[TOC]
前言
Shell正则表达式:使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,Linux上的一些编辑器就支持
例如:vi, grep, awk ,sed,expr等等工具,因为她们有支持正规表示法,所以这些工具就可以使用正规表示法的特殊字符来进行字符串的处理;
注意事项:
- 不同的软件在使用上有不同的差异:命令不一样但大部分是相同得.
- 语系对正则表达式的影响: 由于不同语系的编码数据不同,所以造成不同语系的数据选取结果有所差异。

[TOC]
Shell正则表达式:使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,Linux上的一些编辑器就支持
例如:vi, grep, awk ,sed,expr等等工具,因为她们有支持正规表示法,所以这些工具就可以使用正规表示法的特殊字符来进行字符串的处理;
注意事项:
[TOC]
Shell正则表达式:使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,Linux上的一些编辑器就支持
例如:vi, grep, awk ,sed,expr等等工具,因为她们有支持正规表示法,所以这些工具就可以使用正规表示法的特殊字符来进行字符串的处理;
注意事项:
1 | #以英文大小写为例,zh_CN.big5 及 C 这两种语系差异如下: |
一般使用的兼容与 POSIX 的标准,因此使用 C 语系;Shell中的正则表达式组成:
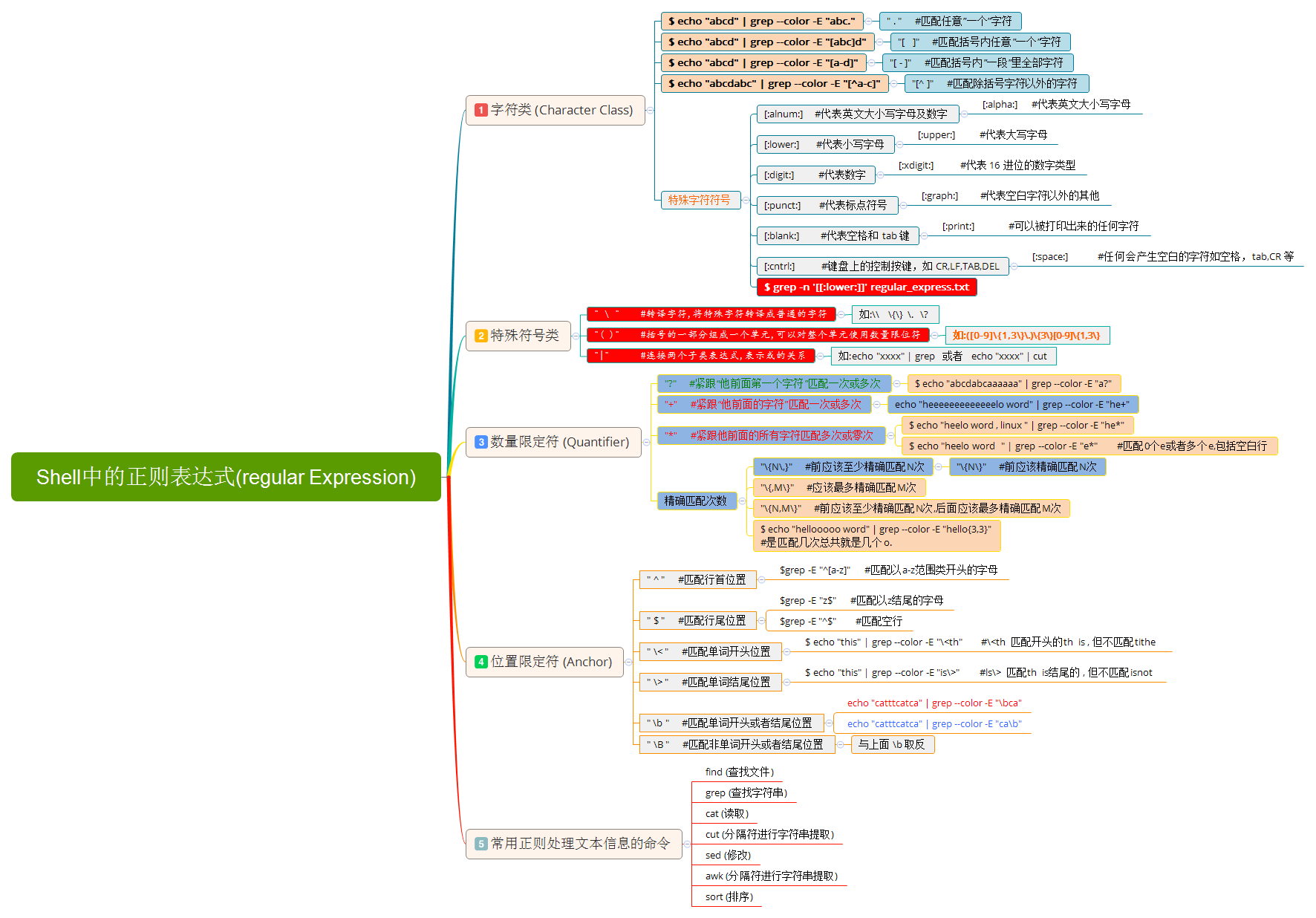
weiyigeek.top-Linux-reg-grep脑图
1 | 元字符 描述 |
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52#示例0.即相当于多种编程语言中都有的"转义字符"的概念。
#"\\n"匹配\n "\n"匹配换行符 序列"\\" 匹配"\" 而"\("则匹配"("
echo "1564362@qq.com" | grep -oE "^[0-9]{5,13}@qq\.com" --color #也可以用""
1564362@qq.com
#示例1.匹配行首 ^ [] ()
#如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。
echo "hello world" | grep -oE '^hello'
hello
#匹配手首行字母不对数字与字母产生效果
echo "abc123ABC bcd456BCD" | grep -oE '^[ab]'
a
#匹配括号里面的字符串
echo "abc123ABC bcd456BCD" | grep -E '^(abc)'
abc
#除此abc之外的全部字符
echo "abc123ABC bcd456BCD" | grep -E '[^abc]'
123ABC d456BCD
echo "plain 123 test" | grep -E '[^a-z]'
123
echo "abc123ABC" | grep -E '[A-Z]'
ABC
echo "abc123ABC bcd456BCD" | grep -oE '[ab]' #有a或者b
a
b
b
echo "abc123ABC acd456BCD" | grep -E 'a[bc]' #ab或者ac
#示例2.匹配行尾 $
grep -n '^$' regular_express.txt #查找空行 (常用)
echo "hello world" | grep -E 'world$' #如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。
world
#示例3.例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。
echo "hello helloe hellaa" | grep -oE 'hel(lo|loe)' #并列两个表达式 ^h|^H
hello
helloe
#例如“z|food”能匹配“z”或“food”,“(z|f)ood”则匹配“zood”或“food”
echo "zood food " | grep -oE 'z|food'
z
food
echo "zood food " | grep -oE '(z|f)ood'
zood
food
注意事项:
1 | .点 匹配除“\r\n”之外的任何单个字符 |
基础示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87# * = {0,}
echo "helloooo world" | grep -E '*o'
echo "helloooo world" | grep -oE 'o*' #zo*能匹配“z”,“zo”以及“zoo” , * 等价于{0,}
oooo
o
echo "helloooo world" | grep -oE 'lo*' #特殊点对比
l
loooo
l
echo "helloooo world" | grep -oE 'l|o*' #特殊点 匹配l或者o零次或者一次
l
l
oooo
o
l
# + = {1,}
echo "helloooo world" | grep -E 'lo+' #“zo+”能匹配“zo”以及“zoo”,但不能匹配“z” , + 等价于{1,}
echo "helloooo world" | grep -oE 'lo+'
loooo
# ? = {0,1}
echo "helloooo world" | grep -oE 'lo?' # “do(es)?” 可以匹配“do”或“does”中的“do” , ? 等价于{0,1} - 理解这个就可以理解上面的grep -oE 'lo*'
l
lo
l
echo "does doee" | grep -E 'do(es)?' # 匹配括号中的字符0次或者一次
does doee
# . = {1}
#匹配除“\r\n”之外的任何单个字符,要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。
echo -e "\n\rloo\n\r" | grep -oE "lo." #loo
echo -e "\n\rloo\n\r" | grep -oE "o." #oo
# --------------- 分割线--------------------
#例如“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o,或者o{n},n的倍数个o
echo "dooes" | grep -E 'o{2}' #匹配2次o,或者2的倍数个o
oo
echo "dooes" | grep -oE 'o{1}' #匹配1次o,或者全部o 特殊
o
o
echo "fooooood" | grep -oE 'fo{3}'
fooo
#例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o
echo "dooooes" | grep -oE 'o{1,}' #“o{1,}”等价于“o+” ,“o{0,}”则等价于“o*”
echo "dooooes" | grep -oE 'o{0,}'
oooo
echo "fooooood" | grep -oE 'fo{3,}'
foooooo
#例如,“o{,0}”不能匹配“Bob”中的“o”,“o{,n}”能匹配“foooood”中的所有o
echo "dooooes" | grep -E 'o{,1}' #至少匹配1次或者多次
echo "dooooes" | grep -E 'o{,2}'
echo "dooooo1osadasdoes" | grep -E "o{,0}" #就是不匹配o
echo "fooooood" | grep -oE 'fo{,3}'
fooo
#例如,“fo{1,3}”将匹配“fooooood”中的前三个o ,“o{0,1}”等价于“o?”
echo "fooooood" | grep -oE 'fo{1,3}' #请注意在逗号和两个数之间不能有空格
fooo
echo "fooooooooooooood" | grep -oE 'o{1,3}' #匹配1~3次
ooo
ooo
ooo
ooo
oo
#正则表达式A[0-9]{3} 能够匹配字符"A"后面跟着正好3个数字字符的串,A123、A348等,但是不匹配A1234
echo "A342 A3333 A666 A7894 " | grep -oE 'A[0-9]{3}\ '
A342
A666
#正则表达式[0-9]{4,6} 匹配连续的任意4个、5个或者6个数字
echo "A342 A3333 A666 A7894 A12345 " | grep -oE 'A[0-9]{4,5}\>' #匹配词(word)的结束
A3333
A7894
A12345
贪婪模式和非贪婪模式1
2
3
4
5
6
7#例如,对于字符串“loooo”,“lo?”将匹配单个“lo”,而“o+”将匹配所有“o”。
echo "loooo" | grep -oE "lo+" #loooo
echo "loooo" | grep -oE "lo?" #lo
echo "loooo helloooo" | grep -oE "lo+?"
loooo
l
loooo
注意事项:
1 | * \< 匹配词(word)的开始(\<) |
基础案例: weiyigeek.top-非开头和结尾1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# \< \>
例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。
注意:这个元字符不是所有的软件都支持的。
echo "plain 123 test" | grep -oE '\<pl' #pl
echo "plain 123 test" | grep -oE 'st\>' #st
# \b
例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”,或者匹配单词开头与结尾
[root@localhost ~]# echo "never verb" | grep -E 'er\b'
echo "computer is whoami iss" | grep -oE '\bis' #匹配头
is
is
echo "computer is whoami iss" | grep -oE 'is\b' #匹配尾
is
echo "computer is whoami iss" | grep -oE '\bis\b' #匹配头尾
is
# \B
例如,“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”,或者匹配非单词开头与结尾
echo "verb never" | grep -E 'er\B'
echo "computer is whoami issisis" | grep -E '\Bis' #非开头位置字符is
echo "computer is whoami issisis" | grep -E 'is\B' #非结尾位置字符is
echo "computer is whoami issisis" | grep -E '\Bis\B' #非开头结尾位置字符is
匹配位置常用正则表达式: weiyigeek.top-匹配位置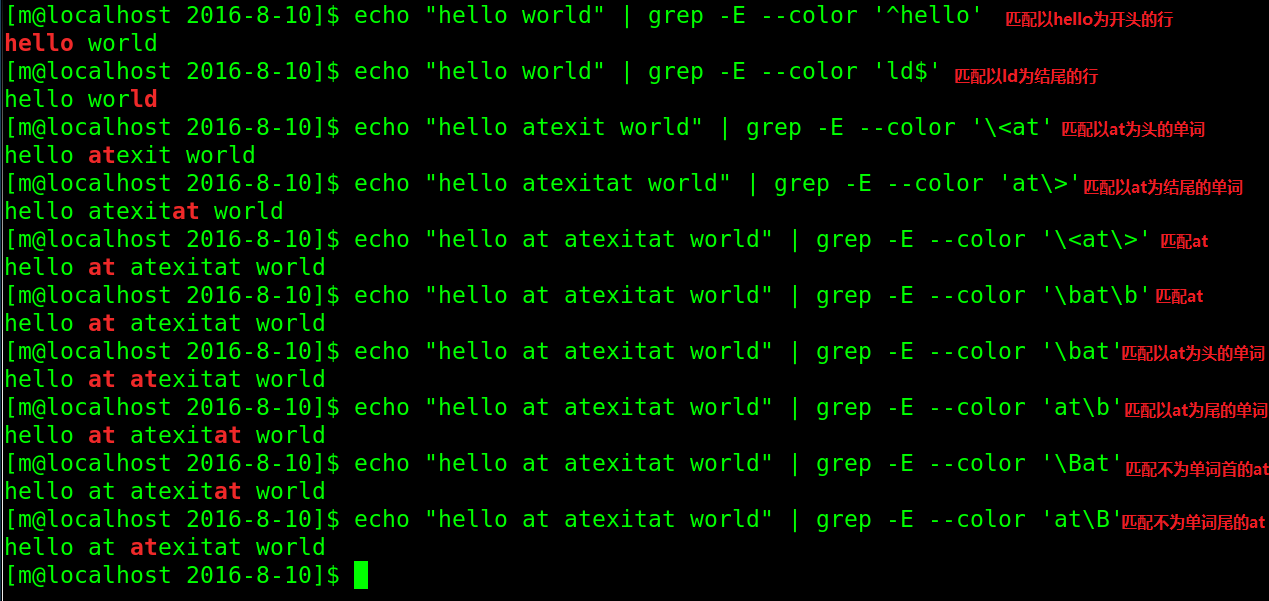
1 | # 数字与非数字 类匹配 |
描述:POSIX类是一个特殊的元字符类集1
2
3
4
5
6
7
8
9
10
11
12
13
14#grep 工具预定义(#define) 采用形式 [[:特殊符号:]]
[:alnum:] 代表英文大小写字母及数字
[:alpha:] 代表英文大小写字母
[:lower:] 代表小写字母
[:upper:] 代表大写字母
[:digit:] 代表数字(Dec默认十进制)
[:xdigit:] 代表16 进位的数字类型
[:punct:] 代表标点符号
[:graph:] 代表空白字符以外的其他
[:blank:] 代表空格和 tab 键
[:print:] 可以被打印出来的任何字符
[:cntrl:] 键盘上的控制按键,如 CR,LF,TAB,DEL
[:space:] 任何会产生空白的字符如空格,tab,CR 等
任意建立一个文本并编辑或者以原有的文本做实验皆可
基础示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14# cat > regular_express.txt<<END
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.Football game is not use feet only.
this dress doesn't fit me.However, this dress is about $ 3183 dollars.
GNU is free air not free beer.Her hair is very beauty.I can't finish the test.
Oh! The soup taste good.motorcycle is cheap than car.This window is clear.
the symbol '*' is represented as start.Oh!My god!The gd software is a library for drafting programs.
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.google is the best tools for search keyword.
goooooogle yes!g
o! go! Let's go.
# I am VBird
END
示例: weiyigeek.top-lower1
2
3
4
5
6
7
8
9
10
11#查找小写字母:
grep -n -E '[[:lower:]]' regular_express.txt
#查找数字
grep -n -E '[[:digit:]]' regular_express.txt
#匹配数字和字母
echo "verb123never" | grep -oE '[[:digit:]]'
123
echo "verb123never" | grep -oE '[[:alpha:]]'
verb123never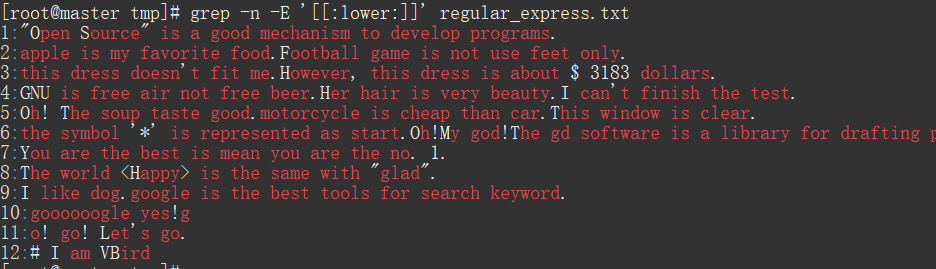
分组:正则表达式中的分组又称为子表达式,就是把一个正则表达式的全部或部分当做一个整体进行处理,分成一个或多个组
其中分组是使用“()”表示的,进行分组之后“()”里面的内容就会被当成一个整体来处理,将正则表达式得一部分用括号括起来组成一个单元,可以对整个单元使用数量限定符;
分组常用:1
* \( \) 将 \( 和 \) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。
分组可以分为捕获组和非捕获组.
基础案例:1
2#echo "192.168.200.255" | grep -E '^([0-9]{1,3}\.){3}[0-9]{1,3}$
192.168.200.255
向后引用
描述:当一个正则表达式被分组后,每个组将会自动的分配一个组号用于代表该组的表达式,
其中,组号的编制规则为:从左到右、以分组的左括号“(”为标志,第一个分组的组号为1,第二个分组的组号为2,以此类推。
基础示例: weiyigeek.top-区别1
2
3
4
5
6
7
8
9
10
11
12#匹配“javajava”
1)仅仅使用分组实现:(Java)(java)
2)使用后向引用的方法:(java)\1
echo "javajava" | grep -oE "(java)" #对比两种情况
java
java
echo "javajava" | grep -oE "(java)\1"
javajava
#对比(\w)\1和(\w)(\w)的区别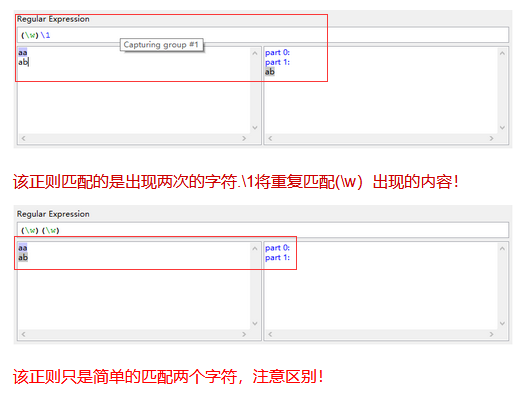
1 | #\num 对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符 |
过滤空白和注释行1
2
3
4
5
6
7
8
9
10#特殊应用实例:查看/etc/ssh/sshd_config 文档
'^$' : 过滤掉空白行
'^#' :过滤掉注释行(以#号开头)
#示例:-n显示上一次的行数,-v表示反向匹配显示
grep -nv '^$' /etc/ssh/sshd_config | grep -nv '^#'
1:1:# $OpenBSD: sshd_config,v 1.100 2016/08/15 12:32:04 naddy Exp $
2:3:# This is the sshd server system-wide configuration file. See
3:4:# sshd_config(5) for more information.
4:6:# This sshd was compiled with PATH=/usr/local/bin:/usr/bin
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/编程世界/RegularExpression/Shell正则表达式.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/8-8-350.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议