[TOC]
0x00 快速了解 EasyOCR 介绍 Q: 什么是 EasyOCR ?
描述: EasyOCR 是一个用于从图像中提取文本的 python 模块, 它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80 多种语言和所有流行的书写脚本,包括:拉丁文、中文、阿拉伯文、梵文、西里尔文等。
Q: 使用 EasyOCR 可以干什么?
描述: EasyOCR 支持两种方式运行一种是常用的CPU,而另外一种是需要GPU支持并且需安装CUDA环境, 我们使用其可以进行图片中语言文字识别, 例如小程序里图片识别、车辆车牌识别(即车债管理系统)。
weiyigeek.top-Examples
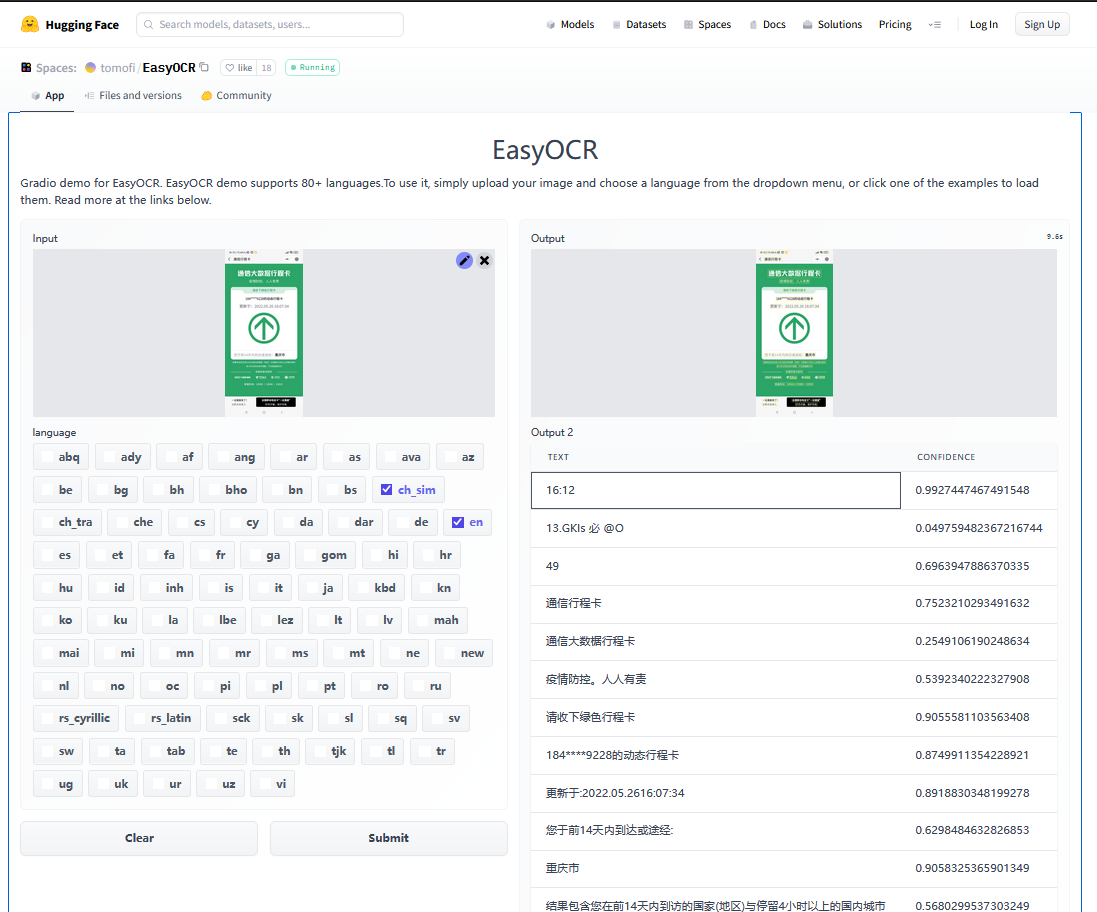
Tips: 在其官网有demo演示,我们可以使用其进行简单图片ocr识别,地址为https://www.jaided.ai/easyocr/ 或者 https://huggingface.co/spaces/tomofi/EasyOCR
weiyigeek.top-官网Demo演示
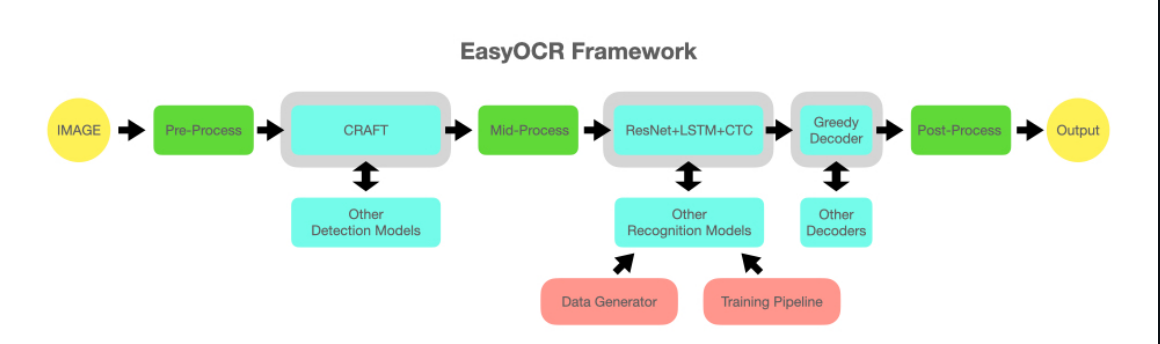
EasyOCR Framework
weiyigeek.top-EasyOCR Framework
温馨提示: 图中 灰色插槽是可更换的浅蓝色模块的占位符,我们可以重构代码以支持可交换的检测和识别算法 api
EasyOCR 参考来源 官网地址: https://www.jaided.ai/easyocr/
项目地址: https://github.com/JaidedAI/EasyOCR
实践项目源码地址:https://github.com/WeiyiGeek/SecOpsDev/tree/master/Project/Python/EasyOCR/Travelcodeocr
文档原文地址: https://www.bilibili.com/read/cv16911816
实践视频地址: https://www.bilibili.com/video/BV1nY4y1x7JG
温馨提示: 该项目基于来自多篇论文和开源存储库的研究和代码,所有深度学习执行都基于 Pytorch ,识别模型是 CRNN 它由 3 个主要部分组成:特征提取(我们目前使用 Resnet )和 VGG、序列标记( LSTM )和解码( CTC )。 ❤️
0x01 安装部署 环境依赖 环境依赖
Python 建议 3.8 x64 以上版本 (原本我的环境是 Python 3.7 安装时各种稀奇古怪的错误都出来,不得已abandon放弃)
easyocr 包 -> 依赖 torch 、torchvision 第三方包
注意事项:
Note 1.本章是基于 cpu 与 GPU 下使用 EasyOCR, 如果你需要使用 GPU 跑, 那么请你安装相应的CUDA环境。
1 2 3 4 5 6 7 8 9 10 11 12 13 $ nvidia-smi -l Fri May 27 14:57:57 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA Tesla V1... Off | 00000000:1B:00.0 Off | 0 | | N/A 41C P0 36W / 250W | 0MiB / 32510MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
Note 2.最好在Python 3.8 x64 位系统上安装使用 easyocr , 非常注意其不支持32位的python。
Note 3.对于 Windows,请先按照 https://pytorch.org 的官方说明安装 torch 和 torchvision。 在 pytorch 网站上,请务必选择您拥有的正确 CUDA 版本。 如果您打算仅在 CPU 模式下运行,请选择 CUDA = None。
环境安装 描述: 此处我们使用 pip 安装 easyocr 使用以及通过官方提供的Dockerfile。
pip 方式 1 pip install easyocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
对于最新的开发版本:1 pip install git+git://github.com/jaidedai/easyocr.git
Dockerfile 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 $ cd /opt/images/easyocr && git clone https://github.com/JaidedAI/EasyOCR.git --depth=1 $ ls Dockerfile EasyOCR $ cat Dockerfile FROM pytorch/pytorch LABEL DESC="EasyOCR Enviroment Build with Containerd Images" ARG service_home="/home/EasyOCR" RUN sed -i -e "s#archive.ubuntu.com#mirrors.aliyun.com#g" -e "s#security.ubuntu.com#mirrors.aliyun.com#g" /etc/apt/sources.list && \ apt-get update -y && \ apt-get install -y \ libglib2.0-0 \ libsm6 \ libxext6 \ libxrender-dev \ libgl1-mesa-dev \ git \ vim \ && apt-get autoremove -y \ && apt-get clean -y \ && rm -rf /var/lib/apt/lists COPY ./EasyOCR "$service_home " RUN cd "$service_home " \ && pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ \ && python setup.py build_ext --inplace -j 4 \ && python -m pip install -e .
环境验证 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 pip freeze | findstr "easyocr" easyocr @ file:///E:/%E8%BF%85%E9%9B%B7%E4%B8%8B%E8%BD%BD/easyocr-1.4.2-py3-none-any.whl $ pip freeze | grep "EasyOCR" -e git+https://github.com/JaidedAI/EasyOCR.git@7a685cb8c4ba14f2bc246f89c213f1a56bbc2107 >>> from pprint import pprint >>> import easyocr >>> reader = easyocr.Reader(['ch_sim' ,'en' ]) CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU. >>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png' ) >>> pprint(result) [([[354, 46], [444, 46], [444, 76], [354, 76]], '中国移动' , 0.981803297996521), ([[477, 55], [499, 55], [499, 75], [477, 75]], '46' , 0.3972922105840435), ([[533, 55], [555, 55], [555, 75], [533, 75]], '5G' , 0.5360637875500641), ([[354, 76], [474, 76], [474, 104], [354, 104]], '中国移动四 ' , 0.25950584649873865), ([[489, 57], [625, 57], [625, 95], [489, 95]], 'GMl s @' , 0.011500043801327683), ([[693, 55], [801, 55], [801, 95], [693, 95]], 'Q92%' , 0.022083675488829613), ([[864, 60], [950, 60], [950, 92], [864, 92]], '09:03' , 0.9793587315696877), ([[884, 158], [938, 158], [938, 214], [884, 214]], '@' , 0.29484160211053734), ([[123, 298], [592, 298], [592, 361], [123, 361]], '通信行程卡提供服务>' , 0.6739866899213806), ([[115, 429], [384, 429], [384, 497], [115, 497]], '通信行程卡' , 0.9159307714297187), ([[153, 596], [848, 596], [848, 704], [153, 704]], '通信大数据行程卡' , 0.2522292283860262), ................................ ([[663, 2129], [793, 2129], [793, 2173], [663, 2173]], '保护你我' , 0.9819014668464661)] >>> result = reader.readtext('00e336dbde464c809ef1f6ea568d4621.png' , detail = 0)
使用说明
Note 1.在使easyocr.Reader(['ch_sim','en'])于将模型加载到内存中(可能会耗费一些时间), 并且我们需要设定默认阅读的语言列表, 可以同时使用多种语言,但并非所有语言都可以一起使用, 而通常会采用英语与其他语言联合。
下面列举出可用语言及其语言对应列表 (https://www.jaided.ai/easyocr/ ) :1 2 3 4 5 Simplified Chinese ch_sim Traditional Chinese ch_tra English en
weiyigeek.top-支持识别的语言列表图
温馨提示: 所选语言的模型权重将自动下载,或者您可以从模型中心 并将它们放在~/.EasyOCR/model文件夹中
Note 2.如果--gpu=True设置为True, 而机器又没有GPU支持的化将默认采用 CPU ,所以通常你会看到如下提示:
1 2 CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
Note 3.在reader.readtext(‘参数值’)函数中的参数值,可以是图片路径、也可是图像文件字节或者 OpenCV 图像对象(numpy 数组)以及互联网上图像的URL 等几种方式.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 reader.readtext('chinese.jpg' ) reader.readtext('https://www.weiyigeek.top/wechat.jpg' ) with open("chinese_tra.jpg" , "rb" ) as f: img = f.read() result = reader.readtext(img) img = cv2.imread('chinese_tra.jpg' ) result = reader.readtext(img)
方法参数 描述: 官方提供的包的模块方法以及参数说明, 参考地址 ( https://www.jaided.ai/easyocr/documentation/ )
1.EasyOCR 的基类
1 2 3 4 5 6 easyocr.Reader(['ch_sim' ,'en' ], gpu=False , model_storage_directory="~/.EasyOCR/." ,download_enabled=True , user_network_directory="~/.EasyOCR/user_network" ,recog_network="recog_network" ,detector=True ,recognizer=True )
2.Reader 对象的主要方法, 有 4 组参数:General、Contrast、Text Detection 和 Bounding Box Merging, 其返回值为列表形式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 reader.readtext( 'chinese.jpg' ,image,decoder='greedy' ,beamWidth=5,batch_size=1,workers=0,allowlist="ch_sim" ,blocklist="ch_tra" ,detail=1,paragraph=False,min_size=10,rotation_info=[90, 180 ,270], contrast_ths = 0.1, adjust_contrast = 0.5, text_threshold = 0.7, low_text = 0.4,link_threshold = 0.4, canvas_size = 2560, mag_ratio = 1, slope_ths = 0.1, ycenter_ths = 0.5, height_ths = 0.5, width_ths = 0.5, add_margin = 0.1, x_ths = 1.0, y_ths = 0.5 ) --batch_size : 当其值大于 1 时将使 EasyOCR 更快,但使用更多内存。 --allowlist : 强制 EasyOCR 仅识别字符子集。 对特定问题有用(例如车牌等) --detail : 将此设置为 0 以进行简单输出. --paragraph :将结果合并到段落中 --min_size: 过滤小于像素最小值的文本框 --rotation_info:允许 EasyOCR 旋转每个文本框并返回具有最高置信度分数的文本框。例如,对所有可能的文本方向尝试 [90, 180 ,270]。 --contrast_ths : 对比度低于此值的文本框将被传入模型 2 次,首先是原始图像,其次是对比度调整为“adjust_contrast”值,结果将返回具有更高置信度的那个。 --adjust_contrast : 低对比度文本框的目标对比度级别 --text_threshold: 文本置信度阈值 --link_threshold: 链接置信度阈值 --canvas_size: 最大图像尺寸,大于此值的图像将被缩小。 --mag_ratio: 图像放大率 height_ths (float , default = 0.5) - 盒子高度的最大差异,不应合并文本大小差异很大的框。 width_ths (float , default = 0.5) - 合并框的最大水平距离。 x_ths (float , default = 1.0) - 当段落 = True 时合并文本框的最大水平距离。 y_ths (float , default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
3.detect method, 检测文本框的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Parameters image (string, numpy array, byte) - Input image min_size (int, default = 10) - Filter text box smaller than minimum value in pixel text_threshold (float , default = 0.7) - Text confidence threshold low_text (float , default = 0.4) - Text low-bound score link_threshold (float , default = 0.4) - Link confidence threshold canvas_size (int, default = 2560) - Maximum image size. Image bigger than this value will be resized down. mag_ratio (float , default = 1) - Image magnification ratio slope_ths (float , default = 0.1) - Maximum slope (delta y/delta x) to considered merging. Low value means tiled boxes will not be merged. ycenter_ths (float , default = 0.5) - Maximum shift in y direction. Boxes with different level should not be merged. height_ths (float , default = 0.5) - Maximum different in box height. Boxes with very different text size should not be merged. width_ths (float , default = 0.5) - Maximum horizontal distance to merge boxes. add_margin (float , default = 0.1) - Extend bounding boxes in all direction by certain value. This is important for language with complex script (E.g. Thai). optimal_num_chars (int, default = None) - If specified, bounding boxes with estimated number of characters near this value are returned first. Return horizontal_list, free_list - horizontal_list is a list of regtangular text boxes. The format is [x_min, x_max, y_min, y_max]. free_list is a list of free-form text boxes. The format is [[x1,y1],[x2,y2],[x3,y3],[x4,y4]].
4.recognize method, 从文本框中识别字符的方法,如果未给出 Horizontal_list 和 free_list,它将整个图像视为一个文本框。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Parameters image (string, numpy array, byte) - Input image horizontal_list (list, default=None) - see format from output of detect method free_list (list, default=None) - see format from output of detect method decoder (string, default = 'greedy' ) - options are 'greedy' , 'beamsearch' and 'wordbeamsearch' . beamWidth (int, default = 5) - How many beam to keep when decoder = 'beamsearch' or 'wordbeamsearch' batch_size (int, default = 1) - batch_size>1 will make EasyOCR faster but use more memory workers (int, default = 0) - Number thread used in of dataloader allowlist (string) - Force EasyOCR to recognize only subset of characters. Useful for specific problem (E.g. license plate, etc.) blocklist (string) - Block subset of character. This argument will be ignored if allowlist is given. detail (int, default = 1) - Set this to 0 for simple output paragraph (bool, default = False) - Combine result into paragraph contrast_ths (float , default = 0.1) - Text box with contrast lower than this value will be passed into model 2 times . First is with original image and second with contrast adjusted to 'adjust_contrast' value. The one with more confident level will be returned as a result. adjust_contrast (float , default = 0.5) - target contrast level for low contrast text box Return list of results
0x02 实践案例 1.批量识别行程码图片 描述: 公司有业务需求做一个行程码识别, 当前是调用某云的文字识别接口来识别行程码, 而其按照调用次数进行计费, 所以为了节约成本就要Python参考了Github上大佬的们项目, 截取部分函数,并使用Flask Web 框架进行封装,从而实现通过网页进行请求调用,并返回JSON字符串。
项目源码Github地址:https://github.com/WeiyiGeek/SecOpsDev/tree/master/Project/Python/EasyOCR/Travelcodeocr
项目实践 1 pip install flask -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
步骤 02.项目路径以及图片路径 D:\Study\Project1 2 3 4 5 6 7 PS D:\Study\Project> ls 目录: D:\Study\Project Mode LastWriteTime Length Name ---- ------------- ------ ---- d----- 2022/5/25 15:59 img d----- 2022/5/26 21:17 templates -a---- 2022/5/25 19:34 3966 setup.py
步骤 03.基于Flask web框架下进行调用EasyOCR执行图片文字识别的python代码(v1 版本).1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 import os,sys import cv2 import re import glob import json import easyocr from flask import Flask, jsonify, request,render_template from datetime import datetime from werkzeug.utils import secure_filename import numpy as np import collections app = Flask(__name__) RUNDIR = None IMGDIR = None colorDict= {"red" : "红色" , "red1" : "红色" , "orange" : "橙色" , "yellow" : "黄色" , "green" : "绿色" } def getColorList(): "" " 函数说明: 定义字典存放 HSV 颜色分量上下限 (HSV-RGB) 例如:{颜色: [min分量, max分量]} {'red': [array([160, 43, 46]), array([179, 255, 255])]} 返回值: 专门的容器数据类型,提供Python通用内置容器、dict、list、set和tuple的替代品。 " "" dict = collections.defaultdict(list) lower_red = np.array([156, 43, 46]) upper_red = np.array([180, 255, 255]) color_list = [] color_list.append(lower_red) color_list.append(upper_red) dict['red' ]=color_list lower_red = np.array([0, 43, 46]) upper_red = np.array([10, 255, 255]) color_list = [] color_list.append(lower_red) color_list.append(upper_red) dict['red2' ] = color_list lower_orange = np.array([11, 43, 46]) upper_orange = np.array([25, 255, 255]) color_list = [] color_list.append(lower_orange) color_list.append(upper_orange) dict['orange' ] = color_list lower_yellow = np.array([26, 43, 46]) upper_yellow = np.array([34, 255, 255]) color_list = [] color_list.append(lower_yellow) color_list.append(upper_yellow) dict['yellow' ] = color_list lower_green = np.array([35, 43, 46]) upper_green = np.array([77, 255, 255]) color_list = [] color_list.append(lower_green) color_list.append(upper_green) dict['green' ] = color_list return dict def getTravelcodeColor(img_np): "" " 函数说明: 利用阈值返回行程码主页颜色 参数值: cv2.imread() 读取的图像对象(np数组) 返回值: 行程卡颜色{红、橙、绿} " "" hsv = cv2.cvtColor(img_np, cv2.COLOR_BGR2HSV) maxsum = -100 color = None color_dict = getColorList() for d in color_dict: mask = cv2.inRange(hsv,color_dict[d][0],color_dict[d][1]) binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1] binary = cv2.dilate(binary,None,iterations=2) cnts, hiera = cv2.findContours(binary.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) sum = 0 for c in cnts: sum+=cv2.contourArea(c) if sum > maxsum : maxsum = sum color = d return colorDict[color] def information_filter(file_path,img_np,text_str): "" " 函数说明: 提出ocr识别的行程码 参数值:字符串,文件名称 返回值:有效信息组成的字典 " "" try: re_healthcode = re.compile('请收下(.{,2})行程卡' ) healthcode = re_healthcode.findall(text_str)[0] except Exception as _: healthcode = getTravelcodeColor(img_np) print ("[*] Get Photo Color = " ,healthcode) re_phone = re.compile('[0-9]{3}\*{4}[0-9]{4}' ) phone_str = re_phone.findall(text_str)[0] re_data = re.compile('2022\.[0-1][0-9]\.[0-3][0-9]' ) data_str = re_data.findall(text_str)[0] re_time = re.compile('[0-9][0-9]:[0-9][0-9]:[0-9][0-9]' ) time_str = re_time.findall(text_str)[0] citys_re = re.compile('到达或途经:(.+)结果包含' ) citys_str = citys_re.findall(text_str)[0].strip().split('(' )[0] result_dic = {"status" : "succ" , "file" : file_path ,"类型" : healthcode, "电话" : phone_str, "日期" : data_str, "时间" : time_str, "行程" : citys_str} print ("\033[032m" ,result_dic,"\033[0m" ) return result_dic def getTravelcodeInfo(filename, img_np): "" " 函数说明: 返回以JSON字符串格式过滤后结果 参数值:文件名称,图像作为 numpy 数组(来 opencv传递 返回值:JSON字符串格式 " "" img_gray = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY) _,img_thresh = cv2.threshold(img_gray,180,255,cv2.THRESH_BINARY) text = reader.readtext(img_thresh, detail=0, batch_size=10) result_dic = information_filter(filename, img_np, "" .join(text)) return result_dic @app.route('/' ) @app.route('/index' ) def Index(): return "<h4 style='text-algin:center'>https://www.weiyigeek.top</h4><script>window.location.href='https://www.weiyigeek.top'</script>" @app.route('/tools/ocr' ,methods=["GET" ]) def Travelcodeocr(): "" " 请求路径: /tools/ocr 请求参数: (/tools/ocr?file=20220520/test.png, /tools/ocr?dir=20220520) " "" filename = request.args.get("file" ) dirname = request.args.get("dir" ) if (filename): img_path = os.path.join(IMGDIR, filename) if (os.path.exists(img_path)): print (img_path) img_np = cv2.imread(img_path) try: result_dic_succ = getTravelcodeInfo(filename,img_np) except Exception as err: print ("\033[31m" + img_path + " -->> " + str(err) + "\033[0m" ) return json.dumps({"status" :"err" , "img" : filename}).encode('utf-8' ), 200, {"Content-Type" :"application/json" } return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"status" : "err" ,"msg" : "文件" +img_path+"路径不存在." }) elif (dirname and os.path.join(IMGDIR, dirname)): result_dic_all = [] result_dic_err = [] img_path_all = glob.iglob(os.path.join(os.path.join(IMGDIR,dirname)+"/*.[p|j]*g" )) for img_path in img_path_all: print (img_path) img_np = cv2.imread(img_path) try: result_dic_succ = getTravelcodeInfo(os.path.join(dirname,os.path.basename(img_path)),img_np) except Exception as err: print ("\033[31m" + img_path + " -->> " + str(err) + "\033[0m" ) result_dic_err.append(img_path) continue result_dic_all.append(result_dic_succ) res_succ_json=json.dumps(result_dic_all, ensure_ascii=False) res_err_json=json.dumps(result_dic_err, ensure_ascii=False) with open(os.path.join(IMGDIR, dirname, dirname + "-succ.json" ),'w' ) as succ: succ.write(res_succ_json) with open(os.path.join(IMGDIR, dirname, dirname + "-err.json" ),'w' ) as error: error.write(res_err_json) return res_succ_json.encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"status" : "err" ,"msg" : "请求参数有误!" }) @app.route('/tools/upload/ocr' ,methods=["GET" ,"POST" ]) def TravelcodeUploadocr(): if request.method == 'POST' : unix = datetime.now().strftime('%Y%m%d-%H%M%S%f' ) f = request.files['file' ] if (f.mimetype == 'image/jpeg' or f.mimetype == 'image/png' ): filedate = unix.split("-" )[0] filesuffix = f.mimetype.split("/" )[-1] uploadDir = os.path.join('img' ,filedate) if (not os.path.exists(uploadDir)): os.makedirs(uploadDir) img_path = os.path.join(uploadDir,secure_filename(unix+"." +filesuffix)) print (img_path) f.save(img_path) if (os.path.exists(img_path)): img_np = cv2.imread(img_path) try: result_dic_succ = getTravelcodeInfo(os.path.join(filedate,os.path.basename(img_path)),img_np) except Exception as err: print ("\033[31m" + err + "\033[0m" ) return json.dumps({"status" :"err" , "img" : img_path}).encode('utf-8' ), 200, {"Content-Type" :"application/json" } return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"status" : "err" ,"msg" : "文件" +img_path+"路径不存在!" }) else : return jsonify({"status" : "err" ,"msg" : "不能上传除 jpg 与 png 格式以外的图片" }) else : return render_template('index.html' ) if __name__ == '__main__' : try: RUNDIR = sys.argv[1] IMGDIR = sys.argv[2] except Exception as e: print ("[*] Uage:" + sys.argv[0] + " RUNDIR IMGDIR" ) print ("[*] Default:" + sys.argv[0] + " ./ ./img" + "\n" ) RUNDIR = os.path.abspath(os.curdir) IMGDIR = os.path.join(RUNDIR,"img" ) reader = easyocr.Reader(['ch_sim' , 'en' ], gpu=False) app.run(host='0.0.0.0' , port=8000, debug=True)
步骤 03.运行该脚本并使用浏览进行指定行程码图片路径以及识别提取。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 python .\setup.py
温馨提示: 从上面的Python脚本中可以看出我们可使用file参数指定图片路径或者使用dir参数指定行程码图片存放目录(默认在img目录下的子目录)。
例如,获取单个行程码图片信息,我本地浏览器访问http://127.0.0.1:8000/tools/ocr?file=20220530/00e336dbde464c809ef1f6ea568d4621.png地址,将会返回如下JSON字符串。1 2 3 D:\Study\Project\img\20220530\00e336dbde464c809ef1f6ea568d4621.png 127.0.0.1 - - [01/Jun/2022 16:58:58] "GET /tools/upload/ocr HTTP/1.1" 200 - {'status' : 'succ' , 'file' : '20220530\\00e336dbde464c809ef1f6ea568d4621.png' , '类型' : '绿色' , '电话' : '157****2966' , '日期' : '2022.05.25' , '时间' : '09:03:56' , '行程' : '重庆市' }
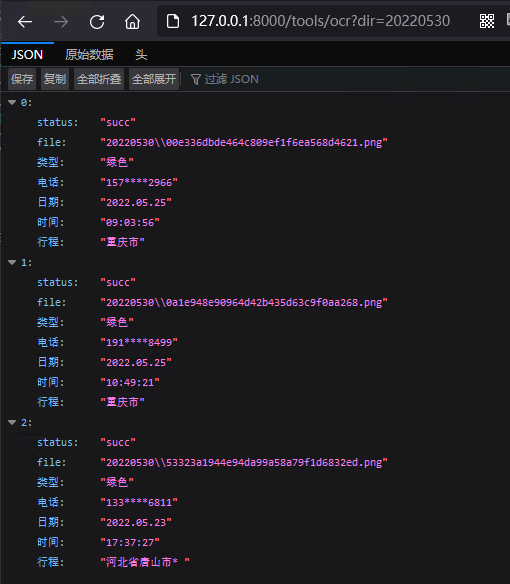
例如,获取多个行程码图片识别信息,我本地浏览器访问http://127.0.0.1:8000/tools/ocr?dir=20220530地址,将会返回如下图所示结果。
weiyigeek.top-批量获取行程码图片信息
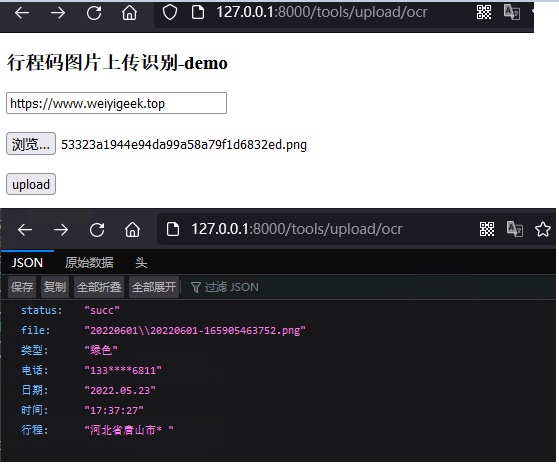
例如, 我们可以上传并识别行程码图片信息,本地浏览器访问http://127.0.0.1:8000/tools/upload/ocr地址,将会返回如下图所示结果。
weiyigeek.top-上传并识别行程码图片信息
0x03 代码迭代 温馨提示: 如下环境依赖与模块安装, 建议 Python 3.8.x 的环境下进行.
mylogger.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 import osimport loggingfrom logging.handlers import TimedRotatingFileHandlerLOG_PATH = "log" LOG_INFO = '_info.log' LOG_ERROR = '_error.log' class logger : def __init__ (self, prefix_name = "flask" ) : if (not os.path.exists(LOG_PATH)): os.makedirs(LOG_PATH) self.prefix = prefix_name self.info_logger = logging.getLogger("info" ) self.error_logger = logging.getLogger("error" ) self.info_logger.setLevel(logging.DEBUG) self.error_logger.setLevel(logging.ERROR) self.format = logging.Formatter('[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s] : %(message)s' ) TimeFileHandlerINFO = TimedRotatingFileHandler("%s/%s%s" % (LOG_PATH, prefix_name, LOG_INFO), when='MIDNIGHT' , encoding="utf-8" , backupCount=8760 , delay=True ) TimeFileHandlerINFO.suffix = "%Y-%m-%d.log" TimeFileHandlerERROR = TimedRotatingFileHandler("%s/%s%s" % (LOG_PATH, prefix_name, LOG_ERROR), when='MIDNIGHT' , encoding="utf-8" , backupCount=8760 , delay=True ) TimeFileHandlerERROR.suffix = "%Y-%m-%d.log" LoggerStream = logging.StreamHandler() TimeFileHandlerINFO.setFormatter(self.format) TimeFileHandlerERROR.setFormatter(self.format) LoggerStream.setFormatter(self.format) self.info_logger.addHandler(TimeFileHandlerINFO) self.error_logger.addHandler(TimeFileHandlerERROR) def debug (self, msg, *args, **kwargs) : self.info_logger.debug(msg, *args, **kwargs) def info (self, msg, *args, **kwargs) : self.info_logger.info(msg, *args, **kwargs) def warn (self, msg, *args, **kwargs) : self.info_logger.warning(msg, *args, **kwargs) def error (self, msg, *args, **kwargs) : self.error_logger.error(msg, *args, **kwargs) def fatal (self, msg, *args, **kwargs) : self.error_logger.fatal(msg, *args, **kwargs) def critical (self, msg, *args, **kwargs) : self.error_logger.critical(msg, *args, **kwargs)
setup.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 import os import cv2 import re import glob import json import easyocr import logging import collections import argparse import numpy as np from flask import Flask, jsonify, request,render_template from datetime import datetime from werkzeug.utils import secure_filename from gevent import pywsgi from mylogger import logger from logging.handlers import RotatingFileHandler from geventwebsocket.handler import WebSocketHandler app = Flask(__name__) parser = argparse.ArgumentParser(description="本程序利用 easyocr 进行图像文字识别,实现行程码与健康码的识别, 本项目为开源欢迎各位大佬提供更好的方法." ,prog='setup.py ' ,epilog="Author: WeiyiGeek, Blog: www.weiyigeek.top" )parser.add_argument('--rundir' ,dest="rundir" , type =str, help ="指定程序运行目录" , required=False, default="./" ) parser.add_argument('--imgdir' ,dest="imgdir" , type =str, help ="指定图像存放目录" , required=False, default="./img" ) parser.add_argument('--logdir' ,dest="logdir" , type =str, help ="指定程序日志存放目录" , required=False, default="./log" ) parser.add_argument('--gpu' ,dest="gpu" , type =bool, help ="指定是否使用GPU执行计算(缺省: Flase)" , required=False, default=False) parser.add_argument('--ip' ,dest="ip" , type =str, help ="指定服务监听网卡(缺省: 0.0.0.0)" , required=False, default="0.0.0.0" ) parser.add_argument('--port' ,dest="port" , type =int, help ="指定服务的端口(缺省: 8000)" , required=False, default=8000) args = parser.parse_args() RUNDIR = args.rundir IMGDIR = args.imgdir IMGCV2 = None codeDict = {"green" : "绿码" , "yellow" : "黄码" , "red" : "红码" , "other" : "暂时无法确认" } colorDict = {"red" : "红色" , "red1" : "红色" , "orange" : "橙色" , "yellow" : "黄色" , "green" : "绿色" } def getColorList(): "" " 函数说明: 定义字典存放 HSV 颜色分量上下限 (HSV-RGB) 例如:{颜色: [min分量, max分量]} {'red': [array([160, 43, 46]), array([179, 255, 255])]} 返回值: 专门的容器数据类型,提供Python通用内置容器、dict、list、set和tuple的替代品。 " "" dict = collections.defaultdict(list) lower_red = np.array([156, 43, 46]) upper_red = np.array([180, 255, 255]) color_list = [] color_list.append(lower_red) color_list.append(upper_red) dict['red' ]=color_list lower_red = np.array([0, 43, 46]) upper_red = np.array([10, 255, 255]) color_list = [] color_list.append(lower_red) color_list.append(upper_red) dict['red2' ] = color_list lower_orange = np.array([11, 43, 46]) upper_orange = np.array([25, 255, 255]) color_list = [] color_list.append(lower_orange) color_list.append(upper_orange) dict['orange' ] = color_list lower_yellow = np.array([26, 43, 46]) upper_yellow = np.array([34, 255, 255]) color_list = [] color_list.append(lower_yellow) color_list.append(upper_yellow) dict['yellow' ] = color_list lower_green = np.array([35, 43, 46]) upper_green = np.array([77, 255, 255]) color_list = [] color_list.append(lower_green) color_list.append(upper_green) dict['green' ] = color_list return dict def getTravelcodeColor(img_np): "" " 函数说明: 利用阈值返回行程码主页颜色 参数值: cv2.imread() 读取的图像对象(np数组) 返回值: 行程卡颜色{红、橙、绿} " "" hsv = cv2.cvtColor(img_np, cv2.COLOR_BGR2HSV) maxsum = -100 color = None color_dict = getColorList() for d in color_dict: mask = cv2.inRange(hsv,color_dict[d][0],color_dict[d][1]) binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1] binary = cv2.dilate(binary,None,iterations=2) cnts, hiera = cv2.findContours(binary.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) sum = 0 for c in cnts: sum+=cv2.contourArea(c) if sum > maxsum : maxsum = sum color = d return colorDict[color] def health_filter(file_path, img_np ,text_str): "" " 函数说明: ocr识别的健康码 参数值:字符串,文件名称 返回值:有效信息组成的字典 " "" try: result_dic = None for i in codeDict: if (text_str.find(codeDict[i]) > 0) : result_dic = {"code" : 200,"msg" : "成功获取健康码图片数据为有健康码状态." , "data" :{"file" : file_path ,"type" : codeDict[i]}} if ( i == "other" ): result_dic = {"code" : 200,"msg" : "成功获取健康码图片数据为无码." , "data" :{"file" : file_path ,"type" : "无码" }} break else : result_dic = {"code" : 0,"msg" : "识别健康码图片数据未在字典范围内." , "data" :{"file" : file_path ,"type" : "未知" }} return result_dic except Exception as _: result_dic = {"code" : 0,"msg" : "识别健康码图片数据失败." , "data" :{"file" : file_path ,"type" : "未知" }} return result_dic def getHealthCodeInfo(filename, img_np): "" " 函数说明: 获取健康码信息 参数值:文件名称, 图像作为 numpy 数组进行opencv传递 返回值:返回以JSON字符串格式过滤后结果 " "" text = reader.readtext(img_np, detail=0, batch_size=64) result_dic = health_filter(filename, img_np, "" .join(text)) return result_dic def travel_filter(file_path,img_np,text_str): "" " 函数说明: ocr识别的行程码 参数值:字符串,文件名称 返回值:有效信息组成的字典 " "" try: re_healthcode = re.compile('请收下(.{,2})行程卡' ) healthcode = re_healthcode.findall(text_str)[0] except Exception as _: healthcode = getTravelcodeColor(img_np) print ("[*] Get Photo Color = " ,healthcode) re_phone = re.compile('[0-9]{3}\*{4}[0-9]{4}' ) phone_str = re_phone.findall(text_str)[0] re_data = re.compile('2022\.[0-1][0-9]\.[0-3][0-9]' ) data_str = re_data.findall(text_str)[0] time_str = "null" citys_re = re.compile('到达或途经:(.+)结果包含' ) citys_str = citys_re.findall(text_str)[0].strip().split('(' )[0] result_dic = {"code" : 200,"msg" : "成功获取行程码数据." , "data" :{"file" : file_path ,"type" : healthcode, "phone" : phone_str, "date" : data_str, "time" : time_str, " travel" : citys_str}} return result_dic def getTravelCodeInfo(filename, img_np): "" " 函数说明: 返回以JSON字符串格式过滤后结果 参数值:文件名称,图像作为numpy数组进行opencv传递 返回值:JSON字符串格式 " "" img_gray = cv2.cvtColor(img_np, cv2.COLOR_BGR2GRAY) _,img_thresh = cv2.threshold(img_gray,166,255,cv2.THRESH_BINARY) text = reader.readtext(img_thresh, detail=0, batch_size=1) result_dic = travel_filter(filename, img_np, "" .join(text)) return result_dic @app.route('/' ) @app.route('/index' ) def Index(): return render_template('index.html' ) @app.route('/api/v1/ocr/health' ,methods=["GET" ]) def Travelcodeocr(): "" " 请求路径: /api/v1/ocr/health 请求参数: (/api/v1/ocr/health?action=['jkm','xcm']&file=20220520/test.png) " "" action = request.args.get("action" ) filename = request.args.get("file" ) if (action and filename): img_path = os.path.join(IMGDIR, filename) if (os.path.exists(img_path)): log.info("Path: " + img_path) IMGCV2 = cv2.imread(img_path) try: if (action == "jkm" ): result_dic_succ = getHealthCodeInfo(filename,IMGCV2) else : result_dic_succ = getTravelCodeInfo(filename,IMGCV2) except Exception as err: result_dic_err = {"code" : 0,"msg" : "图像数据获取异常, 请调用第三方接口识别." ,"data" :{"action" : action,"file" : filename ,"type" : "未知" }} log.error(str(err) + ":" + str(result_dic_err)) return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } log.info(result_dic_succ) return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : result_dic_err={"code" : 0,"msg" : "图像数据获取异常, 文件" + filename + "或者路径不对, 请检查." } log.error(str(result_dic_err)) return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"code" : "0" ,"msg" : "请求参数有误!" }) @app.route('/api/v1/ocr/health/dir' ,methods=["GET" ,"POST" ]) def TravelcodeMultipleocr(): "" " 请求路径: /api/v1/ocr/health/dir 请求参数: /api/v1/ocr/health/dir?action=['jkm','xcm']&dir=20220520 " "" action = request.args.get("action" ) dirname = request.args.get("dir" ) if (action and dirname and os.path.join(IMGDIR, dirname)): result_dic_all = [] result_dic_err = [] img_path_all = glob.iglob(os.path.join(os.path.join(IMGDIR,dirname)+"/*.[p|j]*g" )) for img_path in img_path_all: IMGCV2 = cv2.imread(img_path) try: if (action == "jkm" ): result_dic_succ = getHealthCodeInfo(os.path.join(dirname,os.path.basename(img_path)),IMGCV2) elif (action == "xcm" ): result_dic_succ = getTravelCodeInfo(os.path.join(dirname,os.path.basename(img_path)),IMGCV2) else : log.error("\033[31m 参数有误 -->> " + str(err) + "\033[0m" ) break except Exception as err: log.error("\033[31m" + img_path + " -->> " + str(err) + "\033[0m" ) result_dic_err.append(img_path) continue result_dic_all.append(result_dic_succ) res_succ_json=json.dumps(result_dic_all, ensure_ascii=False) res_err_json=json.dumps(result_dic_err, ensure_ascii=False) with open(os.path.join(IMGDIR, dirname, dirname + "-succ.json" ),'w' ) as succ: succ.write(res_succ_json) with open(os.path.join(IMGDIR, dirname, dirname + "-err.json" ),'w' ) as error: error.write(res_err_json) return res_succ_json.encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"code" : "0" ,"msg" : "请求参数有误!" }) @app.route('/api/v1/ocr/health/upload' ,methods=["GET" ,"POST" ]) def TravelcodeUploadocr(): if request.method == 'POST' : unix = datetime.now().strftime('%Y%m%d-%H%M%S%f' ) action = request.form["action" ] f = request.files['file' ] if (f.mimetype == 'image/jpeg' or f.mimetype == 'image/png' ): filedate = unix.split("-" )[0] filesuffix = f.mimetype.split("/" )[-1] uploadDir = os.path.join('img' ,filedate) if (not os.path.exists(uploadDir)): os.makedirs(uploadDir) img_path = os.path.join(uploadDir,secure_filename(unix+"." +filesuffix)) f.save(img_path) log.info("识别类型: " + action + ", 图片路径:" + img_path) if (os.path.exists(img_path)): IMGCV2 = cv2.imread(img_path) try: if (action == "jkm" ): result_dic_succ = getHealthCodeInfo(os.path.join(filedate,os.path.basename(img_path)),IMGCV2) else : result_dic_succ = getTravelCodeInfo(os.path.join(filedate,os.path.basename(img_path)),IMGCV2) except Exception as err: result_dic_err = {"code" : 0,"msg" : "图像数据获取异常, 请调用第三方接口识别." ,"data" :{"action" : "upload" ,"img_path" : img_path ,"type" : "未知" }} log.error(str(err) + "-" + str(result_dic_err)) return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } log.info(str(result_dic_succ)) return json.dumps(result_dic_succ, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : result_dic_err={"code" : 0,"msg" : "图像数据获取异常, 文件" +img_path+"或者路径不对, 请检查." } log.error(str(result_dic_err)) return json.dumps(result_dic_err, ensure_ascii=False).encode('utf-8' ), 200, {"Content-Type" :"application/json" } else : return jsonify({"status" : "err" ,"msg" : "不能上传除 jpg 与 png 格式以外的图片" }) else : return render_template('upload.html' ) if __name__ == '__main__' : log = logger("app" ,args.logdir) logging.basicConfig(level=logging.INFO) file_log_handler = RotatingFileHandler("log/console.log" , maxBytes=1024 * 1024 * 100, backupCount=10, encoding="utf-8" ) formatter = logging.Formatter('%(levelname)s - %(message)s' ) file_log_handler.setFormatter(formatter) logging.getLogger().addHandler(file_log_handler) reader = easyocr.Reader(['ch_sim' , 'en' ], gpu=args.gpu, detector=True, recognizer=True) server = pywsgi.WSGIServer((args.ip, args.port), app, handler_class=WebSocketHandler) server.serve_forever()
程序说明: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 usage: setup.py [-h] [--rundir RUNDIR] [--imgdir IMGDIR] [--logdir LOGDIR] [--gpu GPU] [--ip IP] [--port PORT] 本程序利用 easyocr 进行图像文字识别,实现行程码与健康码的识别, 本项目为开源欢迎各位大佬提供更好的方法. optional arguments: -h, --help show this help message and exit --rundir RUNDIR 指定程序运行目录 --imgdir IMGDIR 指定图像存放目录 --logdir LOGDIR 指定程序日志存放目录 --gpu GPU 指定是否使用GPU执行计算(缺省: Flase) --ip IP 指定服务监听网卡(缺省: 0.0.0.0) --port PORT 指定服务的端口(缺省: 8000) Author: WeiyiGeek, Blog: www.weiyigeek.top
程序执行: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 python ./setup.py --imgdir=/imgs --logdir=/logs --ip=0.0 .0 .0 --port=8000 --gpu=True $ kubectl create ns devtest $ kubectl apply -f healthcode-sts.yaml $ kubectl get pod -n devtest NAME READY STATUS RESTARTS AGE healthcode-0 -5 1 /1 Running 0 15 h healthcode-0 -4 1 /1 Running 0 15 h healthcode-0 -3 1 /1 Running 0 15 h healthcode-0 -2 1 /1 Running 0 15 h healthcode-0 -1 1 /1 Running 0 15 h healthcode-0 -0 1 /1 Running 0 15 h nvidia-smi Fri Dec 9 10 :08 :32 2022 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 465.19 .01 Driver Version: 465.19 .01 CUDA Version: 11.3 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA Tesla V1... Off | 00000000 :1 B:00.0 Off | 0 | | N/A 41 C P0 36 W / 250 W | 6697 MiB / 32510 MiB | 0 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 1 NVIDIA Tesla V1... Off | 00000000 :1 D:00.0 Off | 0 | | N/A 51 C P0 53 W / 250 W | 9489 MiB / 32510 MiB | 14 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 2 NVIDIA Tesla V1... Off | 00000000 :3 D:00.0 Off | 0 | | N/A 53 C P0 42 W / 250 W | 5611 MiB / 32510 MiB | 20 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 3 NVIDIA Tesla V1... Off | 00000000 :3 F:00.0 Off | 0 | | N/A 37 C P0 35 W / 250 W | 10555 MiB / 32510 MiB | 0 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 4 NVIDIA Tesla V1... Off | 00000000 :40 :00.0 Off | 0 | | N/A 45 C P0 51 W / 250 W | 5837 MiB / 32510 MiB | 5 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 5 NVIDIA Tesla V1... Off | 00000000 :41 :00.0 Off | 0 | | N/A 37 C P0 37 W / 250 W | 10483 MiB / 32510 MiB | 0 % Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 167660 C python 6693 MiB | | 1 N/A N/A 166790 C python 9485 MiB | | 2 N/A N/A 165941 C python 5607 MiB | | 3 N/A N/A 165032 C python 10551 MiB | | 4 N/A N/A 164226 C python 5833 MiB | | 5 N/A N/A 163344 C python 10479 MiB | +-----------------------------------------------------------------------------+
最新脚本可访问博主Github [ https://github.com/WeiyiGeek/SecOpsDev/edit/master/Project/Python/EasyOCR/Travelcodeocr/Readme.md ]
0x04 入坑出坑 问题1.通过pip install 安装easyocr离线的whl包是报ERROR: No matching distribution found for torch
错误信息:1 2 3 pip install ./easyocr-1.4.2-py3-none-any.whl -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com ERROR: Could not find a version that satisfies the requirement torch (from easyocr) (from versions: none) ERROR: No matching distribution found for torch
解决办法: python.exe -m pip install --upgrade pip
问题2.在Python3.7的环境中安装easyocr依赖的torch模块的whl安装包报not a supported wheel on this platform.错误
错误信息:1 2 3 4 $ pip install torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple/ WARNING: Requirement 'torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl' looks like a filename, but the file does not exist Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple/ ERROR: torch-1.8.0+cpu-cp37-cp37m-win_amd64.whl is
错误原因: 平台与下载的whl不符合, 此处我遇到的问题明显不是这个导致的,百度后我想是由于pip版本与python版本、以及系统平台联合导致。
解决办法: 1 2 3 4 5 文件名解释:cpu或显卡/文件名-版本号-python版本-应该是编译格式-平台-cpu类型(intel也选amd64)
问题3.在执行调用torch模块的py脚本时报`Error loading “D:** \lib\site-packages\torch\lib\asmjit.dll” or one of its dependencies.`错误**
错误信息:1 2 3 4 5 Microsoft Visual C++ Redistributable is not installed, this may lead to the DLL load failure. It can be downloaded at https://aka.ms/vs/16/release/vc_redist.x64.exe Traceback (most recent call last): ..... OSError: [WinError 193] <no description> Error loading "D:\Program Files (x86)\Python37-32\lib\site-packages\torch\lib\asmjit.dll" or one of its dependencies.
解决办法: 在你的电脑上下载安装 https://aka.ms/vs/16/release/vc_redist.x64.exe 缺少的C++运行库,重启电脑。
问题4.在安装opencv_python_headless进行依赖模块安装时报ERROR: No matching distribution found for torchvision>=0.5错误
错误信息:1 2 3 Using cached https://mirrors.aliyun.com/pypi/packages/a4/0a/39b102047bcf3b1a58ee1cc83a9269b2a2c4c1ab3062a65f5292d8df6594/opencv_python_headless-4.5.4.60-cp37-cp37m-win32.whl (25.8 MB) ERROR: Could not find a version that satisfies the requirement torchvision>=0.5 (from easyocr) (from versions: 0.1.6, 0.1.7, 0.1.8, 0.1.9, 0.2.0, 0.2.1, 0.2.2, 0.2.2.post2, 0.2.2.post3) ERROR: No matching distribution found for torchvision>=0.5
解决办法: 如果你的 python 版本为3.7.x,那么你只能安装 torch 1.5 和 torchvision0.6。
问题5.在执行easyocr文字识别时出现Downloading detection model, please wait. This may take several minutes depending upon your network connection.提示
问题描述: 在首次使用时会自动下载EasyOCR模块所需的模型, 而由于国内网络环境,通常会报出超时错误,此时我们提前从官网下载其所需的数据模型,并安装在指定目录中。
模型下载: https://www.jaided.ai/easyocr/modelhub/ 1 2 3 4 5 6 7 8 9 10 11 english_g2 : https://github.com/JaidedAI/EasyOCR/releases/download/v1.3/english_g2.zip zh_sim_g2 : https://github.com/JaidedAI/EasyOCR/releases/download/v1.3/zh_sim_g2.zip CRAFT : https://github.com/JaidedAI/EasyOCR/releases/download/pre-v1.1.6/craft_mlt_25k.zip C:\Users\WeiyiGeek\.EasyOCR\model /home/weiyigeek/.EasyOCR\model