[TOC]
0x00 基础知识 Linux内核涉及进程和程序的所有算法都围绕一个名为task_struct的数据结构建立,该结构定义在/usr/include/sched.h中;task_struct数据结构提供了两个链表表头,用于实现进程家族关系;
Linux内核把虚拟地址空间划分为两个部分即核心态,用户状态,两种状态的关键差别在于对高于TASK_SIZE的内存区域的访问:
Linux进程可以分为实时进程和非实时进程,硬实时进程的关键特征某些任务必须在指定的时限内完成(严格的时间限制),而软实时进程是硬实时进程的一种弱化形式。
Linux使用了源于BSD的套接字抽象,而套接字Socket可以看作应用程序、文件接口、内核的网络实现之间的代理;
Linux提供资源限制(resource limit,rlimit)机制对进程使用系统资源施加某些限制。该机制利用了task_struct中的rlimit数组项类型为struct rlimit。打开文件的数目(RLIMIT_NOFILE,默认限制在1024)。 每用户的大进程数(RLIMIT_NPROC)定义为max_threads/2。max_threads是一个全局变量,指定了在把八分之一可用内存用于管理线程信息的情况下可以创建的线程数目。在计算时提前给定了20个线程的小可能内存用量。
1.名词解释 (1)伙伴系统:系统中的空闲内存块总是两两分组,每组中的两个内存块称作伙伴
伙伴的分配可以是彼此独立的但如果两个伙伴都是空闲的,内核会将其合并为一个更大的内存块,作为下一层次上某个内存块的伙伴。
(2)字符设备:提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取。
此类设备支持按字节/字符来读写数据。举例来说调制解调器是典型的字符设备。
(3)块设备:应用程序可以随机访问设备数据,程序可自行确定读取数据的位置。
硬盘是典型的块设备,应用程序可以寻址磁盘上的任何位置,并由此读取数据。
此外数据的读写只能以块(通常是512B)的倍数进行。与字符设备不同,块设备并不支持基于字符的寻址。 编写块设备的驱动程序比字符设备要复杂得多,因为内核为提高系统性能广泛地使用了缓存机制。
(4)抢占式多任务处理(preemptive multitasking):各个进程都分配到一定的时间段可以执行。
时间段到期后内核会从进程收回控制权,让一个不同的进程运行,而不考虑前一进程所 执行的上一个任务。
被抢占进程的运行时环境,即所有CPU寄存器的内容和页表都会保存起来,因此其执行结果不会丢失。
在该进程恢复执行时,其进程环境可以完全恢复,时间片的长度会根据进程执行环境决定;
(5)完全公平调度器(completely fair scheduler):在内核版本2.6.23开发期间合并进来。
新的代码再 一次完全放弃了原有的设计原则;例如前一个调度器中为确保用户交互任务响应快速,需要许多启 发式原则。该调度器的关键特性是,它试图尽可能地模仿理想情况下的公平调度。
此外它不仅可以调度单个进程,还能够处理更一般性的调度实体(scheduling entity);例如该调度器分配可用时间时, 可以首先在不同用户之间分配,接下来在各个用户的进程之间分配。
(6)内核抢占(kernel preemption):该选项支持在紧急情况下切换到另一个进程,甚至当前是处于核心态执行系统调用(中断处理期间是不行的)
尽管内核会试图尽快执行系统调用,但对于依赖恒定数据流的应用程序来说,系统调用所需的时间仍然太长了。
内核抢占可以减少这样的等待时间,因而保证“更平滑的”程序执行。但该特性的代价是 增加内核的复杂度,因为接下来有许多数据结构需要针对并发访问进行保护,即使在单处理器系统上 也是如此。
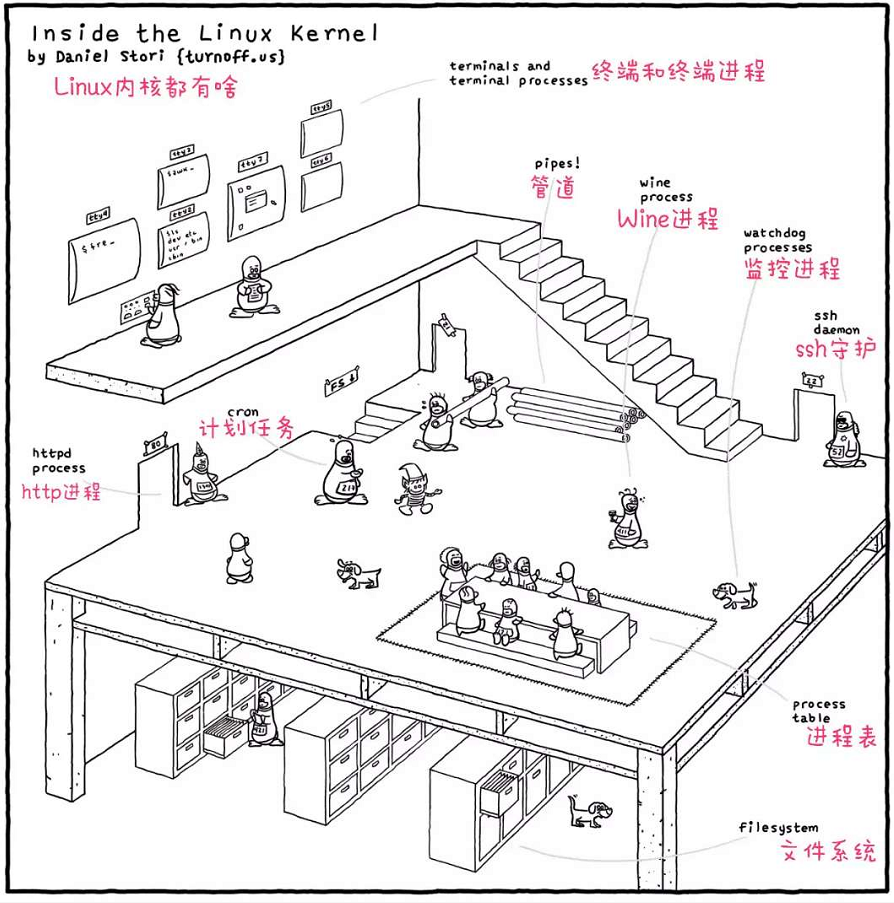
2.Inside the Linux Kernel 描述: 从下面一张图看出Linux内核之中都有啥进行简单描述:
weiyigeek.top-
PIPE: 是Uinx/posix中一种进程通讯机制,数据可以通过管道进行传输(实际是进程间的通讯)。
3.名称空间(Namespace) Linux 内核中实现6种namespace说明:
示例1:当前Linux宿主机终端进程对应的namespace信息:
[TOC]
0x00 基础知识 Linux内核涉及进程和程序的所有算法都围绕一个名为task_struct的数据结构建立,该结构定义在/usr/include/sched.h中;task_struct数据结构提供了两个链表表头,用于实现进程家族关系;
Linux内核把虚拟地址空间划分为两个部分即核心态,用户状态,两种状态的关键差别在于对高于TASK_SIZE的内存区域的访问:
Linux进程可以分为实时进程和非实时进程,硬实时进程的关键特征某些任务必须在指定的时限内完成(严格的时间限制),而软实时进程是硬实时进程的一种弱化形式。
Linux使用了源于BSD的套接字抽象,而套接字Socket可以看作应用程序、文件接口、内核的网络实现之间的代理;
Linux提供资源限制(resource limit,rlimit)机制对进程使用系统资源施加某些限制。该机制利用了task_struct中的rlimit数组项类型为struct rlimit。打开文件的数目(RLIMIT_NOFILE,默认限制在1024)。 每用户的大进程数(RLIMIT_NPROC)定义为max_threads/2。max_threads是一个全局变量,指定了在把八分之一可用内存用于管理线程信息的情况下可以创建的线程数目。在计算时提前给定了20个线程的小可能内存用量。
1.名词解释 (1)伙伴系统:系统中的空闲内存块总是两两分组,每组中的两个内存块称作伙伴
伙伴的分配可以是彼此独立的但如果两个伙伴都是空闲的,内核会将其合并为一个更大的内存块,作为下一层次上某个内存块的伙伴。
(2)字符设备:提供连续的数据流,应用程序可以顺序读取,通常不支持随机存取。
此类设备支持按字节/字符来读写数据。举例来说调制解调器是典型的字符设备。
(3)块设备:应用程序可以随机访问设备数据,程序可自行确定读取数据的位置。
硬盘是典型的块设备,应用程序可以寻址磁盘上的任何位置,并由此读取数据。
此外数据的读写只能以块(通常是512B)的倍数进行。与字符设备不同,块设备并不支持基于字符的寻址。 编写块设备的驱动程序比字符设备要复杂得多,因为内核为提高系统性能广泛地使用了缓存机制。
(4)抢占式多任务处理(preemptive multitasking):各个进程都分配到一定的时间段可以执行。
时间段到期后内核会从进程收回控制权,让一个不同的进程运行,而不考虑前一进程所 执行的上一个任务。
被抢占进程的运行时环境,即所有CPU寄存器的内容和页表都会保存起来,因此其执行结果不会丢失。
在该进程恢复执行时,其进程环境可以完全恢复,时间片的长度会根据进程执行环境决定;
(5)完全公平调度器(completely fair scheduler):在内核版本2.6.23开发期间合并进来。
新的代码再 一次完全放弃了原有的设计原则;例如前一个调度器中为确保用户交互任务响应快速,需要许多启 发式原则。该调度器的关键特性是,它试图尽可能地模仿理想情况下的公平调度。
此外它不仅可以调度单个进程,还能够处理更一般性的调度实体(scheduling entity);例如该调度器分配可用时间时, 可以首先在不同用户之间分配,接下来在各个用户的进程之间分配。
(6)内核抢占(kernel preemption):该选项支持在紧急情况下切换到另一个进程,甚至当前是处于核心态执行系统调用(中断处理期间是不行的)
尽管内核会试图尽快执行系统调用,但对于依赖恒定数据流的应用程序来说,系统调用所需的时间仍然太长了。
内核抢占可以减少这样的等待时间,因而保证“更平滑的”程序执行。但该特性的代价是 增加内核的复杂度,因为接下来有许多数据结构需要针对并发访问进行保护,即使在单处理器系统上 也是如此。
2.Inside the Linux Kernel 描述: 从下面一张图看出Linux内核之中都有啥进行简单描述:
weiyigeek.top-
PIPE: 是Uinx/posix中一种进程通讯机制,数据可以通过管道进行传输(实际是进程间的通讯)。
3.名称空间(Namespace) Linux 内核中实现6种namespace说明:
示例1:当前Linux宿主机终端进程对应的namespace信息:1 2 3 4 5 6 7 8 ls -l /proc/$$/ns 总用量 0 lrwxrwxrwx. 1 root root 0 7月 4 23:27 ipc -> ipc:[4026531839] lrwxrwxrwx. 1 root root 0 7月 4 23:27 mnt -> mnt:[4026531840] lrwxrwxrwx. 1 root root 0 7月 4 23:27 net -> net:[4026531956] lrwxrwxrwx. 1 root root 0 7月 4 23:27 pid -> pid:[4026531836] lrwxrwxrwx. 1 root root 0 7月 4 23:27 user -> user:[4026531837] lrwxrwxrwx. 1 root root 0 7月 4 23:27 uts -> uts:[4026531838]
内核Kernel是Linux的系统重要组成部分,相当于是其心脏;
通过前面的学习与内核升级我们知道Kernel包括以下几个软件包
kernel.x86_64
kernel-headers.x86_64
kernel-devel.x86_64
kernel-tools.x86_64
kernel-tools-libs.x86_64
简述几个软件包的作用:
1) Kernel-header : 包含应用程序所需的头文件(定义需要的结构和常量以及变量类型所占空间)以及Kconfig和Makefile,从而在Linux内核和用户空间库和程序之间构建应用程序在目标机器上运行; 例如 virtualbox使用的模块或专有的nvidia驱动程序;
提供/usr/include/linux:/usr/include/asm*等内核头文件。
内核对外的一个接口,当需要向内核提供兼容的功能模块时,势必需要提供内核的信息所以在安装驱动的时候它是必须的;
2) Kernel-devel : 包含Linux内核完整的源代码还有内核的配置文件,以及其他的开发用的资料,当您需要更换最新版本的内核时候它是必不可少的,常用于Fedora, Redhat, CentOS系统;
提供”/usr/src/kernels/$(uname -r)/include/*”内核开发相关的头文件
kernel-devel是用做内核的一般开发的,比如编写内核模块,原则上,可以不需要内核的原代码。
3) Kernel-source : 在RH某些版本之后不再附带在发行版中了,必须自己通过kernel-XXX.src.rpm提取出来。
关于kernel source的有kernel和kernel-devel两个rpm,其中kernel rpm包含源文件和头文件(就像2.4下的kernel-source rpm),而kernel-devel则主要是头文件。
Linux 内核源代码下载地址https://mirrors.edge.kernel.org/pub/linux/kernel/ https://git.kernel.org/pub/
国内:https://mirror.bjtu.edu.cn/kernel/linux/kernel/ http://mirrors.163.com/kernel/
kerner-lt # 长期支持版本; Linux内核(任何基于linux的操作系统的核心。)
kernel-ml-4.20.13-1.el7.elrepo.x86_64
1 2 3 4 4 :目前发布的内核主版本。 18 :偶数表示稳定版本,奇数表示开发中版本。 1 :错误修补的次数。 1 :当前这个版本的第 1 次微调 patch
2.Q&A Q: 那么什么是动态库?为什么需要动态库?
1) 静态库指的是在链接阶段将汇编生成的目标文件.o 与引用到的库一起链接打包到可执行文件中,因此对应的链接方式称为静态链接(static linking)。
2) 而动态库在程序编译时并不会被连接到目标代码中,而是在程序运行是才被载入,因此对应的链接方式称为动态链接(dynamic linking)。
补充说明: 90 年代的程序大多使用的是静态链接,因为当时的程序大多数都运行在软盘或者盒式磁带上,而且当时根本不存在标准库。这样程序在运行时与函数库再无瓜葛,移植方便。但对于 Linux 这样的分时系统,会在同一块硬盘上并发运行多个程序,这些程序基本上都会用到标准的 C 库,这时使用动态链接的优点就体现出来了。使用动态链接时,可执行文件不包含标准库文件,只包含到这些库文件的索引。例如,某程序依赖于库文件 libtrigonometry.so 中的 cos 和 sin 函数,该程序运行时就会根据索引找到并加载 libtrigonometry.so,然后程序就可以调用这个库文件中的函数。
Q: 使用动态链接的好处显而易见?
节省磁盘空间,不同的程序可以共享常见的库。
节省内存,共享的库只需从磁盘中加载到内存一次,然后在不同的程序之间共享。
更便于维护,库文件更新后,不需要重新编译使用该库的所有程序。
严格来说,动态库与共享库(shared libraries)相结合才能达到节省内存的功效。Linux 中动态库的扩展名是 .so( shared object),而 Windows 中动态库的扩展名是 .DLL(Dynamic-link library
Q: 问:什么是内核线程? 将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上也并行于内核自身的执行), 内核线程经常称之为(内核)守护进程Deamon。它们用于执行下列任务。
周期性地将修改的内存页与页来源块设备同步(例如使用mmap的文件映射)。
如果内存页很少使用则写入交换区。
管理延时动作(deferred action),以及我们后面讲解的Systemd。
实现文件系统的事务日志。
1.线程启动后一直等待,直至内核请求线程执行某一特定操作。
2.线程启动后按周期性间隔运行,检测特定资源的使用,在用量超出或低于预置的限制值时采取行动。内核使用这类线程用于连续监测任务。
问:如何启动或者定义一个Linux内核函数?kernel_thread函数可启动一个内核线程。。
问:Linux中运行的进程如何识别那些是内核线程? 1 2 3 4 $ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 51780 3788 ? Ss 2019 5:05 /usr/lib/systemd/systemd --system --deserialize 20 root 2 0.0 0.0 0 0 ? S 2019 0:01 [kthreadd]
问:进程运行有几种状态?
运行:该进程此刻正在执行。
等待:进程能够运行但没有得到许可,因为CPU分配给另一个进程。调度器可以在下一次任务切换时选择该进程。
睡眠:进程正在睡眠无法运行,因为它在等待一个外部事件。调度器无法在下一次任务切换 时选择该进程
问:僵尸进程是如何产生的?
在两种事件发生时程序将终止运行:首先必须由另一个进程或一个用户杀死(通常是通过发送SIGTERM或SIGKILL 信号来完成,这等价于正常地终止进程);其次进程的父进程在子进程终止时必须调用或已经调用wait4 (读做wait for)系统调用。这相当于向内核证实父进程已经确认子进程的终结,该系统调用使得内核可以释放为子进程保留的资源。
只有在第一个条件发生(程序终止)而第二个条件不成立的情况下(wait4),才会出现“僵尸” 状态。在进程终止之后,其数据尚未从进程表删除之前,进程总是暂时处于“僵尸”状态。有时候(例如如果父进程编程极其糟糕,没有发出wait调用),僵尸进程可能稳定地寄身于进程表中直至下一次系统重启。
问:典型的UNIX进程包括那些?
问:Unix多线程的实现方式?
fork生成当前进程的一个相同副本,该副本称之为子进程。原进程的所有资源都以适当的方式复制到子进程,因此该系统调用之后,原来的进程就有了两个独立的实例。这两个实例的联系包括:同一组打开文件、同样的工作目录、内存中同样的数据(两个进程各有一份副本)等等此外二者别无关联。
exec从一个可执行的二进制文件加载另一个应用程序来代替当前运行的进程。加载了一个新程序。因为exec并不创建新进程,所以必须首先使用fork复制一个旧的程序,然后调用exec在系统上创建另一个应用程序。
clone的工作原理基本上与fork相同但新进程不是独立于父进程的, 而可以与其共享某些资源。写时复制,直至新进程对内存页执行写操作才会复制内存页面,这比在执行fork时盲目地立即复制所有内存页要更高效。父子进程内存页之间的联系,只有对内核才是可见的,对应用程序是透明的可以指定需要共享和复制的资源种类,例如,父进程的内存数据、打开文件或安装的信号处理程序。clone用于实现线程,但仅仅该系统调用不足以做到这一点,还需要用户空间库才能提供完整的实现。
线程库的例子有Linuxthreads和Next Generation Posix Threads等
由此就可知 systcl 命令是通过 /proc/sys/ 目录下的各个接口文件实现配置的。
├── abi
sysctl 接口暨 procfs 工作流程 那么在内核中各子系统是如何导出这些参数到 procfs,并允许用户通过 echo, cat 等工具操作这些节点来设置参数的呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 static struct ctl_table sysctl_base_table [] = { { .procname = "kernel" , .mode = 0555 , .child = kern_table, }, { .procname = "vm" , .mode = 0555 , .child = vm_table, }, { .procname = "fs" , .mode = 0555 , .child = fs_table, }, { .procname = "debug" , .mode = 0555 , .child = debug_table, }, { .procname = "dev" , .mode = 0555 , .child = dev_table, }, { } }; static struct ctl_table vm_table [] = { ... { .procname = "drop_caches" , .data = &sysctl_drop_caches, .maxlen = sizeof (int ), .mode = 0644 , .proc_handler = drop_caches_sysctl_handler, .extra1 = &one, .extra2 = &four, }, ... }; int __init sysctl_init (void ) struct ctl_table_header *hdr ; hdr = register_sysctl_table(sysctl_base_table); kmemleak_not_leak(hdr); return 0 ; } int drop_caches_sysctl_handler (struct ctl_table *table, int write, void __user *buffer, size_t *length, loff_t *ppos) int ret; ret = proc_dointvec_minmax(table, write, buffer, length, ppos); if (ret) return ret; if (write) { static int stfu; if (sysctl_drop_caches & 1 ) { iterate_supers(drop_pagecache_sb, NULL ); count_vm_event(DROP_PAGECACHE); } if (sysctl_drop_caches & 2 ) { drop_slab(); count_vm_event(DROP_SLAB); } if (!stfu) { pr_info("%s (%d): drop_caches: %d\n" , current->comm, task_pid_nr(current), sysctl_drop_caches); } stfu |= sysctl_drop_caches & 4 ; } return 0 ; }
通过上述分析,大致梳理了 sysctl 接口在 kernel 中运行的大致流程。
如何新增一个 sysctl 接口 接下来,学以致用,我们可以在 /proc/sys 这个根目录下写一个 my_sysctl 的节点,首先定义并填充 ctl_table 结构体,并通过 register_sysctl_table 注册到系统。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 static int data; static struct ctl_table_header * my_ctl_header; int my_sysctl_callback( struct ctl_table *table, int write,void __user *buffer, size_t *lenp, loff_t *ppos) { int rc = proc_dointvec( table, write, buffer, lenp, ppos); if (write) { printk("write operation,cur data=%d\n" , *((unsigned int*)table->data)); } } /* The default sysctl tables: */ static struct ctl_table my_sysctl_table[] = { { .procname = "my_sysctl" , .mode = 0644, .data = &data, .maxlen = sizeof(unsigned int), .proc_handler = my_sysctl_callback, }, { }, }; static int __init sysctl_test_init(void) { printk("sysctl test init...\n" ); my_ctl_header = register_sysctl_table(my_sysctl_table); return 0; } static void __exit sysctl_test_exit(void) { printk("sysctl test exit...\n" ); unregister_sysctl_table(my_ctl_header); }
通过 qemu 进入目标文件系统,使用 insmod 注册驱动,在 /proc/sys 目录下出现 my_sysctl 节点,此时就可以通过 cat/echo 命令向该节点读写数据,也可以直接通过 systcl 设置该参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 /mnt [ 89.904485] sysctl test init... /mnt my_sysctl = 0 /mnt [ 151.278213] write operation,cur data=2 /mnt my_sysctl = 2 /mnt 2
四. OOM killer
OOM killer会在可用内存不足时选择性的杀掉用户进程,它的运行规则是怎样的,会选择哪些用户进程“下手”呢?OOM killer进程会为每个用户进程设置一个权值,这个权值越高,被“下手”的概率就越高,反之概率越低。每个进程的权值存放在/proc/{progress_id}/oom_score中,这个值是受/proc/{progress_id}/oom_adj的控制,oom_adj在不同的Linux版本的最小值不同,可以参考Linux源码中oom.h(从-15到-17)。当oom_adj设置为最小值时,该进程将不会被OOM killer杀掉,设置方法如下。
echo {value} > /proc/${process_id}/oom_adj
对于Redis所在的服务器来说,可以将所有Redis的oom_adj设置为最低值或者稍小的值,降低被OOM killer杀掉的概率。
for redis_pid in $(pgrep -f “redis-server”)
运维提示:
有关OOM killer的详细细节,可以参考Linux源码mm/oom_kill.c中oom_badness函数。
笔者认为oom_adj参数只能起到辅助作用,合理的规划内存更为重要。
通常在高可用情况下,被杀掉比僵死更好,因此不要过多依赖oom_adj配置