[TOC]
Set集合
描述:Set集合概述和特点包含没有重复元素的集合。

[TOC]
描述:Set集合概述和特点包含没有重复元素的集合。1
2public interface Set<E>
extends Collection<E>
Set集合特点:
HashSet存储自定义对象如何保证元素唯一性?
答:我们重了equals()与hashCode()方法,由于当每一个元素的hashCode的值是一样的时候才调用equals方法,为了提高效率我们必须降低优化hashCode()代码写法使之重复机率;(在以后开发中通常是采用了自动生成的方法方如下:)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//com.weiyi.Collection.Students;
//#alt+shift+s -> Generate hashCode() and equals()
@Override
public int hashCode() {
final int prime = 31; //为什么选择31? 1.31是一个质数(1和本身才能整除); 2.31该数不大也不下;3.31该数好表示 2 << 5 - 1
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) //调用的对象和传入的对象是同一个对象-直接返回True
return true;
if (obj == null) //传入的对象是null
return false;
if (getClass() != obj.getClass()) //判断两个对象对应的字节码文件是否是同一个字节码文件
return false;
Students other = (Students) obj; //向下转型
if (age != other.age)
return false;
if (name == null) { //调用对象的姓名不能为null
if (other.name != null) //传入对象的姓名不能为null
return false;
} else if (!name.equals(other.name)) //调用的对象名称不等于传入的对象姓名
return false;
return true;
}
HashSet如何保证元素唯一性的原理:
1.HashSet原理:
实际案例:HashSet存储字符串并遍历以及存储自定义对象保证元素唯一性1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62#Tips:这里采用了Students类 import com.weiyi.Collection.Students;
/**
* @Filename: Set_Demo1.java
* @Author: WeiyiGeek
* @Function: Set集合学习
* @CreateTime: 下午7:38:16
*/
package com.weiyi.set;
import java.util.HashSet;
import com.weiyi.Collection.Students;
public class Set_Demo1 {
public static void main(String[] args) {
//1.Set集合的特点:
//无索引、不可重复、无序(存取可能顺序不一致)
System.out.println("#########示例1#############");
demo();
//2.存储自定义对象保证元素唯一性
System.out.println("\n\n@@@@@@@@@@示例2@@@@@@@@@@");
demo1();
}
public static void demo1() {
HashSet<Students> st = new HashSet<>();
st.add(new Students("张三",35));
st.add(new Students("李连杰",32));
st.add(new Students("王富贵",35));
st.add(new Students("李三丰",32));
st.add(new Students("张三",35));
//查看集合中存放元素的个数(由于开始我们还未作重复过滤的时候size()输出为5)
System.out.println(st.size()); //4
System.out.println(st); //由于重写HashCode()和euquals()方法使其自定义类对象的元素保持不重复
}
public static void demo() {
HashSet<String> hs = new HashSet<String>(); //创建HashSet对象;
boolean b1 = hs.add("a"); //当向set集合中存储重复元素的时候返回false;
boolean b2 = hs.add("a");
hs.add("b");
hs.add("d");
hs.add("c");
System.out.println(hs); //HashSet继承体系中重写了toString方法,且输出元素不重复和无序
System.out.println(b1 + " - " + b2);
for (String string : hs) { //只要能用迭代器迭代的就可以使用增强for循环遍历
System.out.print(string + " ");
}
}
}
#执行结果:
#########示例1#############
[a, b, c, d]
true - false
a b c d
@@@@@@@@@@示例2@@@@@@@@@@
4
[Students [name=李连杰, age=32], Students [name=李三丰, age=32], Students [name=张三, age=35], Students [name=王富贵, age=35]]
补充复习实现快捷键:1
2
3
4
5
6// alt+shift+s+c //有参无参构造
// alt+shift+s+o //生成get方法
// alt+shift+s+r //生成set方法
// alt+shift+s+s //重写toString
// alt+shift+s+ Generate HashCode() and euqauls() //提高效率少调用euquals方法使HashCode不一致
// alt+shift+m //方法抽取
描述: LinkedHashSet的概述和使用,Linked代表底层使用链表来实现的保证了怎么存就怎么取,而HashSet保证元素唯一性,且该类多数方法来着于父类或者说是爷爷类;
特点:保证怎么存就怎么取并且不重复;
基础案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74package com.weiyi.set;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Scanner;
public class set_LinkedHashCode {
public static void main(String[] args) {
//示例1.LinkedHashSet类型初步使用
LinkedHashSet<String> lhs = new LinkedHashSet<>();
lhs.add("a");
lhs.add("b");
lhs.add("c");
lhs.add("d");
System.out.println("示例1:LinkedHashSet的使用 " + lhs + "\n");
//示例2.使用Scanner从键盘读取去掉不同的字符打印出不同的那些字符
/**
* 1.创建Scanner对象
* 2.创建HashSet对象将字符存储去掉重复
* 3.将字符串转换为字符数据,获取每一个字符存储在HashSet集合之中自动去除重复
* 4.遍历HashSet打印每一个字符
*/
Scanner sc = new Scanner(System.in);
System.out.print("请输入一行字符串: ");
HashSet<Character> c = new HashSet<Character>();
String line = sc.nextLine();
char[] arr = line.toCharArray();
for (char d : arr) {
c.add(d);
}
//遍历打印每一个字符
for (Character ch : c) {
System.out.print(ch); //打印出是无序的
}
//示例3.List集合与LinkedHashSet集合联合使用案例
/**
* (*)去除List集合中的重复元素:
* - 创建一个LinkedHashSet集合
* - 将List集合中所有元素添加到LinkedHashSet集合
* - 将List集合中的元素清除
* - 将LinkedHashSet集合中元素加回到List集合之中
**/
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("c");
list.add("b");
list.add("a"); //重复元素
getSingle(list);
System.out.println(list);
}
//这里改成List可以兼容linked
public static void getSingle(ArrayList<String> list) {
LinkedHashSet<String> lhs = new LinkedHashSet<String>();
lhs.addAll(list); //包括其所有的子类对象(去重了)
list.clear();
list.addAll(lhs); //非常值得学习去重后重新放入list集合中
}
}
//#####执行结果#########
示例1:LinkedHashSet的使用 [a, b, c, d]
请输入一行字符串: whoamiweiygeek
aewghiykmo
[a, c, b]
描述:TreeSet集合是用来对象元素进行排序的可以指定一个顺序,当对象存入之后会按照指定的顺序排序,同样他也可以保证元素的唯一;
参考JDK8文档:1
2
3
4TreeSet() //#构造一个新的、空的树集,根据其元素的自然排序进行排序。
TreeSet(Collection<? extends E> c) //#构造一个新的树集包含在指定集合的元素,根据其元素的自然排序排序。
TreeSet(Comparator<? super E> comparator) //#构造一个新的、空的树集,根据指定的比较器进行排序。
TreeSet(SortedSet<E> s) //#构造一个包含相同元素的新树集,并使用相同的排序作为指定的排序集。
TreeSet使用方式一览:
调用的对象是compare方法的第一个参数,集合中的对象(根节点)是compare方法的第二个参数(1)TreeSet存储自定义对象:
描述:使用TreeSet集合框架来排序去重自定义对象来保证元素的唯一和自然排序的;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//这里任然采用Students类的方法 com.weiyi.Collection.Students;
//原理:二叉树两个叉小的存储在左边(负数) 在HashSet集合中如何存储元素取决于compareTo方法的返回值;
public class Students implements Comparable<Students> {
@Override
public int compareTo(Students o) {
// TODO Auto-generated method stub
/**
当compareTo方法返回0的时候集合中只有一个元素(不存储其他元素)
当compareTo方法返回正数的时候集合会怎么存就怎么取(右边) - 方便理解以最后参数作为参考
当compareTO方法返回负数的时候集合会倒序存储(左边)
简单一句话常规输出方式: 负数 -> 0 -> 正数 - 方便理解
return 0;
*/
//1.二叉树取元素的时候是从左边开向右边(主要光匹配年龄当年龄重复的时候会出现问题所以这里我们要考虑完整次要条件姓名)
int num = this.age - o.age; //Stuents代表根对象
return num == 0 ? this.name.compareTo(o.name) : num; //判断年龄是否相同如果相同再看其姓名是是不是相同(再String中已经重写了compareTo)否则返回num
//2.如果按照姓名排序则交换this.age - o.age 和 this.name.compareTo(o.name)
//#相同返回0,o.name < this.name返回1(右边), o.name > this.name 返回-1(左边)
//3.按照姓名长度进行排序
int length = this.name.length() - o .name.length();
int num = length == 0 ? this.name.compareTo(o.name) : length;
return num == 0 ? this.age - o.age : num; //如果连姓名都相同的话就比较其年龄
}
}

weiyigeek.top-原理解析图
(2)TreeSet集合比较器原理 weiyigeek.top-
描述:再声明创建TreeSe集合对象向的时候需要调用自己实现的Comparator接口类中的compare方法;
原理理解: 集合中已有的根对象的为s2,add比较的元素为s1
基础实例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64package com.weiyi.set;
import java.util.Comparator;
import java.util.TreeSet;
import com.weiyi.Collection.Students;
public class TreeSet_demo {
public static void main(String[] args) {
//示例1.TreeSet集合基本使用
TreeSet<Integer> ts = new TreeSet<>(); //创建TreeSet对象去重和排序
ts.add(3);ts.add(1);ts.add(1);ts.add(2);ts.add(2);
System.out.println("示例1:\n" + ts); //输出元素
//实例2.TreeSet集合保证元素唯一和自然排序(采用了二叉树的原理)
TreeSet<Students> st = new TreeSet<>();
st.add(new Students("掌门人",25));
st.add(new Students("凡哥",23));
st.add(new Students("渣渣辉",25));
st.add(new Students("刘师傅",24));
System.out.println("示例2:\n" + st);
//示例3.compareTo中的姓名的对比采用的是unicode码
System.out.println("示例3:\n");
System.out.println('掌' + 0);
System.out.println('凡' + 0);
System.out.println('渣' + 0);
System.out.println('刘' + 0);
//示例4.TreeSet集合比较器原理
System.out.println("示例4:\n");
TreeSet<String> compare = new TreeSet<>(new CompareByLength());
compare.add("aaaaa");
compare.add("z");
compare.add("xa");
compare.add("weiyigeek");
compare.add("cba");
System.out.println("示例4:\n" + compare);
}
}
class CompareByLength extends Object implements Comparator<String>{
//注意这里:Comparator接口虽然是两个方法但是这里只写了一个也不会报错;由于所有的类都默认基础Object类而该类中已经重写了equals方法
@Override
public int compare(String s1, String s2) {
// TODO Auto-generated method stub
int num = s1.length() - s2.length(); //判断长度
return num == 0 ? s1.compareTo(s2) : num; //长度一致则判断条件
}
}
//#指向结果
示例1:
[1, 2, 3]
示例2:
[Students [name=凡哥, age=23], Students [name=刘师傅, age=24], Students [name=掌门人, age=25], Students [name=渣渣辉, age=25]]
示例3:
25484
20961
28195
21016
示例4:
[z, xa, cba, aaaaa, weiyigeek]
学习案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
package com.weiyi.set;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Scanner;
import java.util.TreeSet;
/**
* @author WeiyiGeek
*/
public class set_CollectionExample {
public static void main(String[] args) {
//需求1:输入一个集合存储重复且无序的元素,排序但是不去重;
ArrayList<String> demo = new ArrayList<>();
demo.add("weiy_");
demo.add("小伟");
demo.add("weiyi");
demo.add("WeiyiGeek");
demo.add("weiyi");
//定义的方法对其排序保留
sort(demo);
//打印List
System.out.println("需求1:\n" + demo );
//需求2:从键盘输入一个字符串程序对其排序后输出(任然不去重复)
System.out.println("需求2:");
Scanner sc = new Scanner(System.in);
System.out.print("请输入串字符串: ");
String line = sc.nextLine();
char[] arr = line.toCharArray(); //字符串转换成为字符数组
TreeSet<Character> ch = new TreeSet<Character>(new Comparator<Character>() {
@Override
public int compare(Character c1, Character c2) {
// TODO Auto-generated method stub
int flag = c1.compareTo(c2); //这里就不用自动拆箱了(值得学习)
return flag == 0 ? -1 : flag;
}
});
//将字符数组值传入到TreeSet集合之中(需要自动装箱)
for (Character c : arr) {
ch.add(c);
}
//遍历输出字符
for (Character de : ch) {
System.out.print(de + " ");
}
//示例3.键盘输入多个整数直到quit时候退出。把所有输出的整数倒序排列打印;
System.out.println("\n示例3:");
TreeSet<Integer> in = new TreeSet<Integer>(new Comparator<Integer>() {
//匿名内部类
@Override
public int compare(Integer i1, Integer i2) {
//由于是需要倒序排序则这里集合中元素i2减去调用的参数i1
int num = i2 - i1;
return num == 0 ? 1 : num; //不需要剔除重复则返回非0即可
}
});
while(!(line = sc.nextLine()).equals("quit")) {
//将字符串转成Integer对象(捕捉异常)
try{
Integer i = Integer.parseInt(line);
in.add(i);
} catch (Exception e){
System.out.println("输入的值非数字!");
}
}
System.out.println("集合倒序结果:"+in);
System.out.println("Game Over!");
}
public static void sort(ArrayList<String> demo) {
// 1)创建TreeSet集合对象,还需要自定义比较器(由于String虽然自带比较器但是重复不能够保留),这里采用匿名内部类实现”
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int num = o1.compareTo(o2);
return num == 0 ? 1 : num; //精辟之处
}
});
// 2)将列表元素给TreeSet集合
ts.addAll(demo);
// 3)清空list列表中元素
demo.clear();
// 4)将排好序的元素重新放入list中
demo.addAll(ts);
}
}
指向结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14#需求1:
[WeiyiGeek, weiy_, weiyi, weiyi, 小伟]
#需求2:
请输入串字符串: whoami
a h i m o w
#示例3:
1024
852
836
256
354
quit
集合倒序结果:[1024, 852, 836, 354, 256]
Game Over!
案例需求:键盘录入5个学生信息(姓名,语数外成绩以,分割),之后按照总分从高到低输出到控制台Control weiyigeek.top-
步骤流程分析:(多写有助于学习)
1 | package com.weiyi.set; |
执行结果:1
2
3
4
5
6
7
8
9
10
11请用键盘录入5个学生信息(姓名,语数外成绩以,分割) :
小红,30,40,50
小黑,50,60,100
小绿,59,59,59
小兰,85,87,10
小紫,100,100,99
name=小紫, chinese=100, math=100, english=99, 总分=299
name=小黑, chinese=50, math=60, english=100, 总分=210
name=小兰, chinese=85, math=87, english=10, 总分=182
name=小绿, chinese=59, math=59, english=59, 总分=177
name=小红, chinese=30, math=40, english=50, 总分=120
描述:Map集合是一个双列集合内含Key/Value概述:
语法:1
2
3
4
5java.util
Interface Map<K,V>
#实际用的时候
Map<String, Integer> stu = new HashMap<String, Integer>();
描述:比下面的集合框架都节省实际时间效率高,直接向里面丢入数据到时候直接取就行,所以再没有特殊要求下一般采用HashMap来存储键值对;
Map集合的常用功能:
V put(K key,V value):添加元素。void clear():移除所有的键值对元素V remove(Object key):根据键删除键值对元素,并把值返回boolean containsKey(Object key):判断集合是否包含指定的键boolean containsValue(Object value):判断集合是否包含指定的值boolean isEmpty():判断集合是否为空Set<Map.Entry<K,V>> entrySet():V get(Object key):根据键获取值Set<K> keySet():获取集合中 所有键key 的集合Collection<V> values():获取集合中 所有值value 的集合int size():返回集合中的键值对的个数Map集合的遍历之键找值思路:
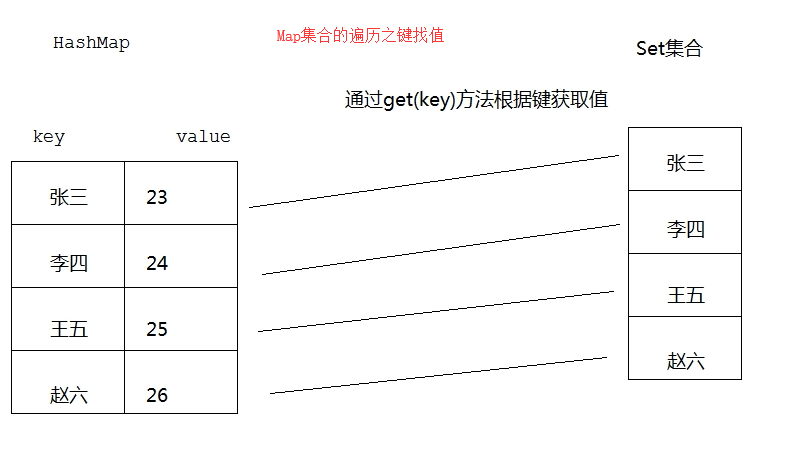
weiyigeek.top-
Map集合的遍历之键值对对象找键和值思路
1 | #关键方法有了Entry接口我们就可以进行getKey于和getValue以及迭起 |
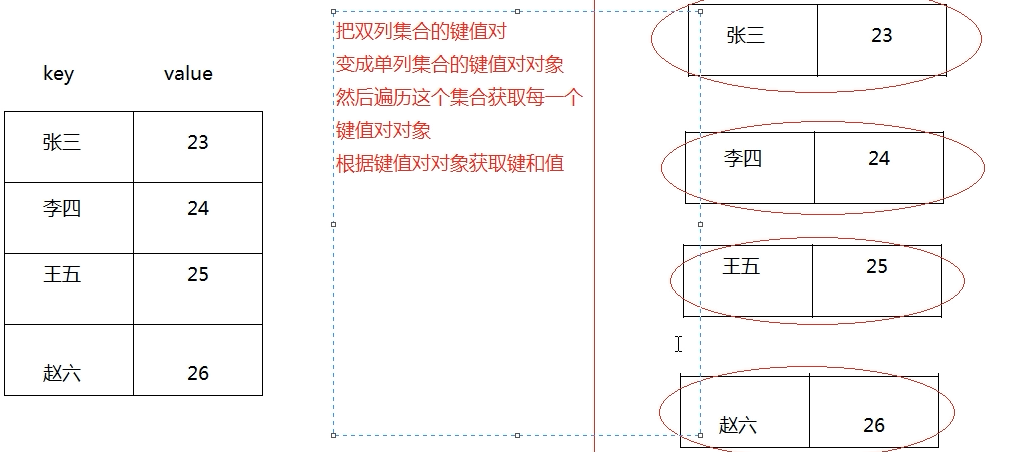
weiyigeek.top-
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73package com.weiyi.Map;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Demo1_MapCollection {
public static void main(String[] args) {
//示例1.Map集合的添加功能(注意Hash默认是不对数据进行排序的)
Map<String, Integer> stu = new HashMap<String, Integer>();
stu.put("小王",25); //注意由于Key不能重复put第一次返回null,第二次则是返回被覆盖的值
stu.put("小伟",88);
stu.put("小赵",18);
stu.put("小李",14);
System.out.println("示例1: " + stu);
//示例2.判断值是否包含键是否包含
boolean keyFlag = stu.containsKey("小伟");
boolean ValueFlag = stu.containsValue(88);
System.out.println("示例2: " + "小伟 Key是否存在" + keyFlag +",88 Value是否存在" + ValueFlag + ", 是否为空 :" + stu.isEmpty());
//示例3.获取Map集合长度和集合中的键值
System.out.println("示例3:\nMap集合长度: " + stu.size());
System.out.println("获取指定Key的Value: " + stu.get("小伟"));
System.out.println("获取Map集合所有Key: " + stu.keySet());
System.out.println("获取Map集合所有Value: " + stu.values());
//示例5.Map双列集合迭代方法(两种方法);Map集合的遍历之键找值
//Iterator迭代器
System.out.println("\n示例5:");
Set<String> keySet = stu.keySet(); //返回是一个Set集合类型的值,而Set集合中存在迭代器则进行使用
Iterator<String> ot = keySet.iterator(); // 获取迭代器
while(ot.hasNext())
{
String key = ot.next(); //获取每一个键
Integer value = stu.get(key); //根据键获取值
System.out.println("Key=" + key + ", Value=" + value);
}
//增强for循环遍历方式(实际使用中推荐)
for (String Key : stu.keySet()) {
System.out.println(Key+":"+stu.get(Key));
}
//示例6.遍历之`键值对对象找键和值`思路
System.out.println("\n示例6:");
//Map.Entry说明Entry是Map的内部接口,将键和值封装成为Entry对象并存在再Set集合中
Set<Map.Entry<String, Integer>> entryset = stu.entrySet();
Iterator<Map.Entry<String, Integer>> it = entryset.iterator(); //获取迭代器对象
while(it.hasNext())
{
//获取每一个Entry对象
Map.Entry<String, Integer> st = it.next();
//之后就可以根据这个接口里面的方法获取值/keys
String stkey = st.getKey();
Integer stvalue = st.getValue();
System.out.println( stkey + " - " + stvalue);
}
//还是可以采用增强for循环(实际开发中推荐方式)
for (Map.Entry<String, Integer> entry : stu.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue() + " " + entry.getClass());
}
//示例4.删除Map集合中的Key值
System.out.println("\n示例4:\n移除删除键值对元素: " + stu.remove("小伟"));
stu.clear();
System.out.println("删除全部Key/Value: " + stu);
}
}
执行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33示例1: {小李=14, 小王=25, 小伟=88, 小赵=18}
示例2: 小伟 Key是否存在true,88 Value是否存在true, 是否为空 :false
示例3:
Map集合长度: 4
获取指定Key的Value: 88
获取Map集合所有Key: [小李, 小王, 小伟, 小赵]
获取Map集合所有Value: [14, 25, 88, 18]
示例5:
Key=小李, Value=14
Key=小王, Value=25
Key=小伟, Value=88
Key=小赵, Value=18
小李:14
小王:25
小伟:88
小赵:18
示例6:
小李 - 14
小王 - 25
小伟 - 88
小赵 - 18
小李 14 class java.util.HashMap$Node #调用的字节码文件名词.class
小王 25 class java.util.HashMap$Node
小伟 88 class java.util.HashMap$Node
小赵 18 class java.util.HashMap$Node
示例4:
移除删除键值对元素: 88
删除全部Key/Value: {}
HashMap集合键是存入Student对象是String的案例: 同样这里的Students对象也是采用 com.weiyi.Collection.Students中的 Students 类;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package com.weiyi.Map;
import java.util.HashMap;
import java.util.Map;
import com.weiyi.Collection.Students;
public class Demo1_MapClass {
public static void main(String[] args) {
//示例说明:将键存入我们的students对象,value是存入每一个学生的生源地
Map<Students, String> ss = new HashMap<Students, String>();
ss.put(new Students("王爱国",25),"北京"); //关键点1由于Students类中重写了 equals() 和 hashcode()方法 会进行去冲后除插入集合
ss.put(new Students("王爱国",25),"上海"); //Value的上海将会覆盖北京
ss.put(new Students("颜国富",18),"广州");
ss.put(new Students("渝艳华",26),"重庆");
ss.put(new Students("志疆",26),"深圳");
System.out.println(ss); //HashMap重写了toString() 方法
}
}
//#执行结果
{Students [name=王爱国, age=25]=上海, Students [name=渝艳华, age=26]=重庆, Students [name=颜国富, age=18]=广州}
HashMap嵌套HashMap(重点)
1 | package com.weiyi.Map; |
执行结果:1
2
3
4
5
6
7
8
9
10示例1:
字符串中单个不相同字符的数量 : {a=6, b=1, s=4, c=1, d=4, g=1}
示例2:
姓名/年龄:Students [name=王五, age=93],归属地深圳, 班级:1999级
姓名/年龄:Students [name=李四, age=53],归属地广州, 班级:1999级
姓名/年龄:Students [name=张三, age=13],归属地北京, 班级:1999级
姓名/年龄:Students [name=阿斯顿, age=13],归属地重庆, 班级:2000级
姓名/年龄:Students [name=张伟, age=98],归属地北京, 班级:2000级
姓名/年龄:Students [name=坤璄烤, age=23],归属地浙江, 班级:2000级
总结归类:
Eclipse: ctrl+o)查看方法,Map集合中默认没有iterator(迭代器)方法;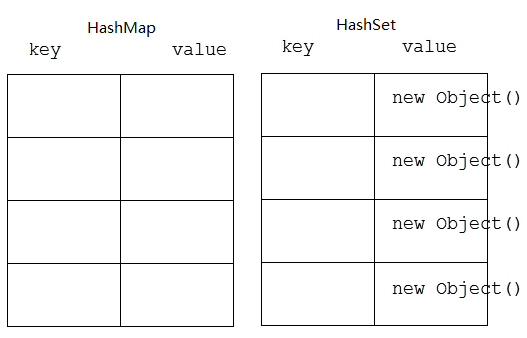
weiyigeek.top-集合类比
描述:LinkedHashMap的特点底层是链表实现的,可以保证怎么存就怎么取,同时和Map特性一致重复key将覆盖其值;1
2
3
4
5
6
7
8
9
10
11
12
13
14package com.weiyi.Map;
import java.util.LinkedHashMap;
public class Demo2_LinekedHashMap {
public static void main(String[] args) {
//LinkedHashMap自动去除重复的键值
LinkedHashMap<String, Integer> lhm = new LinkedHashMap<String, Integer>();
lhm.put("张三",15);
lhm.put("张四",25);lhm.put("王五",35);lhm.put("赵六",25);
lhm.put("张三",55);
System.out.println(lhm);
}
}
//#执行结果
{张三=55, 张四=25, 王五=35, 赵六=25}
描述:TreeMap需要对输入集合的元素进行排序,所以效率自然没有HashMap高;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45package com.weiyi.Map;
import java.util.Comparator;
import java.util.HashMap;
import java.util.TreeMap;
import com.weiyi.Collection.Students;
public class Demo3_TreeMap {
public static void main(String[] args) {
//示例1.TreeMap集合采用com.weiyi.Collection.Students包中Students类当作对象作为Key(按照年龄进行排序),String为生源地
TreeMap<Students, String> tm = new TreeMap<>(); //TreeMap对象采用了compareTo进行比较去除重复(如不重写则会导致ClassCastException异常)
tm.put(new Students("颜国富",26), "北京");
tm.put(new Students("喻艳华",27), "上海");
tm.put(new Students("张三丰",100), "深圳");
tm.put(new Students("颜国富",26), "广州"); //覆盖第一条
System.out.println(tm);
//示例2.匿名类Comparator重写compare方法实现按照姓名排序(升序)
TreeMap<Students, String> ss = new TreeMap<Students, String>(new Comparator<Students>() {
@Override
public int compare(Students o1, Students o2) {
int num = o1.getName().compareTo(o2.getName());
return num == 0 ? o1.getAge() - o2.getAge():num ;
}
});
ss.put(new Students("颜国富",26), "北京");
ss.put(new Students("喻艳华",27), "上海");
ss.put(new Students("三丰",100), "深圳");
ss.put(new Students("颜国富",26), "广州"); //同样是覆盖第一条
System.out.println(ss);
System.out.println('喻' + 0); //可以查看unicode码得出顺序
System.out.println('张' + 0);
System.out.println('颜' + 0);
}
}
//#执行结果
{Students [name=颜国富, age=26]=广州, Students [name=喻艳华, age=27]=上海, Students [name=张三丰, age=100]=深圳}
{Students [name=三丰, age=100]=深圳, Students [name=喻艳华, age=27]=上海, Students [name=颜国富, age=26]=广州}
21947
24352
39068
HashMap和Hashtable的区别?
不可以存储null键和null值,HashMap可以存储null键和null值;(与Victor命运差不多)基础示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24package com.weiyi.Map;
import java.util.HashMap;
import java.util.Hashtable;
public class Demo5_Hashtable {
public static void main(String[] args) {
//HashMap与Hashtable的区别
HashMap<String, Integer> hM = new HashMap<String, Integer>();
hM.put(null, 23);
hM.put("张三", null);
System.out.println("HashMap在键值为null的情况下正确执行" + hM);
Hashtable<String, Integer> ht = new Hashtable<String, Integer>();
ht.put(null,25);
ht.put("我是谁",null);
System.out.println("Hashtable在键值为null的情况下不能正确执行(所以本句不输出)" + ht);
}
}
//######执行结果#######
HashMap在键值为null的情况下正确执行{null=23, 张三=null}
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:465)
at com.weiyi.Map.Demo5_Hashtable.main(Demo5_Hashtable.java:16)
总结:为了能在输入null键值之后HashMap还能够正常执行程序;
描述:Collections类概述针对集合操作的工具类,常用的方法如下:1
2
3
4
5
6//#Collections成员方法(字面意思您懂的))
public static <T> void sort(List<T> list)
public static <T> int binarySearch(List<?> list,T key) //搜索到返回搜索键的索引,否则返回(-(插入点) - 1)
public static <T> T max(Collection<?> coll)
public static void reverse(List<?> list)
public static void shuffle(List<?> list)
示例1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34package com.weiyi.Collections;
import java.util.ArrayList;
import java.util.Collections;
public class Demo1_CollectionsUse {
public static void main(String[] args) {
//1.Collections工具类的基础使用
ArrayList<String> list = new ArrayList<String>();
list.add("c");
list.add("d");
list.add("a");
list.add("b");
list.add("A");
System.out.println("ArrayList 怎么存就会怎么取 : " + list);
Collections.sort(list);
System.out.println("经过Collections工具类排序后的结构: " + list); //String 默认安装acsii表排序
int index = Collections.binarySearch(list, "a");
System.out.println("查找到的结果的索引:" + index);
System.out.println("查找到的结果的索引:" + Collections.binarySearch(list, "B")); // -(插入点1)-1=-2
//取最大最小
System.out.println("根据默认排序结果获取集合中最大值:"+Collections.max(list));
System.out.println("根据默认排序结果获取集合中最小值:"+Collections.min(list));
//反转
Collections.reverse(list);
System.out.println("反转输出结果(从大到小): " + list);
//随机排序
Collections.shuffle(list);
System.out.println("每次都随机的输出:" + list);
}
}
执行结果:1
2
3
4
5
6
7
8ArrayList 怎么存就会怎么取 : [c, d, a, b, A]
经过Collections工具类排序后的结构: [A, a, b, c, d]
查找到的结果的索引:1
查找到的结果的索引:-2
根据默认排序结果获取集合中最大值:d
根据默认排序结果获取集合中最小值:A
反转输出结果(从大到小): [d, c, b, a, A]
每次都随机的输出:[d, b, a, c, A]
扑克牌示例(重点掌握思路):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108package com.weiyi.Collections;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.TreeSet;
public class Demo2_Collections {
public static void main(String[] args) {
//需求:模拟地主洗牌和发牌,【牌没有排序】
//1.创建扑克牌
String[] pk = {"A","2","3","4","5","6","7","8","9","10","J","Q","K"};
String[] color = {"红桃","黑桃","方片","梅花"};
//拼接花色采用列表存放即可
ArrayList<String> poker = new ArrayList<>();
for (String p : pk) {
for (String c : color) {
poker.add(c.concat(p));
}
}
poker.add("大王");
poker.add("小王");
System.out.println("牌数:"+ poker.size() + "\n" + poker + "\n");
//2.洗牌
Collections.shuffle(poker);
//3.发牌和底牌
ArrayList<String> A = new ArrayList<String>();
ArrayList<String> C = new ArrayList<String>();
ArrayList<String> B = new ArrayList<String>();
ArrayList<String> dipai = new ArrayList<String>();
for(int i = 0; i < poker.size(); i++)
{
if( i >= poker.size() - 3){
dipai.add(poker.get(i)); //存放三张底牌
}else if(i % 3 == 0) { //精辟的地方来了,利用取余来发牌
A.add(poker.get(i));
}else if(i % 3 == 1) {
B.add(poker.get(i));
}else if(i % 3 == 2) {
C.add(poker.get(i));
}
}
//4.看牌(无排序)
System.out.println("A:" + A);
System.out.println("B:" + B);
System.out.println("C:" + C);
System.out.println("dipai:" + dipai);
//#################牌实现排序#################
//1.创建扑克牌
String[] p1 = {"3","4","5","6","7","8","9","10","J","Q","K","A","2"};
String[] c1 = {"红桃","黑桃","方片","梅花"};
//采用键值对来存储我们的牌(后面就方便我们排序了)
HashMap<Integer, String> hm = new HashMap<Integer, String>();
ArrayList<Integer> index = new ArrayList<Integer>(); //存储索引
int i = 0;
for(String sp1 : p1)
{
for (String sc1 : c1) {
index.add(i);
hm.put(i++,sc1.concat(sp1));
}
}
index.add(i);
hm.put(i++,"小王");
index.add(i);
hm.put(i,"大王");
//洗牌
Collections.shuffle(index);
//发牌
TreeSet<Integer> a = new TreeSet<Integer>();
TreeSet<Integer> b = new TreeSet<Integer>();
TreeSet<Integer> c = new TreeSet<Integer>();
TreeSet<Integer> dp = new TreeSet<Integer>();
for(i = 0; i < hm.size(); i++)
{
if( i >= hm.size() - 3){
dp.add(index.get(i)); //存放三张底牌
}else if(i % 3 == 0) { //精辟的地方来了,利用取余来发牌
a.add(index.get(i));
}else if(i % 3 == 1) {
b.add(index.get(i));
}else if(i % 3 == 2) {
c.add(index.get(i));
}
}
//看牌(重复采用函数的形式值得学习)
lookup(hm, dp, "底牌");
lookup(hm, a, "A");
lookup(hm, b, "B");
lookup(hm, c, "C");
}
public static void lookup(HashMap<Integer, String> hm, TreeSet<Integer> dp,String name) {
ArrayList<String> flag = new ArrayList<String>();
for (Integer idp : dp) {
flag.add(hm.get(idp));
}
System.out.println("角色"+name+"的牌是:\n"+flag);
}
}
运行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//#未排序
牌数:54
[红桃A, 黑桃A, 方片A, 梅花A, 红桃2, 黑桃2, 方片2, 梅花2, 红桃3, 黑桃3, 方片3, 梅花3, 红桃4, 黑桃4, 方片4, 梅花4, 红桃5, 黑桃5, 方片5, 梅花5, 红桃6, 黑桃6, 方片6, 梅花6, 红桃7, 黑桃7, 方片7, 梅花7, 红桃8, 黑桃8, 方片8, 梅花8, 红桃9, 黑桃9, 方片9, 梅花9, 红桃10, 黑桃10, 方片10, 梅花10, 红桃J, 黑桃J, 方片J, 梅花J, 红桃Q, 黑桃Q, 方片Q, 梅花Q, 红桃K, 黑桃K, 方片K, 梅花K, 大王, 小王]
A:[方片10, 红桃5, 黑桃J, 小王, 梅花5, 红桃10, 梅花2, 方片4, 黑桃3, 方片3, 方片Q, 红桃2, 黑桃K, 黑桃9, 红桃8, 梅花10, 红桃A]
B:[黑桃Q, 方片6, 方片7, 方片A, 方片J, 梅花9, 梅花3, 黑桃8, 梅花K, 红桃7, 红桃4, 方片2, 梅花6, 黑桃A, 梅花A, 梅花8, 黑桃5]
C:[黑桃4, 方片5, 红桃9, 红桃J, 梅花7, 黑桃6, 红桃K, 方片K, 梅花Q, 梅花4, 红桃Q, 黑桃7, 方片9, 大王, 红桃3, 黑桃10, 方片8]
dipai:[黑桃2, 红桃6, 梅花J]
//#排序
角色底牌的牌是:
[梅花9, 黑桃10, 红桃J]
角色A的牌是:
[黑桃3, 方片3, 梅花3, 方片4, 红桃6, 黑桃6, 梅花6, 红桃7, 方片7, 梅花7, 红桃10, 方片Q, 黑桃K, 梅花K, 红桃A, 梅花A, 大王]
角色B的牌是:
[黑桃5, 方片5, 黑桃7, 红桃8, 黑桃8, 梅花8, 方片10, 梅花10, 方片J, 梅花J, 红桃Q, 梅花Q, 方片K, 黑桃A, 黑桃2, 方片2, 小王]
角色C的牌是:
[红桃3, 红桃4, 黑桃4, 梅花4, 红桃5, 梅花5, 方片6, 方片8, 红桃9, 黑桃9, 方片9, 黑桃J, 黑桃Q, 红桃K, 方片A, 红桃2, 梅花2]
描述:1
2
3
4
5
6
7
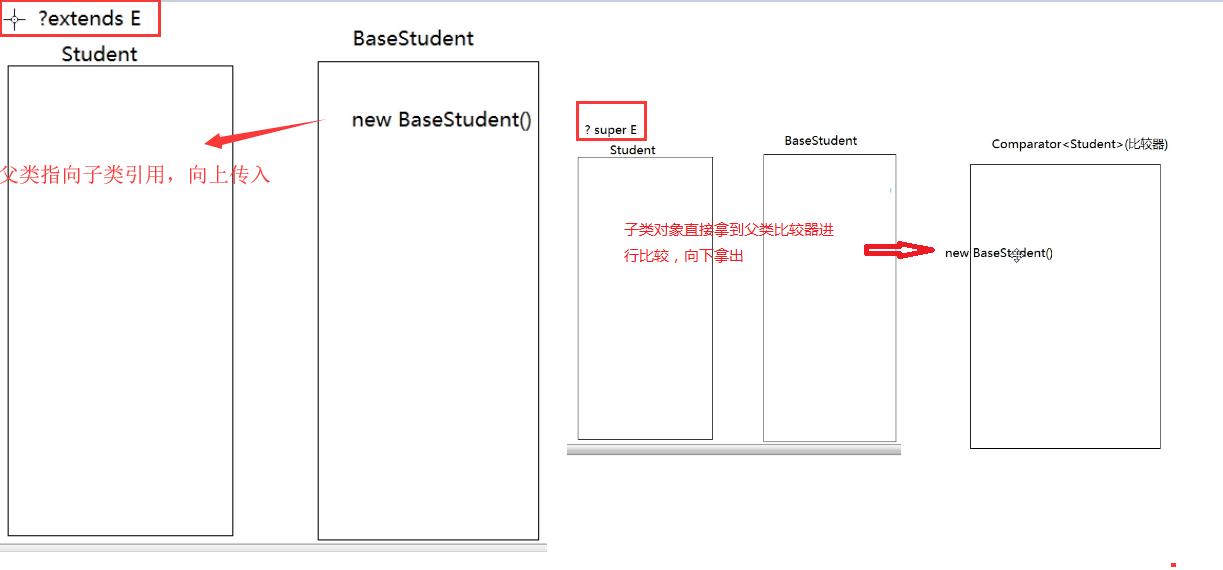
8#泛型固定上边界
? extends E #把子类对象添加到父类对象集合里面去,(父类引用指向子类对象) -> 放进去就是继承extend
比如:Collection.addAll(Collection<? extends E> c)
#泛型固定下边界
? super E #子类也可以使用父类的比较器进行比较排序(也是同样的父类指向子类对象) -> 拿出来放入比较器就是super
比如:TreeSet(Comparator<? super E> comparator)
比如:TreeMap(Comparator<? super K> comparator)
下面的案例我们基于Students生成一个子类ChildStudents: weiyigeek.top-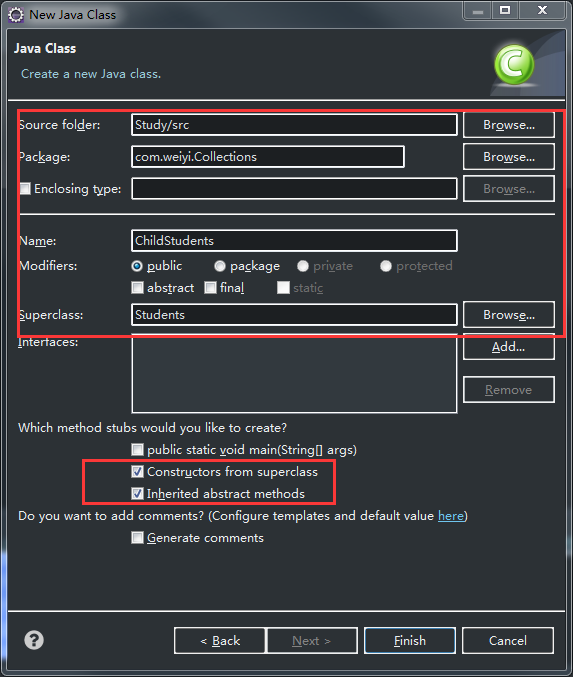
1
2
3
4
5
6package com.weiyi.Collections;
import com.weiyi.Collection.Students;
public class ChildStudents extends Students {
public ChildStudents() {super();}
public ChildStudents(String name, int age) {super(name, age);}
}
泛型示例1:泛型固定上边界1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16package com.weiyi.Collections;
import java.util.ArrayList;
import com.weiyi.Collection.Students;
public class Demo3_Extends {
public static void main(String[] args) {
ArrayList<Students> al = new ArrayList<>();
al.add(new Students("父类测试", 23));
al.add(new Students("父类安全开发", 30));
ArrayList<ChildStudents> a2 = new ArrayList<>();
a2.add(new ChildStudents("子类测试", 23));
a2.add(new ChildStudents("子类安全开发", 30));
al.addAll(a2); //关键点:把子类对象添加到父类对象集合里面去
}
}
泛型示例2:泛型固定下边界1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33package com.weiyi.Collections;
import java.util.Comparator;
import java.util.TreeSet;
import com.weiyi.Collection.Students;
public class Demo4_super {
public static void main(String[] args) {
TreeSet<Students> ts1 = new TreeSet<>(new CompareByAge());
ts1.add(new Students("父类", 1024));
ts1.add(new Students("父类1", 1021));
TreeSet<ChildStudents> ts2 = new TreeSet<>(new CompareByAge());
ts2.add(new ChildStudents("子类", 1023));
ts2.add(new ChildStudents("子类", 1021));
//关键点注意ts1与ts2的输出
System.out.println(ts1);
System.out.println(ts2); //子类对象同样的可以进行按照age排序(说白了子类也可以采用父类的比较器)
}
}
//重写比较器来验证泛型固定下边界(Students对象作比较)
class CompareByAge implements Comparator<Students>
{
@Override
public int compare(Students o1, Students o2) {
int num = o1.getAge() - o2.getAge();
return num == 0 ? o1.getName().compareTo(o2.getName()) : num;
}
}
//#执行结果
[Students [name=父类1, age=1021], Students [name=父类, age=1024]]
[Students [name=子类, age=1021], Students [name=子类, age=1023]]
weiyigeek.top-
描述:
Collection:
Map
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/编程世界/Java/JAVA入门学习七.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/9-20-286.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议