
[TOC]
2.ElasticStack分布式数据采集搜索引擎集群搭建配置
|[TOC]
0x01 ES集群搭建实践
1.宿主机安装
(1.1) 节点环境
描述: 此处系统的环境设置请参考上一章的重要系统配置章节。
操作环境说明:1
2
3elk1 Master 2C 4G - Ubuntu 20.04.2 LTS 5.4.0-86-generic
elk2 Slave 2C 2G - Ubuntu 20.04.2 LTS 5.4.0-86-generic
elk3 Slave 2C 2G - Ubuntu 20.04.2 LTS 5.4.0-86-generic
节点信息:
| Name | Role | IP | HTTP PORT | Cluster TCP PORT |
|---|---|---|---|---|
| es01 | MASTER | 10.10.107.225 | 9200 | 9300 |
| es02 | SLAVE | 10.10.107.226 | 9200 | 9300 |
| es03 | SLAVE | 10.10.107.227 | 9200 | 9300 |
基础环境设置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38# 系统启动配置
if [[ $(grep -c "ulimit" /etc/profile) -ne 2 ]];then
tee -a /etc/profile <<'EOF'
swapoff -a
ulimit -HSn 65535
#ulimit -HSu 65535
EOF
fi
# 系统资源限制配置
if [[ $(grep -E -c "^elk" /etc/security/limits.conf) -eq 0 ]];then
tee -a /etc/security/limits.conf <<'EOF'
# 在启动 Elasticsearch 之前将 memlock 设置为无限制
elk soft memlock unlimited
elk hard memlock unlimited
# 文件描述符数量与线程数
elk soft nofile 65535
elk hard nofile 65535
elk soft nproc 65535
elk hard nproc 65535
EOF
fi
# 系统内核参数配置&生效设置
tee -a /etc/sysctl.conf <<'EOF'
# 禁用 swap
vm.swappiness=1
# 确保足够的虚拟内存
vm.max_map_count=262144
# TCP重传超时次数
net.ipv4.tcp_retries2=5
EOF
sysctl -p
# 系统主机名称解析配置
tee -a /etc/hosts <<'EOF'
10.10.107.225 es01
10.10.107.226 es02
10.10.107.227 es03
EOF
(1.2) 实践流程
- Step 1.三台主机分别进行ES Linux Tar 安装包下载解压到/usr/local/目录中。
1
2
3
4
5
6
7
8
9
10
11
12
13export ES_VERSION="7.15.0"
export ES_DIR="/usr/local/elasticsearch-${ES_VERSION}"
wget -L https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-${ES_VERSION}-linux-x86_64.tar.gz
wget -L https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-${ES_VERSION}-linux-x86_64.tar.gz.sha512
shasum -a 512 -c elasticsearch-${ES_VERSION}-linux-x86_64.tar.gz.sha512
if [ $? -eq 0 ];then
sudo tar -xzf elasticsearch-${ES_VERSION}-linux-x86_64.tar.gz -C /usr/local
cd /usr/local/elasticsearch-${ES_VERSION}/
else
echo -e "\e[31m[*] check shasum elasticsearch-${ES_VERSION}-linux-x86_64.tar.gz failed! \e[0m"
exit 1
fi
- Step 2.环境变量设置(ES/JAVA)以及ES运行账户创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# ES_HOME / JAVA 的环境变量配置
if [[ $(grep -c "ES_HOME" /etc/profile) -eq 0 ]];then
tee -a /etc/profile <<'EOF'
ES_VERSION="7.15.0"
ES_HOME="/usr/local/elasticsearch-${ES_VERSION}"
ES_JAVA_HOME="${ES_HOME}/jdk"
PATH=${ES_JAVA_HOME}/bin:${ES_HOME}/bin:$PATH
export ES_VERSION ES_HOME ES_JAVA_HOME PATH
EOF
else
echo -e "\e[31[*] melasticsearch environment failed! \e[0m"
exit 1
fi
source /etc/profile
echo $PATH
# /usr/usr/local/elasticsearch-7.15.0/jdk/bin:/usr/usr/local/elasticsearch-7.15.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
#创建运行 elasticsearch 用户与权限设置
groupadd elk && useradd -s /bin/bash -U elk -g elk
chown -R elk:elk ${ES_HOME}
- Step 3.创建 ES 集群的PKCS#12证书和安全配置,通过查看官网证书的创建((https://www.elastic.co/guide/en/elasticsearch/reference/7.15/certutil.html)方式分为两种:一是通过 elasticsearch-certutil 命令逐一创建证书,二是使用 elasticsearch-certutil 的 Silent Mode 创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64# 1.在instances.yml中记录集群的节点名称和IP实例信息
cat > ${ES_HOME}/instances.yml<<EOF
instances:
- name: "es01"
ip:
- "10.10.107.225"
- name: "es02"
ip:
- "10.10.107.226"
- name: "es03"
ip:
- "10.10.107.227"
EOF
# 2.此处使用静默模式(Silent Mode)一键创建
bin/elasticsearch-certutil cert --silent --in instances.yml --out ./config/cert.zip --pass testpassword
# 3.进入config目录并解压证书文件
cd /usr/local/elasticsearch-7.15.0/config && unzip cert.zip
Archive: cert.zip
creating: es01/
inflating: es01/es01.p12
creating: es02/
inflating: es02/es02.p12
creating: es03/
inflating: es03/es03.p12
# 4.将此处zip分别拷贝到ES02/ES03机器的/usr/usr/local/elasticsearch-7.15.0/config目录下。
scp -P 20211 cert.zip weiyigeek@10.10.107.226:/tmp
scp -P 20211 cert.zip weiyigeek@10.10.107.227:/tmp
unzip /tmp/cert.zip -d ${ES_HOME}/config
# 5.所有节点存入 PKCS#12 秘钥的密码,所有节点都需要运行下面的命令,
# 生成 keystore 文件
cd ${ES_HOME} && ./bin/elasticsearch-keystore create
# 下面两个命令,均需要 输入 在 生成 PKCS#12 秘钥 时的密码(testpassword)
./bin/elasticsearch-keystore add xpack.security.transport.ssl.keystore.secure_password
./bin/elasticsearch-keystore add xpack.security.transport.ssl.truststore.secure_password
# 6.查看添加的密钥
./bin/elasticsearch-keystore list
# keystore.seed
# xpack.security.transport.ssl.keystore.secure_password
# xpack.security.transport.ssl.truststore.secure_password
# 7.elastic 认证之配置内置用户的密码(集群启动后将会自动同步)
${ES_HOME}/bin/elasticsearch-setup-passwords interactive
# Enter password for [elastic]: weiyi123456
# Reenter password for [elastic]: weiyi123456
....
# Enter password for [remote_monitoring_user]:
# Reenter password for [remote_monitoring_user]:
# Changed password for user [apm_system]
# Changed password for user [kibana_system] weiyigeek
# Changed password for user [kibana] weiyigeek
# Changed password for user [logstash_system]
# Changed password for user [beats_system]
# Changed password for user [remote_monitoring_user]
# Changed password for user [elastic]
# 上面过程中我们需要设置多个默认用户的信息,每个内置用户负责不同的内容。
# 8.如果你不想使用上面内置的用户,您也可以创建自己指定的用户名称
${ES_HOME}/bin/elasticsearch-users useradd weiyigeek -p password -r superuser
- Step 4.配置三台主机中ES的systemd来管理它。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60# 0.创建Systemctl在进行ES启动时的环境变量,此种方法可以解析变量
cat << EOF > ${ES_HOME}/es.env
ES_HOME=${ES_HOME}
ES_PATH_CONF=${ES_HOME}/config/
PID_DIR=/var/run
EOF
# 1.采用 systemd 进行ES服务管理的service文件创建。
sudo tee /usr/lib/systemd/system/elasticsearch.service <<'EOF'
[Unit]
Description=Elasticsearch Services Manager
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
User=elk
Group=elk
RuntimeDirectory=elk
EnvironmentFile=-/usr/local/elasticsearch-7.15.0/es.env
WorkingDirectory=/usr/local/elasticsearch-7.15.0/
ExecStart=/usr/local/elasticsearch-7.15.0/bin/elasticsearch -p /usr/local/elasticsearch-7.15.0/elasticsearch.pid --quiet
# StandardOutput配置为错误重定向到journalctl,如果您还想启用journalctl记录日志时只需从ExecStart中删除quiet选项即可。
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Specifies the maximum number of processes
LimitNPROC=4096
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
EOF
# 2.重载 systemd 后台守护进程
systemctl daemon-reload
- Step 5.ES集群配置文件(三台机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49# (1)Master - es01
tee ${ES_HOME}/config/elasticsearch.yml <<'EOF'
#------- 集群Cluster -------
#- 集群名称
cluster.name: es-cluster
#- 集群初始化时指定的Master节点。
cluster.initial_master_nodes: ["es01"]
#- 集群节点列表
discovery.seed_hosts: ["10.10.107.225","10.10.107.226","10.10.107.227"]
#------- 节点Node -------
node.name: es01
#--------网络Network -------
# 监听接口
network.host: 0.0.0.0
# ES的HTTP服务端口
http.port: 9200
# ES的TCP服务端口(集群使用)
transport.tcp.port: 9300
# ES的TCP服务端口(压缩传输)
transport.tcp.compress: true
#--------数据与日志存储目录--------
path.data: /usr/local/elasticsearch-7.15.0/data
path.logs: /usr/local/elasticsearch-7.15.0/logs
#--------性能Perfece--------
# ARM CPU 才开启,试将进程地址空间锁定到 RAM 中以防止任何 Elasticsearch 堆内存被换出,但为了性能我们需要将其关闭。
#bootstrap.memory_lock: fasle
#bootstrap.system_call_filter: false
#--------插件跨域配置--------
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Type,Content-Length
#--------证书安全配置----------
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.keystore.path: es01/es01.p12
xpack.security.transport.ssl.truststore.path: es01/es01.p12
EOF
# (2) node - es02
sed -i -e 's#es01#es02#g' -e 's#"es02"#"es01"#g' ${ES_HOME}/config/elasticsearch.yml
# (3) node - es03
sed -i -e 's#es01#es03#g' -e 's#"es03"#"es01"#g' ${ES_HOME}/config/elasticsearch.yml
- Step 6.启动ES前的最后一次配置,然后依次启动elastic服务
1
2
3
4
5
6
7
8
9
10
11# 1.根据节点机器的配置设置其jvm参数。(非常注意系统内存一定要大于设置)
# JVM heap size 默认为4G,其中最大值和最小值必须一致。
# sed -i -e 's|## -Xms4g|-Xms4g|g' -e 's|## -Xmx4g|-Xmx4g|g' ${ES_HOME}/config/jvm.options
# sed -i -e 's@## -Xmx4g@-Xmx2g@g' -e "s@## -Xms4g@-Xms2g@g" ${ES_HOME}/config/jvm.options
# 3.再次对 ${ES_HOME} 目录下的所有文件目录进行授权,防止elk用户没有访问权限。
chown -R elk:elk ${ES_HOME}
# 4.启动并查看ES服务
systemctl start elasticsearch.service
systemctl status elasticsearch.service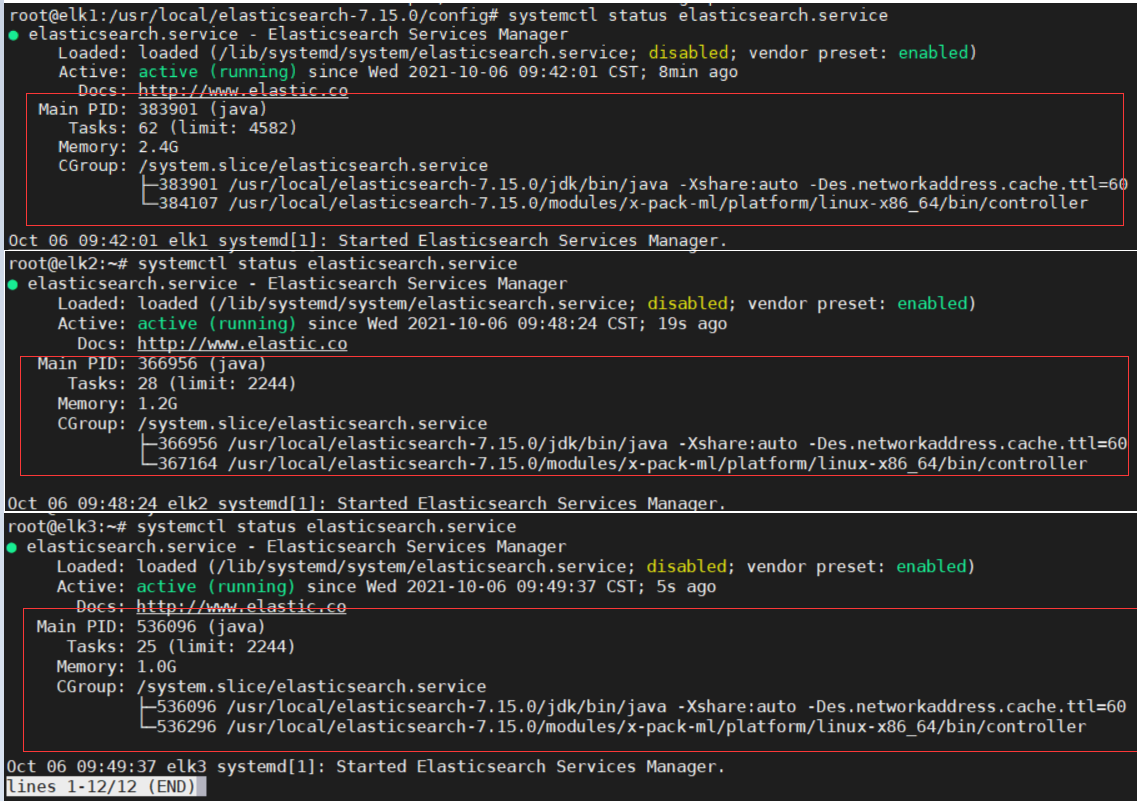
weiyigeek.top-ES_CLUSTER_START
- Step 7.验证ES集群服务是否正常工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62# 1.访问三台主机的ES服务,采用-u选择指定前面我们自己创建的用户。
for i in {225..227};do
curl -u weiyigeek:password 10.10.107.${i}:9200
done
# {
# "name" : "es01",
# "cluster_name" : "es-cluster",
# "cluster_uuid" : "f4MbDAeMReOH7XeGHr5irA",
# "version" : {
# "number" : "7.15.0",
# "build_flavor" : "default",
# "build_type" : "tar",
# "build_hash" : "79d65f6e357953a5b3cbcc5e2c7c21073d89aa29",
# "build_date" : "2021-09-16T03:05:29.143308416Z",
# "build_snapshot" : false,
# "lucene_version" : "8.9.0",
# "minimum_wire_compatibility_version" : "6.8.0",
# "minimum_index_compatibility_version" : "6.0.0-beta1"
# },
# "tagline" : "You Know, for Search"
# }
# {
# "name" : "es02",
# "cluster_name" : "es-cluster",
# "cluster_uuid" : "f4MbDAeMReOH7XeGHr5irA",
# "version" : {
# "number" : "7.15.0",
# "build_flavor" : "default",
# "build_type" : "tar",
# "build_hash" : "79d65f6e357953a5b3cbcc5e2c7c21073d89aa29",
# "build_date" : "2021-09-16T03:05:29.143308416Z",
# "build_snapshot" : false,
# "lucene_version" : "8.9.0",
# "minimum_wire_compatibility_version" : "6.8.0",
# "minimum_index_compatibility_version" : "6.0.0-beta1"
# },
# "tagline" : "You Know, for Search"
# }
# {
# "name" : "es03",
# "cluster_name" : "es-cluster",
# "cluster_uuid" : "f4MbDAeMReOH7XeGHr5irA",
# "version" : {
# "number" : "7.15.0",
# "build_flavor" : "default",
# "build_type" : "tar",
# "build_hash" : "79d65f6e357953a5b3cbcc5e2c7c21073d89aa29",
# "build_date" : "2021-09-16T03:05:29.143308416Z",
# "build_snapshot" : false,
# "lucene_version" : "8.9.0",
# "minimum_wire_compatibility_version" : "6.8.0",
# "minimum_index_compatibility_version" : "6.0.0-beta1"
# },
# "tagline" : "You Know, for Search"
# }
# 2.查ES集群角色与节点信息
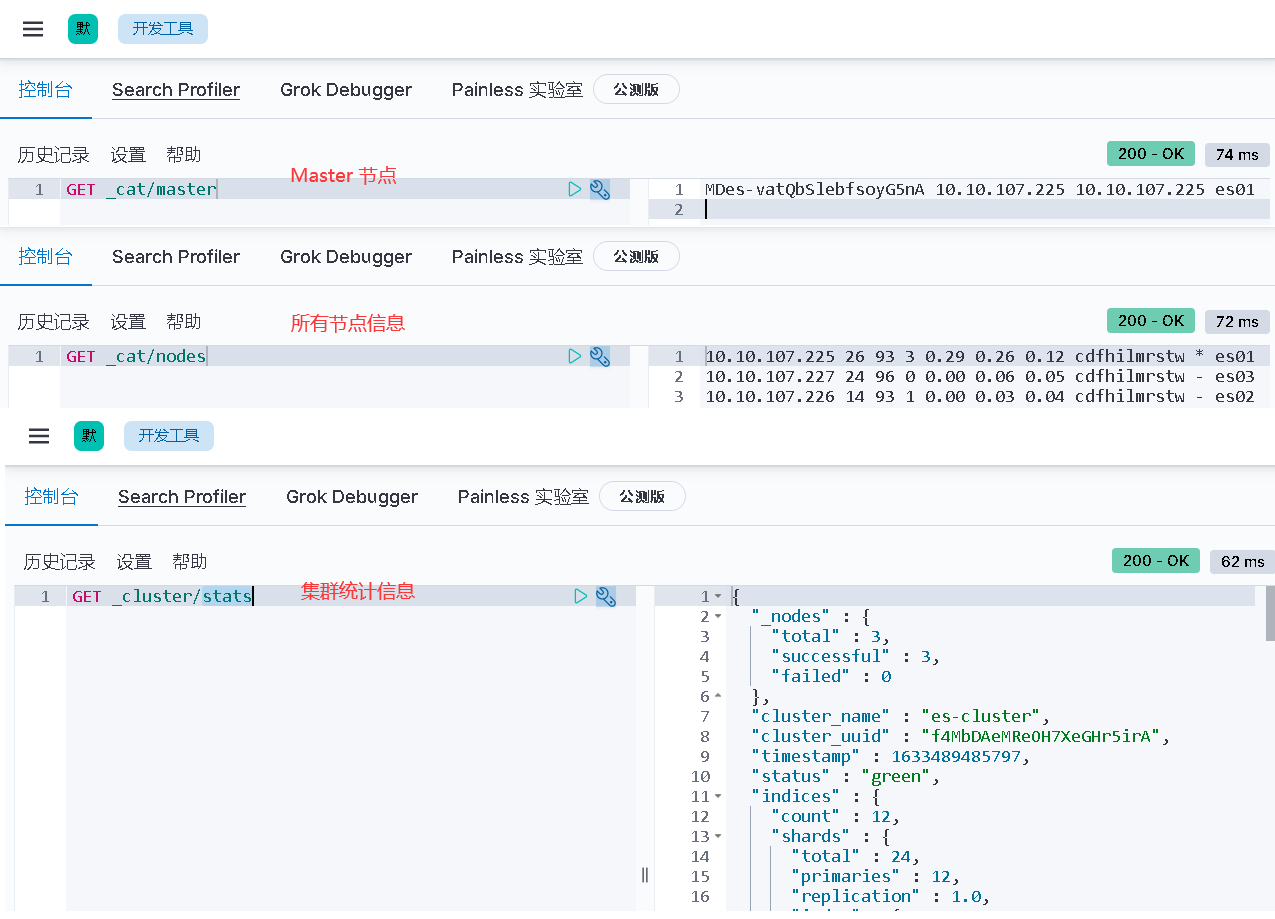
$ curl -u weiyigeek:password 10.10.107.226:9200/_cat/nodes?v
# ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
# 10.10.107.226 17 93 1 0.00 0.03 0.04 cdfhilmrstw - es02
# 10.10.107.227 14 95 0 0.00 0.04 0.02 cdfhilmrstw - es03
# 10.10.107.225 23 97 0 0.00 0.02 0.01 cdfhilmrstw * es01
- Step 8.ES集群高可用验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 1.此时我们把10.10.107.225节点服务关闭
systemctl stop elasticsearch.service
# 2.再次请求节点查看,发现es02已从slave变为了master
curl -u weiyigeek:password 10.10.107.226:9200/_cat/nodes?v
# ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
# 10.10.107.227 47 96 0 0.00 0.00 0.00 cdfhilmrstw - es03
# 10.10.107.226 53 93 0 0.11 0.04 0.01 cdfhilmrstw * es02
# 3.当把10.10.107.225节点的ES服务重启后,它会自动加入到集群之中,其角色变为slave。
curl -u weiyigeek:password 10.10.107.226:9200/_cat/nodes?v
# ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
# 10.10.107.226 36 94 1 0.02 0.03 0.00 cdfhilmrstw * es02
# 10.10.107.227 34 96 0 0.01 0.02 0.00 cdfhilmrstw - es03
# 10.10.107.225 18 95 9 0.34 0.10 0.04 cdfhilmrstw - es01
2.docker-compose 安装
描述: 要在 Docker 中启动并运行三节点 Elasticsearch 集群,您可以使用 Docker Compose:
docker-compose.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.5.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
执行部署命令1
docker-compose up -d .
4.K8S 安装
此处使用官方示例 Elasticsearch StatefulSet 将使用 EmptyDir 卷来存储数据,当 pod 终止时EmptyDir 将被擦除,如果想要数据持久化可将存储更改为永久卷声明。
访问redhat 仓库查看 elasticsearch 可用版本(https://quay.io/repository/fluentd_elasticsearch/elasticsearch?tab=tags)
温馨提示: 建议提前拉取 quay.io/fluentd_elasticsearch/elasticsearch:v7.16.2 镜像到私有仓库之中。1
2# 此处利用skopeo镜像搬运工工具, 不知道如何安装使用的请参考,我的另外一篇文章(Skopeo如何优雅的做一个镜像搬运工)
skopeo copy --insecure-policy --src-tls-verify=false --dest-tls-verify=false --dest-authfile /root/.docker/config.json docker://quay.io/fluentd_elasticsearch/elasticsearch:v7.16.2 docker://harbor.cloud/weiyigeek/elasticsearch:v7.16.2
安装ES集群的的配置清单yaml文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134tee es-statefulset.yml <<'EOF'
# RBAC authn and authz
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch-logging
namespace: web
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "services"
- "namespaces"
- "endpoints"
verbs:
- "get"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: web
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: elasticsearch-logging
namespace: web
apiGroup: ""
roleRef:
kind: ClusterRole
name: elasticsearch-logging
apiGroup: ""
---
# Elasticsearch deployment itself
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch-logging
namespace: web
labels:
k8s-app: elasticsearch-logging
version: v7.16.2
addonmanager.kubernetes.io/mode: Reconcile
spec:
serviceName: elasticsearch-logging
replicas: 3
selector:
matchLabels:
k8s-app: elasticsearch-logging
version: v7.16.2
template:
metadata:
labels:
k8s-app: elasticsearch-logging
version: v7.16.2
spec:
serviceAccountName: elasticsearch-logging
containers:
- image: quay.io/fluentd_elasticsearch/elasticsearch:v7.16.2
name: elasticsearch-logging
imagePullPolicy: Always
resources:
# need more cpu upon initialization, therefore burstable class
limits:
cpu: 1000m
memory: 3Gi
requests:
cpu: 100m
memory: 3Gi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
livenessProbe:
tcpSocket:
port: transport
initialDelaySeconds: 5
timeoutSeconds: 10
readinessProbe:
tcpSocket:
port: transport
initialDelaySeconds: 5
timeoutSeconds: 10
volumeMounts:
- name: elasticsearch-logging
mountPath: /data
env:
- name: "NAMESPACE"
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: "MINIMUM_MASTER_NODES"
value: "1"
volumes:
- name: elasticsearch-logging
emptyDir: {}
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
initContainers:
- image: alpine:3.15
command: ["/sbin/sysctl", "-w", "vm.max_map_count=262144"]
name: elasticsearch-logging-init
securityContext:
privileged: true
# volumeClaimTemplates:
# - apiVersion: v1
# kind: PersistentVolumeClaim
# metadata:
# name: elasticsearch-logging
# spec:
# accessModes:
# - ReadWriteOnce
# resources:
# requests:
# storage: 5Gi
# storageClassName: managed-nfs-storage
EOF
4.Helm 安装
官方项目地址: https://github.com/elastic/helm-charts
安装流程
Step 1.安装环境以及Charts准备;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57# (1) 添加 elastic 仓库
~/K8s/Day11$ helm repo add elastic https://helm.elastic.co
# (2) 拉取 elasticsearch / Filebeat / Kibana 等 Chart 到本地并解压
~/K8s/Day11$ helm fetch elastic/elasticsearch --untar
~/K8s/Day11$ helm fetch elastic/filebeat --untar
~/K8s/Day11$ helm fetch elastic/kibana --untar
~/K8s/Day11$ tree -d 1 .
# ├── elasticsearch
# │ ├── examples
# │ │ ├── config
# │ │ │ └── test
# │ │ ├── default
# │ │ │ └── test
# │ │ ├── docker-for-mac
# │ │ ├── kubernetes-kind
# │ │ ├── microk8s
# │ │ ├── migration
# │ │ ├── minikube
# │ │ ├── multi
# │ │ │ └── test
# │ │ ├── openshift
# │ │ │ └── test
# │ │ ├── oss
# │ │ │ └── test
# │ │ ├── security
# │ │ │ └── test
# │ │ └── upgrade
# │ │ └── test
# │ └── templates
# │ └── test
# ├── filebeat
# │ ├── examples
# │ │ ├── default
# │ │ │ └── test
# │ │ ├── oss
# │ │ │ └── test
# │ │ ├── security
# │ │ │ └── test
# │ │ └── upgrade
# │ │ └── test
# │ └── templates
# └── kibana
# ├── examples
# │ ├── default
# │ │ └── test
# │ ├── openshift
# │ │ └── test
# │ ├── oss
# │ │ └── test
# │ ├── security
# │ │ └── test
# │ └── upgrade
# │ └── test
# └── templates
# 47 directoriesStep 2.名称空间创建(暂不使用)以及elasticsearch的安装部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# (1) 名称空间的创建 以及存储卷访问模式为 ReadWriteOnce - efk-pv
~/K8s/Day11/elasticsearch$ kubectl create namespace log-efk
# PS : 此处需要依赖于StorageName动态存储卷,所以您需要提前进行配置;
# (2) 由于测试环境资源有限我们将Charts中Values关于副本数以及最小master节点都该成(3Master节点~20G内存)
~/K8s/Day11/elasticsearch$ vim values.yaml
# 修改点
replicas: 1
minimumMasterNodes: 1
# PS: 生产环境中推荐修改values.yaml文件中pv为storageClass动态分配
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage" # 非常重要 它是与 StorageClass 资源器绑定的名称要一致
resources:
requests:
storage: 20Gi
# PS :开启持久化
persistence:
enabled: true
labels:
enabled: true # 为有状态集的volumeClaimTemplate添加默认标签 ( 坑 )
annotations: {}
# (3) 将elasticsearch进行安装部署 (-n log-efk) 不能正常部署 (坑)
~/K8s/Day11/elasticsearch$ helm install elasticsearch .
# NAME: elasticsearch
# LAST DEPLOYED: Wed Dec 9 09:52:35 2020
# NAMESPACE: log-efk
# STATUS: deployed
# REVISION: 1
# NOTES:
# 1. Watch all cluster members come up.
# $ kubectl get pods-l app=elasticsearch-master -w
# 2. Test cluster health using Helm test.
# $ helm test elasticsearch
# * Install it:
# - with Helm 3: `helm install elasticsearch --version <version> elastic/elasticsearch`
# - with Helm 2 (deprecated): `helm install --name elasticsearch --version <version> elastic/elasticsearch`Step 3.查看StatefulSete资源控制器创建的elasticsearch以及PVC卷的绑定和SVC;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# StatefulSet
~/K8s/Day11/elasticsearch$ kubectl get sts -o wide
# NAME READY AGE CONTAINERS IMAGES
# elasticsearch-master 1/1 2m57s elasticsearch docker.elastic.co/elasticsearch/elasticsearch:7.10.0
# Pod
~/K8s/Day11/elasticsearch$ kubectl get pod -o wide --show-labels | grep "elasticsearch"
# elasticsearch-master-0 1/1 Running 0 3m30s 10.244.1.180 k8s-node-4 app=elasticsearch-master,chart=elasticsearch,controller-revision-hash=elasticsearch-master-76c48b9f74,release=elasticsearch,statefulset.kubernetes.io/pod-name=elasticsearch-master-0
# Svc
~/K8s/Day11/elasticsearch$ kubectl get svc -o wide
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
# elasticsearch-master ClusterIP 10.104.178.144 <none> 9200/TCP,9300/TCP 9m49s app=elasticsearch-master,chart=elasticsearch,release=elasticsearch
# elasticsearch-master-headless ClusterIP None <none> 9200/TCP,9300/TCP 9m49s app=elasticsearch-master
# StorageClass 动态存储卷查看
~/K8s/Day11/elasticsearch$ kubectl get storageclass,pv,pvc
# NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
# storageclass.storage.k8s.io/managed-nfs-storage (default) fuseim.pri/ifs Delete Immediate false 25h
# NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
# persistentvolume/pvc-8a991669-60c0-48c6-9879-5b4fa9d481c3 20Gi RWO Delete Bound default/elasticsearch-master-elasticsearch-master-0 managed-nfs-storage 2m6s
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# persistentvolumeclaim/elasticsearch-master-elasticsearch-master-0 Bound pvc-8a991669-60c0-48c6-9879-5b4fa9d481c3 20Gi RWO managed-nfs-storage 2m6sStep 4.Helm安装filebeat查看并验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# vim filebeat/value.yaml
# Root directory where Filebeat will write data to in order to persist registry data across pod restarts (file position and other metadata).
# 默认读取的是节点/var/lib下的所有文件
hostPathRoot: /var/lib
# 安装 filbeat
~/K8s/Day11/filebeat$ helm install filbeat .
# NAME: filbeat
# LAST DEPLOYED: Thu Dec 10 17:09:53 2020
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
# NOTES:
# 1. Watch all containers come up.
# $ kubectl get pods --namespace=default -l app=filbeat-filebeat -w
# 查看状态,因为是DaemonSet类型所以每台node都会装一个。
~/K8s/Day11/filebeat$ kubectl get pods --namespace=default -l app=filbeat-filebeat -o wide
# NAME READY STATUS RESTARTS AGE IP NODE
# filbeat-filebeat-2dr52 1/1 Running 0 4h39m 10.244.2.78 k8s-node-5
# filbeat-filebeat-mgj5r 1/1 Running 0 58m 10.244.0.190 master
# filbeat-filebeat-qm7wt 1/1 Running 0 4h39m 10.244.1.181 k8s-node-4Step 5.Helm 安装 kibana 以及验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38vim kibana/values.yaml
# 修改values.yaml文件中service为nodePort类型
service:
type: NodePort # 修改点
loadBalancerIP: ""
port: 5601
nodePort: 30002
labels: {} # 修改点
annotations: {}
# cloud.google.com/load-balancer-type: "Internal"
# service.beta.kubernetes.io/aws-load-balancer-internal: 0.0.0.0/0
# service.beta.kubernetes.io/azure-load-balancer-internal: "true"
# service.beta.kubernetes.io/openstack-internal-load-balancer: "true"
# service.beta.kubernetes.io/cce-load-balancer-internal-vpc: "true"
loadBalancerSourceRanges: []
# 0.0.0.0/0
# 安装 Kibana
~/K8s/Day11/kibana$ helm install kibana .
# NAME: kibana
# LAST DEPLOYED: Thu Dec 10 20:16:13 2020
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
# 查看 deployment 和 Pod
~/K8s/Day11/filebeat$ kubectl get deploy,pod -o wide -l app=kibana
# NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
# deployment.apps/kibana-kibana 1/1 1 1 52m kibana docker.elastic.co/kibana/kibana:7.10.0 app=kibana,release=kibana
# NAME READY STATUS RESTARTS AGE IP NODE
# pod/kibana-kibana-86d4cc75f7-gbmjt 1/1 Running 0 28m 10.244.0.192 master
# 查看 svc
~/K8s/Day11/filebeat$ kubectl get svc -l app=kibana
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# kibana-kibana NodePort 10.110.225.148 <none> 5601:30002/TCP 54mStep 6.利用 Helm 查看安装的 EFK RELEASE,访问 kibana URL 并创建索引: http://10.10.107.202:30002/app/management/kibana/indexPatterns
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32~/K8s/Day11/filebeat$ helm ls
# NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
# elasticsearch default 1 2020-12-10 16:51:42.74817589 +0800 CST deployed elasticsearch-7.10.0 7.10.0
# filbeat default 1 2020-12-10 17:09:53.872762268 +0800 CST deployed filebeat-7.10.0 7.10.0
# kibana default 1 2020-12-10 21:01:17.44414926 +0800 CST deployed kibana-7.10.0 7.10.0
```
Process : Stack Management > Index patterns -> Create `创建索引` -> Next Step -> Time field `按照时间进行分片`
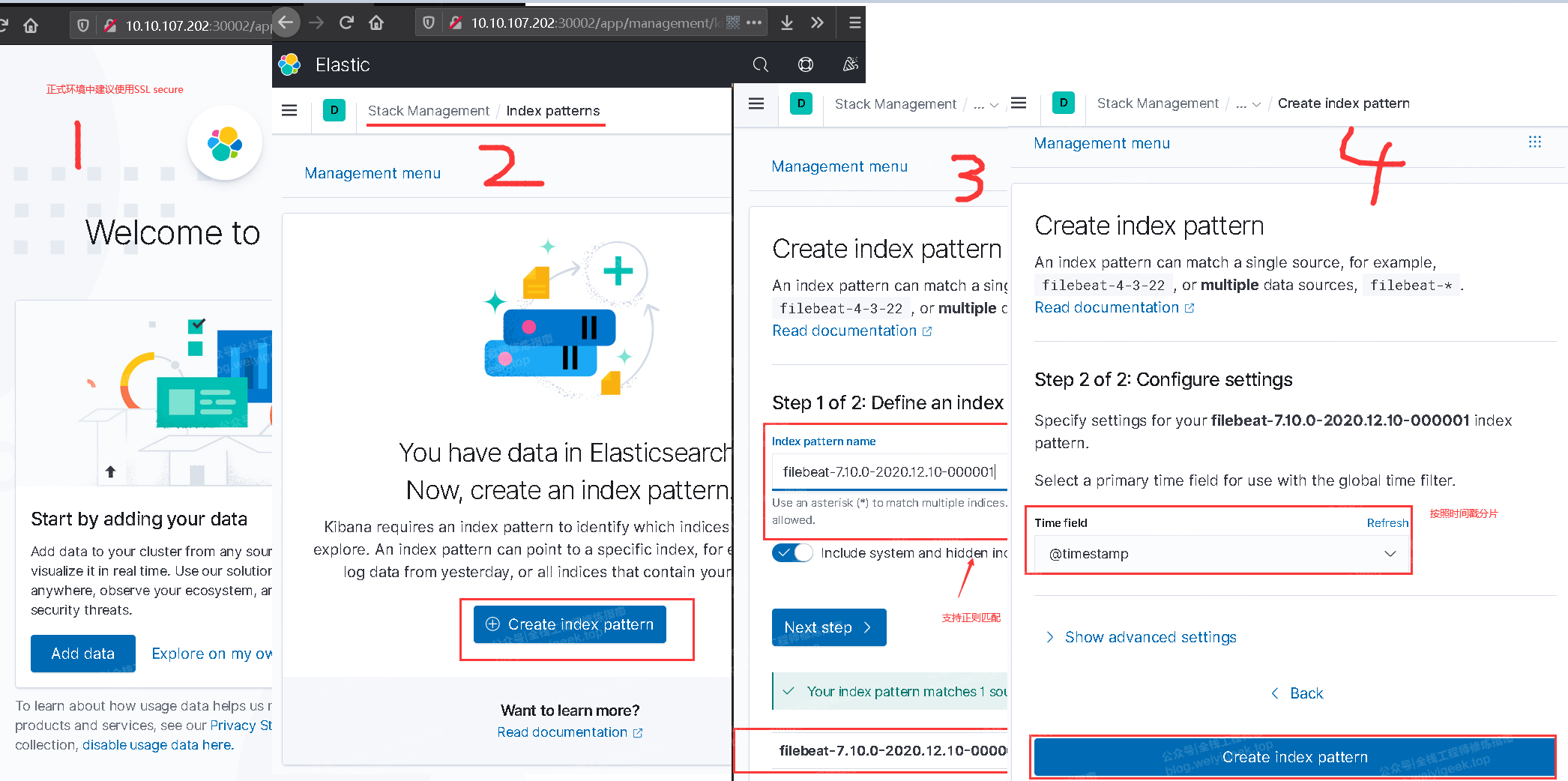
- Step 7.Elasticsearch 的 Kibana 的简单使用;
例如: 按照Node节点查询`kubernetes.node.name : "k8s-node-4" or kubernetes.pod.name : "nfs-client-provisioner-58b5dc958d-5fwl9" `
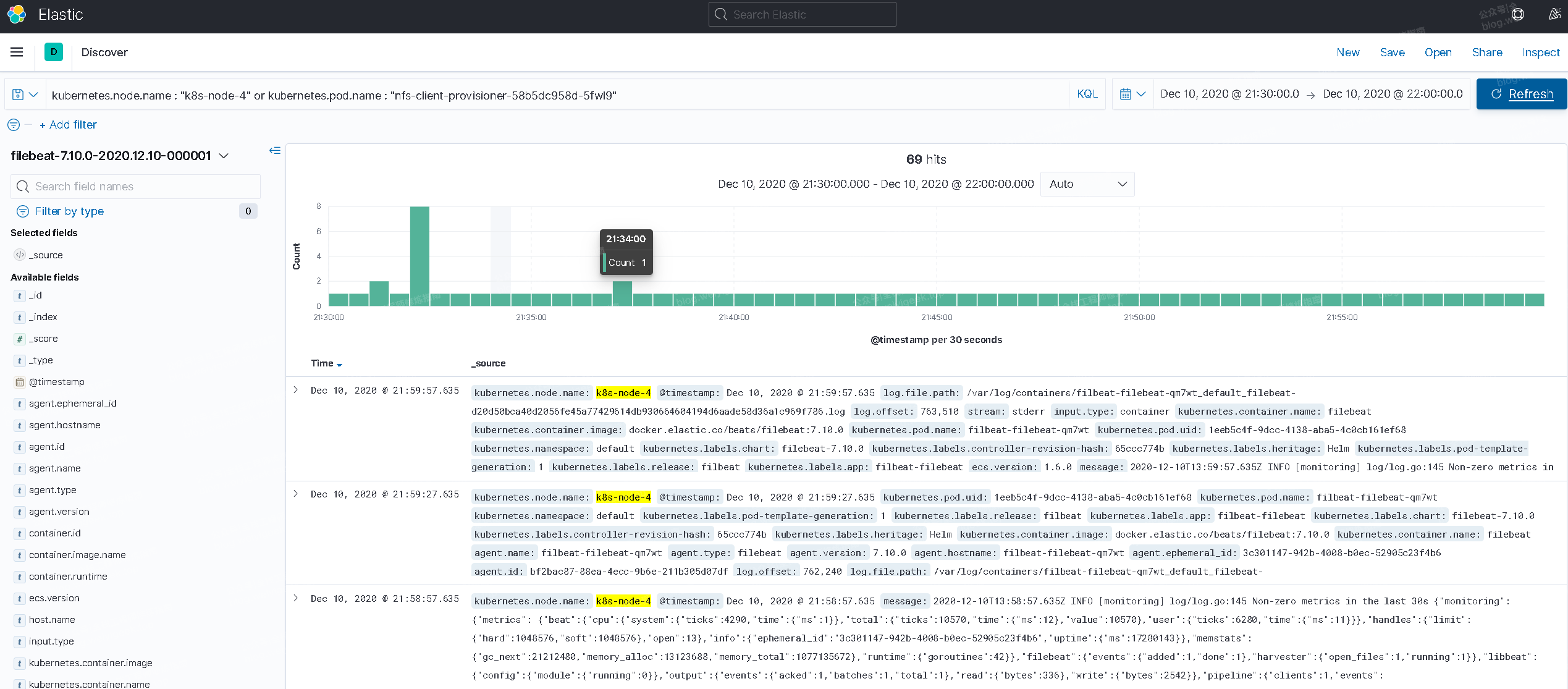
<br/>
**入坑&出坑**
- 问题1.Helm部署kibana无法正常Run显示`Readiness probe failed: Error: Got HTTP code 503 but expected a 200` (该问题把我心态搞得炸裂)
错误信息: 学习排错也是一种学习;
```bash
# Pod 描述信息
~/K8s/Day11/kibana$ kubectl describe pod kibana-kibana-86d4cc75f7-n7kxr
# Normal Started 3m43s kubelet Started container kibana
# Warning Unhealthy 0s (x22 over 3m30s) kubelet Readiness probe failed: Error: Got HTTP code 503 but expected a 200
# Pod 日志信息 (关键点) 发现 resource_already_exists_exception
~/K8s/Day11/kibana$ kubectl logs kibana-kibana-86d4cc75f7-n7kxr
# {"type":"log","@timestamp":"2020-12-10T13:01:32Z","tags":["error","elasticsearch","data"],"pid":7,"message":"[resource_already_exists_exception]: index [.kibana_task_manager_1/WikBnfj8QjCVtpuit2NxwA] already exists"}
# {"type":"log","@timestamp":"2020-12-10T13:01:32Z","tags":["warning","savedobjects-service"],"pid":7,"message":"Unable to connect to Elasticsearch. Error: resource_already_exists_exception"}
问题原因: 由于在elasticsearch中已经存在该.kibana_task_manager_1/WikBnfj8QjCVtpuit2NxwA索引导致错误,不能正常启动;
解决方法: 在 elasticsearch 中 删除 Kibana 所有的Index;1
2
3
4
5
6
7
8
9
10
11
12~/K8s/Day11/kibana$ curl "http://10.104.178.144:9200/_cat/indices/*?v&s=index"
# health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
# green open .kibana_1 HiroxArKS3CO_j_cmiJXNg 1 0 0 0 208b 208b
# green open .kibana_task_manager_1 WikBnfj8QjCVtpuit2NxwA 1 0 0 0 208b 208b
# yellow open filebeat-7.10.0-2020.12.10-000001 Vz2L-FXgQSKMuYMrBMum3w 1 1 238934 0 42.1mb 42.1mb
~/K8s/Day11/kibana$ curl -XDELETE http://10.104.178.144:9200/.kibana*
# {"acknowledged":true}
# 重新构建Pod一切正常
~/K8s/Day11/kibana$ kubectl delete pod kibana-kibana-86d4cc75f7-n7kxr
pod "kibana-kibana-86d4cc75f7-n7kxr" deleted
{"type":"response","@timestamp":"2020-12-10T13:26:19Z","tags":[],"pid":6,"method":"get","statusCode":200,"req":{"url":"/app/kibana","method":"get","headers":{"host":"localhost:5601","user-agent":"curl/7.61.1","accept":"*/*"},"remoteAddress":"127.0.0.1","userAgent":"curl/7.61.1"},"res":{"statusCode":200,"responseTime":19,"contentLength":9},"message":"GET /app/kibana 200 19ms - 9.0B"}
参考地址: https://discuss.elastic.co/t/unable-to-connect-to-elasticsearch-error-resource-already-exists-exception-after-upgrade-elk/249998
0x02 ES集群连接实践
1.Elasticsearch-Head 连接集群
描述:同样我们可以使用elasticsearch-head-master连接到我们进行了安全配置的ES集群之中,便于我们对数据的进行查询和管理。
使用浏览器访问elasticsearch-head插件如URL为,http://10.10.107.225:9100/?auth_user=weiyigeek&auth_password=password
1 | # 1.采用head插件进行查询集群监控状态 |
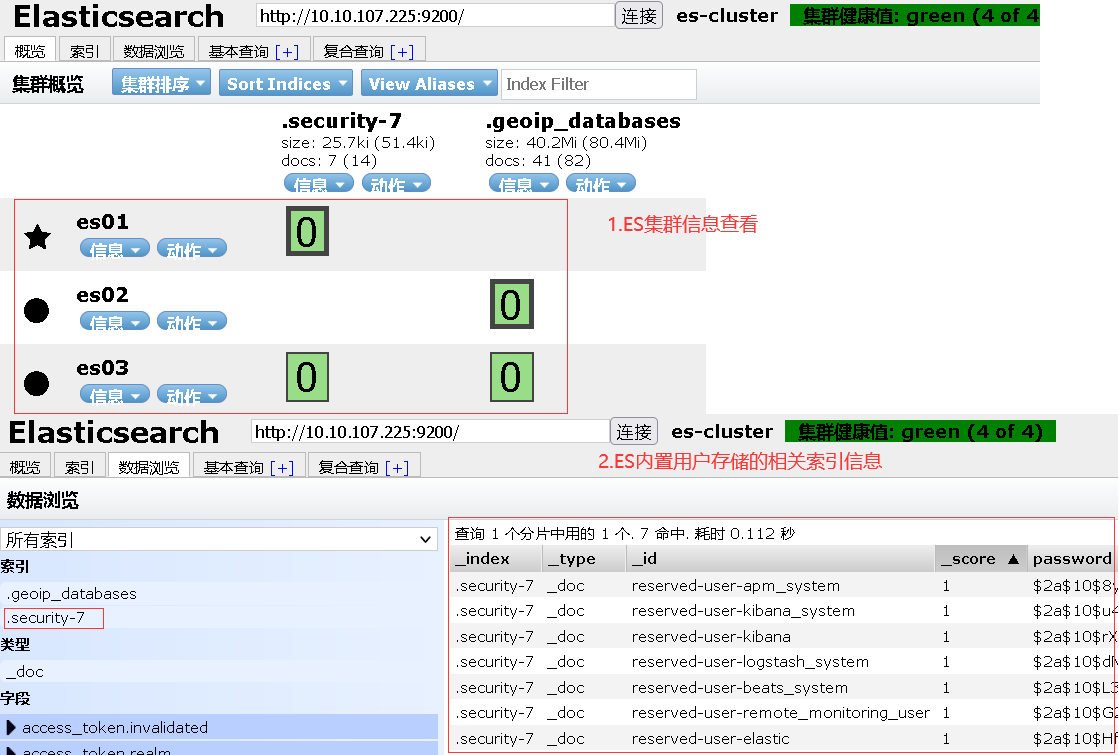
weiyigeek.top-elasticsearch-head
2.Kibana 连接集群
描述: 通常我们使用Kibana 连接到ES集群,对其中采集的指定数据进行展示化。
此处我们需要对Kibana进行简单的认证配置,采用我们前面设置的内置专用用户kibana_system进行连接。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42# 1.Kibana 配置
elk@elk1:/usr/local/kibana-7.15.0/config$ grep -E -v "^#|^$" kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "ES-kibana"
elasticsearch.hosts: ["http://10.10.107.225:9200"]
kibana.index: ".kibana"
elasticsearch.username: "kibana_system"
elasticsearch.password: "weiyigeek"
elasticsearch.pingTimeout: 1500
i18n.locale: "zh-CN"
# 2.Kibana 启动
sudo tee /usr/lib/systemd/system/kibana.service <<'EOF'
[Unit]
Description=kibana in ElasticStack
Documentation=https://elastic.co
After=network.target
Wants=network.target
[Service]
Type=simple
User=elk
Group=elk
LimitNOFILE=65536
LimitNPROC=65536
LimitMEMLOCK=infinity
WorkingDirectory=/usr/local/kibana-7.15.0/
ExecStart=/usr/local/kibana-7.15.0/bin/kibana
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=no
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl restart kibana.service
# 3.Kibana 状态查看&登陆Kibana进行查询验证。
systemctl status kibana.service
weiyigeek.top-Kibana
0x01 配置文件解析
kibana.yml
1 | # - 服务监控地址与服务名称 |
ES 常用配置
问题1.设置-Xms与-Xmx的内存比系统可用内存大1
2
3
4
5
6
7
8Oct 06 09:46:01 elk2 elasticsearch[366853]: OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000080000000, 2147483648, 0) failed; error='Not enough space' (errno=12)
Oct 06 09:46:01 elk2 elasticsearch[366853]: at org.elasticsearch.tools.launchers.JvmOption.flagsFinal(JvmOption.java:119)
Oct 06 09:46:01 elk2 elasticsearch[366853]: at org.elasticsearch.tools.launchers.JvmOption.findFinalOptions(JvmOption.java:81)
Oct 06 09:46:01 elk2 elasticsearch[366853]: at org.elasticsearch.tools.launchers.JvmErgonomics.choose(JvmErgonomics.java:38)
Oct 06 09:46:01 elk2 elasticsearch[366853]: at org.elasticsearch.tools.launchers.JvmOptionsParser.jvmOptions(JvmOptionsParser.java:135)
Oct 06 09:46:01 elk2 elasticsearch[366853]: at org.elasticsearch.tools.launchers.JvmOptionsParser.main(JvmOptionsParser.java:86)
Oct 06 09:46:01 elk2 systemd[1]: elasticsearch.service: Main process exited, code=exited, status=1/FAILURE
Oct 06 09:46:01 elk2 systemd[1]: elasticsearch.service: Failed with result 'exit-code'.
问题2http://10.10.107.225:9100/?auth_user=weiyigeek&auth_password=password
已拦截跨源请求:同源策略禁止读取位于 http://10.10.107.225:9200/_all 的远程资源。(原因:CORS 预检响应的 ‘Access-Control-Allow-Headers’,不允许使用头 ‘authorization’)。
1 |
|
Elasticsearch安全策略-开启密码账号访问
https://blog.csdn.net/qq330983778/article/details/103537252
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.1-amd64.deb
sudo dpkg -i filebeat-7.13.1-amd64.deb
Windows 事件日志
从 Windows 事件日志提取日志。
1.从下载页面下载 Winlogbeat Windows zip 文件。 2.将该 zip 文件的内容解压缩到 C:\Program Files。 3.将 winlogbeat-7.13.1-windows 目录重命名为 Winlogbeat。 4.以管理员身份打开 PowerShell 提示符 (右键单击 PowerShell 图标,然后选择以管理员身份运行) 。如果运行的是 Windows XP,则可能需要下载并安装 PowerShell。 5.从 PowerShell 提示符处,运行以下命令以将 Winlogbeat 安装为 Windows 服务。
http://192.168.12.111:5601/app/home#/tutorial/windowsEventLogs
version: ‘3.2’
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.1
container_name: elastic-single
environment:
- node.name=elastic-single
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
network:
elastic`
回到顶部
一、filebeat是什么
1.1、filebeat和beats的关系
首先filebeat是Beats中的一员。
Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
Packetbeat:网络数据(收集网络流量数据)
Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
Filebeat:日志文件(收集文件数据)
Winlogbeat:windows事件日志(收集Windows事件日志数据)
Auditbeat:审计数据(收集审计日志)
Heartbeat:运行时间监控(收集系统运行时的数据)
1.2、filebeat是什么
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作的流程图如下:
1.3、filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
回到顶部
二、filebeat原理是什么
2.1、filebeat的构成
filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,harvester负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着文件描述符在harvester运行时保持打开状态。如果在收集文件时删除或重命名文件,Filebeat将继续读取该文件。这样做的副作用是,磁盘上的空间一直保留到harvester关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive
关闭harvester可以会产生的结果:
文件处理程序关闭,如果harvester仍在读取文件时被删除,则释放底层资源。
只有在scan_frequency结束之后,才会再次启动文件的收集。
如果该文件在harvester关闭时被移动或删除,该文件的收集将不会继续
一个input负责管理harvesters和寻找所有来源读取。如果input类型是log,则input将查找驱动器上与定义的路径匹配的所有文件,并为每个文件启动一个harvester。每个input在它自己的Go进程中运行,Filebeat当前支持多种输入类型。每个输入类型可以定义多次。日志输入检查每个文件,以查看是否需要启动harvester、是否已经在运行harvester或是否可以忽略该文件
2.2、filebeat如何保存文件的状态
Filebeat保留每个文件的状态,并经常将状态刷新到磁盘中的注册表文件中。该状态用于记住harvester读取的最后一个偏移量,并确保发送所有日志行。如果无法访问输出(如Elasticsearch或Logstash),Filebeat将跟踪最后发送的行,并在输出再次可用时继续读取文件。当Filebeat运行时,每个输入的状态信息也保存在内存中。当Filebeat重新启动时,来自注册表文件的数据用于重建状态,Filebeat在最后一个已知位置继续每个harvester。对于每个输入,Filebeat都会保留它找到的每个文件的状态。由于文件可以重命名或移动,文件名和路径不足以标识文件。对于每个文件,Filebeat存储唯一的标识符,以检测文件是否以前被捕获。
2.3、filebeat何如保证至少一次数据消费
Filebeat保证事件将至少传递到配置的输出一次,并且不会丢失数据。是因为它将每个事件的传递状态存储在注册表文件中。在已定义的输出被阻止且未确认所有事件的情况下,Filebeat将继续尝试发送事件,直到输出确认已接收到事件为止。如果Filebeat在发送事件的过程中关闭,它不会等待输出确认所有事件后再关闭。当Filebeat重新启动时,将再次将Filebeat关闭前未确认的所有事件发送到输出。这样可以确保每个事件至少发送一次,但最终可能会有重复的事件发送到输出。通过设置shutdown_timeout选项,可以将Filebeat配置为在关机前等待特定时间
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全,从而及时采取措施纠正错误。
Beats 是数据采集的得力工具。将 Beats 和您的容器一起置于服务器上,或者将 Beats 作为函数加以部署,然后便可在 Elastisearch 中集中处理数据。如果需要更加强大的处理性能,Beats 还能将数据输送到 Logstash 进行转换和解析。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
EFK 架构图:

weiyigeek.top-ELK架构
EFK(Elasticsearch+Filebeat+Kibana)收集容器日志
https://blog.csdn.net/qq_25934401/article/details/83345144
https://www.cnblogs.com/zsql/p/13137833.html
【摘要】 ELK在运维监控领域使用非常广泛,日志采集通常依靠Logstash,但是通常来讲Logstash架构比较重载,一个安装包由几百MB,相比之下Elastic还提供另一种更轻量的采集工具Beats。Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
ELK在运维监控领域使用非常广泛,日志采集通常依靠Logstash,但是通常来讲Logstash架构比较重载,一个安装包由几百MB,相比之下Elastic还提供另一种更轻量的采集工具Beats。Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。本文简要介绍一下使用Winlogbeat收集Windows日志,并用ES + Kibana检索的配置方法。
elfk 的搭建
filebeat 读取多日志,并打上不同的 tag 来进行区分
logstash 过滤日志,创建不同的动态索引,邮件报警等
elasticsearch 的索引生命周期管理,索引的删除,及我遇见的问题
kibana 的简单使用,包括查询、创建可视图、一些简单的设置
当然了,elfk 的水太深,研究了将近一个月也就是简单的入门,还有更多的设置但入门足以。当然了,要是感觉写的还凑合,微信搜索 苦逼小码农 关注我的微信公众号。
X

你好看友,欢迎关注博主微信公众号哟! ❤
这将是我持续更新文章的动力源泉,谢谢支持!(๑′ᴗ‵๑)
温馨提示: 未解锁的用户不能粘贴复制文章内容哟!
方式1.请访问本博主的B站【WeiyiGeek】首页关注UP主,
将自动随机获取解锁验证码。
Method 2.Please visit 【My Twitter】. There is an article verification code in the homepage.
方式3.扫一扫下方二维码,关注本站官方公众号
回复:验证码
将获取解锁(有效期7天)本站所有技术文章哟!
@WeiyiGeek - 为了能到远方,脚下的每一步都不能少
欢迎各位志同道合的朋友一起学习交流,如文章有误请在下方留下您宝贵的经验知识,个人邮箱地址【master#weiyigeek.top】或者个人公众号【WeiyiGeek】联系我。
更多文章来源于【WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少】, 个人首页地址( https://weiyigeek.top )

专栏书写不易,如果您觉得这个专栏还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注、转个发、赞个助】,这将对我的肯定,我将持续整理发布更多优质原创文章!。
最后更新时间:
文章原始路径:_posts/网安防御/安全建设/日志审计/ElasticStack/2.ElasticStack分布式数据采集搜索引擎集群搭建配置.md
转载注明出处,原文地址:https://blog.weiyigeek.top/2021/8-2-613.html
本站文章内容遵循 知识共享 署名 - 非商业性 - 相同方式共享 4.0 国际协议