排序;不配合-c,则只输出一次排序结果(可以去重复)
-m, --merge 合并已排序的文件,不再进行排序
-o, --output=文件 #将结果写入到文件而非标准输出
-s, --stable 禁用last-resort 比较以稳定比较算法
-S, --buffer-size=大小 指定主内存缓存大小
-t, --field-separator=分隔符 #使用指定的分隔符代替非空格到空格的转换 类似于awk的-F,cut的-d选项;
-T, --temporary-directory=目录 使用指定目录而非$TMPDIR 或/tmp 作为临时目录,可用多个选项指定多个目录
--parallel=N 将同时运行的排序数改变为N
-z, --zero-terminated 以0 字节而非新行作为行尾标志
#指定的大小可以使用以下单位之一:
内存使用率% 1%,b 1、K 1024 (默认),M、G、T、P、E、Z、Y 等依此类推
实际案例: weiyigeek.top-sort示例11
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#示例0.会按照先字母后数字进行排序 (Default)即依次按ASCII码值进行比较,最后将他们按升序输出。
sort -n 1.txt #默认以第一个数据来排序,而且默认是以字符串形式来排序,所以由字母 a 开始升序排序 (可以不加上-k 1,1)
# admin
# blog
# pass
# 123
#示例1.直接去重复进行排序
echo -e " 10.0.0.1 \n 10.0.0.2 \n 10.0.0.2 \n 10.0.0.1 \n 10.0.0.1 \n 10.0.0.3 " | sort -u
# 10.0.0.1
# 10.0.0.2
# 10.0.0.3
#示例1.指定分隔符与位置去掉重复值
sort -t ":" -k 1,1 /etc/passwd #内容是以 : 来分隔的,以第一栏第一个单词排序来排序(默认按照字母排序)
cat /etc/passwd | sort -t':' -k 7 -u
cat /etc/passwd | sort -t ':' -k 3n #用数字排序,默认是以字符串来排序的
cat /etc/passwd | sort -t ':' -k 3nr #倒序排列,默认是升序排序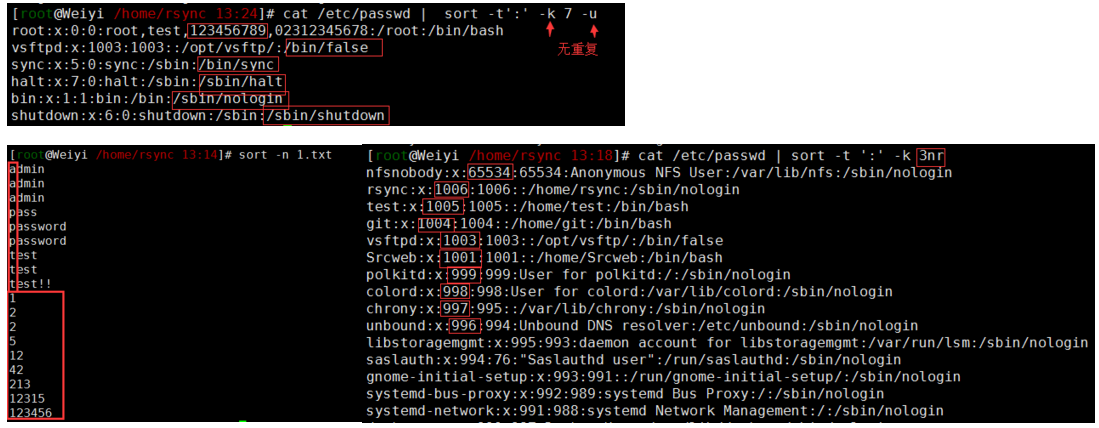
1 | #示例2.-k选项基础使用于进阶 |
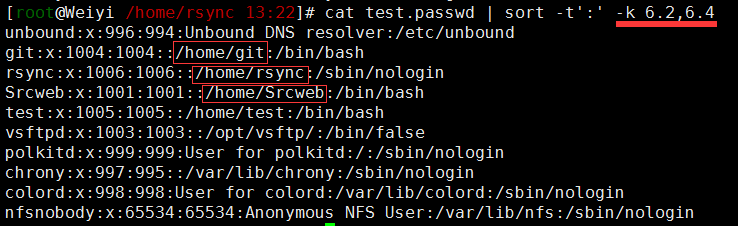
weiyigeek.top-sort示例2
描述:用于报告或忽略文件中的重复行,一般与sort命令结合使用
语法参数:1
2
3
4
5
6
7
8
9
10
11uniq(选项)(参数)
输入文件:指定要去除的重复行文件。如果不指定此项,则从标准读取数据;
输出文件:指定要去除重复行后的内容要写入的输出文件。如果不指定此选项,则将内容显示到标准输出设备(显示终端)。
#[选项]
-c或--count:在每列旁边显示该行重复出现的次数;
-d或--repeated:仅显示重复出现的行列,即表示显示重复的行;
-f n或--skip-fields=n:忽略比较指定的栏位,前n个字段与每个字段前的空白一起被忽略;
-s<字符位置>或--skip-chars=<字符位置>:忽略比较指定的字符;
-u或--unique:仅显示出一次的行列,即表示显示不重复的行;
-w<字符位置>或--check-chars=<字符位置>:指定要比较的字符。
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34#示例0。不加参数只对相邻的行相同的内容去重
uniq file.txt
echo -e "10.0.0.1 \n 10.0.0.2 \n 10.0.0.2 \n 10.0.0.1 \n 10.0.0.1 \n 10.0.0.3 " | uniq
# 10.0.0.1
# 10.0.0.2
# 10.0.0.1 (还是有重复)
# 10.0.0.3
uniq file.txt
#示例1.原本使用sort输出的内容中有很多重复(实际将重复的放在一起),可在后面加上|uniq完全去重
sort file.txt | uniq
echo -e " 10.0.0.1 \n 10.0.0.2 \n 10.0.0.2 \n 10.0.0.1 \n 10.0.0.1 \n 10.0.0.3 " | sort | uniq
# 10.0.0.1
# 10.0.0.2
# 10.0.0.3
#示例2.按照顺序排列并且显示不重复
sort -u file #作用相同去重复
sort file | uniq -u
uniq -u file #不显示重复的数据("只显示出现一次的数据,有重复过的数据则不显示")
#示例3.统计各行在文件中出现的次数
sort file.txt | uniq -c
echo -e " 10.0.0.1 \n 10.0.0.2 \n 10.0.0.2 \n 10.0.0.1 \n 10.0.0.1 \n 10.0.0.3 " | sort | uniq -c
# 3 10.0.0.1
# 2 10.0.0.2
# 1 10.0.0.3
#示例4.文件中找出重复行
sort file.txt | uniq -d
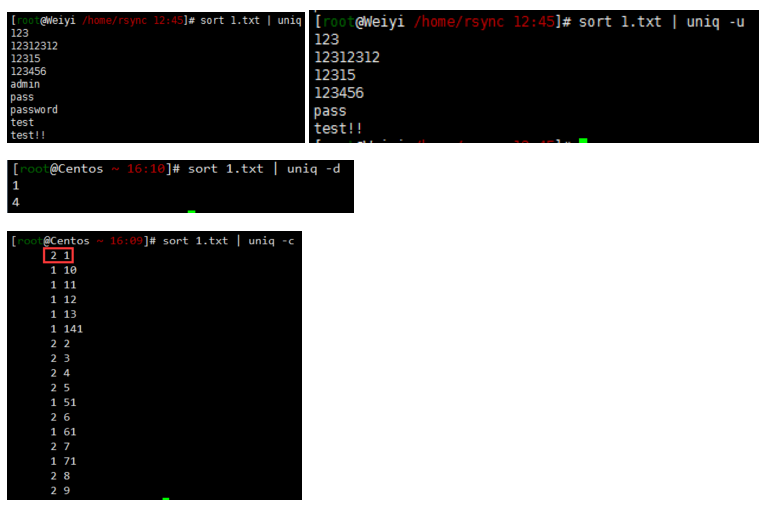
weiyigeek.top-基础示例
描述:用于限制文件列宽,fold指令会从指定的文件里读取内容,将超过限定列宽的列加入增列字符后,输出到标准输出设备。若不指定任何文件名称,或是所给予的文件名为”-“,则fold指令会从标准输入设备读取数据。
1 | #语法 |
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14#示例1.将一个0~9的数字文件进行行折叠宽度成为2
fold -w 2 test.log
# 0123456789
# 01
# 23
# 45
# 67
# 89
#示例2.密码字符长度截取
cat /dev/urandom | tr -dc '_a-zA-Z0-9!@#$%&*.-+' | fold -w 12 | head -1
# yduDZvYNLY42
# .g0VvfzPooh*
描述:truncate命令可以将一个文件缩小或者扩展到某个给定的大小;
基础用法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15用法:truncate 选项... 文件...
#长选项必须使用的参数对于短选项时也是必需使用的。
-c, --no-create 不创建文件
-o, --io-blocks 将SIZE 视为IO 块数而不使用字节数
-r, --reference=文件 使用此文件的大小
-s, --size=大小 使用此大小 KB 1000,K 1024,MB 1000*1000,M 1024*1024,还有 G、T、P、E、Z、Y。
--help 显示此帮助信息并退出
--version 显示版本信息并退出
#指定大小也可使用以下前缀修饰:
"+" 增加,"-" 减少,"<" 至多,">" 至少,
"/" 小于等于原尺寸数字的指定数字的最小倍数,"%" 大于等于原尺寸数字的指定数字的最大倍数。
译者注:当输入值为m,参考值为n 时,
"/" 运算的数学计算式为 m / n * n;
"%" 运算的数学计算式为( m + n - 1 ) / n * n
注意:-r 和-s 是互斥的选项。
基础实例:1
2
3
4
5
6
7
8
9#实例1.清空文件
truncate -s 0 /tmp/test
#实例2.设置文件大小与文件扩容
truncate -s +100M /tmp/test
[root@initiator tmp]$ du -ah test #显示真实文件的大小
0 test
[root@initiator tmp]$ ls -alh test #显示扩容后的文件大小
-rw-r--r--. 1 root root 100M 4月 20 22:16 test
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/系统运维/Linux/常用命令/文件管理类命令/文件查看分割命令.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/6-5-156.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议