[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/lKygsP6t-s6RGz5Pnx2hkA
11.数据结构 在前面学习中使用变量来存储单个实体,尽管单变量在程序设计语言中被大量使用,但它们不能有效地解决复杂问题,所以我们需要不同的数据结构。
什么是数据结构?
数据结构利用了有关的变量的集合,而这些集合能够单独或作为一个整体被访问,即一个数据结构代表了有特殊关系的数据的集合。
例如:常见的三种数据结构数组(Array)、记录(Record) 和 链表(List).
11.1 数组(Array) 数组(类型)在常见的高级语言中都是被支持,它可以帮助我们处理大量同类型的数据。
数组定义 :数组是元素的顺序集合,通常这些元素具有相同的数据类型。
索引定义 : 表示元素在数组中的顺序号,顺序号从数组开始处计数,通常是从0开始。
在开发中高级语言(C、C++、Java、Go),其数组下标索引常常是从0处开始,例如首个元素 scores[0]由数组名+索引组成,其中 scores是数组名称,0是索引下。
即数组名是整个结构的名字,而元素的名字允许我们查阅这个元素
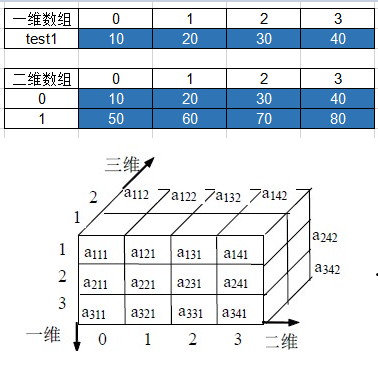
(1) 一、二维或多维数组 一维数组:数据仅是在一个方向上线性组成。
二维数组:数据包括行和列共同指向对应元素,例如 excl 表格。
多维数组:多于二维的数组也是可以的,例如3D空间坐标轴 x,y,z。
weiyigeek.top-一维、二维、多维数组
(2) 数组存储 一维数组:其索引直接定义了元素在实际存储上的相对位置。
例如,有一个一维 weiyigeek 数组有10个整数元素,其中首元素weiyigeek[0]存储的物理地址假设为1000(此处使用十进制演示,通常情况下在计算机中是十六进制表示),
按照在x64系统中 C 语言的 int 整型占 4 Bit,则 尾元素weiyigeek[9] 存储物理地址为 1000+4*9 = 1036
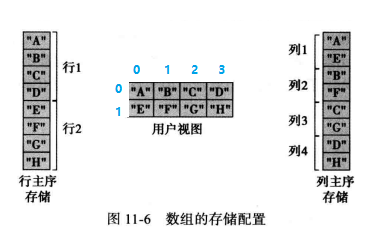
二维数组:使用行和列表示,所以其可以使用行主序存储或列主序存储的,取决于语言特性。
例如,有一个二维数组 weiyigeek 有 5行 x 4列 个元素,假设 weiyigeek [0][0]元素物理地址为 1000 ,并且每个元素占用一个存储地址。
则weiyigeek [2][3] 行存储物理地址为 x起始地址 + Cols * (i) + j = 1000 + 4*2 + 3 = 1011,即该元素的物理地址就是 1011 。
(3) 数组操作 数组作为结构的常用操作有:查找、插入、删除、检索 和遍历.
查找元素 : 我们可以对未排序的数组使用顺序査找,对排序的数组使用折半查找。
插入元素 : 通常计算机语言要求数组的大小(数组中元素的个数) 在程序被写的时候就被定义, 防止在程序的执行过程中被修改,当需要插入元素(尾部、开始或者中间插入)时,通常是将其拷贝到一个新变量中。
尾部插入:如果插入操作在数组尾部进行,而且语言允许增加数组的大小,那便非常简单了。
开始或中间插入:
如果插入操作在开始位置则创建一个新的数组插入首元素后将原数组后续依次移动拷贝。
如果中间插入操作,也是现将查询到元素前面值复制到新数组中,然后插入值,最后将剩余部分元素依次移动拷贝。
删除元素 : 在数组中删除一个元素就像插入操作一样冗长和棘手。例如,如果要删除第9个元素, 则需要把第10个元素到第30个元素向数组的开始位置移动一个位置。
检索元素 : 检索操作就是随便地存取一个元素,达到检查或复制元素中的数据的目的,例如 RetrieveValue ← array[9。
遍历元素:数组的遍历是指被应用于数组中每个元素上的操作,如读、写、应用数学的运算等。
(4) 数组应用 当数据都是同类型时,当需要进行的插入和删除操作数目较少,当需要大量的査找和检索操作时,数组是合适的结构。
11.2 记录(record) 记录定义:它是一组相关元素的集合,它们可能是不同的类型,但整个记录有一个名称,即类似于C/Go语言中的结构体(struct ),在C++/JAVA语言中的类(Class)。
域的定义:记录中的每个元素称为域,域是具有含义的最小命名数据,域不同于变量主要在于它是记录的一部分。
(1) 记录名与域名 重点: 在记录中的元素可以是相同类型或不同类型,但记录中的所有元素必须是关联的(记录中的数据必须都与一个对象关联)。
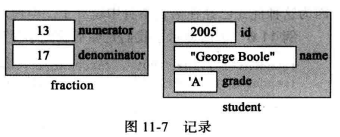
在记录中也有两种标识符(记录的名字和记录中各个域的名字), 记录的名字是整个结构的名字,而每个域的名字允许我们存取这些域, 例如下图中的 student 变量存储的数据。
记录的名字是: student
weiyigeek.top-记录数据类型示例图
第一个例子:fraction 记录,它有两个域,都是整型。
(2) 记录与数组差异 数组定义了元素的集合,而记录定义了元素可以确认的部分。
例如,数组可以定义一个班级的学生(40位学生),而记录定义了学生不同的属性,如标识、姓名或成绩等。
[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/lKygsP6t-s6RGz5Pnx2hkA
11.数据结构 在前面学习中使用变量来存储单个实体,尽管单变量在程序设计语言中被大量使用,但它们不能有效地解决复杂问题,所以我们需要不同的数据结构。
什么是数据结构?
数据结构利用了有关的变量的集合,而这些集合能够单独或作为一个整体被访问,即一个数据结构代表了有特殊关系的数据的集合。
例如:常见的三种数据结构数组(Array)、记录(Record) 和 链表(List).
11.1 数组(Array) 数组(类型)在常见的高级语言中都是被支持,它可以帮助我们处理大量同类型的数据。
数组定义 :数组是元素的顺序集合,通常这些元素具有相同的数据类型。
索引定义 : 表示元素在数组中的顺序号,顺序号从数组开始处计数,通常是从0开始。
在开发中高级语言(C、C++、Java、Go),其数组下标索引常常是从0处开始,例如首个元素 scores[0]由数组名+索引组成,其中 scores是数组名称,0是索引下。
即数组名是整个结构的名字,而元素的名字允许我们查阅这个元素
(1) 一、二维或多维数组 一维数组:数据仅是在一个方向上线性组成。
二维数组:数据包括行和列共同指向对应元素,例如 excl 表格。
多维数组:多于二维的数组也是可以的,例如3D空间坐标轴 x,y,z。
weiyigeek.top-一维、二维、多维数组
(2) 数组存储 一维数组:其索引直接定义了元素在实际存储上的相对位置。
例如,有一个一维 weiyigeek 数组有10个整数元素,其中首元素weiyigeek[0]存储的物理地址假设为1000(此处使用十进制演示,通常情况下在计算机中是十六进制表示),
按照在x64系统中 C 语言的 int 整型占 4 Bit,则 尾元素weiyigeek[9] 存储物理地址为 1000+4*9 = 1036
二维数组:使用行和列表示,所以其可以使用行主序存储或列主序存储的,取决于语言特性。
例如,有一个二维数组 weiyigeek 有 5行 x 4列 个元素,假设 weiyigeek [0][0]元素物理地址为 1000 ,并且每个元素占用一个存储地址。
则weiyigeek [2][3] 行存储物理地址为 x起始地址 + Cols * (i) + j = 1000 + 4*2 + 3 = 1011,即该元素的物理地址就是 1011 。
(3) 数组操作 数组作为结构的常用操作有:查找、插入、删除、检索 和遍历.
查找元素 : 我们可以对未排序的数组使用顺序査找,对排序的数组使用折半查找。
插入元素 : 通常计算机语言要求数组的大小(数组中元素的个数) 在程序被写的时候就被定义, 防止在程序的执行过程中被修改,当需要插入元素(尾部、开始或者中间插入)时,通常是将其拷贝到一个新变量中。
尾部插入:如果插入操作在数组尾部进行,而且语言允许增加数组的大小,那便非常简单了。
开始或中间插入:
如果插入操作在开始位置则创建一个新的数组插入首元素后将原数组后续依次移动拷贝。
如果中间插入操作,也是现将查询到元素前面值复制到新数组中,然后插入值,最后将剩余部分元素依次移动拷贝。
删除元素 : 在数组中删除一个元素就像插入操作一样冗长和棘手。例如,如果要删除第9个元素, 则需要把第10个元素到第30个元素向数组的开始位置移动一个位置。
检索元素 : 检索操作就是随便地存取一个元素,达到检查或复制元素中的数据的目的,例如 RetrieveValue ← array[9。
遍历元素:数组的遍历是指被应用于数组中每个元素上的操作,如读、写、应用数学的运算等。
(4) 数组应用 当数据都是同类型时,当需要进行的插入和删除操作数目较少,当需要大量的査找和检索操作时,数组是合适的结构。
11.2 记录(record) 记录定义:它是一组相关元素的集合,它们可能是不同的类型,但整个记录有一个名称,即类似于C/Go语言中的结构体(struct ),在C++/JAVA语言中的类(Class)。
域的定义:记录中的每个元素称为域,域是具有含义的最小命名数据,域不同于变量主要在于它是记录的一部分。
(1) 记录名与域名 重点: 在记录中的元素可以是相同类型或不同类型,但记录中的所有元素必须是关联的(记录中的数据必须都与一个对象关联)。
在记录中也有两种标识符(记录的名字和记录中各个域的名字), 记录的名字是整个结构的名字,而每个域的名字允许我们存取这些域, 例如下图中的 student 变量存储的数据。
记录的名字是: student
weiyigeek.top-记录数据类型示例图
第一个例子:fraction 记录,它有两个域,都是整型。
(2) 记录与数组差异 数组定义了元素的集合,而记录定义了元素可以确认的部分。
例如,数组可以定义一个班级的学生(40位学生),而记录定义了学生不同的属性,如标识、姓名或成绩等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 使用Go语言演示 package mainimport ( "fmt" ) type User struct { ID string Name string Scores int } func main () var student_array = [...]string ("1001" ,"1002" ,"1003" ) var student_struct = &User{ID: "1001" ,Name: "经天纬地" , Scores: 99 } }
(3) 记录数组与数组差异 如果我们需要定义元素的集合,且同时需要定义元素的属性,那么可以使用记录数组
例如,在一个有30位学生的班级中,我们可以有一个30个记录的数组,每个记录表示一位学生。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 使用Go语言演示 package mainimport "fmt" type User struct { ID string Name string Scores int } func main () var struct_array = [...]User{{ID:"1001" ,Name:"经天纬地" , Scores: 99 },{ID:"1002" ,Name:"WeiyiGeek" , Scores: 100 }} fmt.Printf("%v" ,struct_array) fmt.Printf("%v" ,struct_array[1 ]) }
结果输出:
1 2 [{1001 经天纬地 99} {1002 WeiyiGeek 100}] {1002 WeiyiGeek 100}
由上可以看出数组和记录数组都表示数据项的列表,数组可以被看成是记录数组的一种特例,其中每个元素是只带一个域的记录。
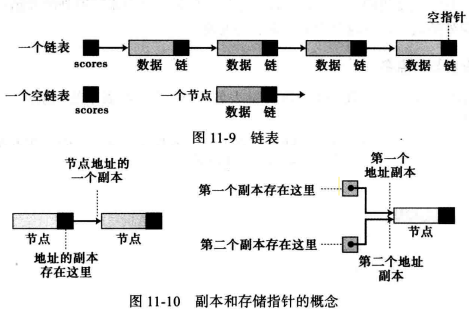
11.3 链表(Link) 链表 :是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表一个数据的集合,其中每个元素包含下一个元素的地址,即每个元素包含两部分数据和链。
数据部分 :包含可用的信息,并被处理。链 :则将数据连在一起,它包含一个指明列表中下一个元素的指针(地址)。另外,一个指针变量标识该列表中的第一个元素,列表的名字就是该指针变量的名字,例如 C语言取链表地址的节点值*link。
例如,下图中,显示了一个称为scores的链表,它含有4个元素(通常称为节点)以及一个空链表的、地址副本例子。
weiyigeek.top-链表示例图
链表的优缺点
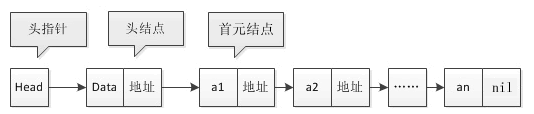
(1) 链表名与节点名 链表必须要有一个名字,并且需要区分链表名和节点名(链表中的元素),
链表名 :是头指针的名字,该头指针指向表中第一个节点,
节点名 :在链表中并没有明显的名字,有的只是隐含的名字,节点的名字与指向节点的指针有关。例如,指向节点的指针称为P,我们称节点为*P。
即,我们常常使用首元结点、头结点和头指针三个概念来表示。
首元结点:就是链表中存储第一个元素的结点,如下图中 a1 的位置。
头结点:它是在首元结点之前附设的一个结点,其指针域指向首元结点。头结点的数据域可以存储链表的长度或者其它的信息,也可以为空不存储任何信息。
头指针:它是指向链表中第一个结点的指针。若链表中有头结点,则头指针指向头结点;若链表中没有头结点,则头指针指向首元结点。
例如,下图所示的单向链表。
weiyigeek.top-单向链表
温馨提示: 头结点在链表中不是必须的,但增加头结点有以下几点好处。
增加了头结点后,首元结点的地址保存在头结点的指针域中,对链表的第一个数据元素的操作与其他数据元素相同,无需进行特殊处理。
增加头结点后,无论链表是否为空,头指针都是指向头结点的非空指针,若链表为空的话,那么头结点的指针域为空。
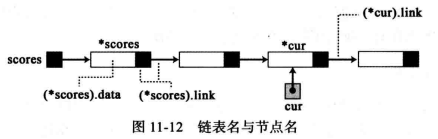
例如,指针P所指节点的数据部分和链部分分别为(*p).data和(*p).link. 这种命名约定隐含着一个节点可以有多于一个的名字。
weiyigeek.top-链表名与节点名
下面以Go语言使用 Struct 作为链表的节点进行演示链表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package mainimport "fmt" type Node struct { Data int Next *Node } func main () var head = new (Node) head.Data = 1000 var node1 = new (Node) node1.Data = 1001 var node2 = new (Node) node2.Data = 1002 head.Next = node1 node1.Next = node2 fmt.Printf("%v \n" ,head) fmt.Println(node1) fmt.Println(node2) }
执行结果:
1 2 3 &{1000 0xc000010220} &{1001 0xc000010230} &{1002 }
(2) 链表操作 链表有 单向链表、双向链表以及循环链表 三种类型,如下演示以单向链表为例。
1.查找链表
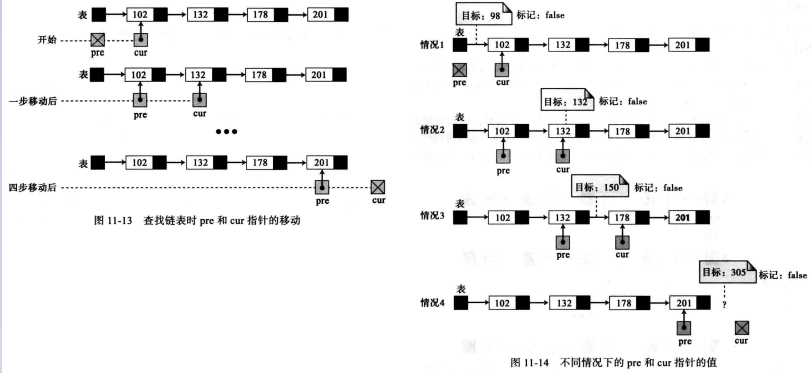
因为链表中的节点没有特定的名字(不像数组中的元素),既然链表中的节点没有名字,那我们使用两个指针:pre (先前的节点)和cur (当前的节点)。
例如,在5个节点的表中,假定目标值是220,它比表中任何值都大,下面都假设是排序后的链表。
在第一种情况中,目标是98 ,此值在链表中不存在,而且比表中任何值都小,所以cur指向第一个节点时,此时pre为空,算法停止。
在第二种情况中,目标是132,此值是第二个节点的值,当 cur 指针指向第二个节点,pre指针指向第一个节点时,算法停止。
在第三种和第四种情况中,目标都没有找到,所以标记的值为假。
weiyigeek.top-链表查找示例图
2.节点插入
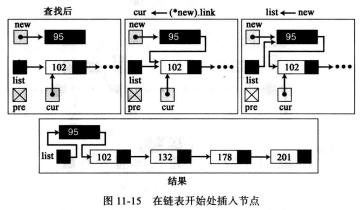
通常会出现以下四种插入情况,在空表中插入、在表的开始处插入、在表的末尾插入、在表中间插入
weiyigeek.top-表开始处插入
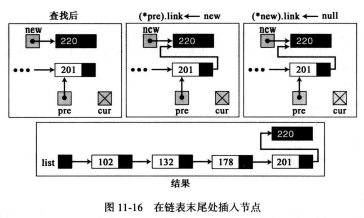
在表的末尾插入: 如果查找算法返回的标记为假,cur指针的值为空,说明已经到链表末尾,那数据就需要插在表的末尾。
weiyigeek.top-在表的末尾插入
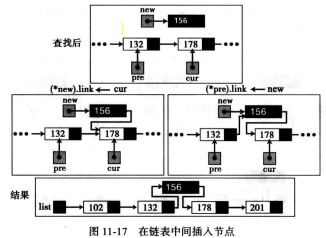
在表中间插入: 如果查找算法返回的标记值为假,判断链表长度,当两个指针都不为空且在链表表中间时,那新数据就需要插在表的中间。
weiyigeek.top-在表中间插入
3.删除节点
在链表中删除节点之前,我们要先应用查找算法,如果査找算法返回的标记是真(节点找到),我们可以从链表中删除该节点。
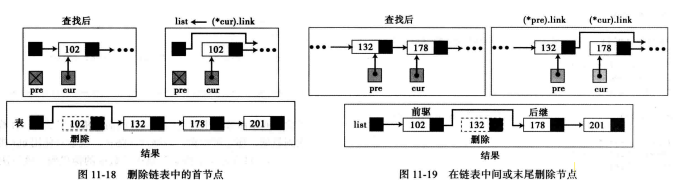
删除首节点:如果pre指针为空,首节点将被删除。
删除中间或末尾节点:如果两个指针都不为空,那要删除的节点或者是中间节点,或者是末尾节点,即通过把后继节点与前驱节点连接在一起,即表明当前节点被删除。
weiyigeek.top-删除链表中的节点
4.检索节点
检索就是为了检査或复制节点中所含数据的目的而随机访问节点。
在检索之前,链表需要被查找,如果找到数据那它被检索,否则过程终止,值得注意检索只使用cur指针,它指向被査找算法找到的节点。
5.遍历链表
为了遍历链表,需要一个“步行”指针,当元素被处理时,它从一个节点移到另一 个节点。
开始遍历时,我们把步行指针指向链表中的首节点,然后使用循环,直到所有数据都被处理,每次循环处理当前节点,然后把步行指针指向下一个节点。当最后一个节点被处理完时,步行指针变为空,循环终止。
此处使用Go语言进行链表的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 package mainimport "fmt" type Node struct { data int next *Node } func Shownode (p *Node) for p != nil { fmt.Println(*p) p=p.next } } func main () var head = new (Node) head.data = 0 var tail *Node tail = head for i :=1 ;i<5 ;i++{ var node = Node{data:i} node.next = tail tail = &node } var temp = Node{data: 100 } temp.next = tail tail = &temp Shownode(tail) fmt.Println("----------------------------------------" ) var end = new (Node) end.data = 0 tail = end for i :=1 ;i<5 ; i++{ var node = Node{data:i} (*tail).next = &node tail = &node } temp = Node{data: 100 } (*tail).next = &temp tail = &temp Shownode(end) }
执行结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 头插法 从大到小 一致指向头结点 {100 0xc00005c220} {4 0xc00005c210} {3 0xc00005c200} {2 0xc00005c1f0} {1 0xc00005c1e0} {0 } ------------------- // 头插法 从小到大 一致指向尾结点 {0 0xc00005c2b0} {1 0xc00005c2c0} {2 0xc00005c2d0} {3 0xc00005c2e0} {4 0xc00005c230} {100 }
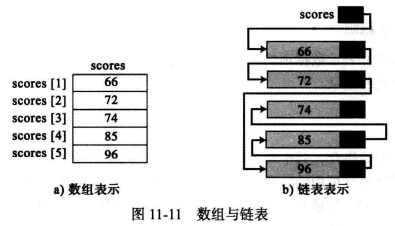
(3) 链表与数组差异 数组和链表都能表示内存中的数据项列表,其唯一的区别在于数据项连接在一起的方式。
在记录数组中,连接工具是索引,物理地址是有序的(连续),例如 元素scores[3]与元素scores[4]相连
在链表中,连接工具是指向下一元素的链(指针或下一元素的地址),其节点尾部的物理地址是无序的,换言之,计算机可以选择连续存储它们或把节点分布在整个内存中。
weiyigeek.top-数组与链表
总结:链表与数组相比,链表可以无限增长,也可以缩短为空,并且节点很容易被删除,不需要移动其他节点,但是不利于数据查询。
(4) 链表应用 当需要对存储数据进行许多插入和删除的场景时,链表是一种非常高效动态的数据结构,其中表从没有节点开始,然后当需要新节点时,它就逐渐增长。
例如,链表可以应用于包含学校学生的记录,每季或每学期,新生进入学校,而有些学生离开学校或毕业的场景。
总结:如果需要大量的插入和删除,那么链表是合适的结构,但查找一个链表比査找一个数组要慢
在下一章中,我们可以看到一些抽象数据类型,它们既有数组对于査找的优点,也有链表对于插入和删除的优点。