[TOC]
0x00 前言介绍 正则表达式(Regular Expression)描述字符串结构模式的形式化表达方法,正则(Regex)表达式处理的对象的字符串或者抽象地说是一个对象序列(计算机体系的本质数据结构)
正则表达式发展历史
为什么使用正则表达式?
正则表达式特点:
灵活性、逻辑性和功能性非常的强;
可以迅速地用极简单的方式达到字符串的复杂控制;
对于刚接触的人来说比较晦涩难懂,如果想学得大成任然需要系统的学习;
构造正则表达式的方法和创建数学表达式的方法一样,也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。
正则表达式学习难点
regex的使用
regex的特性(feature)
regex的工作原理:正则表达式引擎(regular expression engine)
正则表达式应用
正则表达式在生物信息学和人类基因图谱的研究中发挥关键的作用;
正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器。
正则表达式在(文本编辑EditPlus、文字处理软件Microsoft Word、系统开发工具Visual Studio、数据库引擎、搜索工具)
正则表达式是一串文本(a chunk of text)的特征,可以使用来验证用户输入的数据也可以用它来检索大量的文本,也可以进行控制数据(查找匹配文本/删除|替换|提取文本)
正则表达式正在作为编程语言的一部分:Java/JScript/VisualBasic/VBscript/JavaScript/ECMAScript/C/C++/C/elispse/Perl/Python等等开发环境
正则表达式在 *nix(Linux, Unix等)、HP 等操作系统中
weiyigeek.top-正则表达式应用情况
应用场景 :
开发输入校验: 例如可以测试输入字符串以查看字符串内是否出现电话号码模式或信用卡号码模式称为数据验证。
安全拦截: 比如XSS,SQL注入以及playload-POC测试验证字符串的匹配拦截,常常出现在云waf和传统web的网站防火墙WAF中;
例如,您可能需要搜索整个网站,删除过时的材料以及替换某些 HTML 格式标记。
验证正则表达式工具:
egrep #在Linux和windows平台中都有,值得注意的时候当egrep在正则匹配时候,会把换行符替换掉拼接下一行的字符;
Perl #提供的元字符和操纵能力远远多于egrep,且Perl对正则表达式的支持完整且易于使用;所以推荐在使用正则的时候采用此种方法;
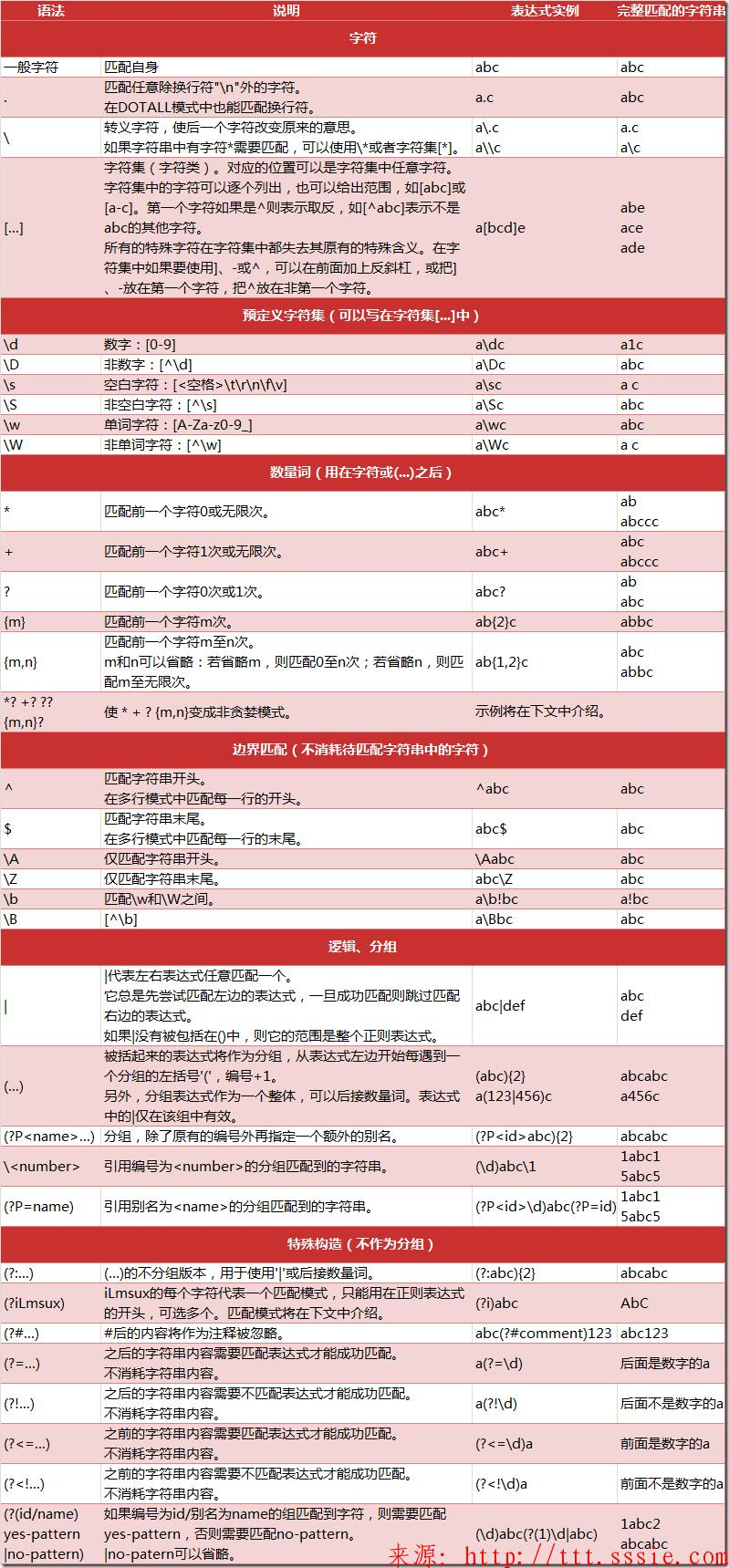
0x01 正则表达式入门 完整的正则表达式由两种字符构成,特殊字符(special characters)也叫元字符(meta characters)其他为文字或者普通文本字符(normal text chracters),当然有的开发语言存在正则表达式的扩展;
正则与文件名模式之间的对比:
附加的特殊字符构成的元字符通配符表达式,但是表达能力还是有限的;
强大的模式语言和模式本身被称为正则表达式(通用的模式语言),
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z ,0-9)以及特殊字符(称为”元字符”)组成的文字模式。
模式描述在搜索文本时要匹配的一个或多个字符串,正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
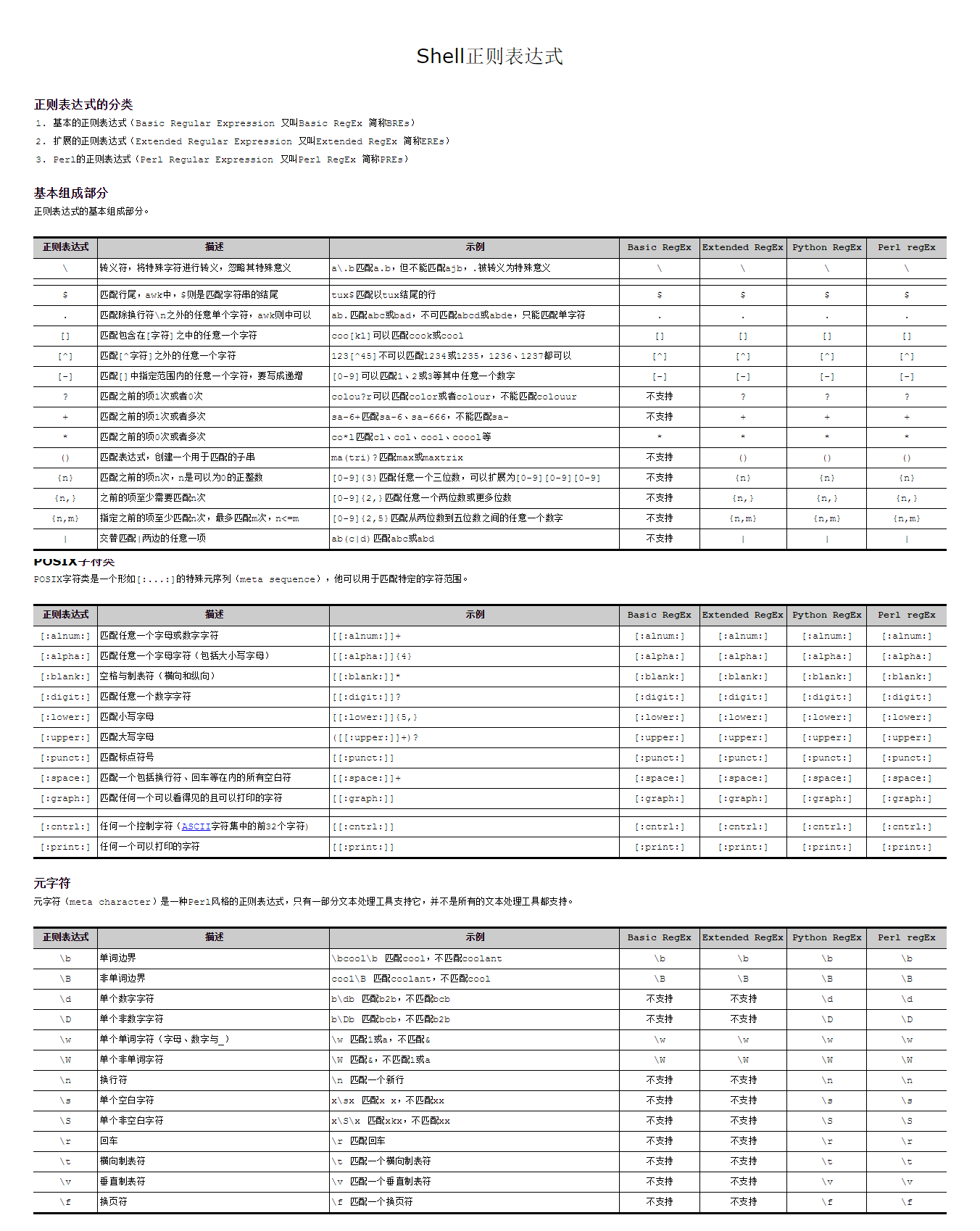
正则表达式的分类
正则表达式的详解
普通字符:
包括没有显式指定为元字符的所有可打印和不可打印字符,包括所有的大小写数字(a-zA-Z0-0)以及所有的标点符号(!@#$%^&*()_+-={}|;:’”<>,./);
非打印字符: ascii 前32位非打印字符;
特殊字符(元字符):
基础元字符(转义)
定位符(匹配开始或者结尾)
字符组(Character Classes)
单词分界符
预定义字符集
数量限定符:用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配;
特殊元字符
分组符号
非捕获型括号
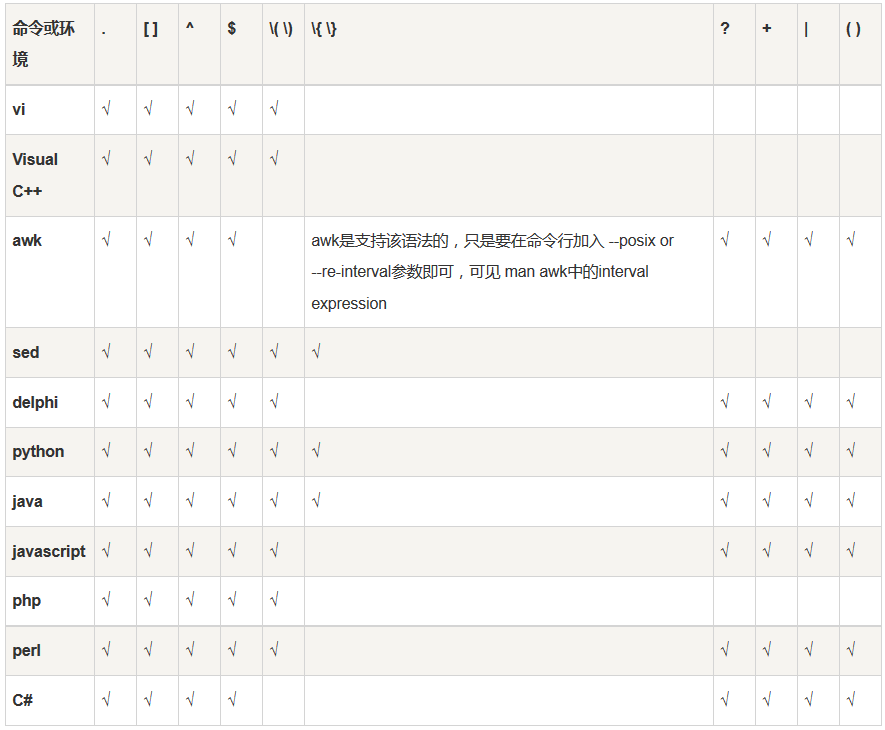
weiyigeek.top-正则表达式分类表
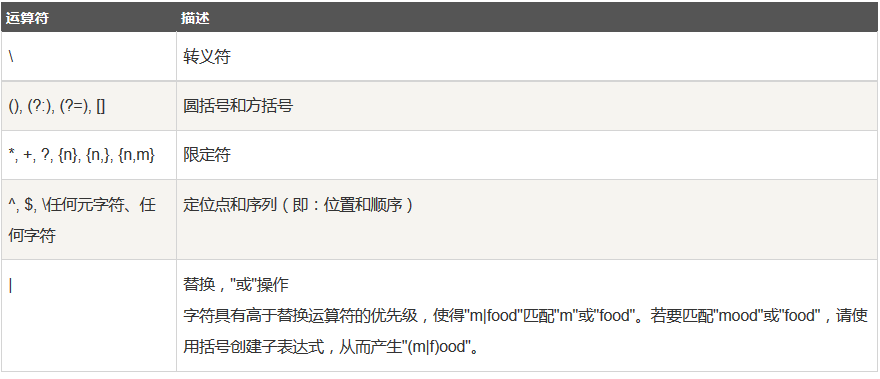
正则表达式运算符优先级 从左到右进行计算,不同优先级先高后低,并且遵循优先级顺序,这和算法表达式非常类似;
weiyigeek.top-regular优先级
基础元字符 描述:常用的一些元字符集基础入门学习regular必备;
[TOC]
0x00 前言介绍 正则表达式(Regular Expression)描述字符串结构模式的形式化表达方法,正则(Regex)表达式处理的对象的字符串或者抽象地说是一个对象序列(计算机体系的本质数据结构)
正则表达式发展历史
为什么使用正则表达式?
正则表达式特点:
灵活性、逻辑性和功能性非常的强;
可以迅速地用极简单的方式达到字符串的复杂控制;
对于刚接触的人来说比较晦涩难懂,如果想学得大成任然需要系统的学习;
构造正则表达式的方法和创建数学表达式的方法一样,也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。
正则表达式学习难点
regex的使用
regex的特性(feature)
regex的工作原理:正则表达式引擎(regular expression engine)
正则表达式应用
正则表达式在生物信息学和人类基因图谱的研究中发挥关键的作用;
正则表达式的第一个实用应用程序就是 Unix 中的 qed 编辑器。
正则表达式在(文本编辑EditPlus、文字处理软件Microsoft Word、系统开发工具Visual Studio、数据库引擎、搜索工具)
正则表达式是一串文本(a chunk of text)的特征,可以使用来验证用户输入的数据也可以用它来检索大量的文本,也可以进行控制数据(查找匹配文本/删除|替换|提取文本)
正则表达式正在作为编程语言的一部分:Java/JScript/VisualBasic/VBscript/JavaScript/ECMAScript/C/C++/C/elispse/Perl/Python等等开发环境
正则表达式在 *nix(Linux, Unix等)、HP 等操作系统中
weiyigeek.top-正则表达式应用情况
应用场景 :
开发输入校验: 例如可以测试输入字符串以查看字符串内是否出现电话号码模式或信用卡号码模式称为数据验证。
安全拦截: 比如XSS,SQL注入以及playload-POC测试验证字符串的匹配拦截,常常出现在云waf和传统web的网站防火墙WAF中;
例如,您可能需要搜索整个网站,删除过时的材料以及替换某些 HTML 格式标记。
验证正则表达式工具:
egrep #在Linux和windows平台中都有,值得注意的时候当egrep在正则匹配时候,会把换行符替换掉拼接下一行的字符;
Perl #提供的元字符和操纵能力远远多于egrep,且Perl对正则表达式的支持完整且易于使用;所以推荐在使用正则的时候采用此种方法;
0x01 正则表达式入门 完整的正则表达式由两种字符构成,特殊字符(special characters)也叫元字符(meta characters)其他为文字或者普通文本字符(normal text chracters),当然有的开发语言存在正则表达式的扩展;
正则与文件名模式之间的对比:
附加的特殊字符构成的元字符通配符表达式,但是表达能力还是有限的;
强大的模式语言和模式本身被称为正则表达式(通用的模式语言),
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如字符 a 到 z ,0-9)以及特殊字符(称为”元字符”)组成的文字模式。
模式描述在搜索文本时要匹配的一个或多个字符串,正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
正则表达式的分类
正则表达式的详解
普通字符:
包括没有显式指定为元字符的所有可打印和不可打印字符,包括所有的大小写数字(a-zA-Z0-0)以及所有的标点符号(!@#$%^&*()_+-={}|;:’”<>,./);
非打印字符: ascii 前32位非打印字符;
特殊字符(元字符):
基础元字符(转义)
定位符(匹配开始或者结尾)
字符组(Character Classes)
单词分界符
预定义字符集
数量限定符:用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配;
特殊元字符
分组符号
非捕获型括号
weiyigeek.top-正则表达式分类表
正则表达式运算符优先级 从左到右进行计算,不同优先级先高后低,并且遵循优先级顺序,这和算法表达式非常类似;
weiyigeek.top-regular优先级
基础元字符 描述:常用的一些元字符集基础入门学习regular必备;
基础实例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 echo "123\nabcdefg" | egrep -o '\\n' \n echo "zreo food" | egrep -o 'z|food' z food echo "zreo food zood" | egrep -o '(z|f)ood' food zood echo "03/19/2019 03-19-2019 03.19.2019" | egrep -o "03[-./]19[-./]2019" 03/19/2019 03-19-2019 03.19.2019 echo -e "03/19/2019\n03-19-2019\n03.19.2019" | egrep -o "(.|\n)" --color
定位符 描述:如果设置了 RegExp 对象的 Multiline 属性,^|$ 也匹配 ‘\n’ 或 ‘\r’ 之前后的位置。1 2 3 4 5 6 ^ 匹配输入字符串的开始位置。 $ 匹配输入字符串的结束位置。 ^$ 代表空白行 ^单词$ 代表匹配一个单词
基础案例:1 2 3 4 5 6 7 8 9 10 11 echo "start 123456789 end" | egrep -o '^start' start echo "start 123456789 end" | egrep -o 'end$' end echo -e "start \n\n123\n\n end" > regular_demo1.txtegrep -n '^$' regular_demo1.txt 2: 4:
字符组 描述:字符组(字符集-character set)为了避免混淆更改叫法,可以看作是一个字符集范围内的字符;1 2 3 4 5 " - " 字符组元字符"-" 表示一个范围(character-class metacharacter)[xyz] 字符集合匹配所包含的任意一个字符。例如'[abc]' 可以匹配 "plain" 中的 'a' 。 [^xyz] 负值字符集合匹配未包含的任意字符。例如'[^abc]' 可以匹配 "plain" 中的'p' 、'l' 、'i' 、'n' 。 [a-z] 字符范围匹配指定范围内的任意字符。例如'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 [^a-z] 负值字符范围,匹配任何不在指定范围内的任意字符(排除型字符组同样是一种肯定断言(positive assertion))。例如'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。
基础案例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 echo "I thinks separete and separate" | egrep -o "separ[ea]te" separete:分离 separate:独立 echo -e "123456789abcABC_\!.?" | egrep "[0-9a-zA-z_\!\.?]" 123456789abcABC_\!.? echo "<h1>h1</h1><h6>H6</h6>" | egrep -o "<h[1-6]>" echo "<h1>h1</h1><h6>H6</h6>" | egrep -o "<h[123456]>" <h1> <h6> echo "123456abcdefABCDEFG" | egrep -o "abc[^ABC]" abcd (1[012]|[1-9]):[0-5][0-9]*(am|pm) ([01]?[0-9]|2[0-3]):[0-5][0-9]
注意事项 :
所有特殊字符在字符集中都失去原有的特殊含义,在字符集中如果要使用] - ^ 等符号需要在前面加上的一个转义字符;
一个字符组即使排除型字符组,也需要匹配一个字符;
单词分界符 描述:就是单词或者字符串的边界匹配(单词开头和结尾),并且不消耗匹配字符串中的字符;
基础示例:1 2 3 4 echo "abc Love Study Compumter" | egrep -io '\<(abc|love)\>' --colorabc Love
注意事项:
预定义字符集 描述:可以单独使用也能在字符集中使用,匹配数字或者非数字,空白符号或者非空白符号,单词词组或者非单词词组;1 2 3 4 5 6 \d 匹配一个数字字符 \D 匹配一个非数字字符 \s 匹配任何空白字符包括空格、制表符、换页符 \S 匹配任何非空白字符 \w 匹配包括下划线的任何单词字符 \W 匹配任何非单词字符
注意事项:
数量限定符 描述:匹配前面正则或者字符0次或者多次,是正则表达式中最常用的元字符了;1 2 3 4 5 6 7 8 9 ? 匹配前面的子表达式 零次或一次。 * 匹配前面的子表达式 零次或多次。 + 匹配前面的子表达式 一次或多次(至少一次)。 {min,max} {n} n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o' ,但是能匹配 "food" 中的两个 o。 {n,} n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o' ,但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+' 。'o{0,}' 则等价于 'o*' 。 {n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?' 。请注意在逗号和两个数之间不能有空格。
贪婪模式和非贪婪模式 1 2 3 4 5 ? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时匹配模式是非贪婪的。 非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。 .* 的警告通常用来表示 "一组任何字符" ,点号可以匹配任何字符,而星号可以为任意数目但是并非必须.
基础示例:1 2 3 4 5 6 7 echo "abdcd" | egrep -o "abc?" ab echo "000333" | egrep -o '[a-zA-Z0-9]{1,6}' 000333
注意事项:
每个量词都规定了匹配成功至少需要次数的下限,以及尝试匹配的次数上线,对某些量词来说下线是0而某些量词的上限是无穷大;
由星号和问号限定的对象在 “匹配成功” 时可能并没有匹配任何字符,即使什么字符都不能匹配到,它任然会报告 “匹配成功”
特殊元字符 描述:特殊元字符描述在Ascii中不可见字符,注意在其他开发或者脚本语言中不一定是通用;元字符具有特殊意义的字符但是在正则表示中并不是统一的(在其他的一些高级语言中),在正则表达式的内部字符组有自己的子语言,其中的元字符是不同的;1 2 3 4 5 6 \cx 匹配由X指明的控制字符; \f 匹配一个换页符。等价于 \x0c 和 \cL。 \n 匹配一个换行符。等价于 \x0a 和 \cJ。 \r 匹配一个回车符。等价于 \x0d 和 \cM。 \t 匹配一个制表符。等价于 \x09 和 \cI。 \v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
实际案例:1 2 3 4 $ perl -E 'if("a\nb\tc" =~ m/\cI|\n/){print "匹配成功"}' 匹配成功 $ perl -E 'if("a\nbc" =~ m/\cI|\n/){print "匹配成功"}' 匹配成功
分组符号 描述:我们已经知道了()的两种用途,现在来介绍第三种:
限制多选项的范围
将若干个字符组合成为一个单元,受?与*之类的量词作用
分组和反向引用
基础符号:
基础示例:1 2 3 4 5 6 7 8 9 10 11 12 13 14 echo "aa11 b2c3 d44" | egrep -o '([a-z])\1([0-9])\2' aa11 echo "the the" | egrep -o '([A-Za-z]+) \1' the the echo "the The" | egrep -io '([a-z]+) \1' the The '\$[0-9]+(\.[0-9][0.9])?'
注意事项:
尽管反向引用非常实用,但是它任然有它的局限性;因为egrep把每行文件都当做一个独立部分来看待(当匹配行尾与行首的字符时候容易出现BUG);
非捕获组 描述:它只用于分组,而不会影响文本的捕获和变量的保存;前面我们使用()来表示分组和捕获,而现在使用(?:)表示只分组不捕获,而且这里?和表示匹配数量限定符无任何联系,简单的说以 (?) 开头的组是非捕获组,它不捕获文本也不针对组合计进行计数。
如果小括号中以?号开头,那么这个分组就不会捕获文本避免了不必要的操作,提高匹配效率是增加了整个表达式的阅读难度
基础示例1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 industr(?:y|ies) $ perl -E 'if("a\nb\tc" =~ m/\cI|\n/){print "匹配成功"}' 匹配成功 $ perl -E 'if("a\nbc" =~ m/\cI|\n/){print "匹配成功"}' 匹配成功 'if("57F" =~ m/^([-+]?[0-9]+(?:\.[0-9]*)?)([CF]$/){ print "$1 $2 }' 57 F
环视功能 描述:正则表达式新特性环视(lookaround),环视结构不匹配任何字符只匹配文本中的特定位置,与单词分节符\b和^以及$相似但是又比他们更加通用;
顺序环视(lookahead):作为表达式的而一部分,顺序环视顺序(从左至右)查看文本,尝试匹配子表达式如果能够匹配则返回匹配成功的信息;
逆序环视(lookbehind):作为表达式的而一部分,顺序环视顺序(从右至左)查看文本,尝试匹配子表达式如果能够匹配则返回匹配成功的信息;
注意:
环视功能不是所有语言都支持,下面演示的以perl和grep为主;
环视是不会占用字符的,即检查子表达式是否匹配,但它只寻找能够匹配的位置而不是真正的占用;环视不消耗字符也就是说在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
顺序环视功能的结合顺序非常重要,由于是对于位置的确立下一步环视字符串之后才会正式匹配下一步中的字符串;逆序环视功能的结合顺序不重要,因为它并没有占用任何字符(并且使用\b锚定位),所以变换顺序并没有影响;无论是先监测左边还是再检测右边;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 (?=pattern) (?!=pattern) (?<=pattern) perl -l -e '$str="Windows2000 95Windows 2000Windows Windows95";if($str =~ s/Windows( ?<=95|98|NT|2000|10)/NOW/g){print "匹配成功 $str"}' (?<!pattern)
weiyigeek.top-
基础示例: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 perl -l -e '$str = "I name is WeiyiGeek, now study Regular expression";if($str =~ m/(?=WeiyiGeek)Weiyi/){print "顺序环视匹配成功: $str"}else{print "匹配失败"};' 顺序环视匹配成功: I name is WeiyiGeek, now study Regular expression echo "My name is WeiyiGeek program" | grep -oP "(?=WeiyiGeek)Weiyi" Weiyi perl -l -e '$str = "I name is Weiyigeek, now study Regular expression";if($str =~ m/(?=WeiyiGeek)Weiyi/){print "顺序环视匹配成功: $str"}else{print "顺序环视匹配失败"};' 顺序环视匹配失败 perl -l -e '$str = "I name is Weiyigeek, now study Regular expression";if($str =~ m/(?=WeiyiGeek)Weiyi/i){print "顺序环视匹配成功: $str"}else{print "匹配失败"};' 顺序环视匹配成功: I name is Weiyigeek, now study Regular expression perl -l -e '$str = "My Name is WeiyiGeeks"; $str =~ s/\bWeiyiGeek(?=s\b)/WeiyiGeek\047/g; print $str' perl -l -e '$str = "My Name is WeiyiGeeks"; $str =~ s/WeiyiGeek(?=s\b)/WeiyiGeek\047/g; print $str' perl -l -e '$str = "My Name is WeiyiGeeks"; $str =~ s/(?<=\bWeiyiGeek)(?=s\b)/\047/g; print $str' perl -l -e '$str = "My Name is WeiyiGeeks"; $str =~ s/(?=s\b)(?<=\bWeiyiGeek)/\047/g; print $str' perl -l -e '$str = "prices 1546782457"; $str =~ s/(?<=\d)(?=(\d\d\d)+$)/,/g; print $str' prices 1 ,546 ,782 ,457 $ perl -E 'if("5569" =~ m/(?<!4)56(?=9)/){print "匹配成功"}else{print "匹配失败"}' 匹配成功 $ perl -E 'if("4569" =~ m/(?<!4)56(?=9)/){print "匹配成功"}else{print "匹配失败"}' 匹配失败 '(?<!\w)(?=\w) | (?<=\w)(?!\w)' '(?!\d)' perl -l -e '$str = "prices 1546782457"; $str =~ s/(\d)(?=(\d\d\d)+(?!\d))/$1,/g; print $str' perl -l -e '$str = "prices 1546782457"; while($str =~ s/(\d)((\d\d\d)+\b)/$1,$2/g){}; print $str' prices 1 ,546 ,782 ,457
进制与unicode 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \xn 匹配n其中n为十六进制转义值,十六进制转义值必须为确定的两个数字长 \num 匹配num其中num是一个正整数 \n 标识一个八进制转义值或一个向后引用 \nm 标识一个八进制转义值或一个向后引用 \nml 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml \un 匹配n其中n是一个用四个十六进制数字表示的Unicode字符。
基础示例:1 2 例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”,正则表达式中可以使用十六进制的ASCII编码
weiyigeek.top-xn
1 2 3 4 5 如果\n之前至少n个获取的子表达式,则n为向后引用否则,如果n为八进制数字(0-7),则n为一个八进制转义值的Ascll \nml 就是三位数的八进制表示Ascll \un 例如\u00A9匹配版权符号(©),用十六进制表示的Unicode
weiyigeek.top-进制
(?P=name) 引用别名为分配到字符串中.\d)abc(?P=Id) #未成功
常用正则表达式 示例1.处理HTML标记 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <\s*(\S+)(\s[^>]*)?> <\s*(\S+)(\s[^>]*)?> [\s\S]* <\s*\/\1\s*> $input =~ s/&/&/g;$input =~ s/</</g;$input =~ s/>/>/g;$text =~ s/^[ \t\r]*$/<p>/mg$text =~ s/^\s*$/<p>/mg$email = Weiyigeek@qq.com$email =~ s/\b(username RegExp\@host RegExp)\b/<a href="mailto:$1 " >$1 <\/a>/g;
示例2.常用正则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 移动电话: /^1[3456789]\d{9}$ //身份证正则表达式(15位) isIDCard1=/^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$/; //身份证正则表达式(18位) isIDCard2=/^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$/; 身份证正则合并:(^\d{15}$)|(^\d{17}([0-9]|X)$) 网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+(' |"| *|>)? 邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* 图片链接:(s|S)(r|R)(c|C) *= *('|" )?(\w|\\|\/|\.)+('|"| *|>)? IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+) 中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14} 中国邮政编码:[1-9]{1}(\d+){5} 中国身份证号码:\d{18}|\d{15} 整数:\d+ 浮点数(即小数):(-?\d*)\.?\d+ 任何数字 :(-?\d*)(\.\d+)? 中文字符串:[\u4e00-\u9fa5]* 双字节字符串 (汉字):[^\x00-\xff]*