[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/V3009OcqY-LHNirueqBHIQ
14.数据库 本章主要讨论数据库和数据库管理系统(DBMS)三层结构, 重点讲解关系数据库模型并举例说明其运算,然后介绍一种在关系数据库上使用的语言(结构化查询语言), 最后简要介绍数据库设计和其他的数据库模型。
14.1 前言简述 数据的存储传统上是使用单独的没有关联的文件有时称为平面文件, 在数据库未出现之前每个应用程序都使用自己的文件, 他们是相对独立存在的为了使数据有关联性, 现在将所有这些平面文件被组合成一个实体的数据库。
(1) 数据库的定义 数据库通常的定义
数据库是一个组织内被应用程序使用的逻辑相一致的相关数据的集合。
(2) 数据库的优点 与平面文件系统相比,我们可以说出数据库系统的几个优点:
冗余较少 : 平面文件系统中存在着大量的冗余,相比之下冗余较少。避免不一致性 : 如果相同的信息被存储在多个地方,那么对数据的任何修改需要在数据存储的所有地方进行, 否则就可能导致数据不一致的问题。效率 :数据库通常比平面文件系统的效率要高得多,因为数据库中一条信息存储在更少的地方。数据完整性 :数据库系统更容易维护数据的完整性,因为数据信息存储在更少的地方。机密性 : 数据是集中存放在一个地方,更容易维护信息的机密性。
(3) 数据库管理系统 数据库管理系统(DBMS)是定义、创建、维护数据库的一种工具, 其允许用户来控制数据库中数据的存取。
数据库管理系统由5部分构成∶硬件、软件、数据、用户和规程。
硬件 :是指允许物理上存取数据的计算机硬件系统。例如,用户终端、硬盘、主机和工作站,都被认为是 DBMS 的硬件组成部分。
软件 :是指允许用户存取、维护和更新物理数据的实际程序。另外,软件工具还可以控制哪些用户可以对数据库中的哪部分数据进行存取。
数据 :数据库中的数据存储在物理存储设备上,数据是独立于软件的一个实体。
用户 : 术语用户在数据库管理系统中有广泛的定义,我们可将将用户分为两类最终用户和应用程序。
最终用户: 指直接从数据库中获取信息的用户,其又划分为数据库管理员(DBA)和普通用户, 其中数据库管理员拥有数据库最大的权限,而普通用户只能使用部分数据库和有限的存取。
规程 : 数据库管理系统的最后一个部分就是必须被明确定义并为数据库用户所遵循的规程或规则的集合。
关系模型的实现是关系数据库管理系统 (RDBMS),RDBMS 将数据移入数据库、存储数据并检索它,以便应用程序可以操作它。
RDBMS 区分以下类型的操作:
逻辑操作: 应用程序指定什么内容为必填项。(如,应用程序请求员工姓名或将员工记录添加到表中。)
物理操作: 确定如何应该做的事情并进行操作。(如,在应用程序查询指定表中特定字段数据时,可能会使用索引来查找请求的行,将数据读入内存,并在将结果返回给用户之前执行许多其他步骤)
Tips : RDBMS 存储和检索数据,以便物理操作对数据库应用程序是透明的。
(4) 数据库分类 当前数据库类型大致分为两类,关系型数据库和非关系型数据库。
关系型数据库
描述: 在 1970 年的开创性论文“大型共享数据库的数据关系模型”中,EF Codd 定义了基于数学集合论的关系模型, 当下最广泛使用的数据库模型就是关系模型。
Q: 关系型数据库的本质是?
答: 关系数据库将数据存储在一组简单的关系中(一种关系是一组元组,一个元组是一组无序的属性值。), 数据以行(元组)和列(属性)形式的关系的二维表示,表中的每一行都具有相同的一组列。
关系模型主要有以下几个方面:
数据结构: 定义良好的对象存储或访问数据库的数据。
操作控制: 明确定义的操作使应用程序能够操作数据库的数据和结构。
管理机制:完整性规则管理对数据库数据和结构的操作。
扩展常见的关系化数据库
非关系型数据库
问: 什么是非关系型数据库(NoSQL)? Key:Value类型的数据库;
非关系型数据库产品
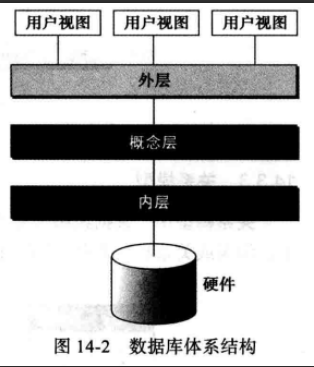
14.2 数据库体系 美国国家标准协会/标准计划和需求委员会(ANSI/SPARC)为数据库管理系统建立了三层体系结构:内层、概念层和外层
weiyigeek.top-数据库体系结构
(1) 内层 内层决定了数据在存储设备中的实际位置,此层次处理低层次的数据存取方法和如何在存储设备间传输字节。
换句话说,内层直接与硬件交互。
(2) 概念层 概念层定义数据的逻辑视图,它是中介层,它使得用户不必与内层打交道。
在此层中定义了数据模式,数据库管理系统的主要功能(如査询)都在该层,数据库管理系统把数据内部视图转化为用户所看到的外部视图。
(3) 外层 外层直接与用户(最终用户或应用程序)交互,它将来自概念层的数据转化为用户所熟悉的格式和视图。
14.3 数据库模型 数据库模型 定义了数据的逻辑设计,它也描述了不同数据之间的联系,在数据库设计发展史中,有三种传统的数据库模型层次、网状和关系等模型。
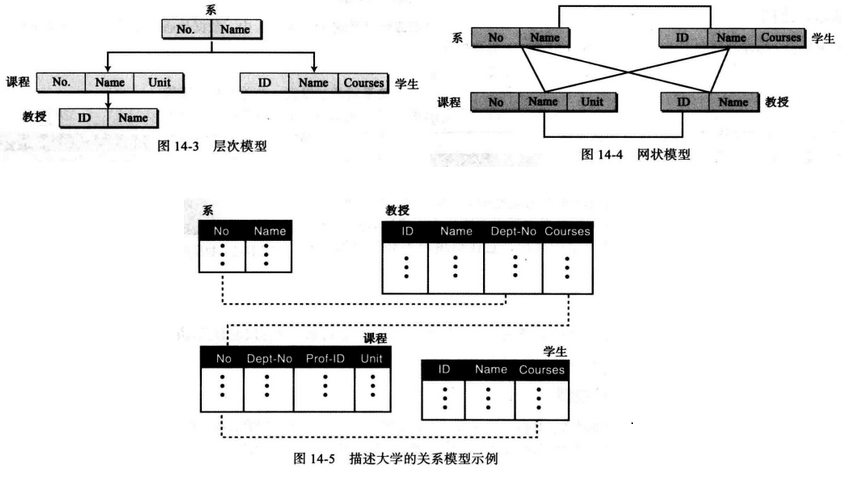
(1) 层次模型 在该模型中,数据被组织成一棵倒置的树,每一个实体可以有不同的子节点,但只能有一个双亲,层次的最顶端有一个实体,称为根。 (PS: 是不是很像我们前面讲解的二叉树呀)
当前,由于层次模型已经过时,我们不再做过多的叙述,只是进行一个简单了解,下图给出层次模型的逻辑图。
(2) 网状模型 在该模型中,实体通过图来组织,图中的部分实体可通过多条路径来访问,同样由于该模型已经过时,我们也不再做过多的描述。
(3) 关系模型 在该模型中,数据组织称为关系的二维表,这里没有任何层次或网络结构强加于数据上,但表或关系相互关联,当前它作为数据库设计中最常用的模型(PS: 后续文章将会持续介绍),下图给出关系型模型的逻辑图。
在后续我将将简要地介绍另外两种常用的、派生于关系模型的数据库模型:分布式模型和面向对象模型。
weiyigeek.top-数据库的三种模型逻辑示意图
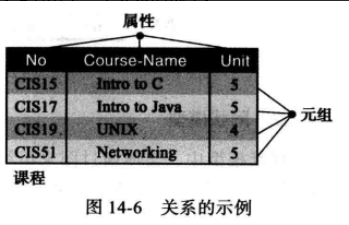
14.4 关系数据库模型 在关系数据库管理系统(RDBMS-Relational Database Management System) 中,数据是通过关系的集合来表示的(数据的外部视图就是关系或表的集合),从表面上看,关系就是二维表,但这并不代表数据以表的形式存储,数据的物理存储与数据的逻辑组织的方式毫无关系。
关系数据库管理系统(RDBMS)中的关系有下列特征:
名称:在关系数据库管理系统中,每一种关系具有唯一的名称,即表名。
属性:关系中的每一列都称为属性,属性在表中是列的头 ,每一个属性表示了存储在该列下的数据的含义。表中的每一列在关系范围内有唯一的名称。关系中属性的总数称为关系的度(例如,图中的关系的度3), 注意属性名并不存储在数据库中,概念层中使用属性给每一列赋予一定的意义,即列名。
元组:关系中的行叫做元组,元组定义了一组属性值。关系中元组的个数叫做关系的基数,当增加或减少元组时,关系的基数就会改变,这就实现了动态数据库,即数据。
weiyigeek.top-关系数据库管理系统示例
14.5 关系数据库操作 在关系数据库中,我们可以定义一些操作来通过已知的关系创建新的关系,例如,采用数据库査询语言SQL (结构化查询语言)进行常规的CURD操作,如插入、删除、更新、选择、投影、连接、并、交和差。
Q: 什么是结构化查询语言 SQL?
它是美国国标协会(ANSI)和国际标准组织(ISO)用于关系数据库上的标准化语言,结构化査询语言于1979 年首次被Oracle 公司实现,它是一种描述性(不是过程化)的语言,这意味着使用者不需要一步步地编写详细的程序而只需声明它,之后有了更多的新版本。
(1) insert - 插入 插入是一元操作,它应用于一个关系,其作用是在表中插入新的元组。
SQL格式如下: INSERT INTO 表名(字段1,字段2) VALUES ("值1","值2")
weiyigeek.top-SQL插入语句
温馨提示: value 子句定义了要插入的相应元组的所有属性,并且字符串的值是要用引号括起来的,而数值就不需要。
(2) delete - 删除 删除也是一元操作,根据要求删除表中相应的元组。
SQL格式如下: delete from 表名 where 字段1=条件
weiyigeek.top-SQL删除操作
温馨提示: 删除的条件是由where 子句定义的,通常在删除数据时一定要带where防止误删表数据(从删库到跑路,😳)
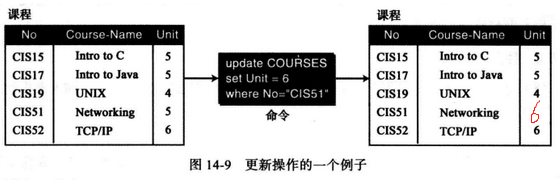
(3) update - 更新操作 更新也是一元操作,它应用于一个关系,用来更新元组中的部分属性值。
SQL格式如下:
[TOC]
计算机科学导论学习笔记 第 5 部分 数据组织与抽象 此部分包含第11 、12 、13 和14 章,讨论了数据结构、抽象数据类型、文件结构以及数据库原理。
在计算机科学中,原子数据汇集成记录、文件和数据库,而数据抽象使得程序员能创建关于数据的抽象观念。
原文地址: https://mp.weixin.qq.com/s/V3009OcqY-LHNirueqBHIQ
14.数据库 本章主要讨论数据库和数据库管理系统(DBMS)三层结构, 重点讲解关系数据库模型并举例说明其运算,然后介绍一种在关系数据库上使用的语言(结构化查询语言), 最后简要介绍数据库设计和其他的数据库模型。
14.1 前言简述 数据的存储传统上是使用单独的没有关联的文件有时称为平面文件, 在数据库未出现之前每个应用程序都使用自己的文件, 他们是相对独立存在的为了使数据有关联性, 现在将所有这些平面文件被组合成一个实体的数据库。
(1) 数据库的定义 数据库通常的定义
数据库是一个组织内被应用程序使用的逻辑相一致的相关数据的集合。
(2) 数据库的优点 与平面文件系统相比,我们可以说出数据库系统的几个优点:
冗余较少 : 平面文件系统中存在着大量的冗余,相比之下冗余较少。避免不一致性 : 如果相同的信息被存储在多个地方,那么对数据的任何修改需要在数据存储的所有地方进行, 否则就可能导致数据不一致的问题。效率 :数据库通常比平面文件系统的效率要高得多,因为数据库中一条信息存储在更少的地方。数据完整性 :数据库系统更容易维护数据的完整性,因为数据信息存储在更少的地方。机密性 : 数据是集中存放在一个地方,更容易维护信息的机密性。
(3) 数据库管理系统 数据库管理系统(DBMS)是定义、创建、维护数据库的一种工具, 其允许用户来控制数据库中数据的存取。
数据库管理系统由5部分构成∶硬件、软件、数据、用户和规程。
硬件 :是指允许物理上存取数据的计算机硬件系统。例如,用户终端、硬盘、主机和工作站,都被认为是 DBMS 的硬件组成部分。
软件 :是指允许用户存取、维护和更新物理数据的实际程序。另外,软件工具还可以控制哪些用户可以对数据库中的哪部分数据进行存取。
数据 :数据库中的数据存储在物理存储设备上,数据是独立于软件的一个实体。
用户 : 术语用户在数据库管理系统中有广泛的定义,我们可将将用户分为两类最终用户和应用程序。
最终用户: 指直接从数据库中获取信息的用户,其又划分为数据库管理员(DBA)和普通用户, 其中数据库管理员拥有数据库最大的权限,而普通用户只能使用部分数据库和有限的存取。
规程 : 数据库管理系统的最后一个部分就是必须被明确定义并为数据库用户所遵循的规程或规则的集合。
关系模型的实现是关系数据库管理系统 (RDBMS),RDBMS 将数据移入数据库、存储数据并检索它,以便应用程序可以操作它。
RDBMS 区分以下类型的操作:
逻辑操作: 应用程序指定什么内容为必填项。(如,应用程序请求员工姓名或将员工记录添加到表中。)
物理操作: 确定如何应该做的事情并进行操作。(如,在应用程序查询指定表中特定字段数据时,可能会使用索引来查找请求的行,将数据读入内存,并在将结果返回给用户之前执行许多其他步骤)
Tips : RDBMS 存储和检索数据,以便物理操作对数据库应用程序是透明的。
(4) 数据库分类 当前数据库类型大致分为两类,关系型数据库和非关系型数据库。
关系型数据库
描述: 在 1970 年的开创性论文“大型共享数据库的数据关系模型”中,EF Codd 定义了基于数学集合论的关系模型, 当下最广泛使用的数据库模型就是关系模型。
Q: 关系型数据库的本质是?
答: 关系数据库将数据存储在一组简单的关系中(一种关系是一组元组,一个元组是一组无序的属性值。), 数据以行(元组)和列(属性)形式的关系的二维表示,表中的每一行都具有相同的一组列。
关系模型主要有以下几个方面:
数据结构: 定义良好的对象存储或访问数据库的数据。
操作控制: 明确定义的操作使应用程序能够操作数据库的数据和结构。
管理机制:完整性规则管理对数据库数据和结构的操作。
扩展常见的关系化数据库
非关系型数据库
问: 什么是非关系型数据库(NoSQL)? Key:Value类型的数据库;
非关系型数据库产品
14.2 数据库体系 美国国家标准协会/标准计划和需求委员会(ANSI/SPARC)为数据库管理系统建立了三层体系结构:内层、概念层和外层
weiyigeek.top-数据库体系结构
(1) 内层 内层决定了数据在存储设备中的实际位置,此层次处理低层次的数据存取方法和如何在存储设备间传输字节。
换句话说,内层直接与硬件交互。
(2) 概念层 概念层定义数据的逻辑视图,它是中介层,它使得用户不必与内层打交道。
在此层中定义了数据模式,数据库管理系统的主要功能(如査询)都在该层,数据库管理系统把数据内部视图转化为用户所看到的外部视图。
(3) 外层 外层直接与用户(最终用户或应用程序)交互,它将来自概念层的数据转化为用户所熟悉的格式和视图。
14.3 数据库模型 数据库模型 定义了数据的逻辑设计,它也描述了不同数据之间的联系,在数据库设计发展史中,有三种传统的数据库模型层次、网状和关系等模型。
(1) 层次模型 在该模型中,数据被组织成一棵倒置的树,每一个实体可以有不同的子节点,但只能有一个双亲,层次的最顶端有一个实体,称为根。 (PS: 是不是很像我们前面讲解的二叉树呀)
当前,由于层次模型已经过时,我们不再做过多的叙述,只是进行一个简单了解,下图给出层次模型的逻辑图。
(2) 网状模型 在该模型中,实体通过图来组织,图中的部分实体可通过多条路径来访问,同样由于该模型已经过时,我们也不再做过多的描述。
(3) 关系模型 在该模型中,数据组织称为关系的二维表,这里没有任何层次或网络结构强加于数据上,但表或关系相互关联,当前它作为数据库设计中最常用的模型(PS: 后续文章将会持续介绍),下图给出关系型模型的逻辑图。
在后续我将将简要地介绍另外两种常用的、派生于关系模型的数据库模型:分布式模型和面向对象模型。
weiyigeek.top-数据库的三种模型逻辑示意图
14.4 关系数据库模型 在关系数据库管理系统(RDBMS-Relational Database Management System) 中,数据是通过关系的集合来表示的(数据的外部视图就是关系或表的集合),从表面上看,关系就是二维表,但这并不代表数据以表的形式存储,数据的物理存储与数据的逻辑组织的方式毫无关系。
关系数据库管理系统(RDBMS)中的关系有下列特征:
名称:在关系数据库管理系统中,每一种关系具有唯一的名称,即表名。
属性:关系中的每一列都称为属性,属性在表中是列的头 ,每一个属性表示了存储在该列下的数据的含义。表中的每一列在关系范围内有唯一的名称。关系中属性的总数称为关系的度(例如,图中的关系的度3), 注意属性名并不存储在数据库中,概念层中使用属性给每一列赋予一定的意义,即列名。
元组:关系中的行叫做元组,元组定义了一组属性值。关系中元组的个数叫做关系的基数,当增加或减少元组时,关系的基数就会改变,这就实现了动态数据库,即数据。
weiyigeek.top-关系数据库管理系统示例
14.5 关系数据库操作 在关系数据库中,我们可以定义一些操作来通过已知的关系创建新的关系,例如,采用数据库査询语言SQL (结构化查询语言)进行常规的CURD操作,如插入、删除、更新、选择、投影、连接、并、交和差。
Q: 什么是结构化查询语言 SQL?
它是美国国标协会(ANSI)和国际标准组织(ISO)用于关系数据库上的标准化语言,结构化査询语言于1979 年首次被Oracle 公司实现,它是一种描述性(不是过程化)的语言,这意味着使用者不需要一步步地编写详细的程序而只需声明它,之后有了更多的新版本。
(1) insert - 插入 插入是一元操作,它应用于一个关系,其作用是在表中插入新的元组。
SQL格式如下: INSERT INTO 表名(字段1,字段2) VALUES ("值1","值2")
weiyigeek.top-SQL插入语句
温馨提示: value 子句定义了要插入的相应元组的所有属性,并且字符串的值是要用引号括起来的,而数值就不需要。
(2) delete - 删除 删除也是一元操作,根据要求删除表中相应的元组。
SQL格式如下: delete from 表名 where 字段1=条件
weiyigeek.top-SQL删除操作
温馨提示: 删除的条件是由where 子句定义的,通常在删除数据时一定要带where防止误删表数据(从删库到跑路,😳)
(3) update - 更新操作 更新也是一元操作,它应用于一个关系,用来更新元组中的部分属性值。
SQL格式如下:
1 2 3 update RELATION-NAME set attributel=valuel, attribute2=value2, ....where criteria
weiyigeek.top-sql更新操作
温馨提示:要改变的属性定义在set子句中,更新的条件定义在where子句中。
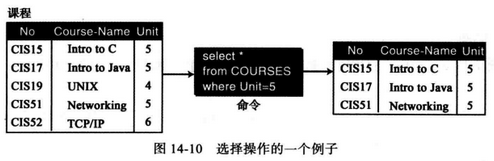
(4) select - 选择操作 选择(查询)也是一元操作,它应用于一个关系并产生另外一个新关系,新关系中的元组(行)是原关系元组的子集,其是根据要求从原表中选择部分元组。
SQL格式如下:
1 select * from RELATION-NAME where criteria;
weiyigeek.top-SQL查询操作
温馨提示: 星号(*)表示所有的属性(字段)都被选择显示。
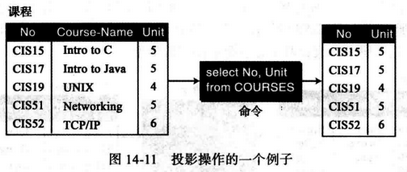
(5) select - 投影操作 投影也是一元操作,它应用于一个关系并产生另外一个新关系。新表中的属性(列)是原表中属性的子集。投影操作所得到的新关系中的元组属性减少,但元组(行)的数量保持不变,新关系的列名被显式地列出。
SQL格式如下: select 字段1,字段2 from 表名
weiyigeek.top-SQL投影操作
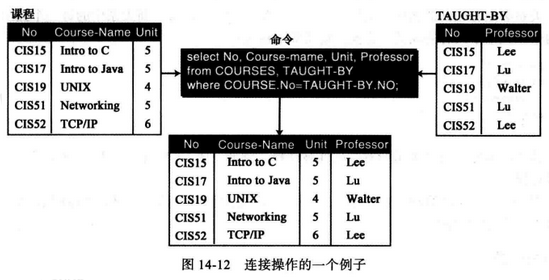
(6) select - 连接操作 连接是二元操作,它基于共有的属性把两个关系组合起来。
SQL格式如下:
1 2 3 select 字段1 ,字段2 from 表1 ,表2 where criteria
weiyigeek.top-连接操作
温馨提示: 属性表是两个输入关系的属性组合,条件明确地定义了作为相同属性的属性,连接操作十分复杂并有很多变化(还可进行分组 group by 等操作)。
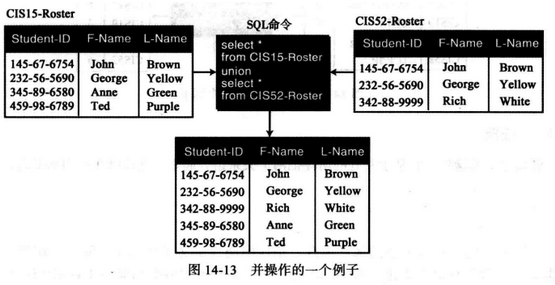
(7) union - 联合查询 并(联合)也是二元操作,它将两个关系合并成一个新的关系,不过这里对两个关系有一个限制,即它们必须有相同的属性。并操作,类似于集合论中的定义,新关系中的每一个元组或者在第一个关系、第二个关系,或者在两个关系中皆有。
SQL 格式如下:
1 2 3 4 5 select *from RELATIONlunion select *from RELATION2
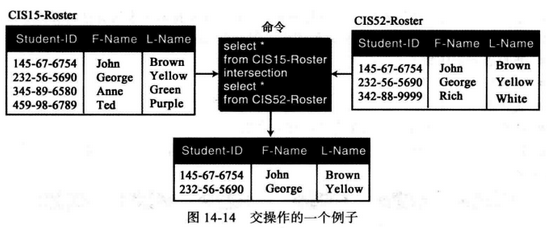
例如,图中给出了两个关系:左上是CIS 15 的花名册,右上是CIS52 的花名册。结果就是一关系,关系中列出了所有包含在CIS15 、CIS52 花名册中,或者两个花名册中都有的学生。
weiyigeek.top-SQL并(联合)操作查询
(8) intersection - 交查询 交也是二元操作,它对两个关系操作,创建一个新关系。和并操作一样,进行交操作的两个关系必须有相同的属性。
交操作,类似于集合论中的定义,新关系中的每一个元组必须是两个原关系中共有的成员。
SQL 格式如下:
1 2 3 4 5 select *from RELATION1intersection select *from RELATION2
例如,图中给出了两个输入关系,经过交操作后,给出了既在CIS15 花名册又在CIS52 花名册中的学生。
weiyigeek.top-SQL交操作查询
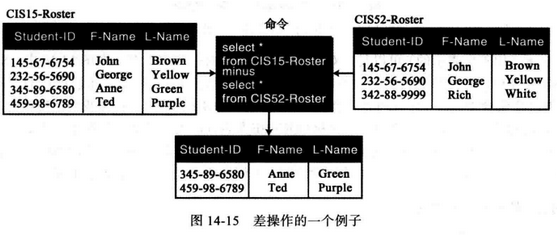
(9) minus - 差查询 差也是二元操作,它应用于具有相同属性的两个关系,生成的关系中的元组是那些存在于第一个关系中而不在第二个关系中的元组。
SQL 格式如下:
1 2 3 4 5 select *from RELATION1 minus select *from RELATION2
weiyigeek.top-SQL差查询
例如,图中给出了两个输入关系,差操作的结果为那些在CIS15 花名册而不在C1S52 花名册中的学生。
除此之外,SQL语言允许我们去组合前面介绍的语言,从数据库中抽取出更复杂的信息,此处不再展开讲解,有兴趣的朋友可以关注我学习MySQL数据库相关学习笔记。
14.6 数据库设计 数据库的设计是一个冗长且只能通过一步步过程来完成的任务。
第一步、通常涉及与数据库潜在用户的面谈(例如,在一个大学里),去收集需要存储的信息和每个部门的存取需求。
第二步、建立一个实体关系模型(ERM), 这种模型定义了其一些信息需要维护的实体、这些实体的属性和实体间的关系。
第三步、建立基于ERM 的关系和规范化这些关系。
(1) 实体关系模型 数据库设计者建立了实体关系(E-R)图来表示那些其信息需要保存的实体和实体间的关系。
问:什么是E-R图?
答:E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
实体(Entity): 方框(矩形)
属性(Property): 椭圆形
关系(Relation): 菱型形,可以是一对一、一对多、多对一和多对多。
线连接属性和实体以及连接实体集和关系集。
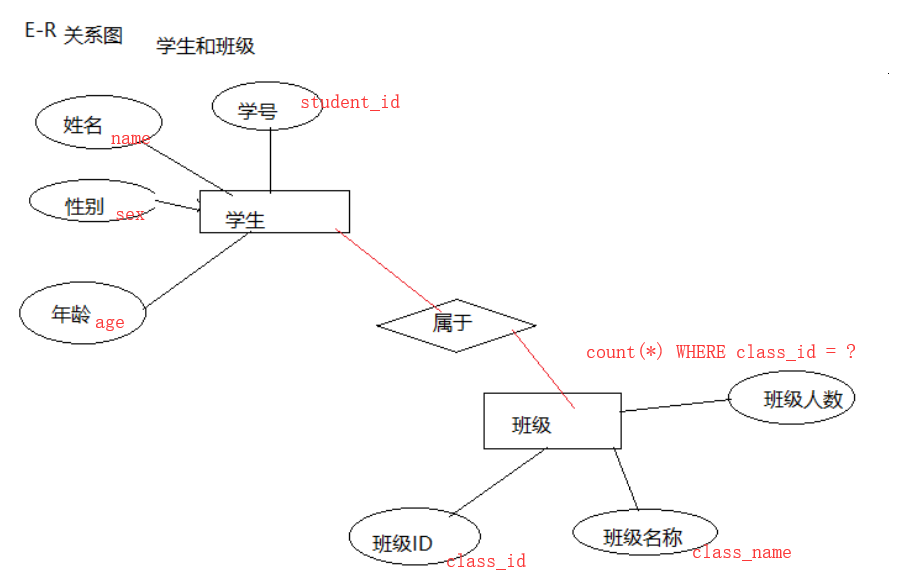
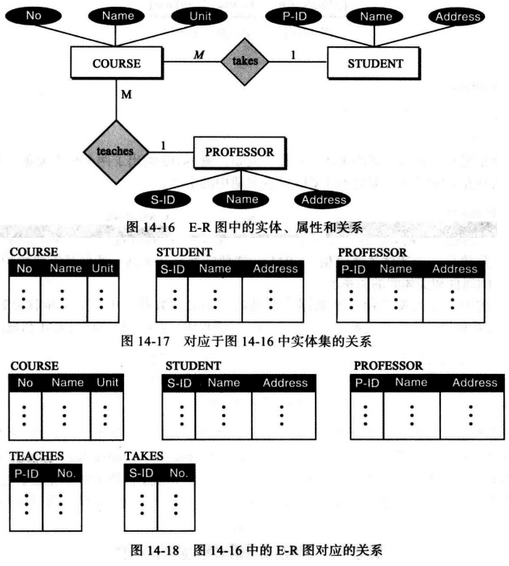
下图显示了一个非常简单的E-R 图,其中有三个实体集及其属性和实体集间的关系。
(2) 从E-R图到关系 在E-R 图完成后,关系数据库中的关系就能建立了。
实体集上的关系: 对于E-R图中的每个实体集,我们都创建一个关系(表),这些关系具有n个列,对应于这个集合所定义的n个属性。关系集上的关系: 对于E-R图中的每个关系集,我们都创建一个关系(表),这个关系中有一个列对应于这个关系所涉及的实体集的关键字,如果关系有属性(本例中没有),这个关系还可以有关系本身的属性对应的列。
例,我们可以有三个关系(表),分别对应于图中所定义的实体集。
例,图中有两个关系集teaches和takes,每一个连接两个实体集,这些关系集的关系被加到先前的实体集关系中。
weiyigeek.top-E-R图中实体、属性和关系
(3) 规范化 规范化是一个处理过程,通过此过程给定的一组关系转化成一组具有更坚固结构的新关系。
规范化要允许数据库中表示的任何关系,要允许像SQL这样的语言去使用由原子操作(全部成功则操作)组成的恢复操作,要移除插入、删除和更新操作中的不规则,要减少当新的数据类型被加入时对数据库重建的需要。
规范化过程定义了一组层次范式(NF),当前多种范式已经被提出,包括1NF、2NF、3NF、BCNF (Boyce-Codd范式)、4NF、PJNF (Projection/Joint 范式)和5NF等。
但是,有一点要知道,那就是这些范式形成了一个层次结构,换言之,如果一个数据库中的关系是3NF,那它首先应该是2NF。
1. 第一范式(1NF)
当我们把实体或关系转换成表格式的关系时,可能有些关系的行或列的交集有多个值。
例如,在图的一组关系中,其中有两个关系teaches和takes就不是第一范式,一个教授可以教授多门课程,而一个学生也可以修多门课程,这两个关系可以通过重复有问题的行来进行规范化。
例如,如果ID 为8256 的教授不再教授课程CIS15, 那我们需要在关系teaches 中删除这个教授记录的一部分,在数据库系统中,我们总是删除一整条记录,而不是一条记录的一部分。
2.第二范式(2NF)
在每个关系中,我们需要有一个关键字(称为主键),所有其他的属性(列值)都依赖于它。
例如,如果学生的ID给定后,就应该有可能找到学生的姓名。但是,当关系是根据E-R图建立时,我们可能有一些复合的关键字(两个或两个以上关键字的组合)
在这种情况下,如果每一个非关键字属性都依赖于整个复合关键字,那么这个关系就是第二范式的。如果有些属性只依赖于复合关键字的一部分,那这个关系就不是第二范式的。
假设我们有一个关系,有4 个属性(Student ID, Course No, Student Grade, Student Name),其中前两个组成一个复合关键字。学生的成绩是依赖于整个关键字的,但姓名只依赖于关键字的一部分。
3.其他范式
14.7 其他数据库模型 前面我们说过,关系数据库并不是当今唯一通用的数据库模型,另两种通用模型是:分布式数据库和面向对象数据库,我们这里只简要地介绍这两种模型。
(1) 分布式数据库 该模型实际上并不是一个新的模型,而是基于关系模型的,只不过是将数据库中的数据存储在一个通信网络中不同的计算机(服务器、工作站)上,每台计算机(或者站点)拥有部分或全部数据库。
不完全的分布式数据库
在不完全的分布式数据库中,数据是本地化的,本地使用的数据存储在相应的站点上,同时还可以通过因特网或广域网访问其他节点上的数据。
例如,一个医药公司在许多城市拥有多个站点,每个站点有一个数据库,存储着自己的雇员信息,但是中心人事部门能控制所有的数据库。
复制式的分布式数据库
在复制式的分布式数据库中,每个站点都有其他站点的一个完全副本,当对一个站点的数据进行修改时将会同步修改其他站点的副本数据。
此种方式,通常用于企业生产环境,即保证了高可用性,也保证了数据的安全性。
(2) 面向对象数据库 关系数据库具有数据的特定视图,该视图基于该关系数据库的本性(元组和属性),其最小的数据集合就是一个元组与一个属性列的交集,面向对象数据库在试图保留关系模型优点的同时允许应用存取结构化数据。
在面向对象数据库中,定义了对象和它们的关系,另外,每一个对象可以具有属性并以域的形式表达。
例如,在某个组织中,可以定义对象类型,如雇员、部门和客户。
另外,数据库还可以建立雇员与部门间的关系(一个雇员在一个部门工作)。
扩展知识
通常用作面向对象数据的査询语言是XML (Extensible Markup Language),起初XML是用来给文本文档增加标记信息的,但它还应用于数据库査询语言,XML 能用嵌套结构表示数据。