注意:本文分享给安全从业人员、网站开发人员以及运维人员在日常工作防范恶意攻击,请勿恶意使用下面介绍技术进行非法攻击操作。。
[TOC]
0x01 目录扫描
描述:主要针对于网站中一些常规目录和文件存放进行扫描
(1) Dirfuzz
描述:多线程网站目录穷举扫描

注意:本文分享给安全从业人员、网站开发人员以及运维人员在日常工作防范恶意攻击,请勿恶意使用下面介绍技术进行非法攻击操作。。
[TOC]
描述:主要针对于网站中一些常规目录和文件存放进行扫描
描述:多线程网站目录穷举扫描
注意:本文分享给安全从业人员、网站开发人员以及运维人员在日常工作防范恶意攻击,请勿恶意使用下面介绍技术进行非法攻击操作。。
[TOC]
描述:主要针对于网站中一些常规目录和文件存放进行扫描
描述:多线程网站目录穷举扫描 weiyigeek.top-1
2
3
4
5
6python dirfuzz.py http://zhan.***.com/ php
python dirfuzz.py www.wooyun.org asp
python dirfuzz.py www.wooyun.org jsp
#扫描出的结果
[200]:http://zha*.***.com/index.php?g=System&m=Admin&a=index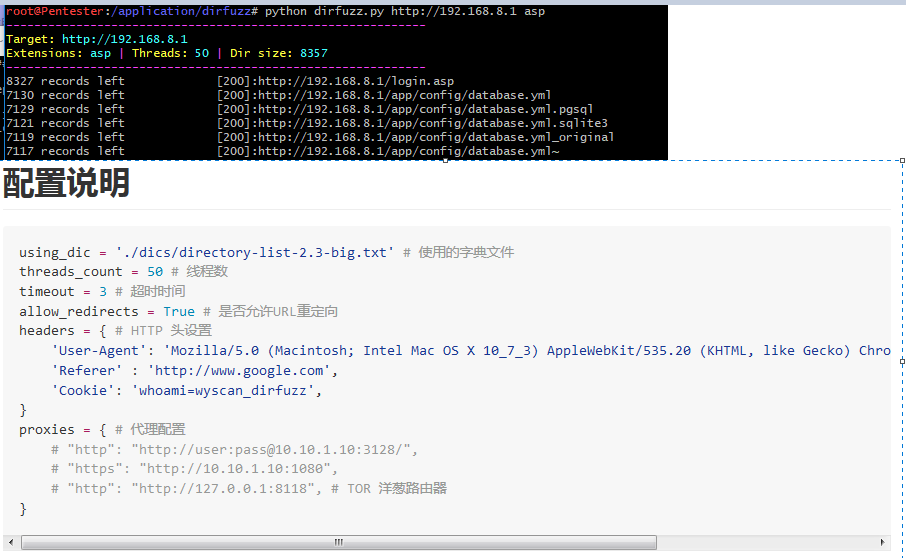
描述:DIRB 是一个专门用于爆破目录的工具,在 Kali 中默认已经安装,类似工具还有国外的patator,dirsearch,DirBuster, 国内的御剑等等。1
dirb http://IP:PORT /usr/share/dirb/wordlists/common.txt #url 文本地址
描述:DirBuster是一个多线程java应用程序,旨在强制在Web /应用程序服务器上强制目录和文件名。 weiyigeek.top-
作者:OWASP.org 许可:Apache 2.0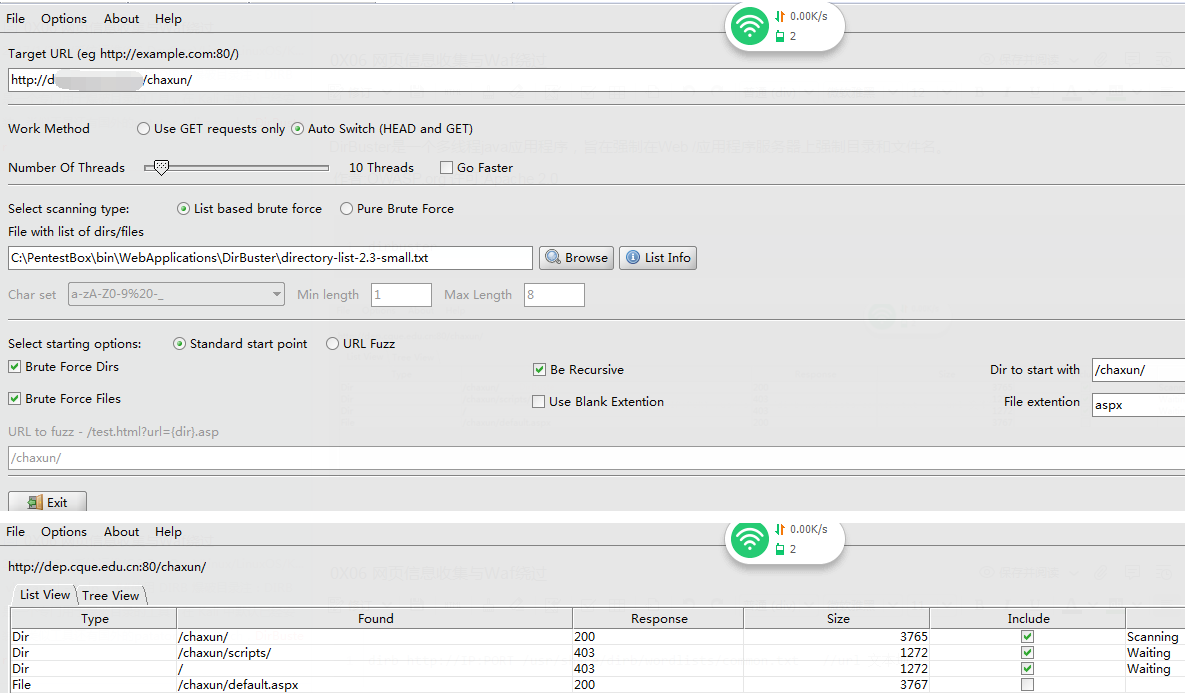
描述:使用 nikto 扫描 Web 服务器扫描器,对于数据库注入、INFO DIscosrue、远程文件、命令执行等等
Kail中配置文件路径配置文件:路径:/etc/nikto.conf
nikto注意功能特点:
帮助文档:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32$nikto -v #数据库Plugin版本
$nikto -list-plugins #查看插件;
$nikto -update #升级,更新插件;
$nikto -h url -T <Scan tuning Number> -t 每个测试类型的时间 -O 和 -F 指定文件名和输出格式
# -Tuning+ Scan tuning:
# 1 Interesting File / Seen in logs
# 2 Misconfiguration / Default File
# 3 Information Disclosure
# 4 Injection (XSS/Script/HTML)
# 5 Remote File Retrieval - Inside Web Root
# 6 Denial of Service
# 7 Remote File Retrieval - Server Wide
# 8 Command Execution / Remote Shell
# 9 SQL Injection
# 0 File Upload
# a Authentication Bypass
# b Software Identification
# c Remote Source Inclusion
# d WebService
# e Administrative Console
# x Reverse Tuning Options (i.e., include all except specified)
-vhost #当一个网站存在多个端口时可以使用-vhost遍历所有网站进行扫描或一个ip对应多个网站
-evasion 逃避方式共8种:
# 1、随机url编码,
# 2、自选路径,
# 3、过早结束的URL,
# 4、优先考虑长随机字符串,
# 5、参数欺骗,
# 6、使用TAB作为命令的分隔符,
# 7、使用变化的URL,
# 8、使用Windows路径分隔符
基础使用方法 weiyigeek.top-1
2
3
4
5
6
7
8
9
10
11#常规用法
nikto -C all -h http://www.baidu.com
nikto -h www.cqwu.net -T 3486 -t 3 -O web -f html
nikto -host http://1.1.1.1 -output #扫描并输出结果
nikto -host 1.1.1.1 -port 80 #扫描目标:ip地址加端口号
nikto -host www.baidu.com -port 443 -ssl #扫描https网站
nikto -host 文件名.txt #批量扫描目标
nikto -host 192.168.0.1 -useproxy http://localhost:8070 #利用代理进行扫描
Nikto -host http://1.1.1.1 -evasion 1234
nmap -p80 192.168.1.0/24 -oG - | nikto -host - #利用nmap扫描开放80端口的IP段并且oG(nmap结果输出并整理)通过管道的方式“|”用nikto进行扫描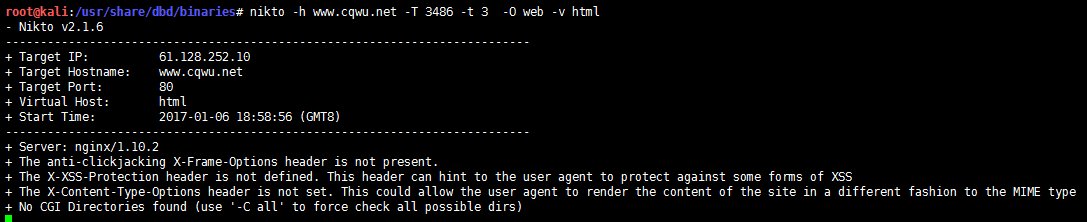
测试结果发现Particularly this:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17+ OSVDB-3092: /test/: This might be interesting...
#首先,我们需要确定有多少字节从一般请求的页面回来:
$curl 'http://rob-sec-1.com/test/?' 1>/dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 53 100 53 0 0 53 0 0:00:01 --:--:-- 0:00:01 289
#这是53从这里我们可以配置wfuzz尝试不同的参数名称,然后寻找有超过53个字符以外的尺寸任何响应。
$ wfuzz -w /usr/share/wordlists/dirb/common.txt --hh 53 'http://rob-sec-1.com/test/?FUZZ=<script>alert("xss")</script>'
==================================================================
ID Response Lines Word Chars Payload
==================================================================
02127: C=200 9 L 8 W 84 Ch "item"
#最终利用
http://rob-sec-1.com/test/?item=<script>alert("xss")</script>
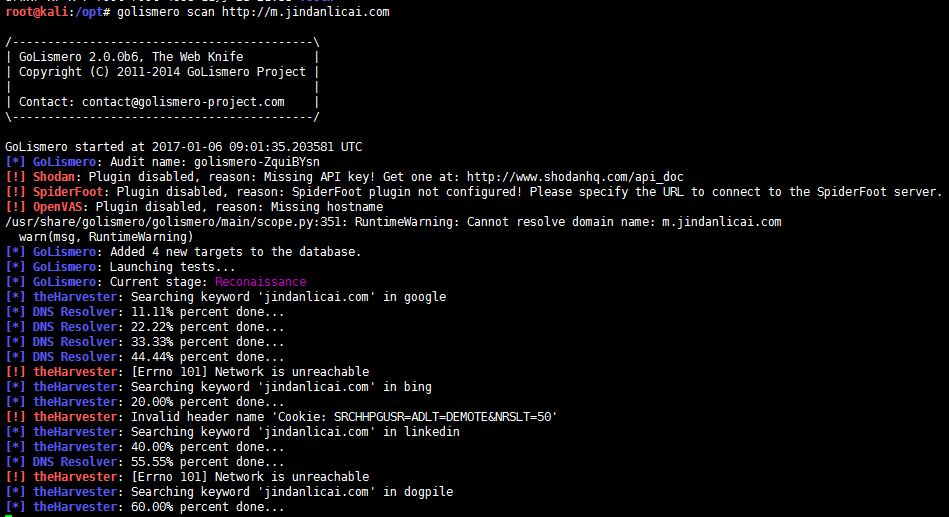
描述: web漏洞扫描(多纬度)安全性测试的是一个开源框架,这是目前针对网络安全,但它可以很容易地扩展到其他类型的扫描。1
2
3
4
5
6
7
8
9
10
11
12#下载Golismero
git clone https://github.com/golismero/golismero.git
#所有的插件列表 http://golismero-project.com/doc/plugin_list/index.html
#显示可用的插件
python golismero.py plugins
#查询指定插件的相关信息.
python golismero.py info <plugin>
#显示所有可用配置文件的列表:
python golismero profiles
# 显示所有信息和插件:
golismero info brute_*
基础示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#可指定输出文件格式, 如果不指定, 扫描结束后就得用命令手工生成结果了.
python golismero.py scan <target> -o <output file name>
python golismero.py scan <target> --audit-name <name>
#扫描一个网站,并显示在屏幕上的结果:
olismero scan http://www.0535code.com
#可以使用 -i 选项, 导入别的工具扫描的结果.
python golismero.py import -i nikto_output.csv -i nmap_output.xml -db database.db
#获取nmap结果,扫描发现所有主机写HTML报告:
golismero scan -i nmap_output.xml -o report.html
#获取结果OpenVAS和它们显示在屏幕上,但不扫描任何东西:
golismero import -i openvas_output.xml
#使用 -nd 可以禁止程序将测试结果存储到数据库中.
python golismero.py <target> -nd
#从以前的扫描中转储数据库:
golismero dump -db example.db -o dump.sql
weiyigeek.top-
生成报告:下面的例子导入Nmap的扫描的结果, 并调用所有的dns插件进行测试, 同时将结果保存到数据库中, 并生成两种格式的报告. weiyigeek.top-1
2
3
4
5
6
7
8
9
10
11python golismero.py scan <target> -o - -o report.html
python golismero.py -i nmap_output.xml -e dns* -db database.db -o report.rst -o report.html
#可以先扫描而不生成报告:
python golismero.py scan <target> -db database.db -no
#扫描完成后再手工生成:
python golismero.py report -db database.db -o report.html
#可以生成多种报告格式:
python golismero.py report -db database.db -o report.html -o report.rst -o report.txt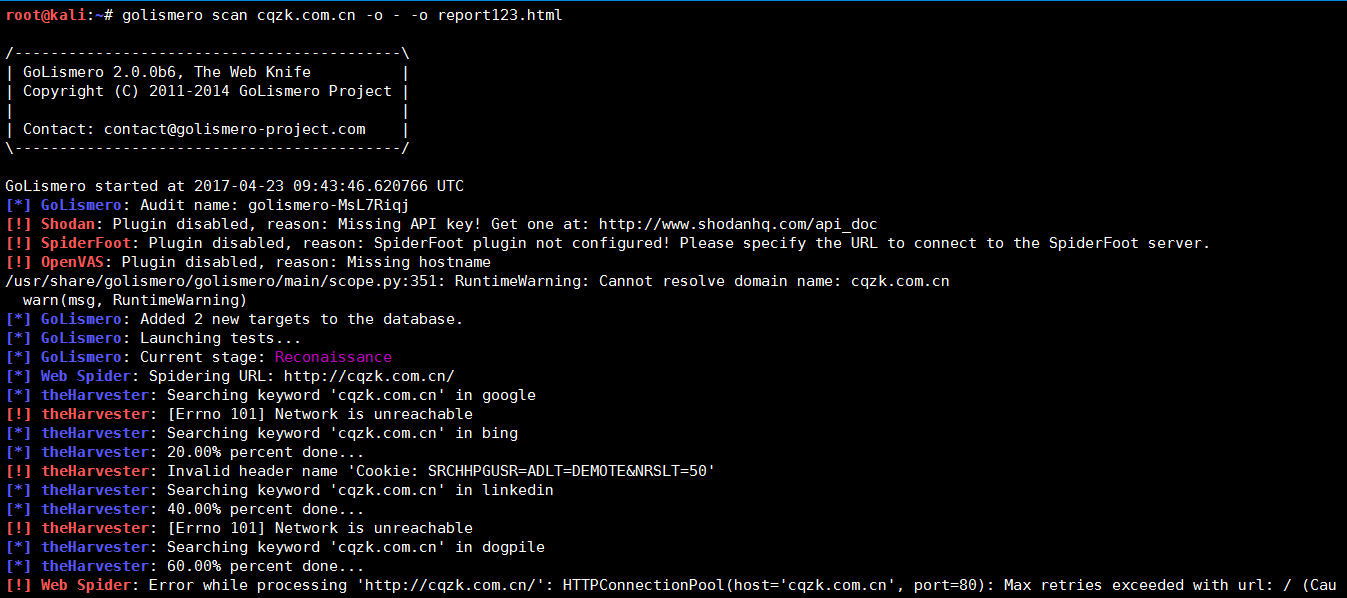
描述: 一个易于使用交互式的用于web应用程序漏洞挖掘的渗透测试工具。 weiyigeek.top-
OWASP Zed攻击代理(攻击)是一个易于使用的综合渗透测试工具在web应用程序中寻找漏洞,是设计用于与广泛的安全经验的人,因此是理想的开发和功能测试人员是渗透测试作为一个有用的补充有经验的笔测试人员工具箱。1
zaproxy #采用java
描述:Paros Proxy(安全分析评估,以及方式分析网络地址)-支持SSL weiyigeek.top-1
2root@kali:~$ paros
file:/usr/share/paros/paros.jar
描述:Skipfish 是一款 Web 应用安全侦查工具,Skipfish 会利用递归爬虫和基于字典的探针生成一幅交互式网站地图,最终生成的地图会在通过安全检查后输出。1
skipfish -m 5 -LY -S /usr/share/skipfish/dictionaries/complete.wl -o ./skipfish2 -u http://IP
描述:拦截代理Fuzezer,session ID ,analysic,spider,web services anlyzer,xss,CRLF,Identity等漏洞扫描器
描述:WPScan是一个黑盒WordPress漏洞扫描器,可以用来扫描远程WordPress安装发现安全问题。 weiyigeek.top-1
2
3
4git clone https://github.com/wpscanteam/wpscan.git && cd wpscan
./wpscan –url http://IP/ –enumerate p
# wpscan --url http://www.blogcn.com/ -e p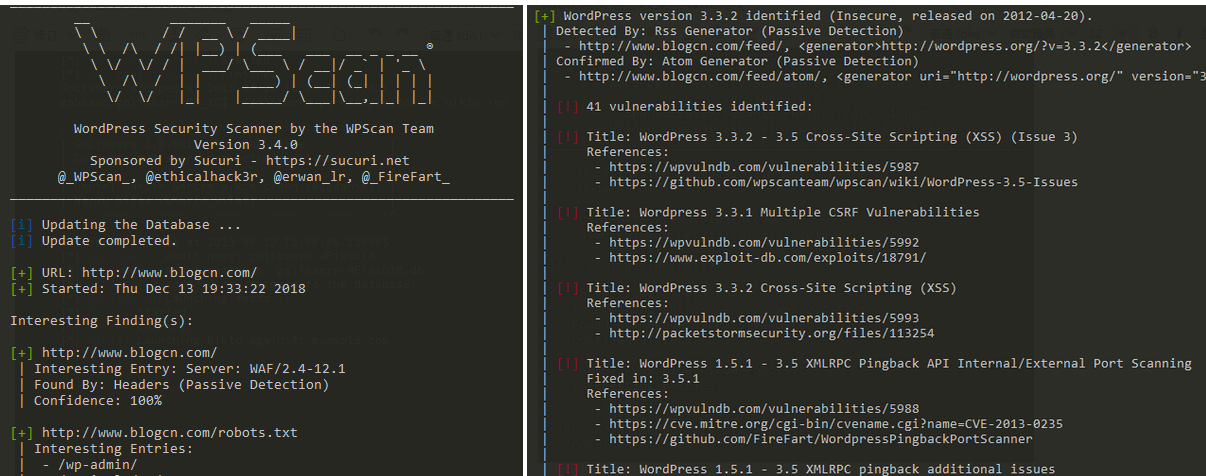
描述:Python开源CMS扫描,自动检测安全漏洞的过程中最受欢迎的CMS,CMSmap的主要目的是为不同类型的cms集成常见漏洞在一个单一的工具。 weiyigeek.top-1
2
3
4
5
6
7Examples:
cmsmap.py -t <URL>
cmsmap.py -t https://example.com
cmsmap.py -t https://example.com -f W -F --noedb
cmsmap.py -t https://example.com -i targets.txt -o output.txt
cmsmap.py -t https://example.com -u admin -p passwords.txt
cmsmap.py -k hashes.txt -w passwords.txt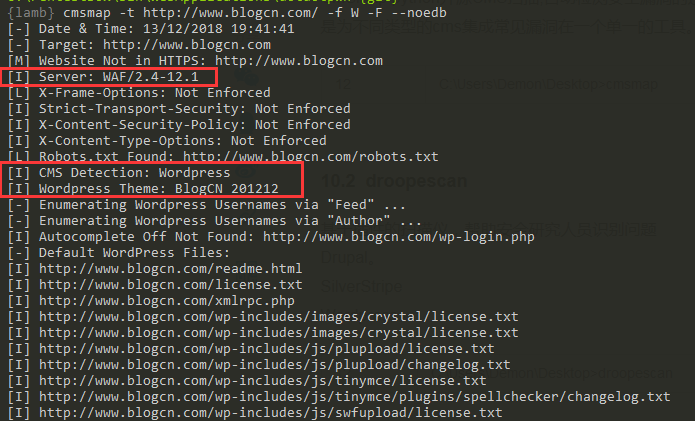
描述:OWASP Joomla Joomla漏洞扫描器 weiyigeek.top-
它可能是最广泛使用的CMS,由于其灵活性,用户友好性,可扩展性命名一些。因此,观察其漏洞,并添加像KB这样的漏洞到Joomla扫描器需要持续的活动。
它将帮助Web开发人员和Web 大师帮助识别他们部署的Joomla可能的安全弱点! 网站。 没有Web安全扫描程序仅专用于一个CMS。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 Example: joomscan.pl -u victim.com -x localhost:8080
joomscan -u http://target.com/joomla
Check: joomscan.pl check - Check if the scanner update is available or not.
Update: joomscan.pl update - Check and update the local database if newer version is available.
Download: joomscan.pl download - Download the scanner latest version as a single zip file - joomscan-latest.zip.
#枚举已安装的组件:
perl joomscan.pl --url www.example.com --enumerate-components
perl joomscan.pl -u www.example.com –ec
#设置cookie:
perl joomscan.pl --url www.example.com --cookie "test=demo;"
#设置user-agent:
perl joomscan.pl --url www.example.com --user-agent "Googlebot/2.1(+http://www.googlebot.com/bot.html)"
perl joomscan.pl -u www.example.com -a "Googlebot/2.1(+http://www.googlebot.com/bot.html)"
#设置随机user-agent
perl joomscan.pl -u www.example.com --random-agent
perl joomscan.pl --url www.example.com -r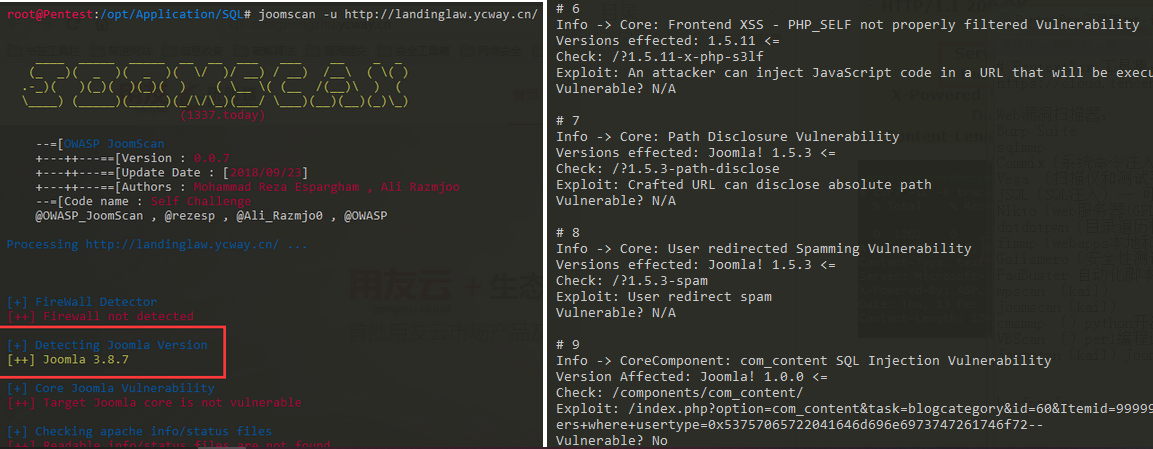
描述:识别基于插件的扫描仪,帮助安全研究人员识别问题Drupal SilverStripe Wordpress; weiyigeek.top-1
2
3
4
5
6
7Use:
droopescan scan drupal -u URL_HERE
droopescan scan silverstripe -u URL_HERE
droopescan scan --help
#实际案例
droopescan scan wordpress -u http://www.blogcn.com/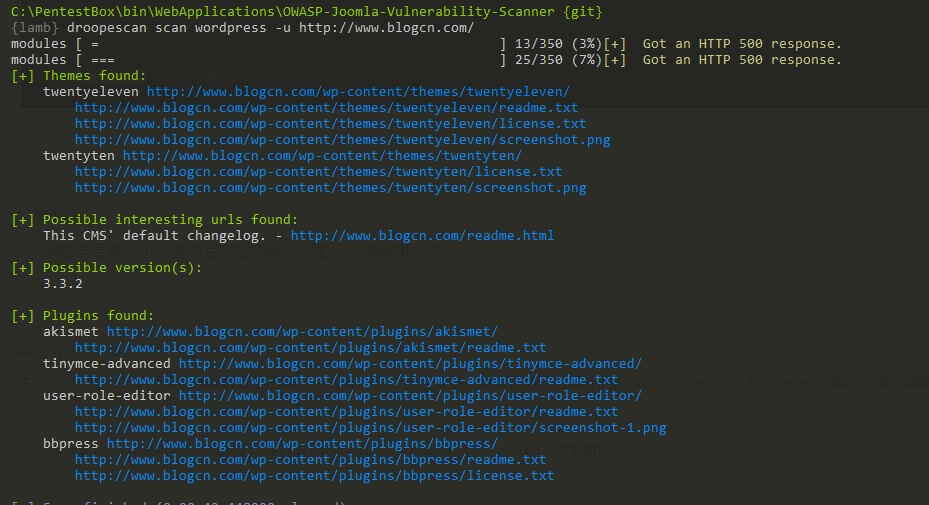
perl编程语言是一个开源项目的检测链入页面CMS漏洞和分析。
项目发起人 : Mohammad Reza Espargham
Github : https://github.com/rezasp/vbscan/1
2
3perl vbscan.pl <target>
perl vbscan.pl http://target.com/vbulletin
perl vbscan.pl --help
描述:Web应用指纹对比浏览程序,扫描固定位置的静态文件,进行对hash值,比对识别技术鉴定速度快,带宽消耗低,无危害,通用性高且高度自动化.1
2BlindElephant.py -l #可用插件
BlindElephant.py http://www.test.com.cn drupal

weiyigeek.top-
描述:wfuzz 是一款Python开发的Web安全模糊测试工具。简而言之就是wfuzz可以用在做请求参数参数类的模糊测试,也可以用来做Web目录扫描等操作。
github项目: https://github.com/xmendez/wfuzz , 安装Wfuzz pip install wfuzz
字典文本: /usr/share/wfuzz/wordlist
1 | Usage: wfuzz [options] -z payload,params <url> |
核心知识:
FUZZ,FUZ2Z,FUZ3Z,….,FUZnZ, 其中n代表了占位序号。Wfuzz模块说明
wfuzz是模块化的框架,wfuzz默认自带很多模块,模块分为5种类型分别是:payloads、encoders、iterators、printers和scripts。1
2
3
4
5
6
7
8
9
10wfuzz [options] -z payload,params <url>
#比如查看payload类中的模块列表
wfuzz -e payloads
# Available payloads:
# Name | Summary
# guitab | This payload reads requests from a tab in the GUI
# dirwalk | Returns filename's recursively from a local directory.
#模块中的说明过滤显示
wfuzz -z help --slice "names"
1.payload为wfuzz生成的用于测试的特定字符串,一般情况下,会替代被测试URL中的FUZZ占位符。
1 | Available payloads: |
2.的作用是将payload进行编码或加密。
1 | Available encoders: |
3.wfuzz的iterator提供了针对多个payload的处理方式。
1 | Available iterators: |
4.wfuzz的printers用于控制输出打印。
1 | Available printers: |
5.wfuzz中的scripts用监测一些常见的存在漏洞的路径
1 | Available scripts: |
过滤器
描述:wfuzz具有过滤器功能,在做测试的过程中会因为环境的问题需要进行过滤,例如在做目录扫描的时候,你事先探测并知道了这个网站访问不存在目录的时候使用的是自定义404页面(也就是状态码为200),而你可以选择提取该自定义页面的特征来过滤这些返回结果。
wfuzz过滤分为两种方法:隐藏符合过滤条件的结果 和 显示符合过滤条件的结果
标准线 or 及格线)。内置工具
实际案例:
示例1实际的使用一遍1
2
3
4
5
6
7
8
9
10#地址其中FUZZ单词,这个单词可以理解是一个占位符,
wfuzz -w 字典 https://weiyigeek.cn/FUZZ
wfuzz -w test_dict.txt https:/weiyigeek..cn/FUZZ
#返回结果如下:
==================================================================
ID Response Lines Word Chars Payload
编号、响应状态码、响应报文行数、响应报文字数、响应报文正字符数、测试使用的Payload。
==================================================================
000004: C=404 1 L 121 W 1636 Ch "test123"
示例2第二种方式1
2
3
4
5
6
7
8#第一条命令中的wordlist表示为字典位置
wfuzz -z file --zP fn=wordlist URL/FUZZ
#第二条命令简写了第一条命令的赋值
wfuzz -z file,wordlist URL/FUZZ
#第三条命令使用-w,这个参数就是-z file --zP fn的别名。
wfuzz -w wordlist URL/FUZZ
示例3例如想要同时爆破目录、文件名、后缀1
wfuzz -w 目录字典路径 -w 文件名字典路径 -w 后缀名字典路径 URL/FUZZ/FUZ2Z.FUZ3Z
示例4.隐藏设置响应码的结果 weiyigeek.top-1
2
3
4
5
6
7
8
9
10
11
12
13
14#隐藏404:
wfuzz -w wordlist --hc 404 URL/FUZZ
#隐藏404、403:
wfuzz -w wordlist --hc 404,403 URL/FUZZ
e.g.使用百度举个例子运行wfuzz -w test_dict.txt https://www.baidu.com/FUZZ #这里所有的测试请求,都是不存在的页面
404页面规则就是如上图结果所示:响应报文状态码(302)、响应报文行数(7)、响应报文字数(18)、响应报文字符数(222)
wfuzz -w wordlist --hl 7 https://www.baidu.com/FUZZ
wfuzz -w wordlist --hw 18 https://www.baidu.com/FUZZ
wfuzz -w wordlist --hh 222 https://www.baidu.com/FUZZ
#如果根据单个条件判断相对来说肯定是不精确的,所以整合一下就是这样的命令:
wfuzz -w wordlist --hc 302 --hl 7 --hw 18 --hh 222 https://www.baidu.com/FUZZ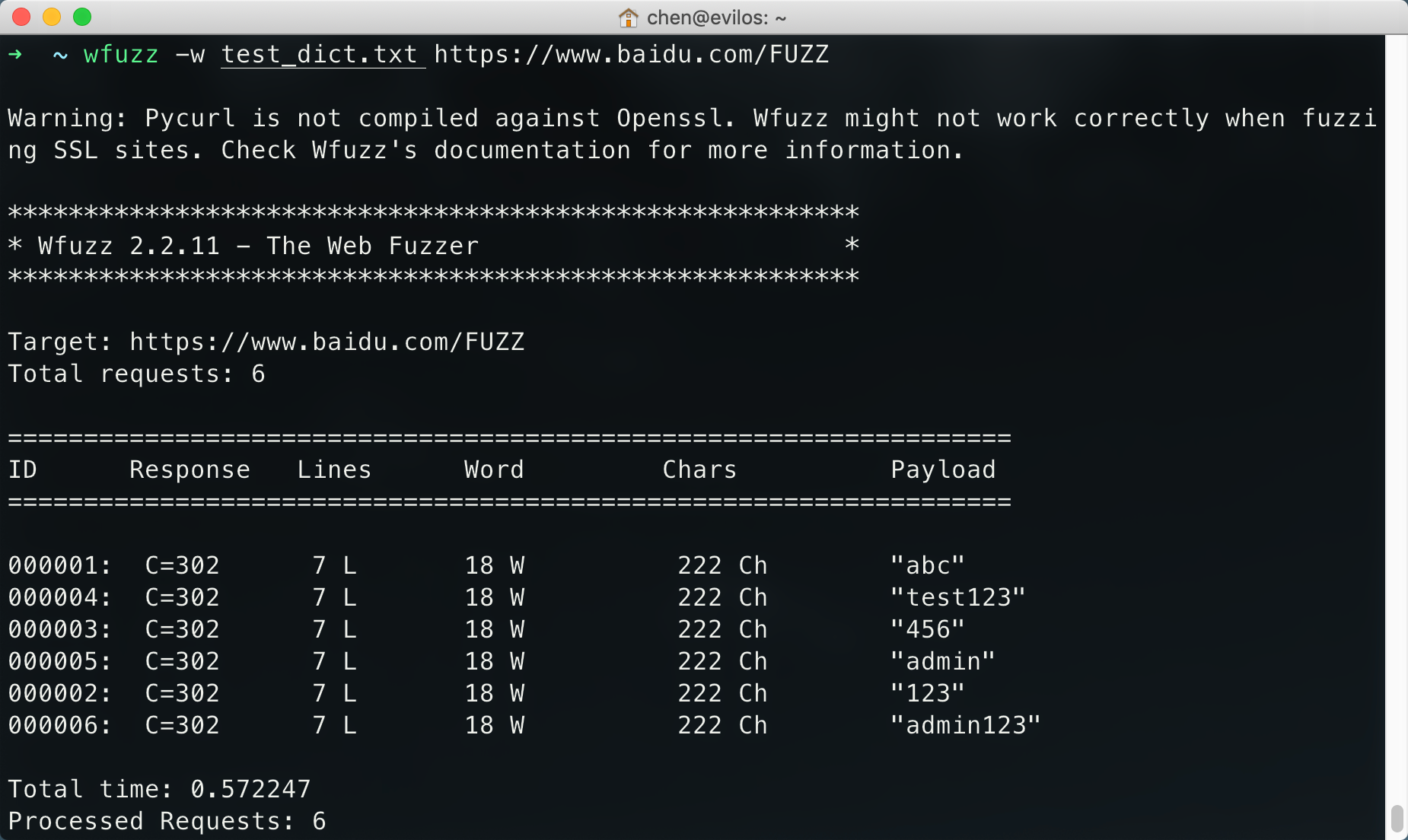
示例5.基准线(Baseline)的使用 weiyigeek.top-1
wfuzz -w wordlist --hh BBB https://www.baidu.com/FUZZ{404there}
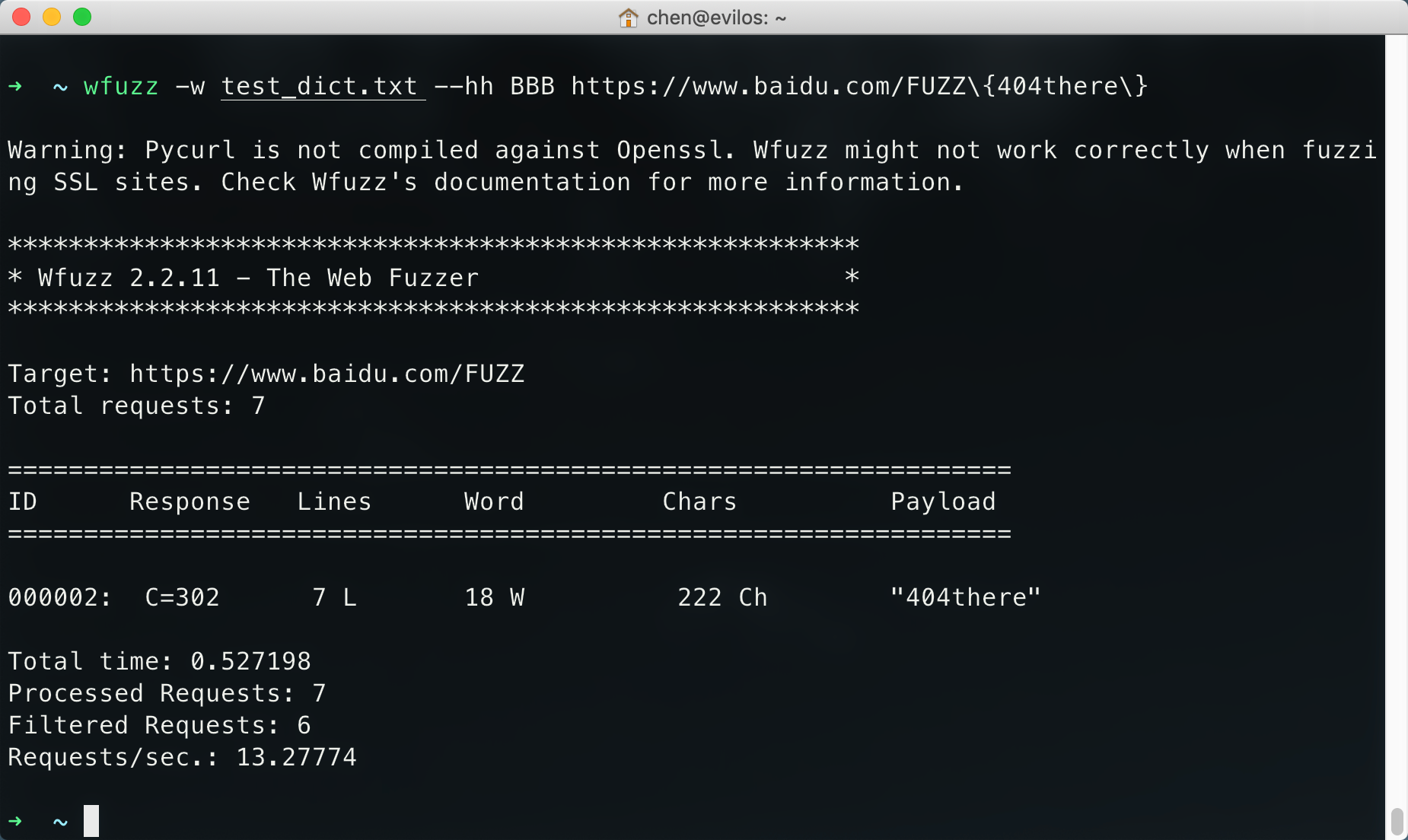
代表wfuzz第一个请求是请求https://www.baidu.com/404there这个网址,`在{ }内的值用来指定wfuzz第一个请求中的FUZZ占位符,而这第一个请求被标记为BBB(BBB不能换成别的)基准线`;其次这里使用的参数是–hh,也就是以BBB这条请求中的Chars为基准,其他请求的Chars值与BBB相同则隐藏。
示例6.使用正则表达式过滤的使用1
2
3
4
5
6#e.g. 在这里一个网站自定义返回页面的内容中包含Not Found,想根据这个内容进行过滤可以使用如下的命令:
wfuzz -w wordlist --hs "Not Found" http://127.0.0.1/FUZZ
#总结
wfuzz -w wordlist --hs 正则表达式 URL/FUZZ #隐藏
wfuzz -w wordlist --ss 正则表达式 URL/FUZZ #显示
示例7.内置工具的使用1
2
3
4
5
6
7
8
9
10
11
12
13
14#(1) 目前支持内建的encoders的加/解密
wfencode -e base64 123456
#[RES] MTIzNDU2
wfencode -d base64 MTIzNDU2
#[RES] 123456
#(2) wfpayload是payload生成工具
wfpayload -z range,0-10
[RES]
0
1
#(3) wxfuzz 工具
wxPython化的wfuzz也就是GUI图形界面的wfuz
描述:wfuzz本身自带字典爆破文件、目录;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57├── Injections #注入
│ ├── All_attack.txt
│ ├── SQL.txt
│ ├── Traversal.txt
│ ├── XML.txt
│ ├── XSS.txt
│ └── bad_chars.txt
├── general #通用
│ ├── admin-panels.txt
│ ├── big.txt
│ ├── catala.txt
│ ├── common.txt
│ ├── euskera.txt
│ ├── extensions_common.txt
│ ├── http_methods.txt
│ ├── medium.txt
│ ├── megabeast.txt
│ ├── mutations_common.txt
│ ├── spanish.txt
│ └── test.txt
├── others #其他
│ ├── common_pass.txt
│ └── names.txt
├── stress #压力
│ ├── alphanum_case.txt
│ ├── alphanum_case_extra.txt
│ ├── char.txt
│ ├── doble_uri_hex.txt
│ ├── test_ext.txt
│ └── uri_hex.txt
├── vulns #漏洞测试
│ ├── apache.txt
│ ├── cgis.txt
│ ├── coldfusion.txt
│ ├── dirTraversal-nix.txt
│ ├── dirTraversal-win.txt
│ ├── dirTraversal.txt
│ ├── domino.txt
│ ├── fatwire.txt
│ ├── fatwire_pagenames.txt
│ ├── frontpage.txt
│ ├── iis.txt
│ ├── iplanet.txt
│ ├── jrun.txt
│ ├── netware.txt
│ ├── oracle9i.txt
│ ├── sharepoint.txt
│ ├── sql_inj.txt
│ ├── sunas.txt
│ ├── tests.txt
│ ├── tomcat.txt
│ ├── vignette.txt
│ ├── weblogic.txt
│ └── websphere.txt
└── webservices
├── ws-dirs.txt
└── ws-files.txt
实际案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45#爆破文件:
wfuzz -w wordlist URL/FUZZ.php
#爆破目录:
wfuzz -w wordlist URL/FUZZ
#遍历枚举参数值使用payloads模块类中的range模块进行生成
wfuzz -z range,000-999 http://127.0.0.1/getuser.php?uid=FUZZ #uid参数可以遍历,已知123为三位数纯数字,需要从000-999进行遍历
#POST请求测试,-d参数传输POST请求正文。
wfuzz -w userList -w pwdList -d "username=FUZZ&password=FUZ2Z" http://127.0.0.1/login.php
#Cookie测试越权,b参数指定Cookie多个Cookie需要指定多次,也可以对Cookie进行测试,仍然使用FUZZ占位符即可。
wfuzz -z range,000-999 -b session=session -b cookie=cookie http://127.0.0.1/getuser.php?uid=FUZZ
#HTTP Headers测试伪造XFF头(IP),-H指定HTTP头,多个需要指定多次(同Cookie的-b参数)
wfuzz -z range,0000-9999 -H "X-Forwarded-For: FUZZ" http://127.0.0.1/get.php?userid=666
#测试HTTP请求方法(Method),-X参数是指定HTTP请求方法类型,因为这里要测试HTTP请求方法,后面的值为FUZZ占位符。
wfuzz -z list,"GET-POST-HEAD-PUT" -X FUZZ http://127.0.0.1/
#代理设置与关键字隐藏,多个代理可使用多个-p参数同时指定,wfuzz每次请求都会选取不同的代理进行
wfuzz -w wordlist -p proxtHost:proxyPort:TYPE URL/FUZZ #-p参数指定主机:端口:代理类型
wfuzz -z file,starter.txt -p 192.168.31.26:1080:SOCKS5 --hs "Cannot" https://foo.domain.com/FUZZ
#认证:测试一个需要HTTP Basic Auth保护的内容可使用如下命令:
#wfuzz可以通过--basec --ntml --digest来设置认证头,使用方法都一样:
# --basec/ntml/digest username:password
wfuzz -z list,"username-password" --basic FUZZ:FUZZ URL
#递归测试指定一个payload被递归的深度(数字)。
#例如:爆破目录时,我们想使用相同的payload对已发现的目录进行测试
wfuzz -z list,"admin-login.php-test-dorabox" -R 1 http://127.0.0.1/FUZZ
#并发和间隔,wfuzz提供了一些参数可以用来调节HTTP请求的线程
#使用-t参数设置并发请求,该参数默认设置都是10。
#使用-s参数可以调节每次发送HTTP的时间间隔。
wfuzz -z range,0-20 -t 20 -d "money=1" http://127.0.0.1/dorabox/race_condition/pay.php?FUZZ
#保存测试结果,可以通过printers模块来将结果以不同格式保存到文档中
#使用-f参数,指定值的格式为输出文件位置,输出格式。
$ wfuzz -f outfile,json -w wordlist URL/FUZZ
Iterators-迭代器
BurpSuite的Intruder模块中Attack Type有Sniper(狙击手)、Battering ram(撞击物)、Pitchfork(相交叉)、Cluster bomb(集束炸弹)~wfuzz的Iterators模块也可以完成这样的功能,将不同的字典的组合起来
使用参数-m 迭代器,wfuzz自带的迭代器有三个:zip、chain、product,如果不指定迭代器,默认为product迭代器。
一一对应进行组合,如果字典数不一致则多余的抛弃掉不请求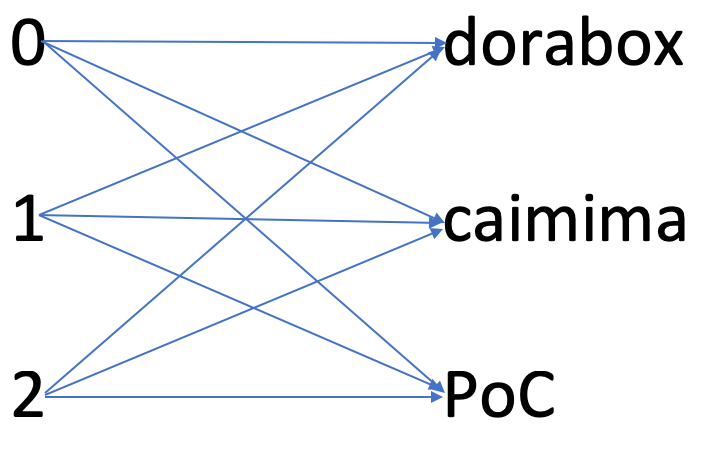
weiyigeek.top-
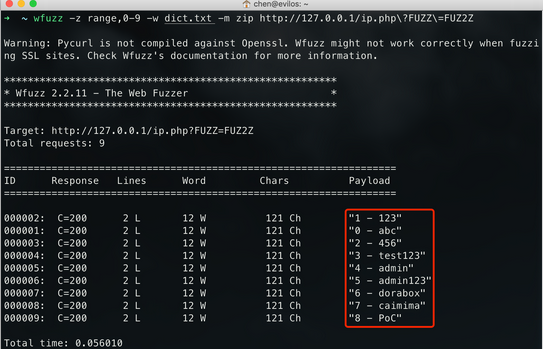
1.zip命令:
1 | wfuzz -z range,0-9 -w dict.txt -m zip http://127.0.0.1/ip.php?FUZZ=FUZ2Z |
weiyigeek.top-
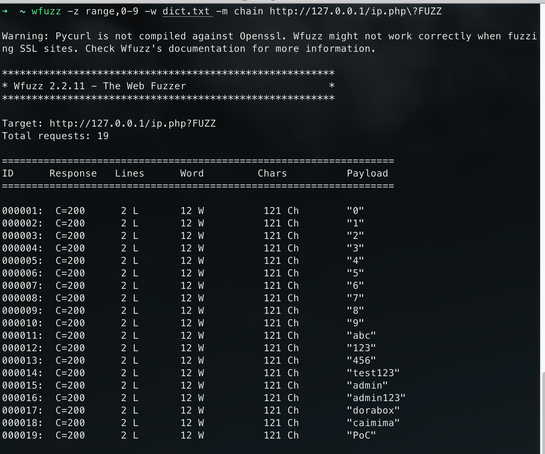
2.chain命令:
1 | wfuzz -z range,0-9 -w dict.txt -m chain http://127.0.0.1/ip.php?FUZZ |
weiyigeek.top-
3.product命令:
1 | wfuzz -z range,0-2 -w dict.txt -m product http://127.0.0.1/ip.php?FUZZ=FUZ2Z |
Encoders-编码加解密
wfuzz中encoders模块可以实现编码解码、加密,它支持所列转换功能请参考上面的;
正常使用:
1 | #使用Encoders的md5加密。 |
使用多个Encoder:
多个转换,使用一个-号分隔的列表来指定
1 | wfuzz -z file,dict.txt,md5-base64 http://127.0.0.1/ip.php\?FUZZ |
多次转换使用一个@号分隔的列表来按照从右往左顺序多次转换
1 | #这里让传入的字典先md5加密然后base64编码 |
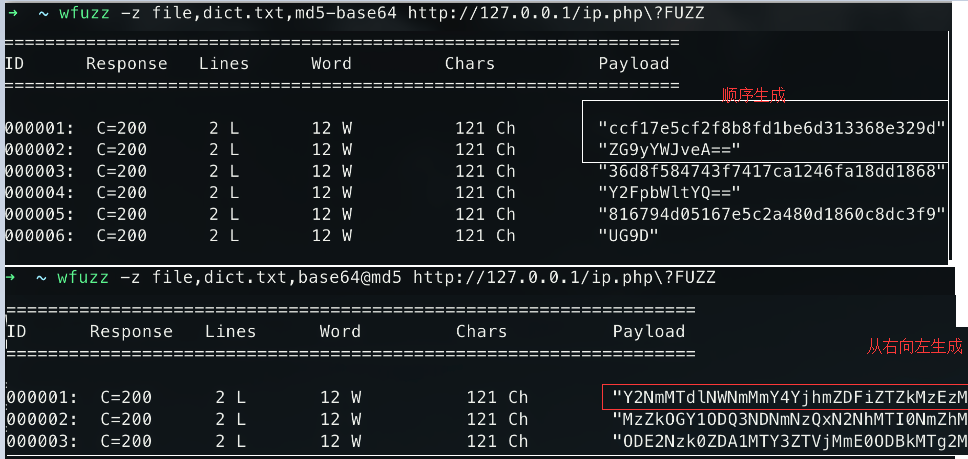
weiyigeek.top-
Scripts-脚本插件
描述:wfuzz支持插件,其本身也有很多插件,插件大部分都是实现扫描和解析功能,插件共有两大类和一类附加插件:
基础使用 weiyigeek.top-1
2
3
4#查看script中robots脚本的帮助信息
wfuzz --script-help=robots #该模块解析robots.txt的并且寻找新的内容
wfuzz --script=robots -z list,"robots.txt" http://127.0.0.1/FUZZ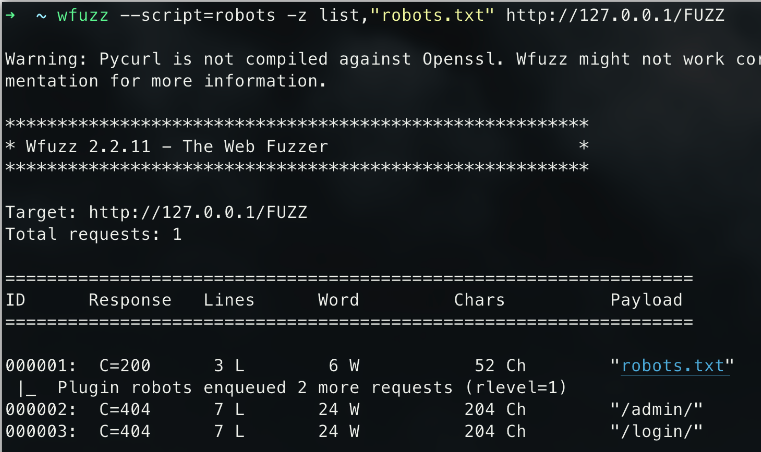
script是使用脚本模块的参数,这时候就有个疑惑命令为什么要加上list呢?
因为在这里robots脚本只是解析robots.txt规则的,所以你需要告诉wfuzz去请求哪个文件而这里我写的就是robots.txt就可以解析;
自定义插件:需要放在~/.wfuzz/scripts/目录下,具体如何编写可以参考已有的插件:
技巧-脚本插件
1 | #生成一个recipes: |
1 | #解析burplog里面请求的url |
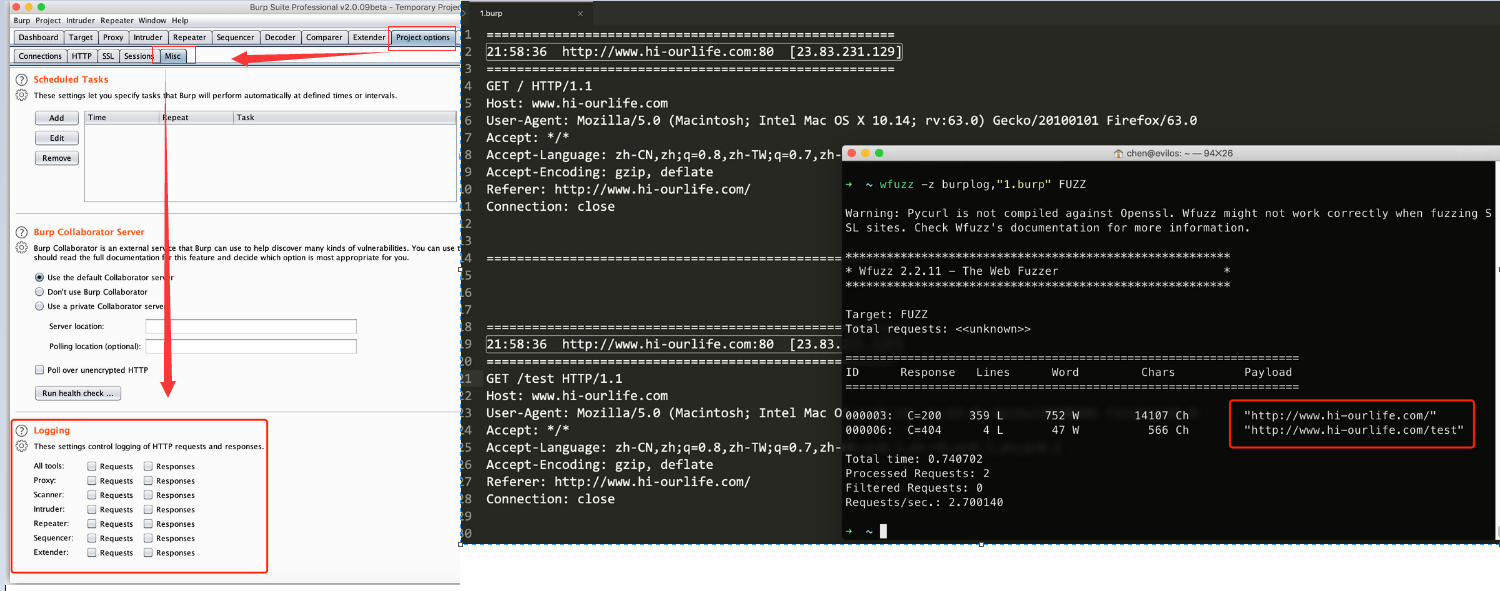
weiyigeek.top-
参考来源补充:
描述:w3af是一款丰富的Webapplication程序attack和审计框架-还支持Xpath注入、OS命令、错误的应用等。 weiyigeek.top-1
2
3
4
5
6
7
8w3af_console #命令行模式交互式
w3af_gui #可以用GUI版本的
w3af_console>>>help #首先使用OUTPUT插件,然后启用特定的Audit测试选项,设置Target然后对其scan.
#插件帮助
w3af>>> plugins
w3af/plugins>>> help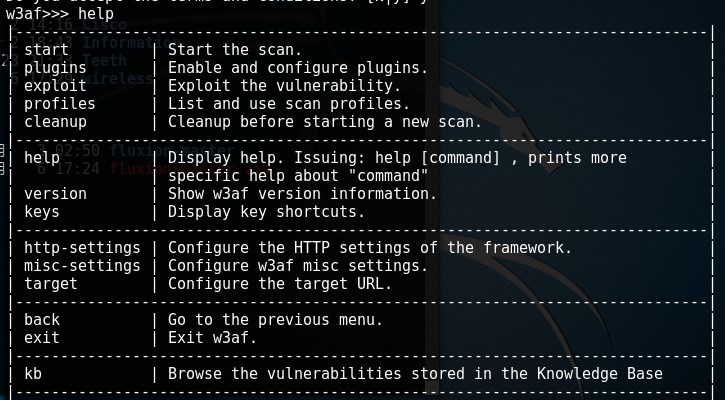
描述:wafwoof检测Web应用防火墙(WAF),规避Waf规则,涉及一些Http污染、空字节替换和规范化处理.HEX字符或者Unicode字符的URL编码. weiyigeek.top-
用法:wafw00f http://xiaomi.com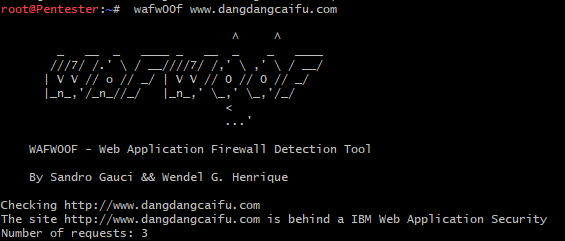
你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!

@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/网安大类/渗透系统/Kail/网站扫描与Fuzz测试之敏感信息收集.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2019/9-20-425.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议