[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/s0h4391GpnmYq_8IrVKEqw
13.文件结构 在计算机中我们知道,文件被存储在辅助存储设备中,那它究竟是如何存储以及被索引的呢? 这将会在本小节中了解到。
文件是作为一个单元看待的相关数据的外部集合。文件的主要目的是存储数据。因为当计算机关机后,主存的内容将丢失,所以我们需要文件用更持久的形式存储数据,因此文件通常是存储在辅助存储设备 或二级存储设 备中,最常见的二级存储设备是磁盘(机械、SSD固态)和磁带(过去式了),通常文件在二级存储设备中是可读写的,也可以设定权限拥有只读权限。
按照我们的意图,文件是数据记录的集合,每一个记录都由一个或多个域组成。在设计一个文件时,关键问题是如何从文件中检索信息(一个特定的记录),有时需要一个接一个地处理记录,有时又需要快速存取一个特定的记录而不用检索前面的记录,所以通常存取方法决定了怎样检索记录(顺序的 或 随机的)
例如,在系统监视器上显示的信息,就是一种类似于发送到打印机的数据形式的文件。广义上,键盘也是文件,虽然它并不能存储数据。
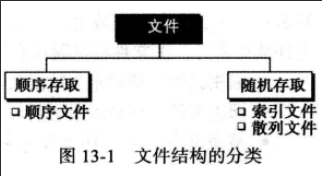
13.1 文件结构分类 (1) 顺序存取 什么时候使用顺序存取?
如果需要顺序地存取记录(一个接一个,从头到尾),则使用顺序文件结构。
(2) 随机存取 什么时候使用随机存取?
如果想存取某一特定记录而不用检索其之前的所有记录,则使用允许随机存取的文件结构。索引文件和散列文件。
文件结构的分类方法如下图所示:
weiyigeek.top-文件结构分类
13.2 顺序文件 定义:顺序文件是指记录只能按照顺序从头到尾一个接一个地进行存取。
通常记录被一个接一个地存储到辅助存储器(磁带或磁盘)中,并在最后的记录加上EOF (文件末尾)的标志,操作系统没有有关记录地址(但记录了磁盘分区)的信息,它只知道记录是一个挨着一个存取的。
应用: 顺序文件用于需要从头到尾存取记录的场景。
例如,将公司里每个职员个人资料存储于一个文件中,月底就可以通过顺序存取检索每条记录来打印工资,因为需要对每一位员工进行处理记录,所以顺序存取比随机存取更简便有效。
然而,顺序文件对随机存取来说效率并不高。例如,如果一个银行的所有客户记录只能被顺序存取,那么一个客户想从自动取款机中提款,就要等到系统从头开始查找直到找到这名客户的信息。如果这个银行有100万个客户,系统在查到记录之前平均要检索50万个记录,效率是非常低的。
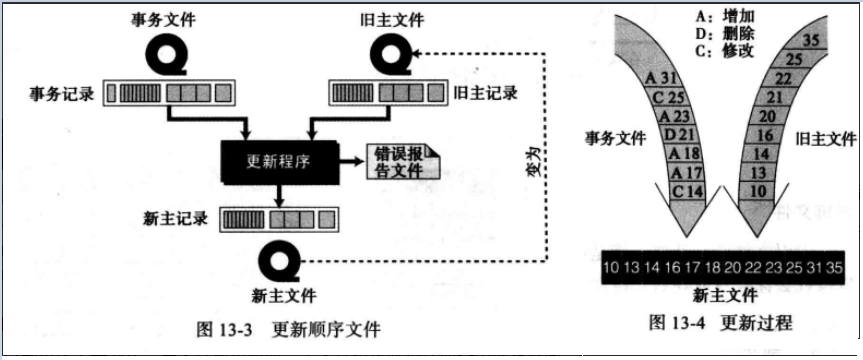
顺序文件更新与过程
描述: 顺序文件必须定期更新,以反映信息的变化。更新过程将非常棘手,因为所有记录都要被顺序地检査和更新(必要的话)。
与更新程序有关的一共有4个文件,新主文件、旧主文件、事务文件和错误报告文件,如下图所示,虽然我们用了磁带的符号表示文件,但是我们可以很容易用磁盘的符号表示。
注意在更新完成之后,新主文件要被送到脱机存储器中去,直到再次需要为止。当文件被更新时,主文件将从脱机存储器中检索返回,成为旧主文件。
新主文件:新的永久数据文件通常称为新主文件。新的主文件里包含大部分当前数据。
旧主文件:它是需要更新的永久文件。即使在更新后,旧主文件作为参考将继续保留。
事务文件:第三种文件是事务文件。它包含将要对主文件作的改变。在所有的文件更新中,一共有三种基本类型的改变。添加事务包含将要追加到主文件中的新数据。删除事务把将要从文件中删除的记录标识出来。而更改事务则包含对文件中特定记录的修改。要处理这些事务就需要键。键就是文件中一个或多个能唯一标识数据的字段。例如,在一个关于学生的文件里,键是学生的学号。在一个关于雇员的文件里,键是社会保险号。
错误报告文件:在更新程序中需要的第4个文件是错误报告文件。更新过程中难免不出任何错误。当错误发生时,应向用户报告错误。错误报告包括在数据更新时所发现的错误的清单,并且提供给用户以进行纠错操作。
要使文件更新过程有效率,所有文件都必须按同一个键排序,更新过程要求比较事务文件和主文件中的键,假定在没有错误发生的情况下,更新过程遵循以下步骤(如下图所示):
1)如果事务文件的键小于主文件的键,事务就是一个增加 (A),则将事务追加到新主文件中。
2)如果事务文件的键与主文件的相同,则
3)如果事务文件的键大于主文件的键,将旧主文件记录写入新主文件。
4)有几种情况可能产生一个错误,错误被记录在错误报告文件中:
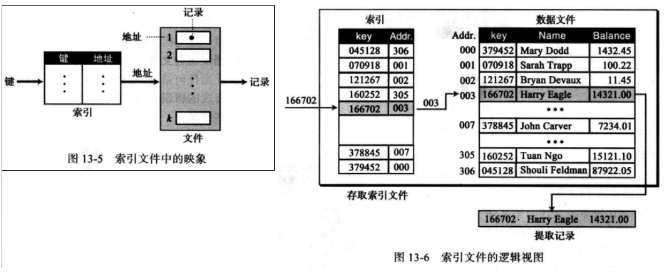
13.3 索引文件 如果想在文件中随机存取记录,我们就必须知道其记录的地址,而索引文件可以把信息和记录地址关联(对应)起来,即索引将键映射到地址。
索引文件由数据文件组成,它是带索引的顺序文件,索引本身非常小,只占两个字段顺序文件的键和在磁盘上相应记录的地址,所以说索引是基于数据文件的关键字值排序。
例如,一个客户想要查询银行账户,通常会有银行卡或者身份证(理解为Key,身份识别),交于柜台人员进行查询。
由图可知,索引文件的好处之一就是可以有多个索引,每个索引有不同的键,我们熟知的Redis内存数据库。
例如,职员的名单文件可以按社会保险号或姓名来检索,这种索引文件被称为倒排文件。
索引存取过程 :
1 )整个索引文件都载入内存中(文件很小,只占用很小的内存空间)。
2)搜索项目,用高效的算法(如折半查找法)査找目标键。
3)检索记录的地址。
4)按照地址,检索数据记录并返回给用户。
.
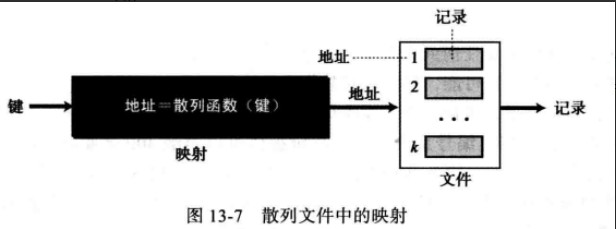
13.4 散列文件 散列文件用一个数学函数来完成映射,用户给出键,函数将键映射成地址,再传送给操作系统,以此完成检索记录。
weiyigeek.top-散列文件中的映射
索引文件与散列文件间的区别:
在索引文件中,必须将文件的索引保存在磁盘上,当需要处理数据文件时,先要把索引导入内存中,搜索索引找到数据记录的地址,再访问数据文件存取记录。
在散列文件中,用函数来寻找地址,这里不需要索引和随之而来的所有开销,然而散列文件自身也存在问题。
注意:散列文件无需额外的文件(索引),在键-地址(K/V)映射中,可以选择多种散列方法中的一种。例如,直接散列法、求模法、数字析取法、以及其他流行的方法(像平方中值法、折叠法、旋转法和伪随机法)。
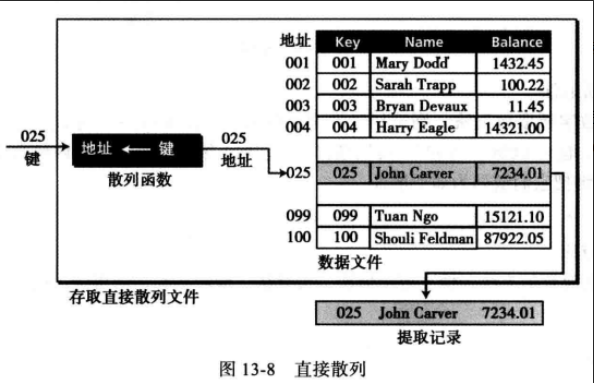
(1) 直接散列法 在直接散列法中,键是未经算法处理的数据文件地址,文件因此必须对每个可能的键都包含一个记录。
虽然用直接散列的情况很少,但它非常有用,因为它保证没有其他方法所存在的同义词或冲突问题(唯一性)。
假如,有一个机构,雇员少于100名,每个雇员都被分配一个1到100之间的编号(雇员ID)。在这种情形下,如果建立了一个有100个记录的文件,雇员的编号可以作为任何单独记录的地址;如图所示,键为025 (John Carver)的记录被散列为地址(扇区)025 ,虽然这是一种理想的方法,但它的应用非常有限。
例如,用社会保险号作为键效率是非常低下的,因为社会保险号有9位。这样需要一个有999 999 999条记录的巨大文件,但是可能只用到不到100条记录。因此,让我们把注意力转到可以把大量可能的键映射为一个小的地址空间的散列技术。
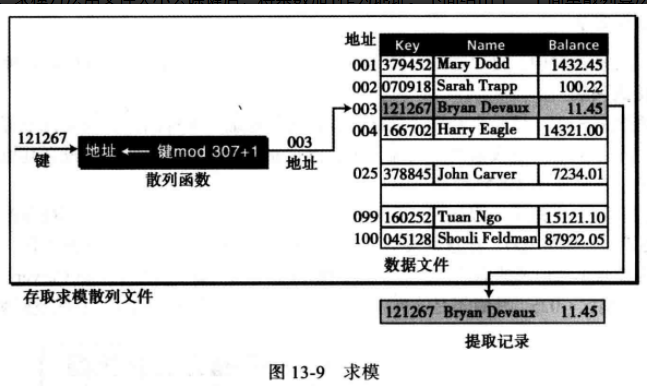
(2) 求模法 求模法也称为除余散列法,求模方法用文件大小去除键后,将余数加1作为地址;
例如下面给出了一个简单散列算法,此处list_size是文件中元素的数目,求模运算的结果加1是因为我们的表始于1而不是0。
address = (Key mod List_size) + 1
虽然这个算法适用于任何列表大小,但是一个为素数的列表大小要比其他的列表大小产生更少的冲突。因此只要可能,尽量用素数作为文件的大小。
例如,创建一个新的可以处理100万雇员的雇员编号系统,同时决定提供可以容纳300名雇员的数据空间,第一个大于300的素数是307,因此选择307作为列表(文件)的大小。
在这种情况下,Bryan Devaux,其键为 121267,被散列到地址 003, 因为 121267 mod 307 = 2, 然后再加1, 就可以得到地址003。
(3) 数字析取法 使用该方法,则选择从键中析取的数字作为地址。
例如,从6位的员工编号中析取3位地址(000- 999),可以选择(从左数)第一、第三和第四位数作为地址。
如,125870 →158 ,122801→ 128 ,121267 → 112
当然,除开上述方法,还有其他流行的方法,像平方中值法、折叠法、旋转法和伪随机法
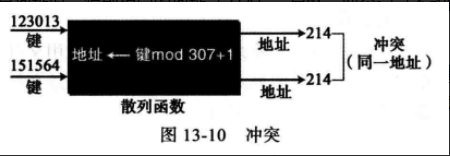
(4) 冲突解决法 通常散列列表中键的数量比在数据文件中的记录数量要多。
例如,如果你有一个包含50名学生的班级的文件,学生由最后4位社会保险号标识,这样在文件中每个元素就有200 个可能的键(10 000/50 ).因为在文件中有很多键对应于一个地址,有可能多于一个的键将被散列为文件中的同一个地址,我们把列表中一些映射为同一地址的键称为同义词。
例如,下图中,当为两个不同的记录计算地址时,得到相同的地址(214)。显然,两个记录不能储存在同一个地址之中,需要按照下一节所讨论的来解决这种情况。冲突的产生是在散列算法为插入键产生地址时,发现该地址已被占用。
weiyigeek.top-地址冲突
由散列算法产生的地址称为内部地址,包含所有内部地址的区域称为主区。当两个键在内部地址上冲突时,必须将其中一个键和数据存放到主区外的另一个地址单元中来解决冲突。
如何解决此种冲突呢?
我们可以采用如下几种方法来处理冲突,每种都不依赖于散列算法开放寻址/链表解决法/桶散列法/组合方法
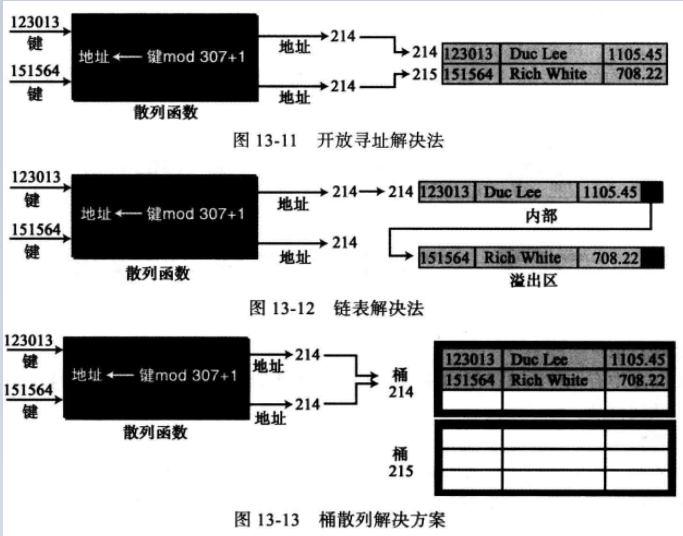
开放寻址法:解决在主区的冲突,当一个冲突发生时,主区地址将査找开放的或空闲的记录来用于存放新数据。对于不能在内部地址中存放的数据,一种简单的策略就是把该数据存储在内部地址的下一个地址中去(内部地址+1),但它有个主要缺点是每个冲突的解决增加了将来冲突的可能性。
图13-11 展示了如何用开放寻址解决法解决图13-10中的冲突,第一个记录存在地址214中,下一个记录存在地址215中。
链表解决法:第一条记录存储在内部地址,但它包含了一个指向下一条记录的指针。
图13-12展示了用此方法如何解决图13-10中冲突的情况,可以使用此方法来解决开放寻址主要缺点。
桶散列法:桶是一能接纳多个记录的节点,这种方法的缺点是可能有很多浪费的(未占用的)存储单元。
图13-13展示了如何用桶散列法解决图13-10中的冲突
组合方法:正如散列方法一样,复杂的实现方法通常是组合使用多种方法。
weiyigeek.top-散列方法解决办法
13.5 目录文件 目录是大多数操作系统提供的,用来组织文件(就像是档案柜中的文件夹一样)。但是在大多数操作系统OS中,目录被表示为含有其他文件信息的一种特殊文件类型。
目录的作用不仅仅像一种索引文件,该索引文件告诉操作系统文件在辅助存储设备上的位置,目录还包含了关于它所包含的文件的其他信息,如:谁有访问文件的权限,文件被创建、存取和修改的日期。
[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/s0h4391GpnmYq_8IrVKEqw
13.文件结构 在计算机中我们知道,文件被存储在辅助存储设备中,那它究竟是如何存储以及被索引的呢? 这将会在本小节中了解到。
文件是作为一个单元看待的相关数据的外部集合。文件的主要目的是存储数据。因为当计算机关机后,主存的内容将丢失,所以我们需要文件用更持久的形式存储数据,因此文件通常是存储在辅助存储设备 或二级存储设 备中,最常见的二级存储设备是磁盘(机械、SSD固态)和磁带(过去式了),通常文件在二级存储设备中是可读写的,也可以设定权限拥有只读权限。
按照我们的意图,文件是数据记录的集合,每一个记录都由一个或多个域组成。在设计一个文件时,关键问题是如何从文件中检索信息(一个特定的记录),有时需要一个接一个地处理记录,有时又需要快速存取一个特定的记录而不用检索前面的记录,所以通常存取方法决定了怎样检索记录(顺序的 或 随机的)
例如,在系统监视器上显示的信息,就是一种类似于发送到打印机的数据形式的文件。广义上,键盘也是文件,虽然它并不能存储数据。
13.1 文件结构分类 (1) 顺序存取 什么时候使用顺序存取?
如果需要顺序地存取记录(一个接一个,从头到尾),则使用顺序文件结构。
(2) 随机存取 什么时候使用随机存取?
如果想存取某一特定记录而不用检索其之前的所有记录,则使用允许随机存取的文件结构。索引文件和散列文件。
文件结构的分类方法如下图所示:
weiyigeek.top-文件结构分类
13.2 顺序文件 定义:顺序文件是指记录只能按照顺序从头到尾一个接一个地进行存取。
通常记录被一个接一个地存储到辅助存储器(磁带或磁盘)中,并在最后的记录加上EOF (文件末尾)的标志,操作系统没有有关记录地址(但记录了磁盘分区)的信息,它只知道记录是一个挨着一个存取的。
应用: 顺序文件用于需要从头到尾存取记录的场景。
例如,将公司里每个职员个人资料存储于一个文件中,月底就可以通过顺序存取检索每条记录来打印工资,因为需要对每一位员工进行处理记录,所以顺序存取比随机存取更简便有效。
然而,顺序文件对随机存取来说效率并不高。例如,如果一个银行的所有客户记录只能被顺序存取,那么一个客户想从自动取款机中提款,就要等到系统从头开始查找直到找到这名客户的信息。如果这个银行有100万个客户,系统在查到记录之前平均要检索50万个记录,效率是非常低的。
顺序文件更新与过程
描述: 顺序文件必须定期更新,以反映信息的变化。更新过程将非常棘手,因为所有记录都要被顺序地检査和更新(必要的话)。
与更新程序有关的一共有4个文件,新主文件、旧主文件、事务文件和错误报告文件,如下图所示,虽然我们用了磁带的符号表示文件,但是我们可以很容易用磁盘的符号表示。
注意在更新完成之后,新主文件要被送到脱机存储器中去,直到再次需要为止。当文件被更新时,主文件将从脱机存储器中检索返回,成为旧主文件。
新主文件:新的永久数据文件通常称为新主文件。新的主文件里包含大部分当前数据。
旧主文件:它是需要更新的永久文件。即使在更新后,旧主文件作为参考将继续保留。
事务文件:第三种文件是事务文件。它包含将要对主文件作的改变。在所有的文件更新中,一共有三种基本类型的改变。添加事务包含将要追加到主文件中的新数据。删除事务把将要从文件中删除的记录标识出来。而更改事务则包含对文件中特定记录的修改。要处理这些事务就需要键。键就是文件中一个或多个能唯一标识数据的字段。例如,在一个关于学生的文件里,键是学生的学号。在一个关于雇员的文件里,键是社会保险号。
错误报告文件:在更新程序中需要的第4个文件是错误报告文件。更新过程中难免不出任何错误。当错误发生时,应向用户报告错误。错误报告包括在数据更新时所发现的错误的清单,并且提供给用户以进行纠错操作。
要使文件更新过程有效率,所有文件都必须按同一个键排序,更新过程要求比较事务文件和主文件中的键,假定在没有错误发生的情况下,更新过程遵循以下步骤(如下图所示):
1)如果事务文件的键小于主文件的键,事务就是一个增加 (A),则将事务追加到新主文件中。
2)如果事务文件的键与主文件的相同,则
3)如果事务文件的键大于主文件的键,将旧主文件记录写入新主文件。
4)有几种情况可能产生一个错误,错误被记录在错误报告文件中:
13.3 索引文件 如果想在文件中随机存取记录,我们就必须知道其记录的地址,而索引文件可以把信息和记录地址关联(对应)起来,即索引将键映射到地址。
索引文件由数据文件组成,它是带索引的顺序文件,索引本身非常小,只占两个字段顺序文件的键和在磁盘上相应记录的地址,所以说索引是基于数据文件的关键字值排序。
例如,一个客户想要查询银行账户,通常会有银行卡或者身份证(理解为Key,身份识别),交于柜台人员进行查询。
由图可知,索引文件的好处之一就是可以有多个索引,每个索引有不同的键,我们熟知的Redis内存数据库。
例如,职员的名单文件可以按社会保险号或姓名来检索,这种索引文件被称为倒排文件。
索引存取过程 :
1 )整个索引文件都载入内存中(文件很小,只占用很小的内存空间)。
2)搜索项目,用高效的算法(如折半查找法)査找目标键。
3)检索记录的地址。
4)按照地址,检索数据记录并返回给用户。
.
13.4 散列文件 散列文件用一个数学函数来完成映射,用户给出键,函数将键映射成地址,再传送给操作系统,以此完成检索记录。
weiyigeek.top-散列文件中的映射
索引文件与散列文件间的区别:
在索引文件中,必须将文件的索引保存在磁盘上,当需要处理数据文件时,先要把索引导入内存中,搜索索引找到数据记录的地址,再访问数据文件存取记录。
在散列文件中,用函数来寻找地址,这里不需要索引和随之而来的所有开销,然而散列文件自身也存在问题。
注意:散列文件无需额外的文件(索引),在键-地址(K/V)映射中,可以选择多种散列方法中的一种。例如,直接散列法、求模法、数字析取法、以及其他流行的方法(像平方中值法、折叠法、旋转法和伪随机法)。
(1) 直接散列法 在直接散列法中,键是未经算法处理的数据文件地址,文件因此必须对每个可能的键都包含一个记录。
虽然用直接散列的情况很少,但它非常有用,因为它保证没有其他方法所存在的同义词或冲突问题(唯一性)。
假如,有一个机构,雇员少于100名,每个雇员都被分配一个1到100之间的编号(雇员ID)。在这种情形下,如果建立了一个有100个记录的文件,雇员的编号可以作为任何单独记录的地址;如图所示,键为025 (John Carver)的记录被散列为地址(扇区)025 ,虽然这是一种理想的方法,但它的应用非常有限。
例如,用社会保险号作为键效率是非常低下的,因为社会保险号有9位。这样需要一个有999 999 999条记录的巨大文件,但是可能只用到不到100条记录。因此,让我们把注意力转到可以把大量可能的键映射为一个小的地址空间的散列技术。
(2) 求模法 求模法也称为除余散列法,求模方法用文件大小去除键后,将余数加1作为地址;
例如下面给出了一个简单散列算法,此处list_size是文件中元素的数目,求模运算的结果加1是因为我们的表始于1而不是0。
address = (Key mod List_size) + 1
虽然这个算法适用于任何列表大小,但是一个为素数的列表大小要比其他的列表大小产生更少的冲突。因此只要可能,尽量用素数作为文件的大小。
例如,创建一个新的可以处理100万雇员的雇员编号系统,同时决定提供可以容纳300名雇员的数据空间,第一个大于300的素数是307,因此选择307作为列表(文件)的大小。
在这种情况下,Bryan Devaux,其键为 121267,被散列到地址 003, 因为 121267 mod 307 = 2, 然后再加1, 就可以得到地址003。
(3) 数字析取法 使用该方法,则选择从键中析取的数字作为地址。
例如,从6位的员工编号中析取3位地址(000- 999),可以选择(从左数)第一、第三和第四位数作为地址。
如,125870 →158 ,122801→ 128 ,121267 → 112
当然,除开上述方法,还有其他流行的方法,像平方中值法、折叠法、旋转法和伪随机法
(4) 冲突解决法 通常散列列表中键的数量比在数据文件中的记录数量要多。
例如,如果你有一个包含50名学生的班级的文件,学生由最后4位社会保险号标识,这样在文件中每个元素就有200 个可能的键(10 000/50 ).因为在文件中有很多键对应于一个地址,有可能多于一个的键将被散列为文件中的同一个地址,我们把列表中一些映射为同一地址的键称为同义词。
例如,下图中,当为两个不同的记录计算地址时,得到相同的地址(214)。显然,两个记录不能储存在同一个地址之中,需要按照下一节所讨论的来解决这种情况。冲突的产生是在散列算法为插入键产生地址时,发现该地址已被占用。
weiyigeek.top-地址冲突
由散列算法产生的地址称为内部地址,包含所有内部地址的区域称为主区。当两个键在内部地址上冲突时,必须将其中一个键和数据存放到主区外的另一个地址单元中来解决冲突。
如何解决此种冲突呢?
我们可以采用如下几种方法来处理冲突,每种都不依赖于散列算法开放寻址/链表解决法/桶散列法/组合方法
开放寻址法:解决在主区的冲突,当一个冲突发生时,主区地址将査找开放的或空闲的记录来用于存放新数据。对于不能在内部地址中存放的数据,一种简单的策略就是把该数据存储在内部地址的下一个地址中去(内部地址+1),但它有个主要缺点是每个冲突的解决增加了将来冲突的可能性。
图13-11 展示了如何用开放寻址解决法解决图13-10中的冲突,第一个记录存在地址214中,下一个记录存在地址215中。
链表解决法:第一条记录存储在内部地址,但它包含了一个指向下一条记录的指针。
图13-12展示了用此方法如何解决图13-10中冲突的情况,可以使用此方法来解决开放寻址主要缺点。
桶散列法:桶是一能接纳多个记录的节点,这种方法的缺点是可能有很多浪费的(未占用的)存储单元。
图13-13展示了如何用桶散列法解决图13-10中的冲突
组合方法:正如散列方法一样,复杂的实现方法通常是组合使用多种方法。
weiyigeek.top-散列方法解决办法
13.5 目录文件 目录是大多数操作系统提供的,用来组织文件(就像是档案柜中的文件夹一样)。但是在大多数操作系统OS中,目录被表示为含有其他文件信息的一种特殊文件类型。
目录的作用不仅仅像一种索引文件,该索引文件告诉操作系统文件在辅助存储设备上的位置,目录还包含了关于它所包含的文件的其他信息,如:谁有访问文件的权限,文件被创建、存取和修改的日期。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ dir /L /Q /T /A:D /X 驱动器 C 中的卷是 OS 卷的序列号是 000E-673F C:\Users\WeiyiGeek 的目录 2020/11/04 23:47 <JUNCTION> applic~1 WEIYIGEEK\WeiyiGeek application data [C:\Users\WeiyiGeek\AppData\Roaming] 2020/07/16 09:57 <DIR> WEIYIGEEK\WeiyiGeek bin $ ls -alh total 401M 1966175 -rw-r--r-- 1 root root 1.5M Feb 7 2021 agent.jar 1966176 -rw-r--r-- 1 root root 9.1M Feb 7 2021 apache-maven-3.6.3-bin.tar.gz 1966222 drwxr-xr-x 2 root root 4.0K Sep 8 23:03 cache
在大多操作系统中,目录被组织成像树的抽象数据类型(ADT), 这种抽象数据类型在第12章中讨论过,其中除根目录外每个目录都有双亲,包含在另一个目录中的目录称为包含目录的子目录。
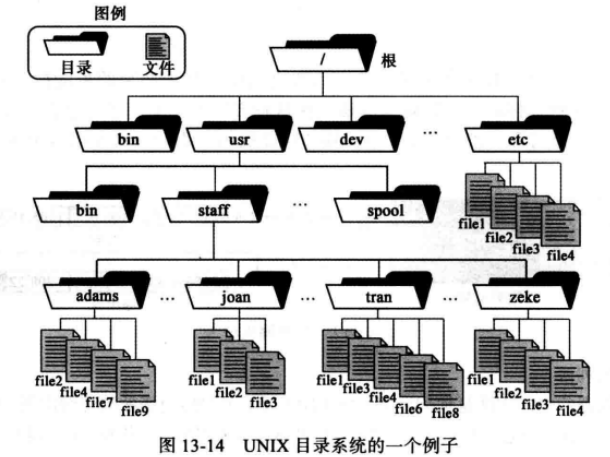
例如,在UNIX操作系统中的目录:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 $ tree -L 1 / / ├── bin -> usr/bin ├── boot ├── cdrom ├── data ├── dev ├── etc ├── home ├── lib -> usr/lib ├── lib32 -> usr/lib32 ├── lib64 -> usr/lib64 ├── libx32 -> usr/libx32 ├── lost+found ├── media ├── mnt ├── opt ├── proc ├── root ├── run ├── sbin -> usr/sbin ├── srv ├── storage ├── swap.img ├── sys ├── tmp ├── usr └── var
(1) 特殊目录 在UNIX中有4种在目录结构中起着非常重要作用的特殊目录类型:根目录、主目录、工作目录和父目录。
根目录: 是文件系统层次结构的最高层。它是整个文件结构的根,因此它没有父目录,并且只有系统管理员能修改它。主目录: 当我们通过终端登录到系统中的用户默认的家目录,例如root用户的/root、普通用户的/home/weiyigeek。工作目录: 也叫当前目录是在用户会话中在任意点我们所在的目录。当首次登录后,工作目录就是我们的主目录,如果有子目录,在会话中,当需要时我们总是喜欢从主目录移到一个或多个子目录中。父目录: 工作目录的直接上层目录,我们在我们的主目录中时,它的父目录就是系统目录中的一个。
此处,以Linux系统的文件目录为例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 根目录 $ ls / bin boot cdrom data dev etc home lib lib32 lib64 libx32 lost+found media mnt opt proc root run sbin srv sys tmp usr var # 主目录 (家目录) ~$ ls /root/ ~$ ls /home/weiyigeek/ # 工作目录 /var/log$ pwd /var/log # 父目录(以工作目录为例) /var/log$ cd .. && pwd /var
(2) 路径和路径名 文件系统的每个目录和文件都必须有一个名字,因此为了唯一地标识一个文件,我们需要指明从根目录到文件的文件路径。文件路径由它的绝对路径名来指明,它是斜线字符(/)分隔的所有目录的列表。
文件或目录又通常分为绝对路径与相对路径,例如:
1 2 相对路径名:weiyigeek/file 绝对路径名:/home/weiyigeek/file
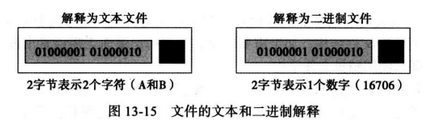
13.6 文本与二进制文件 此处,我们讨论两个用于文件分类的术语,即文本文件和二进制文件。
存储在存储设备上的文件是一个位的序列,可被应用程序翻译成一个文本文件或是二进制文件,如图所示。
weiyigeek.top-文本与二进制文件
(1) 文本文件 文本文件是一个字符文件,在它们的内存储器格式中不能包含整数、浮点数或其他数据结构,要存储这些类型的数据,必须把它们转换成对应的字符格式。
值得注意的是用于键盘、监视器和打印机的文件流(像C++面向对象语言中的输入/输出对象)只能用字符数据格式,这也是为什么需要特殊的函数来格式化上述设备的输入或输出数据。
让我们来看这样一个例子,当数据(文件流)传给打印机时,打印机获得8位数据,解释成1字节,我们将其译码成打印机的编码系统(ASCII或EBCDIC,占八位), 如果字符属于可打印的种类,它将被打印;否则,将执行另外的操作,如打印空白,然后打印机将读取下一个8位数据,依次重复该过程直到数据流结束。
(2) 二进制文件 二进制文件是计算机的内部格式存储的数据集合,在这种定义中,数据可以是整型(包括其他表示成无符号整数的数据类型,例如图像、音频或视频)、浮点型或其他数据结构(除了文件)。
与文本文件的区别?
文本文件是字符的文件
二进制文件是使用计算机内部格式存储的数据集合。
答: 不像文本文件,二进制文件中的数据只有当被程序正确地解释时才有意义,如果数据是文本格式的,就用一个字节来表示一个字符,如果数据是数字格式的,则用两个或是更多字节来表示一个数据项。
例如,假如个人计算机要用2字节来存储一个整数,当读写整数时,计算机就用2字节来表示。