
[TOC]
3.ElasticSearch分布式数据分析引擎基础概念与使用
|[TOC]
0x00 基础快速入门
核心概念
索引(Index): 类似于关系型数据中得库(database),一个ES的集群中可以有多个索引,并且每个索引都是一批独立的存储数据,其按照一定的数据结构保存、方便查询。
类型(Type): 类似于关系型数据库中的表格(Table),一个索引中可以有多个类型,每个类型中的数据是一致的。
Tips : 非常注意,在6.x中使用类型,但是在7.x版本中所有索引的类型只有一个叫做
_Doc, 并在8.x的版本里将会彻底移除类型的概念,其目的是提升索引的效率。映射(Mapping): 类似于关系型数据库中定义得结构约束(Schema),用于定义我们想往ES索引里存储的数据结构,是String字符串、还是integer整数、或是Boolean布尔等等
- 文档(Document): 类似于关系型数据库中的行数据(Rows),它是ES中存储数据的最小数据单元,每个文档都能根据数据的结构存储多个字段field,值得注意Field类型是在存储数据时由Mapping映射决定的。
- 字段(Field): 类似于关系型数据库中的列数据(Columns),每个文档都由多个Field组成。
- 集群(Cluster): ES支持分布式集群结构,每个ES进程都属于一个集群,即使只有一个ES进程再启动它也是一个集群,注意不同集群由集群名称进行分开。
- 节点(Node): 每个ES进程都是一个节点,并且每个节点都拥有自己的名称。
- 分片(Shard): 单台机器存储数据量是有限的,而ES可将一个Index索引下的数据划分为多个Shard并存储在不同的机器上,横向扩展以存储更多的数据,而且可以让搜索、分析等操作分配到多个机器上去执行,提升吞吐量金额性能,每个Shard都是一个Lucene Index。
分片复制(Replica): 每台机器都可能会出现宕机的情况,此时Shard上的数据就可能会丢失。因此可以为每个Shard建立多个副本,保证在一个Shard不可用时还可以使用副本且保证数据不丢失、也能提升查询性能。
Tips: 主分片的个数是在建立索引时定下的不能修改默认为5个,而副本切片(Replica)是我们可以随时修改默认是一个,注意为了保证分布式与高可用集群的正常运行,每个分片的主分片和副本分片不能在一台主机上。
- 接近实时(NearReatime-NRT): 当数据写入后一般在1秒左右就可以被客户端调用,基于ES执行搜索和分析可以达到秒级。
工具介绍
描述: ES是支持以及HTTP协议进行REST风格接口访问,一般得我们需要有个工具帮我们发送http请求,该工具常见的是curl英 [kɜːl]、Head插件、Kibana DeveloperTool软件等。
Curl 使用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49# 示例1.获取ES相关信息
curl -XGET "http://10.10.107.225:9200/" -H 'Content-Type: application/json' -H 'Authorization: Basic ZWxhc3RpYzp3ZWl5aTEyMzQ1Ng=='
# {
# "name" : "elk",
# "cluster_name" : "elasticsearch",
# "cluster_uuid" : "R8kofupCROGCAt6WrXT8bQ",
# "version" : {
# "number" : "7.15.0",
# .....
# },
# "tagline" : "You Know, for Search"
# }
# 示例2.新增索引并为索引添加数据
curl -XPUT "http://10.10.107.225:9200/index01/_doc/curl?pretty" -H 'Content-Type: application/json' -H 'Authorization: Basic ZWxhc3RpYzp3ZWl5aTEyMzQ1Ng==' -d '{"name":"WeiyiGeek","age": 100,"hobby":"computer"}'
# {
# "_index" : "index01",
# "_type" : "_doc",
# "_id" : "curl",
# "_version" : 1,
# "result" : "created", # 结果显示
# "_shards" : {
# "total" : 2,
# "successful" : 1,
# "failed" : 0
# },
# "_seq_no" : 0,
# "_primary_term" : 1
# }
# 示例3.获取刚才添加的数据
# 示例2.新增索引并为索引添加数据
curl -XGET "http://10.10.107.225:9200/index01/_doc/curl?pretty" -H 'Content-Type: application/json' -H 'Authorization: Basic ZWxhc3RpYzp3ZWl5aTEyMzQ1Ng=='
# {
# "_index" : "index01",
# "_type" : "_doc",
# "_id" : "curl",
# "_version" : 1,
# "_seq_no" : 0,
# "_primary_term" : 1,
# "found" : true,
# "_source" : {
# "name" : "WeiyiGeek",
# "age" : 100,
# "hobby" : "computer"
# }
# }
Head 插件使用 weiyigeek.top-ES-Plugins-Head
描述: 我们也可以利用ES的Head插件进行数据的相关增删改查。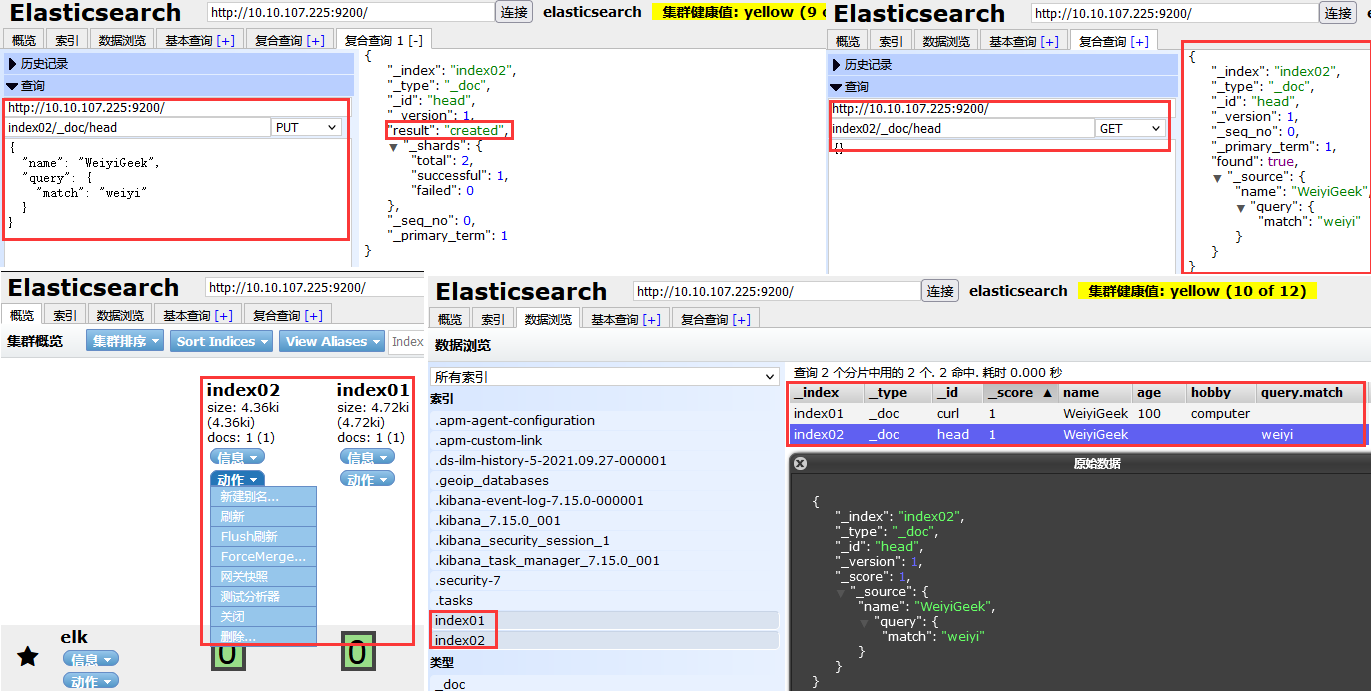
Kibana DeveloperTool 使用
描述: 登陆Kibana后我们可以在左边菜单选择开发工具或者访问http://log.weiyigeek.top:5601/app/dev_tools#/console。打开后Console UI 分为两个窗格:编辑器窗格(左)和响应窗格(右)。使用编辑器键入请求并将它们提交到 Elasticsearch,结果将显示在右侧的响应窗格中。
weiyigeek.top-Kibana
Tips : 非常建议通过按 Enter/Tab 键来进行查询参数补全,它可以有效帮助我们基于请求结构以及索引和类型快速查询。
Tips : 实际上Kibana的控制台也是通过类似于curl与ES交互的。
0x01 基础使用操作
描述: 为了方便学习后续请求演示都基于Kibana的开发工具来验证。
1.索引&文档操作
请求示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
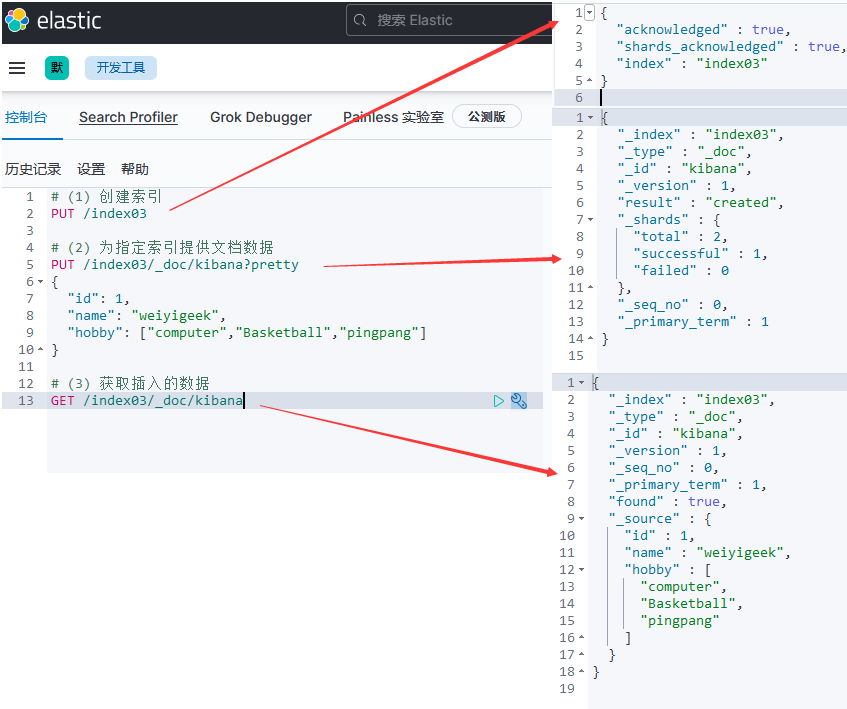
67# (1) 创建索引
PUT /index03
# (2) 为索引提供文档数据
PUT /index03/_doc/kibana?pretty
{
"id": 1,
"name": "weiyigeek",
"hobby": ["computer","Basketball","pingpang"]
}
# (3) 获取指定索引插入的数据
GET /index03/_doc/kibana
# (4) 批量写入索引文档数据
# 如果有许多文档需要索引则我们可以通过API批量提交,使用这种方式比单独提交请求要快得多因为其减少了网络往返,例如下列的数据集合。
PUT /index03/_bulk
{"index":{"_id":"0"}}
{"id":0,"name":"朴乾","job":"c","age":31,"salary":35000,"gender":"female","like":"鲜肉"}
{"index":{"_id":"1"}}
{"id":1,"name":"郝霞","job":"go","age":25,"salary":18000,"gender":"male","like":"大叔"}
# (5) 删除索引的指定文档数据
DELETE /index03/_doc/kibana
# (6) 批量删除索引
DELETE /index02,index01
# (7) 删除数据(单条、多条、清空、所有)
# 7.1 根据主键删除数据:DELETE /索引名称/类型名称/主键编号
DELETE /index09/_doc/LgafeHwBA4hYcZDAvgAo
# 7.2 根据匹配条件删除数据(注意请求方式) : 索引名称/_delete_by_query
POST /index09/_delete_by_query
{
"query":{
"match_phrase":{
"title": "我爱学习"
}
}
}
# 7.3 清空多个索引数据 : 索引名称1,索引名称2/_delete_by_query
POST http://es-server:9200/index01,index02/_delete_by_query?pretty
{
"query": {
"match_all": {}
}
}
# 返回结果
{
"took" : 147, #执行时间,毫秒数
"timed_out": false, #是否超时
"total": 119, #处理文档条数
"deleted": 119, #删除文档条数
"batches": 1, # by_query回调的响应次数
"version_conflicts": 0, #by_query命中的版本冲突数
"noops": 0, #在by_query方式下为0。
"retries": {
"bulk": 0, #整体重试次数
"search": 0 #查询重试次数
},
"throttled_millis": 0, # 每秒休眠的时间,已符合requests_per_second的设置
"requests_per_second": -1.0, # 每秒最大有效操作数
"throttled_until_millis": 0, # 在by_query方式为0,api方式下标识开始的毫秒时间
"failures" : [ ] #如果进程中有任何不可恢复的错误,则返回失败数组。
# 如果这是非空的,那么请求会因为这些失败而中止。按查询删除是使用批处理实现的,任何失败都会导致整个进程中止,但当前批处理中的所有失败都会收集到数组中。您可以使用conflicts选项来防止重新索引在版本冲突时中止。
}
Tips : 当文档数据过多时不建议使用Kibana工具进行调试提交,而建议使用curl指定json文件提交。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20tee data.json<<'EOF'
{"index":{"_id":"2"}}
{"id":2,"name":"陈哲","job":"c","age":22,"salary":25000,"gender":"female","like":"青年"}
{"index":{"_id":"3"}}
{"id":3,"name":"曹洋","job":"html","age":25,"salary":30000,"gender":"female","like":"御姐"}
{"index":{"_id":"4"}}
{"id":4,"name":"兰刚","job":"go","age":24,"salary":10000,"gender":"female","like":"青年"}
{"index":{"_id":"5"}}
{"id":5,"name":"叶尚青","job":"java","age":34,"salary":14000,"gender":"male","like":"青年"}
{"index":{"_id":"6"}}
{"id":6,"name":"肖旭伟","job":"python","age":32,"salary":22000,"gender":"female","like":"鲜肉"}
{"index":{"_id":"7"}}
{"id":7,"name":"韩少云","job":"html","age":45,"salary":20000,"gender":"female","like":"御姐"}
{"index":{"_id":"8"}}
{"id":8,"name":"刘巧珍","job":"java","age":38,"salary":15000,"gender":"female","like":"鲜肉"}
EOF
curl -XPOST "http://10.10.107.225:9200/index03/_bulk?pretty" -H 'Content-Type: application/json' -H 'Authorization: Basic ZWxhc3RpYzp3ZWl5aTEyMzQ1Ng==' --data-binary "@data.json"
curl -XPOST "http://10.10.107.225:9200/index03/_bulk?pretty" -H 'Content-Type: application/json' -H 'Authorization: Basic ZWxhc3RpYzp3ZWl5aTEyMzQ1Ng==' --data-binary "@books.json"
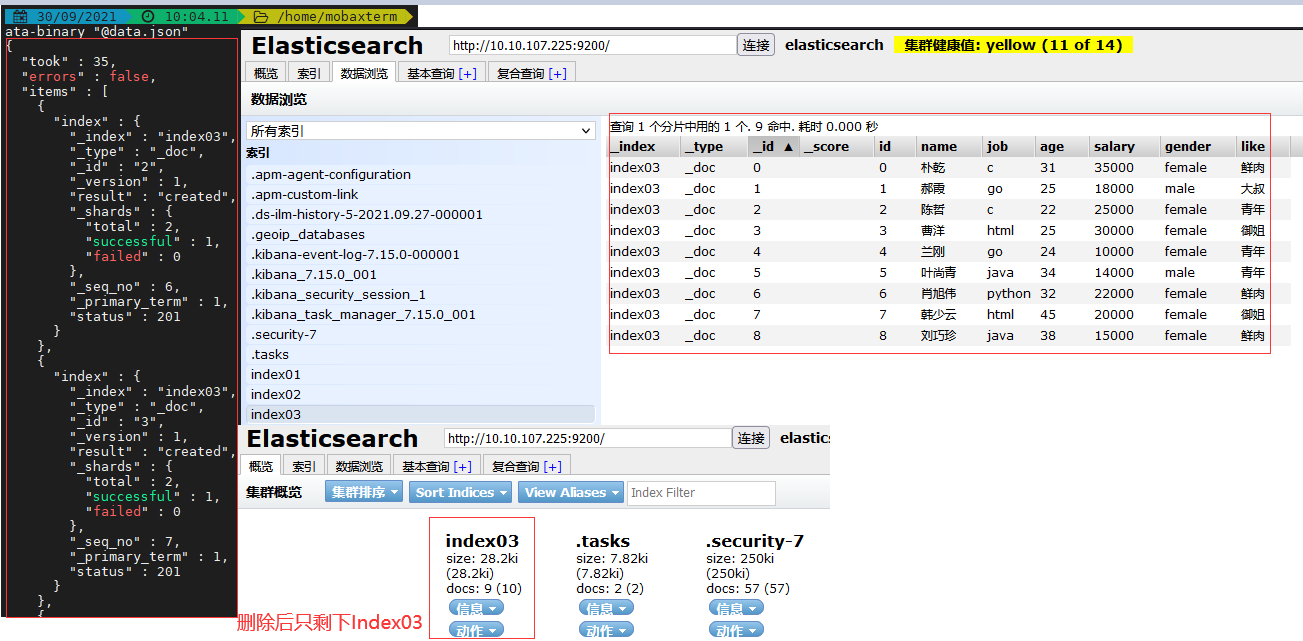
weiyigeek.top-索引操作
Tips : 非常注意上面在数据集合的末尾有个回车换行,否则报The bulk request must be terminated by a newline [\\n],状态400错误。
Tips : 非常注意采用POST进行请求并 –data-binary 参数指定数据文件前有@
2.查询操作
描述: ES提供了非常多的搜索功能方法,我们可以从多维度搜索所需的数据,所有查询条件都是以JSON格式存在的。
Tips : 值得注意,如果查询返回的数据条数超过十条,则默认只会选择十条进行返回, 如果你想改变他请在请求中设置size和from字段(与query字段同级)。1
2# size 字段: 返回查询结果的最大条数。(全局有效)
# from 字段: 从第几条进行显示。(全局有效)
(1) match_all - 所有匹配
描述: match_all 它是最简单的没有任何查询约束的查询条件,它就是将当前的所有文档数据查询出来。
(2) term - 单分词匹配
描述:term (词项)在文档数据写入到ES时进行分词计算的一个基础单位,在查询时指定字段如果拥有该词项就会被查询和显示出来。
Tips : 什么是分词计算?
分词计算是将一个字符串文本按照分词计算器的逻辑拆分的过程。例如当
{"name": "唯一极客"}当写入ES时将拆分为”唯”、”一”、”极”、”客”四个词项,ES默认计算分词是将英文按照词组划分(如Hello)而中午则是按照字进行划分。当然我们也可以指定拆分逻辑。
所以当针对词项term查询时,返回的文档是包含查询提供的确切词项进行的,如果文档没有包含这个词项便不会被查询到和显示。
Tips : 值得注意,由于分词计算的存在,所以避免使用Term查询做全文的文本检索,例如:1
{"query": {"term": {"author": {"value": "929 Eldert Lane","boost": 2 }}}
(3) range
描述: range 返回指定字段范围内所包含的文档数据,你可以为该范围指定一个上限与下限。
条件运输符: gt(大于) / lt(小于) / gte(大于等于) / lte(小于等于)
(4) exists
描述: exists 返回包含某些指定的查询字段,包含则返回不包含则不返回文档数据。
Tips : 值得注意,文档的字段不能存在的原因有如下几种可能写入索引字段值在json中是null或者[]/字段设置了"index":false的映射导致不会写入到索引中、字段设置了ignore_above当超出长度不会写入到索引中1
{"name":"weiyigeek","age":"null","hobby":"[]"}
(5) bool
描述: bool 是由多个子查询组成的布尔查询,您可以定义一个或者多个子查询它会影响最终结果的逻辑关系。
布尔查询四种逻辑关系值:
- must : 布尔结果必须是must子条件的查询子集。
- must_not : 布尔结果必须不是must_not子条件查询的子集。
- should : 查询结果可能是或者不是这个条件的子集,其唯一的作用就是影响最终结果相关性的评分计算(上升评分),一般得should和must同时使用。
- filter : 查询结果必须是该条件的子集,即满足子条件的结果其评分将被忽略,但是其他子条件的查询评分不会因为filter存在而影响。
子集概念: 条件结果算子集,空集也算是子集。
(6) match - 多字分词匹配
描述: match 匹配查询会返回我们提供的查询条件、文本,日期,布尔,数字相匹配的文档数据。
Tips : match与Term查询不同的是match查询会在查询之前对我们所提供的数据先进行分词计算,默认得只有指定字段中匹配到其中一个词便会被显示。
实例演示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167# (1) match_all : 最简单的没有任何查询约束的查询条件,它就是将当前的所有文档数据查询出来。
# 指定index03索引采用_search方法。
GET /index03/_search
{"query":{"match_all": {}}}
# (2) term : (词项)在文档数据写入到ES时进行分词计算的一个基础单位,在查询时指定字段如果拥有该词项就会被查询和显示出来。
# boost 属性: 该属性使得每个查询结果的文档数据评分会乘以该属性值从而返回`_score`字段所保存的值。(局部)
# 例如,搜索author字段带有宋的字,并将_score*2最后返回1~20条数据
GET /index03/_search
{
"query": {
"term": {
"author": {
"value": "宋",
"boost": 2
}
}
}
, "size": 20
, "from": 0
}
# (3) range : 返回指定字段范围内所包含的文档数据,你可以为该范围指定一个上限与下限。
# 条件符号: gt(大于) / lt(小于) / gte(大于等于) / lte(小于等于)
# 例如,搜索price价格区间在20~40之间的文档数据。
GET /index03/_search
{
"query": {
"range": {
"price": {
"gte": 20,
"lte": 40
}
}
}
}
# (4) exists :返回包含某些指定的查询字段,包含则返回不包含则不返回文档数据。
GET /index03/_search
{
"query": {"exists": {"field": "price"}}
}
# (5) match : 匹配查询会返回我们提供的查询条件、文本,日期,布尔,数字相匹配的文档数据。
# 与Term查询不同的是match查询会在查询之前对我们所提供的数据先进行分词计算,默认得只有指定字段中匹配到其中一个词便会被显示。
# 只要Type类型包含为`大学教材`其中一个词的文档数据(便会被查询显示)。查询结果550条
GET /index03/_search
{"query": {"match": {"type": "大学教材"}}}
# 只显示Type类型为`数学`的文档数据(包含多一个或者少一个词都不被查询显示)。查询结果48条
GET /index03/_search
{"query": {"match": {"type": {"query": "数学","operator": "and"}}},"from": 45}
# (6) bool : 是由多个子查询组成的布尔查询
# - must 逻辑关系值: 当布尔查询中只有一个字条件match时与其单独使用match查询的结果一致。结果为8条
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}}
]
}}}
# 两个子条件都是must关系,结果即为两个match的交集。
# author(包含词组的)与type包含(大)同时满足的结果为2条
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}},
{
"term": {
"type": {"value": "大"}
}
}
]
}}}
# author与type字段分别分包其词组交集结果为4条。
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}},
{
"match": {
"type": "大学"
}
}
]
}}}
# - must_not :author包含(宋、天、佑)词组与type字段不包含("大","学")集合结果为4条。
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}}
],
"must_not": [
{"match": {
"type": "大学"
}}
]
}}}
# - should 与 must 联合使用,影响其评分匹配,越精确其评分越高。结果为8条,例如"type" : "大学教材"和"author" : "宋天佑"评分最高
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}}
],
"should": [
{"match": {
"type": "大学"
}}
]
}}}
# - filter 单独使用影响其评分,匹配到的评分_score都为0.0,结果为475条
GET /index03/_search
{"query": {"bool": {
"filter": [
{"match": {
"type": "大学"
}}
]
}}}
# filter 与 must 联合使用,条件匹配越精确其评分越高。结果为4条,仍然是"type" : "大学教材"和"author" : "宋天佑"评分最高,此处的评分_score不在为0.0.因为受到must逻辑条件的影响
GET /index03/_search
{"query": {"bool": {
"must": [
{"match": {
"author": {
"query": "宋天佑"
}
}}
],
"filter": [
{"match": {
"type": "大学"
}}
]
}}}
(7) match_phrase - 完全匹配短语
描述: match_phrase 其可以精准的匹配带有我们制定的关键字短语默认并不会像match进行分词后匹配。
示例演示:1
2
3
4
5
6
7
8
9
10# 例如此时有两个文档数据hobby分别为面向过程编程语言、编程语言
GET /logstash-userinfo/_search
{
"query": {
"match_phrase": {
"hobby": "过程编程"
}
}
}
# 则仅仅会显示 面向过程编程语言 的该条数据
(7) match_phrase_prefix - 完全匹配以指定前缀短语
描述: match_phrase_prefix 其可以完全匹配前缀短语查询,例如以下搜索返回包含以开头的短语的文档 quick brown f在里面 message 字段里。
示例演示: 此搜索将匹配 message 字段里为 quick brown fox 或者 two quick brown ferrets 但不是 the fox is quick and brown.1
2
3
4
5
6
7
8
9
10GET /_search
{
"query": {
"match_phrase_prefix": {
"message": {
"query": "quick brown f"
}
}
}
}
(8) multi_match - 匹配多个字段中的短语
描述:multi_match 可以对多个字段进行配置,只要任意一个字段满足则该文档局满足。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28GET /index09/_search
{
"query": {
"multi_match": {
"query": "我爱学习网络安全技术",
"fields": ["title","hobby"],
"type": "best_fields",
"tie_breaker": 0.3
}
}
}
# Type 字段可选参数
# - best_fields : 完全匹配的文档占的评分比较高
# - most_fields : 越多字段匹配的文档评分越高
# - cross_fields :词条的分词词汇是分配到不同字段中
# tie_breaker 字段文档评分次数, 文档评分乘以0.3的系数
# 返回结果
"_score" : 5.139209,
"_source" : {
"title" : "我爱学习网络安全技术,例如安全攻防",
"hobby" : "网络安全技术"
}
"_source" : {
"title" : "我爱学习计算机技术,例如ES/Kibana",
"hobby" : "计算机技术"
}
3.映射操作
(1) Mapping 概念
描述: 映射(Mapping)是ES中决定了文档如何存储、如何生成索引、如何定义字段的各种类型的过程。其实它类似于我们在创建数据库表时定义有那些字段以及字段类型。在ES中有两种映射一种是动态映射(Dynamic Mapping),一种是静态映射(Explicit Mapping),它们拥有自己的特点如动态映射可以根据索引数据自动设置字段类型,而静态映射需要采用手动指定字段类型(一般只在特殊需求时使用)。
TIPS: 从7.0开始ES逐渐丢弃Type类型的概念,在8.x版本中将彻底丢弃。
(2) Mapping 设置
2.1 Dynamic Mapping(动态映射)
描述: ES通过索引文档自动添加新字段,您可以向顶级映射、内部对象和嵌套字段添加字段类型。总得来说动态映射你无需做任何修改操作,它会自动识别您添加的字段并为其数据设置类型。
实际操作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122# 当创建一个索引并为随意添加一个字段,它将会动态映射。
# 1.创建索引
PUT /index04
# {
# "acknowledged" : true,
# "shards_acknowledged" : true,
# "index" : "index04"
# }
# 2.添加索引文档数据(此处我们添加了多种数据类型进行了演示)
PUT /index04/_doc/info
{
"name": "WeiyiGeek",
"age": 25,
"sex": true,
"birthday": "2021-01-01 13:00",
"hobby": ["computer","Network"],
"salary": 20000.0,
"ip": "192.168.10.251",
"location": {
"lat": 29.511864116937787,
"lon":106.57363404248045
}
"address": "重庆市渝北区花卉园xx小区xx栋x号-12",
"employed_time": "2020-01-05"
}
# {
# "_index" : "index04",
# "_type" : "_doc",
# "_id" : "info",
# "_version" : 1,
# "result" : "created",
# "_shards" : {
# "total" : 2,
# "successful" : 1,
# "failed" : 0
# },
# "_seq_no" : 0,
# "_primary_term" : 1
# }
# 3.查看索引以及索引中字段映射信息
GET /index04
GET /index04/_mapping
# 得到的结果就是动态Mapping映射生成的结构。
# {
# "index04" : {
# "mappings" : {
# "properties" : {
# "address" : {
# "type" : "text",
# "fields" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "age" : {
# "type" : "long"
# },
# "birthday" : {
# "type" : "text",
# "fields" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "hobby" : {
# "type" : "text",
# "fields" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "ip" : {
# "type" : "text",
# "fields" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "location" : {
# "properties" : {
# "lat" : {
# "type" : "float"
# },
# "lon" : {
# "type" : "float"
# }
# }
# },
# "name" : {
# "type" : "text",
# "fields" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "salary" : {
# "type" : "float"
# },
# "sex" : {
# "type" : "boolean"
# },
# "employed_time" : {
# "type" : "date"
# },
# }
# }
# }
# }
动态Mapping映射生成的基本结构(JSON 字符串):1
2
3
4
5
6
7
8
9{
"index04" : {
"mappings" : {
"properties" : {
"字段对应的映射结构": "结构的值"
}
}
}
}
动态Mapping映射自动分字段生成的结构分类说明:
- 字符串类型: 在文档索引数据中上述是字符串类型的字段有
name,birthday,hobby,ip,address,它们动态映射的结构是一致的。1
2
3
4
5
6
7
8
9"name" : { // 字段名称,其后{}包含的内容就是描述这个字段在映射中的结构。
"type" : "text", // 字段类型,每个字段必须包含一个类型的属性。
"fields" : { // 字段扩展属性,例如此处扩展了该字段keyword类型
"keyword" : { // 表示当前字符串既拥有text特点也拥有keyword的特点
"type" : "keyword", // 字段扩展类型
"ignore_above" : 256 // 表示当该字段值长度超过256时,keyword扩展类型将消失。
}
}
} - 整数类型: 如age字段其类型就是long,所以整数默认映射的是long类型,但是也可能为integer类型。
1
2
3"age" : {
"type" : "long"
} - 浮点数类型: 如salary、location.lon字段其类型就是float,还可以是Double类型
1
2
3"salary" : {
"type" : "float"
} - 日期类型: 如employed_time字段其类型就是date日期类型,默认的日期格式yyyy-MM-dd
1
2
3"employed_time" : {
"type" : "date"
}, 布尔类型: 如sex字段其类型就是布尔类型,其值传入时只有true或者false。
1
2
3"sex" : {
"type" : "boolean"
}对象类型: 此处location字段为对象类型,其包含properties属性,来指定子字段的类型,如lat(纬)、lon(经)其属性为浮点数类型。
1
2
3
4
5
6
7
8
9
10"location" : {
"properties" : {
"lat" : {
"type" : "float"
},
"lon" : {
"type" : "float"
}
}
}
Q: Text 和 keyword 类型有何区别?
答: 它们相同点都是可以表示字符串,而text类型会被分词器计算(默认使用索引分词器),而Keyword不会被计算分词。例如针对于姓名名称、邮箱地址、ID值、身份证、url地址做分词是无意义的。但是我们可以通过为其加上字段扩展keyword属性来使其支持分词计算。
差异查看: 验证text与keyword两种不同类型的区别1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# (1) text 类型
GET /index04/_search
{
"query": {
"term": {
"address": {
"value": "重"
}
}
}
}
# (2) keyword 类型: 由于keyword保存的是文本整体的字符串,所以必须输入完整才行查询到
GET /index04/_search
{
"query": {
"term": {
"address.keyword": {
"value": "重庆市渝北区花卉园xx小区xx栋x号-12"
}
}
}
}
2.2 Explicit Mapping(静态映射)
描述: 当某些特殊场景需要我们自己在创建索引时手动指定mapping或者是在一个已存在的索引中添加Mapping,此时这种方式就是静态映射。
操作实例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102# 1.创建索引时添加mapping(方法1)
# 注意email类型本身就是keyword无需在查询时添加email.keyword
PUT /index05
{
"mappings": {
"properties": {
"email": {
"type": "keyword"
}
}
}
}
# 2.查看手动创建的静态映射 (返回信息)
GET /index05/_mapping
# {
# "index05" : {
# "mappings" : {
# "properties" : {
# "email" : {
# "type" : "keyword"
# }
# }
# }
# }
# }
# 3.批量插入几条数据演示(此时将除去已经设置过mapping的email,其它的字段将采取自动映射,设置其类型)
PUT /index05/_bulk
# {"index":{"_id":"0"}}
# {"id":0,"name":"朴乾","job":"c","age":31,"salary":35000,"gender":"female","like":"鲜肉","email": "master@weiyigeek.top"}
# {"index":{"_id":"1"}}
# {"id":1,"name":"郝霞","job":"go","age":25,"salary":18000,"gender":"male","like":"大叔","email": "hao@weiyigeek.top"}
# {"index":{"_id":"2"}}
# {"id":2,"name":"陈哲","job":"c","age":22,"salary":25000,"gender":"female","like":"人妖","email": "cheng@weiyigeek.top"}
# {"index":{"_id":"3"}}
# {"id":3,"name":"曹洋","job":"html","age":25,"salary":30000,"gender":"female","like":"御姐","email": "cao@weiyigeek.top"}
# 4.查询数据(此处email必须指定完整的邮箱地址才能查询得到)
GET /index05/_search
# {"query": {
# "term": {
# "email": {
# "value": "master@weiyigeek.top"
# }
# }
# }}
# 5.对创建索引之后单独添加Mapping静态映射,直接添加properties属性 (方法2)
PUT /index05/_mapping
{
"properties": {
"address": {
"type": "text"
}
}
}
# {
# "acknowledged" : true
# }
# 6.添加address字段到已存在文档数据中
PUT /index05/_bulk
{"index":{"_id":"0"}}
{"id":0,"name":"朴乾","job":"c","age":31,"salary":35000,"gender":"female","like":"鲜肉","email": "master@weiyigeek.top","address": "重庆市渝北区花卉园街道"}
{"index":{"_id":"1"}}
{"id":1,"name":"郝霞","job":"go","age":25,"salary":18000,"gender":"male","like":"大叔","email": "hao@weiyigeek.top","address": "重庆市沙坪坝区小龙坎街道"}
# 7.单独或者多个filed字段查看 (以逗号分隔)
GET /index05/_mapping/field/email,address,gender.keyword
# {
# "index05" : {
# "mappings" : {
# "address" : {
# "full_name" : "address",
# "mapping" : {
# "address" : {
# "type" : "text"
# }
# }
# },
# "gender.keyword" : {
# "full_name" : "gender.keyword",
# "mapping" : {
# "keyword" : {
# "type" : "keyword",
# "ignore_above" : 256
# }
# }
# },
# "email" : {
# "full_name" : "email",
# "mapping" : {
# "email" : {
# "type" : "keyword"
# }
# }
# }
# }
# }
Tips : 当在Kibana中查询其索引别名时(alias),会显示如下警告,#!此请求访问为系统索引保留名称的别名:[.kibana_7.15.0, .kibana_task_manager, .kibana_task_manager_7.15.0, .security, .kibana],但在未来的主要版本中,将不允许直接访问系统索引及其别名1
2
3
4
5{
"index04" : {
"aliases" : { }
}
}
4.设置操作
描述: 每个Index(索引)都有一个Setting属性,它可以对index设置某些值。并且设置时也有动态索引与静态索引之分。
- 静态索引: 索引创建后不可修改的值。
- 动态索引: 动态索引在使用时可以修改,如分片和副本
(1) shards 分片
描述: 为了可以让一个索引文件行程并行读写、提升查询效率,每个索引都有一个设置的属性叫做分片,分片被存储到多个节点之中,并且为了保证集群的高可用还设置了副本数量。
Tips: 在7.x版本中索引的分片默认为1,你可以通过ES的Head插件查看到一个索引拥有一个分片(主从分片)。
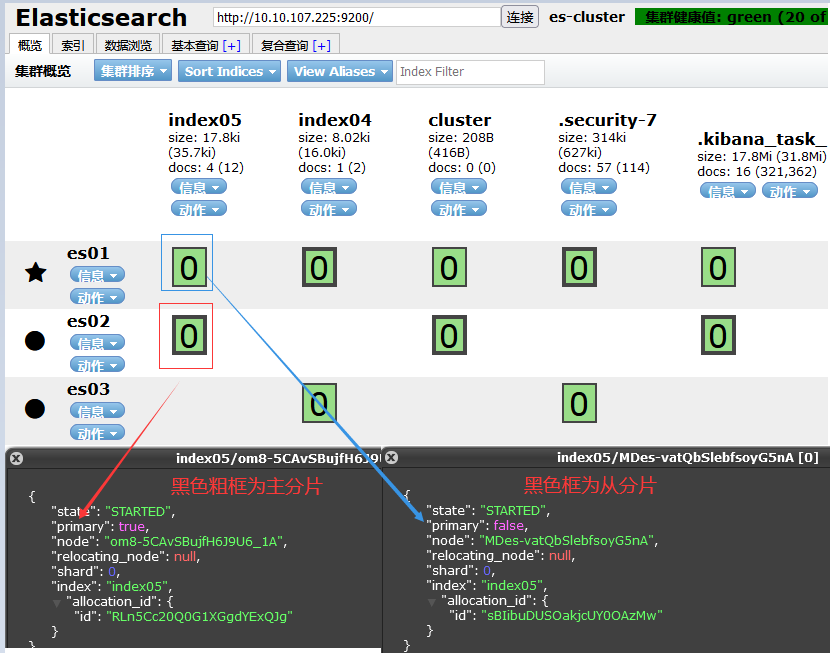
weiyigeek.top-索引分片数
Tips: 那有童鞋可能要问了我们可以自己配置分片的个数吗?答案是肯定的我们可以在elasticsearch.yml中修改index.number_of_shards来决定分片个数。
(2) replicas 副本
描述: 为了保证索引的每一个分片的高可用,不会因为部分分片而导致整个索引丢失数据,此时我们可以引入副本的概念及其配置,每一个分片默认都是有一个副本数,副本的设置是动态的,所以我们可以对一个正在使用的索引修改他的副本数量以及属性名称:index.number_of_replicas
实践验证:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34# 1.指定索引的分片与副本数查看
GET /index05/_settings
# 2.新增索引的分片和副本个数(3分片、2副本)
PUT /index06
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
# 返回值
# {
# "acknowledged" : true,
# "shards_acknowledged" : true,
# "index" : "index06"
# }
# 分片数与副本数
#"number_of_shards" : "3",
#"number_of_replicas" : "2",
# 3.设置已存在的索引分片副本数(不能设置分索引的分片数)
PUT /index06/_settings
{
"index": {
"number_of_replicas": 5
}
}
# 返回: { "acknowledged" : true }
# 4.再次查看我们创建的index06索引的分片与副本数查看
GET /index06/_settings
#"number_of_shards" : "3",
#"number_of_replicas" : "3",
Tips: 如要指定分片请在创建索引前指定,在创建后无法指定分片。
Tips: 主分片与从分片通常不会放在同一个节点之上,同时从分片也不会放在一个节点。

weiyigeek.top-创建分片数与副本数
Tips : 分片数与副本数计算方式,如上图所示我们设置三分片、三副本数。
三分片(
主分片运行的节点): es01 / es02 / es03
三副本(除去了012三个主分片之外的从分片): es02 / es03 / unassigned (无节点可以被分配了)
0x02 进阶使用操作
1.分词器
基础概念
描述: ES中为了方便查询以及提供多维度的查询功能,对存储在索引中的文档进行分词计算。但由于文本内容不同、类型不同、语言的不同其分词计算逻辑是不一样的,同时我们可以采用ES自带的分词或者采用第三方的分词器,以达到自定义分词的效果。
文本分析使得ES能够执行全文搜索,其搜索返回的所有相关结果(例如模糊匹配、语义匹配等)而不仅仅是精确匹配。
例子: 如果您希望搜索”王者荣耀”字符串时,返回的文档中包含”王者”、”荣耀”和”王者荣耀”的文档,还可能希望包含相关”王”或”者”的文档。
ES的每次分词都会经过以下两个过程步骤。
- Tokenization : 将文本拆分为一小块一小块(每块包含的内容称为Token),通常情况下一个Token代表着一个词语。
- Normalization : 词条允许在单个术语上进行匹配,但每个标记仍然是字面上匹配的,此时我们可以通过该操作流程,将词条规范化标记,使之你不仅能使用精确的匹配收缩,还可以使用相关性搜索查询。
Tips: 上面说到词条允许在单个术语上进行匹配,但每个标记仍然是字面上匹配的,这将会导致如下结果
- a : 当搜索Quick时并不会匹配quick(大小写敏感)
- b : 当搜索fox时并不会匹配foxex,虽然它拥有相同的词根。
- c : 当搜索jumps时并不糊匹配Leaps,它们不同根但同义。
分词类别
描述: 为了应对不同的分词计算逻辑,ES中使用底层的不同分词器.
Standard Analyzer
英 [ˈænəlaɪzə]: ES默认分词器,该标准分词器应对多种不同的语言文本环境,其按照词进行切分、支持多语言、大小写、可以删除大多数标点符号、小写术语,并支持删除停止词。Simple Analyzer: 简单分词器,按照特殊字符分割而非字母切分,当遇到不是字母的字符时将文本分解为term处理(以特殊字符进行分割).
Whitespace Analyzer: 空白分词器,按照空白字符作为分隔符,即当遇到任何空白字符时,空白分词器将文本划分称为Term。
Stop Analyzer: 类似于Simple Analyzer 但与之相比Simple Analyzer 支持删除停止字、停止词指语气、助词等修饰性词语,如
the an is等。
操作演示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135# 分词器分析测试验证
## 1.Standard Analyzer
# - 中文 (注意其会删除特殊符号)
POST /_analyze
{
"text": "空想千万遍,不如做一遍",
"analyzer": "standard"
}
# 返回结果:
# {
# "tokens" : [
# {
# "token" : "空",
# "start_offset" : 0,
# "end_offset" : 1,
# "type" : "<IDEOGRAPHIC>",
# "position" : 0
# },
# ..... [想,千,万,遍,不,如,做,一] ....
# {
# "token" : "遍",
# "start_offset" : 10,
# "end_offset" : 11,
# "type" : "<IDEOGRAPHIC>",
# "position" : 9
# }
# ]
# }
# - 英文
POST /_analyze
{
"text": "This is a analyzer demo!",
"analyzer": "standard"
}
# 返回结果(简单化展示): [This,is,a,analyzer,demo]
## 2.Simple analyzer
POST /_analyze
{
"text": "空想千万遍,不如做一遍!",
"analyzer": "simple"
}
# 返回结果:
# {
# "tokens" : [
# {
# "token" : "空想千万遍",
# "start_offset" : 0,
# "end_offset" : 5,
# "type" : "word",
# "position" : 0
# },
# {
# "token" : "不如做一遍",
# "start_offset" : 6,
# "end_offset" : 11,
# "type" : "word",
# "position" : 1
# }
# ]
# }
POST /_analyze
{
"text": "This#_is*a^demo!",
"analyzer": "simple"
}
# 返回结果(简单化展示): [This,is,a,demo]
## 3.Whitespace analyzer
POST /_analyze
{
"text": "Weiyi Geek",
"analyzer": "whitespace"
}
# 返回结果(简单化展示):[Weiyi,Geek]
## 4.Stop analyzer
POST /_analyze
{
"text": "The an is bone.",
"analyzer": "stop"
}
# {
# "tokens" : [
# {
# "token" : "bone",
# "start_offset" : 10,
# "end_offset" : 14,
# "type" : "word",
# "position" : 3
# }
# ]
# }
# 在此示例中,我们将停止分析器配置为使用指定的单词列表作为停止词:
PUT index08
{
"settings": {
"analysis": {
"analyzer": {
"my_stop_analyzer": {
"type": "stop",
"stopwords": ["my", "name", "is"]
}
}
}
}
}
# 使用配置的指定停止分析器单词列表进行分词。
POST /index08/_analyze
{
"analyzer": "my_stop_analyzer",
"text": "Hello,my name is WeiyiGeek"
}
# {
# "tokens" : [
# {
# "token" : "hello",
# "start_offset" : 0,
# "end_offset" : 5,
# "type" : "word",
# "position" : 0
# },
# {
# "token" : "weiyigeek",
# "start_offset" : 17,
# "end_offset" : 26,
# "type" : "word",
# "position" : 4
# }
# ]
# }
2.热词配置
描述: ES的内置分词器可以处理常见的通用场景,而针对于某些场景还需要特点的分词器插件进行实现。
Tips : 例如,对于中文的分词常用的是lk分词器(插件),可以让我们自行的进行扩展分词词语。
IK分析插件将Lucene IK分析器集成到elasticsearch中,支持自定义字典, 项目地址: https://github.com/medcl/elasticsearch-analysis-ik
安装并配置LK分词器
(1) 下载安装解压lk插件(注意其与ES的对应版本一致):1
2
3
4
5
6
7
8# optional 1 - download pre-build package from here
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.2/elasticsearch-analysis-ik-7.15.0.zip
mkdir ${ES_HOME}/plugins/ik
# optional 2 - use elasticsearch-plugin to install ( supported from version v5.5.1 - 建议先将zip然后再本地指定安装):
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.15.0/elasticsearch-analysis-ik-7.15.0.zip
# NOTE: replace 6.3.0 to your own elasticsearch version
(2) 上传到ES各个服务器节点之中,并将其解压到ES家目录下的plugins/目录,之后重启ES服务即可,如上面的两种安装方式。
systemctl restart elasticsearch && systemctl status elasticsearch
Tips : 注意多个ES节点的集群中所有节点都需要配置lk分词器否则计算将会报错。
Tips :如果最新的lk版本与您ES版本有差异,此时是不能运行的,利用一个择中的选择(掩耳盗铃法)直接更改配置lk版本,如7.14.2->7.15.0。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37# 目录结构
# /usr/local/elasticsearch-7.15.0/plugins/lk$ tree
# .
# ├── commons-codec-1.9.jar
# ├── commons-logging-1.2.jar
# ├── config
# │ ├── extra_main.dic # 字典文件
# │ ├── extra_single_word.dic
# │ ├── extra_single_word_full.dic
# │ ├── extra_single_word_low_freq.dic
# │ ├── extra_stopword.dic
# │ ├── IKAnalyzer.cfg.xml # 配置文件
# │ ├── main.dic
# │ ├── preposition.dic
# │ ├── quantifier.dic
# │ ├── stopword.dic
# │ ├── suffix.dic
# │ └── surname.dic
# ├── elasticsearch-analysis-ik-7.15.0.jar
# ├── httpclient-4.5.2.jar
# ├── httpcore-4.4.4.jar
# ├── plugin-descriptor.properties
# └── plugin-security.policy
# 更改lk版本
$ mv elasticsearch-analysis-ik-7.14.2.jar elasticsearch-analysis-ik-7.15.0.jar
$ vim plugin-descriptor.properties
# 'version': plugin's version
version=7.15.0
# plugins with the incorrect elasticsearch.version.
elasticsearch.version=7.15.0
# 查看插件信息
curl -u weiyigeek:password -XGET http://10.10.107.225:9200/_cat/plugins?v
# es03 analysis-ik 7.15.0
# es01 analysis-ik 7.15.0
# es02 analysis-ik 7.15.0
(3) 简单使用lk分词器插件,这里选择两个不同名称的分词器,一个是ik_smart分词器(粗粒度),一个是ik_max_word(细粒度)分词计算,测试返回结果如下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67# 验证ik_smart分词
POST _analyze
{
"text": ["王者荣耀","绝地求生","黑客白帽"],
"analyzer": "ik_smart"
}
# 验证ik_max_word分词
POST _analyze
{
"text": ["王者荣耀","绝地求生","黑客白帽"],
"analyzer": "ik_max_word"
}
# 返回结果: [王者,荣耀,绝地,求生,黑客,白,帽]
# {
# "tokens" : [
# {
# "token" : "王者",
# "start_offset" : 0,
# "end_offset" : 2,
# "type" : "CN_WORD",
# "position" : 0
# },
# {
# "token" : "荣耀",
# "start_offset" : 2,
# "end_offset" : 4,
# "type" : "CN_WORD",
# "position" : 1
# },
# {
# "token" : "绝地",
# "start_offset" : 5,
# "end_offset" : 7,
# "type" : "CN_WORD",
# "position" : 2
# },
# {
# "token" : "求生",
# "start_offset" : 7,
# "end_offset" : 9,
# "type" : "CN_WORD",
# "position" : 3
# },
# {
# "token" : "黑客",
# "start_offset" : 10,
# "end_offset" : 12,
# "type" : "CN_WORD",
# "position" : 4
# },
# {
# "token" : "白",
# "start_offset" : 12,
# "end_offset" : 13,
# "type" : "CN_CHAR",
# "position" : 5
# },
# {
# "token" : "帽",
# "start_offset" : 13,
# "end_offset" : 14,
# "type" : "CN_CHAR",
# "position" : 6
# }
# ]
# }
Tips : 我们除了可以采用lk自带的热词以外,我们还可以通过lk分词器插件目录中的xml配置文件(IKAnalyzer.cfg.xml),指定静态或者动态更新热词方式。1
2
3
4
5
6
7
8
9
10
11
12
13
14$ cat config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
Tips : 从配置文件可以看出无论是location还是remote都拥有两种词典,一种是扩展字典,而另外一种是停止字典。
- 扩展字典: 让ES可以根据我们自定义的词典来切分字词。例如:白帽
- 扩展停止字典: 让ES可以根据我们自定义的词典来停止计算分析一些无意义或者少意义的词语。例如:那些、那个、the、an、this、that
(1) 静态更新
描述: 这里的静态更新指定的是本地扩展字典或者停止字典。
Tips: 值得注意的是使用本地词典时,其词典配置文件需要指定相对路径,其一般与lk词典配置文件同在config目录下。
案例演示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# - (1) 字典准备
# 本地扩展字典
tee my_extra.dic <<'EOF'
网络安全
等级保护
白帽
EOF
# 本地扩展停止字典
tee my_extra_stop.dic <<'EOF'
黑客
EOF
# - (2) 字典调用配置
$vim IKAnalyzer.cfg.xml
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my_extra.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">my_extra_stop.dic</entry>
# - (3) 重启ES服务 (防止错误,建议以上三步在所有ES集群节点上运行)
systemctl restart elasticsearch
# - (4) 验证分词
# 验证ik_smart分词,可以查看到黑客在我们停止字典上所以带有该词的数据将不会显示,同时也能看出ik_smart分词与ik_max_word分词的区别。
POST _analyze
{
"text": ["网络安全","等级保护","黑客白帽"],
"analyzer": "ik_smart"
}
# 返回结果: [网络安全,等级保护,白帽]
# 验证ik_max_word分词
POST _analyze
{
"text": ["网络安全","等级保护","黑客白帽"],
"analyzer": "ik_max_word"
}
# 返回结果: [网络安全,网络,安全,等级保护,等级,保护,白帽]
(2) 动态更新
描述: 这里的动态更新指定的是使用远程扩展字典或者停止字典,即我们可以从任意一个远程的Web服务器资源中配置词典,从而使lk分词器可以通过网络访问去动态更新我们的热词。
Tips : 在使用动态更新热词前,你需要搭建一个web服务器,常用Nginx或者tomcat以及Python搭建。
案例演示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# - (1) 字典准备
# 远程扩展字典
tee /tmp/re_my_extra.dic <<'EOF'
王者荣
EOF
# 远程扩展停止字典
tee /tmp/re_my_extra_stop.dic <<'EOF'
黑客
白帽
EOF
# - (2) 采用Python启动web服务器
/tmp$ python3 -m http.server 8080
Serving HTTP on 0.0.0.0 port 8080 (http://0.0.0.0:8080/) ...
# - (3) 配置lk词典配置文件
vi IKAnalyzer.cfg.xml
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://10.10.107.227:8080/re_my_extra.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://10.10.107.227:8080/re_my_extra_stop.dic</entry>
# - (4) 重启ES服务(启动它会进行访问我们远程路径),建议在所有节点的lk中都进行配置。
systemctl restart elasticsearch
# 10.10.107.225 - - [08/Oct/2021 20:50:38] "GET /re_my_extra.dic HTTP/1.1" 200 -
# 10.10.107.225 - - [08/Oct/2021 20:50:38] "GET /re_my_extra_stop.dic HTTP/1.1" 200 -
# - (5) 验证lk分词器
# 验证ik_smart分词
POST _analyze
{
"text": ["王者荣耀","黑客白帽"],
"analyzer": "ik_smart"
}
# 返回结果: [王者,荣耀]
# 验证ik_max_word分词
POST _analyze
{
"text": ["王者荣耀","黑客白帽"],
"analyzer": "ik_max_word"
}
# 返回结果:
Tips : 配置远程扩展字典后,ES会在启动时GET以及每一分钟进行HEAD请求我们设置的远程扩展字典以及远程扩展停止字典,当发现更新后便会GET请求。1
2
3
4
5
610.10.107.225 - - [08/Oct/2021 20:50:48] "GET /re_my_extra.dic HTTP/1.1" 200 -
10.10.107.225 - - [08/Oct/2021 20:50:48] "GET /re_my_extra_stop.dic HTTP/1.1" 200 -
10.10.107.225 - - [08/Oct/2021 20:51:48] "HEAD /re_my_extra.dic HTTP/1.1" 304 -
10.10.107.225 - - [08/Oct/2021 20:51:48] "HEAD /re_my_extra_stop.dic HTTP/1.1" 304 -
10.10.107.225 - - [08/Oct/2021 20:52:48] "HEAD /re_my_extra.dic HTTP/1.1" 304 -
10.10.107.225 - - [08/Oct/2021 20:52:48] "HEAD /re_my_extra_stop.dic HTTP/1.1" 304 -
https://www.cnblogs.com/wanghj-15/p/11307999.html
ES(ElasticSearch)文档的表现形式以及增删改查
https://www.cnblogs.com/wangcuican/p/13896973.html
X

你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!
@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/网安防御/安全建设/日志审计/ElasticStack/3.ElasticSearch分布式数据分析引擎基础概念与使用.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2021/8-2-614.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议