[TOC]
0x00 前言简述及环境准备 描述: 本章主要讲解和实践Prometheus在企业中的应用场景的复现,采用了docker-compose的资源清单进行快速构建prometheus_server、prometheus_pushgateway、prometheus_alertmanager、grafana等环境。
主要实现目标(功能):
0) 实现Windows主机的监控和展示
1) 实现MySQL与Redis数据库的监控和展示
2) 实现外部kubernetes集群的监控和展示
主机说明:
[TOC]
0x00 前言简述及环境准备 描述: 本章主要讲解和实践Prometheus在企业中的应用场景的复现,采用了docker-compose的资源清单进行快速构建prometheus_server、prometheus_pushgateway、prometheus_alertmanager、grafana等环境。
主要实现目标(功能):
0) 实现Windows主机的监控和展示
1) 实现MySQL与Redis数据库的监控和展示
2) 实现外部kubernetes集群的监控和展示
主机说明: 1 2 3 4 5 6 7 8 9 10 11 12 13 192.168.12.107 - master 192.168.12.108 - master 192.168.12.109 - master 192.168.12.223 - work 192.168.12.224 - work 192.168.12.225 - work 192.168.12.111 192.168.12.226
环境说明 192.168.12.107主机中安装了docker-compose软件,下面进行的配置循序渐进的进行添加。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 192.168.12.107 - prometheus_server: 30090 - prometheus_pushgateway: 30091 - prometheus_alertmanager: 30093 - grafana: 9091 192.168.12.108~109 192.168.12.223~225 - node_exporter: 9091 192.168.12.111 - cAdivsor: 9100 192.168.12.226 - kubernetes Api Server: 6443
目录结构一览:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 $ tree -L 5 . ├── docker-compose.yml ├── grafana │ └── data └── prometheus ├── conf │ ├── alertmanager.yaml │ ├── conf.d │ │ ├── discovery │ │ │ └── k8s_nodes.yaml │ │ ├── rules │ │ │ └── alert.rules │ │ └── auth │ │ ├── k8s_client.crt │ │ ├── k8s_client.key │ │ └── k8s_token │ └── prometheus.yml └── data
环境快速准备
0.目录结构快速生成
1 2 3 mkdir -vp /nfsdisk-31/monitor/prometheus/conf/conf.d/{discovery,rules,auth} mkdir -vp /nfsdisk-31/monitor/prometheus/data mkdir -vp /nfsdisk-31/monitor/grafana/date
1.prometheus.yaml 主配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 tee prometheus.yaml <<'EOF' global: scrape_interval: 2 m scrape_timeout: 10 s evaluation_interval: 1 m external_labels: monitor: 'prom-demo' scrape_configs: - job_name: 'prom-Server' static_configs: - targets: ['localhost:9090'] - job_name: 'cAdvisor' static_configs: - targets: ['192.168.12.111:9100'] - job_name: 'prom-Host' file_sd_configs: - files: - /etc/prometheus/conf.d/discovery/k8s_nodes.yaml refresh_interval: 1 m rule_files: - /etc/prometheus/conf.d/rules/*.rules alerting: alertmanagers: - scheme: http static_configs: - targets: - '192.168.12.107:30093' EOF
2.alert.rules 配置文件:
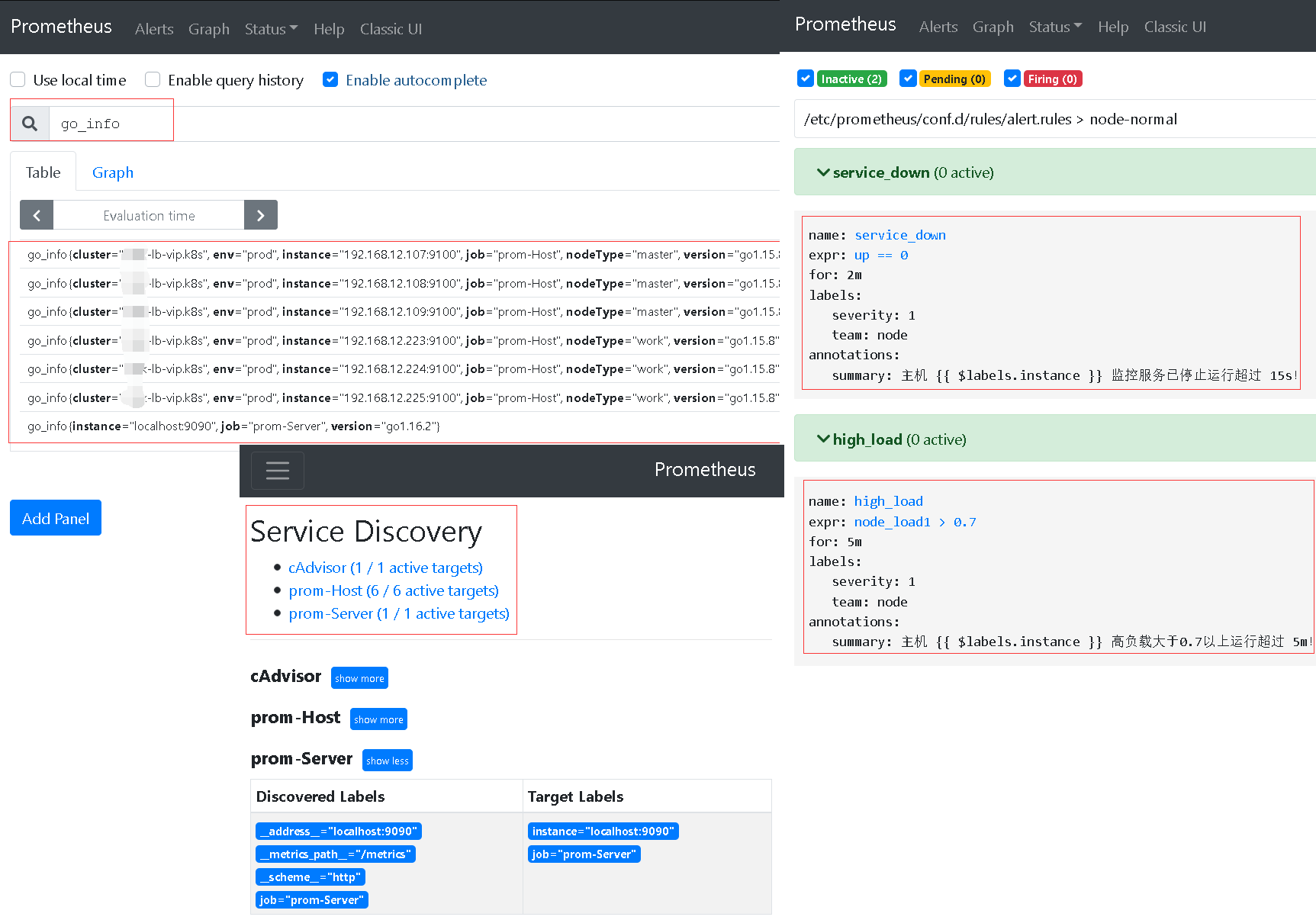
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 tee alert.rules <<'EOF' groups: - name: node-normal rules: - alert: service_down expr: up == 0 for : 2m labels: severity: 1 team: node annotations: summary: "主机 {{ $labels .instance }} 监控服务已停止运行超过 15s!" - alert: high_load expr: node_load1 > 0.7 for : 5m labels: severity: 1 team: node annotations: summary: "主机 {{ $labels .instance }} 高负载大于0.7以上运行超过 5m!" EOF
3.k8s_nodes.yaml 自动发现file_sd_configs配置文件。
1 2 3 4 5 6 tee k8s_nodes.yaml <<'EOF' - targets: [ '192.168.12.107:9100' ,'192.168.12.108:9100','192.168.12.109:9100' ] labels: {'env': 'prod' ,'cluster': 'weiyigeek-lb-vip.k8s' ,'nodeType': 'master' } - targets: [ '192.168.12.223:9100' ,'192.168.12.224:9100','192.168.12.225:9100' ] labels: {'env': 'prod' ,'cluster': 'weiyigeek-lb-vip.k8s' ,'nodeType': 'work' } EOF
4.alertmanager.yaml 邮箱报警发送配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 tee alertmanager.yaml <<'EOF' global: resolve_timeout: 5m smtp_from: 'monitor@weiyigeek.top' smtp_smarthost: 'smtp.exmail.qq.com:465' smtp_auth_username: 'monitor@weiyigeek.top' smtp_auth_password: xxxxxxxxxxx' smtp_require_tls: false # smtp_hello: ' qq.com' route: group_by: [' alertname'] group_wait: 30s group_interval: 1m repeat_interval: 10m receiver: ' default-email' receivers: - name: ' default-email' email_configs: - to: ' master@weiyigeek.top' send_resolved: true # inhibit_rules: # - source_match: # severity: ' critical' # target_match: # severity: ' warning' # equal: [' alertname', ' instance'] EOF # Tips : 可以采用amtool工具校验该yml文件是否无误`./amtool check-config alertmanager.yml`
5.docker-compose.yml 资源清单内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 $ docker network create monitor --driver bridge tee docker-compose.yml <<'EOF' version: '3.2' services: prometheus: image: prom/prometheus:v2.26.0 container_name: prometheus_server environment: TZ: Asia/Shanghai volumes: - /nfsdisk-31/monitor/prometheus/conf/prometheus.yaml:/etc/prometheus/prometheus.yaml - /nfsdisk-31/monitor/prometheus/conf/conf.d:/etc/prometheus/conf.d - /nfsdisk-31/monitor/prometheus/data:/prometheus/data - /etc/localtime:/etc/localtime command : - '--config.file=/etc/prometheus/prometheus.yaml' - '--storage.tsdb.path=/prometheus/data' - '--web.enable-admin-api' - '--web.enable-lifecycle' ports: - '30090:9090' restart: always networks: - monitor pushgateway: image: prom/pushgateway container_name: prometheus_pushgateway environment: TZ: Asia/Shanghai volumes: - /etc/localtime:/etc/localtime ports: - '30091:9091' restart: always networks: - monitor alertmanager: image: prom/alertmanager:v0.21.0 container_name: prometheus_alertmanager environment: TZ: Asia/Shanghai volumes: - /nfsdisk-31/monitor/prometheus/conf/alertmanager.yaml:/etc/alertmanager.yaml - /etc/localtime:/etc/localtime command : - '--config.file=/etc/alertmanager.yaml' - '--storage.path=/alertmanager' ports: - '30093:9093' restart: always networks: - monitor grafana: image: grafana/grafana:7.5.5 container_name: grafana user: "472" environment: - TZ=Asia/Shanghai - GF_SECURITY_ADMIN_PASSWORD=weiyigeek volumes: - /nfsdisk-31/monitor/grafana/data:/var/lib/grafana - /etc/localtime:/etc/localtime ports: - '30000:3000' restart: always networks: - monitor dns: - 223.6.6.6 - 192.168.12.254 networks: monitor: external: true EOF docker-compose config docker-compose up -d
6.环境验证: 访问搭建的prometheus server 服务地址http://192.168.12.107:30090/service-discovery进行查询以及监控节点的查看。
weiyigeek.top-基础环境验证
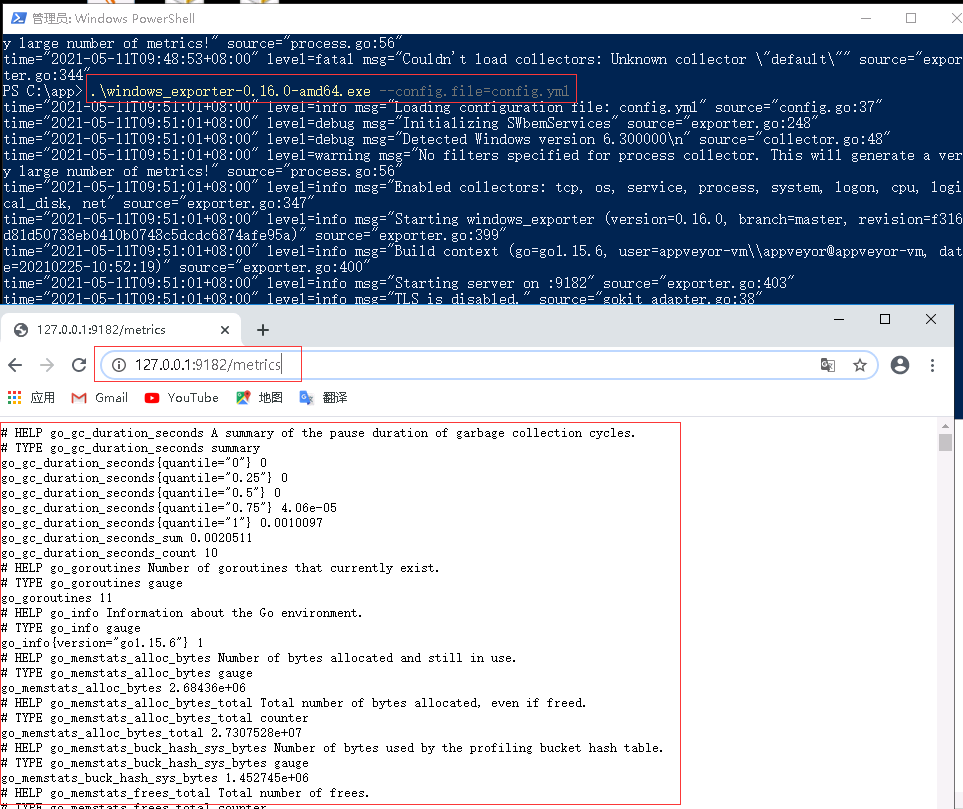
0x01 实现Windows主机的监控和展示 描述: 我们采用 Prometheus 监控进行 Windows 机器,我们也要像在 node_exporter 二进制可执行软件安装运行在Linux系统上, 在Windows系统上安装 windows_exporter 操作流程如下:
weiyigeek.top-windows-metrics
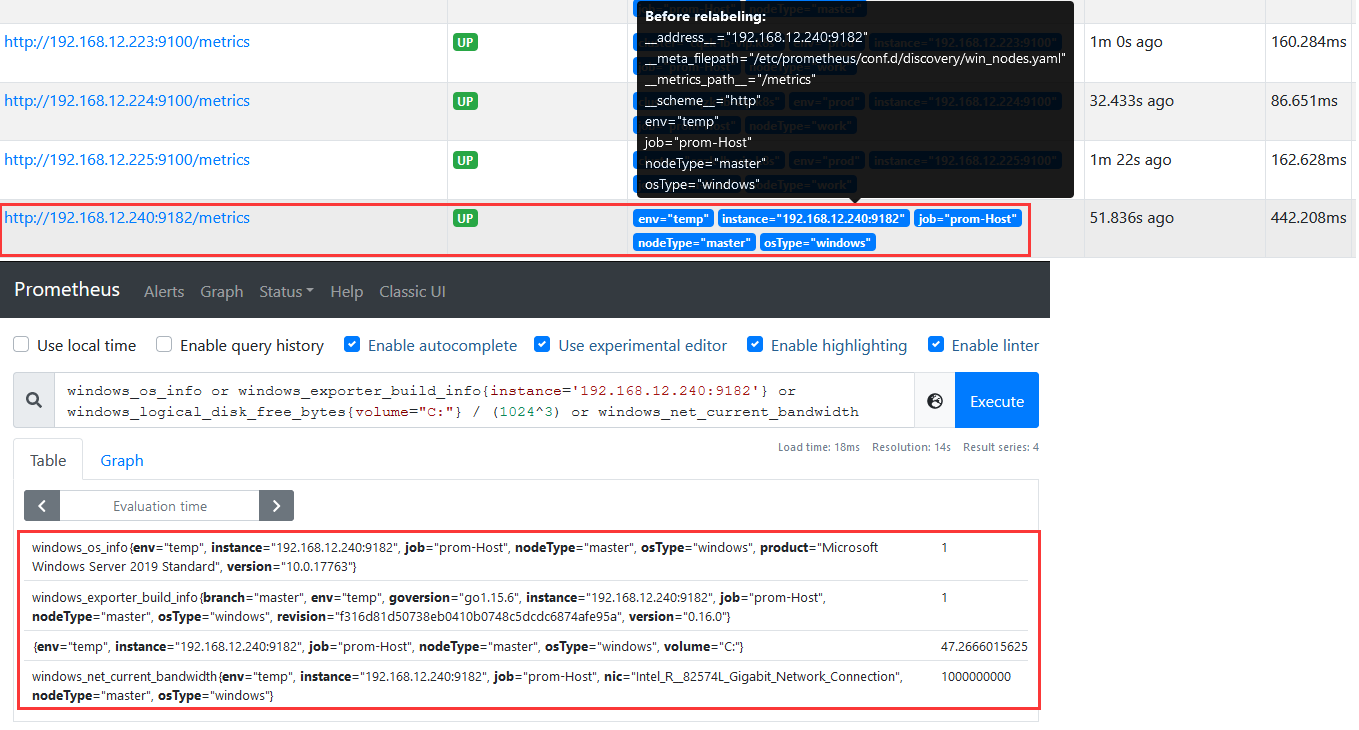
Step 3.添加到prometheus.yaml主配置文件之中进行重新加载配置即可发现该机器,如下图所示。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 scrape_configs: - job_name: 'windows-exporter' file_sd_configs: - files: - /etc/prometheus/conf.d/discovery/win_nodes.yaml refresh_interval: 1m - targets: [ '192.168.12.240:9182' ] labels: {'env' : 'temp' ,'osType' : 'windows' ,'nodeType' : 'master' } windows_os_info or windows_exporter_build_info{instance='192.168.12.240:9182' } or windows_logical_disk_free_bytes{volume="C:" } / (1024^3) or windows_net_current_bandwidth
weiyigeek.top-windows_exporter_promQL
Step 4.配置Grafana添加prometheus的windows监控的dashboard(官方搜索 )
weiyigeek.top-Grafana_windows_export
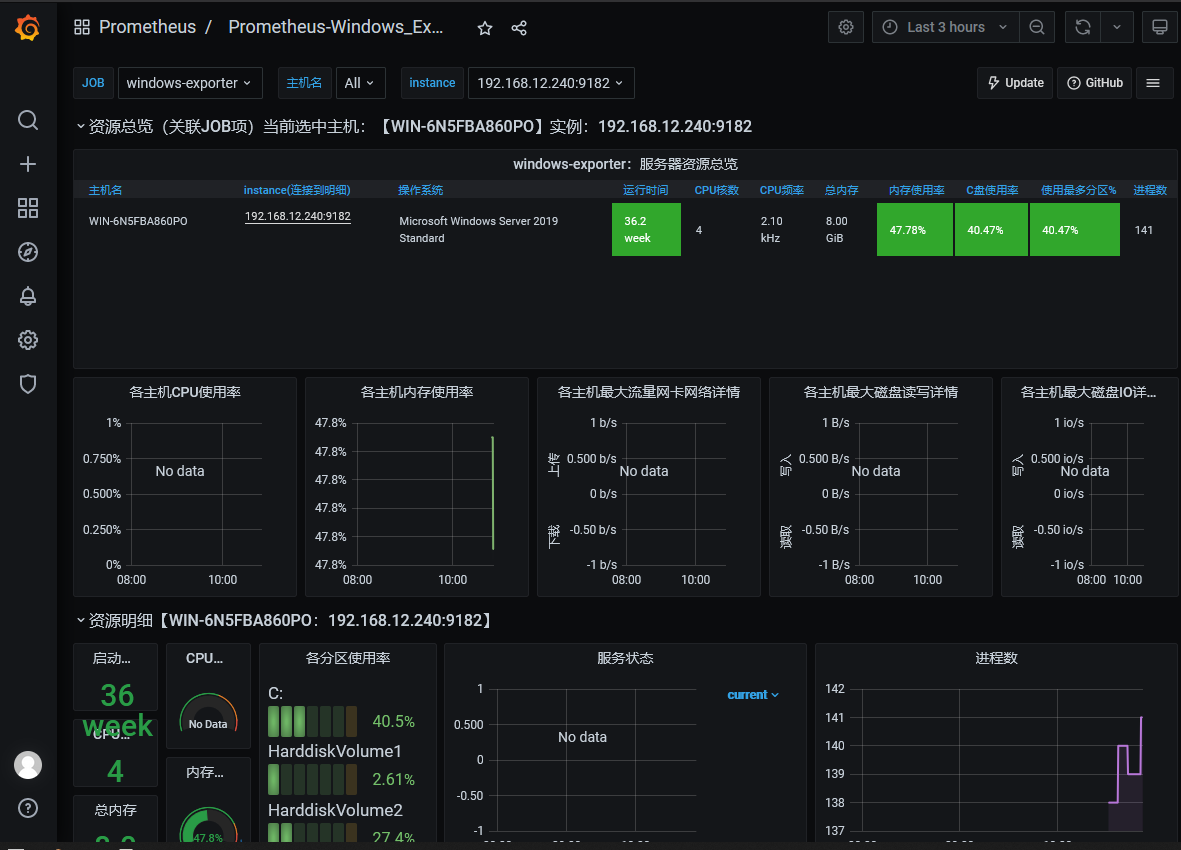
Step 5.访问Grafana的Dashbord查看windows采集的数据展示验证
weiyigeek.top-
0x02 实现MySQL与Redis数据库的监控和展示 描述: 我们可以针对于MySQL以及Redis进行数据库的监控配置利用到的软件是mysql_exporter(https://github.com/prometheus/mysqld_exporter)和`redis_exporter`(https://github.com/oliver006/redis_exporter/)。
Step 1.准备测试的MySQL与Redis的数据库然后利用docker容器进行监控指标的采集;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 CREATE USER 'exporter' @'%' IDENTIFIED BY 'XXXXXXXX' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter' @'%' ; docker run -d -p 9104:9104 --name mysqld-exporter -e DATA_SOURCE_NAME="exporter:XXXXXXXX@(192.168.12.185:3306)/" prom/mysqld-exporter docker run -d --name redis_exporter --network host -e REDIS_ADDR="redis://192.168.12.1doc85:6379" -e REDIS_PASSWORD="weiyigeek.top" oliver006/redis_exporter $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c3a7a5663143 oliver006/redis_exporter "/redis_exporter" 9 minutes ago Up 9 minutes redis_exporter 0a3d557bf36b prom/mysqld-exporter "/bin/mysqld_exporter" 16 minutes ago Up 16 minutes 0.0.0.0:9104->9104/tcp mysqld-exporter
Step 2.分别访问mysqld-exporter和redis_exporter的metrics的URL
1 2 3 4 5 6 7 8 9 10 11 12 13 $ curl -s http://192.168.12.111:9104/metrics | tail -n -5 promhttp_metric_handler_requests_total{code="200" } 2 promhttp_metric_handler_requests_total{code="500" } 2 promhttp_metric_handler_requests_total{code="503" } 0 $ curl -s http://192.168.12.111:9121/metrics | tail -n -5 redis_up 1 redis_uptime_in_seconds 1.281979e+06
Step 3.prometheus.yaml 主配置文件修改和添加;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 scrape_configs: - job_name: 'mysql_discovery' file_sd_configs: - files: - /etc/prometheus/conf.d/discovery/mysql_discovery.yaml refresh_interval: 1 m - job_name: 'redis_discovery' file_sd_configs: - files: - /etc/prometheus/conf.d/discovery/redis_discovery.yaml refresh_interval: 1 m - targets: [ '192.168.12.111:9104' ] labels: {'env': 'test' ,'osType': 'container' ,'nodeType': 'database' } - targets: [ '192.168.12.111:9121' ] labels: {'env': 'test' ,'osType': 'container' ,'nodeType': 'database' }
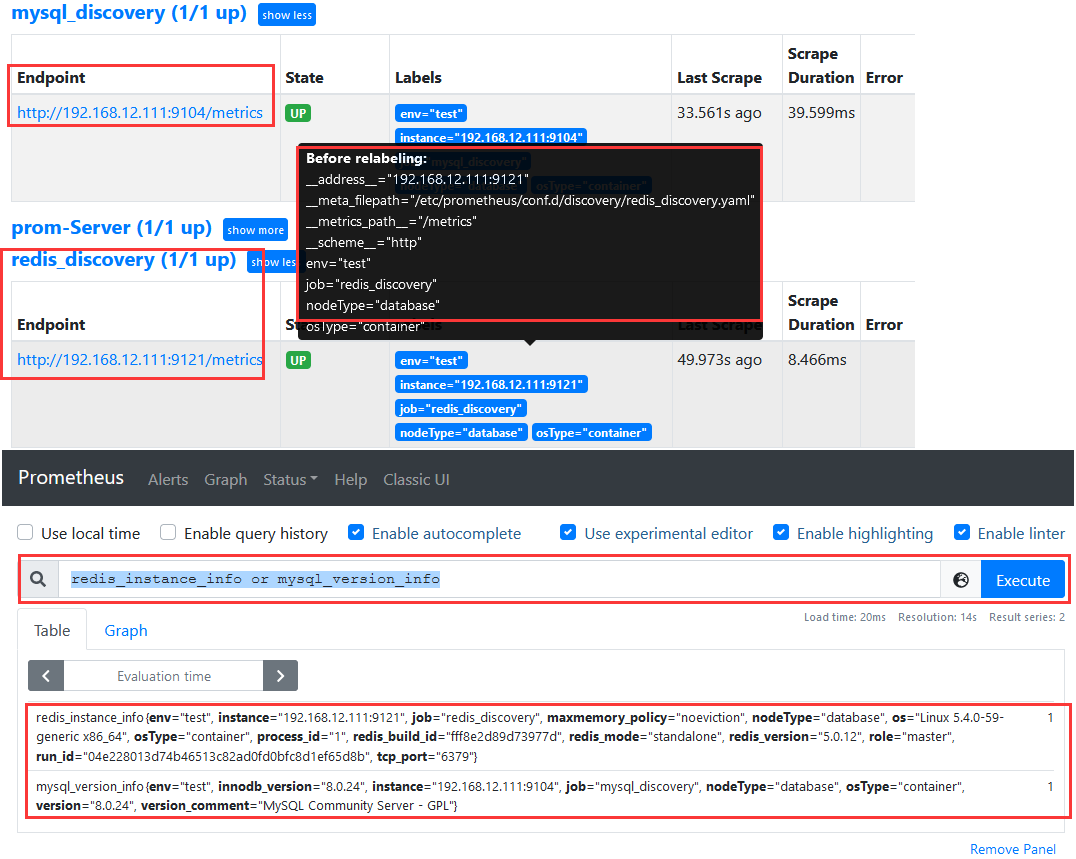
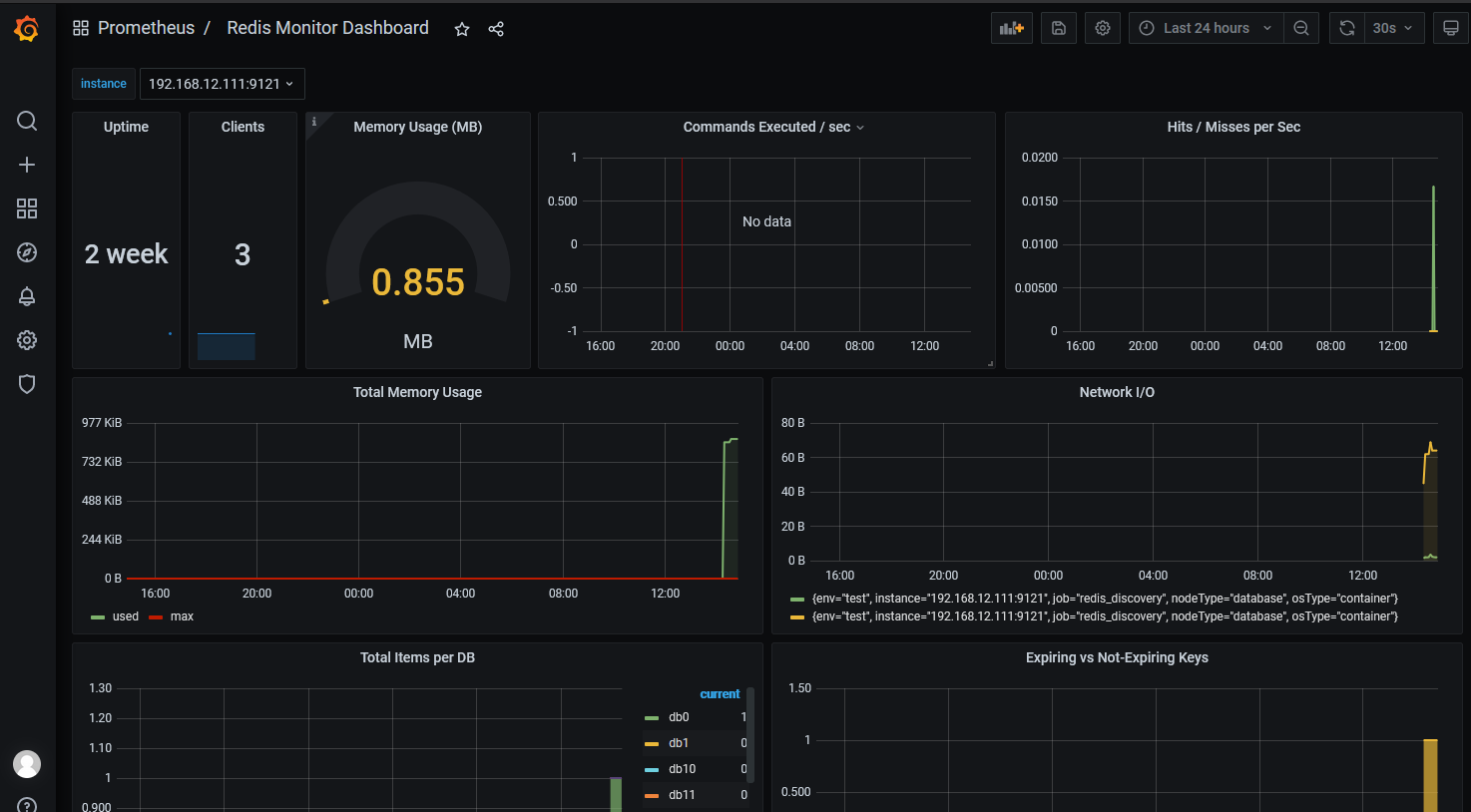
Step 4.热加载prometheus.yaml配置或者重新启动prometheus容器验证monitor目标执行PromQL表达式: redis_instance_info or mysql_version_info
weiyigeek.top-redis&mysql_exporter
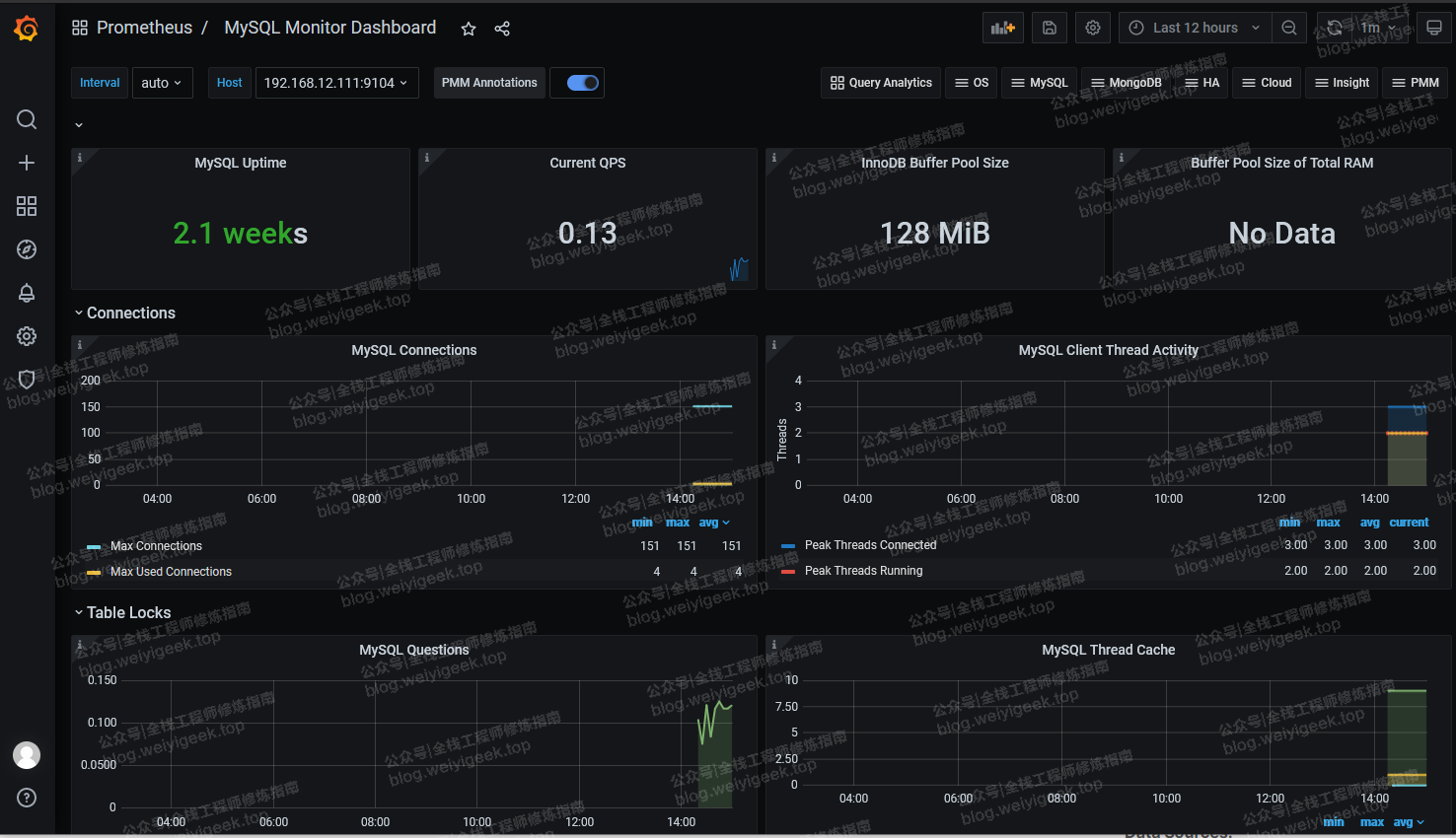
weiyigeek.top-MySQL-Dashbord
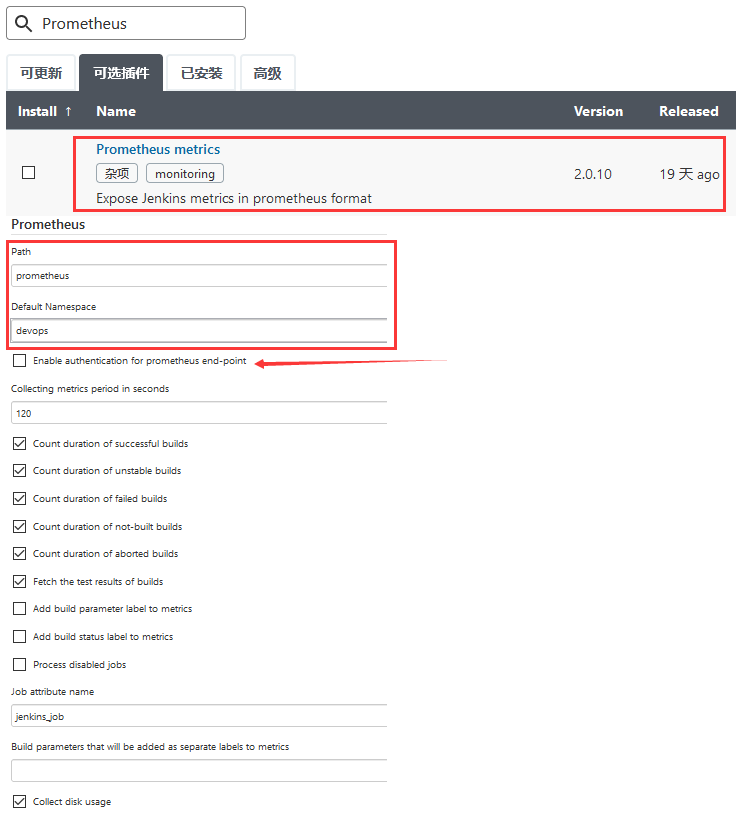
0x03 实现Jenkins持续集成和交付的服务监控和展示 目标: 使用Prometheus对持续集成Jenkins进行监控,并通过Grafana展示监控数据。
weiyigeek.top-Prometheus metrics
Step 3.测试验证Prometheus插件运行情况,即访问http://yourjenkinserver:port/prometheus
weiyigeek.top-reuqets-Prometheus
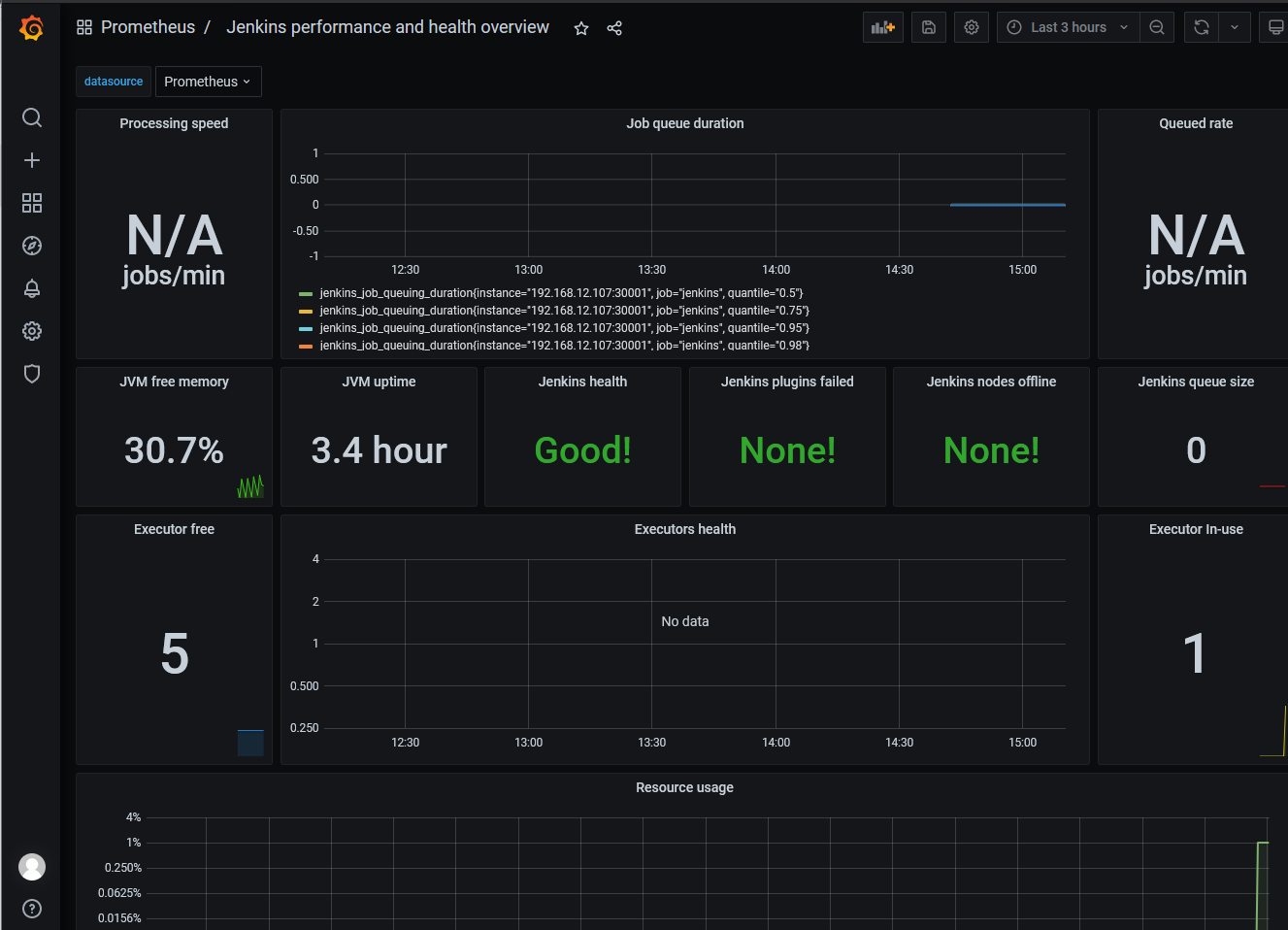
Step 6.在Grafana进行添加数据源配置并显示采集的指标。
weiyigeek.top-a Jenkins performance and health overview
0x04 实现kubernetes外部集群的监控和展示 描述: 我们知道学习测试 Prometheus 一般将其安装在k8s集群中进行数据metrics的采集,但在实际的环境中企业大多选择将
Q: Prometheus 如何采集Kubernetes集群数据?
答: 如果我们对集群内部的 Prometheus 自动发现 Kubernetes 的数据比较熟悉的话,那么监控外部集群的原理也是一样的,只是访问 APIServer 的形式有 inCluster 模式变成了 KubeConfig 的模式,inCluster 模式下在 Pod 中就已经自动注入了访问集群的 token 和 ca.crt 文件,所以非常方便,那么在集群外的话就需要我们手动提供这两个文件,才能够做到自动发现了。
Q: Prometheus通过exporter收集各种维度的监控指标
答: Prometheus 通过 kubernetes_sd_configs 从 Kubernetes 的 REST API 查找并拉取指标,并始终与集群状态保持同步,使用endpoints,service,node,pod,ingress等角色进行自动发现
endpoints : 自动发现service中的endpoint
node: 自动发现每个集群节点发现一个target,其地址默认为Kubelet的HTTP端口如"https://192.168.3.217:10250/metrics"
service : 自动发现每个服务的每个服务端口的target
pod : 自动发现所有容器及端口
ingrsss : 自动发现ingress中path
Q: 可以通过哪几种方式维度收集监控指标?
维度 | 工具 | 监控url(__metrics_path__) |备注|__scheme__://__address____metrics_path__|Deploy/ds等|
Tips : 注意kube-state-metrics监控的URL的动态发现是基于标签的自动补全,其中标签的值都可以通过Prometheus的relabel_config拼接成最终的监控url,由于集群外部署Prometheus和集群内部署Prometheus是不一样的,因此我们可以通过proxy url集群外Prometheus就可以访问监控url来拉取监控指标。
Q: 如何构造Apiserver proxy url? 1.通过public IPs访问service , 2.通过proxy 访问node、pod、service, 3.通过集群内的node或pod间接访问
例如: 通过kubectl cluster-info命令可以查看kube-system命令空间的proxy url1 2 3 $ kubectl cluster-info Kubernetes master is running at https://k8s-dev.weiyigeek:6443 KubeDNS is running at https://k8s-dev.weiyigeek:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
所以其默认的构造规则为如下格式。1 2 3 4 5 6 7 set other_apiserver_address = k8s-dev.weiyigeek:6443https://${other_apiserver_address} /api/v1/nodes/node_name:[port_name]/proxy/metrics https://${other_apiserver_address} /api/v1/namespaces/service_namespace/services/http:service_name[:port_name]/proxy/metrics https://${other_apiserver_address} /api/v1/namespaces/pod_namespace/pods/http:pod_name[:port_name]/proxy/metrics
在我们了解如何构造proxy url后,我们可以通过集群外Prometheus的relabel_config自行构造proxy url。
1.Endpoints 之服务自动发现 描述: 此处我们采用进行安装部署k8s集群监控的kube-state-metrics服务, 它监听Kubernetes API服务器并生成关联对象的指标, 它不关注单个Kubernetes组件的运行状况,而是关注内部各种对象(如deployment、node、pod等)的运行状况。
流程步骤:
Step 1.我们先查看当前kube-state-metrics兼容性矩阵与我们kubernetes集群版本的对应参考地址 ,下面最多记录5个kube状态度量和5个kubernetes版本。1 2 3 4 5 kube-state-metrics Kubernetes 1.17 Kubernetes 1.18 Kubernetes 1.19 Kubernetes 1.20 Kubernetes 1.21 v1.8.0 - - - - - v1.9.8 - - - - - v2.0.0 -/✓ -/✓ ✓ ✓ -/✓ master -/✓ -/✓ ✓ ✓ ✓
Step 2.k8s集群 ApiServer 访问鉴权账号创建和绑定的集群角色权限配置。K8S apiserver需要先进行授权,而集群内部Prometheus可以使用集群内默认配置进行访问,而集群外访问需要使用token+客户端cert进行认证因此需要先进行RBAC授权。
此处测试由于我们需要访问不同的namespace,建议先使用分配绑定cluster-admin权限,但在生产中一定要使用最小权限原则来保证其安全性(后面会进行演示)。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 kubectl create ns monitor kubectl create sa prometheus --namespace monitor $ kubectl create clusterrolebinding prometheus --clusterrole cluster-admin --serviceaccount=monitor:prometheus $ kubectl get sa $ kubectl get sa prometheus -n monitor -o yaml kubectl get secret -n monitor $(kubectl get sa prometheus -n monitor -o yaml | tail -n 1 | cut -d " " -f 3) -o yaml | grep "token:" | head -n 1 | awk '{print $2}' |base64 -d > k8s_token ~$ grep 'client-certificate-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d > k8s_client.crt ~$ grep 'client-key-data' ~/.kube/config | head -n 1 | awk '{print $2}' | base64 -d > k8s_client.key scp -P20211 weiyigeek@weiyigeek-226:~/.kube/k8s_client.crt ./conf.d/ssl/ scp -P20211 weiyigeek@weiyigeek-226:~/.kube/k8s_client.key ./conf.d/ssl/
Step 3.参考采用官方提供的部署资源清单参考地址 ,此处已采用上面创建的 prometheus 用户。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 tee kube-state-metrics.yaml <<'EOF' apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/version: 2.0.0 name: kube-state-metrics namespace: kube-system spec: replicas: 1 selector: matchLabels: app.kubernetes.io/name: kube-state-metrics template: metadata: labels: app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/version: 2.0.0 spec: containers: - image: bitnami/kube-state-metrics:2.0.0 livenessProbe: httpGet: path: /healthz port: 8080 initialDelaySeconds: 5 timeoutSeconds: 5 name: kube-state-metrics ports: - containerPort: 8080 name: http-metrics - containerPort: 8081 name: telemetry readinessProbe: httpGet: path: / port: 8081 initialDelaySeconds: 5 timeoutSeconds: 5 securityContext: runAsUser: 65534 nodeSelector: kubernetes.io/os: linux serviceAccountName: prometheus --- apiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: kube-state-metrics app.kubernetes.io/version: 2.0.0 name: kube-state-metrics namespace: kube-system annotations: prometheus.io/scrape: 'true' spec: clusterIP: None ports: - name: http-metrics port: 8080 targetPort: http-metrics - name: telemetry port: 8081 targetPort: telemetry selector: app.kubernetes.io/name: kube-state-metrics EOF kubectl create ns monitor sed -i "s#kube-system#monitor#g" kube-state-metrics.yaml kubectl apply -f kube-state-metrics.yaml
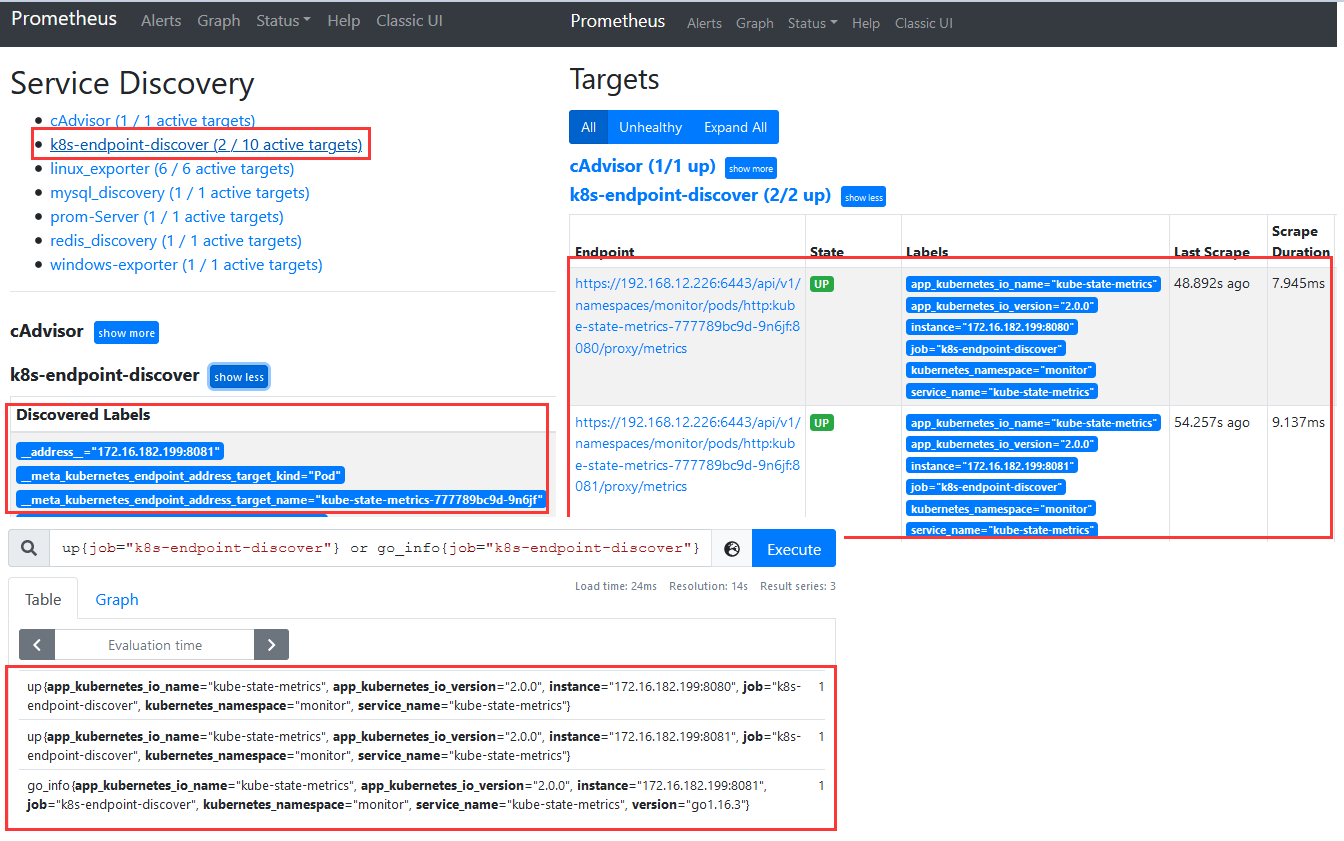
Step 6.配置prometheus.yml主配置文件添加kubernetes_sd_configs对象配置endpoints角色的自动发现。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 - job_name: 'k8s-endpoint-discover' scheme: https tls_config: ca_file: /etc/prometheus/conf.d/auth/k8s_ca.crt insecure_skip_verify: true bearer_token_file: /etc/prometheus/conf.d/auth/k8s_token kubernetes_sd_configs: - role: endpoints api_server: 'https://192.168.12.226:6443' tls_config: ca_file: /etc/prometheus/conf.d/auth/k8s_ca.crt insecure_skip_verify: true bearer_token_file: /etc/prometheus/conf.d/auth/k8s_token relabel_configs: - source_labels: [__meta_kubernetes_service_name] action: keep regex: '^(kube-state-metrics)$' - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__address__] action: replace target_label: instance - target_label: __address__ replacement: 192.168.12.226:6443 - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name, __meta_kubernetes_pod_container_port_number] regex: ([^;]+);([^;]+);([^;]+) target_label: __metrics_path__ replacement: /api/v1/namespaces/${1} /pods/http:${2} :${3} /proxy/metrics - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: service_name
Tips: 通过relabel_configs构造 prometheus (endpoints) Role 访问 API Server 的 URL;
标签
默认
构造后
__scheme__https
https
__address__ | 172.16.182.200:8081 |192.168.12.226:6443|__metrics_path__ | /metrics | /api/v1/namespaces/kube-system/pods/http:kube-state-metrics-6477678b78-6qkjg:8081/proxy/metrics |https://10.244.2.10:8081/metrics | https://192.168.12.226:6443/api/v1/namespaces/kube-system/pods/http:kube-state-metrics-6477678b78-6qkjg:8081/proxy/metrics |
Step 6.修改主配置文件完成后进行重启 prometheus Server 容器然后查看启动状态,由图中可以看见监控成功。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 __meta_kubernetes_endpoint_address_target_kind="Pod" __meta_kubernetes_endpoint_address_target_name="kube-state-metrics-6477678b78-6qkjg" __meta_kubernetes_endpoint_node_name="weiyigeek-226" __meta_kubernetes_endpoint_port_name="telemetry" __meta_kubernetes_endpoint_port_protocol="TCP" __meta_kubernetes_endpoint_ready="true" __meta_kubernetes_endpoints_label_app_kubernetes_io_name="kube-state-metrics" __meta_kubernetes_endpoints_label_app_kubernetes_io_version="2.0.0" __meta_kubernetes_endpoints_labelpresent_app_kubernetes_io_name="true" __meta_kubernetes_endpoints_labelpresent_app_kubernetes_io_version="true" __meta_kubernetes_endpoints_labelpresent_service_kubernetes_io_headless="true" __meta_kubernetes_endpoints_name="kube-state-metrics" __meta_kubernetes_namespace="monitor" __meta_kubernetes_pod_annotation_cni_projectcalico_org_podIP="172.16.182.200/32" __meta_kubernetes_pod_annotation_cni_projectcalico_org_podIPs="172.16.182.200/32" __meta_kubernetes_pod_annotationpresent_cni_projectcalico_org_podIP="true" __meta_kubernetes_pod_annotationpresent_cni_projectcalico_org_podIPs="true" __meta_kubernetes_pod_container_name="kube-state-metrics" __meta_kubernetes_pod_container_port_name="telemetry" __meta_kubernetes_pod_container_port_number="8081" __meta_kubernetes_pod_container_port_protocol="TCP" __meta_kubernetes_pod_controller_kind="ReplicaSet" __meta_kubernetes_pod_controller_name="kube-state-metrics-6477678b78" __meta_kubernetes_pod_host_ip="192.168.12.226" __meta_kubernetes_pod_ip="172.16.182.200" __meta_kubernetes_pod_label_app_kubernetes_io_name="kube-state-metrics" __meta_kubernetes_pod_label_app_kubernetes_io_version="2.0.0" __meta_kubernetes_pod_label_pod_template_hash="6477678b78" __meta_kubernetes_pod_labelpresent_app_kubernetes_io_name="true" __meta_kubernetes_pod_labelpresent_app_kubernetes_io_version="true" __meta_kubernetes_pod_labelpresent_pod_template_hash="true" __meta_kubernetes_pod_name="kube-state-metrics-6477678b78-6qkjg" __meta_kubernetes_pod_node_name="weiyigeek-226" __meta_kubernetes_pod_phase="Running" __meta_kubernetes_pod_ready="true" __meta_kubernetes_pod_uid="70037554-7c4c-4372-9128-e9689b7cff10" __meta_kubernetes_service_annotation_kubectl_kubernetes_io_last_applied_configuration="{" apiVersion":" v1"," kind":" Service"," metadata":{" annotations":{" prometheus.io/scrape":" true "}," labels":{" app.kubernetes.io/name":" kube-state-metrics"," app.kubernetes.io/version":" 2.0.0"}," name":" kube-state-metrics"," namespace":" monitor"}," spec":{" clusterIP":" None"," ports":[{" name":" http-metrics"," port":8080," targetPort":" http-metrics"},{" name":" telemetry"," port":8081," targetPort":" telemetry"}]," selector":{" app.kubernetes.io/name":" kube-state-metrics"}}} " __meta_kubernetes_service_annotation_prometheus_io_scrape="true" __meta_kubernetes_service_annotationpresent_kubectl_kubernetes_io_last_applied_configuration="true" __meta_kubernetes_service_annotationpresent_prometheus_io_scrape="true" __meta_kubernetes_service_label_app_kubernetes_io_name="kube-state-metrics" __meta_kubernetes_service_label_app_kubernetes_io_version="2.0.0" __meta_kubernetes_service_labelpresent_app_kubernetes_io_name="true" __meta_kubernetes_service_labelpresent_app_kubernetes_io_version="true" __meta_kubernetes_service_name="kube-state-metrics" __metrics_path__="/metrics" __scheme__="https" job="k8s-endpoint-discover" app_kubernetes_io_name="kube-state-metrics" app_kubernetes_io_version="2.0.0" instance="172.16.182.200:8081" job="k8s-endpoint-discover" kubernetes_namespace="monitor" service_name="kube-state-metrics" up{job="k8s-endpoint-discover" } or go_info{job="k8s-endpoint-discover" }
weiyigeek.top-k8s-endpoint-discover
补充说明: metrics-server 和 kube-state-metrics对比
示例: kube-state-metrics 收集到的节点信息, 如验证指标是否采集成功请求kube-state-metrics的pod ip+8080端口出现以下页面则正常1 2 $ kube_node_info{job="k8s-endpoint-discover" }
kube-state-metrics
2.Node 之服务自动发现 描述: 通过node-exporter采集集群node节点的服务器层面的数据,如cpu、内存、磁盘、网络流量等,当然node-exporter可以独立部署在node节点服务器上但是每次都要进行手动配置添加监控是非常不方便。
流程步骤:
Step 3.Prometheus.yaml 主配置文件添加kubernetes_sd_configs对象使用node级别自动发现;1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 - job_name: 'k8s-nodes-discover' scheme: https tls_config: insecure_skip_verify: true bearer_token_file: /etc/prometheus/conf.d/auth/k8s_prometheuser_token kubernetes_sd_configs: - role: node api_server: 'https://192.168.12.226:6443' tls_config: insecure_skip_verify: true bearer_token_file: /etc/prometheus/conf.d/auth/k8s_prometheuser_token relabel_configs: - target_label: __address__ replacement: 192.168.12.226:6443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1} :9100/proxy/metrics - source_labels: [__meta_kubernetes_service_name] action: replace target_label: service_name - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace
Tips: 通过relabel_configs构造 prometheus (node) Role 访问 API Server 的 URL;
标签
默认
构造后
__scheme__https
https
__address__192.168.3.217:10250
192.168.3.217:6443
__metrics_path__ (node_exporter)/metrics
/api/v1/nodes/uvmsvr-3-217:9100/proxy/metrics
URL
https://192.168.3.217:10250/metricshttps://192.168.3.217:6443/api/v1/nodes/uvmsvr-3-217:9100/proxy/metrics
__metrics_path__ (kubelet)/metrics
/api/v1/nodes/uvmsvr-3-217:10250/proxy/metrics
URL
https://192.168.3.217:10250/metricshttps://192.168.3.217:6443/api/v1/nodes/uvmsvr-3-217:10250/proxy/metrics/cadvisor
__metrics_path__ (advisor)/metrics
/api/v1/nodes/uvmsvr-3-217:10250/proxy/metrics
URL
https://192.168.3.217:10250/metricshttps://192.168.3.217:6443/api/v1/nodes/uvmsvr-3-217:10250/proxy/metrics/cadvisor
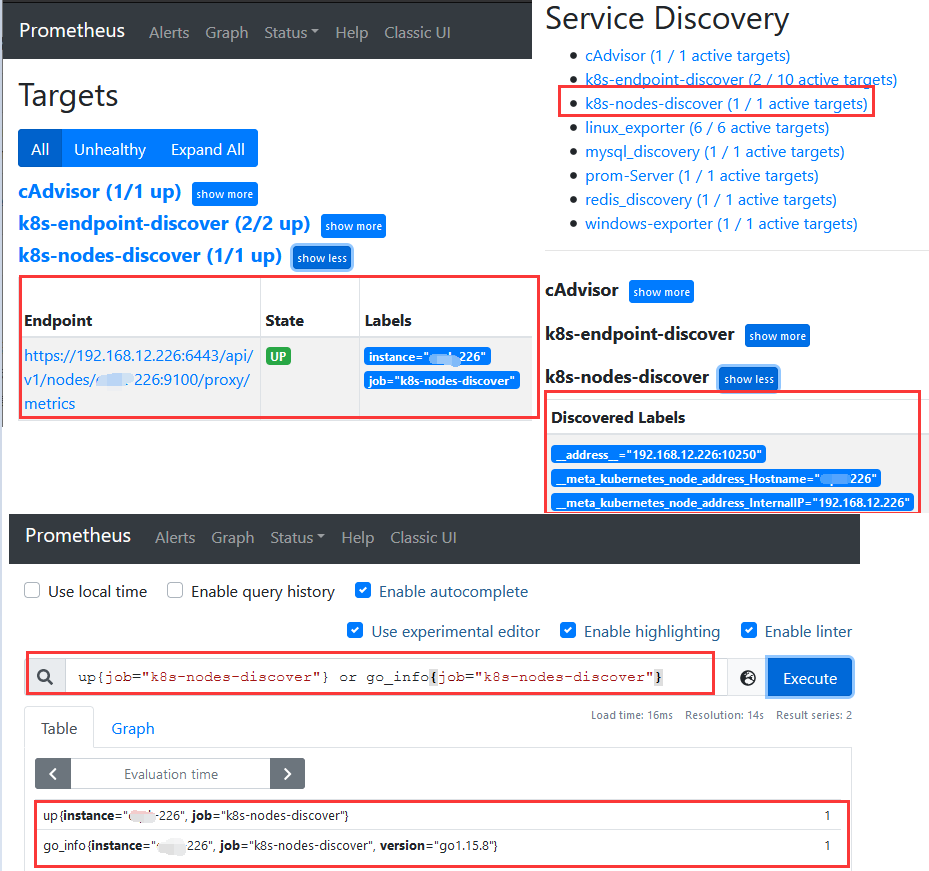
Step 4.重启服务查看监控目标状态以及服务发现是否成功监控。1 2 3 4 5 6 7 8 9 k8s-nodes-discover (1/1 up) Endpoint State Labels Last Scrape Scrape Duration Error https://192.168.12.226:6443/api/v1/nodes/weiyigeek-226:9100/proxy/metrics UP instance="weiyigeek-226" job="k8s-nodes-discover" up{job="k8s-nodes-discover" } or go_info{job="k8s-nodes-discover" }
weiyigeek.top-k8s-nodes-discover-9100
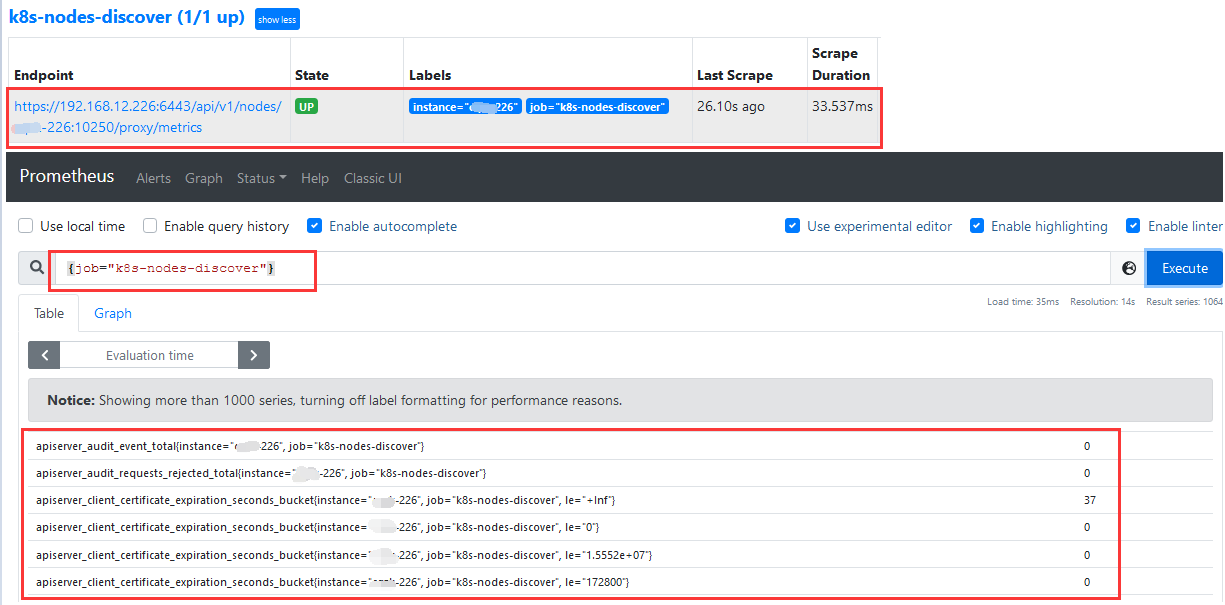
Step 5.此时我们可以将__metrics_path__替换成/api/v1/nodes/${1}:10250/proxy/metrics,如此便采用了kubelet采集拉取监控指标。
weiyigeek.top-k8s-nodes-discover-10250
3.综合实践之(cAdvisor+Kube-state-metrics+Grafana)组合拳方案 描述: Grafana从prometheus数据源读取监控指标并进行图形化,根据其官网提供的众多模板,我们可以针对不同维度的监控指标,我们可以自行选择喜欢的模板直接导入Dashboard id使用。
例如:以下针对于不同场景采用的不同的Dashboard面板:
1.Node 性能监控展示
2.pod 性能监控展示
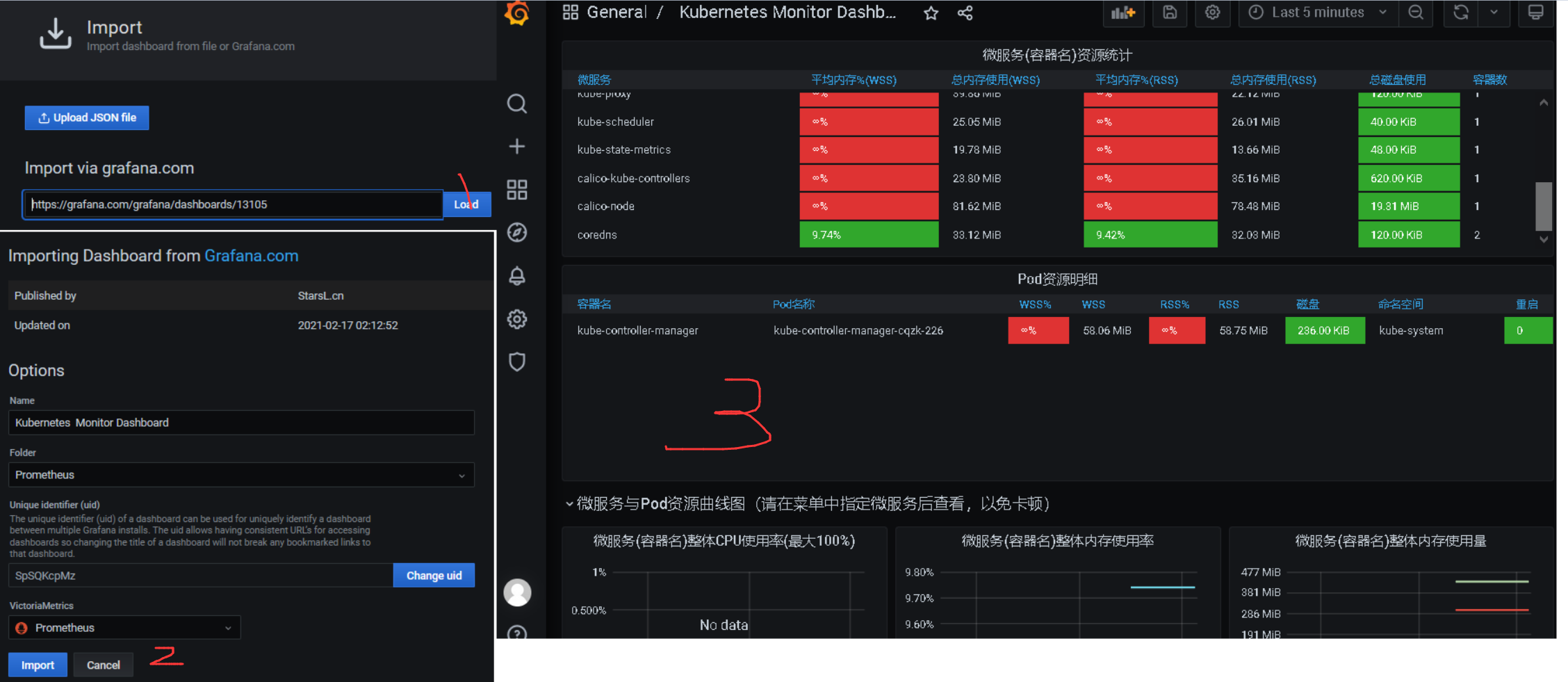
3.K8S 资源性能监控展示(kubernetes资源全面展示!包含K8S整体资源总览、微服务资源明细、Pod资源明细及K8S网络带宽,优化重要指标展示。)
实践目标: 使用cadvisor采集Pod容器相关信息+使用kube-state-metrics采集集群相关信息+使用Grafana将Prometheus采集到的数据进行展示。
流程步骤:
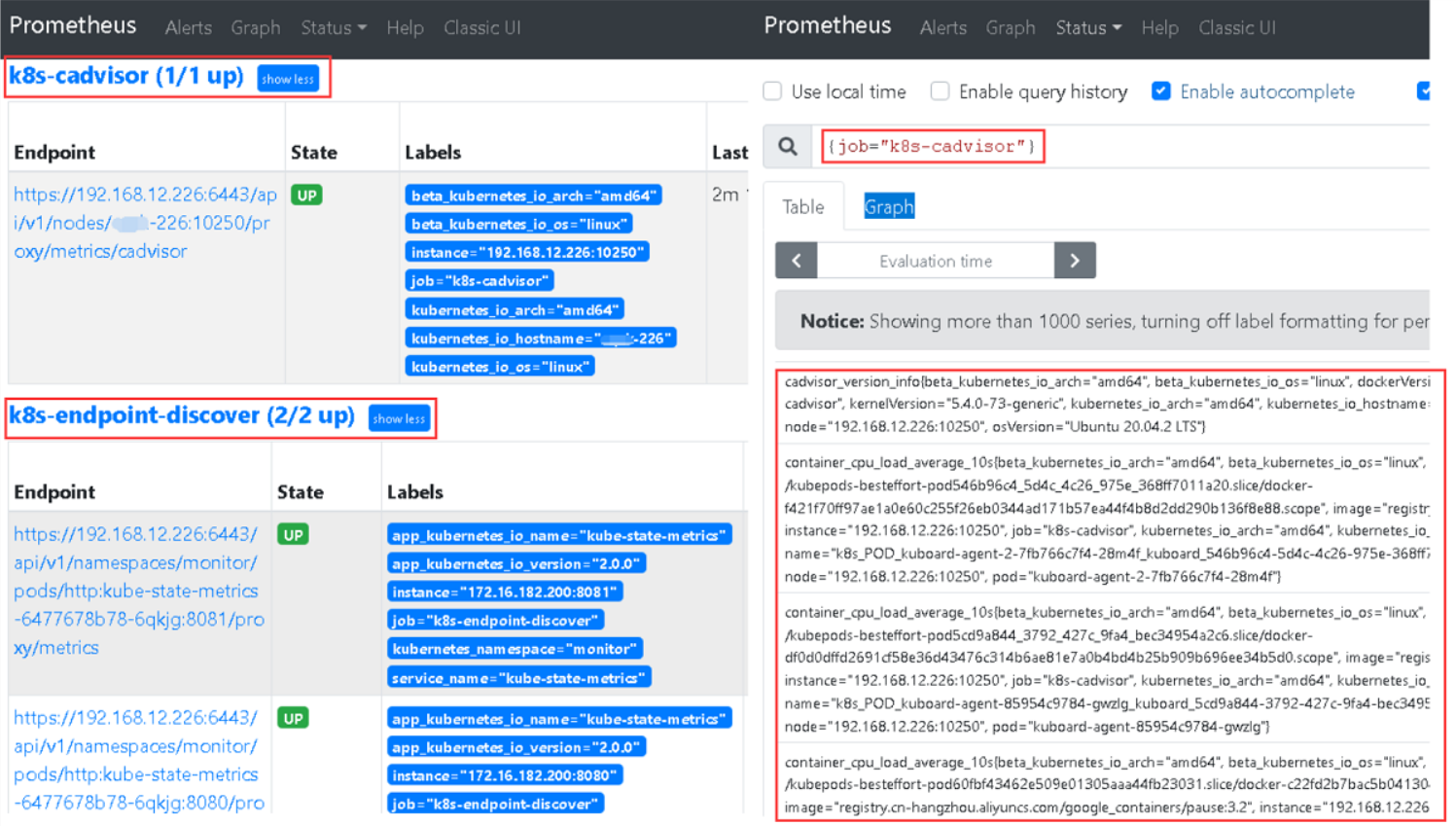
Step 3.重启我们的Prometheus服务并验证服务发现和目标。
weiyigeek.top-k8s-cadvisor
weiyigeek.top-cadvisor+Dashboard
Tips : 通过 Dashboard 模板我们需要自行选择并组合, 灵活有余但规范不足, 我们常常使用grafana专门针对Kubernetes集群监控的插件grafana-kubernetes-app它包括4个仪表板,集群,节点,Pod /容器和部署,但由于其插件作者没有更新维护,所以更多是采用KubeGraf ,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。